













האטת השקיפון ב־PostgreSQL מתרחשת כאשר שינויים שנעשו בשרת הראשי לוקחים זמן כדי להתבטא בשרת הרפליקה. בין אם משתמשים בשקיפון זרים או שקיפון לוגי, ההטלה יכולה להשפיע על ביצועים, עקביות וזמינות במערכת. הפוסט הזה מכסה את סוגי השקיפון, ההבדלים ביניהם, סיבות להטלה, נוסחאות מתמטיות להערכת הטלה, טכניקות מעקב, ואסטרטגיות למינומום האטת השקיפון.
סוגי השקיפון ב־PostgreSQL
שקיפון זר
שקיפון זר שולח באופן מתמיד את השינויים ב־Write-Ahead Log (WAL) מהשרת הראשי אל שרתי הרפליקה אחד או יותר בזמן רציני קרוב לזמן אמת. הרפליקה מיישמת את השינויים בסדר רציף כפי שהם מתקבלים. שיטה זו משקפת את כל בסיס הנתונים ווודאי שהרפליקות נשארות מסונכרנות.
יתרונות
- האטה נמוכה עם סנכרון בזמן אמת קרוב לזמן אמת.
- יעיל לשקיפון של בסיס נתונים שלם.
חסרונות
- הרפליקות הן לקריאה בלבד, לכן כל עסקאות כתיבה צריכות לעבור לשרת הראשי.
- אם חיבור הרשת נקטע, ההטלה עשויה להתרחש באופן משמעותי.
שקיפון לוגי
שכפול לוגי מעביר שינויים ברמת הנתונים במקום שינויים ברמת ה-WAL הנמוכה. זה מאפשר שכפול סלקטיבי, שבו רק טבלאות או חלקים ספציפיים של בסיס נתונים משוכפלים. שכפול לוגי משתמש בתהליך דיקוד לוגי כדי להמיר שינויים של WAL לשינויים בדומים ל-SQL.
יתרונות
- מאפשר שכפול סלקטיבי של טבלאות או סכמות ספציפיות.
- תומך בשכפולים ניתנים לכתיבה עם אפשרויות פתרון קונפליקטים.
חסרונות
- לְאַט גבוה יותר בשל עלות הדיקוד הלוגי.
- זה פחות יעיל משכפול סטרימינג עבור מערכות נתונים גדולות.
כיצד מתרחש פיגור בשכפול
פיגור בשכפול מתרחש כאשר קצב השינויים שנוצרים בשרת הראשי עולה על הקצב שבו ניתן לעבד ולהחיל אותם על השרת השכפול. חוסר האיזון הזה יכול להתרחש בגלל גורמים שונים, שכל אחד מהם תורם לעיכובים בסנכרון הנתונים. הגורמים השכיחים ביותר לפיגור בשכפול הם:
עיכוב רשת
עיכוב רשת מתייחס לזמן שלוקח לנתונים לעבור מהשרת הראשי לשרת השכפול. קטעי WAL (יומן כתיבה מקדימה) מועברים כל הזמן דרך הרשת במהלך שכפול סטרימינג. אפילו עיכובים קטנים בהעברת נתונים ברשת יכולים להצטבר, causing the replica to lag.
גורמים
- זמני חזרה ברשת (RTT) גבוהים.
- יותר רוחב פס כדי להתמודד עם כמויות גבוהות של נתוני WAL.
- congestיה ברשת או אובדן מנות.
אם השרת הראשי יוצר שינויים משמעותיים במהלך שעות השיא, רשת איטית או עמוסה יכולה לגרום לבקבוק, במניעה שהשכפול יקבל שינויים ב-WAL.
פתרון
השתמש בחיבורי רשת בעלי השהייה נמוכה ורוחב פס גבוה והפעל דחיסת WAL (wal_compression = on) כדי להפחית את גודל הנתונים במהלך ההעברה.
צווארי בקבוק ב-I/O
צווארי בקבוק ב-I/O מתרחשים כאשר הכונן של שרת השכפול איטי מדי כדי לכתוב את שינויי ה-WAL הנכנסים. שכפול סטרימינג מתבסס על כתיבת שינויים לכונן לפני שהם מיועדים, כך שכל עיכוב במערכת I/O עלול לגרום לצבירה של עיכוב.
סיבות
- כוננים קשיחים (HDDs) איטיים או עמוסים.
- קצב כתיבה לכונן לא מספיק.
- תחרות על הכונן מתהליכים אחרים.
- אם שרת השכפול משתמש בכוננים מסתובבים (HDD) ולא בכוננים סוליד סטייט (SSD), שינויים ב-WAL עשויים שלא להיכתב מספיק מהר כדי לעמוד בקצב שינויים בנתונים, מה שיגרום לשכפול להישאר מאחור ביחס לראשי.
פתרון
כדי להאיץ את I/O של כונן בשכפול, השתמש ב-SSDs עבור מהירות כתיבה גבוהה יותר והפרד את תהליכי השכפול משאר המשימות הכבדות על הכונן.
מגבלות CPU/זיכרון
תהליכי שכפול דורשים מעבד וזיכרון כדי לפענח, לכתוב ולהחיל שינויים. אם לשרת השכפול אין מספיק כוח עיבוד או זיכרון, הוא עלול להיאבק לעמוד בקצב עם השינויים המגיעים, דבר שיגרום לעיכוב בשכפול.
סיבות
- ליבות מעבד מוגבלות או מעבדים איטיים.
- זיכרון לא מספק עבור буфери WAL.
- תהליכים אחרים צורכים משאבי מעבד או זיכרון.
- אם השכפול מעבד עסקאות גדולות או מפעיל שאילתות במקביל לשכפול, המעבד עלול להיות רווי, מה שיאט את תהליך השכפול.
פתרון
הקצה יותר ליבות מעבד וזיכרון לשרת השכפול. הגדל את גודל ה-wal_buffers כדי לשפר את היעילות של עיבוד ה-WAL.
עומסים כבדים על השרת הראשי
עיכוב בשכפול יכול להתרחש גם כאשר השרת הראשי מפיק יותר מדי שינויים מהר מדי עבור השכפול להתמודד איתם. עסקאות גדולות, הוספות מסיביות או עדכונים תכופים עלולים להעמיס על השכפול.
סיבות
- ייבוא נתונים מסיביים או עסקאות גדולות.
- עדכונים בתדירות גבוהה לטבלאות גדולות.
- עומסי עבודה עם תחרות גבוהה על הראשי.
- עומס העסקאות עשוי להיות כבד מדי אם השרת הראשי מעבד מספר עסקאות גדולות במקביל, כמו במהלך ייבוא נתונים מסיבי. נפח נתוני ה-WAL יכול לעלות על מה שהשכפול יכול לעבד בזמן אמת, מה שמגביר את העיכוב.
פתרון
שפרו את העסקאות על ידי איחוד יותר של עדכונים קטנים ומניעת עסקאות ארוכות. אם סנכרון מחמיר אינו חיוני, השתמשו בשיטת שילוב כגון שכפול אסינכרוני כדי להפחית את המשאבים הנדרשים לשיכפול.
תחרות על משאבים
תחרות על משאבים מתרחשת כאשר תהליכים מרביים תחרו על אותם משאבים, דוגמת CPU, זיכרון או כונן I/O. זה עלול לקרות גם בשרת הראשי וגם בשרת הרפליקה ולגרום להשהיות בעיבוד השכפול.
גורמים
- תהליכים אחרים צורפים כונן I/O, CPU או זיכרון.
- משימות רקע כגון גיבויים או אנליטיקה בשימוש רציף.
- תחרות ברשת בין תעבורת השכפול וההעברות הנתונים האחרות.
- אם שרת הרפליקה רץ גם גיבויים או שאילתות אנליטיות, התחרות על משאבי CPU וכונן עשויה להאט את תהליך השכפול.
פתרון
בדיקו את עומס השכפול מפעולות אחרות שמצריכות משאבים רבים. תזמנו גיבויים ואנליטיקות בשעות פחות עמוסות כדי למנוע הפרעה בשכפול.
נוסח מתמטי להשהיית שכפול
השתמשו בנוסחא הבאה כדי לחשב את ההשהייה בשכפול:

בשכפול לוגי, זמן נוסף נצרך על ידי חישוב לוגי:

מעקב אחר השהיית השכפול
מעקב אחר השהיית השכפול בזמן אמת
התצוגה pg_stat_replication ניתנת לשימוש לניטור איחור בשקלול זרימתי. היא מספקת מבט על מצב ואיחור בין שרת הראשי ושרת הרפליקה.
SELECT application_name, state,
pg_size_pretty(sent_lsn - write_lsn) AS lag_bytes,
sync_state
FROM pg_stat_replication;
sent_lsn: המיקום האחרון של WAL שנשלח לרפליקה.write_lsn: המיקום האחרון של WAL שנכתב על הרפליקה.lag_bytes: ההבדל ביניהם מציין איחור.
ניטור של שיטת השקלול הלוגי
איחור בשיטת השקלול הלוגי ניתן לנטור באמצעות התצוגה pg_stat_subscription.
SELECT subscription_name, active,
pg_size_pretty(pg_current_wal_lsn() - replay_lsn) AS lag_bytes
FROM pg_stat_subscription;
דוגמה: ויזואליזציה של איחור בשקלול
קטע קוד פייתון הבא מציג ויזואליזציה של איחור בשקלול זרימתי ולוגי לאורך זמן.
import matplotlib.pyplot as plt
time = ['12:00', '12:10', '12:20', '12:30', '12:40', '12:50', '13:00']
streaming_lag = [0.5, 0.6, 0.4, 0.7, 1.0, 0.9, 0.6]
logical_lag = [2.0, 2.5, 3.0, 2.8, 3.5, 4.0, 3.2]
plt.plot(time, streaming_lag, label='Streaming Replication Lag', marker='o')
plt.plot(time, logical_lag, label='Logical Replication Lag', marker='s')
plt.xlabel('Time')
plt.ylabel('Lag (seconds)')
plt.title('Replication Lag Over Time')
plt.legend()
plt.grid(True)
# Save the plot as an image file
plt.savefig('replication_lag_plot.png')
print("Plot saved as replication_lag_plot.png")
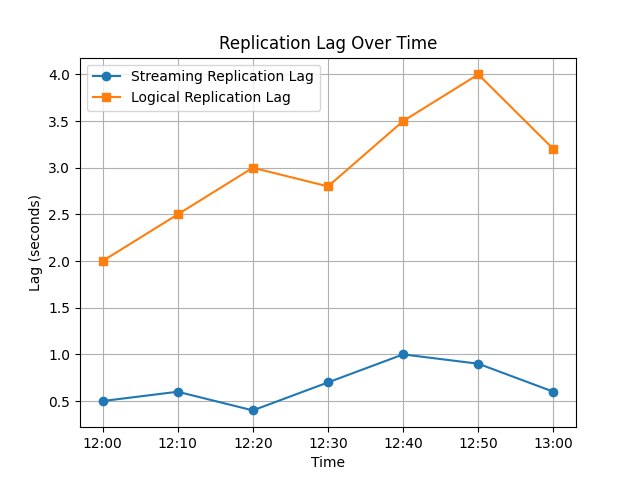
הגרף המתוצאה משווה בין ביצועי השקלול הזרמתי והלוגי. השקלול הלוגי נטיית להציג איחור משתנה יותר עקב הוצאת קוד ועיבוד.
איך להפחית את איחור השקלול
1. לייעל את התצורת WAL
- הגדל את
wal_buffersכדי להחזיק יותר נתוני WAL בזיכרון. - הגדר
wal_writer_delayלערך נמוך יותר (לדוגמה, 10 מילישניות) כדי לכתוב נתוני WAL במהירות יותר.
wal_buffers = 64MB
wal_writer_delay = 10ms
2. שפר ביצועי רשת
- השתמש בחיבורי רשת בעלי נמוך בלטנציה ורוחב פס גבוה בין השרת הראשי והשאליים.
- דחוף את נתוני ה-WAL במהלך העברתם על ידי דחיסתם:
wal_compression = on.
3. השתמש בשיבוץ אסינכרוני (כאשר אפשר)
-
שיבוץ אסינכרוני מפחית את העיכוב על ידי אי המתנה לאישור של השאליים על שינויים, אך מביא לסיכון אובדן נתונים.
ALTER SYSTEM SET synchronous_commit = 'off';
4. הפעל אפשרות החילוק הקבוצתי בשיבוץ לוגי
-
PostgreSQL 14+ מאפשר חילוק קבוצתי של שינויים לוגיים, מפחית את העיכוב עבור עסקאות גדולות.
ALTER SUBSCRIPTION my_subscription SET (parallel_apply = on);
5. הקצה יותר משאבים לשרתים שאליהם משנים
- וודא שהרפליקה יש לה מספיק CPU וזיכרון כדי לעבד שינויים ב-WAL במהירות.
- השתמש ב-SSDs עבור קריאות כתיבה מהירות יותר על הרפליקה.
6. עסק בתהליכי עסקאות באופן קבוצתי
-
קבץ עדכונים משניים מרביים לתהליכי עסקאות פחות כדי למזער עלות.
דוגמאות ממציאות
הפחתת האיחור בשידורי רפליקציה
חברה המריצה אשכול PostgreSQL בעל תעבורת גבוהה נתקלה באיחור ברפליקציה בשעות השיא. הם הצליחו להפליא את האיחור ברפליקציה למחצית על ידי הגדלת wal_buffers ל-64 מגה-בייט והפחתת wal_writer_delay ל-10 מילישניות. החלפה לחיבור רשת מהיר יריד את האיחור לפחות משנייה.
הפחתת האיחור ברפליקציה לוגית
מערכת עם מספר מנויים לוגיים נתקלה באיחור במהלך עומס כתיבה גבוה. הפעלת האפשרות ליישום מקבילי ב-PostgreSQL 14 פיזרה את העומס על מספר עובדים, מהפחית את האיחור ברפליקציה מ-4 שניות לפחות משנייה.
מסקנה
איחור ברפליקציה הוא בעיה קריטית שמשפיעה על הביצועים והעקביות של מערכות PostgreSQL. רפליקצית שידור מציעה זמן תגובה נמוך אך מחייבת שכל בסיס הנתונים יש לשפר, בעוד רפליקצית לוגית מספקת גמישות אך עם עלות גבוהה יותר. מעקב רגיל באמצעות pg_stat_replication ו-pg_stat_subscription מאפשר למנהלים לזהות ולהפחית את האיחור.
ייעול הגדרות WAL, שיפור ביצועי הרשת, שימוש ביישומים מקביליים והקצאת משאבים מספיקה עשויים להפחית באופן משמעותי את העיכוב. הכוונון המתאים מבטיח שהשכפולים יישארו מסונכרנים והמערכת תשמור על זמינות גבוהה וביצועים.
Source:
https://dzone.com/articles/understanding-and-reducing-postgresql-replication-lag