













שירות VAR-As-A-Service הוא גישה MLOps ליישום ומיתוג של מודלים סטטיסטיים ומודלים ללמידה מלאכותית, ולשימוש חוזר בזרמי פלט של מודלים אלה. זהו הפרק השני בסדרת המאמרים שנבנה על פי הפרויקט, המייצג ניסויים עם מודלים סטטיסטיים ומודלים ללמידה מלאכותית שונים, זרמי נתונים שהונצלו באמצעות כלים DAG קיימים, ושירותי אחסון, גם מבוססי אינטרנט וגם פתרונות מקומיים חלופיים. מאמר זה מתמקד באחסון קבצי המודל באמצעות גישה שניתן ליישם גם למודלים ללמידה מלאכותית. האחסון שהונצל מבוסס על MinIO כשירות אחסון אובייקטים מתאים ל-AWS S3. בנוסף, המאמר מביא סקירה של פתרונות אחסון חלופיים ומסביר את היתרונות של אחסון מבוסס אובייקט.
המאמר הראשון בסדרה (ניתוח רצף הזמן: VARMAX-As-A-Service) משווה בין מודלים סטטיסטיים ומודלים ללמידה מלאכותית כמודלים מתמטיים ומספק יישום מקלט עד מוצא של מודל סטטיסטי מבוסס VARMAX לחיזוי כלכלי באמצעות ספריית Python הנקראת statsmodels. המודל מופעל כשירות REST באמצעות Python Flask ושרת אינטרנט Apache, וארוז במכובד Docker. הארכיטקטורה הרמה-גבוהה של האפליקציה מתוארת בתמונה הבאה:
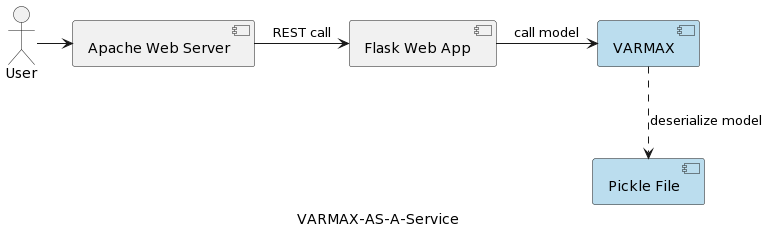
המודל מתועד כקובץ פיקל ומופעל על שרת האינטרנט כחלק מחבילת השירות של REST. עם זאת, בפרויקטים ממשיים, המודלים מקבלים גישה מסוגרת, מלווים במידע מטא-נתונים, מוגנים, ונסיונות האימון צריכים להיות מתועדים ומאוחסנים כך שיהיה אפשרי לשחזר אותם. עוד, מנקודת מבט ארכיטקטונית, אכן שמירת המודל במערכת הקבצים ליד היישום סותרת את עקרון האחריות היחידה. דוגמה טובה היא ארכיטקטורת מיקרוסרביס. קיבוע שירות המודל באופן אופקי פירושו של כל מצב של מיקרוסרביס יהיה גרסה משלו של הקובץ הפיזי של פיקל המופץ על כל מצבי השירות. זה גם אומר שתמיכה במספר גרסאות של המודלים תדרוש שחרור חדש והפעלה מחדש של שירות ה-REST והתשתיות שלו. המטרה של המאמר הזה היא להפריד בין המודלים לבין תשתיות שירות האינטרנט ולאפשר שימוש חוזר בהיגיון שירות האינטרנט עם גרסאות שונות של המודלים.
לפני שנצלול למימוש, בואו נוסיף מילה או שתיים על מודלים סטטיסטיים והמודל VAR המשמש בפרויקט זה. מודלים סטטיסטיים הם מודלים מתמטיים, וכך גם מודלים למידה מלאכותית. על ההבדל בין שני הסוגים ניתן למצוא במאמר הראשון בסדרה. מודל סטטיסטי בדרך כלל מוגדר כקשר מתמטי בין משתנים רנדומליים אחד או יותר ומשתנים לא רנדומליים אחרים. אורקט התפלגות עצמית וקטורית (VAR) הוא מודל סטטיסטי המשמש ללכידת הקשר בין כמות מרובה כפי שהיא משתנה לאורך זמן. מודלי VAR מכפילים את המודל הרגיל של התפלגות עצמית במשתנה אחד (AR) על ידי אפשרות לסדרות זמן רב ממדיות. בפרויקט המוצג, המודל מאומן לבצע תחזית לשני משתנים. מודלי VAR משמשים לעתים קרובות בכלכלה ובמדעי הטבע. באופן כללי, המודל מיוצג על ידי מערכת משוואות, שבפרויקט מוסתרות מאחורי ספריית Python statsmodels.
הארכיטקטורה של יישום שירות המודל VAR מתוארת בתמונה הבאה:
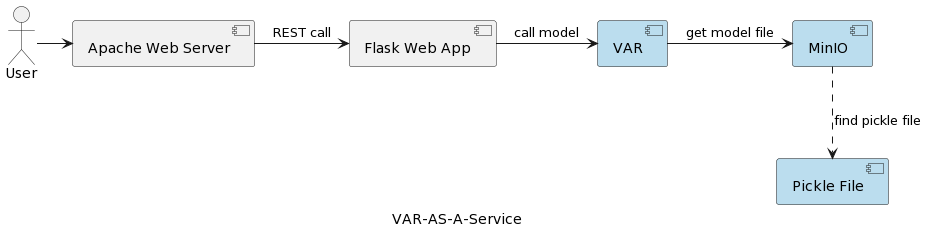
רכיב הריצה של VAR מייצג את ביצוע המודל האמיתי על סמך הפרמטרים שנשלחו על ידי המשתמש. הוא מתחבר לשירות MinIO דרך ממשק REST, מוצא את המודל ומבצע את החיזוי. לעומת הפתרון במאמר הראשון, שם המודל VARMAX מועלה ומפורש בהתחלת היישום, המודל VAR נקרא משרת MinIO בכל פעם שנדרש חיזוי. זה בא עם עלות נוספת של זמן טעינה ופירוש, אך גם עם היתרון של שימוש בגרסה העדכנית ביותר של המודל בכל פעם שהוא פועל. בנוסף, זה מאפשר גישה דינמית לגרסאות המודלים, מה שהופך אותם לנגישים אוטומטית למערכות ולמשתמשים חיצוניים, כפי שיוצג מאוחר יותר במאמר. שים לב שבגלל עלויות הטעינה האלה, ביצועי שרת האחסון הנבחר הם חשובים מאוד.
אבל למה MinIO ואחסון מבוסס אובייקטים באופן כללי?
MinIO היא פתרון אחסון אובייקטים בעלת ביצועים גבוהה עם תמיכה מקורית בפריסות Kubernetes שמספקת API מתאים ל-Amazon Web Services S3 ותומכת בכל התכונות המרכזיות של S3. בפרויקט המוצג, MinIO מופעל במצב סטנדלון, המורכב משרת MinIO יחיד ומכונית או נפח אחסון יחיד ב-Linux באמצעות Docker Compose. לצורך סביבות פיתוח מורחבות או סביבות יצור, ישנה אפשרות למצב המופץ המתואר במאמר לפרוס את MinIO במצב מופץ.
בואו נעבור במהירות על כמה אלטרנטיבות אחסון בעת שתיאור מקיף ניתן למצוא כאן ו-כאן:
- אחסון קבצים מקומי/מרוחב: אחסון קבצים מקומי הוא הפתרון שהוכנס במאמר הראשון, שכן זו האפשרות הפשוטה ביותר. חישוב ואחסון מתרחשים באותו מערכת. זה מתאים במהלך שלב ההוכחת עקרון או עבור מודלים פשוטים מאוד התומכים בגרסה יחידה של המודל. מערכות האחסון המקומיות מצויות בקיבולת אחסון מוגבלת ואינן מתאימות למערכים גדולים יותר במידה ורוצים לאחסן מסמכים נוספים כמו המערך המדעני שנמצא בשימוש. מאחר ואין שיכפול או התרחבות אוטומטית, מערכת האחסון המקומית לא יכולה לפעול באופן זמין, אמין ונרחב. כל שירות שמופק להתרחבות אופקית מופעל עם העתק משלו של המודל. כמו כן, האחסון המקומי בטוח ככמות המערכת המארחת. ברורים לאחסון הקבצים המקומי הם NAS (מערכת אחסון מחוברת לרשת), SAN (רשת אחסון מקצועית), מערכות אחסון מרוחב (מערכת הקבצים המרוחבת של הדפון (HDFS), מערכת הקבצים של גוגל (GFS), מערכת הקבצים האלסטית של אמזון (EFS) ו- Azure Files). לעומת המערכת האחסון המקומית, הפתרונות האלה מאופיינים על ידי זמינות, נרחבות ועמידות, אך מגיעים עם העלות של מורכבות מוגברת.
- מבני נתונים רלוונטיים: בגלל המילוי הבינארי של מודלים, מבני נתונים רלוונטיים מספקים את האפשרות לאחסון blob או בינארי של מודלים בעמודות של טבלאות. מפתחי תוכנה ורבים ממדעני הנתונים מכירים מבני נתונים רלוונטיים, מה שהופך את הפתרון לישיר. גירסאות מודל יכולות להישמש כשורות טבלאות נפרדות עם מטא-נתונים נוספים, שקל לקרוא מהמסד הנתונים, גם כן. חיסרון הוא שהמסד הנתונים ידרוש יותר מקום לאחסון, וזה ישפיע על הגיבויים. גישה לכמויות גדולות של נתונים בינאריים במסד נתונים יכולה גם להשפיע על הביצועים. בנוסף, מבני נתונים רלוונטיים מצריכים כמה תנאים על מבני הנתונים, מה שעשוי להקשות על אחסון נתונים מורכבים כמו קבצי CSV, תמונות וקבצי JSON כמטא-נתונים של מודלים.
- אחסון אובייקטים: אחסון אובייקטים קיים כבר זמן רב, אך הועצמה כשאמזון הפכה אותו לשירות ה-AWS הראשון בשנת 2006 עם שירות האחסון הפשוט (S3). אחסון אובייקטים מודרני הוא טבעי לענן, ובמהרה גילמו גם ענפי הענן האחרים את ההצעות שלהם לשוק. מיקרוסופט מציעה אחסון Blob של Azure, וגוגל מציעה שירות אחסון Google Cloud. ממשק S3 הוא הסטנדרט למעשי קייטים לאינטראקציה עם אחסון בענן, ויש מספר חברות המציעות אחסון תואם ל-S3 לענן הציבורי, ענן פרטי ופתרונות פרטיים על-ידי. לא משנה איפה נמצא מאגר האובייקטים, הוא נגיש באמצעות ממשק RESTful. בעוד שאחסון אובייקטים מבטל את הצורך במדריכים, תיקיות וארגון היררכי מורכב אחר, זה אינו מוצע טוב לנתונים דינמיים שמשתנים כל הזמן מאחר שיהיה עליך לכתוב מחדש את האובייקט כדי לשנות אותו, אך זהו בחירה טובה לאחסון מודלים מאוחסנים ותכונות המודל.
A summary of the main benefits of object storage are:
- התרחבות עצומה: גודל אחסון אובייקטים הוא בעצם בלתי מוגבל, כך שניתן להגדיל את הנתונים לאקסבייטים על ידי הוספת מכשירים חדשים. פתרונות אחסון אובייקטים מבצעים גם הכי טוב כשהם פועלים כשרשת מרוחקת.
- פשטות מופחתת: הנתונים מאוחסנים במבנה שטוח. היעדר עצים מורכבים או חלונות (בלי תיקיות או מדריכים) מקטין את מורכבות השליפה של קבצים כפי שאינך צריך להכיר את המיקום המדויק.
- חיפושיות: מטמון הוא חלק מאוביקטים, מה שהופך את החיפוש והניווט לקלים מבלי צורך ביישום נפרד. אפשר לתייג אוביקטים עם תכונות ומידע, כגון צריכה, עלות ומדיניות למחיקה אוטומטית, שמירה ושידור. עקב המרחב הכתובתי השטוח של האחסון הבסיסי (כל אוביקט בסך אחד ולא בוקט בתוך בוקט), מאגרי אוביקטים יכולים למצוא אוביקט בין אולי מיליארדי אוביקטים במהירות.
- גמישות: אחסון אוביקטים יכול לשכפל אוטומטית נתונים ולאחסן אותם במכשירים ובמיקומים גאוגרפיים רבים. זה יכול לעזור להגן מול הפסקות, להגן מול אבדון נתונים ולעזור לתמוך באסטרטגיות הגנה מהפסקה.
- פשטות: השימוש ב-REST API לאחסון ושליפת מודלים מעיד על שיעור למידה כמעט שאינו קיים והופך את השילובים לתוך ארכיטקטורות מבוססות מיקרוסרביס ברורות.
הגיע הזמן להסתכל על היישום של מודל VAR כשירות והשילוב עם MinIO. פרויקט הפצה של הפתרון המוצג מפושט על ידי שימוש ב-Docker ו-Docker Compose. הארגון של כל הפרויקט נראה כך:

כמו במאמר הראשון, ההכנה של המודל מורכבת מכמה שלבים המוצגים בתכנית פייתון הנקראת var_model.py הממוקמת במאגר מיוחד ב-GitHub :
- טעינת נתונים
- חלוקת הנתונים לקבוצת אימון ובדיקה
- הכנת משתנים תוצאה
- מציאת פרמטר המודל האופטימלי p (העיכובים הראשונים p של כל משתנה משמשים כמיוארים רגרסיה)
- הפעלת המודל עם הפרמטרים האופטימליים שזוהו
- אריזת המודל המופעל לקובץ פיקל
- שמירת הקובץ הפיקלי כאובייקט מעובר בפחית MinIO
שלבים אלה יכולים גם להיות מיושמים כמשימות במנוע זירת תהליך (למשל, Apache Airflow) שנפעיל על מנת לאמן גרסה חדשה של המודל עם נתונים מואחרים יותר. DAGs והיישומים שלהם ב-MLOps יהיו הנושא של מאמר אחר.
השלב האחרון המיושם ב-var_model.py הוא שמירת המודל המוצקל כקובץ פיקל בפחית ב-S3. עקב המבנה השטוח של אחסון האובייקטים, הפורמט שנבחר הוא:
<שם הפחית>/<שם הקובץ>
אך לגבי שמות הקבצים, מותר להשתמש בחתירה קדימה כדי לחקות מבנה היררכי, בעודם שמירה על יתרון החיפוש הליניארי המהיר. האמנה לאחסון מודלים VAR היא כדלקמן:
models/var/0_0_1/model.pkl
כאשר שם הדלי הוא models, ושם הקובץ הוא var/0_0_1/model.pkl ובממשק המשתמש של MinIO, זה נראה כך:

זו דרך נוחה מאוד למבנה מודלים וגרסאות מודל שונות בעודם עדיין נותרים בביצועים ובפשטות של אחסון קבצים שטוחים.
שים לב שאחסון גרסאות המודל מיושם כחלק משם המודל. MinIO מספק גם אחסון גרסאות של קבצים, אך הגישה שנבחרה כאן עשויה להביא לכמה יתרונות:
- תמיכה בגרסאות צילום לשמיים ושינויים
- שימוש באחסון גרסאות סמנטי (נקודות הוחלפו בג׳ינג׳י בגלל הגבלות)
- שליטה רבה יותר באמצעי אחסון גרסאות
- הפרדה של מנגנון האחסון הבסיסי במונחים של תכונות אחסון גרסאות מסוימות
ברגע שהמודל מופעל, הגיע הזמן לחשוף אותו כשירות REST באמצעות Flask ולפרוס אותו באמצעות docker-compose הפועל MinIO ושרת אינטרנט אפ״ח. התמונת Docker, כמו גם קוד המודל, ניתן למצוא במאגר מיוחדב-GitHub.
ולבסוף, השלבים הדרושים להפעלת היישום הם:
- לפרוס את היישום:
docker-compose up -d - לבצע אלגוריתם הכנת המודל:
python var_model.py(דרוש שרידת שירות MinIO) - לבדוק אם המודל פועל: http://127.0.0.1:9101/browser
- לבדוק את המודל:
http://127.0.0.1:80/apidocs
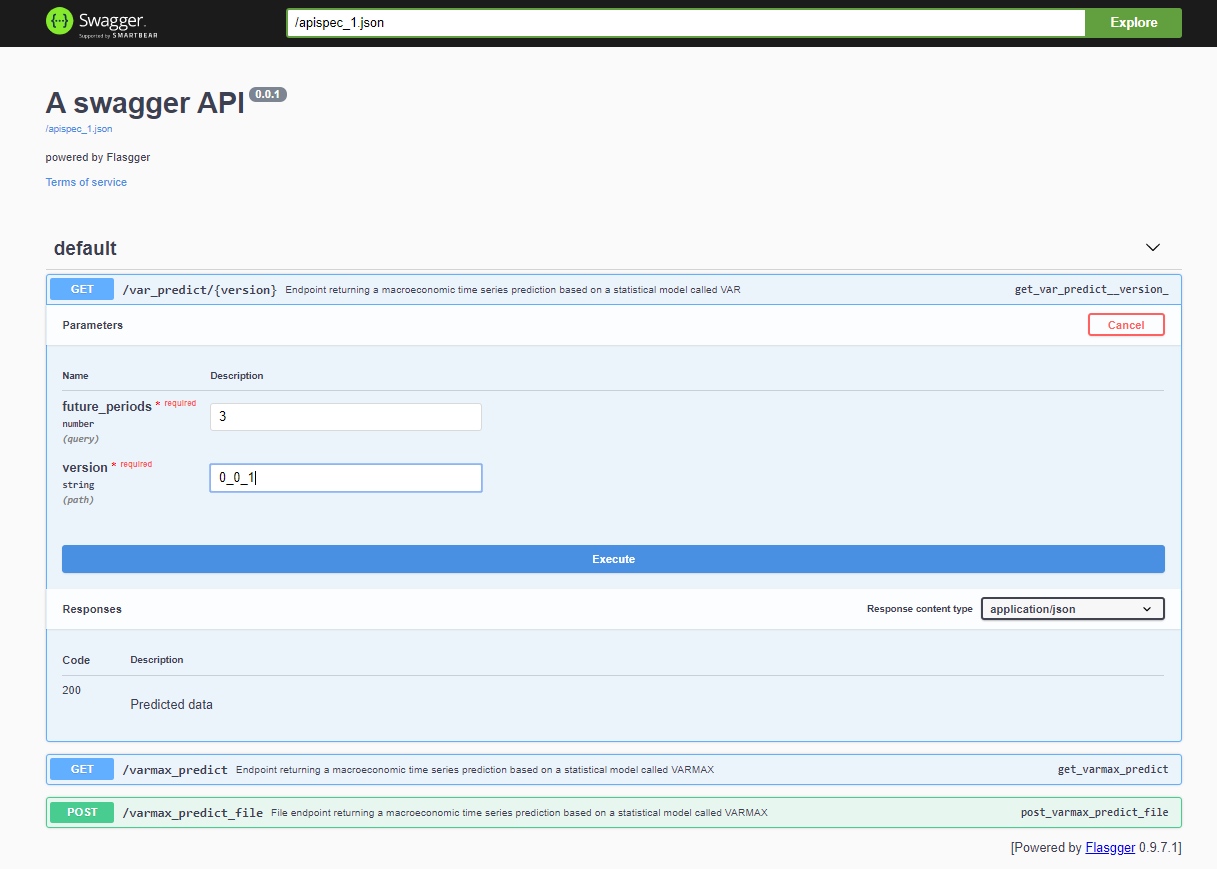
לאחר פריסת הפרויקט, ניתן לגשת ל-Swagger API דרך <host>:<port>/apidocs (למשל, 127.0.0.1:80/apidocs). קיים נקודת קצה אחת למודל VAR שמוצג אחריה שניים נוספים המציגים מודל VARMAX:
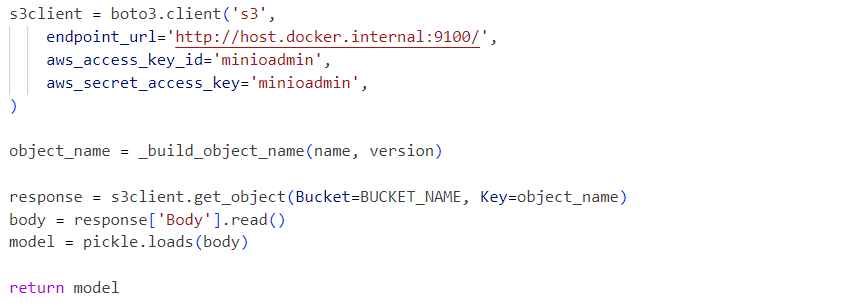
בפנים, השירות משתמש בקובץ הפיקל של המודל המפושט משירות MinIO:
בקשות נשלחות למודל המאותחל כך:

הפרויקט המוצג הוא זרם עבודה מודל VAR מופשט שניתן להרחיב צעד אחר צעד עם תכונות נוספות כמו:
- לחקור פורמטים סימולציה סטנדרטיים ולהחליף את הפיקל בפתרון חלופי
- לשלב כלים חישובי זמן סדרתי כמו Kibana או Apache Superset
- לאחסן נתוני זמן סדרתי במסד נתונים זמן סדרתי כמו Prometheus, TimescaleDB, InfluxDB, או אחסון אובייקט כגון S3
- להרחיב את הזרם עם צעדים טעינת נתונים ועיבוד נתונים
- לשלב דוחות מדדים כחלק מהזרמים
- ליישם זרמים באמצעות כלים ספציפיים כמו Apache Airflow או AWS Step Functions או כלים סטנדרטיים יותר כמו Gitlab או GitHub
- השוואת ביצועים ודיוק של מודלים סטטיסטיים עם מודלים של למידת מכונה
- יישום פתרונות מושלמים של ענן מושלם, כולל תשתית כשירות
- חשוף מודלים סטטיסטיים ו-ML נוספים כשירותים
- יישום API שמאחסן מודלים המסתיר את מנגנון האחסון האמיתי ואת גרסאות המודל, מאחסן מטא-נתונים של המודל ונתוני האימון
השיפורים העתידיים אלו יהיו המיקוד של מאמרים ופרויקטים קרובים. המטרה של מאמר זה היא לשלב API של אחסון מתאים ל-S3 ולאפשר את האחסון של מודלים בגרסאות. תכונה זו תועבר לספרייה נפרדת בקרוב. הפתרון המוצק המוצג יכול להתקיים בפרודוקטים ולהשתפר כחלק מתהליך CI/CD לאורך זמן, כמו גם באמצעות אפשרויות פרוסות של MinIO או בהחלפתו ב-AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service