













שירות האחסון הפשוט של אמזון (S3) הוא שירות של אחסון עצמים ברוב עידן, חסין ואבטחה שמציעה שירותי אמזון האינטרנט (AWS). S3 מאפשר לעסקים לאחסן ולהשיב כמות כזו של נתונים מכל מקום ברחבי הרשת על ידי שימוש בשירותים ברמת הארגון. S3 מיועד להיות משולב בצורה גבוהה ומשתלב באופן חלק עם שירותי אמטנגים אחרים וכלי וטכנולוגיות של זולת כדי לעבד נתונים שנשמרים באמזון S3. אחד מהם הוא שירות אמזון EMR (Elastic MapReduce) המאפשר לך לעבד כמויות גדולות של נתונים באמצעות כלים פתוחים כמו Spark.
Apache Spark הוא מערכת חיבור פתוחה מבוססת על הפצה לעיבוד נתונים גדולים. Spark מבוסס לאפשר מהירות ותומך במקורות נתונים שונים, כולל אמזון S3. Spark מספק דרך יעילה לעיבוד כמויות גדולות של נתונים ולבצע חישובים מורכבים בזמן מינימלי.
Memphis.dev היא אלטרנטיבה דורית למנהלי הודעות מסורתיים. מנהל הודעות קלון, חסין וחסין על הענן שמכוסה במערכת שלמה שמאפשרת פיתוח מהיר, אפקטיבי ואמין של מקרים של שימוש בתיקיות מודרניות.
הדפוס הנפוץ של מנהלי הודעות הוא למחוק הודעות לאחר שהן עוברות את מדיניות השאריות המוגדרת, כמו זמן/גודל/מספר הודעות. ממפיס מציע רמה שנייה של אחסון לשמירה ארוכה יותר, אולי אינסופית, להודעות שנשמרו. כל הודעה שנפלטת מהתחנה תעבור אוטומטית לרמת האחסון השנייה, שבמקרה זה היא AWS S3.
בדרכי ההדרכה הללו, תקבל הדרכה במהלך תהליך הקמת תחנת ממפיס עם מחלקת אחסון שנייה המחוברת ל-AWS S3. סביבה ב-AWS. לאחר מכן יוצרים באק אובקט, מקמים קבוצת EMR, מתקינים ומכוונים את אפפרה הפר קלאסטר, מכינים נתונים ב-S3 לעיבוד, מעבדים נתונים עם אפפרה הפר, עיצובים טובים, ועיבוד ביצועים.
הקמת הסביבה
ממפיס
- כדי להתחיל, קודם כל להתקין ממפיס.
- לאפשר אינטגרציה של AWS S3 דרך מרכז האינטגרציה של ממפיס
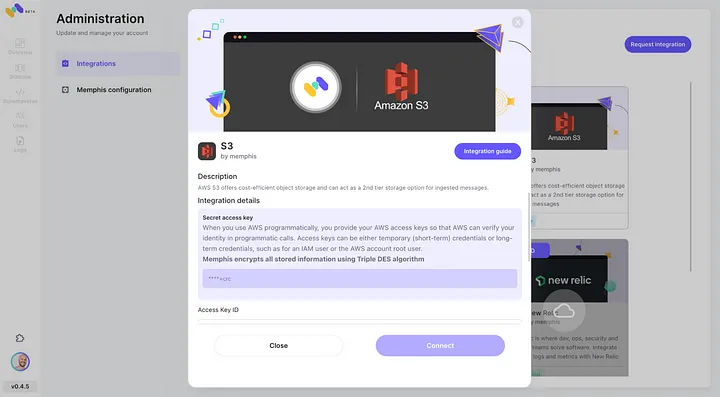
3. צור תחנה (נושא), ובחר מדיניות שימור.
4. כל הודעה שעוברת את המדיניות השמורה המוגדרת תיעבר לבאקט S3.
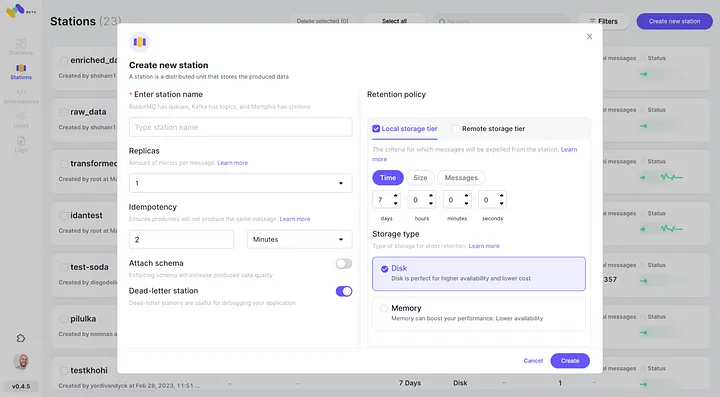
5. בדוק את האינטגרציה המתוקננת החדשה של AWS S3 כמחלקת אחסון שנייה על ידי לחיצה על "התחבר".
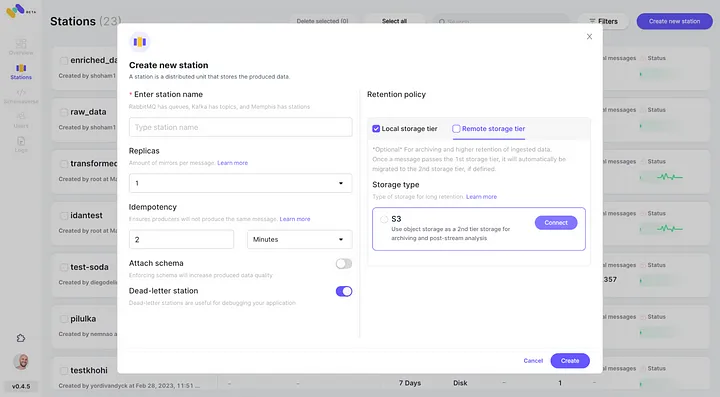
6. התחל לייצר אירועים עבור התחנה הממפיס החדשה שלך.
צור באקט S3 של AWS
אם עוד לא עשית זאת, קודם כל, אתה צריך ליצור חשבון AWS חשבון. לאחר מכן, צור באגף S3 שבו תוכל לאחסן את הנתונים שלך. תוכל להשתמש בתוכנית הניהול של AWS, ב-AWS CLI או ב-SDK כדי ליצור באגף. למדריך זה, תשתמש בתוכנית הניהול של AWS תוכנית הניהול.
לחץ על "צור באגף".
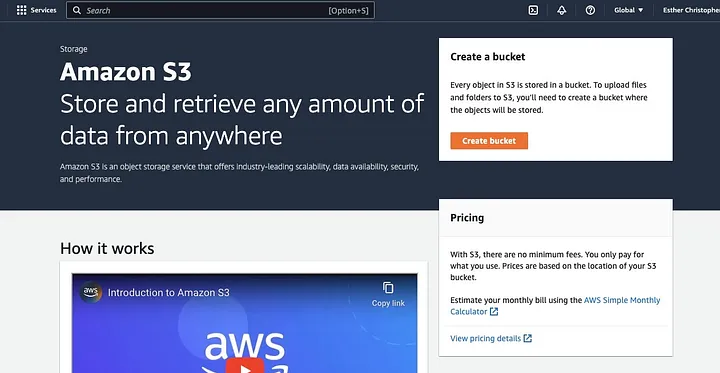
לאחר מכן תקדים ליצירת שם באגף המקיים את המוסכמה הקריאה ובחר באזור שבו אתה רוצה שהבאגף יהיה ממוקם. תכוון את "נכסי האובייקט" ואת "חסימת גישה ציבורית כוללת" למקרה השימושי שלך.
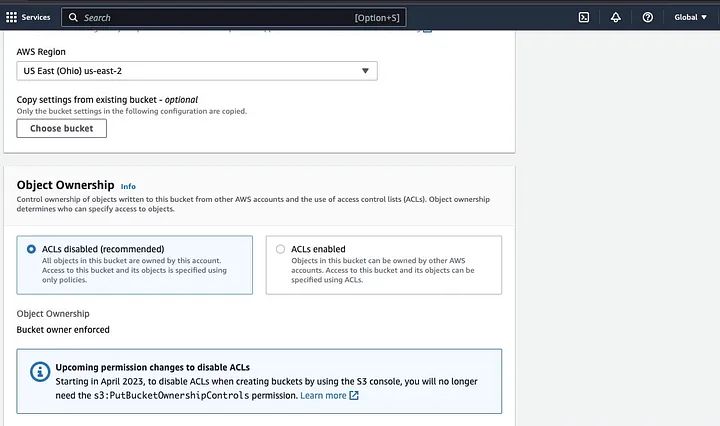
הקפיד להגדיר גם את ההרשאות האחרות של הבאגף כדי לאפשר ליישום הספרק שלך לגשת לנתונים. לבסוף, לחץ על כפתור "צור באגף" כדי ליצור את הבאגף.
הקמת צב של EMR עם Spark מותקן
Amazon Elastic MapReduce (EMR) הוא שירות אינטרנט המבוסס על Apache Hadoop המאפשר למשתמשים לעבד באופן יעיל מחירים של כמויות עצומות של נתונים באמצעות טכנולוגיות ענק נתונים, כולל Apache Spark. כדי ליצור צב EMR עם Spark מותקן, פתח את תוכנית EMR ובחר "צבים" תחת "EMR ב-EC2" בצד שמאל של הדף.
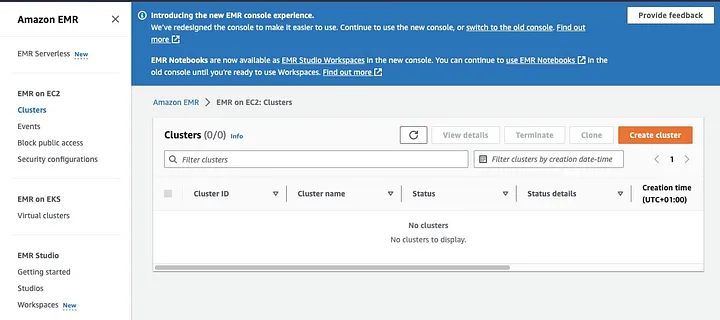
לחץ על "צור צב" ותן לצב שם מדויק. תחת "חבילת יישומים", בחר את Spark כדי להתקין אותו בצב שלך.
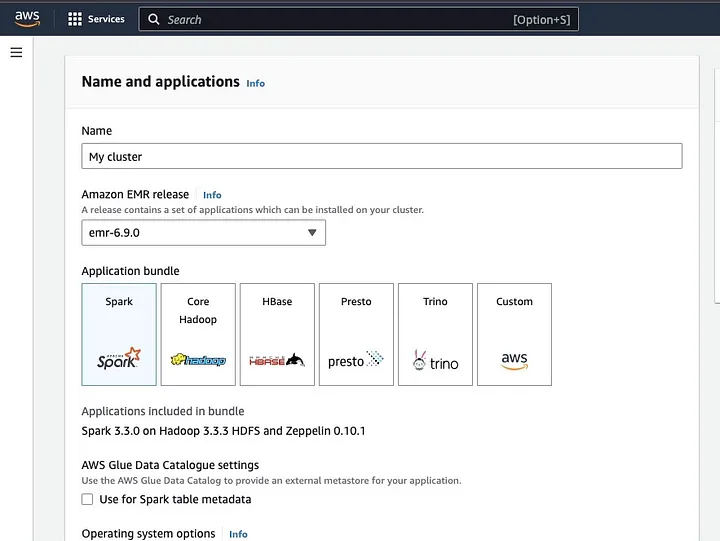
הפניה לסעיף "יומני קבוצה" ובחירה בסמל הסימון לפרסום יומנים ספציפיים ל-Amazon S3.
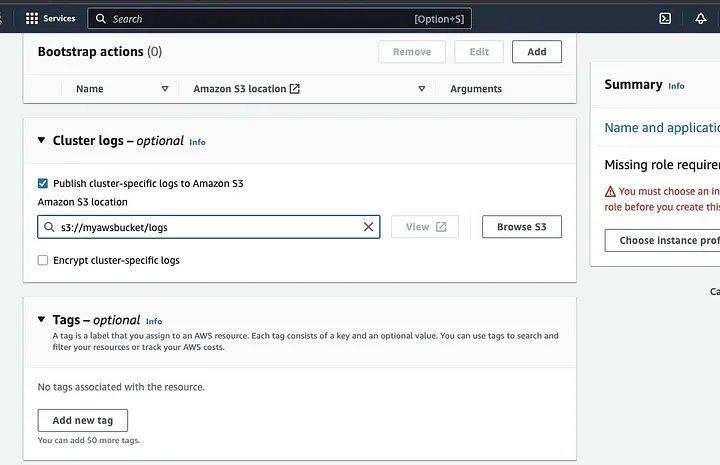
זה ייצור הזמנה להזנת מיקום של Amazon S3 באמצעות שם מפלס S3 שיצרת בשלב הקודם, ולאחר מכן /logs, לדוגמה, s3://myawsbucket/logs. /logs הם הכרחיים עבור Amazon ליצור תיקייה חדשה במפלס שלך שבו Amazon EMR יכול להעתיק את קבצי היומן של הקבוצה שלך.
עבור אל סעיף "התקנת אבטחה והרשאות" והזן את זיכרון EC2 שלך או המשך עם האפשרות ליצור אחד.
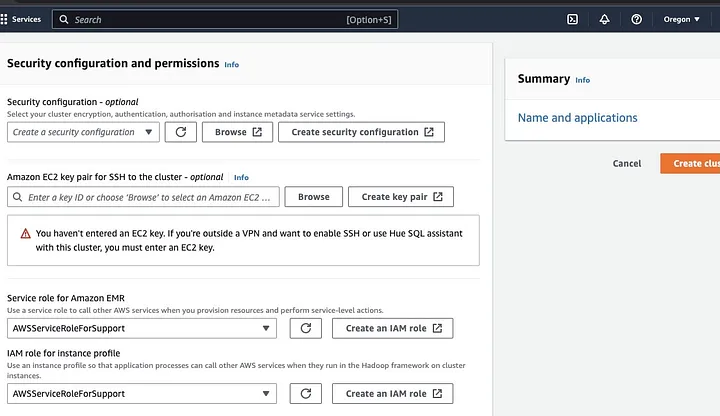
לאחר מכן לחץ על אפשרויות המפל עבור "תפקיד שירות עבור Amazon EMR" ובחר AWSServiceRoleForSupport. בחר את אותה אפשרות מפל עבור "תפקיד IAM עבור פרופיל מצביע". רענן את הסמל עם צורך לקבל את אפשרויות המפל.
לבסוף, לחץ על כפתור "יצירת קבוצה" כדי להשיק את הקבוצה ולנטר את מצב הקבוצה כדי לאמת שהיא נוצרה.
התקנה והכיוון של Apache Spark על קבוצת EMR
לאחר יצירת קבוצת EMR בהצלחה, השלב הבא יהיה להכיוון את Apache Spark על קבוצת EMR. קבוצות EMR מספקות סביבה מנוהלת להפעלת יישומי Spark על מבנה AWS, מה שהופך את זה קל להשיק ולנהל קבוצות Spark בענן. הם מכיוונים את Spark לעבוד עם הנתונים והצרכים שלך ולאחר מכן שולחים משימות Spark לקבוצה לעיבוד הנתונים שלך.
אפשר להגדיר אפשריות של Apache Spark לקבוצת השירות באמצעות פרוטוקול Secure Shell (SSH). אבל קודם כל, עליך לאשר קשרים בטחוניים של SSH לקבוצת השירות, שהוגדרו כברירת מחדל כשיצרת את קבוצת EMR. מדריך כיצד לאשר קשרי SSH נמצא כאן.
כדי ליצור קשר SSH, עליך לציין את זוג המפתחות EC2 שבחרת כשיצרת את הקבוצה. לאחר מכן התחבר לקבוצת EMR באמצעות שלל ה-Spark על ידי התחברות לצומת הראשי. עליך קודם כל להשיג את ה-DNS הציבורי של הצומת הראשי על ידי גלישה לשמאל התוכנית הניידת של AWS, תחת EMR על EC2, בחר קבוצות, ולאחר מכן בחר את קבוצת ה-DNS הציבורי שברצונך להשיג.
במסוף המערכת של המערכת הפלטפורמה שלך, הזכיר את הפקודה הבאה.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemהחלף את ec2-###-##-##-###.compute-1.amazonaws.com בשם ה-DNS הציבורי של הראשי שלך ואת ~/mykeypair.pem בשם הקובץ ובשם הנתיב של הקובץ .pem שלך (עקוב אחר מדריך זה כדי להשיג את הקובץ .pem ). הודעת פתיחה תופיע לשאלה שבה תשובך צריכה להיות כן – הקלד יציאה כדי לסגור את הפקודת SSH.
הכנת נתונים לעיבוד עם Spark והעלאתם למזרן S3
עיבוד נתונים דורש הכנה לפני העלאה לייצוג הנתונים בפורמט שספארק יכול לעבד בקלות. הפורמט שמשתמשים בו מושפע מסוג הנתונים שיש לך ומהניתוח שאתה מתכנן לבצע. כמה פורמטים שמשתמשים בהם כוללים CSV, JSON ו-Parquet.
צור דר ספארק חדש וטען את הנתונים שלך לספארק באמצעות ה-API הרלוונטי. למשל, השתמש בשיטה spark.read.csv() כדי לקרוא קבצי CSV לטבלת ספארק.
Amazon EMR, שירות מנוהל לרשתות הילב עמית, יכול לשמש לעיבוד נתונים. זה מקטין את הצורך להקים, לכוון ולשמור על רשתות. זה גם מציע אינטגרציות אחרות עם Amazon SageMaker, לדוגמה, להתחיל עבודת מידע של SageMaker מזרן ספארק ב-Amazon EMR.
ברגע שהנתונים שלך מוכנים, באמצעות השיטה DataFrame.write.format("s3"), אפשר לקרוא קובץ CSV ממגילת Amazon S3 לטבלת ספארק. אתה צריך להגדיר את הרשאות של AWS שלך ויש לך רשאות כתיבה לגשת למגילה S3.
ציין את מגילת S3 והנתיב שבו אתה רוצה לשמור את הנתונים. לדוגמה, אפשר להשתמש בשיטה df.write.format("s3").save("s3://my-bucket/path/to/data") כדי לשמור את הנתונים למגילה המסוימת של S3.
ברגע שהנתונים נשמרים במגילת S3, אפשר לגשת להם מיישומים ספארק אחרים או כלים, או שאפשר להוריד אותם לניתוח או עיבוד נוסף. כדי להעלות את המגילה, צור תיקייה ובחר את המגילה שבנית בהתחלה. בחר בכפתור "פעולות" ולחץ על "צור תיקייה" בפריטי הנפתח. עכשיו אפשר לקרוא לתיקייה החדשה.
להעלות את קבצי הנתונים לבאגן, בחר את שמת התיקייה של הנתונים.
בעלילת העלאת הקבצים – בחר "אוצר הקבצים" ובחר "הוסף קבצים".
המשך עם ההדרכה בתיבת הודעות של Amazon S3 להעלאת הקבצים ובחר "התחל העלאה".
חשוב לשקול ולהבטיח את הנצילות הטובה ביותר לאבטחת הנתונים שלך לפני העלאת הנתונים לבאגן S3.
הבנת פורמטי נתונים ושכבות
פורמטי נתונים ושכבות הם שני מושגים קשורים אך שונים לחלוטין וחשובים בניהול נתונים. פורמט הנתונים מתייחס לארגון ולמבנה הנתונים במסד הנתונים. ישנם פורמטים רבים לאחסון נתונים, כמו CSV, JSON, XML, YAML וכד'. פורמטים אלו מגדירים איך נתונים צריכים להיות מובנים ביחד עם סוגים שונים של נתונים ויישומים החלופיים לזה. במקביל, שכבות הנתונים הן המבנה של המסד הנתונים עצמו. הם מגדירים את הפריסה של המסד הנתונים ומוודאים שהנתונים מאוחסנים באופן תקין. שכבת מסד הנתונים מגדירה תצוגות, טבלאות, אינדקסים, סוגים ואלמנטים אחרים. המושגים האלה חשובים באנליטיקה ובהצגת המסד הנתונים.
ניקוי ומתיחות נתונים ב-S3
חשוב לבדוק מראש שוב לגבי שגיאות בנתונים שלך לפני עיבודם. כדי להתחיל, גש
היכנס לאתמילון אתינה של אמזון בתיבת המחשב של AWS.
לחץ על "יצירה" כדי ליצור טבלה חדשה ולאחר מכן "יצירת טבלה".
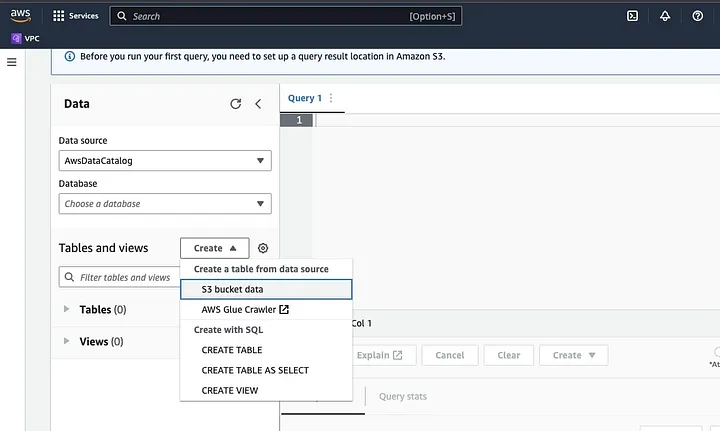
הקלד את מסלול הקובץ של הנתונים שלך בחלק שמודגש כמיקום.
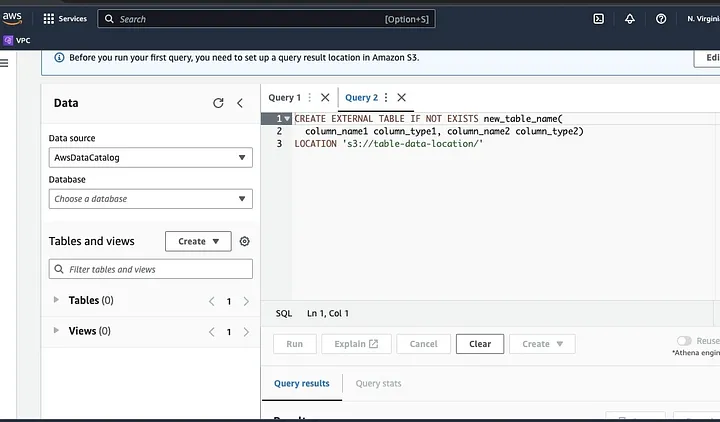
המשיך עם ההדרכות כדי להגדיר את השכבה לנתונים ולשמור את הטבלה. עכשיו, אפשר להריץ שאילתה כדי לאמת שהנתונים עברו באופן תקין ולאחר מכן לנקות ולטפל בנתונים
דוגמה:
שאילתה זו מזהה את השכיחים שקיימים בנתונים.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;דוגמה זו יוצרת טבלה חדשה ללא השכיחים:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;לבסוף, הוצא את הנתונים המנוקבים חזרה ל-S3 על ידי גישה לחציית ה-S3 ולתיקייה להעלאת הקובץ.
הבנת ממסד הנתונים ספרק
ממסד הנתונים ספרק הוא מערכת חישוב צוות פתוחה לכל, פשוטה ומפורטת שנבנתה לפיתוח מהיר. היא מבוססת על שפת התכנות Java ומשמשת כחלופה למסדי נתונים ג'אווה אחרים. התכונה המרכזית של ספרק היא יכולת החישוב בזיכרון שלה שמאיצה את עיבוד מערכי הנתונים הגדולים.
הגדרת ספרק לעבוד עם S3
כדי להגדיר את ספרק לעבוד עם S3, התחל על ידי הוספת הסמכות האדון AWS של האדון ליישום הספרק שלך. עשה זאת על ידי הוספת השורה הבאה לקובץ הבנייה שלך (לדוגמה, build.sbt עבור Scala או pom.xml עבור Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"הזן את מפתח הכניסה של AWS ואת מפתח הכניסה הסודי ביישום הספרק שלך על ידי הגדרת התכונות הבאות:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>הגדר את התכונות הבאות באמצעות אובייקט SparkConf בקוד שלך:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")קבע את כתובת שרת ה-S3 ביישום ה-Spark שלך על ידי הגדרת תכונת ההתקן הבאה:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comהחלף <REGION> באזור ה-AWS שבו נמצא מקלט ה-S3 שלך (למשל, us-east-1).
דרוש שם מקלט תקביל ל-DNS כדי להטיל סמכות על לקוח ה-S3 ב-Hadoop לבקשות S3. אם שם המקלט שלך מכיל נקודות או תחתונים, ייתכן שתצטרך להפעיל גישה בסגנון מדרגת הנתיב עבור לקוח ה-S3 ב-Hadoop, שמשתמש בסגנון מארח וירטואלי. הגדר את תכונת ההתקן הבאה כדי לאפשר גישה בסגנון נתיב:
spark.hadoop.fs.s3a.path.style.access trueלבסוף, צור ברת Spark עם התקן S3 על ידי הגדרת קידומת spark.hadoop בהתקן ה-Spark:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()החלף את השדות של <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY>, ו-<REGION> עם האסימונים והאזור שלך ב-AWS.
כדי לקרוא את הנתונים מ-S3 ב-Spark, ישמש פונקציית spark.read, ולאחר מכן ציין את מסלול S3 לנתונים שלך כמקור הקלט.
דוגמה קוד המדגימה כיצד לקרוא קובץ CSV מ-S3 לתוך מטריצת נתונים ב-Spark:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")בדוגמה זו, החלף <BUCKET_NAME> בשם המקלט שלך ב-S3 ו-<FILE_PATH> במסלול לקובץ ה-CSV שלך בתוך המקלט.
הפיכת נתונים עם Spark
המרת נתונים ב-Spark בדרך כלל מתייחסת לפעולות על נתונים לניקוי, סינון, אסכום וחיבור נתונים. Spark מספק סט עשיר של API להמרת נתונים. כוללים בתוכם את DataFrame, Dataset ו-RDD APIs. חלק מהפעולות הנפוצות של המרת נתונים ב-Spark כוללות סינון, הצגת עמודות, אסכום נתונים, חיבור נתונים ומיון נתונים.
הנה דוגמה אחת לפעולות המרת נתונים:
מיון נתונים: פעולה זו כוללת מיון נתונים על פי עמודה אחת או יותר. ממריצים את השיטה orderBy או sort על DataFrame או Dataset כדי למיון נתונים על פי עמודה אחת או יותר. לדוגמה:
val sortedData = df.orderBy(col("age").desc)לבסוף, ייתכן שתצטרך לכתוב את התוצאה חזרה ל-S3 כדי לאחסן את התוצאות.
Spark מספק מספר API לכתיבת נתונים ל-S3, כגון DataFrameWriter, DatasetWriter ו-RDD.saveAsTextFile.
הבאה היא דוגמת קוד המדגימה איך לכתוב DataFrame ל-S3 בפורמט Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)החלף את השדה הקלט של <BUCKET_NAME> בשם החסימה שלך ב-S3 ו-<OUTPUT_DIRECTORY> בשם המדריך הפלט בחסימה.
השיטה mode מגדירה את מצב הכתיבה, שיכול להיות Overwrite, Append, Ignore, או ErrorIfExists. השיטה option יכולה לשמש כדי לציין אפשרויות רבות לפורמט הפלט, כגון קוד הדחיסה.
אפשר גם לכתוב נתונים ל-S3 בפורמטים אחרים, כגון CSV, JSON ו-Avro, על ידי שינוי הפורמט הפלט וציון האפשרויות המתאימות.
הבנת חלוקת נתונים ב-Spark
במונחים פשוטים, חלוקת נתונים ב-Spark מתייחסת לחלוקת המ Dataset מספר קטן יותר, ויותר ניתן לניהול ברחבי המסוף. המטרה של זה היא לייעל את הביצועים, להפחית את ההיבטים של יעילות ולבסוף לשפר את ניהול המסד נתונים. ב-Spark, הנתונים מעובדים במקביל על מספר מסופים. זה מתבצע באמצעות מערכי נתונים חוזרים ומופצים (RDD), שהם אוסף של נתונים גדולים ומורכבים. כברירת מחדל, RDD מחולקים ברחבי צמדים שונים בגלל גודלם.
כדי לבצע באופן אופטימלי, ישנן דרכים להגדיר את Spark כדי לוודא שהמשימות מבוצעות בזמן, והמשאבים מנוהלים ביעילות. חלק מאלה כוללים שימור, ניהול זיכרון, סריאליזציה נתונים, ושימוש ב-mapPartitions() על map().
Spark UI היא ממשק משתמש גרפי מבוסס אינטרנט המספק מידע מקיף על ביצועים ושימוש במשאבים של יישום Spark. זה כולל מספר דפים, כגון סקירה, מופעים, שלבים ומשימות, המספקים מידע על מספר היבטים של משימת Spark. Spark UI היא כלי חיוני לניטור ולפתרון בעיות של יישומי Spark, שכן זה עוזר לזהות צרכים בביצועים ומגבלות משאבים ולפתור שגיאות. על ידי בחינת מדדים כמו מספר המשימות שהושלמו, משך המשימה, שימוש ב-CPU ובזיכרון, ונתוני הסחרור נכתבים ונקראים, המשתמשים יכולים לייעל את המשימות שלהם ב-Spark ולוודא שהם פועלים ביעילות.
סיכום
בסיכום, עיבוד הנתונים שלך ב-AWS S3 באמצעות Apache Spark מהווה דרך יעילה וניתנת להתרחבות לניתוח מערכי נתונים גדולים. בשימוש במאגרי האחסון והמשאבים הממוחשבים בענן של AWS S3 ו-Apache Spark, המשתמשים יכולים לעבד את הנתונים במהירות וביעילות מבלי לדאוג לניהול הארכיטקטורה.
במדריך זה, עברנו על הקמת באגף S3 וקבוצת שרת Apache Spark ב-AWS EMR, הגדרת Spark לעבוד עם AWS S3, וכתיבת והרצת יישומי Spark לעיבוד נתונים. כמו כן, כיסינו את החלוקה של הנתונים ב-Spark, ממשק המשתמש של Spark, וביצועים מושלמים ב-Spark.
התייחסות
לקישור רחב יותר להגדרת spark לביצועים אופטימליים, נסה כאן.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark