













לימוד מקורס המקצוע שלנו יכול להיות לך מה שצריך כדי להשיג את המידע הנכון ולהבין את הדברים המעניינים באינטרנט.
אנחנו משתמשים בטכנולוגיות מתקדמות כדי לספק לך את השירותים הטובים ביותר.
נאמר, שאתם מקבלים את כל המידע שלכם מקורסים שלנו בצורה די מהירה ובאופן מוצלח.
אז אם אתם רוצים ללמוד על סוגים מסויימים של נושאים, אתם יכולים לעבוד עליהם בעזרת המחשבות המקוריות שלנו.
אנחנו מספקים לכם מידע מאוד מוצק ומשנה על מנת שתוכלו להיות מוכרחים להשתמש במידע הזה בדרך הנכונה.
- פרק 1. הבאת למוד
– 1.1 מה הוא RAG? סקירה בסיסית
– 1.2 איך RAG פותר בעיות מורכבות - פרק 2. יסודות טכניים
– 2.1 העברת ממערכות למידע מוחיות ל-RAG
– 2.2 הבנה של הזיכרון של RAG: פרמטרי נגד לא-פרמטרי
– 2.3 RAG רב-סוגי: שילוב סוגים רבים של מידע - פרק 3. המנגנונים היסודיים
– 3.1 הכח של הצטרפות של איסוף מידע ויצירה ב-RAG
– 3.2 אסטרטגיות השלמה לאיסוף מידע ויצירה - פרק 4. יישומים ומקרים שימוש
– 4.1 RAG בעבודה: משאלות תשובות עד כתיבה יצירתית
– 4.2 RAG עבור שפות עם משאבים נמוכים: הרחבת היכולת וההגיעה - פרק 5. טכניקות אופטימיזציה
– 5.1 טכניקות השלמת מידע מתקדמות לשיפור מערכות RAG - פרק 6. אתגרים וחדשנות
– 6.1 האתגרים הנוכחיים והכיוונים העתידיים ל-RAG
– 6.2 האצה בחומרה והיישום היעיל של מערכות RAG - פרק 7. מחשבות סופניות
– 7.1 העתיד של RAG: סיכומים ומחשבות
דרישות מונחתות
עבור התעניינות בתוכן המתמקד במודלים גדולים של שפה (LLM) כמו Retrieval-Augmented Generation (RAG), ישנם שני דרישות מונחתות חיוניות:
- בסיסי מחשוב מלאכותי: הבנה של תפיסות ואלגוריתמים בסיסיים של למידת מכונה היא חשובה, במיוחד כשזה מתאים למבנה נוירולי.
- עיבוד שפה טבעית (NLP): ידע בטכניקות של NLP, כולל עיבוד קדם טקסט, טוקיניזציה, ושימוש בהבנים, הוא חיוני לעבודה עם מודלים שפתיים.
פרק 1: הקדם לRAG
המהפך RAG משנה את עיבוד השפה הטבעית על-ידי שילוב בין מידע מחיאה חיצונית ומודלים גנרטיביים. מערכות RAG מגישות באופן דינמי למידע חיצוני, שמעבד את הדורשנות והתעדכנות של הטקסט המיוצר.
בפרק זה אנחנו מושפעים מהמנגנונים של RAG, היתרונות והאתגרים שלהם. אנחנו מתחילים בטכניקות המידע החיצוני, השלמתם עם מודלים הגנרציה וההשפעה על היישומים השונים.
RAG מתקל בהזיות, מוסיף מידע עדכני, ומתייחס לבעיות מורכבות. אנחנו גם דון באתגרים כמו מידע חיצוני יעיל ודיוקיות מוסרית. פרק זה מספק תובנה מקיפה על הפוטנציאל המעברת של RAG בעיבוד השפה הטבעית.
1.1 מהו RAG? הסקירה בקצרה
Retrieval-Augmented Generation (RAG) מייצג שינוי פעולה בעיבוד השפה הטבעית, שילוב בין החוזקות של מידע מחיאה חיצונית ומודלים גנרציים. מערכות RAG משתמשות במקורות חיצוניים כדי לעזור לשיפור הדורשנות, הדחוף וההתאמה של הטקסט המיוצר, מתייחסים למגבלות של הזיכרון הפרמטי הסטנדרטי במודלים השפתיים המסורתיים. (Lewis et al., 2020
על ידי שימוש בדיוקים דינמיים במידע רלוונטי בתהליך היצירה, ראג מאפשרת יצירות מורכבות יותר ומאומצות עובדה יותר ברמה המשמעותית בתרגום ישיר וכמותם רחב של יישומים, ממערכות תשובות שאלות ומערכות דיאלוג עד סימולציה וכתיבה יצירתית. (Petroni ואחרים, 2021)
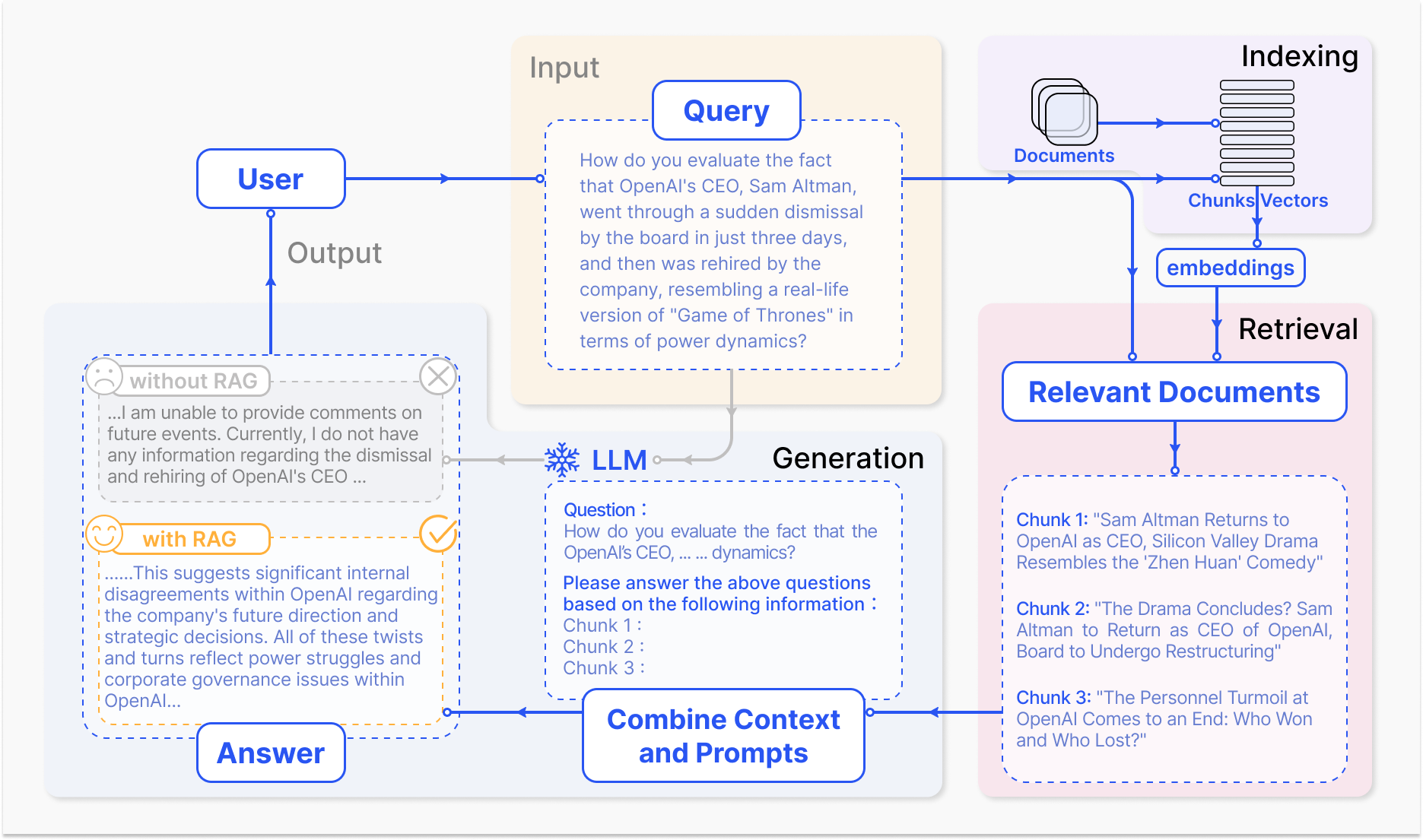
איך מערכת RAG פועלת – arxiv.org
המנגנון היסוד של RAG מרכיב שתי רכיבים עיקריים: ההגיעה והיצירה.
הרכיב הראשון מחפש ביעילות במאגרי ידע נרחבים על מנת לזהות את המידע הכי מתאים לשאלה הקדמית או ההקשר. טכניקות כמו הגיעה מאדירה, שמשתמשת במפת הפעילות הפוכה ובהתאמה מושגים, והגיעה דינמית, שמשתמשת בהיקרבים הדינמיים ובדמיון הסימטרי, מועברים כדי לאופן את תהליך ההגיעה. (Karpukhin ואחרים, 2020)
אחר כך, המידע הנאסף משולב למודל היצירה, בד "" כ מודל מדעני השפה גדול כמו GPT או T5, שמתחברת את התוכן המתאים ליצירה מבנה בררן וזורם. (Izacard & Grave, 2021)
השילוב של שליפה ויצירה ב-RAG מציע מספר יתרונות על פני מודלים לשוניים מסורתיים. בכך שהוא מבסס את הטקסט שנוצר על ידע חיצוני, RAG מפחית באופן משמעותי את התרחשות ההזיות או התוצרים הלא מדויקים מבחינה עובדתית. (Shuster et al., 2021)
RAG גם מאפשר לשלב מידע עדכני, מה שמבטיח שהתשובות שנוצרו משקפות את הידע וההתפתחויות האחרונות בתחום נתון. (Lewis et al., 2020) גמישות זו היא קריטית במיוחד בתחומים כמו בריאות, פיננסים ומחקר מדעי, שבהם הדיוק והעיתוי של המידע הם בעלי חשיבות עליונה. (Petroni et al., 2021)
אך הפיתוח והפריסה של מערכות RAG מציבות גם אתגרים משמעותיים. שליפה יעילה ממאגרי ידע רחבי היקף, מניעת הזיות ואינטגרציה של סוגי נתונים מגוונים הם בין האתגרים הטכניים שצריכים להיפתר. (Izacard & Grave, 2021)
גם השערים האתיים, כמו הבטחת חיפוש וייצור מידע שלא מטוגן והוגן, הם חשובים בשימוש אחראי של מערכות RAG. (Bender וקואליציה אחרים, 2021) פיתוח מדדים ומסגרות הערכה מקיפים שלוקחים בחשבון את המשחק בין הדיוק בחיפוש לאיכות הייצור הם חיוניים לעריכת היעילות של מערכות RAG. (Lewis וקואליציה אחרים, 2020)
עכשיו, כשהתחום של RAG ממשיך להתפתח, הכיוונים העתידיים של המחקר מתמקדים בשיפור תהליכי החיפוש, הרחבת יכולות המולטימודליות, פיתוח מבנים מודולריים והקמת מסגרות הערכה חזקות. (Izacard & Grave, 2021) ההתקדמויות הללו יעשו את המערכות RAG יותר יעילות, מדויקות וסתגלניות, ויאפשרו את הדרך ליישומים יותר חכמים וגמישים בעיבוד שפה טבעית.
הנה דוגמה בפייתון בסיסית שמדגים הקמת תכנית RAG (Retrieval Augmented Generation) באמצעות הספריות הפופולריות LangChain ו-FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. לודא ומטען מסמכים
loader = TextLoader('your_documents.txt') # חלופה עם מקור המסמך שלך
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. למידה של מסמכים רלוונטיים
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. הגדרת שרשרת RAG
llm = OpenAI(temperature=0.1) # הגדרת טמפרטורת התגובה עבור יצירתיות
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. שימוש במודל RAG
def get_answer(query):
return chain.run(query)
# שימוש מדורף
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#דוגמה לשימוש ב-RAG: היסטוריית החברה
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#דוגמה לשימוש ב-RAG: ביצועים פיננסיים
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#דוגמה לשימוש ב-RAG: דעת עתיד
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
על ידי הנטלת הכוח של לימוד והוצאה, RAG מציע בעלי מבט עצום על איך אנחנו מתנהלים במגע עם מידע וביצירתו, ממרחב את תחומים רבים ומעצבים את העתיד של האינטראקציה בין בני אדם ומכונות.
1.2 איך RAG פותר בעיות מורכבות
Retrieval-Augmented Generation (RAG) מציעה פתרון חזק לבעיות מורכבות שלמדים גדולים אוטומטיים בשפה (LLMs) נתקעים בהן, במיוחד בסיטואציות בהן יש כמות עצומה של מידע לא מבנים.
אחת הבעיות היא ההיכולת להתעסק בשיחות משמעותיות על מסמכים ספציפיים או תוכן מדיה רב-מידע, כמו סרטונים בYouTube, ללא הערכת פינימלית קדם או הכשרה מוכנה על החומר המטרי.
גרסאות מסורתיות של LLMs, למרות היכולות הייצוריות המרשימות שלהן, מוגבלות על ידי הזיכרון הפרמטרי שלהן, שמקובע בזמן האימון. (לואיס ועוד, 2020) זה אומר שהן לא יכולות לגשת או לשלב מידע חדש מעבר למידע האימון שלהן, מה שהופך את השיחה המודעת על מסמכים או וידאו חדשים לאתגר.
לכן, גרסאות LLMs עשויות לייצר תגובות שאינן עקביות, לא רלוונטיות או שגויות מעשית כאשר מופעלות עם שאלות קשורות לתוכן ספציפי. (פטרוני ועוד, 2021)
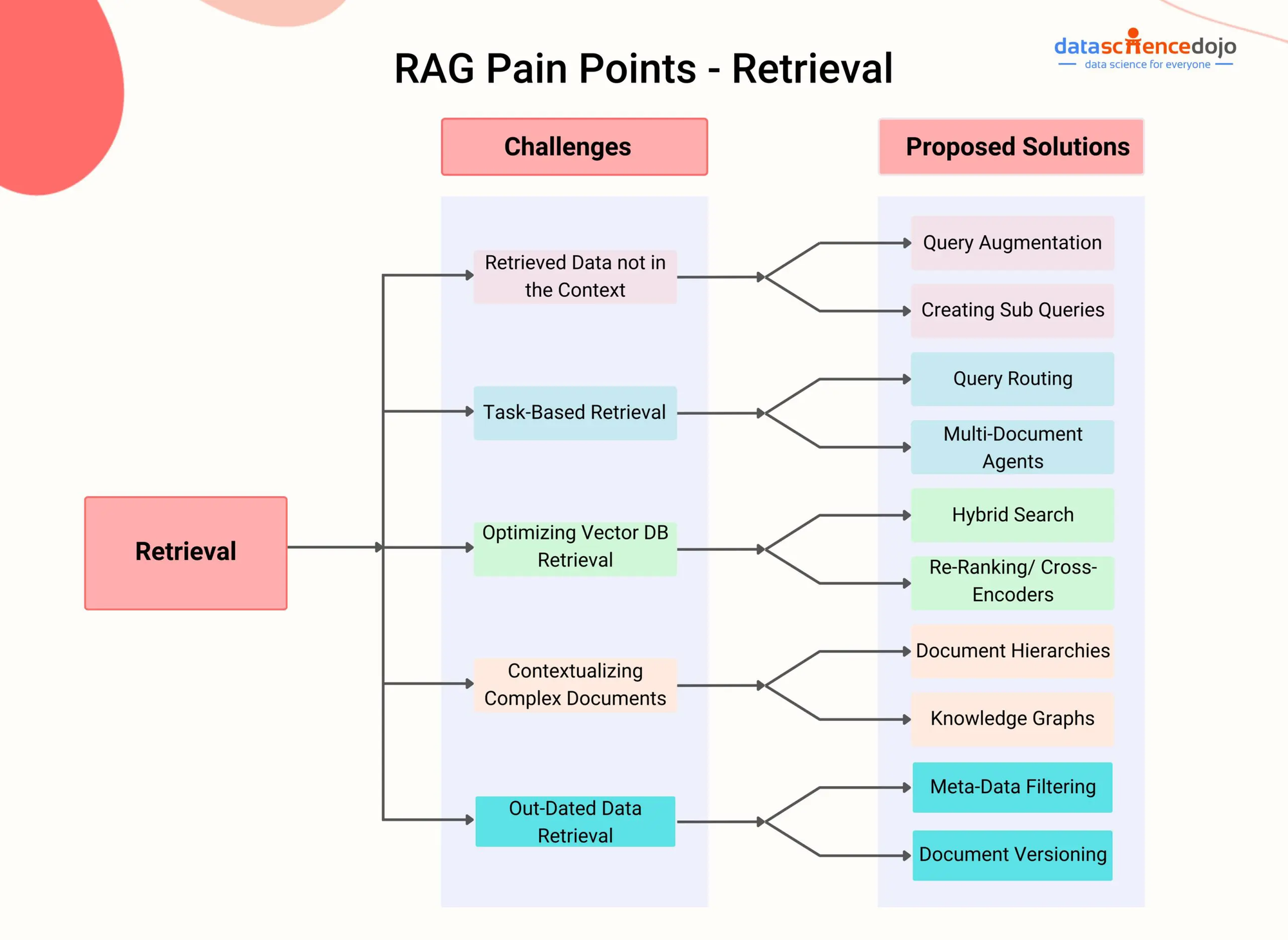
נקודות הכאב של RAG – DataScienceDojo
RAG מתגברת על המגבלה הזו על ידי שילוב רכיב של השלמה שמאפשר למודל לגשת דינאמית ולשלב מידע רלוונטי ממקורות ידע חיצוניים במהלך תהליך הייצור.
על ידי שימוש בטכניקות השלמה מתקדמות, כמו השלמת קטעים צפופים (קארפוכין ועוד, 2020) או חיפוש היברידי (איזקארד & אגרב, 2021), מערכות RAG יכולות לזהות בצורה יעילה את הקטעים או החלקים הכי רלוונטיים ממסמך או וידאו מסוים לפי ההקשר השיחתי.
לדוגמה, שקול תרחיש שבו משתמש רוצה להשתתף בשיחה על סרטון יוטיוב בנושא מדעי מסוים. מערכת RAG יכולה קודם כל לתמלל את תוכן האודיו של הסרטון ולאחר מכן לאנדקס את הטקסט המתקבל באמצעות ייצוגי וקטור צפופים.
לאחר מכן, כאשר המשתמש שואל שאלה הקשורה לסרטון, רכיב האחזור של מערכת RAG יכול לזהות במהירות את הקטעים הרלוונטיים ביותר מהתמלול בהתבסס על הדמיון הסמנטי בין השאילתה לבין התוכן המאנדקס.
הקטעים המאוחזרים מוזנים לאחר מכן למודל הגנרטיבי, המסנתז תגובה קוהרנטית ומידעית שמתייחסת ישירות לשאלת המשתמש תוך שהיא מבססת את התשובה בתוכן הסרטון. (Shuster et al., 2021)
גישה זו מאפשרת למערכות RAG להשתתף בשיחות בעלות ידע על מגוון רחב של מסמכים ותכני מולטימדיה ללא צורך בכיוונון עדין מפורש. על ידי אחזור דינמי ושילוב מידע רלוונטי, RAG יכולה לייצר תגובות מדויקות יותר, רלוונטיות מבחינה קונטקסטואלית ועקביות עובדתית בהשוואה ל-LLMs מסורתיים. (Lewis et al., 2020)
hebrew
גם היכולת של RAG להתמודד עם מידע לא מאורגן מגוון של רכיבים, כמו טקסט, תמונות ואודיו, מעשה אותו לפתרון גמיש לבעיות מורכבות הכוללות מקורות מידע שונים. (Izacard & Grave, 2021) ככל שמערכות RAG ממשיכות להתפתח, היכולת שלהן להתמודד עם בעיות מורכבות בתחומים מגוונים גדלה.
על ידי שימוש בטכניקות מחקר מתקדמות ואינטגרציה מולטימודלית, RAG יכול לאפשר סוכני שיחה יותר חכמים ומודעים להקשר, מערכות המלצה אישיות ויישומים עם נפח ידע.
כשהמחקר מתקדם בתחומים כמו ייצוג יעיל, התאמה בין רכיבים ואינטגרציה בין מחקר ליצירה, RAG ישמש בביטחון בתור משובש בגבולות מה שאפשרי עם מודלי שפה ובינה מלאכותית.
פרק 2: היסודות הטכניים
פרק זה נכנס לעולם המרתק של Multimodal Retrieval-Augmented Generation (RAG), גישה חדשנית שמעברת את המגבלות של מודלים בסיסיים מבוססי טקסט.
על ידי שילוב חלקלק דיאטה כמו תמונות, אודיו וווידאו עם מודלי שפה גדולים (LLM), Multimodal RAG מעצימה את מערכות הבינה המלאכותית להשיבה על פני מנתחים מידעיים גדולים יותר.
נחקור את המנגנונים מאחורי האינטגרציה הזו, כמו למידה מוגדרת ותשומת לב קרוס מולדלית, ואיך הן מאפשרות ל-LLM לייצר תגובות יותר מפורשות ורלוונטי
אף על פי שמולטימודל ראג מציע יתרונות מעוניינים כמו השיפור בדיוק והיכולת לספק תחום שימוש חדשני כמו תשובות לשאלות חזותיות, הוא גם מביא באתגרים ייחודיים. האתגרים האלה מגיעים לדרישה למידע מרובע מינורמלי בני המידע, למחשבה מערכתית גבוהה יותר, ולאפשרויות עיסקיות בין המידעים.
בזמן שאנחנו מתחילים במסע הזה, אנחנו לא רק יביאים את הפוטנציאל המעברי של מולטימודל ראג אלא גם נבדוק קריטית את המכשולים שעומדים בפנינו, ונסלק את דרכם להבנה יותר עמוקה של תחום המתעורר המהיר באופן מדהים.
2.1 מערכות המוח לראג
התפתחות המערכות המוח תיארה בהתמדה מעבר ממערכות מקובעות-עקרונות וידע למערכות סטטיסטיות ומערכות רשתות על-מנת המוח יותר מוסחים.
בימים הראשונים, מערכות המילים סמכו על חוקים מיוצרים בידי אדם וידע לשפה כדי ליצור טקסט, והם היו קשורים ומגבלים ביצירות. הנולדות של מערכות סטטיסטיות, כמו מודלי n-gram, הביאה לגישה מונעת מידע שלמדה דפוסים מקורבים מקורבים ממאגרים המקורבים הגדולים, אפשר ליצור טקסט יותר טבעי ומבנה. (Redis)
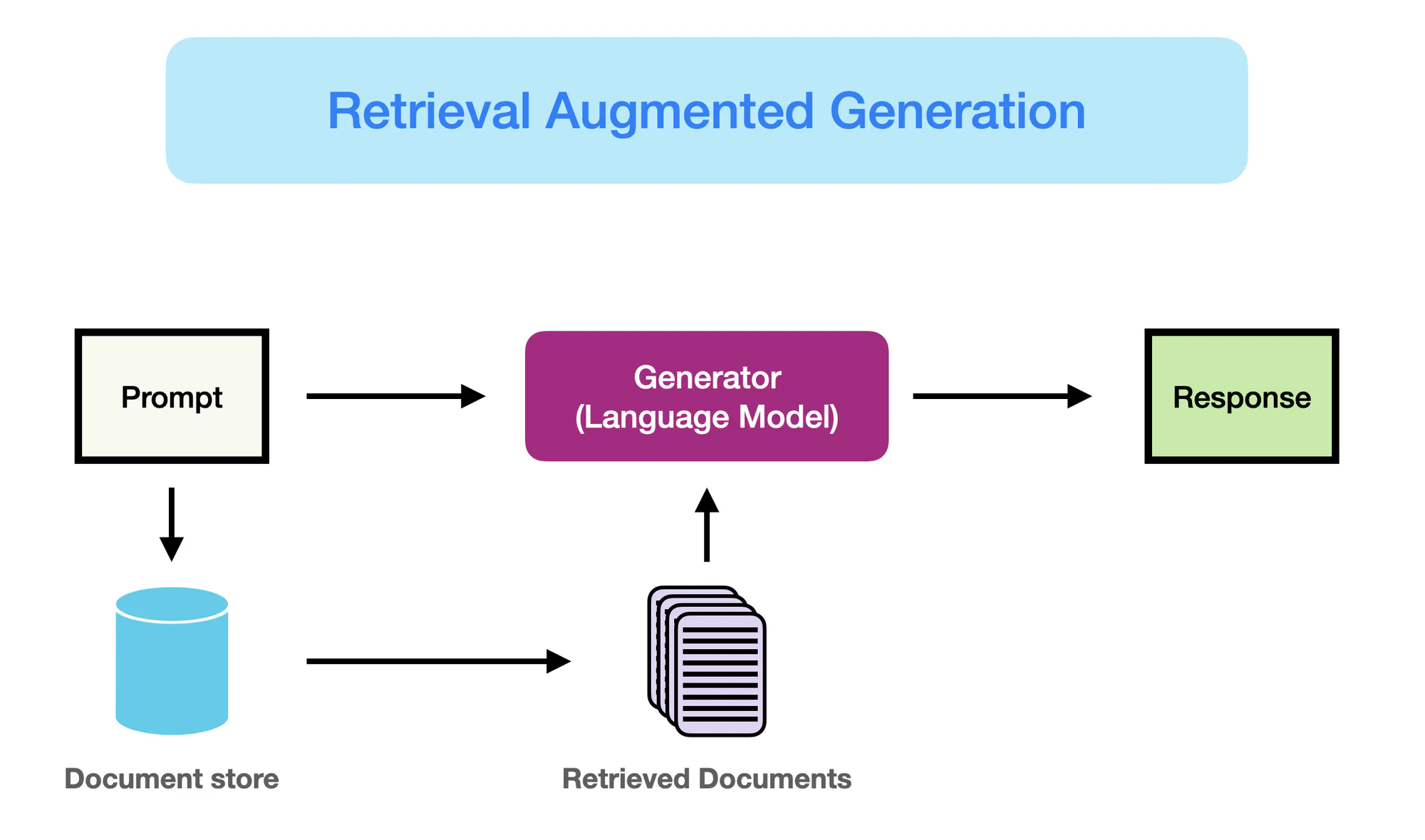
איך ראג פועל – promptingguide.ai
אך ההתחלה של מערכות מולטי-מנהג מבוססות
אלה המודלים האלה, הם ידועים בשם מודלים שפה גדולים (LLMs), משתמשים בכח הלמידה העמוקה כדי לתפוש תבניות שפתיות מורכבות וליצור טקסט דומה לאדם עם ליכוד זעיר והתאמה בפעם הקרובה לפעם. (Yarnit) המודלים הגדולים והמורכבים יותר של LLMs, עם מודלים כמו GPT-3 שמדברים על 175 מיליארד פרמטרים, הובילו ליכולות יוצאות-דופן במשימות כמו תרגום שפה, תשובות לשאלות, ויצירת תוכן.
למרות הביצועים המדהימים שלהם, מודלים LLMs סובלים ממגבלות בגלל תלותם בזיכרון פרמטרי בלבד. (StackOverflow) הידע שמקודד בהם הוא סטטי, מוגבל על ידי תאריך הסגירה של הנתונים המאמצים בהם הם מאמצים.
כתוצאה מכך, LLMs עשויים לייצר תוצאות שהן מוטעות מבחינה עובדה או אינה תואמות עם המידע האחרון. גם, החסרת הגישה הברורה למקורות ידע חייבים מעכבת את היכולתם לספק תשובות מדויקות ומקרינות לשאלות שהן עניינים מאד בידוד ידע.
הפרדיגמה החדשה של RAG (Retrieval Augmented Generation) מופיעה כפתרון לטיפול במגבלות האלה. על-ידי השילוב בעלי היכולת לאסוף מידע עם הכח הגנרטיבי של LLMs, RAG מאפשר למודלים לגיש באופן דינמי ולהשתמש בידע מקורות חיצוניים מושלמים בזמן תהליך יצירת הטקסט.
שילוב הזכרון הפרמטרי והלא פרמטרי מאפשר למודלים LLM חשובים עם RAG לייצר פלוטות שלא רק שפתיים וקוהרנטיים אלא גם מדויקים מבחינה עובדתית ומודעים להקשר.
RAG מייצג קפיצה חשובה בייצור שפה, באמצעות שילוב החוזקות של LLM עם הידע הרחב הנמצא במאגרים חיצוניים. על ידי שימוש בטוב בשני העולמות, RAG מעצים את המודלים לייצר טקסט שהוא יותר אמין, מידעי ומתואם עם הידע העולמי האמיתי.
שינוי הפרדיגמה הזה פותח אפשרויות חדשות עבור יישומי NLP, מעניינים בשאלות ותשובות ויצירת תוכן למשימות עם ידע ניטולי כמו בתחומי בריאות, פיננסים ומחקר מדעי.
2.2 זכרון פרמטרי ולא פרמטרי
זכרון פרמטרי מתייחס לידע שנאחסן בתוך הפרמטרים של מודלי שפה מוכנסים מראש, כמו BERT ו GPT-4. המודלים האלה לומדים ללכוד דפוסים שפתיים ויחסים במהלך התהליך הכישורי, כשהם מקודדים את הידע הזה במיליוני הפרמטרים שלהם.
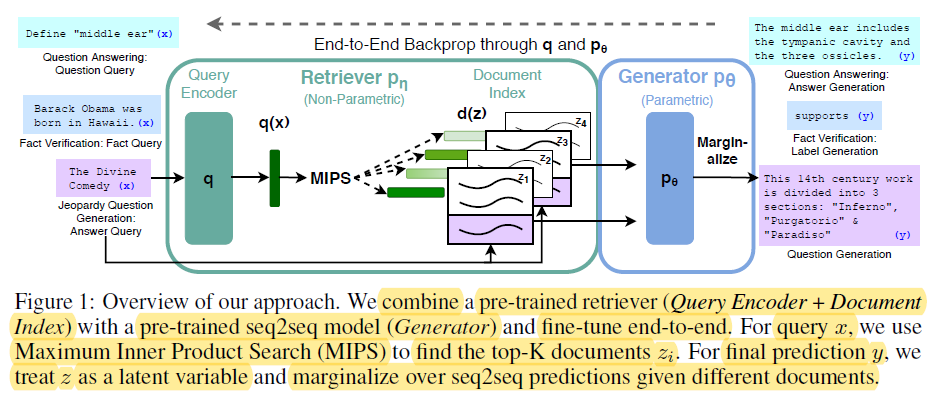
End-t-End Backprop דרך q ו p0 – miro.medium.com
חוזקות הזכרון הפרמטרי הן:
- סידור: מודלים לשפה מאורגנים על-ידי העיבוד מקדם מילים שונות בדיוק ובהתאמה לעוגן השפה הטבעי, שלושך את המידע העדיני ואת הסגנון של השפה הטבעית. (Redis וLewis ואחרים.)
- הכללה: הידע שמחברות בפרמטרים של המודל מאפשר לו להכלל למשימות חדשות ותחומים חדשים, שולחן השימוש בלמידה מעברית ויכולת למידה במצבים מעטים. (Redis וLewis ואחרים.)
אך הזיכרון הפרמטרי גם יש לו מגבלות משמעותיות:
- שגיאות עובדה: מודלים לשפה עשויים לייצר יוצאות שאינן תואמות עם עובדות המציאות, בגלל שהידע שבהם מוכרח מגביל עצמו ביותר מהמידע שהם מאומצים בהכשרה.
- ידע מיושן: הידע שמחברות בפרמטרים של המודל נעשה מיושן במהלך הזמן, כי הוא קבע בזמן ההכשרה ולא מייצג את העדכונים או השינויים במציאות האמיתית.
- עלויות מחשבתיות גבוהות: העברת מודלים גדולים לשפה דורשת מספיק משאבים מחשבתיים ואנרגיה, וזה יקר ומאוד מאמץ לעדכון את הידע שבהם.
- ידע כללי: הידע הנלקח על-ידי מודלים של שפה רחב וכללי, ולא מועבר עמוקות וספציפיות כמו שנדרשת להרבה יישומים ספציפיים.
בניגוד לזה, הזיכרון הלא-פרמטרי מתייחס לשימוש במקורות ידע ברורים, כמו בסיסים מידע, מסמכים וגרפים ידע, כדי לספק למודלים של שפה עם מידע עדכני ומדויק בזמן הפעלה. המקורות החיצוניים מהווים צורה משלמת של זיכרון, שמאפשרת למודלים לגיש ולשלוט במידע רלוונטי בזמן תהליך ייצור.
היתרונות של הזיכרון הלא-פרמטרי הם:
- מידע עדכני: מקורות הידע החיצוניים יכולים להיעדר ולהידרש בקלות, ולוודא שלמודל יש גישה למידע האחרון והמדויק ביותר.
- צמצום הלוחמים: "באמצעות הביאת מידע רלוונטי ממקורות חיצוניים, RAG מייצג בהשפעה משמעותית בצמצום ההלוחמים או היצירות המוצגות כלאמינים." (Lewis et al. ו Guu et al.)
- ידע תחום-מסויים: זיכרון לא-פרמטרי מאפשר למודלים לנצל ידע מיוחד ממקורות תחומיים, ולהפוך את הפלטים ליותר נכונים ורלוונטיים להקשר עבור יישומים ספציפיים. (לואיס ועמיתים וגו ועמיתים)
המגבלות של זיכרון פרמטרי מצביעות על צורך לשינוי הפרדיגמה בייצור שפה.
RAG מייצגת התקדמות משמעותית בעיבוד שפה טבעי על ידי שיפור הביצועים של מודלים יצרניים דרך שילוב טכניקות של מיצפה מידע. (Redis)
הנה קוד בפייתון להדגמה של ההבדל בין זיכרון פרמטרי ללא-פרמטרי בהקשר של RAG, ובנוסף פלט ברור שמצביע על:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# אוסף מסמכים דוגמה (ניתן להניח מסמכים יותר משמעותיים במצב אמיתי)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. זיכרון לא-פרמטרי (מיצפה עם הטמנות)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. זיכרון פרמטרי (מודל שפה עם מיצפה)
llm = OpenAI(temperature=0.1) # התאמת טמפרטורה ליצירתיות התגובה
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- שאילתות ותגובות ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Output:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
והנה מה שקורה בקוד הזה:
זיכרון פרמטרי:
- מנצל את הידע הרחב של ה-LLM כדי ליצור תשובה מקיפה, כולל העובדה המרכזית שהבוזון של היגס נותן מסה לחלקיקים אחרים. ה-LLM "מפרמטר" על ידי הנתונים הרחבים שלו באימון.
זיכרון לא פרמטרי:
- מבצע חיפוש דמיון במרחב הוקטורי, מוצא את המסמך הרלוונטי ביותר שעונה ישירות על השאלה על מיקום ה-LHC. זה אינו מסין מידע חדש, הוא פשוט מחזיר את העובדה הרלוונטית.
הבדלים מרכזיים:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| אחסון ידע | מוצפן בפרמטרים של המודל (משקלים) כייצוגים שנלמדו. | מאוחסן ישירות כטקסט גולמי או בפורמטים אחרים (לדוגמה, embeddings). |
| חיפוש | משתמש ביכולות היוצרות של המודל כדי לייצר טקסט שרלוונטי לשאילתה על סמך הידע שנלמד. | כולל חיפוש אחר מסמכים שדומים לשאילתה (לדוגמה, לפי דמיון או התאמת מילות מפתח). |
| גמישות | גמישות גבוהה ויכול ליצור תגובות חדשות, אך עשוי גם להולצינטר (ליצור מידע שגוי). | פחות גמיש, אך פחות נוטה להולצינציות מאחר שהוא מתבסס על נתונים קיימים. |
| סגנון תגובה | יכול ליצור תגובות מורכבות ומדוררות יותר, אך פוטנציאלית עם יותר מידע לא רלוונטי. | מספק תשובות ישירות וקצרות, אך עשוי להעצים תכנים או הסברים. |
| עלות חישובית | מייצגים יכולים להיות מוניטיניים מאוד, מעבר לדוגמא של עץ הייצוג הסטטי | הם גם יכולים להיות גדולים מאוד, מספקים רבים ומוגבלים |
הם משמשים בהתבסס על הערך הסטטי שלהם, אך לא מסתכלים על האופן בו הערך המוטצי משתנה(מחשבות, אורייל ואחרים, וגו ואחרים)
2.3 רג' רב-מדיה: יחסי טקסט למדע
רג' רב-מדיה מרחיב על הפרדיגמה המקורית של רג' הטקסטי על ידי הכנת מערכת הערך המרכזית הזו של מידע רב-מדיה, כמו תמונות, אודיו ווידאו, כדי להגביר את יכולות האספון והייצוג של מודלים השפה הגדולים (מודלים לשפה גדולים, LLMs).
על ידי שימוש בשיטות לימוד הניגודיות, מערכות רג' רב-מדיה לומדות להדביק את המידע המגוון הזה למרחב הויקובי המשותף, מאפשר את האספון המרכזי המרובד. זה מאפשר לLLMs להגיונים על ההקשר היותר עשיר, על ידי שילוב מידע טקסטי עם סימנים ויזואלים ואודיוגליים כדי לייצר תוצאות יותר מורכבות ומתאימות יותר להקשר. (שן ואחרים)
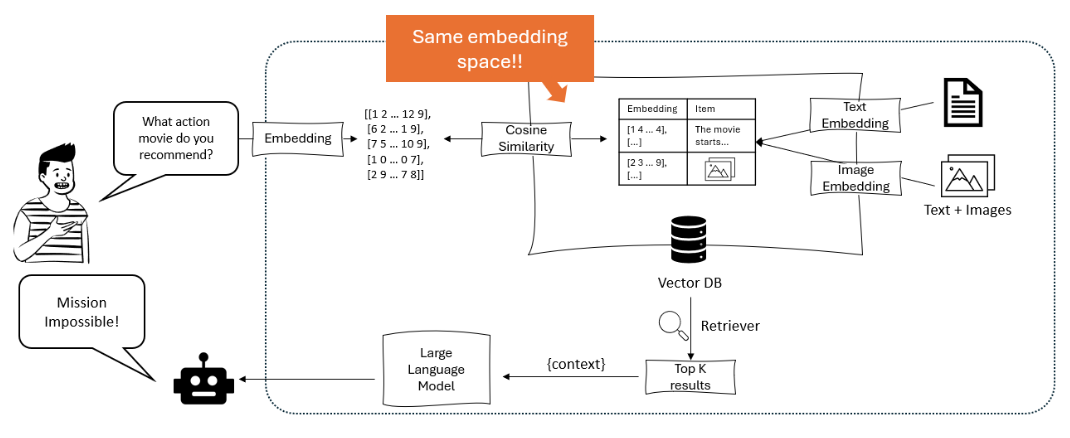
התרשים ממחיש מערכת המומלצים בה מעבד דגם שפה גדול את שאילתת המשתמש ל- embeddings, שמתאות באמצעות דמיון קוסינוס בתוך מסד נתונים וקטורי המכיל embeddings טקסט ותמונה, כדי לאחזר ולהמליץ על הפריטים הרלוונטיים ביותר. – opendatascience.com
גישת מפתח אחת ב- multimodal RAG היא השימוש בדגמים על מנתרים המבוססים על transformer כמו ViLBERT ו- LXMERT המשתמשים במנגנוני תשומת לב cross-modal. דגמים אלה יכולים להתייחס לאזורים רלוונטיים בתמונות או קטעים ספציפיים בשמע/וידאו בזמן יצירת טקסט, תופסים אינטראקציות ספציפיות בין מודליות. דבר זה מאפשר תגובות עם יסוד רב-פרטיות והקשר. (Protecto.ai)
שילוב של טקסט עם אופציות אחרות בצינורות העבודה של RAG מעורב באתגרים כגון התאמת ייצוגים סמנטיים בין סוגי נתונים שונים וטיפול במאפיינים הייחודיים של כל מודליות במהלך תהליך ה- embedding. טכניקות כמו encoding ספציפי למודליות ותשומת לב צלב משמשות לטיפול באתגרים אלו. (Zhu et al.)
אך היתרונות הפוטנציאליים של multimodal RAG הם משמעותיים, כולל דיוק משופר, ניתנות לשליטה ואפשרות לפרשנות של תוכן שנוצר, כמו גם אפשרות לתמוך במקרי שימוש חדשים כגון תשובות על שאלות חזותיות ויצירת תוכן multimodal.
לדוגמה, Li ושות' (2020) הציעו מסגרת RAG מרבי-מודלית עבור תשובה חזותית לשאלה שמחזירה תמונות רלוונטיות ומידע טקסטואלי כדי ליצור תשובות מדויקות, מתקדמת על גבי גישות המצב האמיתי הקודמות בבתי-מבחן כמו VQA v2.0 ו־CLEVR. (MyScale)
למרות התוצאות המבטיחות, RAG מרבי-מודלית מביא גם קשיים חדשים, כגון רכיבות חישוביות מורחבות, הצורך במערכות נתונים מרבי-מודליות בגדלים גדולים, והפוטנציאל לעיוות ורעש במידע שמוחזר.
חוקרים מחקרים פעילים טכניקות להפחתת מספר הבעיות הללו, כגון מבני אינדקסציה יעילים, אסטרטגיות הרחבת נתונים, ושיטות אימון נגדיות. (Sohoni ושות')
פרק 3: מנגנונים יסודיים של RAG
פרק זה חוקר את הקשר המורכב בין מחזירים ומודלים יוצרים במערכות Retrieval-Augmented Generation (RAG), מדגיש את תפקידיהם הקריטיים באינדקסציה, החיפוש, והסינתוזה של מידע כדי ליצור תגובות מדויקות ורלוונטיות הקשורות להקשר.
אנו חוקרים את פרטי הטכניקות של חיפוש צפוי וצפוי-צפוי, משווים את נקודות הכוח והחולשה שלהם בסצנריואם שונים. בנוסף, אנו בודקים אסטרטגיות שונות לשילוב מידע שמוחזר במודלים יוצרים, כגון חיבור ותשומת לב צלבית, ונדון בהשפעתן על היעילות הכוללית של מערכות RAG.
שעל ידי הבנת שיטות האינטגרציה הללו, תקבלו תובנות רבות ערכות לגבי איך להופך מערכות RAG לאופטימליות עבור משימות ותחומים ספציפיים, זה יסלול את הדרך לשימוש מודע ויעיל יותר בפרדיגמה החזקה הזו.
3.1 הכוח של שילוב השליפה והיצירה של מידע ב RAG
RAG (Retrieval-Augmented Generation) מייצג פרדיגמה חזקה שמשלבת באופן בלתי נראה את שיטת השליפה של מידע עם מודלי שפה יצירתיים. RAG מורכב משני מרכיבים עיקריים, כמו שניתן להבין מהשם שלו: שליפה ויצירה.
המרכיב השליפה אחראי לאינדקסינג וחיפוש בתוך מאגר ידע עצום, בעוד המרכיב היצירה מנצל את המידע שנשלף כדי להפיק תשובות רלוונטיות הקשרית ועם עקרונות מדעיים נכונים. (Redis ו-Lewis וקולגות)
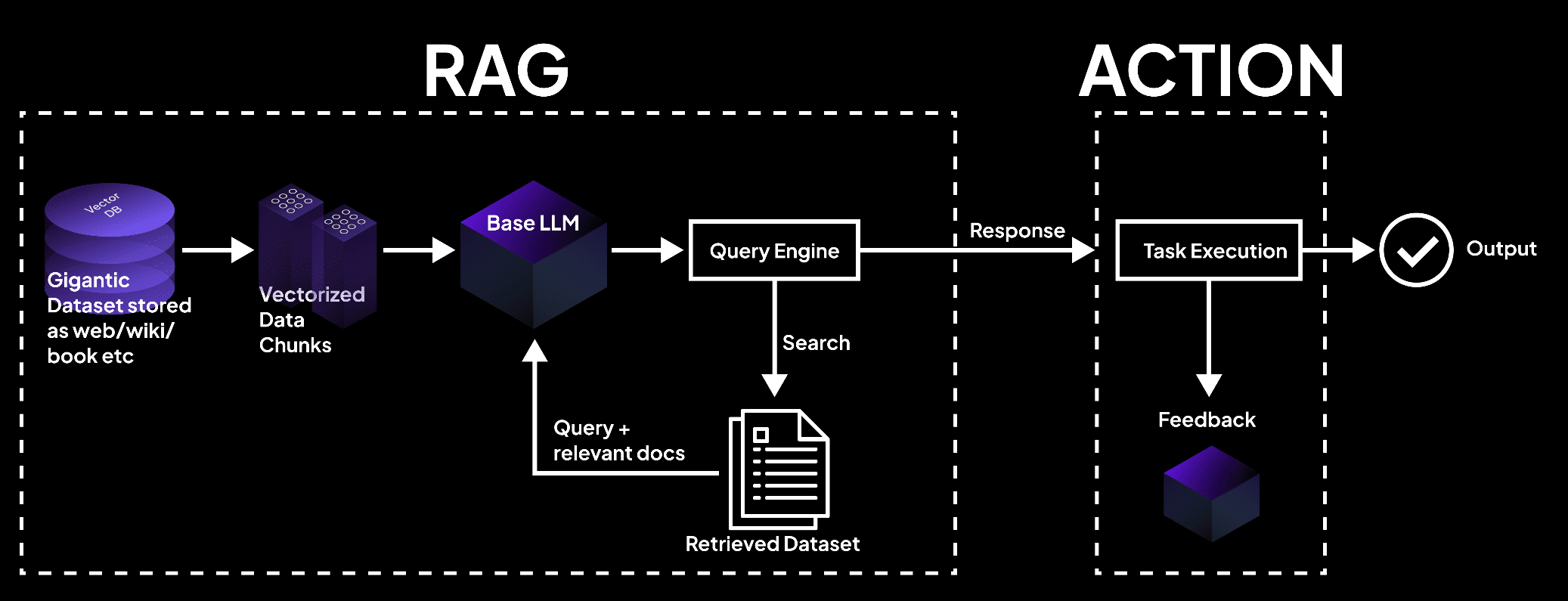
התמונה מראה מערכת RAG בה מאגר וקטורי דיאטה מעבדת מידע לחתיכות, שנשאל על ידי מודל שפה כדי לשלוף מסמכים לביצוע משימות ופלטים מדויקים. – superagi.com
פעילות השליפה מתחילה עם האינדקסציה של מקורות ידע חיצוניים, כמו מסדי נתונים, מסמכים ודפי אינטרנט. (Redis ו-Lewis ועמיתים). סוגי השליפה והאינדקסציה משמשים תפקיד מרכזי בתהליך הזה, הם מארגנים ומאחסנים בצורה יעילה את המידע בפורמט שמאפשר חיפוש ושליפה מהירים.
כאשר שאלה מוגשת למערכת RAG, המשגר מחפש בבסיס הידע המאובקד לזהות את החלקים הכי רלוונטים לפי הדמיון הליגיסטי וקנייני רלוונטיות אחרים.
לאחר שהמידע הרלוונטי נשלף, הרכיב הייצורי לוקח תפקידו. התוכן המשוגר נעשה בשימוש לעצרת ולהדרכת מודל השפה הייצורי, נותן לו את ההקשר הנחוץ והמציאות העובדתית כדי לייצר תשובות מדויקות ומידעיות.
מודל השפה משתמש בטכניקות השערה מתקדמות, כמו מנגנוני תשומת-לב ומבנים טרנספורמריים, כדי לשלב את המידע המשוגר עם הידע הקיים ולייצר טקסט שקורא ושפוי.
תהליך זרימת המידע במערכת RAG ניתן להמחיש כך:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
יתרונות RAG הם רבים:
ההיתוך של יכולות השליפה ויצירה מאפשר יצירת תגובות שלא רק מתאימות להקשר אלא מונעות מהמידע הכי עדכני ודיוקני . (גו ועוד)
לאשר באמצעות מקורות ידע חיצוניים, RAG מורידה באופן משמעותי את תדירות ההזיות או הפלטים המוטעים פיקטואלית, שהם דברים נפוצים במודלים הצריכים בלבד.
בנוסף, RAG מאפשרת שילוב מידע עדכני, וכך להבטיח שהתגובות המיוצרות משקפות את הידע וההתפתחויות העדכניים ביותר בתחום נתון. זה חשוב במיוחד בתחומים כמו הבריאות, הפיננסים ומחקר המדע, בהם הדיוק והזמניות של המידע הם מאוד חשובים. (גו ועוד ו נוידיאה)
RAG מציגה גם יכולת אדפטציה מדהימה, שמאפשרת למודלים לשפה להתמודד עם מגוון רחב של משימות עם ביצועים משופרים. באמצעות שליפה דינמית של מידע התאים לשאלה או ההקשר המסוים, RAG מעצימה את המודלים ליצירת תגובות המותאמות לדרישות הייחודיות של כל משימה, בין אם זה תשובות לשאלות, יצירת תוכן או ביושפעות של מונחות מסוימים.
מחקרים רבים הראו את האפקטיבות של RAG בשיפור הדיוק העובדתי, הרלוונטיות ואדפטציות המודלים הצריכים.
לדוגמה, לואיס ואחרים (2020) הראו ש RAG מצליחה יותר ממודלים גנרטיביים לגמרי במטרות תשובות לשאלות מופיעות בתחום השיעורים, השיגות תוצאות מדגימות המידה במערכות הבניות כמו Natural Questions ו TriviaQA. (Lewis et al.)
בדומה, איזאקארד וגרייב (2021) הוכיחו את העליית האחרונה של RAG על מודלים שפה מסורתיים ביצירת טקסט ארוך בעל התאמה קולקטיבית והתאמה ממשובית.
אם כך, יצירת מידע מחזרה מוסיפה ליצירת שפה מסוג שינויי עיצוב, שמשתמשת בכח המידע החיצוני כדי לשכלל את הדיוק, הרלוונטיות, והסתגלנות של המודלים הגנרטיביים.
דרך השילוב בעלת היכולת המקורית בעזרת ידע חיצוני מוכרף, RAG פתחה אפשרויות חדשות עבור עיבוד השפה הטבעית ופנה את הדרך למערכות יצירת שפה יותר חכמות ואמינות.
3.2 אסטרטגיות השילוב של מחזר ומדפיס
מערכות RAG תלויות בשני רכיבים עיקריים: מחזרים ומודלים גנרטיביים. מחזרים אחראיים לחיפוש ולהוציאה מידע מעבר לבסיסים ידע גדולים.
"היא מרכיבת שתי שלבים, אינדקסינג וחיפוש. אינדקסינג מארגן מסמכים על מנת לסייע לחיפוש באופן יעיל, באמצעות רשימות הפיכות עבור חיפוש דלוק או תעדים מרכזיים מורכבים עבור חיפוש דנס." (Redis
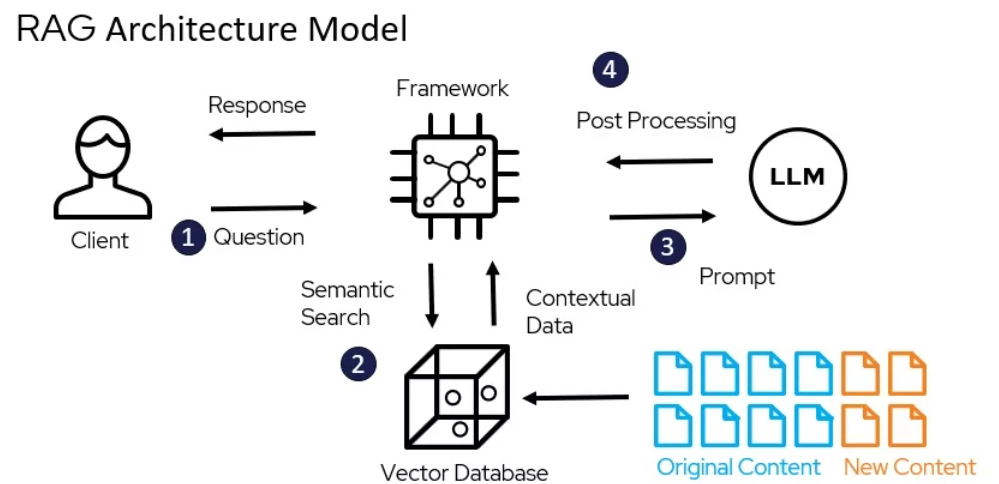
מודל הארכיטקטורה של RAG – miro.medium.com
טכניקות המילוגים הרסיים, כמו TF-IDF ו BM25, מייצגות מסמכים בשבילות מרחבים רסייים גבוהים, בהן כל מימד מתאים למילה ייחודית במילון. הרלוונס של מסמך לשאלה מוגדר על-ידי התערבוב במילים, שמשקע בשמון חשיבות שלהן.
לדוגמה, בעזרת ספריית האלאסטיקס, מנוע חוזר מבוסס על TF-IDF ניתן ליישם באופן אחד:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
טכניקות המילוגים הצפופים, כמו איצוץ מסמכים הצפופים (DPR) ומודלים בעלי BERT, מייצגות מסמכים ושאלות בשבילות צפופות במרחב האימבedding המתמשך. הרלווןס מוגדר על-ידי הדדיות הקוסינית בין הויקטים של השאלה והמסמך.
DPR ניתן ליישם בעזרת ספריית הטרנספורמנטס הפנימיים של Hugging Face:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
מודלים הגנרטיביים, כמו GPT ו T5, משמשים ב-RAG כדי ליצור תשובות מתאימות ומקבילות הקשר על-פי המידע המוצא. מערך את המודלים האלה על נתונים מתחום ספציפי ושימוש בטכניקות העיצוב התעדינים יכולים לשפר בהרבה את הביצועים שלהם במערכות RAG. (קהילת DEV)
אסטרטגיות ההדבקה מחליטות איך התוכן המוצא מובנה למודלים הגנרטיביים.
אימוץ הרכב משתמש בתוכן השוב מחדש כדי ליצור תגובות מתאימות ומקבילות ההקשר עם שלבי העידוד וההנחה. (Redis)
שתי דרכים רבות נפוצות הן ההצמצם והתשומת-מחשבה מעברית.
ההצמצם מעביר את הפרסקאות השובות לשאלה הקדמית, מאפשר למודל הגנרטיבי להתמקד במידע הרלוונטי בתהליך ההתפתחות.
למרות שהגישה הזו קלה ליישם, היא עלולה להתקשות עם מרווחים ארוכים ומידע לא רלוונטי. (קהילת הפיתוח
מנגנונים כמו RAG-Token ו RAG-Sequence מאפשרים למודל הגנרטיבי להתמקד סידרתית על הפרסקאות השובות בכל שלב ההתפתחות.
זה מאפשר שליטה יותר פעילה בתהליך השילוב אך מוביל למערכת מחשבות יותר מורכבת.
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
לדוגמה, RAG-Token יכול להיות מיושב בספריית Hugging Face Transformers:
בחירת המחזר, המודל הגנרטיבי והאסטרטגיית השילוב תלויה בדרישות המערכת RAG, כמו הגודל והמין של המאגר הידע, האיזון הרצון בין יעילות ויעילות, והתחום המטרה של היישום.
הפרק הזה מנסה לחשוב על הפוטנציאל השינויי של הגייסה-מעבדה מורכבת (RAG) בשינוי הייצוג של שפות עם משאבים נמוכים ויישומות רבים-לשפות. אנחנו מתעדים באסטרטגיות כמו תרגום של מסמכים מקוריים לשפות עם משאבים עשירים, שימוש בהערכות רבים-לשפות, ושימוש בלמידה מצטרפת כדי להתגבר על מגבלות הנתונים וההבדלים הלשוניים.
בנוסף, אנחנו מטפלים באתגר הקריטי של התמוטטות במערכות RAG רבים-לשפות כדי להבטיח יצירת תוכן מדויק ואמין. על ידי חקירה בגישות חדשניות אלה, הפרק הזה מעניק מדריך מקיף לטעון את כח הRAG עבור הצלחה והגיוון בעיבוד השפה.
4.1 יישומות RAG: שאלות ותשובות עד כתיבת יצירה מדענית
הגייסה-מעבדה מורכבת (RAG) מוצאה יישומות מעשיים רבים בתחומים שונים, מראה את הפוטנציאל שלו למהפך את הדרך בה אנו מתמודדים עם המידע ועם יצירת מידע. על ידי נצלים את הכח של הגייסה והיצירה, מערכות RAG הוכיחו שיפור משמעותי בדיוק, רלוונטיות ותשומת-לב המשתמשים.
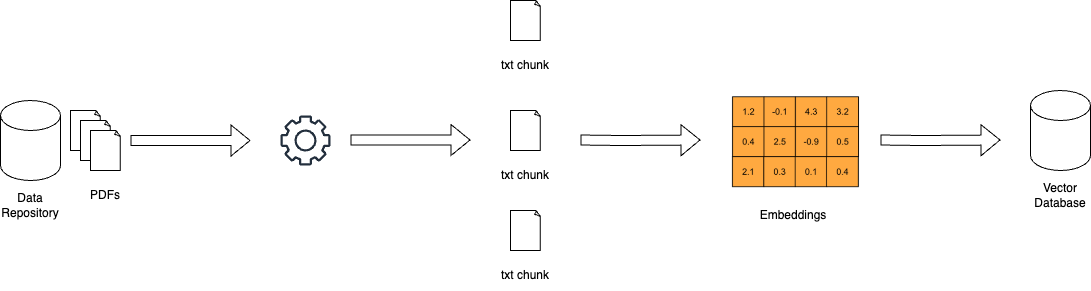
איך RAG פועל – miro.medium.com
שאלות ותשובות
שינוי משחק בשדה התשובות נתן להבין ש-RAG- היא מוצר משנה גמרי. על-ידי קבלת מידע רלוונטי ממקורות ידע חיצוניים ושילובו בתהליך הייצור, מערכות RAG יכולות לספק תשובות מדויקות יותר ורלוונטיות להקשר. (LangChain ו-Django Stars)
לדוגמה, Izacard ו-Grave (2021) הציעו מודל בהקשר RAG בשם Fusion-in-Decoder (FiD), שהשג שיא בביצועים במספר בדיקות תשובות, כולל שאלות טבעיות ו-TriviaQA. (Izacard ו-Grave)
FiD מנצל דוגמה צפופה כדי להשיג פסקאות רלוונטיות ומודל יצירתי כדי לשלב את המידע המשובש לתשובה הגיוונית, משיג ביצועים גדולים יותר ממודלים יצירתיים בלבד. (Izacard ו-Grave)
מערכות שיחה
RAG גם מצא יישומות ביצירת סיסמים שיחתיים יותר מעניינים ומעניינים. דרך הכנסת ידע חיצון באמצעות הבאה, מערכות שיחת התמונה RAG יכולות ליצר תגובות שאינן רק מתאימות בהקשר אלא גם מושמעות על עובדה. (LlamaIndex ו MyScale)
שוסטר ואחרים (2021) הצגו מערכת שיחת התמונה RAG בשם BlenderBot 2.0, שהראתה יכולת שיחת מעבר למקדם הקודם לו. (Shuster et al.)
BlenderBot 2.0 משאיר מידע רלוונטי ממקורות ידע מגוונים, כולל ויקיפדיה, מאמרי חדשות ומדיה חברתית, מה שמאפשר לו להיות מעורב בשיחות יותר מודעות וברורות על ידי סוגים רחבים של נושאים. (Shuster et al.)
סיכום
RAG הוכיח שיש בה תקווה בתהליך השיפור באיכות הסיכומים המגדלים על ידי הכנסת מידע רלוונטי ממקורות רבים. (Hyperight) פאסונורו ואחרים (2021) הצעו מודל סיכום RAG בשם PEGASUS-X, שמשיג ומשלב פסקאות רלוונטיות ממאמרים חיצוניים כדי ליצור סיכומים יותר מודעים וברורים.
PEGASUS-X מידע את הביצועים של מודלים רק גנרטיביים במספר מדגימות לסיכם, ומוכיח את היעילות של אילוץ המחזור בשיפור הדיוק הממשי והרלוונטיות של הסיכמים המיוצרים.
כריתי כתיבה
הפוטנציאל של RAG נמשך מתחומים ממשיים ומגיע לתחום של כריתי כתיבה. על ידי אילוץ פסים רלוונטיים מאונקופוס מגוון של עבודות ספרותיות, מערכות RAG יכולות ליצור סיפורים או מאמרים חדשים ומרגשים.
רשקין ואחרים (2020) הכינו מודל כריתי כתיבה בעזרת RAG שנקרא CTRL-RAG, המאסף פסים רלוונטיים ממאגר גדול של ספרי בדיוני ומשלב אותם את תהליך היצירה. CTRL-RAG הוכיחה את היכולת ליצור סיפורים מתאימים ושייכים סגנונית, מראה את הפוטנציאל של RAG ביישומים כריתיים.
מחקרים מקטעיים
מספר מאמרים ופרוייקטים הוכיחו את היעילות של RAG בתחומים שונים.
לדוגמה, לויס ואחרים (2020) הכינו את המסגרת RAG ויישמו אותה בשאלות ותשובות בתחום השאלות הפתוחה, והגיעו לביצועים של רמת המידה העדכנית על המדגים הנטרליים. (לויס ואחרים) הם דיברו על האתגרים של אינטגרציית האילוץ ועל חשיבות הטיפול במודל הגנרטיבי על פסים שנאספים.
, , , , , ,
שבמחקר נוסף, פטרוני וכוללים (2021) החליטו ליישם את RAG על משימת בדיקת עובדות, והדגימו את היכולתו להשיג ראיות רלוונטיות ולייצר פסקי דין נכונים. הם הדגים את הפוטנציאל של RAG במאבק נגד מידע מוטעה ובשיפור האמינות של מערכות מידע.
ההשפעה של RAG על חווית המשתמש ומדדים העסקיים היתה משמעותית. על ידי ספקת תשובות יותר נכונות ומידעיות, מערכות מבוססות RAG השפרו את השתלמות והתעסקות המשתמש. (LlamaIndex ו־MyScale)
במקרה של סוכני שיחה, RAG איפשר יצירות יותר טבעיות וערוכות יחד, שמובילות להגדלת שיאת המשתמשים ואמון. (LlamaIndex ו־MyScale) בתחום הכתיבה היצירתית, RAG יש לפוטנציאל לסדר את תהליכי יצירת תוכן ולייצר רעיונות חדשים, מחסוך זמן ומשאבים לעסקים.
כפי שאתם יכולים לראות, היישומים המעשיים של RAG כוללים תחומים רחבים, מענין ושיחה לסכמות וכתיבה יצירתית. על ידי שימוש בכוח השליפה והייצור, RAG הדגים שיפורים משמעותיים בדיוק, רלוונטיות ותעסקות משתמש.
ככל שהתחום מתפתח, אנחנו יכולים לצפות לראות יותר אפליקציות מתקדמות של RAG, שמשנות את האופן שבו אנחנו מתקשרים ויוצרים מידע בהקשרים שונים.
4.2 RAG עבור שפות משאב נמוכות והגדרות מרובות
לנצל את היכולת של Retrieval-Augmented Generation (RAG) עבור שפות משאב נמוכות והגדרות מרובות אינו רק הזדמנות – זה חובה. עם מעל 7,000 שפות המדוברות ברחבי העולם, רבות מהן אינן מספקות משאבים דיגיטליים משמעותיים, האתגר ברור: איך אנחנו מבטיחים ששפות אלה לא יישארו מאחור בעידן הדיגיטלי?
תרגום כגשר
אחת האסטרטגיות היעילות היא לתרגם מסמכים מקוריים לשפה עשירה יותר במשאבים לפני האינדוקס. גישה זו מנצלת את הקורפוסים הנרחבים הזמינים בשפות כמו אנגלית, שמשפרת באופן משמעותי את דיוק האינדוקס והרלוונטיות.
על ידי תרגום המסמכים לאנגלית, ניתן לנצל את המשאבים הנרחבים והטכניקות המתקדמות באינדוקס שכבר פותחו עבור שפות עם משאבים מרובים, ובכך לשפר את ביצועי מערכות RAG בהקשרים משאב נמוכים.
התמוססות רב-שפתית
התקדמויות אחרונות באמבדינג של מילים רב-שפתי מציעות פתרון נוסף ומבטיח. על ידי יצירת מרחבי אמבדינג משותפים עבור מספר שפות, ניתן לשפר את הביצוע החוצ-שפתי גם עבור שפות עם משאבים מאוד נמוכים.
מחקרים הראו שלחבר תרגומים ביניים עם אמבדינגים איכותיים גבוהים יכול לחבר את הפער בין זוגות השפות המרוחקות, ולשפר את איכות האמבדינגים הרב-שפתיים בצורה כוללת.
שיטה זו לא רק משפרת את דיוק ההשגה אלא גם מבטיחה שהתוכן המיוצר הוא רלוונטי וקורקטיבי להקשרו.
למידה פדרלית
למידה פדרלית מציגה גישה חדשנית להתמודדות עם מגבלות שיתוף נתונים והבדלים לשפתיים. על-ידי תיקון מודלים על מקורות נתונים פידרליים, אפשר לשמור על פרטיות המשתמשים ובו זמנית לשפר את ביצועי המודל ברחבי שפות מרובות.
שיטה זו הראתה עלייה של 6.9% בדיוק והפחתה של 99% בפרמטרים האימונים בהשוואה לשיטות מסורתיות, מה שהופך אותה לפתרון יעיל ואפקטיבי למערכות RAG רב-לשוניות.
הפחתת ההלוקינציות
אחד האתגרים הכרחיים בהטמעת מערכות RAG בסביבה רב-לשונית הוא הפחתת ההלוקינציות – מקרים בהם המודל מייצר מידע שגוי או לא רלוונטי.
טכניקות RAG מתקדמות, כמו RAG מודולרי, מציגות מודלים חדשים ואסטרטגיות תיקון מתקדם כדי להתמודד עם הבעיה הזאת. על-ידי עדכון מתמיד של בסיס הידע ושימוש במדדים הערכה נוקשים, אפשר להפחית באופן משמעותי את נפילת ההלוקינציות ולהבטיח שהתוכן המיוצר הוא גם נכון וגם אמין.
יישום מעשי
על מנת ליישם בצורה אפקטיבית את האסטרטגיות הללו, תשימו לב לצעדים המעשיים הבאים:
- ניצול תרגום</diy11
- השתמש בשילובי עיבוד מרובי שפות: שלב שפות ביניים עם עיבוד באיכות גבוהה כדי לשפר את הביצועים בין-שפתיים.
- אמץ למידה פדרטיבית: עצב מודלים על מקורות נתונים מבוזרים כדי לשפר את הביצועים בשמירה על הפרטיות.
- צמצם הוֹלוּצִיּוֹת: השתמש בטכניקות מתקדמות של RAG ועדכונים רציפים בבסיס המידע כדי להבטיח דיוק פקטואלי.
על ידי אימוץ האסטרטגיות הללו, תוכל לשפר באופן משמעותי את הביצועים של מערכות RAG בסביבות עם משאבים מוגבלים וברב-שפתיות, ולוודא שאף שפה לא תישאר מאחור במהפכה הדיגיטלית.
פרק 5: טכניקות אופטימיזציה
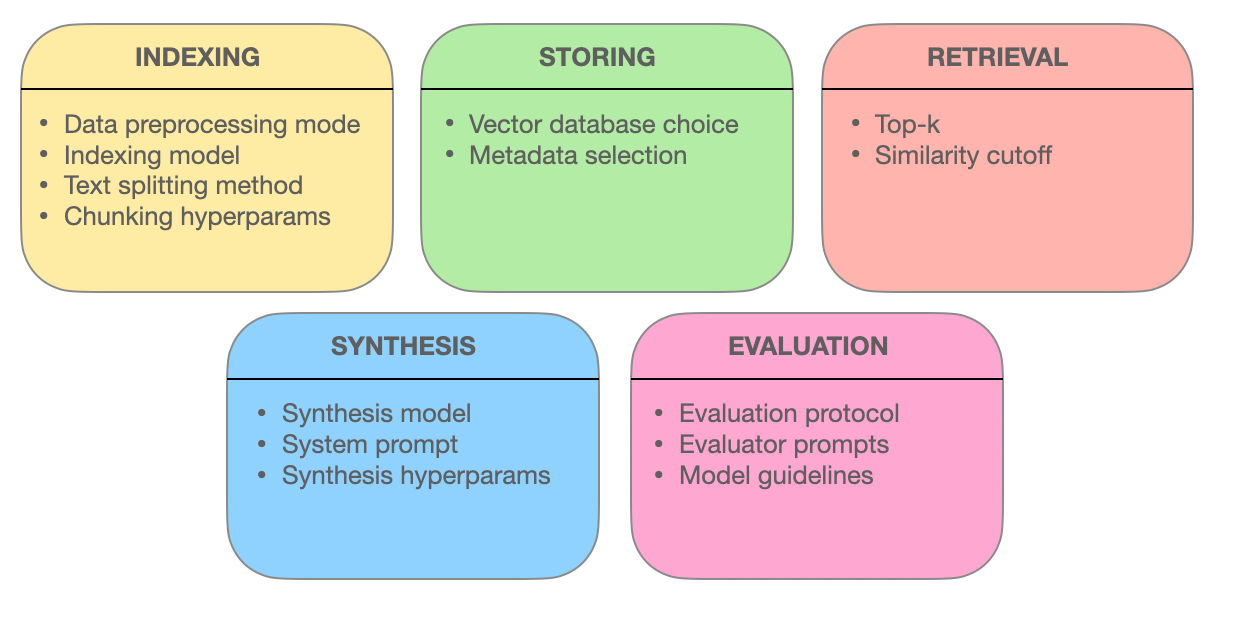
בפרק זה נעסוק בטכניקות המתקדמות של אחזור המידע המבטיחות את היעילות של מערכות Retrieval-Augmented Generation (RAG). אנחנו נבחן כיצד אופטימיזציות פיסוק, שילוב מטא-נתונים, אינדקוסים מבוססי גרף, טכניקות יישור, חיפוש היברידי וסידור מחדש משפרים את הדיוק, הרלוונטיות והמקיף של אחזור המידע.
על ידי הבנת השיטות הלהבות הללו, תרכוש תובנות לגבי כיצד מערכות RAG מתפתחות ממנועי חיפוש פשוטים לספקים מידע חכמים שמסוגלים להבין שאילתות מורכבות ולספק תגובות מדויקות, רלוונטיות בהקשר.
5.1 טכניקות אחזור מתקדמות לאופטימיזציה של מערכות RAG
מערכות Retrieval Augmented Generation (RAG) מהפכות את הדרך בה אנו ניגשים ומשתמשים במידע. לליבת המערכות הללו יש את היכולת לאחזר מידע רלוונטי באופן יעיל.
בואו נעמוד עמוק יותר בטכניקות השחזור המתקדמות שמאפשרות למערכות RAG לספק תשובות מדויקות, רלוונטיות בהקשר ומקיפות.
אופטימיזצית קטעים: מקסימום רלוונטיות דרך שחזור גרנולרי
בעולם המערכות RAG, מסמכים גדולים יכולים להיות מרהיבים. אופטימיזציית קטעים פותרת את האתגר הזה על ידי פיצוץ של טקסטים רבים ליחידים קטנים יותר, שנקראים קטעים. הגרנולריות הזאת מאפשרת למערכות השחזור לזהות קטעים ספציפיים של טקסט שמתאימים למונחי החיפוש, משפרת את הדיוק והיעילות.
אומנות האופטימיזציה של קטעים מתגלה בהגדרת גודל הקטע האידיאלי וההתנגדות. קטע קטן מדי עשוי להעפיל על קשר, בעוד קטע גדול מדי עשוי להרטיד רלוונטיות. פיצוץ דינמי, טכניקה שמתאימה גודל קטע בהתאמה למבנה ולסמנטיקה של התוכן, מבטיחה שכל קטע יהיה עקבי ומשמעותי בהקשר.
אינטגרצית מטא-נתונים: משיכת הכוח שבתגי מידע
מטא-נתונים, המידע המלווה המסמך, עשוי להיות מכריע עבור מערכות השחזור. על ידי אינטגרציה של מטא-נתונים כגון סוג המסמך, המחבר, תאריך הפרסום ותגי נושא, מערכות RAG יכולות לבצע חיפושים ממוקדים יותר.
שחזור עצמי של שאילתות, טכניקה שמאפשרת על ידי אינטגרציה של מטא-נתונים, מאפשרת למערכת ליצור שאילתות נוספות בהתבסס על התוצאות הראשוניות. תהליך זה ממוקד את החיפוש, מבטיח שהמסמכים שנמצאים לא רק מתאימים לשאילתה אלא גם עונים על דרישות המשתמש והצרכים ההקשריים שלו.
מבני אינדקס מתקדמים: רשתות מבוססות גרפים לשאילתות מורכבות
שיטות אינדקסציה מסורתיות, כמו אינדקסים הפוכים וקידודי וקטורים צפים, נתקלות במגבלות בעת עיבוד שאילתות מורכבות הכוללות יחידות מרובות ויחסים שלהן. אינדקסים מבוססי גרפים מציעים פתרון על ידי ארגון מסמכים והחיבורים שלהם במבנה של גרף.
הארגון הדומה לגרף מאפשר עבירה יעילה ואחזור של מסמכים קשורים, גם בתרחישים מורכבים. אינדקסציה הייררכית וחיפוש משכנים קרובים שופרים עוד יותר את הקיבולת והמהירות של מערכות האחזור המבוססות על גרפים.
טכניקות היישור: מבטיחים דיוק ומפחיתים הילוצינציות
האמינות של מערכות RAG תלויה ביכולתן לספק מידע מדויק. טכניקות היישור, כגון הכשרה נגדית, פותרות את הבעיה הזו. על ידי חשיפה של המודל לתרחישים היפותטיים, הכשרה נגדית מלמדת את המודל להבחין בין עובדות מהעולם האמיתי למידע שנוצר, כך מפחיתה הילוצינציות.
במערכות RAG מרב-מודליות, שמשלבות מידע ממקורות שונים כמו טקסט ותמונות, למידה נגדית משמשת תפקיד קריטי. טכניקה זו מיישרת את הייצוגים הסמנטיים של מודלי נתונים שונים, מבטיחה שהמידע שנאחזר הוא עקבי ומשולב בהקשר.
חיפוש היברידי: שילוב דיוק מילות המפתח עם הבנה סמנטית
חיפוש היברידי משלב את הטוב ביותר משני העולמות: מהירות ודיוק של חיפוש מבוסס מילות המפתח עם הבנה סמנטית של חיפוש מבוסס וקטור. בתחילה, חיפוש מבוסס מילות המפתח יורד מהר את הערך של המסמכים הפוטנציאליים.
אחר כך, חיפוש מוטורי מדגים את התוצאות על פי סימילריות סמנטית. הגישה הזו מועילה בעיקר כשחיפוש מותאם בדיוק למילים מפתח הוא חיוני, אבל גם הבנה עמוקה יותר של הכוונה של השאלה היא נחוצה לשימוש בשיחזור מדויק.
סידור מחדש: מעדכן המתאמות עבור התשובה המושלמת
בשלב האחרון של השימוש במידע, סדירה מחדש מגיעה כדי לעדכן את התוצאות. מודלים ללמידה מכונית, כמו קראס-אינקודרים, מדודכים מחדש את הציונים הקשורים למסמכים המוצאים. על-ידי עיבוד השאלה והמסמכים ביחד, המודלים האלה מקבלים הבנה עמוקה יותר של היחסים ביניהם.
ההשוואה המפורטת הזו מובטחת שהמסמכים המובילים באמת מתאמים לשאלה וההקשר של המשתמש, למעשה מעניקה חוויה שיחזור יותר משמחה ומידעית.
הכוח של מערכות RAG מגלים בהם הם מסוגלים לאסוף ולהציג מידע באופן שלילה. על-ידי שימוש בטכניקות מידע מתקדמות אלה – מיטוב חתך, שילוב מידע סימנטי, ישומת ערך בעזרת גרפים, טכניקות התדירות, חיבור מידע, וסידור מחדש – מערכות RAG נהיית יותר מסרנים מסוגלים להבין שאלות מורכבות, להבחין בנוגע למידע העדין, ולספק תשובות מדויקות, מתאמות ואמינות.
פרק 6: אתגרים וחידושים
אנחנו חוקרים את המורכבות של הערכים של מערכות RAG, כולל הצעדה למדידות מורכבות ומערכות אדפטיביות כדי להעריך את הביצועים שלהם בצורה מדוייקת. אנחנו גם מטפלים בהוגנות המעניינת כמו הדיכאון בהתבצעות והוגנות באובחן מידע ויצירתיות.
אנחנו גם בדיקים את חשיבות האיץ האקסלציום ואסטרטגיות ההגעה היעילות, בהצגת השימוש במכשירים מיוחדים ואמצעי התייחסות כמו Optimum להגברת הביצועים וההגעה לסקלריות.
דרך הבנת האתגרים האלה והסקירה של פתרונות אפשריים, פרק זה מעניק מפה מסודרת מוחשית להתקדמות המתמשכת וליישם הגיוני של טכנולוגיית RAG.
6.1 אתגרים וכיוונים העתיד
מערכות RAG הוכיחו פוטנציאל מדהים בתחזיקה בדיוק, הקשר והתאמה של הטקסט המיוצר. אך הפיתוח וההגעה למערכות RAG מעניקים גם אתגרים משמעותיים שצריך להתייחס להם כדי להגיע לפוטנציאלם המלא.
"הערכים של מערכות RAG מוכרחים להתייחס לרבות מהרכיבים הספציפיים האלה ולמורכבות ההערכה הכללית של המערכת." (Salemi ואחרים.)
אתגרים בהערכת מערכות RAG
אחד האתגרים הטכניים העיקריים בראג (RAG) הוא לוודא שיהיה לנו את ההוצאה לשימוש במידע רלוונטי מבססי ידע גדולים ומורחבים. (Salemi ואחרים. ו Yu ואחרים.)
בעקבות הגידול בגודל ובמגוון של מקורות הידע, פיתוח מנגנונים מסוגלים ועמידים נעשה חשוב יותר ויותר. טכניקות כמו אינדקסינג היררכי, חיפוש מייצגים קרובים, ואסטרטגיות שליטה עמידות צריכות להיות נחקקות על מנת לאדם את תהליך ההוצאה.
חלק מהרכיבים במערכת RAG – miro.medium.com
אחד האתגרים המשמעותיים הוא להמתיך את הבעיה של הזיוף, בה המודל הגנרטיבי יוצר מידע שגוי עובדה או לא התאמן עם המידע.
לדוגמה, מערכת RAG עשויה לייצר אירוע היסטורי שמעולם לא התרחש או להעלות על מישהו את תגלית המדע. למרות שההוצאה עוזרת לקישור את הטקסט המיוצר בידע ממשי, הוא עדיין משימה למעשה מורכבת להגיד שהידע המיוצר הוא אמין והגיוני.
לדוגמה, מערכת RAG יכולה להביא מידע די ידוע על תגלית מדעית ממקור אמין כמו ויקיפדיה, אך המודל הגנרטיבי עדיין יכול להזיוף על ידי שילוב המידע הזה בצורה שגויה או על ידי הוספת פרטים שלא קיימים.
איכשהו, בתחום המחקר מאוד פעיל מתמקד בפיתוח מנגנונים יעילים לזיהוי ומניעת הזיות. טכניקות כמו איכוף עובדה בעזרת מאגרים חיצוניים ובדיקת ההתאמה באמצעות הצגה מקבלים רבים, נחקרות בהתמקדות. השיטות האלה מוכוונות לוודא שהתוכן המיוצר נשאר מדויק ואמין, למרות האתגרים הבסיסיים בקשר להתאמה בין תהליך האספוס והתוצרת.
איחדת מקורות ידע מגוונים, כמו מאגרים מבנויים, טקסט לא מבנוי ומידע רב-מידעי, מערערת אתגרים נוספים במערכות RAG. (Yu et al. ו Zilliz) התאמה בין הייצגים והסמנטיקה בין המידע בצורות שונות ומאגרים דיגיטליים דורשת טכניקות מתקנות, כמו תשומת מבט מקורבת ותיעודה של גרף הידע. ההאחדות והתפעולות התאמה של מקורות ידע מגוונים הוא חשוב לפעולה יעילה של מערכות RAG. (Zilliz)
מעבר לאתגרים טכניים, מערכות RAG גם מעלים בעיות אתיות חשובות. בהם בטחון הוא לא יתרגל את מידע החיבור והיצירה ההוגן והשוויוני. מערכות RAG עשויים להגביר ביצועים באופן בלתי מוכרן את הטיעון הקיים במידע האימון או במקורות הידע המקוריים, הובילים ליצירות דוחפות או מוטעות. (Salemi ואחרים. ו Banafa)
פיתוח טכניקות על מנת זיהוי ומתעללות בטיעון, כמו אדוארציאלי העיתוד והשימוש באחיזת השוויון, הוא מסלול מחקר חשוב. (Banafa)
כיומיות של מחקר
על מנת לטפל באתגרים במערכות RAG, ניתן לבדוק מספר פתרונות וכיוונים מחקר.
פיתוח מדדים הולמים שמתפעלים במערכת הביצועים הכללית של האחיזה ואיכות היצירה המשמעותי הוא חשוב. (Salemi ואחרים.)
שיטות מודדות שמעריכות את הרלוונטיות, הקוהרנציה והנכונות העובדתית של טקסט מיוצר, בעוד שמתבקשת היעילות של מרכיב ההשגה, צריכות להיות מוגדרות. (סאלמי ועודן.) זה דורש גישה הוליסטית שמעבר למטריצות מסורתיות כמו BLEU ו-ROUGE ושכוללת בדיקה אנושית ומדדים ספציפיים למשימה.
חקירה של מסגרות בדיקה ניתנות לשינוי ובזמן אמת היא כיוון מתוחכם נוסף.
מערכות RAG פועלות בסביבות דינמיות שבהן מקורות הידע ודרישות המשתמש עשויים לשנות במשך הזמן. (יו ועודן.) פיתוח מסגרות בדיקה שיכולות להתאים לשינויים אלו ולספק משוב בזמן אמת על הביצועים של המערכת הוא הכרחי לשיפור מתמשך ולמעקב.
זה עשוי להכיל טכניקות כמו למידה ברשת, למידה פעילה ולמידה בירות שמעדכנות את המטריצות והמודלים לפי תגובת המשתמש וההתנהגות של המערכת. (יו ועודן.)
המאמצים המשותפים בין חוקרים, מערכת התעשייה ומומחים בתחום המערכת האקראית הסינטית הם נחוצים להתקדם בתחום הערכים של הבחינה במערכות הראג. הגדרת מדדים סטנדרטיים, מידע וprotocols אבחנה יכולים לסייע בהשוואה ובייחודיות של מערכות הראג בתחומים ויישומים שונים. (Salemi et al. ו Banafa)
השיתוף פעולה עם המשתייכים, כולל לקוחות הקצות ומדיניות המדינה, הוא חשוב לוודא שהפיתוח וההגדרה של מערכות הראג מתאימים עם הערכים החברתיים והמודלים האתיים. (Banafa)
אז בעוד שמערכות הראג הראו פוטנציאל עצום, טיפול באתגרים בבחינה שלהן הוא חשוב להרחבת את האימוץ הרחב ואת האמון. על ידי פיתוח מדדים בחינה מקיפים ובודדים, חקירה במערכות בחינה הגיוניות ובזמן אמת, ועל ידי תעמולת מאמצים משותפים, אנחנו יכולים לסלק את הדרך למערכות הראג יותר מאמינות, לא מוטיביות ויעילות.
כשהתחום ממשיך להתפתח, חשוב לדעת את המאמצים החשובים למחקר שלא רק מפתחים את היכולת הטכנית של הראג אלא גם מודאגים על השימוש האתי והאתי בהגדרה של הראג ביישומים הן בעולם האמת.
6.2 איספקציית חומרה והגדלה יעילה של מערכות הראג
ניצוב האצת חומרה חיוני ליישום יעיל של מערכות Retrieval-Augmented Generation (RAG). על ידי העברת משימות מחשוב אינטנסיביות לחומרה מתמחה, ניתן לשפר באופן משמעותי את ביצועי והסקאלביליות של הדגמי RAG שלך.
ניצוב חומרה מתמחה
כלי האופטימיזציה החומרתיים של Optimum מציעים יתרונות משמעותיים. לדוגמה, יישום מערכות RAG על ערכים של מעבדי Habana Gaudi יכול להוביל להפחתה משמעותית בלטנצית ההסקה, בעוד האופטימיזציות של מדחס העצבים של Intel יכולות לשפר עוד יותר את המדדים של הלטנציה. החומרה של AWS Inferentia, המאופטמת דרך Optimum Neuron, יכולה לשפר את יכולות הנפח, עשויות להפוך את מערכת ה-RAG שלך ליותר רספונסיבית ויעילה.
אופטימיזציה של ניצוב משאבים
ניצוב אפקטיבי של משאבים הוא חיוני. אופטימיזציות של Optimum ONNX Runtime עשויות להוביל לשימוש זיכרון יעיל יותר, בעוד אפליקציית BetterTransformer API עשויה לשפר את השימוש במעבד ובמעבד גרפי. אלו האופטימיזציות מבטיחות שמערכת ה-RAG שלך תפעל ביעילות מרבית, ותפחית את עלויות הפעולה ותשפר את הביצועים.
סקאלביליות וגמישות
Optimum תומך במעבר חלק בין מאיץי חומרה שונים, מאפשר סקאלביליות דינמית. תמיכה זו במגוון מאיצי חומרה מאפשרת לך להתאים את עצמך לדרישות חישוביות שונות ללא צורך בהגדרה מחדש משמעותית. בנוסף, תכונות של קוואנטיזציה וצמצום מודלים ב-Optimum עשויות לקל Facilitate גידול גודל מודלים יותר יעיל, מה שיכול להפוך את האימון לקל יותר ולחסוך בעלויות.
תיק תיקי מחקר ויישומים בעולם אמיתי
שימו לב ליישום של אופטימום באיסוף מידע ברפואה. על-ידי שימוש בהפוךת תוצרתיות ספציפית לחומרה, מערכות RAG יכולות להתמודד ביעילות עם מערכות נתונים גדולות, נותנות מידע מדויק ובזמן. זה לא רק משפר את איכות הספקת הבריאות אלא גם משפר את החוויה הכללית של המשתמש.
צעדים מעשיים ליישום
- בחרו חומרה מתאימה: בחרו מאפשריות חיזוק חומרה כמו Habana Gaudi או AWS Inferentia בהתאמה לדרישות הביצועים שלכם.
- שימוש בכלים להפוךת תוצרתיות: הפעלו את כלים ההפוךת התוצרתיות של Optimum כדי לשפר את ההשהיה, תחושת העבודה ושימוש המשאבים.
- וידאו שיכלת המידה: השתמשו בתמיכה בחומרה מרובה כדי להתאם באופן דינמי את מערכת ה-RAG לפי הצורך.
- הפוךת גודל המודל: השתמשו בכימיה ובחיטוי של מודלים כדי להפחית את העומס המחשובי ולאפשר התקנה קלה יותר.
על-ידי שילוב האסטרטגיות הללו, אפשר לשפר באופן משמעותי את הביצועים, הגמישות והיעילות של מערכות ה-RAG, ולוודא שהן מתאימות להתמודדות עם יישומים מורכבים בעולם האמיתי.
הסיכום: הפוטנציאל המשנה של RAG
Retrieval-Augmented Generation (RAG) מייצגת פרדיגמה משנתנת בעיבוד טקסט טבעי, השתלבת בצורה בלתי מובן את הכוח של איסוף מידע עם היכולות הייצוריות של מוד
על ידי השימוש במקורות מידע חיצוניים, מערכות RAG הוכיחו שיפורים מרשימים בדיוק, רלוונטיות והקשרות של הטקסט שנוצר במגוון רחב של יישומים, מתשובות לשאלות ומערכות דיאלוג לסיכום וכתיבה יצירתית.
התפתחותם של מודלי שפה, ממערכות מבוססות כללים מוקדמות ועד למודלים עצביים המתקדמים ביותר כמו BERT ו-GPT-3, פתחה את הדרך להתפשטות של RAG. הגבולות של זיכרון מפרמטרי בלבד במודלים שפה מסורתיים, כמו תאריכי חיתוך ידע ופקטואליות מתנגדת, טופלו ביעילות על ידי הכללה של זיכרון לא מפרמטרי באמצעות מנגנוני איחזור.
הרכיבים המרכזיים של מערכות RAG, בעיקר גורמי האיחזור והדגמה, פועלים בסינרגיה ליצירת תוצאות העונות להקשר והעוסקות בעובדות.
גורמי האיחזור, באמצעות טכניקות כמו איחזור מזעורי ואיחזור מרוכז, מחפשים באופן יעיל דרך מסדי ידע נרחבים כדי לזהות את המידע המתאים ביותר. מודלים יצירתיים, בעזרת ארכיטקטורות כמו GPT ו-T5, מסינתזים את התוכן שנמצא במקורות לטקסט עקבי ורך.
אסטרטגיות השילוב, כמו הצמדה ואטנשן משותפת, קובעות כיצד המידע שנאסף מוכנס לתהליך היצירה.
יישומים מעשיים של RAG מתרכזים בתחומים שונים, מה שמדגיש את הפוטנציאל שלו למהפך בתעשיות שונות.
בשיווק תשובות, RAG שיפר באופן משמעותי את הדיוק והרלוונטיות של התשובות, מאפשר את המציאת המידע היותר מעניינת והולמת. מערכות דיאלוג היו מועילות מאת RAG, מה שהוביל לשיחות יותר מעניינות וסדירות. משימות סיקור ראו את האיכות והסדירות המשושת דרך השילוב של מידע רלוונטי ממקורות מסוימים. אפילו כריתת יצירה חדשנית הועברה, עם מערכות RAG יוצרות סיפורים חדשניים וסגולים במבנה אחד.
אך התפתחות והבחינה במערכות RAG מעניקות את האתגרים המשמעותיים. איצוף יעיל מבחנים מידע מבנים בסיסיים גדולים, התמדה למנע הדמיון, והשלמת המידע המגוונת הינם בין האתגרים הטכניים שצריך להתייחס אליהם. השקפים אתיים, כמו לוודא של מידע הולך וגיינה שהולם והגיוניים, הם חשובים להשתמשה מוסרית במערכות RAG.
על מנת להגיע לפוטנציאל הכללי של RAG, עלינו להתמקד במסלולים המחקר העתידים שישלמו במדדים הביצוע המושלמים שילוב בין דיוק ההוצאה ואיכות היצירה.
מערכות ביצועים הדמינציונלים והזמנים שיכולים להתמודד עם האופי הדינמי של מערכות RAG הם חיוניים לשיפור מתמיד והשגה של הבחינה. המיזם השיתופי בין חוקרים, מומחים בתעשייה ומומחים בתחום המידע הוא נחוץ להגדיר בסטנדרטים, מידע
ובעוד התחום של RAG מתפתח במהירות, הוא מחזיק בהבטחה עצומה לשינוי את הדרך בה אנחנו מתנהלים במגע עם המידע ובייצורו. על-ידי אחדות הכוחות של השימוש באחסון ובייצור, מערכות RAG מצעדות בפעולה למהפך את התחומים השונים, מאחסון מידע ומייצור שיחות עד יצירת תוכן וגילוי ידע.
אתם מקבלים את המילים "Retrieval-Augmented Generation" שמייצגות עמדה חשובה במסע הזה ליצירת תערובת שפה חכמה יותר, מדוייקת יותר, ומתואמת יותר עם ההקשר.
על-ידי חיבור הפער בין הזיכרון הפרמטרי והלא-פרמטרי, מערכות RAG פתחו אפשרויות חדשות עבור עיבוד השפה הטבעית והיישומים שלו.
ובהתפתחות המחקר וטיפול באתגרים, אנחנו יכולים לצפות בRAG בתפקיד מפתח יותר ויותר בעיצוב העתיד של התנהגות האדם-מכונה והייצור הידעי.
על המחבר
הנה והיא אסלניאנ, בנקודת המפגש של מדעי המחשב, מדעי המידע והמידע החי. בואו ל vaheaslanyan.com ותראו תיק הפוטפורטו שלי שמעדן את הדיוק וההתקדמות. הנסיון שלי מגיע מבין הצעדים בין פולשת המידע ואי-פולשת המידע והעיצוב של מוצרי AI, מונע בדרך חדשה את הבעיות.
עם שירותים שכללו השקת מה-קידום מובילה במדעי המידע ועבודה ביחד עם מומחים מקצועגים, המיקוד שלי נשאר על העלייה של חינוך הטכנולוגיה למעלה לעומק ולמקרים אוניברסליים.
איך אתה יכול להיות יותר עמוק?
אחרי שימוש במדריך הזה, אם אתה מעוניין להיות עמוק יותר ולשיטת למידה מאורגנת הוא דוגמה לך, תחשב על הצטרפת אלינו בLunarTech, אנחנו מציעים קורסים פרטיים ומחנך במדעי המידע, לearning ועיניינים.
אנחנו מספקים תוכנית מקיפה שמעניקה הבנה עמוקה של התיזה, יישום מעשי ידני, חומר מתאמה רחבה והכנה מותאמה אישית להכין אותך להצלחה בשלב המשלך.
אתם מוזמנים להסתכל על אומנה מלאה למדעי הנתונים שלנו ולהצטרף לניסוי חינם כדי לנסות את התוכן בעצמכם. זה זכה בכבודה של היות אחד מהאומנות למדעי הנתונים הטובות ביותר של 2023, והופיע בכתבי-עת מכובדים כמו Forbes, Yahoo, Entrepreneur ועוד. זו ההזדמנות שלך להיות חלק מקהילה ששובה על חדשנות וידע. הנה ההודעת ברוכים הבאים!
תתרשמו איתי.

לונרטךchדיוקן חדשות
- עקב אחריי בלינקדין עבור מונים של משאבים חינמיים במדעי המחשב, תכנולוגיית המידע והמחשבה
- ביקור באתר האישי שלי
- הרשמה לדיוקן המידע והמחשבה
אם רוצים ללמוד עוד על קריירה במדעי המידע, תכנולוגיית המידע והמחשבה, וללמוד איך לחסוך עבודה בתכנולוגיית המידע, תוכלו להוריד את המדריך הקריירה בתכנולוגיית המידע והמחשבההחינמי הזה.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/