













בתקופה שמאופיינת בגידול גורפי בייצור נתונים, ארגונים חייבים לנצל בצורה יעילה את המאגר העצום של מידע זה כדי לשמור על יתרון התחרותי שלהם. חיפוש וניתוח נתוני לקוחות בצורה יעילה — כגון זיהוי העדפות משתמשים להמלצות על סרטים או ניתוח רגשות — משמש תפקיד קריטי בניהול קבלת ההחלטות מבוסס על מידע ובשיפור חוויות המשתמשים. לדוגמה, שירות צפייה יכול להשתמש ב-חיפוש וקטורי כדי להמליץ על סרטים המותאמים להיסטוריית הצפייה ולדירוגים האישיים של המשתמש, בעוד סימן מסחרי יכול לנתח את תחושת הלקוחות כדי למקד את אסטרטגיות השיווק שלו.
כמה מהנדסי הנתונים, עלינו ליישם פתרונות מתקדמים אלה, ולוודא שארגונים יכולים להפיק ראיונות פעולה ממערכות מידע עצומות. מאמר זה חוקר את הפרטים המורכבים של חיפוש וקטורי באמצעות Elasticsearch, ומתמקד בטכניקות יעילות ובשיטות מומלצות לאופטימיזציה של ביצועים. על ידי בדיקת סיפורי מקרה על אחזור תמונות לשיווק אישי וניתוח טקסט לאשכולת רגשות לקוח, אנו מדגימים כיצד אופטימיזציה של חיפוש וקטורי עשויה להוביל לאינטראקציות עם לקוח משופרות ולצמיחת עסקים ניכרת.
מהו חיפוש וקטורי?
חיפוש וקטורי הוא שיטה חזקה לזיהוי דמיון בין נקודות נתונים על ידי ייצוגן כווקטורים במרחב בעל ממד גבוה. גישה זו שימושית במיוחד עבור יישומים שדורשים אחזור מהיר של פריטים דומים בהתבסס על המאפיינים שלהם.
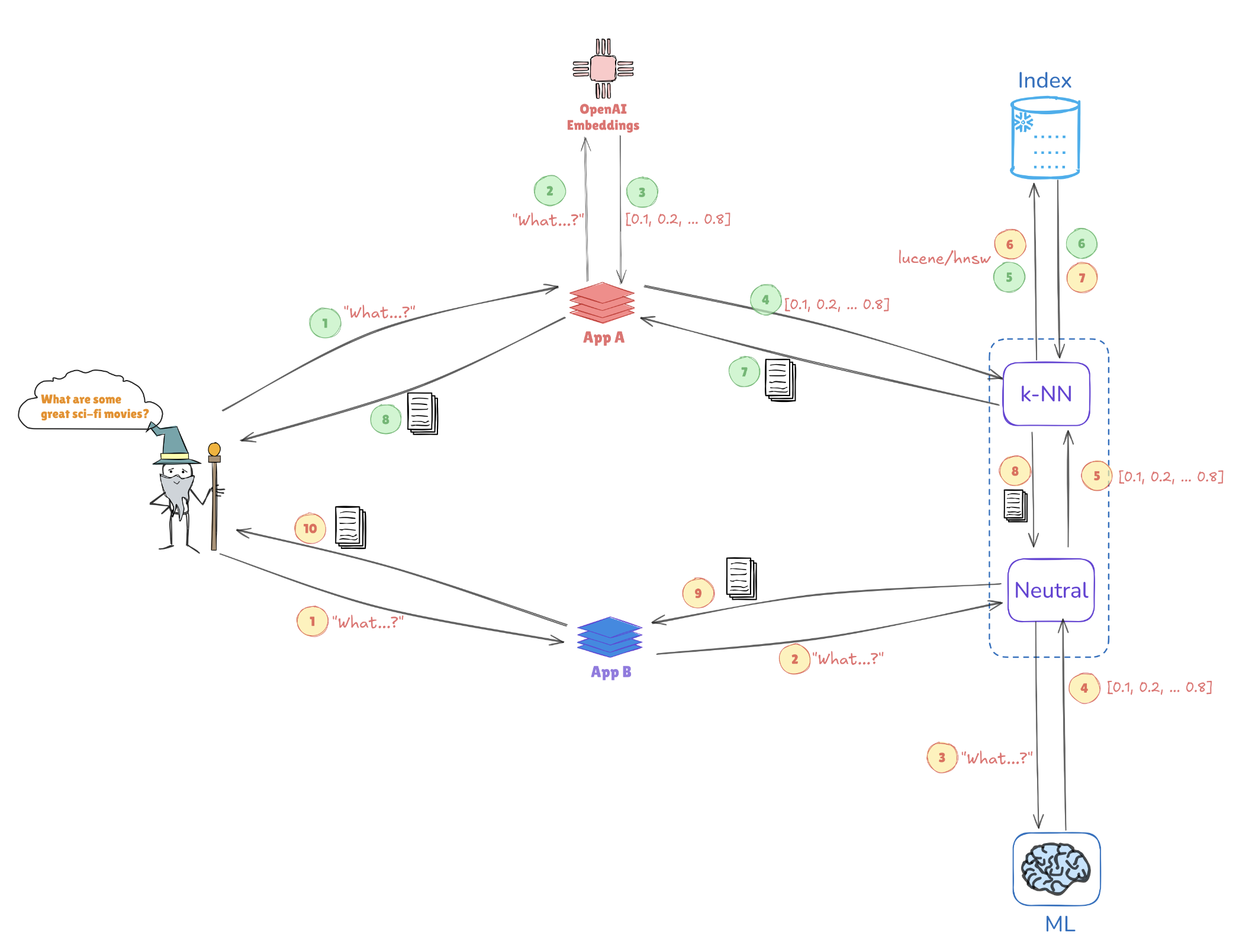
אילוסטרציה של חיפוש וקטורי
שקול את האילוסטרציה למטה, שמתארת כיצד ייצוגים וקטוריים מאפשרים חיפושי דמיון:
- שאלות ממומשות: השאלה "מהן כמה סרטי מדע בדיוני נהדרים?" מומרת לייצוג וקטורי, כמו [0.1, 0.2, …, 0.4].
- אינדוקס: הווקטור הזה מושווה נגד וקטורים שנאגרו מראש ב-Elasticsearch (למשל, מיישומים כמו AppA ו-AppB) כדי למצוא שאלות או נקודות נתונים דומות.
- חיפוש k-NN: באמצעות אלגוריתמים כמו k-Nearest Neighbors (k-NN), Elasticsearch שולף ביעילות את ההתאמות הטובות ביותר מהוקטורים המנודים, ועוזר לזהות את המידע הרלוונטי ביותר במהירות.
מנגנון זה מאפשר ל-Elasticsearch להצטיין במקרים של שימוש כמו מערכות המלצה, חיפושי תמונות, ועיבוד שפה טבעית, שבהם הבנת הקשר ודמיון היא המפתח.
יתרונות מרכזיים של חיפוש וקטורי עם Elasticsearch
תמיכה בממדי גובה
אלסטיקשרץ מצטיין בניהול מבני נתונים מורכבים, חיוניים ליישומי למידת מכונה ובינה מלאכותית. יכולת זו היא קריטית כאשר מתמודדים עם סוגי נתונים רב-צדדיים, כגון תמונות או נתונים טקסטואליים.
סקלאביליות
הארכיטקטורה שלו תומכת בהרחבה אופקית, מה שמאפשר לארגונים להתמודד עם קבוצות נתונים המתרחבות ללא הפחתת הביצועים. זה חיוני ככל שכמויות הנתונים ממשיכות לגדול.
אינטגרציה
אלסטיקשרץ עובד באופן חלק עם ערכת אלסטיק, ומספק פתרון כולל לקליטת נתונים, ניתוח וויזואליזציה. אינטגרציה זו מבטיחה שהנדסאי נתונים יכולים לנצל פלטפורמה מאוחדת עבור מגוון משימות עיבוד נתונים.
שיטות עבודה מומלצות לאופטימיזציית ביצועי חיפוש וקטורים
1. הפחתת ממדי הווקטורים
הפחתת ממדי הווקטורים שלך יכולה לשפר משמעותית את ביצועי החיפוש. טכניקות כמו PCA (ניתוח מרכיב עיקרי) או UMAP (הערכה ופרויקט של מגוון אחיד) עוזרות לשמור על תכונות חיוניות תוך פשטות מבנה הנתונים.
דוגמה: הפחתת ממדים עם PCA
הנה איך ליישם PCA בפייתון באמצעות Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. אינדוקס בצורה יעילה
הניצול של אלגוריתמים של השכן הקרוב המשוער (ANN) יכול להאיץ משמעותית את זמני החיפוש. שקול להשתמש ב:
- HNSW (Hierarchical Navigable Small World): ידועה באיזון ביצועים ודיוק.
- FAISS (Facebook AI Similarity Search): מותאמת לסט נתונים גדולים ומסוגלת להשתמש בתיבול GPU.
דוגמה: יישום של HNSW ב-Elasticsearch
ניתן להגדיר את הגדרות האינדקס שלך ב-Elasticsearch כדי להשתמש ב-HNSW כך:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. שאילתות בצמתים
לשפר את היעילות, עיבוד בצמתים של מספר שאילות בבקשה יחידה מקטין את העומס. זה נפוץ במיוחד ביישומים עם תעבורת משתמשים גבוהה.
דוגמה: עיבוד בצמתים ב-Elasticsearch
ניתן להשתמש בקצה ה-_msearch עבור שאילות בצמתים:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. שימוש במטמון
יש ליישם אסטרטגיות מטמון עבור שאילות שנגישות בתדירות על מנת להפחית את העומס החישובי ולשפר את זמני התגובה.
5. מעקב אחר ביצועים
ניתן לנטור באופן קבוע את מדדי הביצועים כדי לזהות נקודות איטיות. כלים כמו Kibana יכולים לעזור להמחיש את הנתונים הללו, מאפשרים תיקונים מושכלים להגדרת ה-Elasticsearch שלך.
כיוון פרמטרים ב-HNSW לשיפור ביצועים משופרים
אופטימיזציה של HNSW כוללת כיוון של פרמטרים מסוימים להשגת ביצועים יותר טובים על סט נתונים גדול:
M(מספר החיבורים המרבי): הגדלת ערך זה משפרת את הזיכרון אך עשויה לדרוש יותר זיכרון.EfConstruction(גודל רשימה דינמית במהלך הבנייה): ערך גבוה מוביל לגרף דיוק יותר אך עשוי להאריך את זמן האינדוקסציה.EfSearch(גודל רשימה דינמית במהלך חיפוש): התאמה זו משפיעה על הסחר בין מהירות לדייקנות; ערך גדול יותר מספק זיכרון טוב יותר אך לוקח יותר זמן לחישוב.
דוגמה: התאמת פרמטרים של HNSW
ניתן להתאים פרמטרים של HNSW ביצירת אינדקס שלך כך:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
מקרה מבחן: השפעת הפחתת ממדיות על ביצועי HNSW באפליקציות נתוני לקוחות
שחזור תמונות לשיווק מותאם אישית
טכניקות הפחתת ממדיות משחקות תפקיד מרכזי באופטימיזציה של מערכות שחזור תמונות באפליקציות נתוני לקוחות. במחקר אחד, חוקרים יישמו ניתוח רכיב עיקרי (PCA) להפחתת ממדיות לפני אינדוקס תמונות עם רשתות HNSW (עולם קטן נavigable היררכי). PCA סיפק עלייה משמעותית במהירות השחזור — חיוני לאפליקציות שמטפלות בנפחים גבוהים של נתוני לקוחות — אם כי זה בא במחיר של אובדן דיוק קל עקב הפחתת מידע. כדי להתמודד עם זה, החוקרים גם בדקו את קירוב וריאנט אחיד והקרנה (UMAP) כאופציה חלופית. UMAP שימר מבנים מקומיים של נתונים בצורה יעילה יותר, תוך שמירה על הפרטים המורכבים הנדרשים להמלצות שיווק מותאמות אישית. בעוד ש-UMAP דרש כוח חישוב גדול יותר מ-PCA, הוא איזן בין מהירות החיפוש לדיוק גבוה, מה שהפך אותו לבחירה אפשרית למשימות קריטיות לגבי דיוק.
ניתוח טקסט לקיבוץ רגשות לקוחות
בתחום ניתוח רגשות הלקוחות, מחקר שונה מצא כי UMAP מנצח את PCA בקיבוץ נתוני טקסט דומים. UMAP אפשרה למודל HNSW לקבץ רגשות לקוחות עם דיוק גבוה יותר – יתרון בהבנת משוב הלקוחות וסיפוק תגובות מותאמות אישית יותר. השימוש ב-UMAP אפשר ערכים קטנים יותר של EfSearch ב-HNSW, מה ששיפר את מהירות החיפוש והדיוק. היעילות המשופרת של הקיבוץ אפשרה זיהוי מהיר יותר של רגשות לקוחות רלוונטיים, מה ששיפר את מאמצי השיווק הממוקדים ואת סגמנטציית הלקוחות המבוססת על רגשות.
שילוב טכניקות אופטימיזציה אוטומטיות
אופטימיזציה של הפחתת ממדי נתונים ופרמטרים של HNSW היא חיונית למקסום הביצועים של מערכות נתוני לקוחות. טכניקות אופטימיזציה אוטומטיות מפשטות את תהליך הכיוון הזה, ומבטיחות שההגדרות הנבחרות יהיו אפקטיביות במגוון יישומים:
- חיפוש רשתי ואקראי: שיטות אלו מציעות חקירה רחבה ושיטתית של פרמטרים, ומביאות לזיהוי יעיל של הגדרות מתאימות.
- אופטימיזציה בייסיאנית: טכניקה זו ממקדת פרמטרים אופטימליים עם פחות הערכות, ומחסנת משאבים חישוביים.
- אימות צולב: אימות צולב מסייע לאמת פרמטרים במגוון מערכות נתונים, ומבטיח את הכללתם להקשרים שונים של נתוני לקוחות.
התמודדות עם אתגרים באוטומציה
שילוב האוטומציה בתוך תהליכי הפחתת ממדים ו- HNSW עשוי להביא לאתגרים, בעיקר בניהול דרישות חישוביות ומניעת עובדת. האסטרטגיות לכיבוש את האתגרים אלו כוללות:
- הפחתת אוברהד חישובי: שימוש בעיבוד מרובה להפצת העומס מפחית את זמן האופטימיזציה, משפר את יעילות התהליך.
- שילוב מודולרי: גישה מודולרית מקלה על שילוב חלקי המערכות האוטומטיות לתהליכי העבודה הקיימים, מפחיתה רמת המורכבות.
- מניעת עובר הותאה: תהליך אימות חזק דרך אימות חוצת קריאה מבטיח שפרמטרים מאופטימיזים יבצעו באופן עקבי בקרב מערכות נתונים שונות, ממזער את עובר ההותאה ומשפר את הנפילות ביישומי נתונים של הלקוח.
סיכום
כדי למצטיין בביצועי חיפוש וקבלת תוצאות מהירות ומדויקות ב- Elasticsearch, על מנהלי נתונים לאמץ אסטרטגיה המשלבת הפחתת ממדים, אינדוקסינג יעיל וכיוון פרמטרים מקפיץ. על ידי שילוב שיטות אלו, מהנדסי נתונים יכולים ליצור מערכת אחזור נתונים מדויקת ומהירה לעומק. שיטות אופטימיזציה אוטומטיות מעלות את התהליך הזה, מאפשרות רפינה רצופה של פרמטרי חיפוש ושיטות אינדוקס ולצמיחה קבועה של הפרמטרים האלו. בעוד שארגונים נוספים נופלים על תוצאות בזמן אמת ממאגרי נתונים עצומים, אופטימיזציות אלו יכולות לשפר באופן משמעותי את יכולות הקבלת ההחלטות, לספק תוצאות חיפוש מהירות ונכונות יותר. אימוץ של גישה זו מצביע את הדרך לדרגת הקיבולת העתידית והתגובה המשופרת, מביא את יכולות החיפוש להתאמה לדרישות העסקיות המשתנות ולצמיחת הנתונים.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch