













מהו Elasticsearch?
Elasticsearch הוא מנוע חיפוש וניתוח מתקדם ומקיף שמבוסס על ספריית החיפוש של Apache Lucene. מיועד להתמודדות עם כמויות גדולות של נתונים מובנים, חצי מובנים ולא מובנים, מה שהופך אותו למתאים היטב למגוון רחב של שימושים, כולל מנועי חיפוש, ניתוחי יומן, אינטרנט עסקי וניתוח בקרת אבטחה.
Elasticsearch משתמש בארכיטקטורה מרוחקת המאפשרת לו לאחסן ולעבד כמויות גדולות של נתונים ברחבי קודקודים רבים בצביר. נתונים מאותחלים ומאוחסנים בשריפות, שמופצות ברחבי הקודקודים לשיפור ההיבטים של ההרחבה ושל עמידות בפני כשלים. Elasticsearch גם תומך בחיפוש וניתוח בזמן אמת, מה שמאפשר למשתמשים לשאול ולנתח נתונים בקירוב בזמן אמת.
אחת המאפיינים המרכזיים של Elasticsearch היא היכולות החזקות של החיפוש. הוא תומך במגוון רחב של שאילתות חיפוש, כולל חיפוש מלא-טקסט, חיפוש גיאומטרי וכו '. הוא גם מספק תמיכה במאפיינים ניתוח מתקדם כגון אגרגציות, מדדים והמחשת נתונים.
Elasticsearch משמש לעתים קרובות בשילוב עם כלים אחרים בעמודת Elastic, כולל Logstash לאיסוף ועיבוד נתונים ו-Kibana להמחשה וניתוח נתונים. יחד, כלי אלה מספקים פתרון מקיף לחיפוש וניתוח שניתן להשתמש בו למגוון רחב של יישומים ושימושים.
מהו Apache Lucene?
Apache Lucene הוא ספריית חיפוש עם זכויות פתוחות המספקת יכולות חזקות של חיפוש ורישום טקסט. משמשת באופן נרחב על ידי מפתחים וארגונים לבניית יישומים חיפוש בין אם זה מנועי חיפוש לפלטפורמות אלקטרוניות.
Lucene פועל על ידי רישום תוכן הטקסט של מסמכים ואחסון הרישום בפורמט מובנה שניתן לחפש בצורה יעילה. הרישום מורכב מסדרת רשימות הפוכות, המספקות מיפויים בין מונחים למסמכים שבהם הם מופיעים. כששאילתת חיפוש מוגרשת, Lucene משתמש ברישום כדי להשיג במהירות את המסמכים שמתאימים לשאילתה.
כמו כן, לLucene יש כמה תכונות מתקדמות נוספות, כולל תמיכה בחיפוש מעורפל וחיפוש מרחבי. היא גם מספקת כלים להדגמת תוצאות החיפוש ודירוג תוצאות החיפוש על פי רלוונטיות.
Lucene משמשת על ידי מספר רחב של ארגונים ופרויקטים, כולל Elasticsearch. קבוצת התכונות העשירה שלה, הגמישות והנגלה מהווה בחירה פופולרית לבניית יישומים חיפוש מכל סוג.
מהו רשימה הפוכה?
רשימה הפוכה של Lucene היא מבנה נתונים המשמש לחיפוש ורענון יעיל של נתוני טקסט מקבצי מסמכים. רשימה הפוכה היא תכונה מרכזית של Lucene, והיא משמשת לאחסון המונחים והמסמכים המשויכים להם שמרכיבים את הרישום.
האינדקס ההפוך מספק מספר יתרונות על פני אסטרטגיות חיפוש אחרות. ראשית, הוא מאפשר שליפה מהירה ויעילה של מסמכים על פי מונחי חיפוש. שנית, הוא יכול להתמודד עם כמות גדולה של נתוני טקסט, מה שהופך אותו למתאים מאוד למקרים של שימוש בקולקציות גדולות של מסמכים. לבסוף, הוא תומך במגוון רחב של תכונות חיפוש מתקדמות, כגון התאמה עקיפה וסטמינג, שיכולות לשפר את הדיוק והרלוונטיות של תוצאות החיפוש.
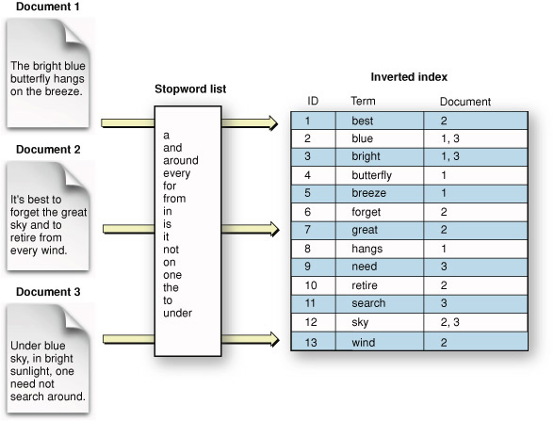
למה Elasticsearch?
יש מספר סיבות מדוע Elasticsearch הוא בחירה פופולרית לבניית יישומים של חיפוש וניתוחים:
קל להתרחב (מרובד): Elasticsearch מוקמה כדי להתרחב אופקית מיידית. כשאתה זקוק להגדלת קיבולת, פשוט הוסף עוד צמדים, ותן להם להתארגן מחדש כדי לנצל את החומרה הנוספת.
שרת אחד יכול להחזיק בחלק אחד או יותר מאחד או יותר מהאינדקסים, ובכל פעם שמוסיפים צמדים חדשים לצביר, הם פשוט מוסיפים למסיבה. כל אינדקס כזה, או חלק ממנו, נקרא גרף, וגרפים של Elasticsearch יכולים לנוע ברחבי הצביר בקלות.
הכל במרחק קריאת JSON אחת (API RESTful): Elasticsearch מבוסס על API. כמעט כל פעולה יכולה להתבצע באמצעות API פשוט RESTful באמצעות JSON מעל HTTP. התשובות תמיד בפורמט JSON.
כוח השחרור של Lucene מתחת למכסה: Elasticsearch משתמש ב-Lucene באופן פנימי כדי לבנות את יכולות החיפוש והאナליטיקה המתקדמות ביותר שלו. מאחר ש-Lucene היא טכנולוגיה יציבה ומוכחת וממשיכה להוסיף עוד תכונות ומומחיות מיטביות, בעלת Lucene כמנוע הבסיסי שמניע את Elasticsearch.
שפת שאילתא DSL מצוינת: חיבור REST מחשיף DSL שאילתא מאוד מורכבת ויכולתית שקל להשתמש בה. כל שאילתא היא עצם JSON שיכולה להכיל כמעט כל סוג של שאילתא או אפילו מספרים מורכבים שלהם ביחד. שימוש בשאילתות מ филטרים, עם חלק מהשאילתות מבוטאות כ-Lucene מסננים, עוזר למנף את הזיכוי מקשים וכך להאיץ את השאילתות הנפוצות או המורכבות עם חלקים שניתן לשימוש חוזר.
מסד נתונים מרובת תושבים: ניתן לאחסן מסדי נתונים מרובים בממשק אחד של Elasticsearch – צומת או קבוצה. הדבר הנחמד הוא שניתן לבדוק מסדי נתונים מרובים עם שאילתא פשוטה אחת.
תמיכה בתכונות חיפוש מתקדמות (מלא טקסט): Elasticsearch משתמש ב-Lucene מתחת למכסה כדי לספק את היכולות המלאות ביותר בחיפוש טקסט שקיימות במוצר פתוח לכלל הציבור. החיפוש מגיע עם תמיכה רב-שפתית, שפה של שאילתא חזקה, תמיכה במיקום גיאוגרפי, הצעות מהסוג "האם רצית לומר", מלשון מוכנה ונספחי חיפוש. תמיכה בסקריפטים במסננים ובמדריכים.
התאמה והרחבה ניתנים להגדרה: רבים מההתאמות של Elasticsearch יכולים להשתנות תוך כדי שימוש ב-Elasticsearch, אך חלקם ידרשו הפעלה מחדש (ובמקרים מסוימים, רידקסינג). רוב ההתאמות ניתן לשנות באמצעות חיבור REST גם כן.
מסמך מוקצב: שמור ישויות מציאותיות מורכבות ב-Elasticsearch כמסמכים JSON מובנים. כל השדות מאותחלים כברירת מחדל, וכל האינדקסים יכולים לשמש בשאילתה יחידה כדי להחזיר תוצאות במהירות מרגשת.
חופשי תבניות: Elasticsearch מאפשר לך להתחיל בקלות. שלח מסמך JSON, וזה ינסה לזהות את מבנה הנתונים, לאסוף את הנתונים, ולהפוך אותם לניתנים לחיפוש.
ניהול סכסוכים: שליטה אופטימית בגירסאות יכולה לשמש במקומות הנחוצים כדי להבטיח שהנתונים לעולם לא יאבדו בגלל שינויים קונפליקטים ממספר תהליכים.
קהילה פעילה: הקהילה, חוץ מיצירת כלים נחמדים ותוספות, מאוד עוזרת ותומכת. ההרגשה הכוללת היא נהדרת, וזה מדד חשוב של כל פרויקט ספירת קוד. יש גם כמה ספרים שנכתבו כרגע על ידי חברי הקהילה והרבה פוסטים בלוג ברשת המשתפים חוויות וידע.
ארכיטקטורת Elasticsearch
הרכיבים העיקריים של ארכיטקטורת Elasticsearch הם:
צומת: צומת הוא משתנה של Elasticsearch המאחסן נתונים ומספק יכולות חיפוש וגיבוי. ניתן להגדיר צמתים להיות או צמתי מאסטר או צמתי נתונים, או גם מאסטר וגם נתונים. צמתי מאסטר אחראים לניהול ממוקד ברחבי המוקד, וצמתי נתונים מאחסנים את הנתונים ומבצעים פעולות חיפוש.
מוקד: מוקד הוא קבוצה של צמתים אחד ויותר העובדים יחד כדי לאחסן ולעבד נתונים. מוקד יכול להכיל מספר אינדקסים (אוספי מסמכים) וממדים (דרך לחלוקת נתונים ברחבי מספר צמתים).
אינדקס: אינדקס הוא אוסף של מסמכים המשתפים מבנה דומה. כל מסמכ מיוצג כאובייקט JSON ומכיל שדה אחד או יותר. Elasticsearch מאכסן את כל השדות כברירת מחדל, מה שמקל על החיפוש והניתוח של הנתונים.
שברים: אינדקס יכול להיות מחולק למספר שברים, שהם למעשה תת-קבוצות קטנות יותר של האינדקס. שיטת השבירה מאפשרת עיבוד מקבילי של הנתונים ואחסון מרוחק במספר קטגוריות.
עותקים: Elasticsearch יכול ליצור עותקים של כל שביר כדי לספק עמידות בפני תקלות וגישה גבוהה למוצקים. העותקים הם עותקים של השביר המקורי ויכולים להיות ממוקמים בקטגוריות שונות.
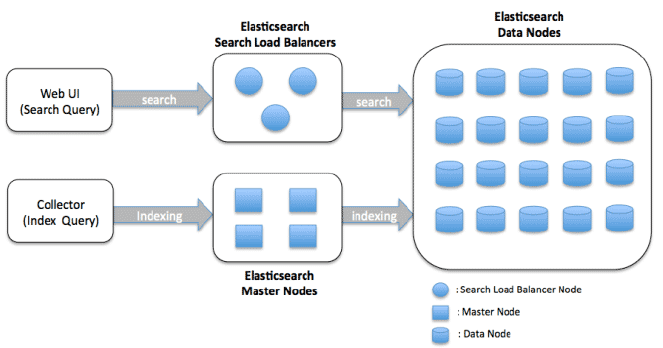
ארכיטקטורת קבוצת קטגוריית נתונים
קטגוריות הנתונים אחראיות לאחסון ועיבוד נתונים, כמו גם פעילויות חיפוש ואגרגציה. הארכיטקטורה מיועדת להיות מתקדמת ומרוחקת, מה שמאפשר קיבולת אופקית על ידי הוספת קטגוריות נוספות לקבוצה.
הנה הרכיבים העיקריים של ארכיטקטורת קבוצת קטגוריית נתונים של Elasticsearch:
קטגוריית נתונים: קטגורייה היא מופע של Elasticsearch המאחסן נתונים ומספק יכולות חיפוש ועיבוד. בקבוצת קטגוריית הנתונים, כל קטגורייה אחראית לאחסון חלק מנתוני האינדקס ולשרת שאילתות חיפוש נגד הנתונים שם.
מצב הקבוצה: מצב הקבוצה הוא מבנה נתונים המחזיק מידע על הקבוצה, כולל רשימת הקטגוריות, האינדקסים, השברים ומיקומם. הקטגורייה הראשית אחראית לשמירת מצב הקבוצה ולהפיץ אותו לכל קטגוריות אחרות בקבוצה.
גילוי והעברת נתונים: צמתים בטבעת Elasticsearch מתקשרים זה עם זה בשתי שיטות: גילוי והעברת נתונים. שיטת הגילוי אחראית לגילוי צמתים חדשים המצטרפים לטבעת או צמתים שעזבו את הטבעת. שיטת ההעברת נתונים אחראית לשליחת וקבלת נתונים בין צמתים.
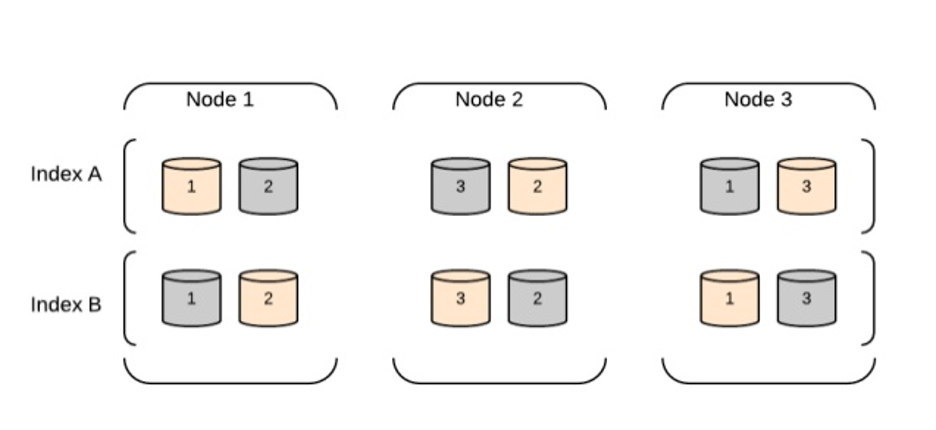
בקשת אינדקס
בקשת אינדקס מבוצעת כפי שמוצג בתרשים הבלוקים ב-Elasticsearch.
מי משתמש ב-Elasticsearch?
כמה חברות וארגונים המשתמשים ב-Elasticsearch:
Netflix: Netflix משתמש ב-Elasticsearch כדי להפעיל את מנוע החיפוש וההמלצות שלה, מה שמאפשר למשתמשים למצוא במהירות תוכן לצפייה.
GitHub: GitHub משתמש ב-Elasticsearch כדי לספק יכולות חיפוש מהירות ויעילות ברחבי המאגרי הקוד שלהם, הבעיות ובקשות המשאבה.
Uber: Uber משתמש ב-Elasticsearch כדי להפעיל את פלטפורמת האנליטיקה בזמן אמת שלהם, מה שמאפשר להם לעקוב ולנתח נתונים על שירות ההסעות שלהם בזמן אמת.
ויקיפדיה: ויקיפדיה משתמשת ב-Elasticsearch כדי להפעיל את מנוע החיפוש שלה ולספק תוצאות חיפוש מהירות ומדויקות למשתמשים.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1