













מהו JPA Hibernate?
Hibernate הוא אחד המבוססי האובייקט-מיפוי ריאליים (ORM) הפופולריים ביותר עבור יישומים Java ו-Spring. הוא עוזר למפתחים להתחבר ולעבוד עם מסדי נתונים ריאליים מיישומים Java מבלי שיהיו צריכים לכתוב שאילתות SQL. הספרייה מיושמת את המגדר JPA (Java Persistence API) ומספקת מספר תכונות נוספות המאפשרות לפתח את הקבצה ביישומים מהר יותר ויותר קל.
קישון ב-JPA Hibernate
אחת התכונות המגניבות שמתומכת על ידי Hibernate היא קישון. Hibernate תומך בשני רמות קישון – L1 ו-L2. קישון L1 מופעל כברירת מחדל ופועל בתוך תחום יישום, כך שאינו יכול לשתף בין קווי עבודה מרובות. לדוגמה, אם יש לך יישום מיקרוסרף מוגדל שקורא וכותב לשולחן בסטודיו של מסדי נתונים ריאליים, קישון L1 זה נשמר באופן בלתי תלוי בכל אחד מהמכוניות אליהן פועל המיקרוסרף.
קישון L2 הוא ממשק חיצוני נספחי, שבאמצעותו אנו יכולים לקלטט נתונים שנגישים לעיתים קרובות בספק קישון חיצוני דרך Hibernate. במקרה זה, הקישון נשמר מחוץ לספינת המזון ויכול להיות שיתוף במסד המיקרוסרף (בדוגמה לעיל).
Hibernate תומך בקישון L2 עם רוב ספקי הקישון הפופולריים כמו Redis, Ignite, NCache וכד'.
מהו NCache?
NCache הוא אחד המסחריים הנפוצים ביותר של מפתחות הזכרון המרוחק הזמינים בשוק. הוא מציע מספר תכונות ותומך בשילוב עם ערימות התכנות הפופולריות כמו .NET, Java וכד'.
NCache מגיע בכמה טעמים – בחינם, מקצועי וארגוני ותוכלו לבחור מבין אלה על פי התכונות שהם מציעים.
שילוב NCache עם Hibernate
NCache תומך בשילוב עם Hibernate כמו זיכרון L2 וגם לצורך זיכרון שאילתות. על ידי שימוש בשידור מרובע חיצוני של זיכרון מרוחק, אנו יכולים להבטיח שהיגויים הנצפים לעיתים קרובות ייזכרו ויימשכו בין המיקרוסרביס בסביבה מוגדלת ללא הטענה הבלתי רצויה על שכבת המסד הנתונים. בדרך זו, קריאות המסד הנתונים משמרים כמעט ככל האפשר, והביצועים של היישום מותאמים גם כן.
כדי להתחיל, בואו נוסיף את החבילות ה החובה לפרויקט הרגיסט המתוכנן שלנו. כדי להדגים, אני הולך עם מאגר JPA שמשתמש ב- Hibernate ORM לעבוד עם מסד הנתונים הרלטיוניסטי – הגדרת MySQL.
הסמיכות בקובץ pom.xml שלי נראות ככה:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>המאגר JPARepository שלי קורא וכותב לשולחן בשם ספרים במסד הנתונים של MySQL שלי. המאגר והיגוי נראים כדלקמן:
package com.myjpa.helloapp.repositories;
import com.myjpa.helloapp.models.entities.Book;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BookRepository extends JpaRepository<Book, Integer> {}
package com.myjpa.helloapp.models.entities;
import jakarta.persistence.*;
import java.util.Date;
import org.hibernate.annotations.CreationTimestamp;
@Entity(name = "Book")
@Table(name = "Book")
public class Book {
@Id @GeneratedValue(strategy = GenerationType.AUTO) private int bookId;
@Column(name = "book_name") private String bookName;
@Column(name = "isbn") private String isbn;
@CreationTimestamp @Column(name = "created_date") private Date createdDate;
public Book() {}
public Book(String bookName, String isbn) {
this.bookName = bookName;
this.isbn = isbn;
}
public int getBookId() {
return bookId;
}
public String getBookName() {
return bookName;
}
public String getIsbn() {
return isbn;
}
public Date getCreatedDate() {
return createdDate;
}
}A BookService interacts with this repository and exposes GET and INSERT functionalities.
package com.myjpa.helloapp.services;
import com.myjpa.helloapp.models.entities.Book;
import com.myjpa.helloapp.repositories.BookRepository;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class BookService {
@Autowired
private BookRepository repository;
public int createNew(String bookName, String isbn) {
var book = new Book(bookName, isbn);
// לשמור את היגוי
repository.save(book);
// לגבות את השינויים
repository.flush();
// להחזיר את המזהה שנוצר
var bookId = book.getBookId();
return bookId;
}
public Book findBook(int id) {
var entity = repository.findById(id);
if (entity.isPresent()) {
return entity.get();
}
return null;
}
}בעוד שהסט הזה עובד בצורה מושלמת, עדיין לא הוספנו שימוש בזיכרון חצי. בואו נראה איך ניתן לשלב זיכרון חצי עם Hibernate באמצעות NCache כמתודת הפסקל.
זיכרון רמה 2 עם NCache
כדי לשלב את NCache עם Hibernate, נוסיף שתי תלות נוספות לפרויקט שלנו. אלה מוצגים להלן:
<dependency>
<groupId>com.alachisoft.ncache</groupId>
<artifactId>ncache-hibernate</artifactId>
<version>5.3.2</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jcache</artifactId>
<version>6.4.2.Final</version>
</dependency>נוסיף גם קובץ Hibernate.cfg.xml שבו נקבע את זיכרון הרמה השנייה ופרטים נמצאים להלן:
<hibernate-configuration>
<session-factory>
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.region.factory_class">JCacheRegionFactory</property>
<property name="hibernate.javax.cache.provider" >com.alachisoft.ncache.hibernate.jcache.HibernateNCacheCachingProvider</property>
<property name="ncache.application_id">booksapi</property>
</session-factory>
</hibernate-configuration>מעל הישות Book, נוסיף הערה שתקבע את סטטוס הזיכרון עבור הישות:
@Entity(name = "Book")
@Table(name = "Book")
@Cache(region = "demoCache", usage = CacheConcurrencyStrategy.READ_WRITE)
public class Book {}I’m indicating that my entities will be cached under the region demoCache, which is basically my cache cluster name.
I’d also place my client.nconf and config.nconf files, which contain information about the cache cluster and its network details in the root directory of my project.
קובץ client.nconf נראה ככה:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Client configuration file is used by client to connect to out-proc caches.
Light weight client also uses this configuration file to connect to the remote caches.
This file is automatically generated each time a new cache/cluster is created or
cache/cluster configuration settings are applied.
-->
<configuration>
<ncache-server connection-retries="5" retry-connection-delay="0" retry-interval="1"
command-retries="3" command-retry-interval="0.1" client-request-timeout="90"
connection-timeout="5" port="9800" local-server-ip="192.168.0.108" enable-keep-alive="False"
keep-alive-interval="0" />
<cache id="demoCache" client-cache-id="" client-cache-syncmode="optimistic"
skip-client-cache-if-unavailable="False" reconnect-client-cache-interval="10"
default-readthru-provider="" default-writethru-provider="" load-balance="True"
enable-client-logs="True" log-level="info">
<server name="192.168.0.108" />
</cache>
</configuration>כשאני מריץ את היישום שלי עם הסט הזה ומבצע GET פעולה עבור ספר אחד, Hibernate מחפש את הישות בשרת NCache ומחזיר את הישות המאוחסנת בזיכרון; אם היא איננה קיימת, זה מראה פגיעה בזיכרון.
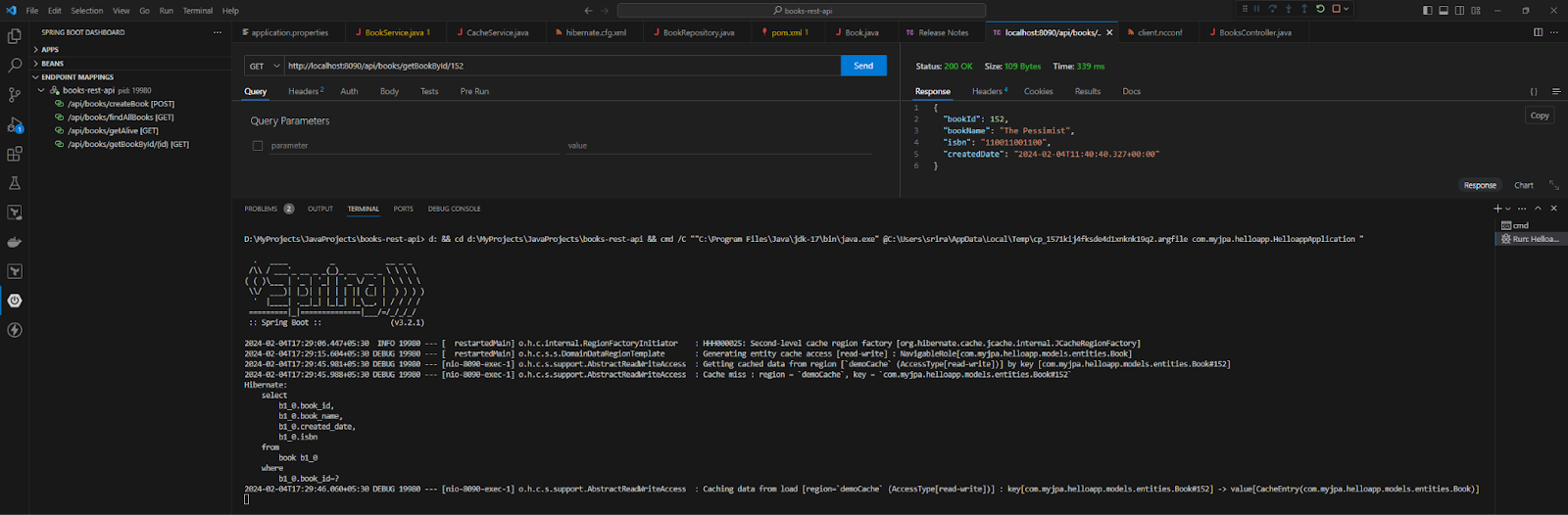
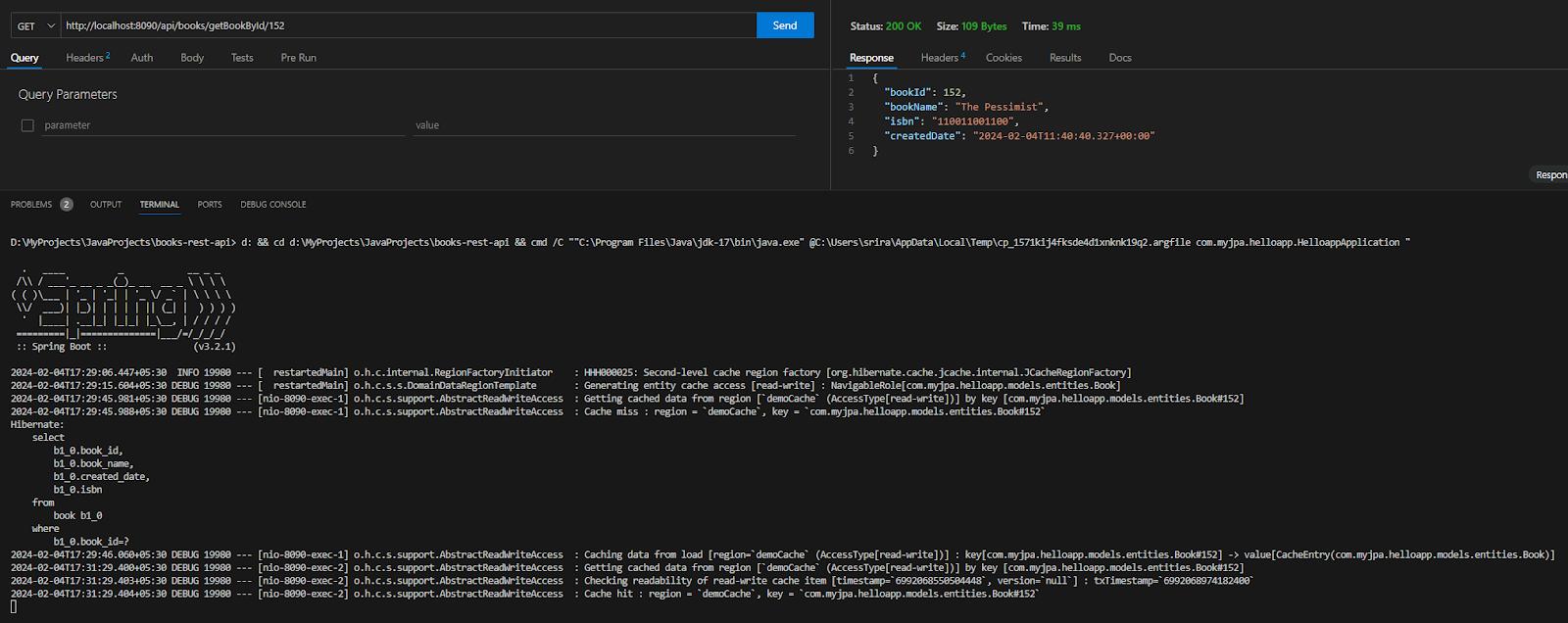
זיכרון שאילתות עם NCache
עוד תכונה של Hibernate שNCache תומך בה לחלוטין היא זיכרון שאילתות. בגישה זו, מערך התוצאות של שאילתה ניתן לאחסון עבור נתונים שנגישים לעתים קרובות. זה מבטיח שהמסד הנתונים לא נבדק לעתים קרובות עבור נתונים שנגישים לעתים קרובות. זה ספציפי לשאילתות HQL (שפת השאילתות של Hibernate).
לאפשר את מטלת הקישורים, אני פשוט אוסיף שורה נוספת ל-Hibernate.cfg.xml מתחת:
<property name="hibernate.cache.use_query_cache">true</property>במאגר הקוד, הייתי יוצר שיטה נוספת שתפעיל שאילתה ספציפית, והתוצאה תימצא בזיכרון.
@Repository
public interface BookRepository extends JpaRepository<Book, Integer> {
@Query(value = "SELECT p FROM Book p WHERE bookName like 'T%'")
@Cacheable(value = "demoCache")
@Cache(usage = CacheConcurrencyStrategy.READ_ONLY, region = "demoCache")
@QueryHints(value = { @QueryHint(name = "org.hibernate.cacheable", value = "true") })
public List<Book> findAllBooks();
}בשיטה זו, אני מחפש את כל הספרים שמתחילים באות T, והסט התוצאות צריך להישמר בזיכרון. לשם כך, אוסיף רמז שאילתה שיקבע את הזיכרון לאמת.
כשאנו פונים ל-API שקורא לשיטה זו, אנו יכולים לראות שכל ערכת הנתונים כעת מקושרת.
מסקנה
זיכרון הוא אחד האסטרטגיות הנפוצות ביותר בבניית יישומים מורכבים. בארכיטקטורת מיקרוסרביס, שבה יישום אחד מוכפל X פעמים בהתאם לעומס, הפגיעה התדירה במסד הנתונים עבור נתונים יכולה להיות יקרה.
ספקי זיכרון כמו NCache מספקים פתרון קל ונצנץ לשירותים מיקרוסרביס ב-Java שמשתמשים ב-Hibernate לשאילתות במסדי נתונים. במאמר זה, ראינו כיצד להשתמש ב-NCache כ-זיכרון רמה 2 עבור Hibernate ולהשתמש בו לזיכרון יחידים ולזיכרון שאילתות.
Source:
https://dzone.com/articles/how-to-integrate-ncache-with-jpa-hibernate-for-cac