













כִּיווּן: כל הדעות והחוויות המובאות בבלוג שייכות בלעדית למחבר ולא בהכרח למעסיק של המחבר או לקבוצה או אדם אחר. מאמר זה אינו קידום לפלטפורמת ניהול עננים/נתונים כלשהי. כל התמונות וממשקי ה- API זמינים לציבור באתר של Azure/Databricks.
מה זה ניטור Lakehouse של Databricks?
במאמרי אחרים, תיארתי מהו Databricks וקטלוג Unity וכיצד ליצור קטלוג מאפס באמצעות סקריפט. במאמר זה, אתן את תיאור תכונת ניטור Lakehouse הזמינה כחלק מהפלטפורמה Databricks וכיצד להפעיל את התכונה באמצעות סקריפטים.
ניטור Lakehouse מספק פרופיל נתונים ומדדי איכות נתונים עבור Delta Live Tables ב-Lakehouse. ניטור Lakehouse של Databricks מספק תובנה מקיפה בנתונים כגון שינויים בנפח הנתונים, שינויים בהפצת מספרית, % של ערכים ריקים ואפסים בעמודות, וזיהוי חריגויות קטגוריות לאורך זמן.
למה להשתמש בניטור Lakehouse?
מעקב אחר הנתונים שלך וביצועי המודל ML מספק מדדים כמותיים שעוזרים לך לעקוב ולאשר את איכותם וההתאמה של הנתונים ושל ביצועי המודל שלך לאורך הזמן.
הנה פירוט של התכונות העיקריות:
- מעקב אחר איכות הנתונים ושלמותם: מעקב אחר זרימת הנתונים במערכות השיגור, בטיחות הנתונים והצגת האורה על איך הנתונים השתנו לאורך הזמן, אחוזים של עמודות מספריות, % של עמודות ריקות ועמודות בערך אפס, וכו'.
- שינויים בנתונים לאורך הזמן: מספק מדדים לזיהוי שינויים בנתונים בין הנתונים הנוכחיים לבסיס ידוע, או בין חלונות זמן רצופים של הנתונים
- הפצת נתונים סטטיסטית: מספק שינוי בהפצה מספרית של הנתונים לאורך הזמן שעונה על השאלה מהו חלוקת הערכים בעמודה קטגוריאלית ואיך זה שונה מהעבר
- ביצועי המודל ML ושינויים בחיזוי: קלטי מודל ML, חיזויים, ומגמות ביצועים לאורך הזמן
איך זה עובד
מעקב אחר האגם של Databricks מספק את סוגי הניתוח הבאים: שורות זמן, צילום, והסקה.
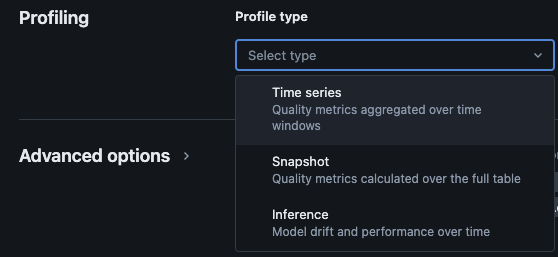
סוגי פרופיל למעקב
כאשר אתה מפעיל ניטור Lakehouse עבור טבלה בקטלוג האחידות, הוא יוצר שתי טבלאות בסכמת הניטור המוגדרת. אתה יכול לשאול וליצור לוחות מחוונים (Databricks מספקת לוח מחוונים ברירת מחדל שניתן להגדיר אותו מהקופסה) והודעות על הטבלאות כדי לקבל מידע סטטיסטי ומידע פרופיל מקיף על הנתונים שלך לאורך זמן.
- טבלת מדדי סטיית תקן: טבלת מדדי הסטייה מכילה סטטיסטיקות הקשורות לסטיית הנתונים לאורך זמן. היא קולטת מידע כגון הבדלים בספירה, ההבדל בממוצע, ההבדל באחוזים של ערכים ריקים ואפסים וכו'.
- טבלת מדדי פרופיל: טבלת מדדי הפרופיל מכילה סטטיסטיקות סיכום עבור כל עמודה ועבור כל שילוב של חלון זמן, חיתוך ועמודות קבוצות. עבור ניתוח InferenceLog, טבלת הניתוח מכילה גם מדדי דיוק מודל.
איך להפעיל ניטור Lakehouse דרך סקריפטים
דרישות מוקדמות
- קטלוג האחידות, סכימה וטבלאות Delta Live קיימות.
- המשתמש הוא הבעלים של טבלת Delta Live.
- עבור אשכולות Azure Databricks פרטיים, חיבור פרטי מחשבון ללא שרת מוגדר.
שלב 1: צור מחברת והתקן את SDK של Databricks
צור מחברת בסביבת העבודה של Databricks. כדי ליצור מחברת בסביבת העבודה שלך, לחץ על "+" חדש בסרגל הצד, ואז בחר מחברת.
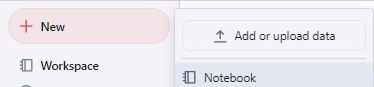
מחברת ריקה נפתחת בסביבת העבודה. ודא שPython נבחר כשפת המחברת.
העתק והדבק את קטע הקוד למטה לתוך תא המחברת והרץ את התא.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
שלב 2: צור משתנים
העתק והדבק את קטע הקוד למטה לתוך תא המחברת והרץ את התא.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
שלב 3: צור סכמת ניטור
העתק והדבק את קטע הקוד למטה לתוך תא המחברת והרץ את התא. קטע זה ייצור את סכמת הניטור אם היא לא קיימת כבר.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
שלב 4: צור ניטור
העתק והדבק את קטע הקוד למטה לתוך תא המחברת והרץ את התא. קטע זה ייצור ניטור Lakehouse עבור כל הטבלאות בתוך הסכמה.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
אימות
לאחר שהסקריפט רץ בהצלחה, תוכל לנווט לקטלוג -> סכמה -> טבלה ולעבור ללשונית "איכות" בטבלה כדי לראות את פרטי הניטור.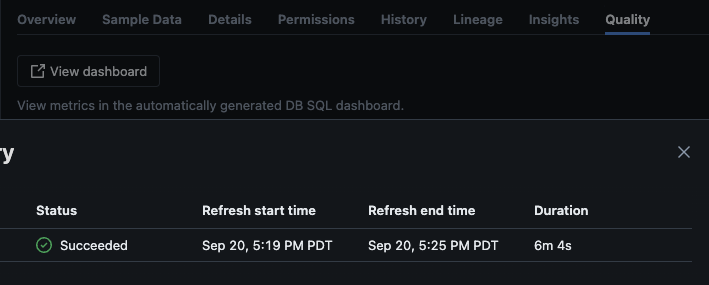
כאשר אתה לוחץ על כפתור "הצג לוח בקרה" בפינה השמאלית העליונה של עמוד ניטור, הלוח בקרה ברירת המחדל ייפתח. בהתחלה, הנתונים יהיו ריקים. ככל שהניטור רץ על הלוח זמנית, במהלך הזמן הוא ימלא את כל הערכים הסטטיסטיים, הפרופיל ואיכות הנתונים.
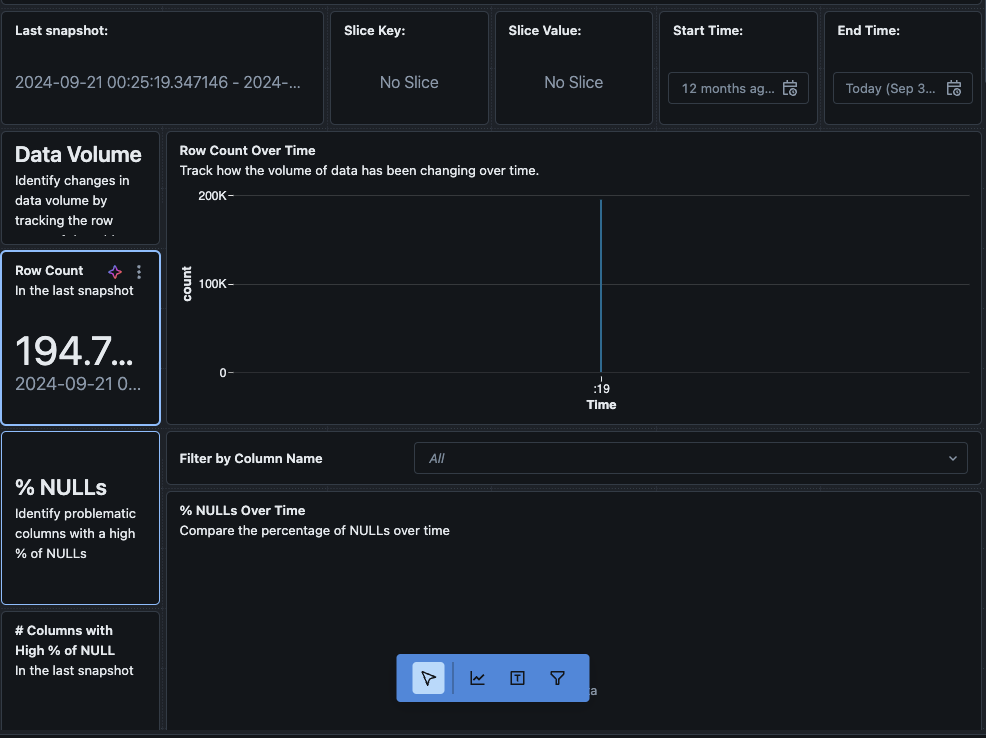
בנוסף, ניתן לנווט לכרטיסיית "נתונים" בלוח הבקרה. Databricks מספקת מראש רשימת שאילתות כדי לקבל את הנטיית הנתונים ומידע פרופיל נוסף. ניתן גם ליצור שאילתות משלך על פי הצורך כדי לקבל תצוגה מקיפה של הנתונים שלך במהלך הזמן. 
מסקנה
ניטור Lakehouse של Databricks מציע דרך מובנית לעקוב אחר איכות הנתונים, למדדי פרופיל ולזהות שינויים בנתונים במהלך הזמן. על ידי הפעלת תכונה זו דרך סקריפטים, צוותים יכולים להשיג תובנות בהתנהגות הנתונים ולהבטיח את אמינות צינורות הנתונים שלהם. התהליך של ההתקנה המתואר במאמר זה מספק בסיס לשמירה על תקינות הנתונים ולתמוך במאמצי ניתוח נתונים רציניים.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring