













בחלק 1, כיסינו מספר נושאים מרכזיים. אני ממליץ לך לקרוא אותו, מכיוון שהחלק הבא מתבסס עליו.
כסקירה מהירה, בחלק 1, בחנו את הנתונים שלנו מנקודת מבט כוללת והבדלנו בין נתונים בפנים ונתונים בחוץ. גם דנו בסכמות וחוזים נתונים ואיך הם מספקים את האמצעים לנהל, לשנות ולפתח את הזרמים שלנו לאורך זמן. סופית, כיסינו סוגי אירועים עובדה (מצב) ודלתא. אירועי עובדה הם הכי טובים לתקשורת מצב והפרדת מערכות, בעוד שאירועי דלתא נטפלים יותר לנתונים בפנים, כמו במקור אירועים ומקרים אחרים של חיבור צפוף.
טבלאות נרמלות יוצרות זרמים נרמלים
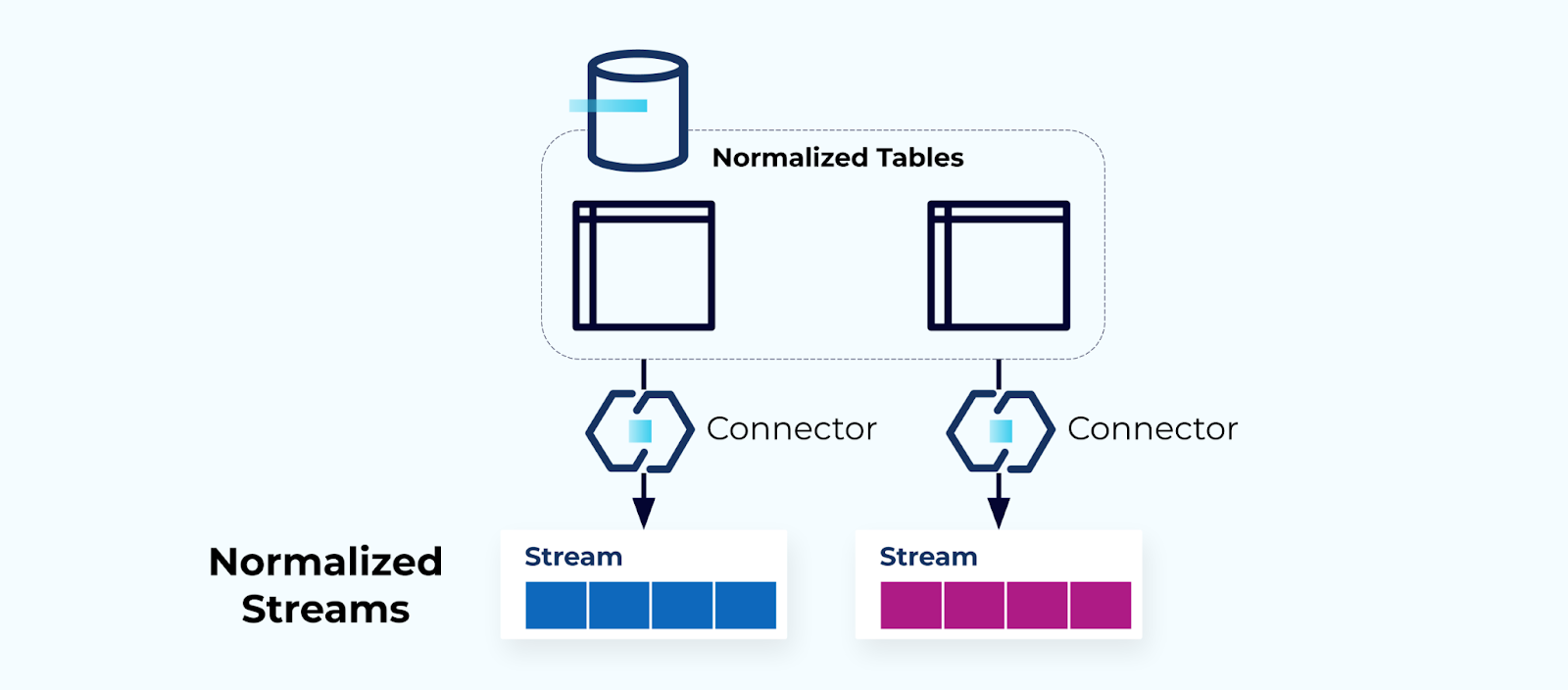
טבלאות נרמלות מובילות לזרמי אירועים נרמלים. קונקטורים (למשל, CDC) מוציאים נתונים ישירות מהמסד נתונים לקבוצה מרוקעת של זרמי אירועים. זה לא אידיאלי, מכיוון שהוא יוצר חיבור חזק בין הטבלאות הפנימיות של המסד נתונים והזרמי אירועים החיצוניים.
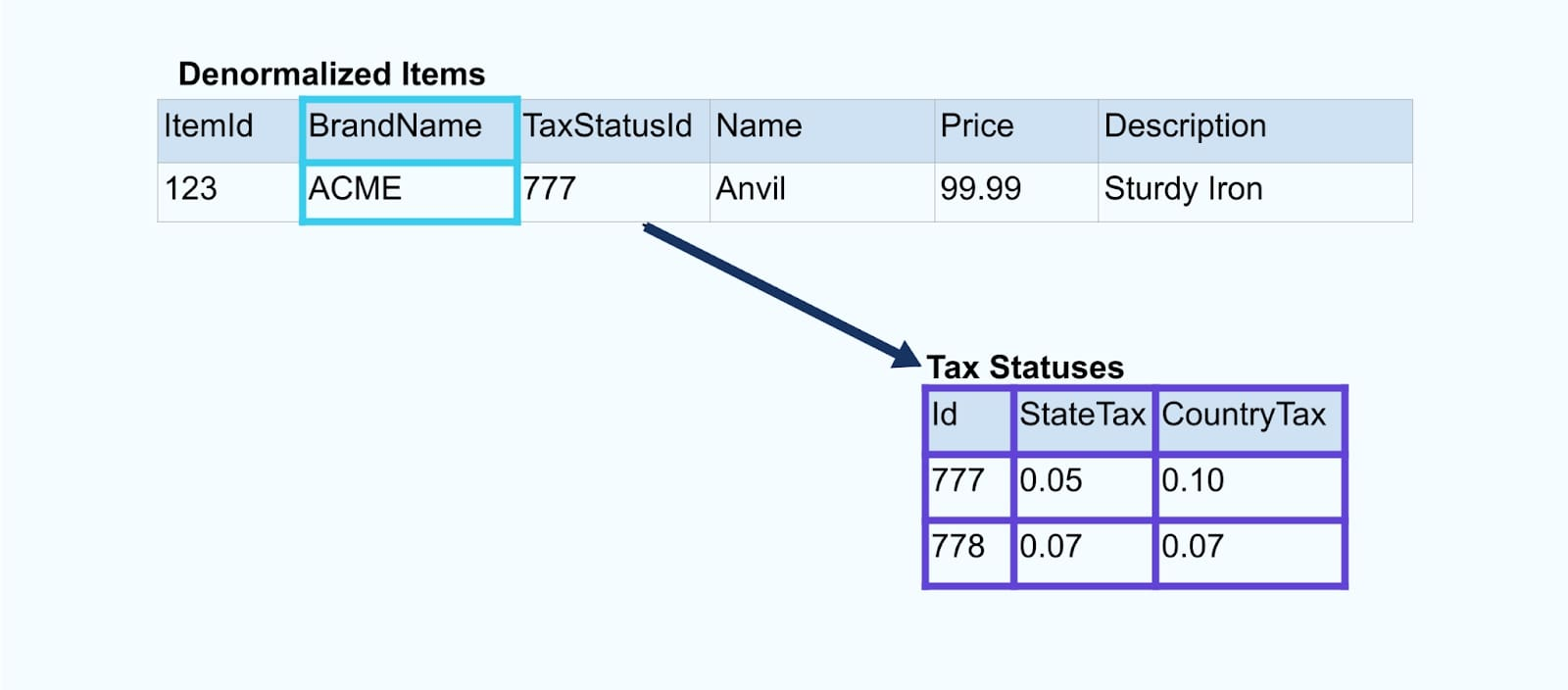
נשקול פשוט אתר קמעונאות פריט והטבלאות המשויכות אליו של מותג ומעמד מס.
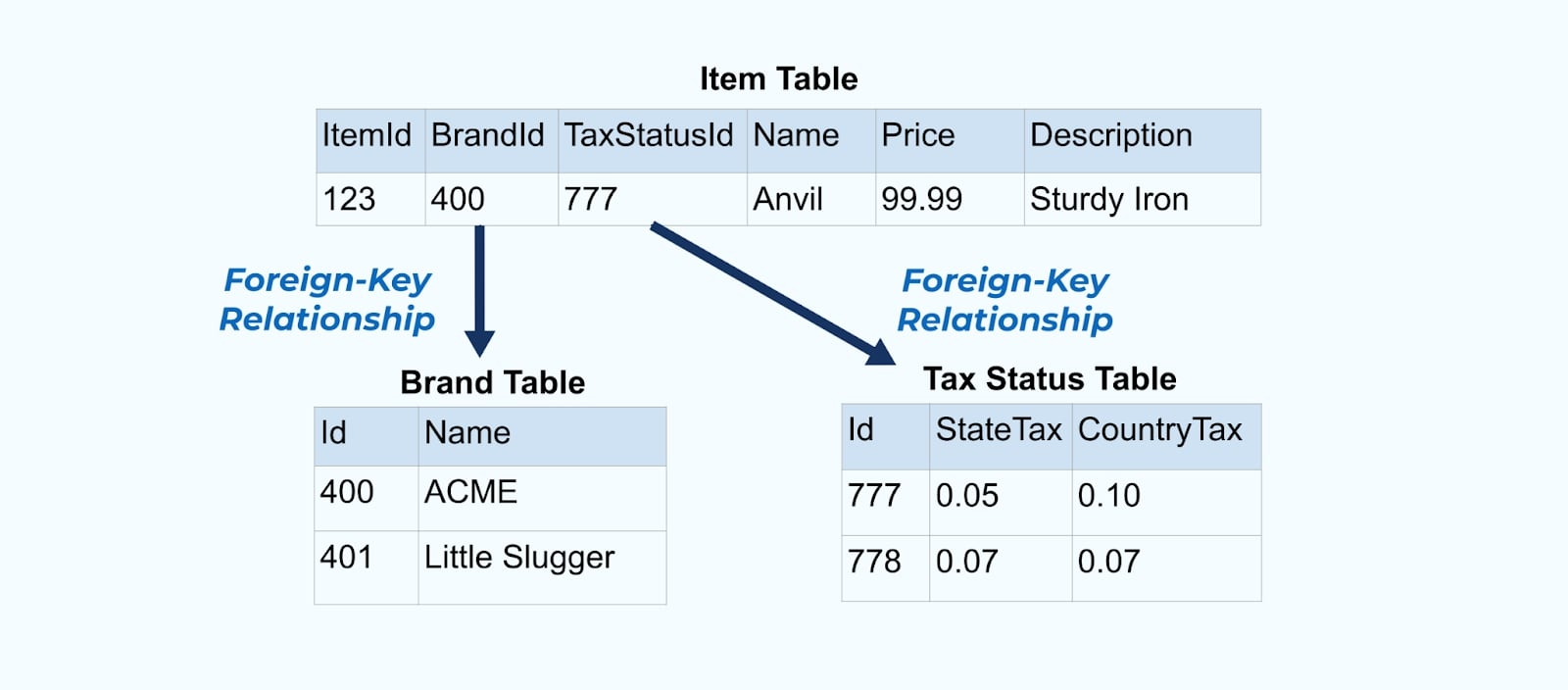
הטבלאות מותג ומעמד מס קשורות לטבלת פריט דרך יחסי מפתח זר. בעוד שאנו מראים רק פריט אחד בטבלה, סביר להניח שיהיו לך אלפים (או מיליונים), תלוי במוצרים שאתה מוכר.
זה נפוץ להגדיר קונקטור עבור כל טבלה, לשלוף את הנתונים מהטבלה, להרכיב אותם לאירועים, ולכתוב כל טבלה לזרם אירועים מיועד.
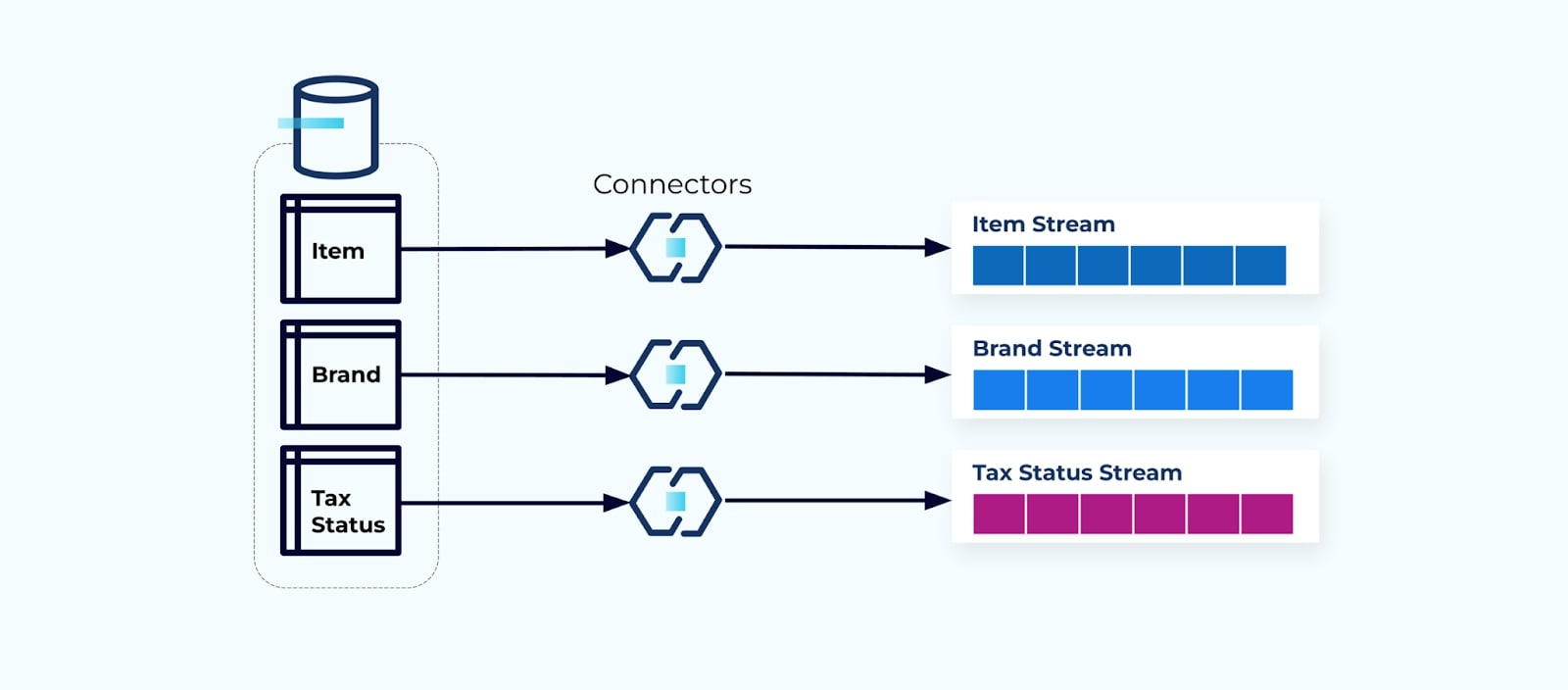
חשיפת הטבלאות התחתונות במסד הנתונים מובילה לזרם אירועים מתאים עבור כל טבלה. בעוד שקל להתחיל בדרך זו, זה מוביל למספר בעיות, שניתן לסכמן כבעיית צימוד או בעיית עלות או. הבה נבחן כל אחת.
בעיה: הצרכנים מצמדים למודל הפנימי
חשיפת טבלת המקור פריט כמו שהיא מכריחה את הצרכנים להצמיד את עצמם ישירות אליה. שינויים במודל הנתונים של מערכת המקור ישפיעו על הצרכנים במורד הזרם.
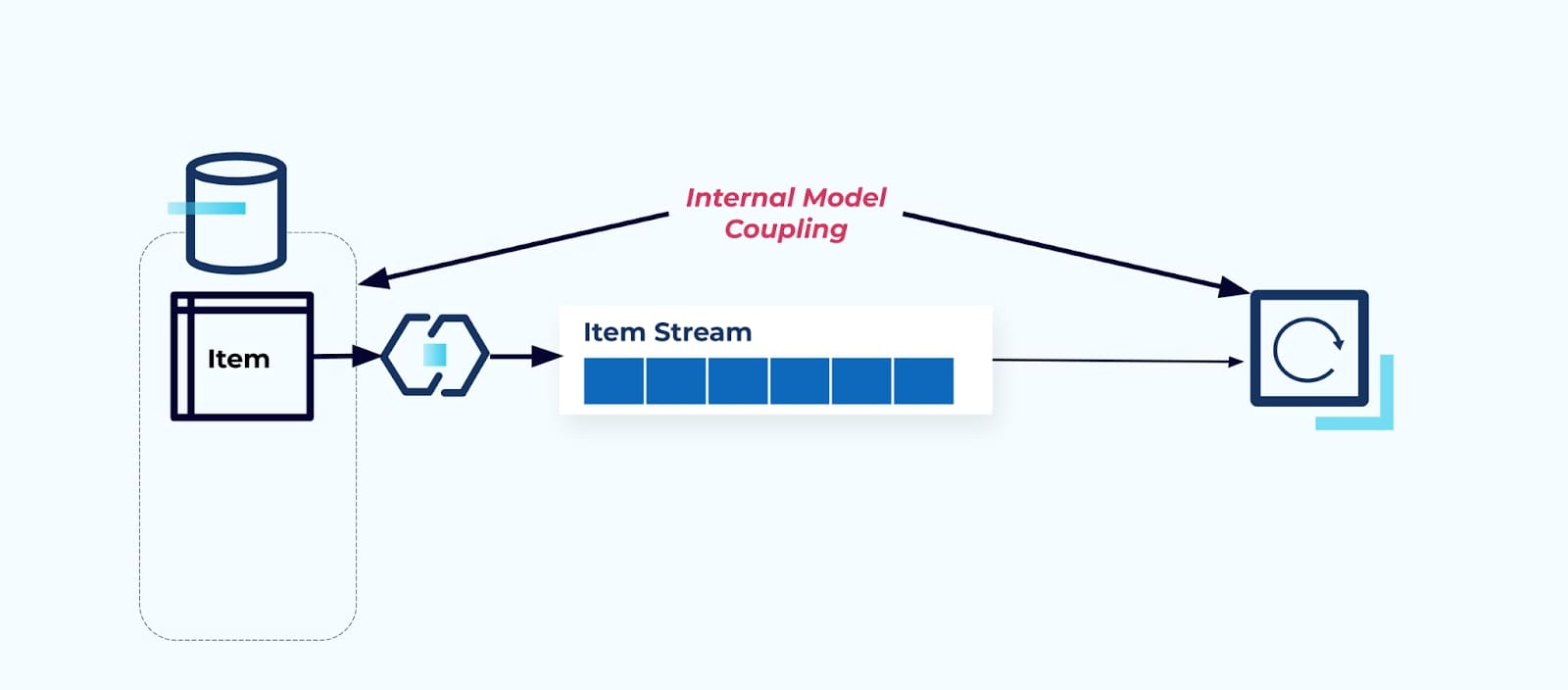
נניח שאנו משנים את טבלת פריט כדי למצות את מחירולהפרידו לטבלה נפרדת שלו.
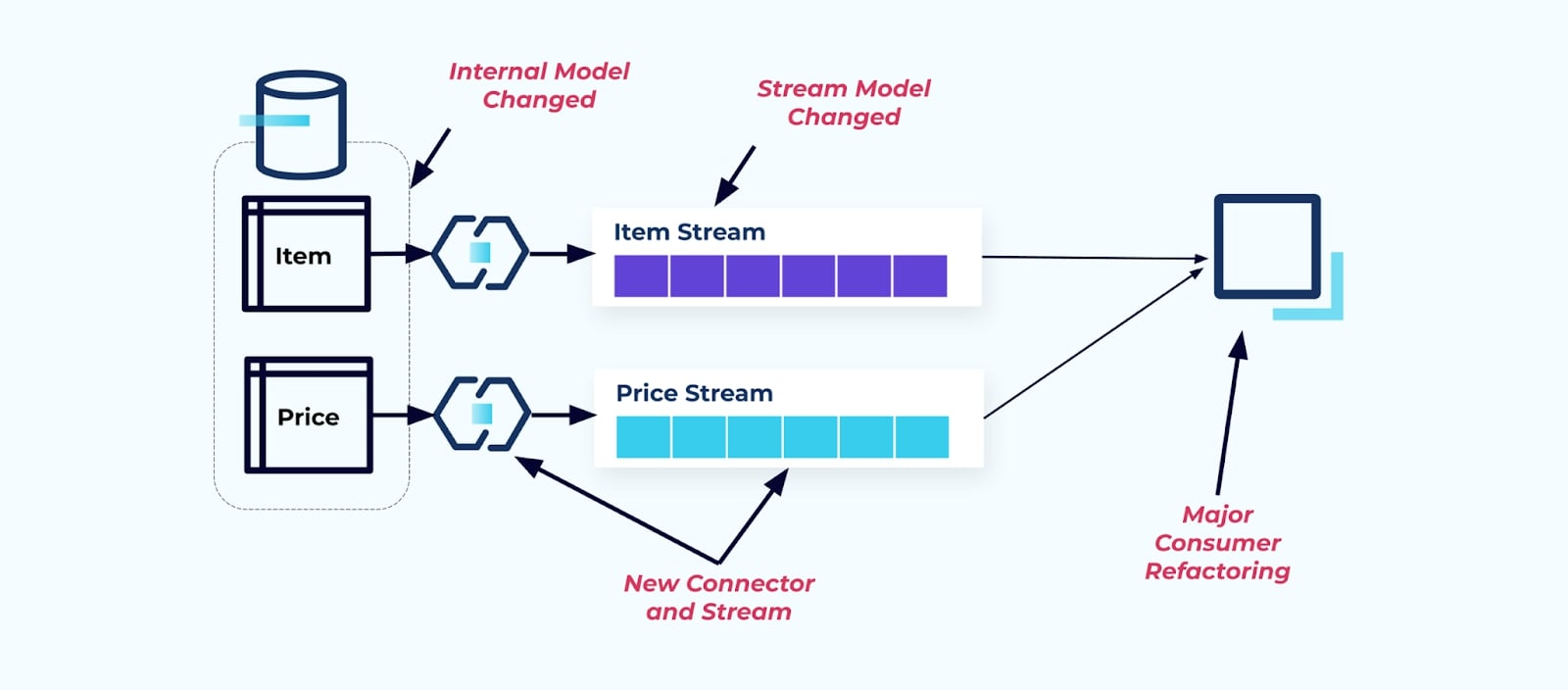
שיפוץ טבלאות המקור גורם לחוזה נתונים שבור עבור זרם הפריטים. הצרכן לא מקבל עוד את אותם נתוני פריט שציפה להם במקור. עלינו גם ליצור מחבר חדש — זרם Price חדש — ולבסוף, לשפץ את לוגיקת הצרכן שלנו כדי להפעיל אותו שוב. שינוי שמות עמודות, שינוי ערכי ברירת מחדל ושינוי סוגי עמודות הם צורות אחרות של שינויים מפרקים שמוכנסים על ידי חיבור צפוף של מודל הנתונים הפנימי.
בעיה: חיבורי זרימה הם (בדרך כלל) יקרים
מסדי נתונים רלציוניים מובנים במיוחד כדי לפתור חיבורים במהירות ובזול. חיבורי זרימה, למרבה הצער, אינם כאלה.
נניח שיש שני שירותים שרוצים לגשת לפריט, ל
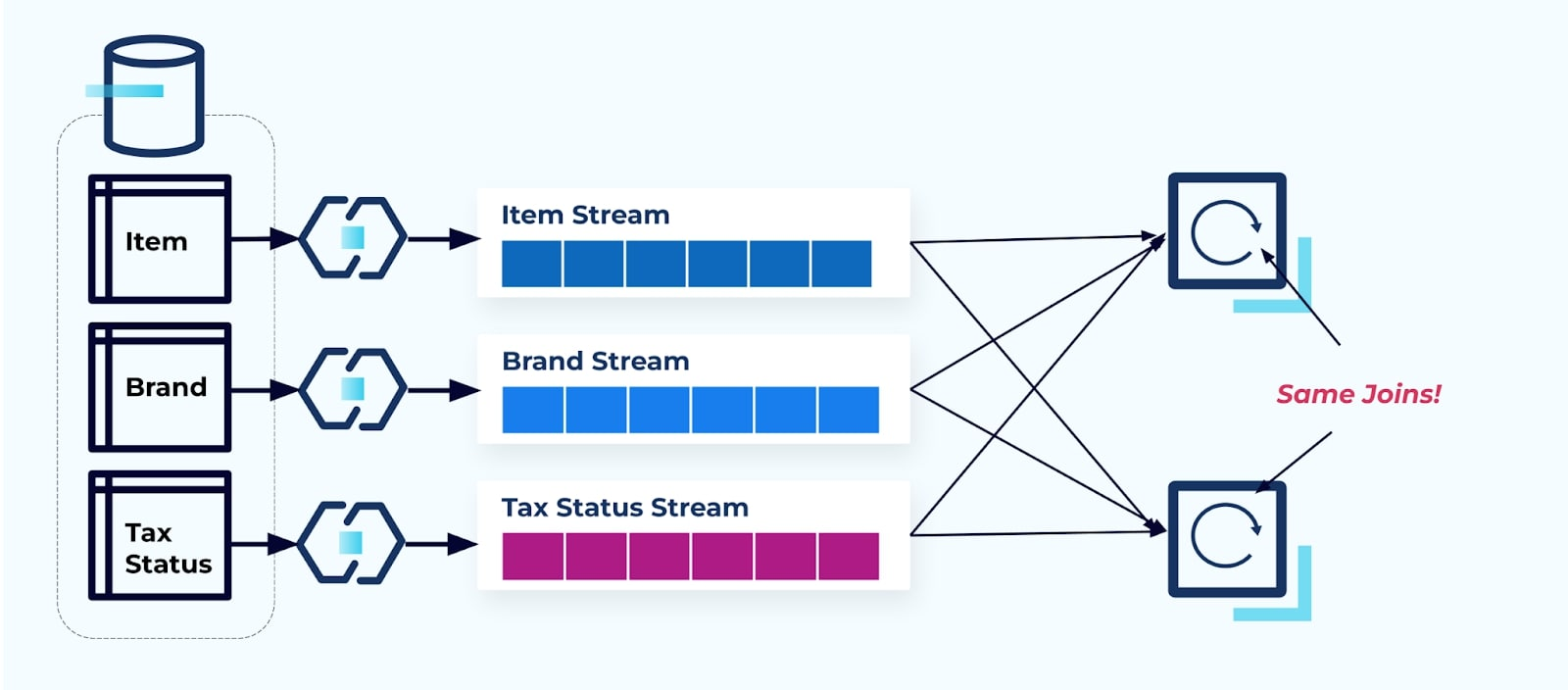
אסטרטגיה זו יכולה להסתיים בעלויות גבוהות, הן בשעות פיתוח לכתיבת היישומים והן בעלויות שרת לחישוב הצירופים. פתרון צירופי זרימה בקנה מידה גדול יכול להוביל להרבה חילופי נתונים, מה שמטיל עלויות של כוח עיבוד, רשת ואחסון. יתרה מכך, לא כל מסגרות לעיבוד זרימה תומכות בצירופים, במיוחד על מפתחות זרים. מאלה שכן תומכות, כמו Flink, Spark, KSQL או Kafka Streams (לדוגמה), תמצאו את עצמכם מוגבלים לתת-קבוצה של שפות תכנות (Java, Scala, Python).
פתרון: מתן נתונים לא נרמלים הוא הטוב ביותר
כעיקרון, עשו את זרמי האירועים קלים לשימוש עבור הצרכנים שלכם. לא נרמלו את הנתונים לפני שהם זמינים לצרכנים באמצעות שכבת אבסטרקציה ויצרו מודל חיצוני מפורש חוזה נתונים (נתונים בצד החיצוני) שעליו יתחברו הצרכנים.
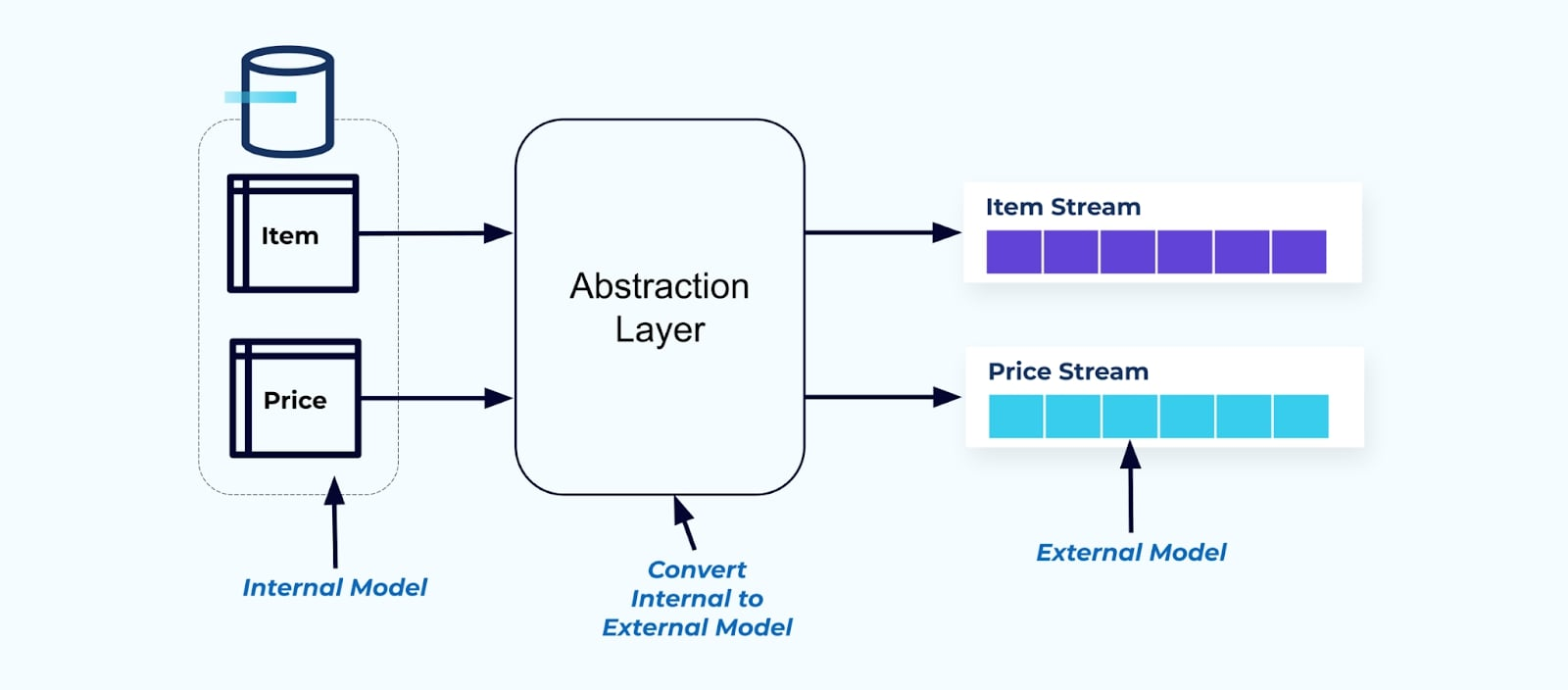
שינויים במודל הפנימי נשארים מבודדים במערכות המקור. הצרכנים מקבלים חוזה נתונים מוגדר היטב לחיבור. שינויים שנעשים במודל המקור יכולים להמשיך ללא הפרעה, כל עוד מערכת המקור מקיימת את חוזה הנתונים עבור הצרכנים.
אבל איפה אנחנו לא נרמלים? שתי אפשרויות:
- שיקום מחוץ למערכת המקור באמצעות שירות צירוף מיועד.
- במהלך יצירת האירוע במערכת המקור באמצעות תבנית הפתק הטרנזקציוני.
בואו נבחן כל פתרון בתורו.
אפשרות 1: לא לנרמל באמצעות שירות צירוף מיועד
בדוגמה זו, הזרמים משמאל משקפים את הטבלאות שהם הגיעו מהן במסד הנתונים.
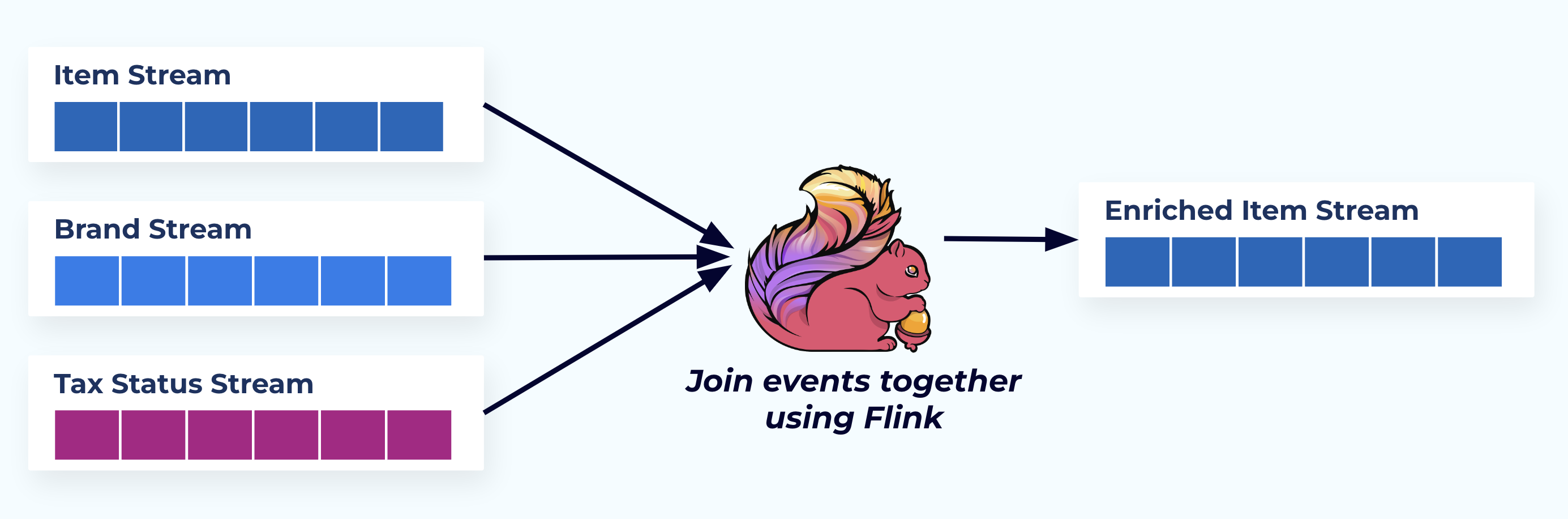
אנו מחברים את האירועים באמצעות יישום מותאם אישית (או שאילתת SQL מוזרמת) המבוסס על יחסי מפתח זר ומפיק זרם פריט מועשר יחיד.

לוגית, אנו מפתרים את היחסים ומדחיסים את הנתונים לשורה חד-ממדית יחידה.
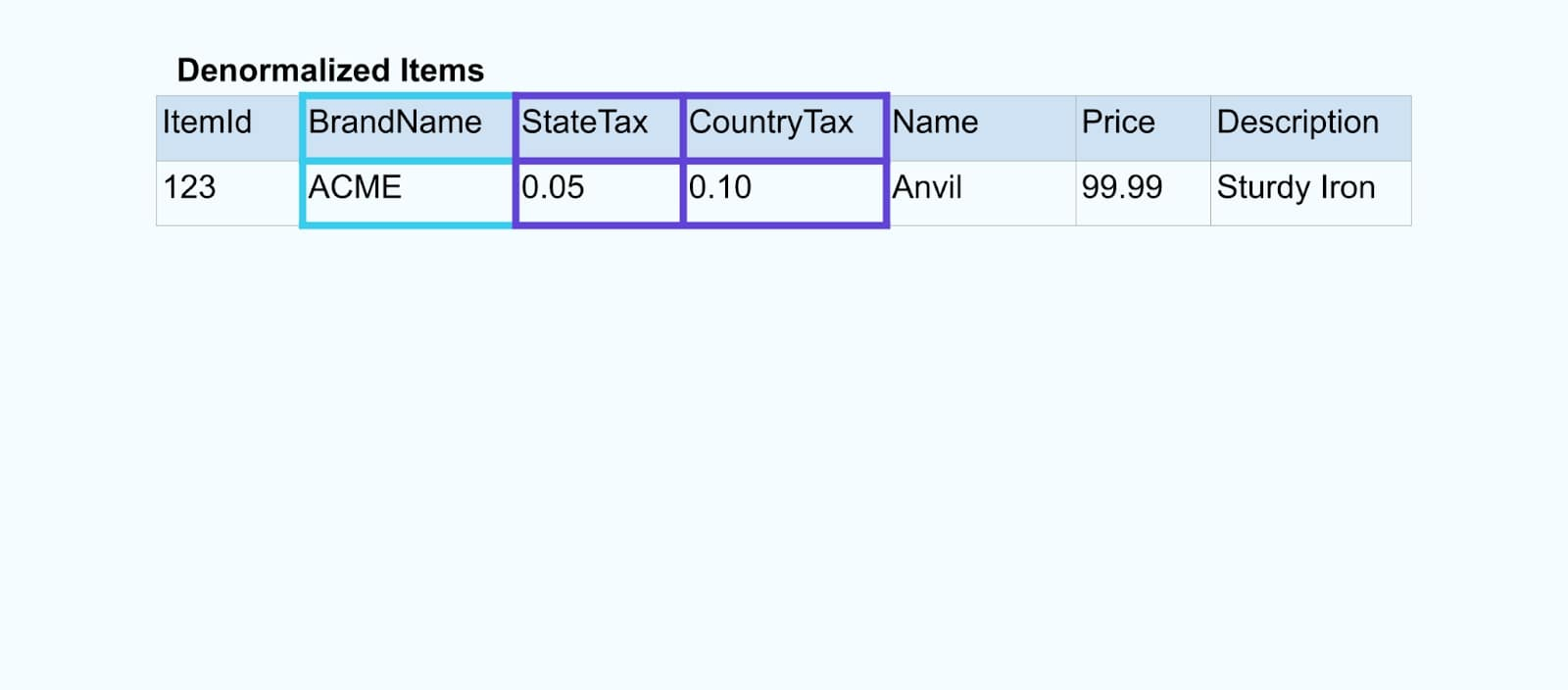
יישומי החיבור המותאמים אישית נסמכים על מסגרות עיבוד זרם כמו Apache Kafka Streams ו-Apache Flink לפתרון חיבורים של מפתחות ראשיים וזרים. הם ממציאים את נתוני הזרם לפורמטי טבלאות פנימיים עמידים, ומאפשרים ליישום החיבור לחבר אירועים לאורך כל תקופה – לא רק אלה המוגבלים על ידי חלון זמן מוגבל.
מחברים המשתמשים ב-Flink או Kafka Streams הם גם ניתנים להתאמה בקלות — הם יכולים להתרחב ולהתכווץ בהתאם לעומס ולהתמודד עם נפחי תנועה עצומים.
טיפ: אל תשימו שום לוגיקת עסקים במחבר. כדי להצליח בתבנית זו, על נתוני החיבור לייצג במדויק את המקור, פשוט כתוצאה חד-ממדית. תנו לצרכנים במורד הזרם ליישם את לוגיקת העסקים שלהם, תוך שימוש בנתונים החד-ממדיים כמקור אמת יחיד.
אם אינכם רוצים להשתמש במחבר במורד הזרם, ישנם אפשרויות אחרות. הבה נבחן את תבנית תא המשלוח הטרנזקציוני בהמשך.
אפשרות 2: תבנית תא משלוח טרנזקציוני
ראשית, צרו טבלת תא משלוח מיוחדת לכתיבת אירועים לזרם.
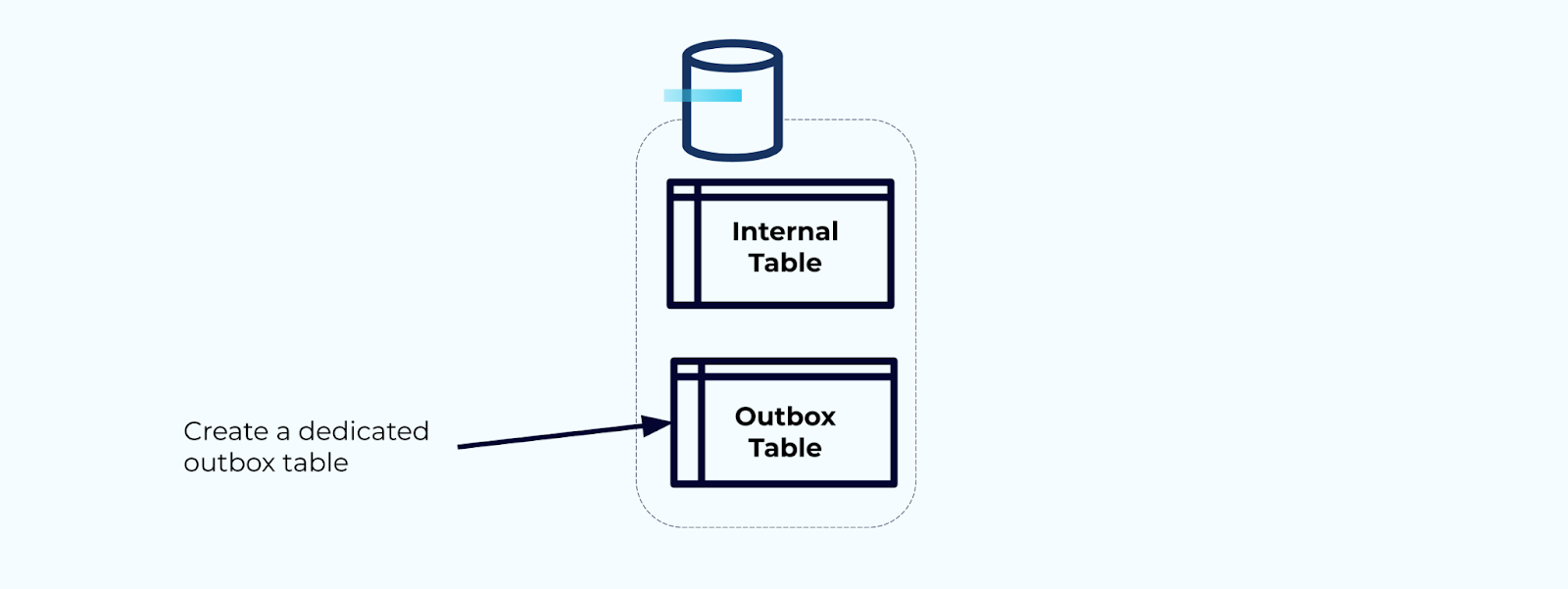
שנית, כיסו את כל עדכוני הטבלה הפנימיים הנדרשים בתוך טרנזקציה. טרנזקציות מבטיחות שכל עדכון שנעשה לטבלה הפנימית ייכתב גם לטבלת האאוטבוקס.
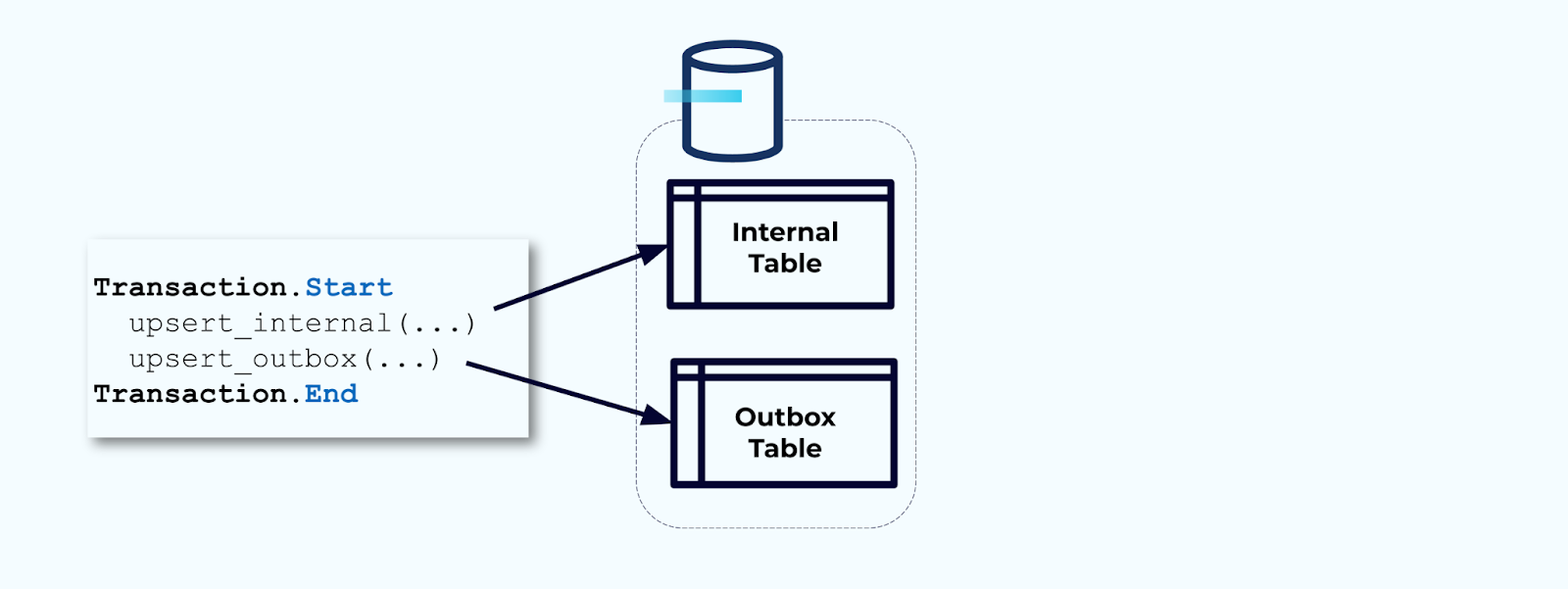
האאוטבוקס מאפשר לכם לבודד את מודל הנתונים הפנימי מכיוון שאתם יכולים לחבר ולהמיר את הנתונים לפני שאתם כותבים אותם לאאוטבוקס. האאוטבוקס פועל כשכבת אבסטרקציה בין הנתונים שלכם בפנים והנתונים בחוץ, ומשמש כחוזה נתונים למשתמשים שלכם.
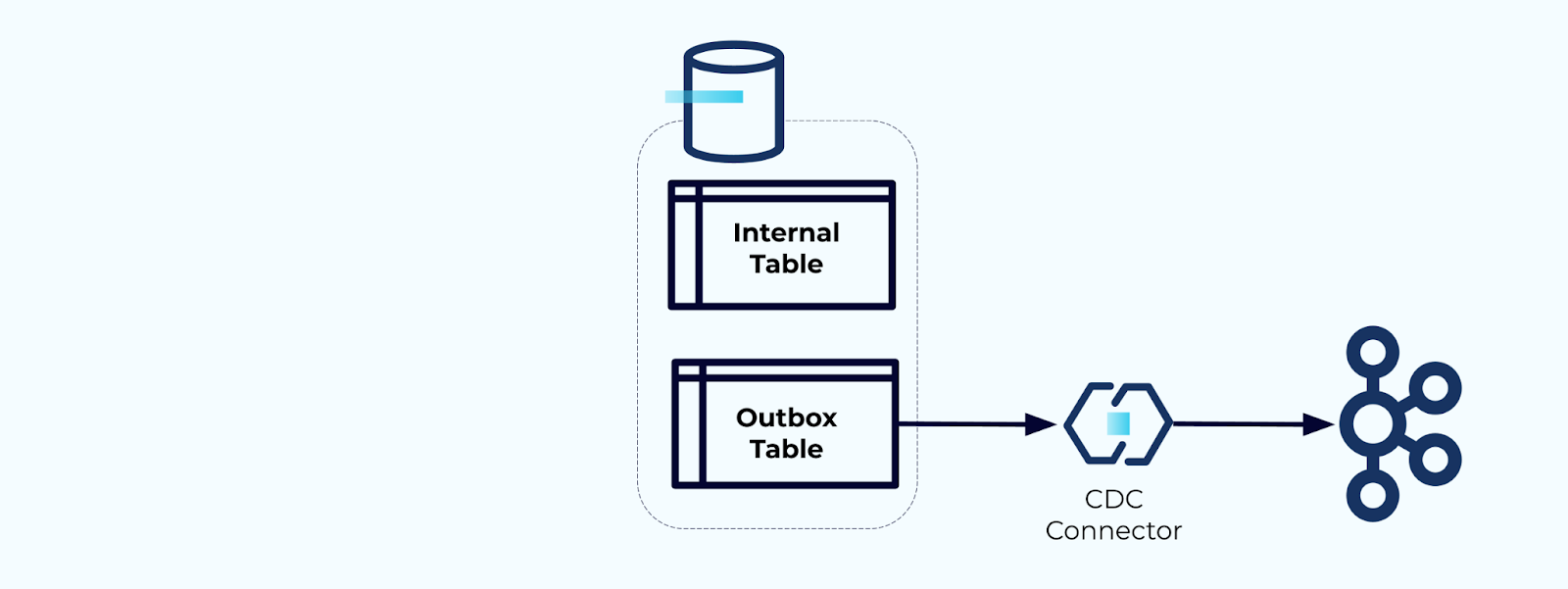
לבסוף, אתם יכולים להשתמש בקונקטור כדי להוציא את הנתונים מהאאוטבוקס ולהעביר אותם לקפקה.
אתם חייבים לוודא שהאאוטבוקס לא גדל ללא הגבלה — או למחוק את הנתונים לאחר שהם נלכדו על ידי ה-CDC או באופן תקופתי באמצעות עבודה מתוזמנת.
דוגמה: דנורמליזציה של אירועי עקיבת התנהגות משתמשים
עקיבה אחרי התנהגות משתמשים בדפי האינטרנט ובאפליקציות שלכם היא מקור נפוץ לאירועים מנורמלים – חשבו על Google Analytics או אפשרויות פנים ביתיות ראשונות. אך אנו לא כוללים את כל המידע באירוע; במקום זאת, אנו מגבילים אותו למזהים (מהיר יותר, קטן יותר, זול יותר), ומבצעים דנורמליזציה לאחר יצירת העובדות.
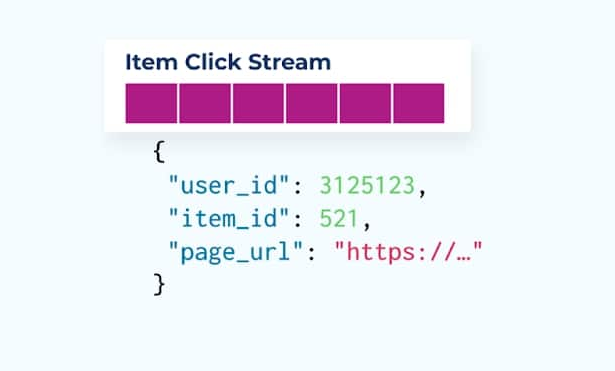
חשבו על זרם של אירועי לחיצה על פריטים המפרטים מתי משתמש הקיש על פריט בזמן גלישה בפריטים מסחר אלקטרוני. שימו לב שאירוע לחיצה זה לא מכיל מידע עשיר יותר על הפריט כמו שם, מחיר ותיאור, רק ids בסיסיים.
הדבר הראשון שרבים מצרכני זרם הקליקים עושים הוא מצרפים אותו לזרם העובדות של הפריט. ומכיוון שאתה מתמודד עם אירועי קליק רבים, אתה מגלה שזה מסתיים בשימוש בכמות גדולה של משאבי חישוב. יישום Flink מותאם למטרה יכול לחבר את קליקי הפריט עם הנתונים המפורטים של הפריט ולפרוסם אותם לזרם קליקי פריטים מועשר.
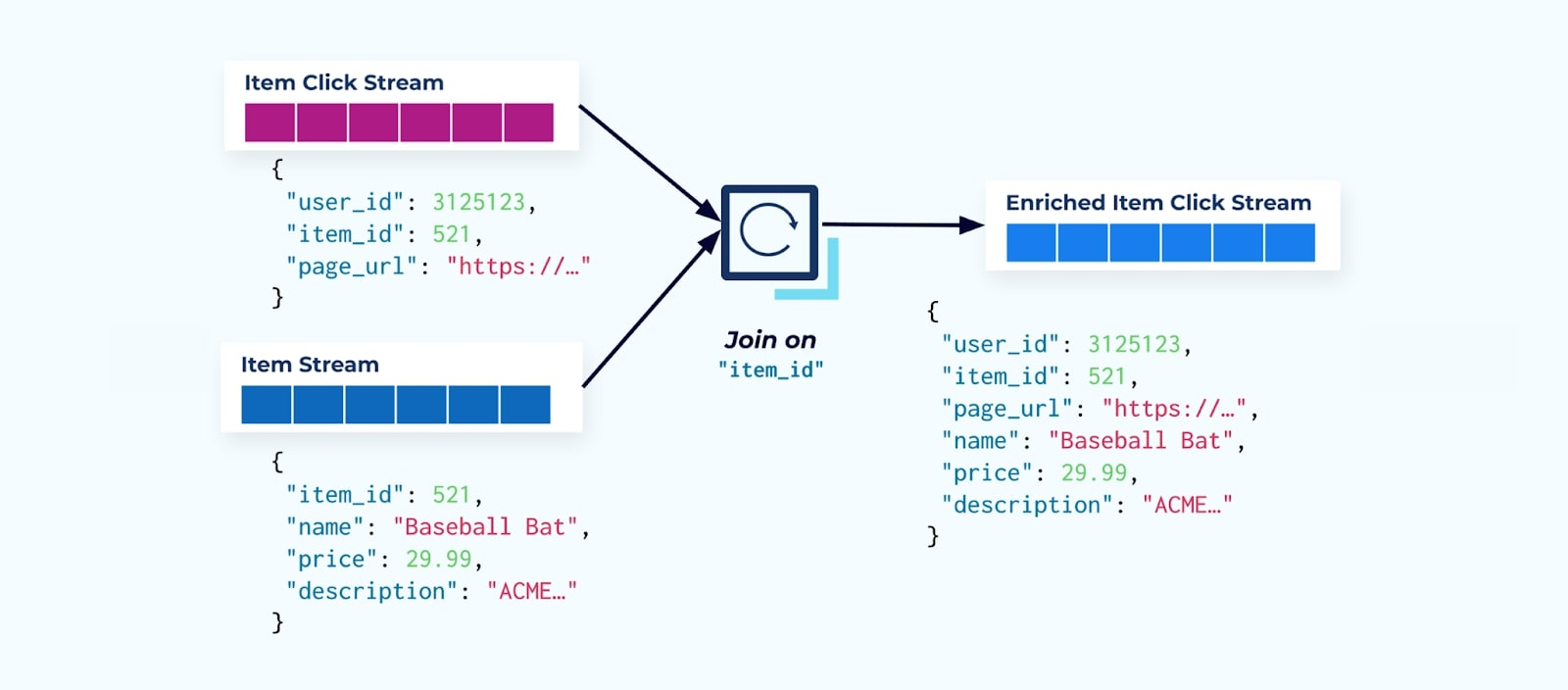
חברות גדולות יותר עם מספר מחלקות (ומערכות) כנראה יראו שהנתונים שלהן מגיעים ממקורות שונים, והצטרפות אחרי העובדה באמצעות מצרף זרמים היא התוצאה הכי סבירה.
שיקולים על מימדים משתנים לאט
כבר דנו בשיקולי הביצועים של כתיבת אירועים המכילים מערכי נתונים גדולים (למשל, טקסטים ארוכים) ומרחבי נתונים שמשתנים לעיתים קרובות (למשל, מלאי פריטים). עכשיו, נבחן את המימדים המשתנים לאט (SCDs), שעצמם מצויינים לעיתים קרובות דרך יחס זר חיצוני, כי אלה יכולים להיות מקור נוסף לנפחי נתונים משמעותיים.
בואו נחזור לדוגמת הפריט שלנו שוב. נאמר שיש לך פעולה שמעדכנת את טבלת הפריטים. אנחנו הולכים לשנות את שם הפריט מאיזמל לאיזמל ברזל.
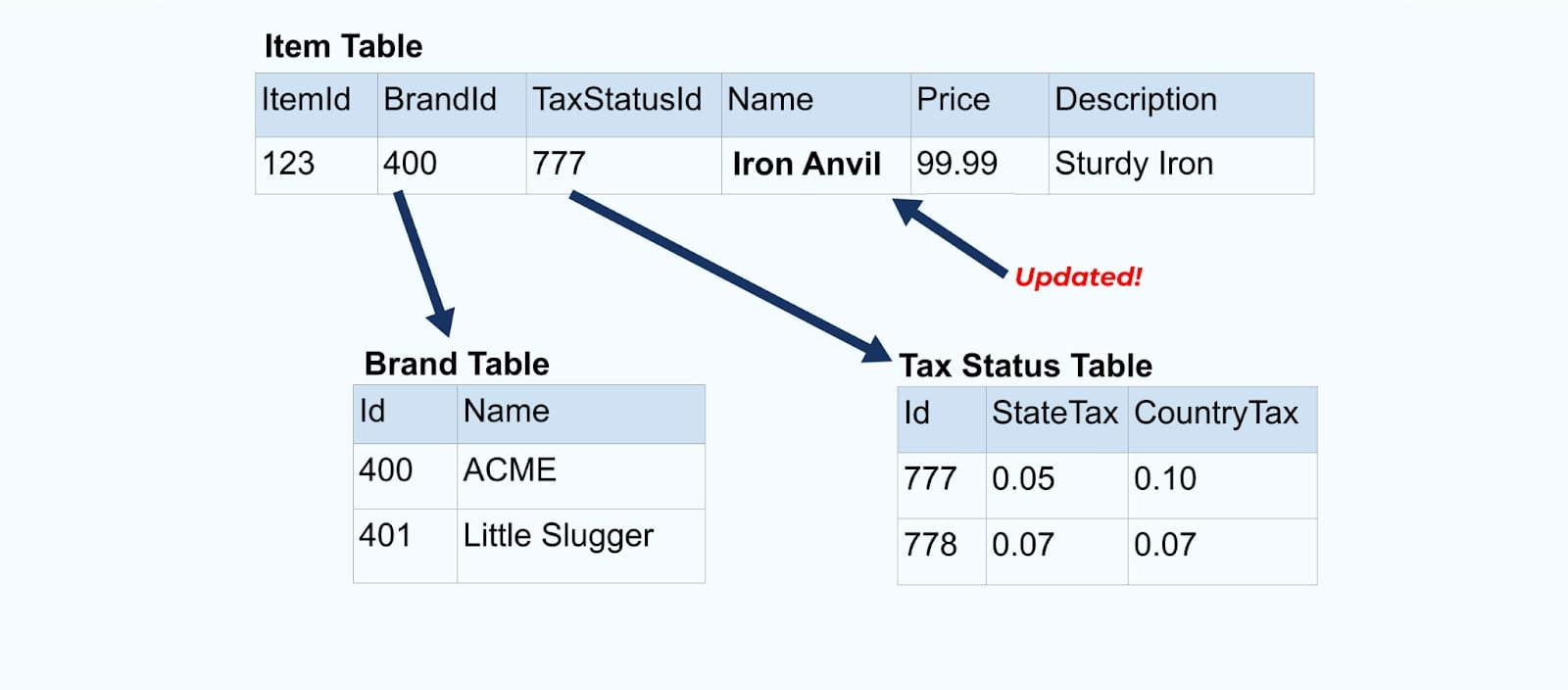
עם עדכון הנתונים בבסיס הנתונים, אנחנו גם מפריסים את הפריט המעודכן (נאמר דרך תבנית האאוטבוקס), כולל מצב המס המסודר מחדש וטבלת המותג.
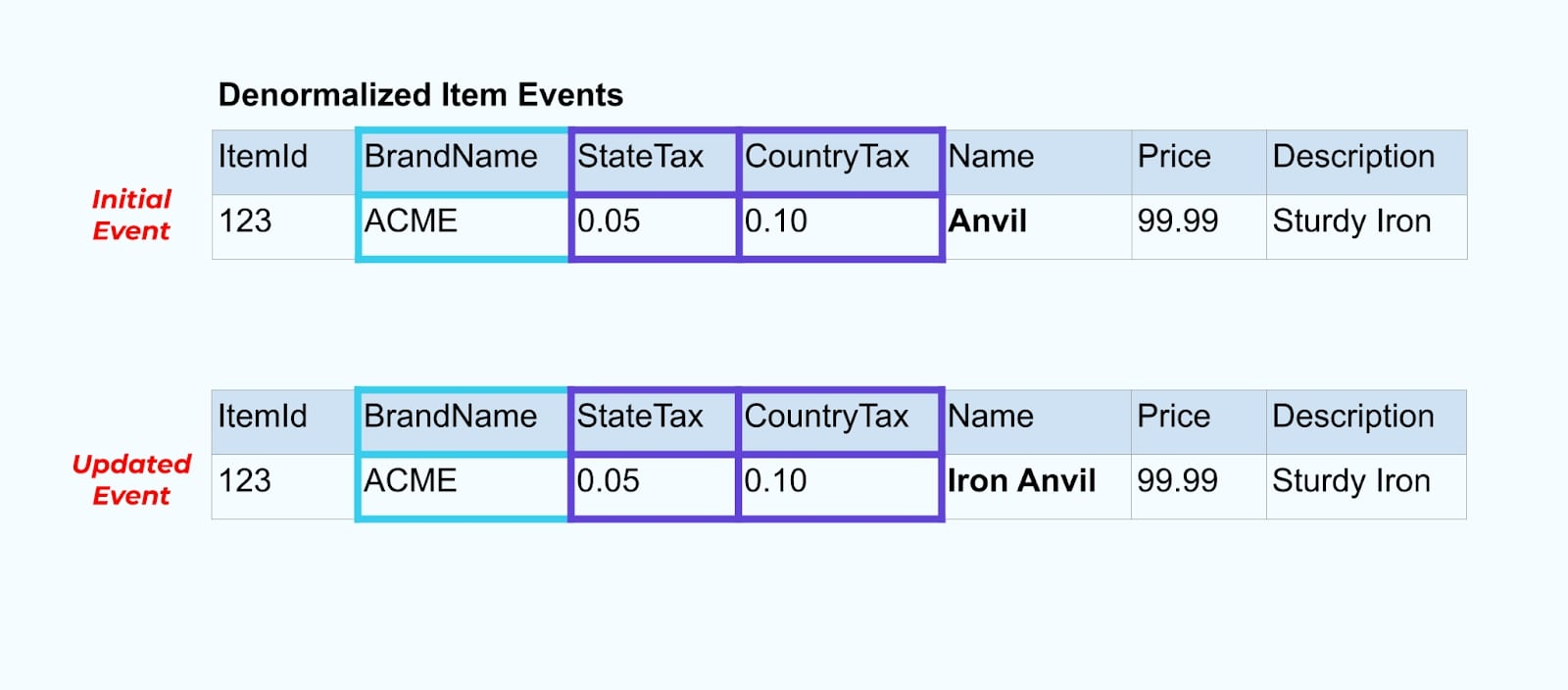
אולם, אנחנו גם צריכים לשקול מה קורה כשמשנים ערכים בטבלאות המותג או המס. עדכון אחד מהמימדים המשתנים לאט האלה יכול להוביל למספר גדול מאוד של עדכונים לכל הפריטים המושפעים.
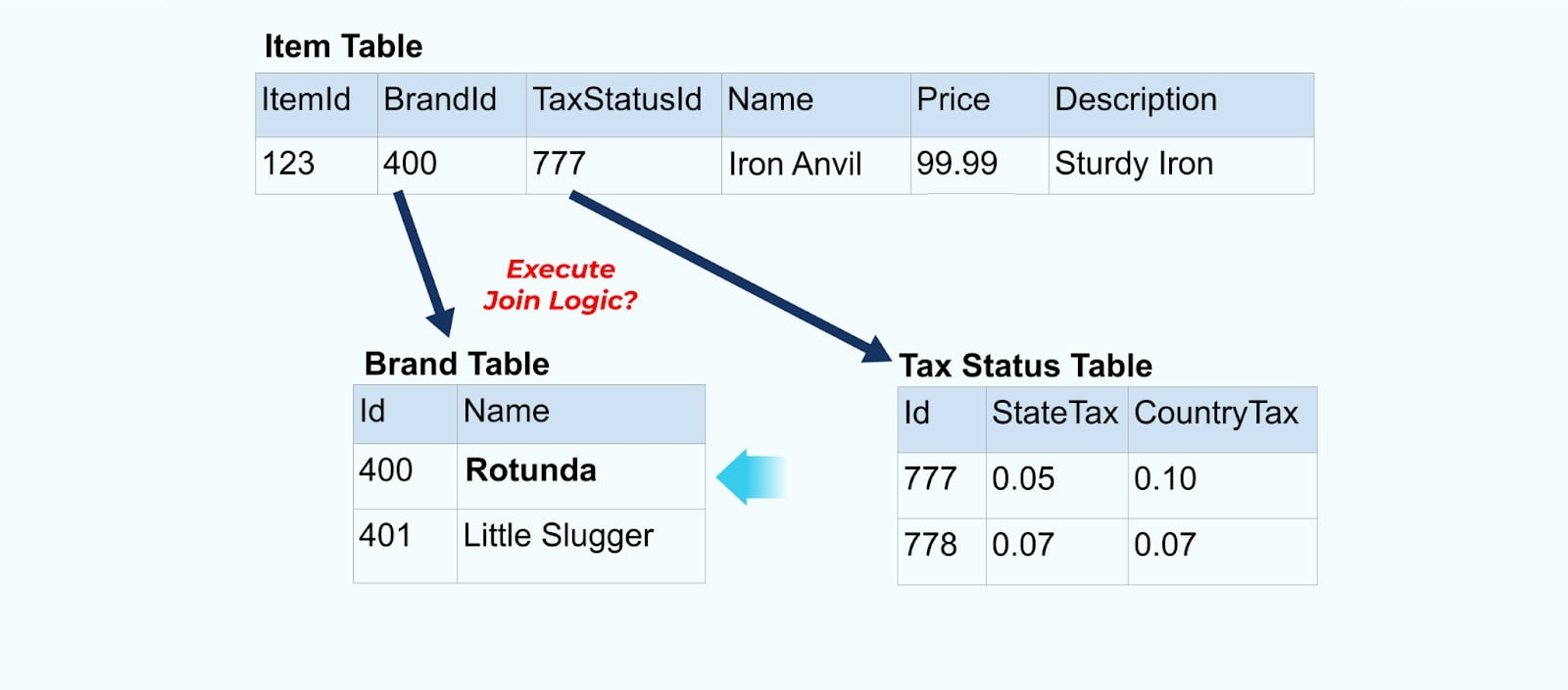
לדוגמה, חברת ACME עוברת מיתוג מחדש ומגיעה עם שם מותג חדש, משנה את שמה מ-ACME ל-Rotunda. אנו מייצרים אירוע נוסף עבור ItemId=123.
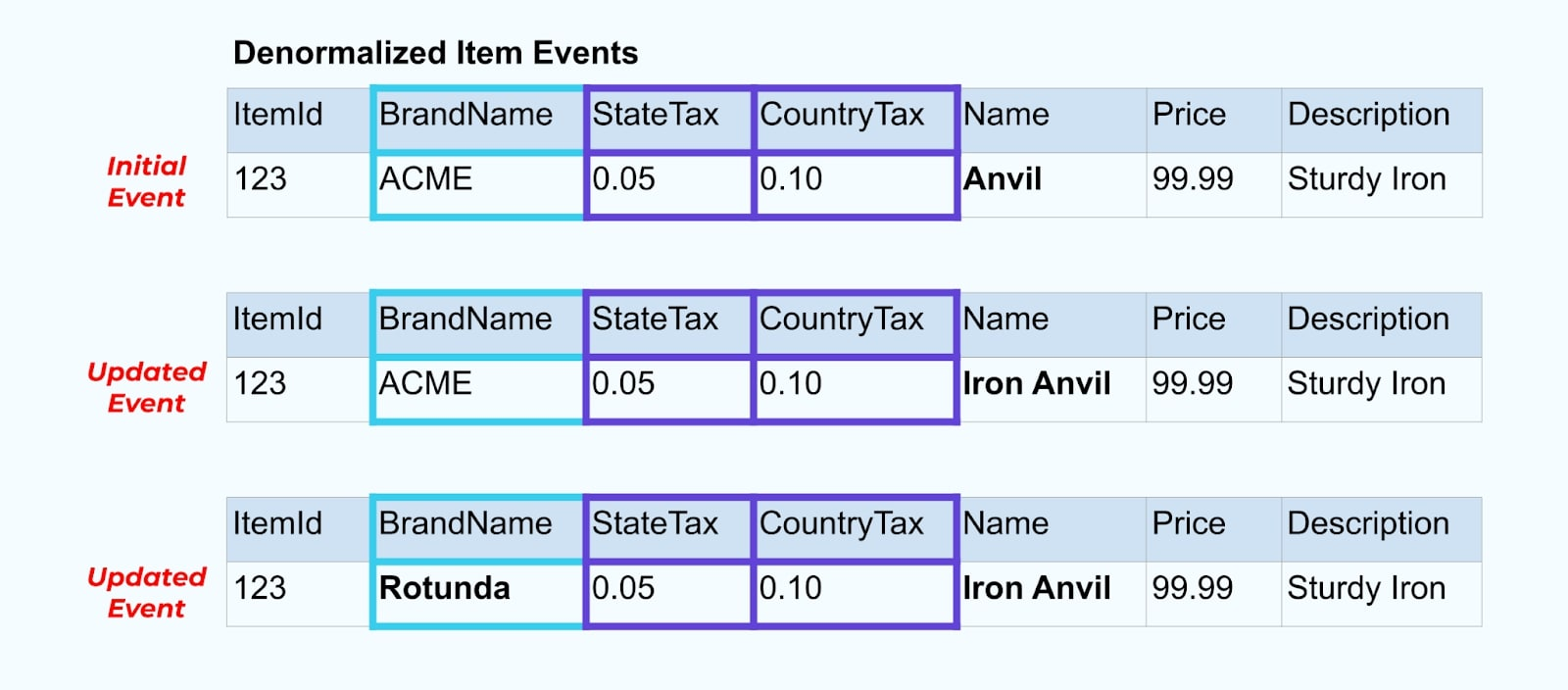
אולם, ל-Rotunda (לשעבר ACME) יש כנראה מאות (או אלפים) של פריטים שגם הם מעודכנים בעקבות השינוי הזה, מה שמוביל למספר מתאים של אירועי פריטים מועשרים שעודכנו.
כשמבצעים דנורמליזציה ל-SCDs ויחסי מפתח זרים, יש לקחת בחשבון את ההשפעה ששינוי ב-SCD עשוי להיות לזרם האירועים כולו. ייתכן שתחליטו לוותר על דנורמליזציה ולהשאיר את זה לצרכן במקרה ששינוי ה-SCD גורם למיליונים או מיליארדים של אירועים מעודכנים.
סיכום
דנורמליזציה הופכת את השימוש בנתונים לקל יותר עבור הצרכנים אך זה בא על חשבון עיבוד יותר מורכב במעלה הזרם ובחירה זהירה של הנתונים להכללה. לצרכנים יכול להיות זמן קל יותר לבנות אפליקציות והם יכולים לבחור מטווח רחב יותר של טכנולוגיות, כולל אלו שלא תומכות נטיבית בחיבורי זרימה.
נרמול נתונים במעלה הזרם עובד היטב כשהנתונים קטנים ומעודכנים לעיתים רחוקות. גודל אירועים גדול יותר, עדכונים תכופים ו-SCDs הם כולם גורמים שיש לשים לב אליהם כשמקבעים מה לדנורמליזציה במעלה הזרם ומה להשאיר לצרכנים לעשות בעצמם.
בסופו של דבר, בחירת הנתונים שיכללו באירוע ומה להשאיר חוץ היא פעולת איזון בין צרכי הצרכנים, יכולות המפיק והיחסים הייחודיים של מודל הנתונים. אך המקום הטוב ביותר להתחיל הוא על ידי הבנת צרכי הצרכנים שלכם ובידוד מודל הנתונים הפנימי של מערכת המקור שלכם.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2