













הופעת מערכת הקבצים המרוחקת של אפטשי הדופן (HDFS) הפכה את האחסון, עיבוד וניתוח הנתונים למהפכה עבור תאגידים, מאיצה את צמיחת הנתונים הגדולים ומביאה לשינויים מהותיים בתעשייה.
בתחילה, האדון שילב אחסון וחישוב, אך הופעת הענן המחשב גרמה להפרדה של רכיבים אלה. שמירת אובייקטים עמדה במקום כחלופה ל-HDFS אך היו לה מגבלות. כדי להשלים את המגבלות האלה, JuiceFS, מערכת קבצים מרוחקת בשירות עצמי, ביצע פתרונות יעילים מבחינת העלות לנושאים רבי נתונים כמו חישוב, ניתוח ואימון. ההחלטה לאמץ הפרדת שמירה-חישוב תלויה בגורמים כמו סקלביליות, ביצועים, עלות ושאיפה.
במאמר זה, נעבור על ארכיטקטורת האדון, נדון בחשיבות ובאפשרות הפרדת השמירה-חישוב, ונחקור את הפתרונות השוק הזמינים, ונדגיש את היתרונות והחסרונות המתאימים. מטרתנו היא לספק תובנות והשראה לתאגידים העוברים מעבר של ארכיטקטורת הפרדת השמירה-חישוב.
מאפייני עיצוב ארכיטקטורת האדון
האדון כמסגרת כוללת
בשנת 2006, האדון שוחרר כמסגרת כוללת המורכבת משלושה רכיבים:
- MapReduce לחישוב
- YARN לתיאום משאבים
- HDFS לאחסון קבצים מרוחק
 Core components of Hadoop
Core components of Hadoopרכיבים חישוביים מגוונים
בין שלושת הרכיבים הללו, השכבה המחשבתית ראתה פיתוח מהיר. בתחילה היה רק MapReduce, אך התעשייה במהרה חזתה את ההופעה של מסגרות שונות כמו Tez ו-Spark לחישוב, Hive לאחסון נתונים, ומנועי חיפוש כמו Presto ו-Impala. במהלך הפעלת רכיבים אלו, קיימים כלי מעבר נתונים רבים כמו Sqoop.

HDFS שלט במערכת האחסון
במשך כעשר שנים, HDFS, מערכת הקבצים המרוחקת, נשארה המערכת האחסון הדומיננטית. זו הייתה הבחירה הברורה לכמעט כל רכיבי החישוב. כל הרכיבים שנמצאים בשיכון הגדול של מערכת הנתונים עורכים את ה-API של HDFS. חלק מהרכיבים משתמשים ביכולות ספציפיות של HDFS באופן עמוק. לדוגמא:
- HBase משתמש ביכולות הכתיבה בזמן רצוני של HDFS ליומני הכתיבה המוקדמים שלהם.
- MapReduce ו-Spark הציעו תכונות של מיקום נתונים.
הבחירות התכנוניות של רכיבים אלו של מערכת הנתונים הגדולה, המבוססות על API של HDFS, הביאו אתגרים פוטנציאליים עבור פרויקטים לפרויקטים של מערכות הנתונים לענן.
ארכיטקטורת האחסון והמחשב המחוברת
התרשים הבא מציג חלק מארכיטקטורת HDFS המופשטת, אשר מחבר חישוב עם אחסון.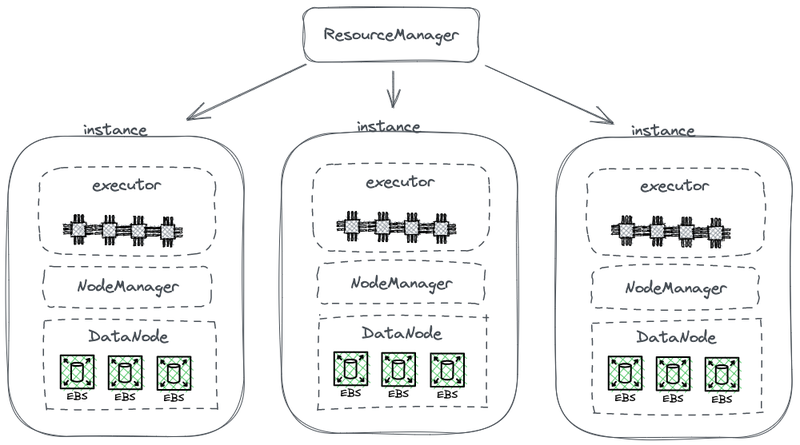
ארכיטקטורת האחסון-חישוב המחוברת של האדון
בתרשים זה, כל צמתי משמש כ-HDFS DataNode לאחסון נתונים. כמו כן, YARN מפעיל תהליך Node Manager על כל צמתי. זה מאפשר ל-YARN להכיר את הצמתי כחלק מהמשאבים הניהולים שלו למשימות חישוב. ארכיטקטור זה מאפשר לאחסון ולחישוב להתקיים על אותו מכשיר, וניתן לקרוא מידע מהכונן במהלך החישוב.
למה האדון מחובר אחסון וחישוב
האדון מחובר אחסון וחישוב בגלל המגבלות של תקשורת הרשת והחומרה בשלב העיצוב שלו.
בשנת 2006, חישוב הענן היה עדיין בשלבו הראשוני, ואמזון השיקה רק את השירות הראשון שלה. במרכזי נתונים, כרטיסי הרשת השולטים היו בעיקר פועלים במהירות 100 מגהביט לשנייה. כוננים הנתונים המשמשים לעבודות גדולות של נתונים השיגו תוצאות שיא של כ-50 מגהבייט לשנייה, שקולים ל-400 מגהביט במונחים של ערוץ רשת.
בהתחשב בצומת עם שמונה דיסקים הפועלים בתפוסה מרבית, היה נדרש כמות גיגהביטים לשנייה של תאוצת הרשת לשיתוף נתונים יעיל. לרוע המזל, יכולת הרשת המקסימלית של כרטיסי הרשת הייתה מוגבלת ל-1 ג'יגהביט לשנייה. כתוצאה מכך, תפוסת הרשת לצומת הייתה חסרה מספיק כדי למלא את היכולות של כל הדיסקים בתוך הצומת. כתוצאה מכך, אם משימות המיחשוב היו בקצה אחד של הרשת והנתונים היו בצמתי נתונים בקצה השני, תפוסת הרשת הייתה מהווה בלש משמעותי.
למה ניתן להפריד בין אחסון לבין חישוב
משנת 2006 עד בערך 2016, חברות התמודדו עם הבעיות הבאות:
- הביקוש לכוח מחשב ואחסון ביישומים היה לא מאוזל, וקצב הגדילה שלהם היה שונה. בעוד שהנתונים של הארגון גדלו במהירות, הצורך בכוח מחשב לא גדל באותו קצב. המשימות האלו, שפותחו על ידי בני אדם, לא הכפילו את עצמן באופן מהיר ואקספוננציאלי. עם זאת, הנתונים שנוצרו מהמשימות האלו הצטברו במהירות, אולי באופן אקספוננציאלי. בנוסף, חלק מהנתונים אולי לא היה מייד שימושי לארגון, אך יהיה חשוב בעתיד. לכן, חברות אחסנו את הנתונים באופן מקיף כדי לחקור את הערך הפוטנציאלי שלהם.
- במהלך ההגדלה, היוונים היו צריכים להרחיב גם את המחשב וגם את האחסון בו זמנית, מה שלעתים קרובות הוביל לבזבוז של משאבי חישוב. המבנה האבטחתי של הארכיטקטורה המחוברת של אחסון-מחשב משפיע על ההרחבה של הקיבולת. כשהקיבולת של האחסון קטנה, היינו צריכים לא רק להוסיף מכונות אלא גם לשדרג ג'יפים וזיכרון מice הצמתים בארכיטקטורה המחוברת היו אחראיים לחישוב. לכן, מכונות בדרך כלל הותקנו עם כוח חישוב מאוזן וצורת אחסון, מה שמספק קיבולת אחסון מספקת יחד עם כוח חישוב דומה. עם זאת, הביקוש האמיתי לכוח חישוב לא גדל כצפוי. כתוצאה מכך, הכוח המוגבר של החישוב גרם לבזבוז גדול עבור היוון
- התאמת חישוב ואחסון ובחירת מכונות מתאימות הפכה לקשה. שימוש המשאבים בכלל המסד במונחים של אחסון ו-I/O יכול להיות מאוד לא מאוזן, והאי שיוויון הזה החמיר ככל שהמסד גדל. בנוסף, היה קשה לרכוש מכונות מתאימות, שכן המכונות היו צריכות להתאים בין צרכי חישוב לצרכי אחסון
- מכיוון שניתן היה לחלק את הנתונים באופן לא שווה, היה קשה לתכנן ביעילות משימות חישוב באירגון שבו הנתונים נמצאים. אסטרטגיית תזמון מקומי של הנתונים לא עשויה לפתור ביעילות תרחישים מציאותיים בגלל האפשרות של חלוקת נתונים לא מאוזנת. לדוגמה, נקודות מסוימות עשויות להפוך לנקודות חממה מקומיות, שדורשות יותר כוח חישוב. כתוצאה מכך, גם אם משימות בפלטפורמת הנתונים הגדולים תוזמננה לצמתים הלוהטים הללו, ביצועי I/O עשויים להפוך לגורם מגביל.
למה ההפרדה בין אחסון ומיחשוב אפשרית
האפשרות להפריד בין אחסון ומיחשוב התאפשרה בשל התקדמות בחומרה ובתוכנה בין השנים 2006 ו-2016. ההתקדמותים הללו כוללים:
כרטיסי רשת
אימוץ כרטיסי רשת במהירות 10 ג'יגהב הפך לנפוץ, עם זמינות גדולה יותר של יכולות גבוהות יותר כגון 20 ג'יגהב, 40 ג'יגהב ואף 50 ג'יגהב במרכזי נתונים וסביבות ענן. בתרחישים של AI, כרטיסי רשת בקיבולת של 100 ג'יגהב משמשים גם כן. זה מייצג עלייה משמעותית ברווחת הרשת של מעל 100 פעמים.
דיסקים
רבים מהארגונים עדיין מסתמכים על פתרונות מבוססי דיסק לאחסון במבחרי נתונים גדולים. תוצאת העברת הנתונים של הדיסקים הוכפלה, עולה מ-50 מגהב לשנייה ל-100 מגהב לשנייה. מופע משומש, המצויד בכרטיס רשת של 10 ג'יגהב, יכול לתמוך בתוצאת עבודה שיא של כ-12 דיסקים. זה מספיק עבור רוב הארגונים, ולכן, שיתוף המידע כבר אינו מפגר.
תוכנה
השימוש באלגוריתמים דחיסה יעילים כמו Snappy, LZ4, ו-Zstandard ופורמטים אחסון עמודתיים כמו Avro, Parquet, ו-Orc הק减轻ה גרונים עליות בלחץ על מערכת ההפעלה. המפגר בעיבוד נתונים גדול הזז מלחץ על מערכת ההפעלה לביצועים של מעבד.
איך ליישם הפרדה בין אחסון למיחשוב
ניסיון ראשון: פרטיות של HDFS לענן
פרטיות של HDFS
מאז 2013, היו נסיונות בתעשייה להפריד בין אחסון ובינת חישוב. הגישה הראשונית היא די פשוטה, וכוללת את הפריסה העצמאית של HDFS מבלי לשלבה עם עובדי החישוב. פתרון זה לא הציג רכיבים חדשים לסביבת האדון.
כפי שמוצג בתרשים למטה, NodeManager לא פורש יותר על DataNodes. זה מעיד על כך שמשימות החישוב לא משוגרות יותר ל-DataNodes. האחסון הפך לצבר נפרד, והנתונים הדרושים לחישובים מועברים דרך הרשת, תוך שימוש בכרטיסי רשת של 10 ג'יגהביט לקצה הרשת. (שים לב שקווי התמסורת הרשתיים אינם מסומנים בתרשים.)

למרות שהפתרון הזה נטש את המקום של הנתונים, העיצוב הכי מבריק של HDFS, המהירות המוגברת של תקשורת הרשת בהחלט פיתחה את האפשרויות לסידור צברים. זה הודגם בניסויים שבוצעו על ידי דייוויס, המייסד של Juicedata, ושותיו במהלך שהיה בפייסבוק ב-2013. התוצאות אישרו את האפשרות לפריסה וניהול עצמאיים של צמתי החישוב.
עם זאת, הניסיון הזה לא התפתח עוד. הסיבה העיקרית היא האתגרים של פריסת HDFS לענן.
אתגרים של פריסת HDFS לענן
פריסת HDFS לענן נתקלת בבעיות הבאות:
- נסיבות רב-עותקי ה-HDFS יכולות להעלות את עלות העסקים בענן: בעבר, העסקים השתמשו בדיסקים גמישים כדי לבנות מערכת HDFS במרכזי הנתונים שלהם. כדי לפגוע בסיכון נזק לדיסק, HDFS מיישם מנגנון רב-עותקים כדי להבטיח את בטחון הנתונים וזמינותם. עם זאת, כשמעבירים נתונים לענן, ספקי הענן מספקים דיסקים ענן שכבר מוגנים על ידי מנגנון רב-עותקים. לכן, על העסקים לשכפל נתונים שלוש פעמים בתוך הענן, דבר הגורם לעליה משמעותית בעלויות.
- אפשרויות מוגבלות לפרוס על דיסקים גמישים: בעוד שספקי הענן מציעים כמה סוגים של מכונות עם דיסקים גמישים, האפשרויות זמינות מוגבלות. למשל, מתוך 100 סוגים של מכונות וירטואליות זמינות בענן, רק 5-10 סוגי מכונות תומכים בדיסקים גמישים. בחירה מוגבלת זו אולי לא תספיק לדרישות הספציפיות של קבוצות העסקים.
- חוסר היכולת לנצל את היתרונות הייחודיים של הענן: פריסת HDFS לענן דורשת יצירת מכונה ידנית, פריסה, תחזוקה, ניטור ופעולות ללא הנוחות של הגדלה אלסטית ומודל תשלום על-פי-שימוש. אלה הם היתרונות העיקריים של חישוב הענן. לכן, פריסת HDFS לענן תוך השגת מרחב-עבודה מופרד לא קל.
חסרונות HDFS
ל-HDFS יש בעצמו חסרונות אלה:
- NameNodes בעלי קיבולת מוגבלת: NameNodes ב-HDFS יכולים להתרחב רק אנכית ולא בצורה מרוחקת. חסרון זה מגביל את מספר הקבצים שניתן לנהל בתוך קבוצת HDFS אחת.
- אחסון יותר מ-500 מיליון קבצים מביא עליות בעלויות הפעולה:לפי הניסיון שלנו, בדרך כלל קל לנהל ולשמור על HDFS עם פחות מ-300 מיליון קבצים. כאשר מספר הקבצים עובר את צומת ה-500 מיליון, יש צורך ליישם את מנגנון הפדרציה של HDFS. עם זאת, זה מציב עלויות גבוהות של פעולה וניהול.
- שימוש גבוה במשאבים ועומס כבד על NameNode משפיע על זמינות קבוצת HDFS:כאשר NameNode גוזב יותר מדי משאבים עם עומס גבוה, עשוי להפעיל קלינקי זבל מלא (GC). זה משפיע על הזמינות של כל קבוצת HDFS. מאחסן המערכת עשוי לחוות זמן ריק, מה שהופך אותו ללא מיקסימלי לקרוא מידע, ואין דרך להתערב בתהליך ה-GC. אי אפשר לקבוע את משך הקפאת המערכת. זו הייתה בעיה בלתי נתקת בקבוצות HDFS בעלות עומס גבוה.
ענן ציבורי + אחסון אובייקטים
עם התקדמות חיבור הענן, עסקים כיום יכולים לבחור להשתמש באחסון אובייקטים כחלופה ל-HDFS. אחסון אובייקטים מיועד במיוחד לאחסון נתונים לא מובנים בקנה מידה גדול, ומציע מבנה להעלאת והורדת מידע בקלות. הוא מספק קיבולת אחסון מתקפלת באופן משמעותי, מה שמבטיח יעילות כספית.
יתרונות האחסון של אובייקטים כחלופה ל-HDFS
אחסון אובייקטים צבר חשיבות, החל מ-AWS ולאחר מכן נאסף על ידי ספקי ענן אחרים כחלופה ל-HDFS. היתרונות הבאים ברורים:
- מבוסס שירותים ומוכן לשימוש: אחסון אובייקטים אינו דורש פריסה, פיקוח או משאבים תחזוקה, ומספק חוויה נוחה ומשתלבת למשתמש.
- סקיילינג אלסטי ותשלום בהתאם לשימוש: תאגידים משלמים עבור אחסון אובייקטים בהתאם לשימושם האמיתי, מה שמבטל את הצורך בתכנון קיבולת. הם יכולים ליצור באגף אחסון אובייקטים ולאחסן כמה שנדרש בלי דאגות לגבי מגבלות קיבולת אחסון.
תפיסות של אחסון אובייקטים
עם זאת, כשמשתמשים באחסון אובייקטים כדי לתמוך במערכות מידע מורכבות כמו הדופן, האתגרים הבאים מתעוררים:
תפיסה מס' 1: ביצועים גרועים של רשימת קבצים
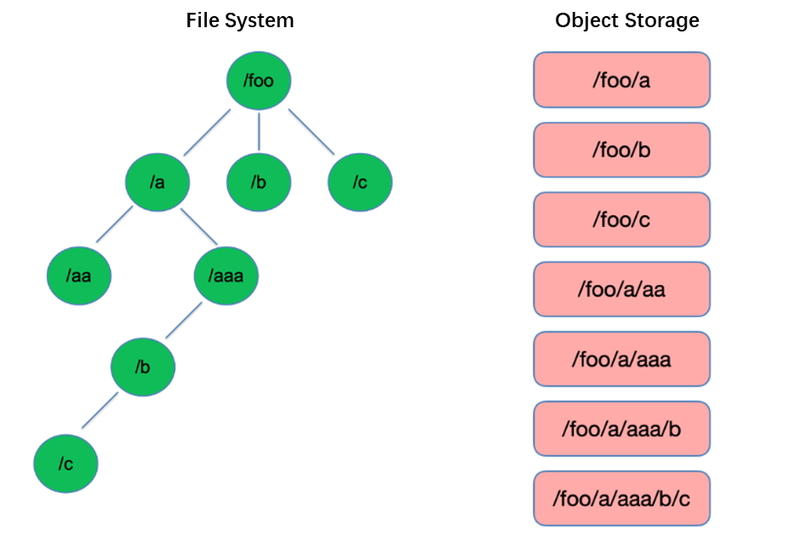
רשימה היא אחת הפעולות הבסיסיות ביותר במערכת הקבצים. זהו פעולה קלה ומהירה במבנים דמויי עץ כמו HDFS.
לעומת זאת, אחסון אובייקטים משתמש במבנה שטוח ודורש אינדקסציה באמצעות מפתחות (מזהים ייחודיים) לאחסון ואיסוף עידן אלפי או אפילו מיליארדי אובייקטים. כתוצאה מכך, כאשר מבוצעת פעולת רשימה, אחסון אובייקטים יכול רק לחפש באינדקס זה, מה שמוביל לביצועים נמוכים בהרבה מאשר במבנים דמויי עץ.
תפיסה מס' 2: חוסר יכולת שינוי שמות אטומיים, המשפיעה על ביצועים ויציבות משימה
במודל חישובים של extract, transform, load (ETL), כל תת-משימה כותבת את התוצאות שלה לספרייה זמנית. כאשר המשימה השלמה מתבצעת, ניתן לשנות את שמות הספרייה הזמנית לשם הספרייה הסופית.
פעולות שמכון אלה הן אטומיות ומהירות במערכות קבצים כמו HDFS, והן מבטיחות עסקאות. עם זאת, מאחר ואחסון אובייקטים אינו כולל מבנה תיקייה מקורי, טיפול בפעולת שמכה היא תהליך מדומה הכולל העתקה רבה של נתונים פנימיים. תהליך זה יכול להיות זמן רב ואינו מספק ביטחונות עסקאות.
כאשר משתמשים משתמשים באחסון אובייקטים, הם בדרך כלל משתמשים בפורמט הנתיב ממערכות הקבצים המסורתיות כמפתח לאובייקטים, כגון "/order/2-22/8/10/detail." במהלך פעולת שמיכה, נדרשת החיפוש אחר כל האובייקטים שמפתחותיהם מכילים את שם התיקייה והעתקת כל האובייקטים באמצעות השם החדש של התיקייה כמפתח. תהליך זה כולל העתקת נתונים, מה שמוביל לביצועים נמוכים בהרבה ממערכות הקבצים, ואף להאטה של סדר אחד או שניים של סדר גודל.
בנוסף, בגלל היעדרות הביטחונות העסקאותיים, יש סיכון של כישלון במהלך התהליך, וכך גורם לנתונים שגויים. ההבדלים הקטנים הללו משפיעים על הביצועים והיציבות של שרשרת המשימות כולה.
חסרון מס' 3: מנגנון העקביות הסופית משפיע על נכונות הנתונים ויציבות המשימה
לדוגמה, כאשר מספר לקוחות יוצרים קבצים בו זמנית תחת נתיב, רשימת הקבצים המתקבלת דרך ה-API של List אינה כוללת מייד כל הקבצים שנוצרו. זמן רב לקח למערכות הפנימיות של אחסון האובייקטים להשיג עקביות נתונים. דפוס גישה זה נמצא לרוב בעיסוק בעיבוד נתונים ETL, ועקביות סופית יכולה להשפיע על נכונות הנתונים ויציבות המשימה.
לכיסות את הבעיה של חוסר היכולת של אחסון עצמים לשמור על עקביות מידע חזקה, AWS השיק מוצר בשם EMRFS. הגישה שלו היא להשתמש בבסיס נתונים נוסף בשם DynamoDB. לדוגמה, כש-Spark כותב קובץ, הוא גם כותב בו זמנית עותק של רשימת הקבצים ל-DynamoDB. נוסדת מנגנון שמשתמש באופן רציף ב-API של List של אחסון העצמים ומשווה את התוצאות שהתקבלו עם התוצאות המאוחסנות במסד הנתונים עד שהן זהות, ואז מחזיר את התוצאות. עם זאת, היציבות של מנגנון זה אינה מספקת מספיק מאחר שהוא יכול להשפיע עליו העומס על האזור בו ממוקם אחסון העצמים, וכך מקבלים ביצועים משתנים. לכן, זו אינה פתרון אידאלי.
חסרון מס' 4: מוגבלת תמיכה ברכיבים של Hadoop
HDFS היה הבחירה העיקרית לאחסון בשלבים הראשונים של מערכת Hadoop, ופותחו רכיבים רבים על סמך API של HDFS. הכנסת אחסון עצמים הביאה לשינויים במבנה האחסון של הנתונים וב-APIs.
לספקי הענן יש צורך לשנות את המחברים בין הרכיבים לבין אחסון עצמים בענן, כמו גם לתקן את הרכיבים העליונים כדי להבטיח תמיכה. משימה זו מטפלת עומס גדול על ספקי הענן הציבוריים.
כתוצאה מכך, מספר הרכיבים המתוכנתים הנתמכים בפלטפורמות בינאריות גדולות המוצעות על ידי ספקי הענן הציבוריים הוא מוגבל, ובדרך כלל כולל רק גרסאות מסוימות של Spark, Hive ו-Presto. המגבלה הזו מהווה אתגר עבור העברת פלטפורמות בינאריות גדולות לענן או למשתמשים עם דרישות מסוימות להתפרסות ורכיבים משלהם.
לייצר ביצועים חזקים מאחסנות אובייקט תוך שמירה על האמינות של מערכת הקבצים, חברות יכולות להשתמש באחסון אובייקט + JuiceFS.
אחסון אובייקט + JuiceFS
כאשר משתמשים רוצים לבצע חישובים מורכבים, ניתוח ואימון על אחסון אובייקט, עצמו אחסון אובייקט אולי לא יספיק כדי לעמוד בדרישות העסקיות של הארגון. זו הסיבה המרכזית לפיתוחו של Juicedata של JuiceFS, שמטרתו לתת לקסם את המגבלות של אחסון אובייקט.
JuiceFS היא מערכת קבצים מרוחקת, בינלאומית בביצועים גבוהים המיועדת לענן פתוח המקור.יחד עם אחסון אובייקט, JuiceFS מספק פתרונות בעלי עלות נמוכה למצבים עשירים בנתונים כגון חישוב, ניתוח ואימון.
איך JuiceFS + אחסון אובייקט עובד
התרשים להלן מציג את פריסת JuiceFS בתוך קבוצת הארדון.
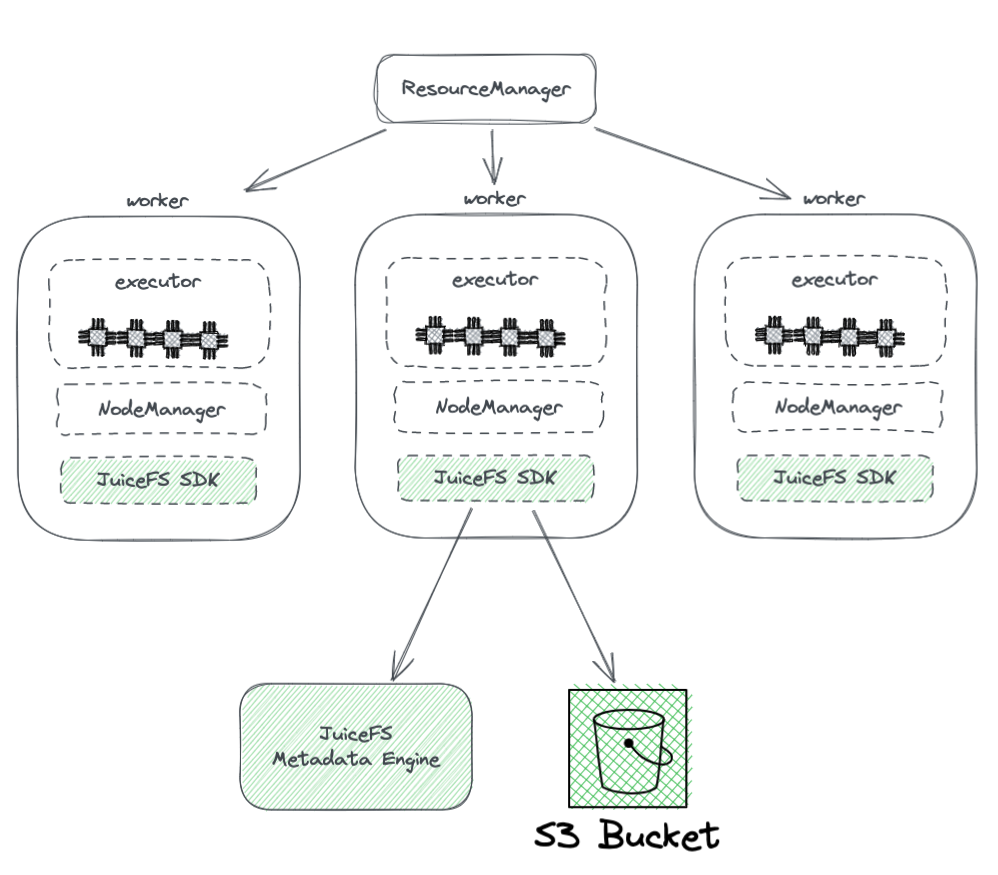
מהתרשים, אנו יכולים לראות את הנקודות הבאות:
- כל צמדי העובדים שנשלטים על ידי YARN נושאים SDK של JuiceFS Hadoop, שיכול להבטיח את השלמה התאמה עם HDFS.
- ה-SDK גולש בשני רכיבים:
-
מנוע המסמך של JuiceFS: מנוע המסמכים משמש כמעמד ל-HDFS' NameNode. הוא מאחסן את מידע המסמכים של מערכת הקבצים כולה, כולל מספרי תיקיות, שמות קבצים, הרשאות ושעות זמני, ומתמודד עם אתגרי ההתרחבות ו-GC שעומדים בפני NameNode של HDFS.
-
חצר S3: הנתונים מאוחסנים בחצר S3, שניתן לראות בה כאנלוג ל-DataNode של HDFS. ניתן להשתמש בה כבמספר גדול של דיסקים, המנוהלים את מפעל האחסון והשכפול של הנתונים.
-
-
JuiceFS מורכב משלושה רכיבים:
- SDK של JuiceFS Hadoop
- מנוע המסמך
- חצר S3
יתרונות של Juicefs על שימוש ישיר באחסון אובייקטים
JuiceFS מציע מספר יתרונות בהשוואה לשימוש ישיר באחסון אובייקטים:
- שלמות תאימות עם HDFS: זה מתבצע על ידי עיצוב התחלתי של JuiceFS לתמיכה מלאה ב-POSIX. סיבובייט POSIX יותר מכסה ומורכב מאשר HDFS.
- יכולת לשימוש עם HDFS קיים ואחסון אובייקטים: תודות לעיצוב המערכת של הדון, JuiceFS יכול לשמש יחד עם מערכות HDFS ואחסון אובייקטים קיימות מבלי צורך בהחלפה מלאה. בצבר הדון, ניתן להגדיר מספר מערכות קבצים, מה שמאפשר ל-JuiceFS ו-HDFS להתקיים ולשתף פעולה. ארכיטקטורה זו מבטלת את הצורך בהחלפה מלאה של צברי HDFS קיימים, מה שמעורב במאמץ רב וסיכונים.
- ביצועים מטמון מסמכים חזקים: JuiceFS מפריד את מנוע המטמון מ-S3 ולא מסתמך על ביצועי מטמון S3. זה מבטיח ביצועים מטמון מסמכים מיטביים. כשמשתמשים ב-JuiceFS, הפעילויות עם האחסון האובייקטי הבסיסי מצטמצמות לפעולות בסיסיות כמו Get, Put ו-Delete. ארכיטקטורה זו מתגברת על המוגבלויות של ביצועי מטמון אובייקטים ומבטלת בעיות הקשורות לקיום קביעות סופית.
- תמיכה בשינוי שמות אטומיים: JuiceFS תומכת בפעולות שינוי שמות אטומיות בזכות מנוע התבניות העצמאי שלה. מטמון משפר את ביצועי הגישה לנתונים חמים ומספק את תכונת המקומיות של הנתונים: בעזרת המטמון, נתונים חמים אינם צריכים להתבקש ממיקור האובייקטים דרך הרשת בכל פעם. בנוסף, JuiceFS מיישם את API מקומיות הנתונים הספציפיים ל-HDFS, כך שכל רכיבי השכבה העליונה התומכים במקומיות של הנתונים יכולים לשחזר את המודעות לנוגעיות הנתונים. זה מאפשר ל-YARN לקדם את תזמון המשימות על צמתים בהם נבנה מטמון, וכתוצאה מכך משולבים ביצועים דומים ל-HDFS עם אחסון ומחשבה מחוברים.
- JuiceFS תואם את POSIX, מה שמקל על השתלבותו עם יישומים קשורים ללמידה ממוחשבת ו-AI.
מסקנה:
עם התפתחות צרכי העסקים והתקדמות הטכנולוגיות, עיקרון הארכיטקטורה של אחסון ומחשבה עבר שינויים, מחיבור להפרדה.
ישנם מספר גישות שונות להשגת הפרדת אחסון ומחשבה, כולם עם יתרונות וחסרונות משלהם. זה יכול להסתכם בבניית HDFS בענן, בשימוש בפתרונות של הענן הציבורי התואמים את הדןופ ואף באסטרטגיות כמו אחסון אובייקטים + JuiceFS, המתאימות לחישובים ואחסון גדולים מורכבים בענן.
עבור תאגידים, אין כפפה כסף, והמפתח הוא בבחירת הארכיטקטורה על פי הצרכים הספציפיים שלהם. עם זאת, פשטות היא תמיד הברכה המושלמת.
אודות המחבר
רוי סו, שותף ב-Juicedata, היה חבר מייסד שעוסק בפיתוח השלמ של מוצר JuiceFS, השוק וקהילת המקור הפתוח מאז 2017. עם 16 שנות ניסיון בתעשייה, שירת בתפקידים כמו מפתח, מנהל מוצר ומייסד בתוכנה, אינטרנט וארגונים לא ממשלתיים.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora