













בחלק 1 של סדרה זו, בדקנו את MongoDB, אחת המאגרים המבוססים על מסמכים (document-oriented) NoSQL האמינים והחזקים ביותר. כאן ב
חלק 2, נבדוק עוד NoSQL בלתי נמנע: Elasticsearch.Elasticsearch הוא יותר מרק מאגר נתונים מבוזר NoSQL פופולרי וחזק, זה קודם כל מנוע חיפוש וניתוח. הוא בנוי על Apache Lucene, ספריית Java לחיפוש הידועה ביותר, ומסוגל לבצע חיפוש וניתוח בזמן אמת על נתונים מובנים ולא מובנים. הוא מעוצב לטפל בכמויות גדולות של נתונים ביעילות.
שוב, עלינו להכריז שהפוסט הקצר הזה בשום אופן לא הוא הדרכה לElasticsearch. על הקורא להשתמש בתיעוד הרשמי באופן נרחב, כמו גם בספר המצוין "Elasticsearch in Action" של Madhusudhan Konda (Manning, 2023) כדי ללמוד יותר על ארכיטקטורת המוצר והתפעולים שלו. כאן, אנחנו רק מיישמים מחדש את אותו מקרה של שימוש כמו בעבר, אבל הפעם בשימוש בMongoDB.
אז, בא נתחיל!
מודל התחום
התרשים שלהלן מראה את מודל התחום שלנו *customer-order-product*:
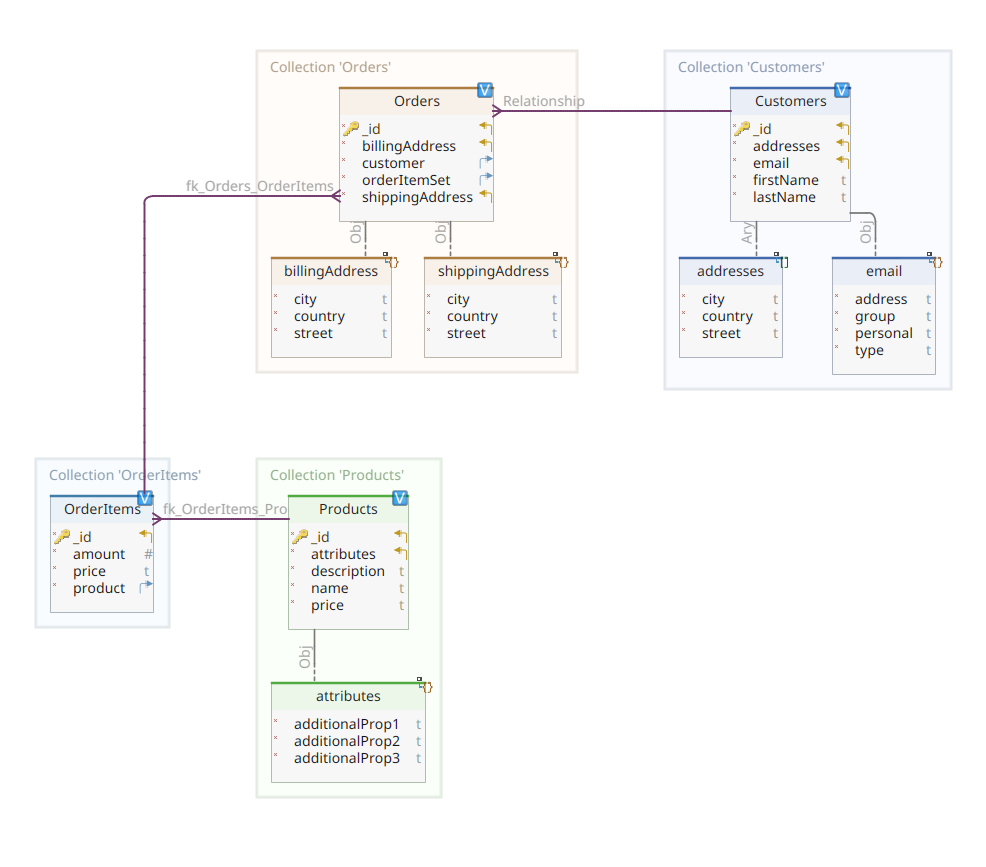
הדיאגרמה הזו זהה לזו שהוצגה בחלק 1. כמו MongoDB, גם Elasticsearch הוא אחסון נתונים תיעודי וכך, הוא מצפה שהתיעוד יוצג בתיביות JSON. ההבדל היחיד הוא שעל מנת להתמודד עם הנתונים, Elasticsearch צריך להקליט אותם.
יש מספר דרכים שבהן נתונים יכולים להיות מוקלטים באחסון נתונים של Elasticsearch; לדוגמה, להעביר אותם ממסד נתונים רגיל, לחלץ אותם ממערכת קבצים, לשדר אותם ממקור חי, וכן הלאה. אבל בין אם זו שיטת קליטה כלשהי, זה לבסוף כולל ביצוע של API RESTful של Elasticsearch דרך לקוח מיוחד. יש שתי קטגוריות של לקוחות כאלה:
- לקוחות מבוססי REST כמו
curl,Postman, מודולי HTTP עבור Java, JavaScript, Node.js, וכן הלאה. - מערכות פיתוח תוכנה (SDKs): Elasticsearch מספק SDKs עבור כל השפות הפיתוח הנפוצות ביותר, כולל, אך לא רק, Java, Python, וכן הלאה.
ליצור תיעוד חדש עם Elasticsearch אומר ליצור אותו באמצעות בקשת POST כנגד נקודת סוף RESTful מיוחדת בשם _doc. לדוגמה, הבקשה הבאה תיצור אינדקס Elasticsearch חדש ותאחסן מופע חדש של לקוח בתוכו.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}ביצוע הבקשה לעיל באמצעות curl או שולחן המכוונים (כפי שנראה אחר כך) יפיק את התוצאה הבאה:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
זוהי התגובה הסטנדרטית של Elasticsearch לבקשת POST. היא מאשרת שיצר את המדינה בשם customers, ויש לו מסמך חדש customer, שמזוהה על ידי מזהה שנוצר אוטומטית (במקרה זה, ZEQsJI4BbwDzNcFB0ubC).
פרמטרים מעניינים אחרים מופיעים כאן, כמו _version ובמיוחד _shards. בלי להיכנס לפרטים רבים, Elasticsearch יוצר מדינות כאוסף לוגי של מסמכים. בדומה לשמירת מסמכים נייריים בארכיון, Elasticsearch שומר מסמכים במדינה. כל מדינה מורכבת משרדים, שהם מופעים פיזיים של Apache Lucene, המנוע מאחורי הקלעים האחראי להבאת המידע לתוך או מתוך האחסון. הם עשויים להיות או עיקריים, ששומרים מסמכים, או מעתיקים, ששומרים, כמו ששמם מרמז, העתקים של שרדים עיקריים. יותר על כך בתיעוד של Elasticsearch – לרגע זה, אנחנו צריכים לשים לב שהמדינה שלנו בשם customers מורכבת משני שרדים: מתוכם אחד, כמובן, עיקרי.
A final notice: the POST request above doesn't mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn't POST anymore, but PUT.
לחזור לתרשים של מודל התחום, כפי שאתם יכולים לראות, המסמך המרכזי שלו הוא Order, המאוחסן באוסף מיוחד בשם Orders. Order הוא אגרגט של מסמכים OrderItem, כל אחד מהם מצביע לProduct המקושר אליו. מסמך Order מציין גם את Customer שהזמין אותו. בJava, זה מיושם כך:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
הקוד לעיל מראה חלק מהכתבה של המחלקה Customer. זהו עצם פשוט של POJO (Plain Old Java Object) שיש לו תכונות כמו מזהה ללקוח, שם פרטי ושם משפחה, כתובת אימייל ומערך של כתובות דואר.
בואו נבדוק עכשיו את המסמך Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
כאן אתה יכול לשים לב לכמה הבדלים בהשוואה לגרסה של MongoDB. למעשה, עם MongoDB, השתמשנו בהפניה למשתנה של הלקוח המקושר להזמנה הזו. המושג הזה של הפניה לא קיים ב-Elasticsearch, ולכן אנחנו משתמשים במזהה של המסמך הזה כדי ליצור אסוציאציה בין ההזמנה ללקוח שהזמין אותה. אותו הדבר נכון גם לגבי התכונה orderItemSet שיצור אסוציאציה בין ההזמנה לאיבריה.
שאר מודל התחום שלנו די דומה ומבוסס על אותם רעיונות של נורמליזציה. לדוגמה, המסמך OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
כאן, אנחנו צריכים לשייך את המוצר שמהווה את האובייקט של האיבר הנוכחי של ההזמנה. אחרון אבל לא פחות חשוב, יש לנו את המסמך Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}מאגרי הנתונים
Quarkus Panache מפשט מאוד את תהליך שמירת הנתונים על ידי תמיכה בשני תבניות עיצוב: רשומה פעילה ו-מאגר. בחלק 1, השתמשנו בהרחבת Quarkus Panache עבור MongoDB כדי ליישם את מאגרי הנתונים שלנו, אך עדיין אין הרחבה מקבילה של Quarkus Panache עבור Elasticsearch. לכן, בהמתנה לאפשרות של הרחבה עתידית של Quarkus עבור Elasticsearch, כאן עלינו ליישם באופן ידני את מאגרי הנתונים שלנו באמצעות לקוח Elasticsearch המוקדש.
Elasticsearch נכתב בשפת Java ולכן אין זה מפתיע שהוא מספק תמיכה טבעית לקריאת API של Elasticsearch באמצעות לקוח ה-Java. ביבליות זו מבוססת על תבנית עיצוב של בונה API רציף ומספקת דגמי עיבוד סינכרוניים ואסינכרוניים. היא דורשת לפחות Java 8.
אז, איך נראים מאגרי הנתונים שלנו המבוססים על בונה API רציף? להלן קטע מהקלסה CustomerServiceImpl שמשמש כמאגר נתונים עבור המסמך Customer.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
כפי שאנחנו רואים, היישום של מאגר הנתונים שלנו צריך להיות בישול CDI עם טווח שליישום. לקוח Java של Elasticsearch מוזרק בקלות, תודות להרחבת quarkus-elasticsearch-java-client של Quarkus. דרך זו נמנעת מאיתנו הרבה פירוטים שהיינו צריכים להשתמש בהם אחרת. הדבר היחיד שאנחנו צריכים כדי להזריק את הלקוח הוא להכריז על המאפיין הבא:
quarkus.elasticsearch.hosts = elasticsearch:9200כאן, elasticsearch הוא שם ה-DNS (שרת שם תחום) שאנחנו מקשרים עם שרת בסיס הנתונים של Elastic search בקובץ docker-compose.yaml. 9200 הוא מספר הפורט TCP שהשרת משתמש בו להאזנה לחיבורים.
השיטה doIndex() לעיל יוצרת מאגר חדש בשם customers אם הוא לא קיים ומאינדקס (שומר) בו מסמך חדש המייצג מופע של הכתב Customer. תהליך האינדקסינג מבוצע על ידי IndexRequest שמקבל כארגומנטים שם המאגר וגוף המסמך. בנוגע למזהה של המסמך, הוא נוצר אוטומטית ומוחזר לקול-אחר עבור התייחסות נוספת.
השיטה הבאה מאפשרת לשלוף את הלקוח המזוהה על ידי מזהה שניתן כארגומנט הקלט:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
העיקרון הוא אותו: באמצעות התבנית fluent API הבונה, אנחנו בונים מקרה GetRequest באותה דרך שבה עשינו עם IndexRequest, ואנחנו מריצים אותו כנגד לקליינט Java של Elasticsearch. הנקודות האחרות של מאגר הנתונים שלנו, שמאפשרות לנו לבצע אופרציות חיפוש מלאות או לעדכן ולמחוק לקוחות, עוצבו באותה דרך.
בבקשה קחו זמן להתבונן בקוד כדי להבין איך דברים עובדים.
API REST
הממשק של MongoDB REST API שלנו היה קל ליישום, תודות לתוסף quarkus-mongodb-rest-data-panache, שבו מעבד האנוטציות יוצר אוטומטית את כל הנקודות הנחוצות. עם Elasticsearch, אנחנו עדיין לא מקבלים את אותו הנוחות ולכן צריך ליישם זאת ידנית. זה לא דבר גדול, כי אנחנו יכולים להזריק את מאגרי הנתונים הקודמים, כפי שמוצג להלן:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}זוהי היישומית של REST API ללקוח. האחרות הקשורות להזמנות, פריטי הזמנה ומוצרים דומות.
בואו נראה כעת איך להריץ ולבדוק את כל הדבר.
הרצה ובדיקת המיקרוסרביסים שלנו
עכשיו כשהסתכלנו על הפרטים של היישום שלנו, בואו נראה איך להריץ ולבדוק אותו. בחרנו לעשות זאת עם המשולש docker-compose. הנה קובץ docker-compose.yml המתאים:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
קובץ זה מורה למשולש docker-compose להריץ שלוש שירותים:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
עכשיו, אתה יכול לבדוק שכל התהליכים הנחוצים רצים:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
כדי לאשר ששרת Elasticsearch זמין ומסוגל לרוץ שאילתות, אתה יכול להתחבר ל Kibana בכתובת http://localhost:601. אחרי שהורדת למטה בדף ובחרת Dev Tools בתפריט ההעדפות, אתה יכול לרוץ שאילתות כפי שמוצג להלן:
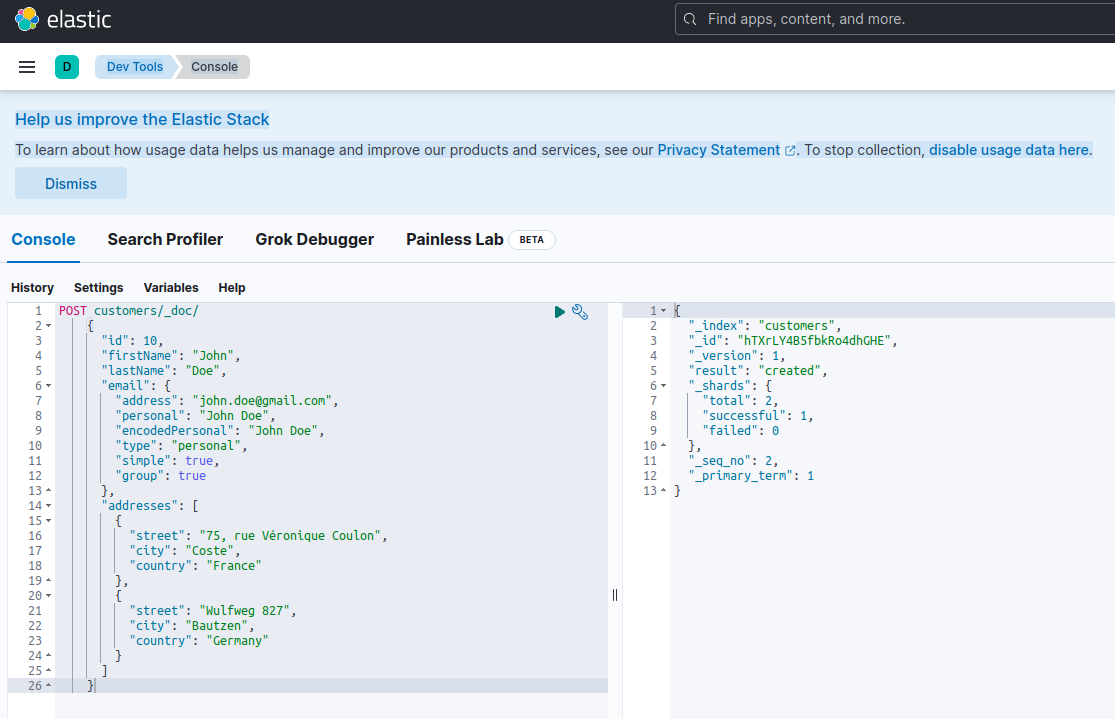
כדי לבדוק את המיקרוסרביסים, תנהג כך:
1. העתק את המאגר המתאים ב GitHub:
$ git clone https://github.com/nicolasduminil/docstore.git2. לך לפרויקט:
$ cd docstore3. עבור לענף הנכון:
$ git checkout elastic-search4. בנה:
$ mvn clean install5. הרץ את בדיקות האינטגרציה:
$ mvn -DskipTests=false failsafe:integration-testפקודה זו תריץ את 17 מבדקי האינטגרציה המוצעים, שכולם צריכים להצליח. ניתן גם להשתמש בממשק Swagger UI למטרות בדיקה על ידי פתיחת הדפדפן המועדף שלך בכתובת http://localhost:8080/q:swagger-ui. לשם בדיקת נקודות קצה, ניתן להשתמש בעומס בקבצי JSON הנמצאים בתיקייה src/resources/data של פרויקט docstore-api.
תענגו!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse