













היישומים לעתים קרובות תופסים את רוב נכסי הנתונים של חברה. דוגמאות ליומנים כוללות יומני עסקים (כגון יומני פעילות משתמש) ויומני תפעול ותיקון של שרתים, מסדי נתונים, רשת או מכשירים IoT.
יומנים הם מלאכי השליטה של העסק. מצד אחד, הם מספקים אזהרות סיכון של מערכת ועוזרים למהנדסים למצוא את הסיבות השורשיות במהירות בזיהוי בעיות. מצד שני, אם מתקרבים אליהם על פי טווח זמן, יכולים לזהות כמה מגמות ודפוסים מועילים, שלא לדבר על כך שיומני העסק הם היסוד לתובנות על המשתמש.
עם זאת, יומנים יכולים להיות מטרדה מפני הסיבות הבאות:
- הם זורמים כמעט בטירוף. כל אירוע במערכת או לחיצה מהמשתמש יוצרת יומן. חברה בדרך כלל מייצרת עשרות ביליוני יומנים חדשים בכל יום.
- הם עצומים. יומנים אמורים להישאר. ייתכן שלא יהיו שימושיים עד שהם כן. לכן חברה יכולה לאסוף עד לכמה טרה-בייטים של נתוני יומן, רבים מהם נצפים לעתים רחוקות אך תופסים מקום מכריע במאגרי האחסון.
- עליהם להיות זמינים במהירות ולמצוא בקלות. מציאת יומן המטרה לפתרון בעיות היא כמעט כמו מציאת מחט בערימת הדוממת. אנשים משתוקקים לכתיבת יומנים בזמן אמת ותגובות מיידיות לשאילתות יומנים.
עכשיו אפשר לראות תמונה ברורה של מהו מערכת עיבוד יומנים אידאלית. היא צריכה לתמוך בארבעת הנקודות הבאות:
- ספיגת נתונים בזמן אמת בתוך עומס גבוה: עליה להיות מסוגלת לכתוב יומנים בקנה מידה גדול ולהפוך אותם לזמינים מייד.
- אחסון זול: היא צריכה להיות מסוגלת לאחסן כמויות נרחבות של יומנים מבלי לעלות מדי במחיר.
- חיפוש טקסט בזמן אמת: עליו להיות מסוגל לחיפוש טקסט מהיר.
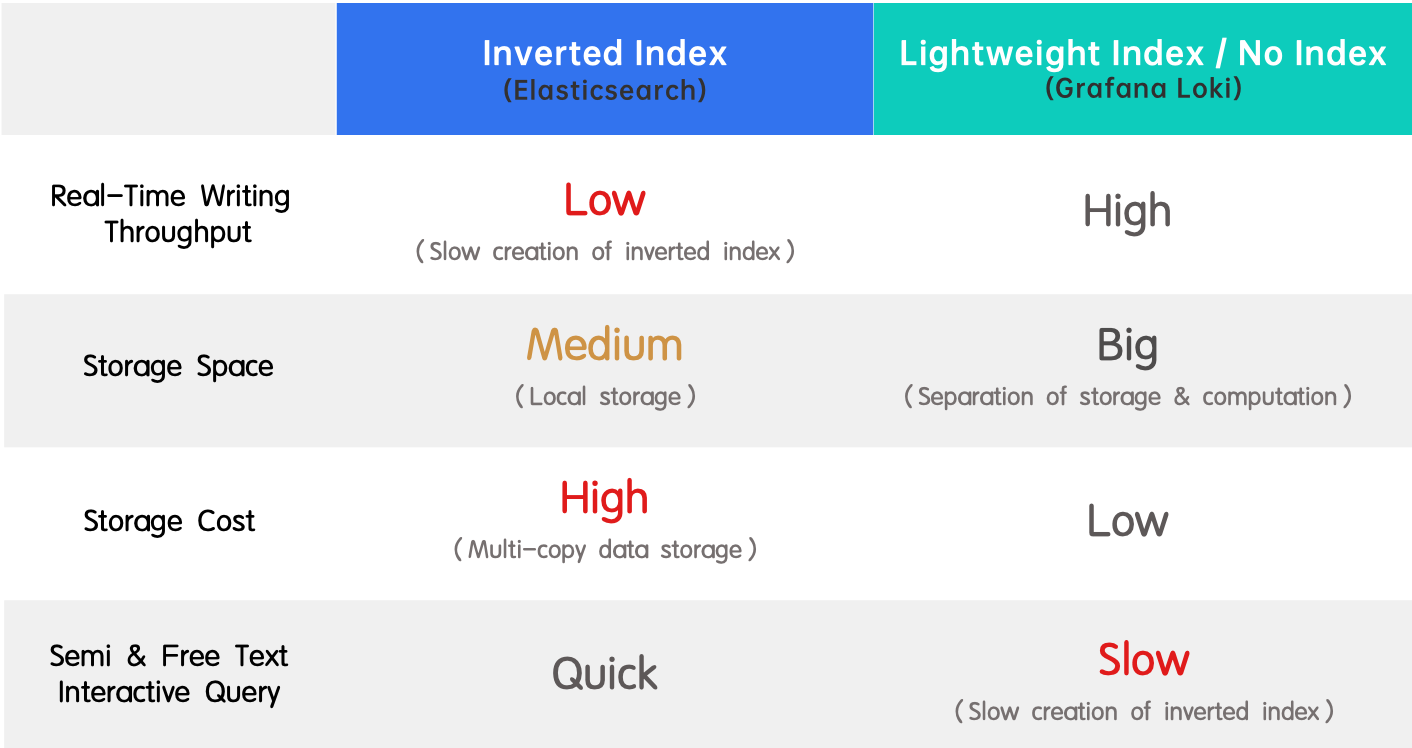
פתרונות נפוצים: Elasticsearch ו-Grafana Loki
קיימים שני פתרונות נפוצים לעיבוד יומנים בתעשייה, שמודגמים על ידי Elasticsearch ו-Grafana Loki, בהתאמה.
- מיון הפוך (Elasticsearch): הוא נאהב בזכות התמיכה בחיפוש שלמות הטקסט וביצועים גבוהים. החיסרון הוא התורן הנמוך בכתיבה בזמן אמת וצריכת משאבים גדולה ביותר ביצירת האינדקס.
- אינדקס קליל / אין אינדקס (Grafana Loki): הוא ההפך ממיון הפוך מכיוון שהוא מצטיין בתורן גבוה בכתיבה בזמן אמת ועלות שמטוחשת נמוכה, אך משיג חיפושים איטיים.
הקדמה למיון הפוך
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
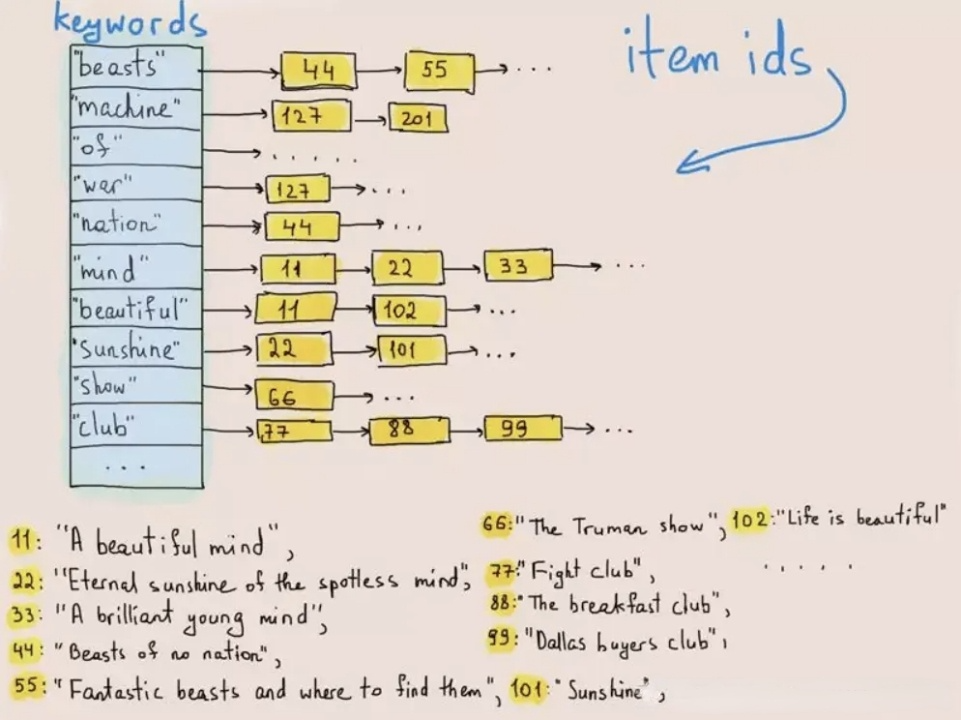
מיון הפוך פותח במקור לאחסון מילים או ביטויים בטקסטים. התרשים להלן מסביר איך זה עובד:
בכתיבת נתונים, המערכת מפרקת טקסטים ל-מונחים ומאחסנים את המונחים אלו ב-רשימת הפוסטינג הממפה מונחים למספר השורה בה הם קיימים. בחיפושי טקסט, מסד הנתונים מוצא את המספר השורה המתאים למילה המפתח (מונח) ברשימת הפוסטינג ומפנה את השורה המבוקשת על פי מספר השורה. בכך, המערכת לא תצטרך לעבור על כל המאגר וכך תשפר את מהירות החיפוש בסדרי גודל רבים.
באינדקס הפוך של Elasticsearch, השיגור המהיר מגיע על חשבון מהירות הכתיבה, תוצאות הכתיבה ומרחב האחסון. מדוע? קודם כל, הפיכת טקסט למילים, מיון מילון ויצירת אינדקס הפוך הם פעולות שדורשות ממומחי CPU וזיכרון. שנית, Elasticssearch חייב לאחסן את הנתונים המקוריים, את האינדקס הפוך ועוד עותק של הנתונים המאוחסנים בעמודות לקידום השאילתות. זהו שכפול כפול.
אבל בלי אינדקס הפוך, Grafana Loki, למשל, פוגע בחוויה של המשתמש עם השאילתות האיטיות שלו, שזו העיכוב הכי גדול עבור המהנדסים בניתוח היומן.
בפשטות, Elasticsearch ו-Grafana Loki מייצגים ביניים שונים בין תוצאות כתיבה גבוהות, עלות אחסון נמוכה וביצועים שאילתא מהירים. מה אם אומר לך שיש דרך לקבל את כולם? הצגנו אינדקסים הפוכים ב-Apache Doris 2.0.0 וביצענו שיפור נוסף כדי להגיע ל-פעמיים מהירות שאילתת יומן מאשר Elasticsearch בשימוש ב-1/5 ממרחב האחסון שלו. שני הגורמים יחד, זו פתרון טוב פי 10.
אינדקס הפוך ב-Apache Doris
בדרך כלל, יש שתי דרכים ליישם אינדקסים: מערכת אינדקס חיצונית או אינדקסים מובנים.
מערכת אינדקסון חיצונית: אתה מחבר מערכת אינדקסון חיצונית לבסיס הנתונים שלך. בספיגת נתונים, נוספים נתונים לשתי המערכות. לאחר שהמערכת האינדקסונית יוצרת אינדקסים, היא מוחקת את הנתונים המקוריים בתוכה. כאשר משתמשי נתונים מזינים שאילתה, המערכת האינדקסונית מספקת את מספרי הסימון של הנתונים הרלוונטיים, ואז המסד נתונים מחפש את הנתונים המטרתיים על פי המספרים האלה.
הקמת מערכת אינדקסון חיצונית קלה יותר ופחות מפריעה למסד הנתונים, אך יש לה כמה פגמים מעצבנים:
- הצורך לכתוב נתונים לשתי המערכות עלול לגרום לחוסר עקביות בנתונים ולעודף באחסון.
- האינטראקציה בין המסד נתונים למערכת האינדקסון מביאה עלויות נוספות, ולכן כשהנתונים המטרתיים הם גדולים, השאילתה בין שתי המערכות עלולה להיות איטית.
- זה מתיש לשמור על שתי המערכות.
ב Apache Doris, אנו מעדיפים את הדרך השנייה. אינדקסים מובנים הפוכים קשים יותר ליצור, אך ברגע שזה נעשה, זה מהיר יותר, ידידותי יותר למשתמש, ובכלל לא מפריע לשמור עליו.
ב-Apache Doris, הנתונים מסודרים בפורמט הבא. האינדקסים מאוחסנים באזור האינדקס:
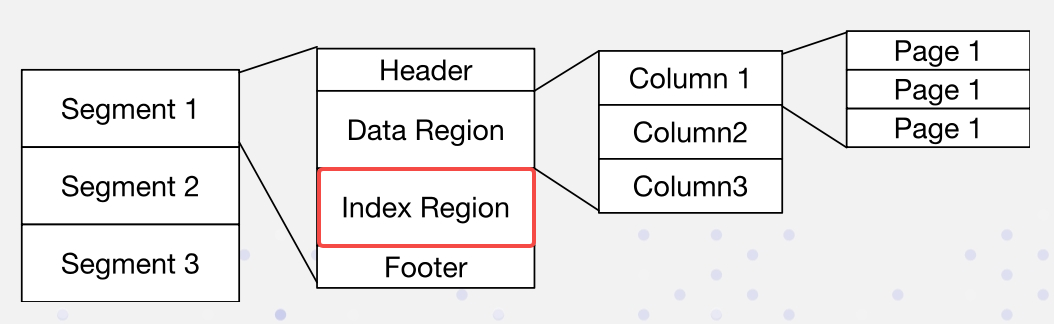
אנו מיישמים אינדקסים הפוכים באופן לא מפריע:
- ספיגת נתונים וקומפקטציה: כשקובץ קטגוריה מוכנס ל-Doris, גם קובץ אינדקס הפוך ייכתב. כתובת קובץ האינדקס נקבעת על ידי מספר הקטגוריה ומספר האינדקס. השורות בקטגוריות מתאימות למסמכים באינדקסים, כך גם RowID ו-DocID.
- שאילתה: אם הפירוט
whereכולל עמודה עם אינדקס הפוך, המערכת תבדוק בקובץ האינדקס, תחזיר רשימת DocID, ותמיר את רשימת הDocID למטריצת RowID Bitmap. תחת מניעת סנן RowID של Apache Doris, יקראו רק השורות המטריות. כך מאוד מאופשרת שיפור מהירות שאילתות.
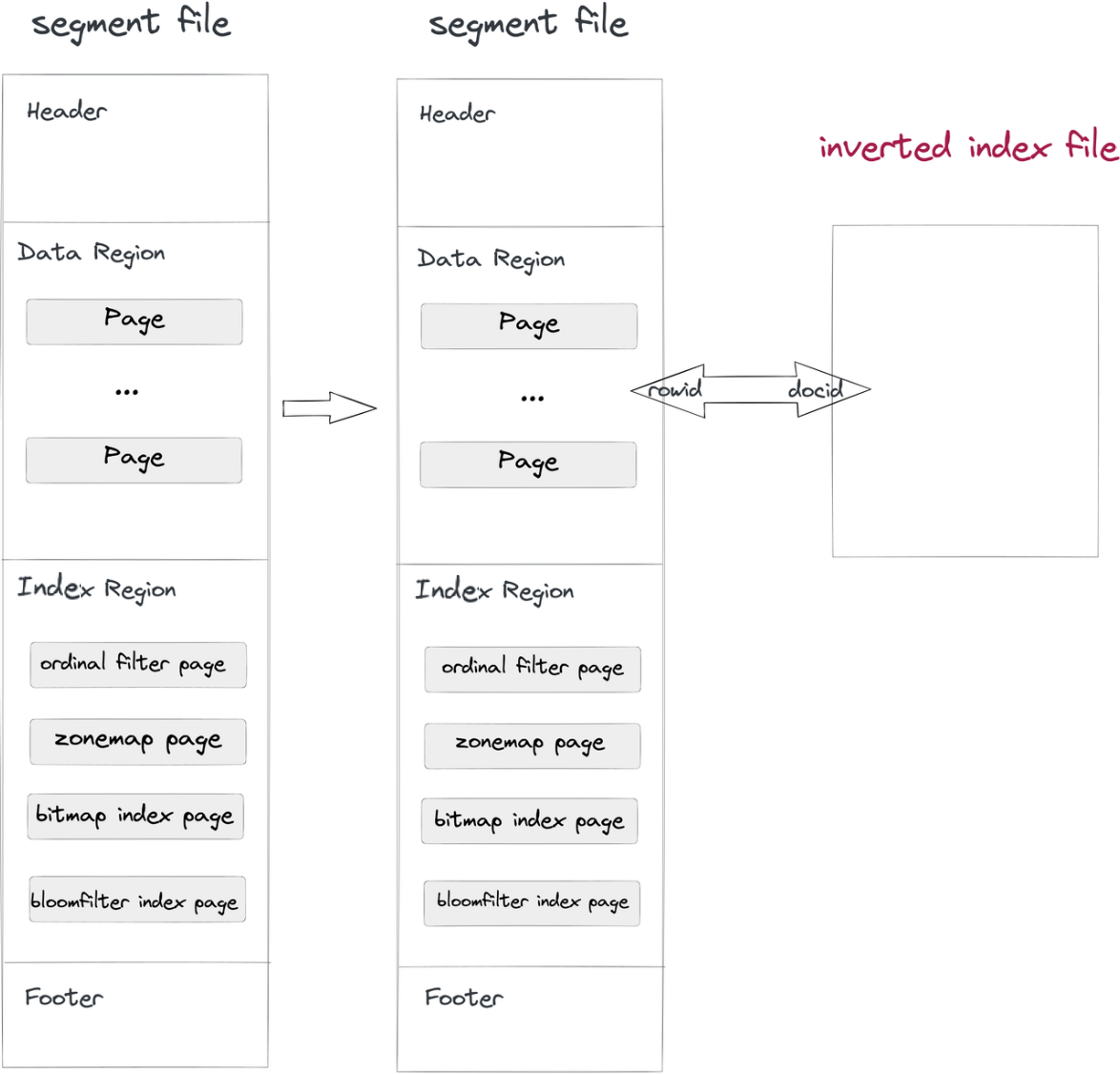
שיטה כזו לא פוגעת מפרידה בין קובץ האינדקס לקבצי הנתונים, כך שאפשר לבצע שינויים כראוי באינדקסים ההפוכים מבלי לדאוג שזה ישפיע על קבצי הנתונים עצמם או על אינדקסים אחרים.
שיפורים עבור אינדקס הפוך
שיפורים כלליים
C++ Implementation and Vectorization
בשונה מ-Elasticsearch, שמשתמש ב-Java, Apache Doris מיישם ב-C++ את מודולי האחסון, מנוע ביצוע השאילתות, ואת האינדקסים ההפוכים. לעומת Java, C++ מספק ביצועים טובים יותר, מאפשר קיצור וקיטור קל יותר, ולא מייצר מעתה הישגי JVM. מקצרים כל שלב של אינדקס הפוך ב-Apache Doris, כגון טוקנולוגיה, יצירת אינדקס, ושאילתות. כדי לתת לך נקודת מבט, באינדקס הפוך, Apache Doris כותב נתונים בקצב של 20MB/s לליבה, שזה ארבעה פעמים יותר מ-Elasticsearch (5MB/s).
אחסון עמודתי ודחיסה
Apache Lucene הוא היסוד לאינדקסים ההפוכים ב-Elasticsearch. מאחר ש-Lucene עצמו בנוי לתמוך באחסון קבצים, הוא מאחסן נתונים בפורמט ממוקד שורה.
ב-Apache Doris, אינדקסים הפוכים עבור עמודות שונות מופרדים זה מזה, וקבצי האינדקס ההפוכים משתמשים באחסון עמודתי כדי לקלות בקטוריזציה ודחיסת נתונים.
באמצעות דחיסת Zstandard, Apache Doris משיג יחס דחיסה של 5:1 עד 10:1, מהירות דחיסה מהירה יותר ושימוש ב-50% פחות מקום מאשר דחיסת GZIP.
מערכי BKD עבור עמודות מספריות / תאריך-זמן
Apache Doris מיישם עצי BKD עבור עמודות מספריות ותאריך-זמן. זה לא רק מעלה את ביצועי השאילתות לטווח קצר אלא גם מהווה שיטה יותר זולה במרחב מאשר המרת עמודות אלה למחרוזות באורך קבוע. יתרונות נוספים של זה כוללים:
- שאילתות טווח יעילות: זה מסוגל למצוא במהירות את טווח הנתונים המטרה בעמודות מספריות ותאריך-זמן.
- פחות מקום אחסון: זה מצרף ודוחס מרכיבים נתונים סמוכים כדי להפחית את עלויות האחסון.
- תמיכה בנתונים רב-ממדיים: עצי BKD הם נרחבים ומותאמים אישית לסוגי נתונים רב-ממדיים, כמו נקודות GEO וטווחים.
פרט לעצי BKD, ביצענו מאמצים נוספים לשיפור השאילתות על עמודות מספריות ותאריך-זמן.
- אופטימיזציה לתרחישים בעלי קרדינליות נמוכה: ביצענו כוונון מדויק של האלגוריתם הדחיסה עבור תרחישים בעלי קרדינליות נמוכה, כך שהתרוקנות והפיכת רשימות הפוך גדולות יצרות פחות משאבי CPU.
- קידום מראש: עבור תרחישים בעלי שיא תוצאות, אנו משתמשים בקידום מראש. אם שיא התוצאות עובר סף מסוים, Doris ידלג על תהליך האינדקסון ויתחיל בסינון נתונים.
אופטימיזציות מותאמות אישית ל-OLAP
בדרך כלל, ניתוח יומני התיקונים הוא סוג פשוט של שאילתה שאינה זקוקה לתכונות מתקדמות (למשל, ציון רלוונטיות ב-Apache Lucene). היכולת הבסיסית של כלי עיבוד יומני התיקונים היא שאילתות מהירות ועלויות אחסון נמוכות. לכן, ב-Apache Doris, חיסכנו את מבנה האינדקס ההפוך כדי לעמוד בצרכים של מסד נתונים OLAP.
- בסריקת נתונים, אנו מונעים ממספר קוי עבודה מלכתחילה לכתוב נתונים לתוך אותו אינדקס ובכך נמנעים מעלויות הנגרמות ממתיחת מנעולים.
- אנו זורקים את קבצי האינדקס הקדמיים ואת קבצי ה-Norm כדי לנקות מרחב אחסון ולהפחית את עלויות ה-I/O.
- אנו פשטנו את ההיגיון המחשבתי של ציון רלוונטיות ודירוג כדי להפחית גורם עלויות נוספת ולהעלות את הביצועים.
בהתחשב בעובדה שהיומנים מחולקים לפי טווח זמן ויומנים היסטוריים נצפים פחות לעתים קרובות, אנו מתכננים לספק ניהול אינדקסים יותר דקדוקי וגמישים בגרסאות הבאות של Apache Doris:
- יצירת אינדקס הפוך לפילוח נתונים מסוים: יצירת אינדקס ליומנים של שבעת הימים האחרונים וכד'.
- מחיקת אינדקס הפוך לפילוח נתונים מסוים: מחיקת אינדקס ליומנים מלפני חודש ואילך (כדי לנקות את מרחב האינדקס).
בדיקות תקן
בדקנו את Apache Doris על קבצי נתונים זמינים לכולם מול Elasticsearch ו-ClickHouse.
לשם השוואה הוגנת, הבטחנו את התאמת התנאים הבדיקה, כולל כלי בדיקות, קבצי נתונים וחומרה.
Apache Doris מול Elasticsearch
- כלי מדידה: ES Rally, כלי הבדיקה הרשמי עבור Elasticsearch
- מערך נתונים: יומני שרת ה-HTTP של גביע העולם 1998 (מערך נתונים מוכלל ב-ES Rally)
- גודל נתונים (לפני דחיסה): 32G, 247 מיליון שורות, 134 בתים לשורה (בממוצע)
- שאילתות: 11 שאילתות, כולל חיפושים מילוליים, שאילתות טווח, אסכומים ודירוג; כל שאילתה מבוצעת סדרתית 100 פעמים.
- סביבה: 3 מחשבים וירטואליים ענקיים בעלי 16C 64G
תוצאות של Apache Doris:
- קצב כתיבה: 550 MB/s,4.2 פעמים מאשר Elasticsearch
- יחס דחיסה: 10:1
- שימוש באחסון: 20% מאשר Elasticsearch
- זמן התגובה: 43% מאשר Elasticsearch

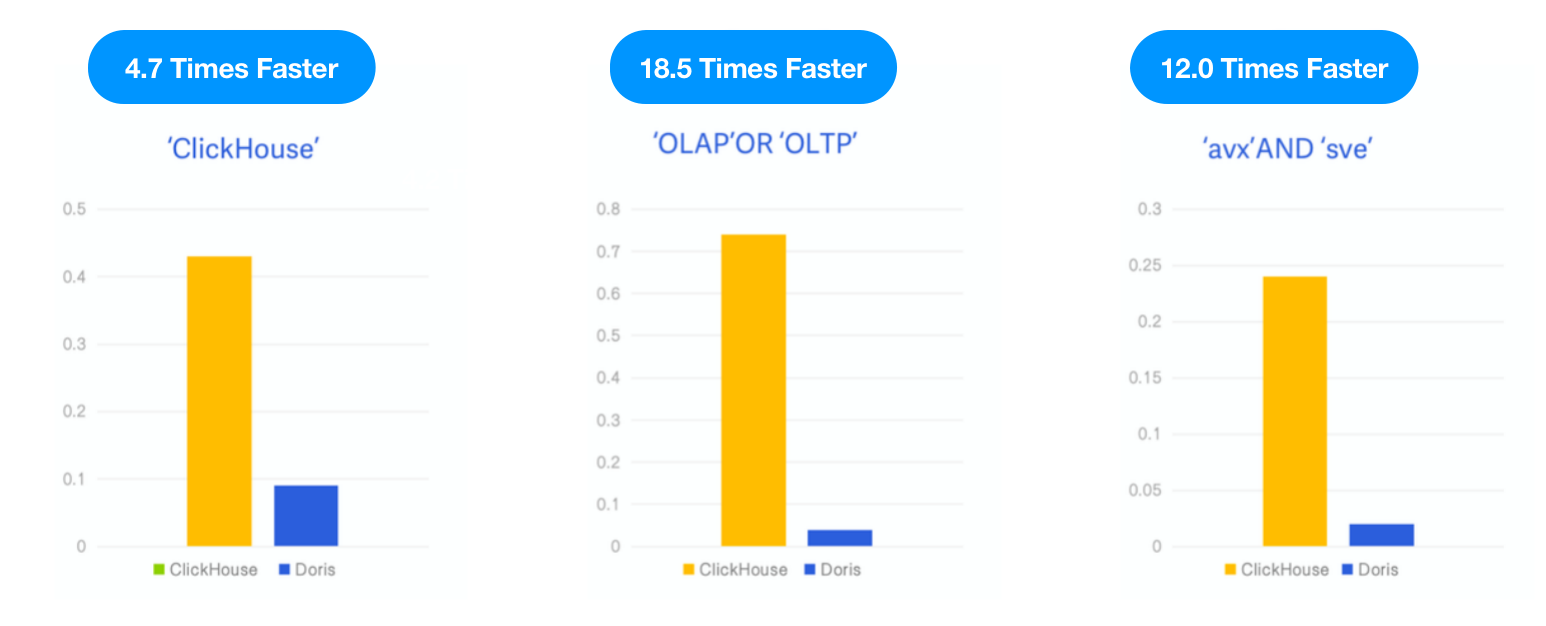
Apache Doris מול ClickHouse
בעוד ש-ClickHouse השיק מיינוי כתכונה ניסיונית ב-v23.1, בדקנו את Apache Doris עם אותו מערך נתונים ו-SQL כפי שמתואר בבלוג של ClickHouseבלוגוהשוונו את הביצועים של שני הפרויקטים תחת אותם משאבי בדיקה, מקרה וכלי.
- נתונים: 6.7G, 28.73 מיליון שורות, מערך נתונים של Hacker News, פורמט Parquet
- שאילתות: 3 חיפושים מילוליים, ספירת מספר התרחשויות של המילים המפתח "ClickHouse," "OLAP," או "OLTP," ו"avx" וגם "sve".
- סביבה: מחשב וירטואלי בן 16C 64G
תוצאה: Apache Doris היה 4.7 פעמים, 18.5 פעמים ו-12 פעמים מהר יותר מ-ClickHouse בשלושת השאילתות, בהתאמה.
שימוש ודוגמה
- מערך הנתונים: מיליון רשומות תגובות מ-Hacker News
שלב 1: ציין את האינדקס ההפוך לשולחן הנתונים במהלך יצירת השולחן.
פרמטרים:
- INDEX idx_comment (
comment): צור אינדקס בשם "idx_comment" לעמודת "comment" - USING INVERTED: ציין אינדקס הפוך לשולחן
- PROPERTIES("parser" = "english"): ציין את שפת הניתוח ל-English
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(הערה: אפשר להוסיף אינדקס לשולחן קיים באמצעות ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). בשונה מאינדקס חכם ואינדקס משני, יצירת אינדקס הפוך כוללת רק קריאת עמודת התגובות, ולכן יכולה להיות מהירה בהרבה.)
שלב 2: שלוף את המילים "OLAP" ו-"OLTP" בעמודת התגובות עם MATCH_ALL. הזמן המשוער כאן היה עשירית מזה בהתאם קשה עם like. (הפער בביצועים גדל ככל שנגדיל את כמות הנתונים.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
לקבלת מידע נוסף על הפונקציונליות והמדריך לשימוש, ראה את התיעוד: Inverted Index
סיכום
בקיצור, מה שמאפשר ל-Apache Doris להיות פי 10 יותר יעיל מבחינת העלות מ-Elasticsearch הוא האופטימיזציות המיוחדות ל-OLAP שלה עבור אינדקס הפוך, שמותמסת על ידי מנוע האחסון עמודה, ממשק העבודה המקביל בקנה מידה גדול, מנוע השאילתה הווקטורי, ומופתע העלות של Apache Doris.
כמו שאנו גאים בפתרון האינדקס ההפוך שלנו, אנו מבינים שבדיקות תקציביות שמופצות על ידי המפרסם עצמו יכולות להיות שנויות במחלוקת, אז אנו פתוחים למשוב מכל בודק צד שלישי ורוצים לראות איך Apache Doris פועל במקרים מציאותיים.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co