













עליית ה-AI האגנטי עוררה התלהבות סביב סוכנים שמבצעים משימות באופן עצמאי, נותנים המלצות ומבצעים זרימות עבודה מורכבות המשלבות AI עם מחשוב מסורתי. אך יצירת סוכנים כאלה בסביבות אמיתיות המונעות על ידי מוצרים מציבה אתגרים החורגים מה-AI עצמו.
ללא ארכיטקטורה זהירה, תלות בין רכיבים יכולה ליצור צווארי בקבוק, להגביל את יכולת ההתרחבות ולסבך את התחזוקה ככל שהמערכות מתפתחות. הפתרון טמון בהפרדת זרימות העבודה, שבהן סוכנים, תשתיות ורכיבים אחרים מתקשרים בצורה גמישה ללא תלות נוקשה.
סוג זה של אינטגרציה גמישה וניתנת להתרחבות דורש "שפה" משותפת להחלפת נתונים – ארכיטקטורה מונחית אירועים (EDA) המונעת על ידי זרמים של אירועים. על ידי ארגון אפליקציות סביב אירועים, סוכנים יכולים לפעול במערכת מגיבה ומנותקת שבה כל חלק עושה את עבודתו באופן עצמאי. צוותים יכולים לבחור טכנולוגיות בחופשיות, לנהל את צרכי ההתרחבות בנפרד ולשמור על גבולות ברורים בין רכיבים, מה שמאפשר גמישות אמיתית.
כדי לבדוק את העקרונות הללו, פיתחתי את PodPrep AI, עוזר מחקר המונע על ידי AI שעוזר לי להתכונן לראיונות פודקאסטים ב-Software Engineering Daily ו-Software Huddle. בפוסט הזה, אני אכנס לעיצוב ולארכיטקטורה של PodPrep AI, מראה כיצד EDA וזרמי נתונים בזמן אמת מניעים מערכת אגנטית אפקטיבית.
הערה: אם אתה רוצה להסתכל רק על הקוד, קפוץ ל-repo שלי ב-GitHub כאן.
למה ארכיטקטורה מונחית אירועים עבור AI?
ביישומי AI בעולם האמיתי, עיצוב צמוד ומונוליתים אינו מתקיים. בעוד הוכחות עקרוניות או הדגמות כמובן יכולות להשתמש במערכת יחידה ואחידה לצורך פשטות, שיטת זו מהר מאוד מתבררת כלא פרקטית בייצור, במיוחד בסביבות מבוזרות. מערכות צמודות יוצרות נקודות צמיחה, מגבילות את ההתרחבות ומשתיקות את השינויים — כל אלו אתגרים עיקריים שחשוב להימנע מהם בהתרחבות פתרונות AI.
שקולים את הסוגיה של סוכן AI טיפוסי.
ייתכן שיהיה צורך למשוך מידע ממקורות מרובים, לטפל בהנדסת הפרומפט ובזרימות עבודה של RAG, ולהתקשר ישירות עם כלים שונים לביצוע זרימות עבודה דטרמיניסטיות. האורכסטרציה הנדרשת היא מורכבת, עם תלות במערכות מרובות. ואם הסוכן צריך לתקשר עם סוכנים אחרים, המורכבות רק מתרבה. בלעדי ארכיטקטורה גמישה, התלות האלו גורמות לקושי בהתרחבות ובשינוי.

בייצור, צוותים שונים טופלים בדרך כלל בחלקים שונים של הערמה: MLOps והנדסת נתונים נוהלים את צינור RAG, מדע הנתונים בוחר במודלים, ומפתחי אפליקציות בונים את הממשק והלשכת השרת. הגדרה צמודה מכריחה את הצוותים האלו להסתמך על תלות שמשקלת את המהירות התוצאות ויוצרת קושי בהתרחבות. רעיון הידיאלי הוא ששכבות האפליקציה לא צריכות להבין את הפנימיות של הAI; עליהן פשוט לצרוך את התוצאות כאשר נדרש.
בנוסף, יישומי בינה מלאכותית לא יכולים לפעול בבידוד. כדי להשיג ערך אמיתי, תובנות הבינה המלאכותית צריכות לזרום באופן חלק בין פלטפורמות נתוני לקוחות (CDPs), CRMs, אנליטיקה ועוד. אינטראקציות עם לקוחות צריכות לגרום לעדכונים בזמן אמת, להזין ישירות לכלים אחרים לפעולה ולניתוח. ללא גישה מאוחדת, אינטגרציה של תובנות בין פלטפורמות הופכת לפאזל שקשה לנהל ובלתי אפשרי להרחיב.
בינה מלאכותית המונעת על ידי EDA מתמודדת עם אתגרים אלה על ידי יצירת "מערכת עצבים מרכזית" עבור נתונים. עם EDA, יישומים משדרים אירועים במקום להסתמך על פקודות מקושרות. זה מנתק רכיבים, מאפשר לנתונים לזרום באופן אסינכרוני היכן שצריך, ומאפשר לכל צוות לעבוד באופן עצמאי. EDA מקדמת אינטגרציה חלקה של נתונים, גידול נרחב, ועמידות — מה שהופך אותה לבסיס חזק עבור מערכות מודרניות מונעות בינה מלאכותית.
עיצוב סוכן מחקר מונע בינה מלאכותית בקנה מידה
במשך השנתיים האחרונות, אירחתי מאות פודקאסטים ב-Software Engineering Daily, Software Huddle ו-Partially Redacted.
כדי להתכונן לכל פודקאסט, אני מבצע תהליך מחקר מעמיק להכנת תקציר פודקאסט שמכיל את המחשבות שלי, רקע על האורח והנושא, וסדרת שאלות פוטנציאליות. כדי לבנות את התקציר הזה, אני בדרך כלל חוקרת את האורח ואת החברה בה הם עובדים, מאזינה לפודקאסטים אחרים שבהם הם עשויים להתארח, קוראת פוסטים בבלוג שהם כתבו, וקוראת על הנושא המרכזי שאנחנו נדון עליו.
אני מנסה לשלב חיבורים לפודקאסטים אחרים שאירחתי או לניסיון שלי הקשור לנושא או בנושאים דומים. כל התהליך הזה לוקח זמן ומאמץ משמעותיים. לפודקאסטים גדולים יש חוקרים ועוזרים ייעודיים שעושים את העבודה הזו עבור המנחה. אני לא מנהל סוג כזה של פעולה כאן. אני צריך לעשות את כל זה בעצמי.
כדי להתמודד עם זה, רציתי לבנות סוכן שיכול לעשות את העבודה הזו עבורי. ברמה גבוהה, הסוכן היה נראה כמו התמונה למטה.

אני מספק חומרים בסיסיים כמו שם האורח, החברה, הנושאים שאני רוצה להתמקד בהם, כמה כתובות URL של בלוגים ופודקאסטים קיימים, ואז קורה קצת קסם של בינה מלאכותית, ומחקר שלי מושלם.
הרעיון הפשוט הזה הוביל אותי ליצור את PodPrep AI, העוזר המחקרי המופעל על ידי בינה מלאכותית שלי, שעולה לי רק בטוקנים.
שאר המאמר הזה דן בעיצוב של PodPrep AI, החל מממשק המשתמש.
בניית ממשק המשתמש של הסוכן
עיצבתי את ממשק הסוכן כאפליקציה מבוססת אינטרנט שבה אני יכול בקלות להזין חומרי מקור לתהליך המחקר. זה כולל את שם האורח, החברה שלו, נושא הראיון, כל הקשר נוסף, וקישורים לבלוגים רלוונטיים, אתרים וראיונות פודקאסט קודמים.
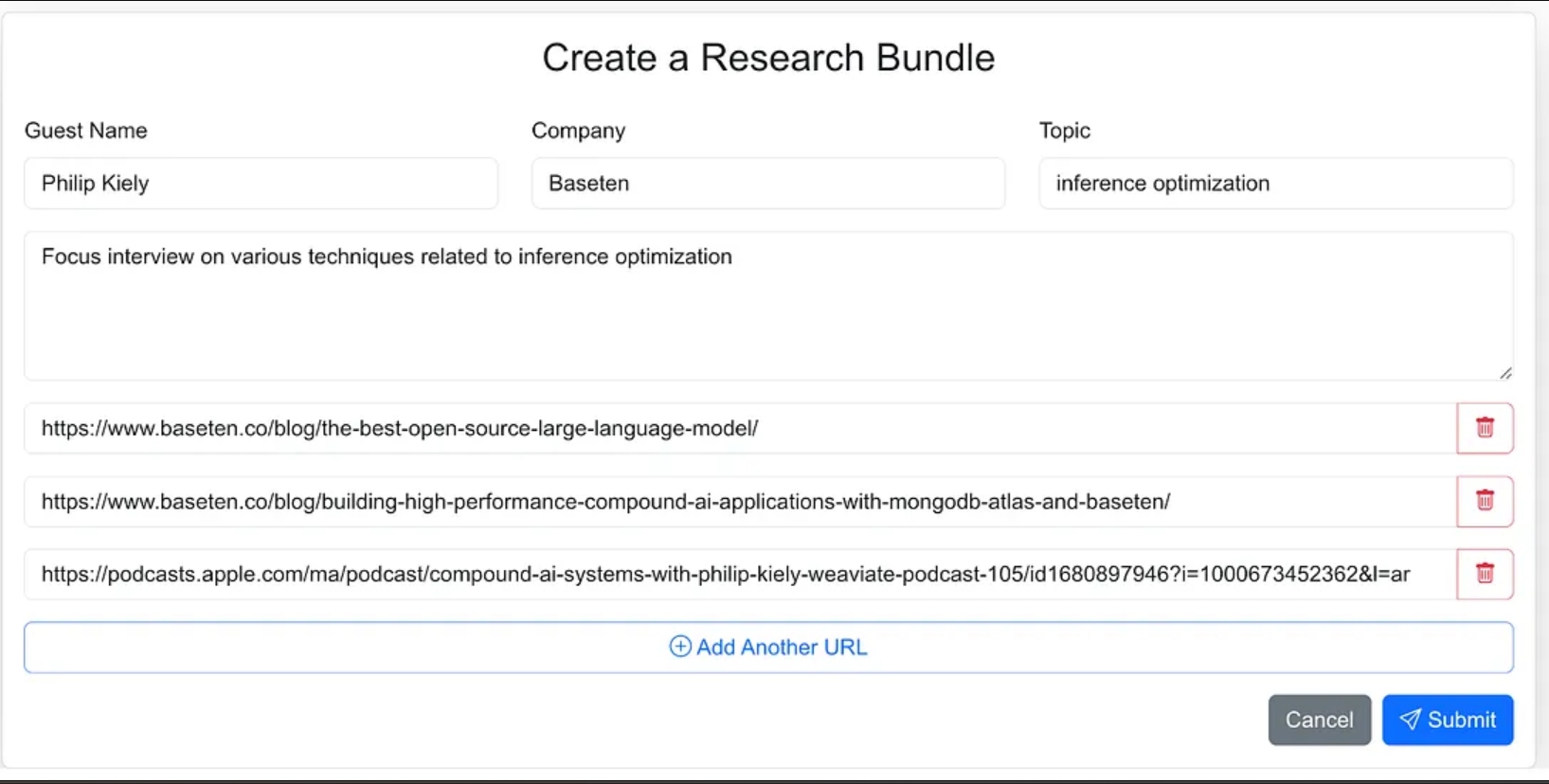
יכולתי לתת לסוכן פחות הנחיות ובחלק מהעבודת הסוכן לתת לו למצוא את חומרי המקור, אבל עבור גרסה 1.0, החלטתי לספק את כתובות ה-URL של המקור.
היישום הרשת הוא אפליקציה תלת-שכבתית סטנדרטית שנבנית עם Next.js ו- MongoDB למסד הנתונים של האפליקציה. הוא אינו יודע דבר על AI. פשוט מאפשר למשתמש להזין אריזות מחקר חדשות והן מופיעות במצב עיבוד עד שהתהליך האגנטי השלים את הזרימת העבודה ומילא תקציר מחקר במסד הנתונים של האפליקציה.
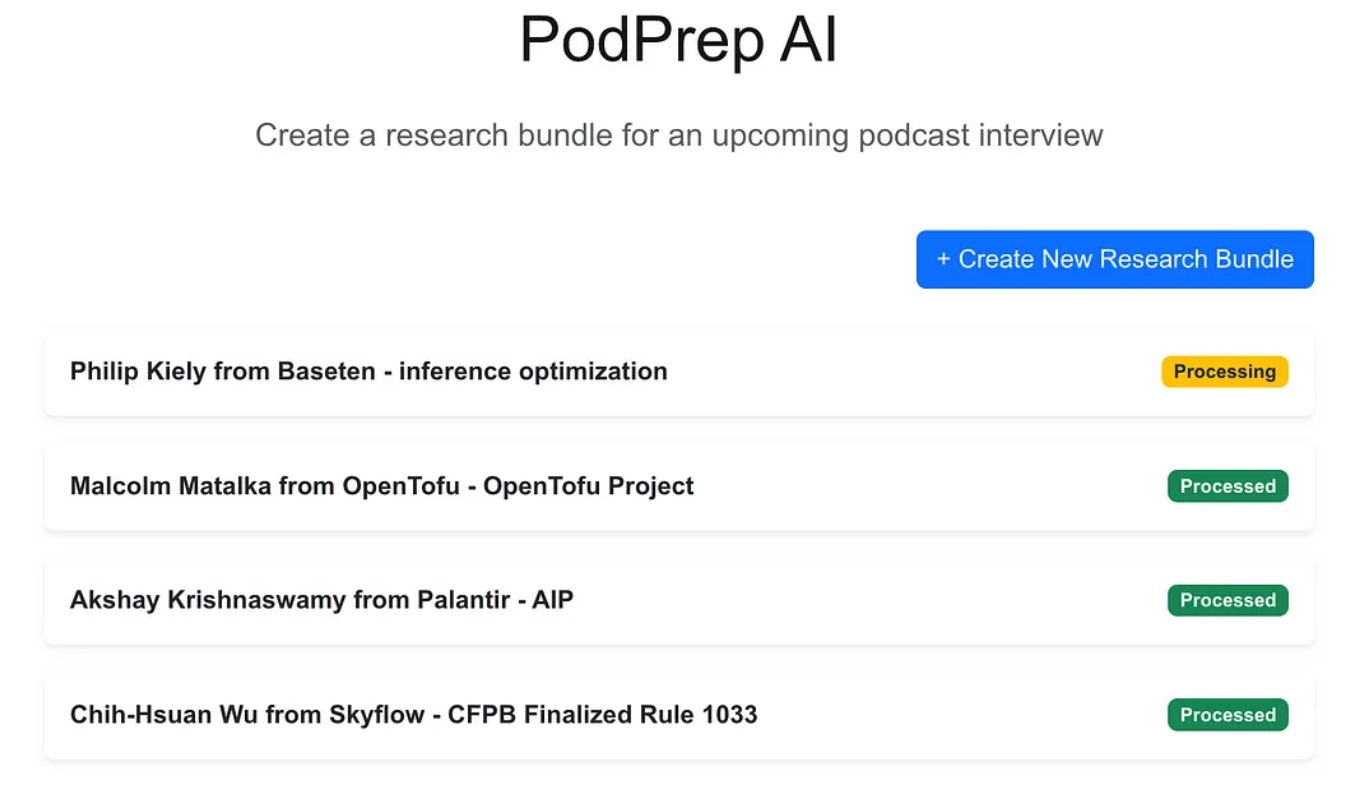
פעם שהקסם של הAI הושלם, אני יכול לגשת למסמך תקציר עבור הרשומה כפי שמוצג למטה.

יצירת הזרימת עבודה האגנטית
לגרסה 1.0, רציתי להיות מסוגל לבצע שלוש פעולות עיקריות כדי לבנות את תקציר המחקר:
- עבור כל כתובת URL של אתר אינטרנט, פוסט בלוג או פודקאסט, לאחזר את הטקסט או הסיכום, לחתוך את הטקסט לגודלים סבירים, ליצור embeddings, ולאחסן את הייצוג הוקטורי.
- עבור כל הטקסט המופלט מכתובות המקורות למחקר, לחלץ את השאלות המעניינות ביותר, ולאחסן אותן.
- ליצור תקציר מחקר לפודקאסט שמשלב את ההקשר הרלוונטי ביותר על סמך ה-embeddings, השאלות הכי טובות שנשאלו לפני כן, וכל מידע אחר שהיה חלק מהקלט של האריזה.
התמונה למטה מראה את הארכיטקטורה מהיישום הרשת אל זרימת העבודה האגנטית.
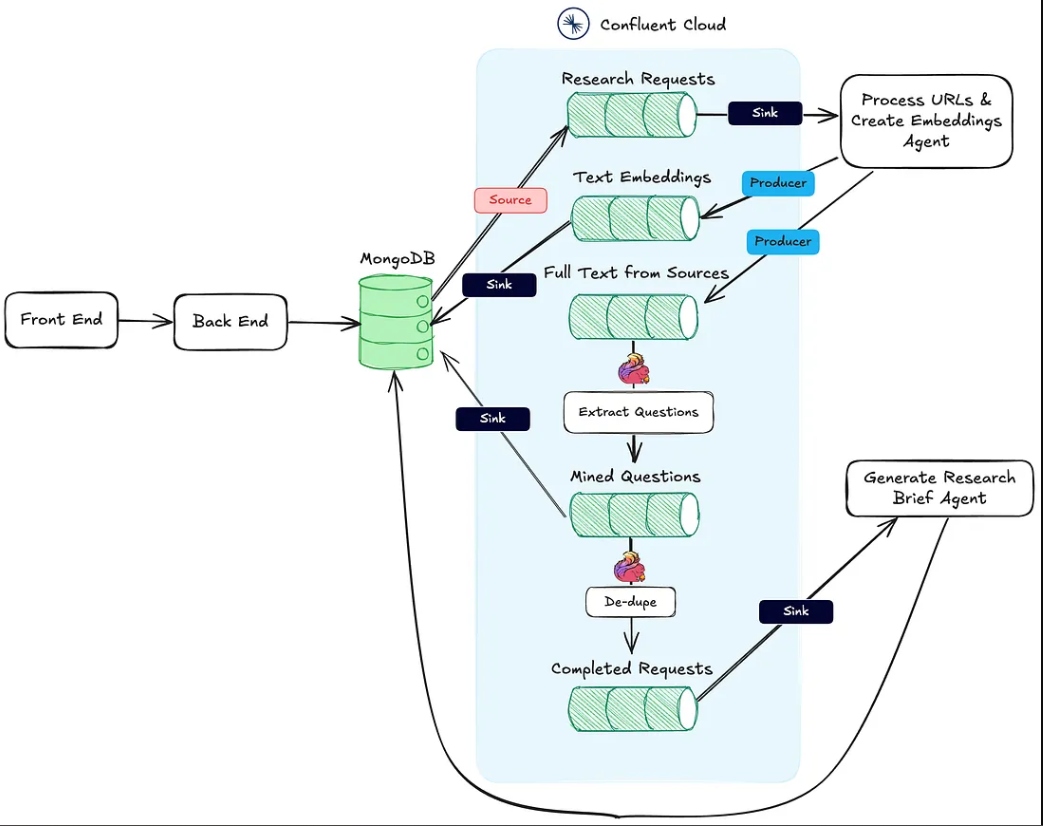
הפעולה מספר 1 מהנ"ל נתמכת על ידי נקודת הקצה Process URLs & Create Embeddings Agent HTTP sink.
הפעולה מספר 2 מבוצעת באמצעות Flink ותמיכת המודל AI המובנה ב- Confluent Cloud.
לבסוף, פעולה #3 מתבצעת על ידי הסוכן יצירת מסמך מחקר, גם הוא נקודת סיום HTTP, שנקרא ברגע שהשתי הפעולות הראשונות הושלמו.
בקטעים הבאים, אני מדבר על כל אחת מהפעולות הללו בפירוט.
סוכן עיבוד כתובות URL ויצירת הטבעות וקטוריות
סוכן זה אחראי על משיכת טקסט מכתובות ה-URL של מקור המחקר וצינור הטבעות הווקטוריות. להלן הזרימה הכללית של מה שמתרחש מאחורי הקלעים כדי לעבד את חומרי המחקר.

ברגע שמחקר נוצר על ידי המשתמש ונשמר ב-MongoDB, מחבר מקור MongoDB מפיק הודעות לנושא Kafka שנקרא research-requests. זה מה שמתחיל את זרימת העבודה הסוכנתית.
כל בקשה POST לכתובת ה-HTTP מכילה את כתובות ה-URL מבקשת המחקר ואת המפתח הראשי באוסף חבילות המחקר של MongoDB.
הסוכן עובר על כל כתובת URL ואם היא לא פודקאסט של אפל, הוא מקבל את ה-HTML של הדף המלא. מכיוון שאני לא יודע את המבנה של הדף, אני לא יכול להסתמך על ספריות ניתוח HTML כדי למצוא את הטקסט הרלוונטי. במקום זאת, אני שולח את טקסט הדף למודל gpt-4o-mini עם טמפרטורה של אפס באמצעות הפקודה למטה כדי לקבל את מה שאני צריך.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
לגבי פודקאסטים, אני צריך לעשות קצת יותר עבודה.
הנדסה הפוכה של כתובות URL של פודקאסטים של אפל
כדי למשוך נתונים מפרקי פודקאסט, קודם כל אנחנו צריכים להמיר את האודיו לטקסט באמצעות מודל Whisper. אבל לפני שנוכל לעשות זאת, אנחנו צריכים לאתר את קובץ ה-MP3 האמיתי עבור כל פרק פודקאסט, להוריד אותו, ולחלק אותו לחלקים של 25MB או פחות (הגודל המקסימלי עבור Whisper).
האתגר הוא ש-Apple לא מספקת קישור ישיר ל- MP3 עבור פרקי הפודקאסט שלה. אך, הקובץ MP3 זמין בערוץ ה- RSS המקורי של הפודקאסט, ואנו יכולים למצוא את הערוץ זה באופן תכנותי באמצעות ה- Apple podcast ID.
לדוגמה, בכתובת ה- URL למטה, החלק המספרי אחרי /id הוא ה- Apple ID הייחודי של הפודקאסט:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
באמצעות API של Apple, אנו יכולים לחפש את ה- podcast ID ולקבל תגובת JSON המכילה את כתובת ה- URL לערוץ ה- RSS:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
לאחר שאנו מאגרים את קובץ ה- RSS, אנו מחפשים בו את הפרק הספציפי. מאחר שיש לנו רק את קישור הפרק מ-Apple (ולא את הכותרת הממשית), אנו משתמשים בסלאג של הכותרת מה-URL כדי לאתר את הפרק בתוך הערוץ ולאחזר את קישור ה- MP3 שלו.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
עכשיו עם הטקסט מפוסטים בלוג, אתרי אינטרנט, וקבצי MP3 זמינים, הסוכן משתמש במפצל טקסט תווי רקורסיבי של LangChain כדי לחלק את הטקסט לחתיכות ולייצר את השיבוץ מהחתיכות אלו. החתיכות מופרסמות לנושא text-embeddings ומוצקות ל-MongoDB.
- הערה: בחרתי להשתמש ב-MongoDB כשתי מערכות המסדים שלי ומסד הנתונים הוקסם. אך, בגלל הגישה EDA שבחרתי, ניתן להפריד אותם למערכות נפרדות בקלות, וזה רק עניין של החלפת מחבר הספינה מנושא השב מ-Text Embeddings.
בנוסף ליצירה ופublishing של ההטמעות, הסוכן גם מפרסם את הטקסט מהמקורות לנושא שנקרא full-text-from-sources. פרסום לנושא זה запускает את פעולה #2.
חילוץ שאלות עם Flink ו-OpenAI
Apache Flink הוא מסגרת עיבוד זרמים קוד פתוח שנבנתה לטיפול בכמויות גדולות של נתונים בזמן אמת, אידיאלית עבור אפליקציות עם תפוקה גבוהה ולחץ נמוך. על ידי חיבור Flink עם Confluent, אנו יכולים להביא LLMs כמו GPT של OpenAI ישירות לזרימות עיבוד. אינטגרציה זו מאפשרת זרימות RAG בזמן אמת, ומוודאת שתהליך חילוץ השאלות עובד עם הנתונים הזמינים הטריים ביותר.
שימור הטקסט המקורי מהמקור בזרם גם מאפשר לנו להציג זרימות עבודה חדשות מאוחר יותר שמשתמשות באותם נתונים, משפרות את תהליך יצירת סיכומי מחקר או שולחות אותו לשירותים downstream כמו מחסן נתונים. הגדרת גמישה זו מאפשרת לנו להוסיף תכונות נוספות של AI ולא AI עם הזמן מבלי צורך לשדרג את צינור הליבה.
ב-PodPrep AI, אני משתמש ב-Flink כדי לחלץ שאלות מטקסט שנמשך מ-URLs מקוריים.
הגדרת Flink כדי לקרוא LLM כרוכה בקונפיגורציה של חיבור דרך ה-CLI של Confluent. להלן דוגמת פקודה להקמת חיבור ל-OpenAI, אם כי קיימות אפשרויות רבות נוספות.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
ברגע שהחיבור הוקם, אני יכול ליצור מודל הן בקונסולת הענן והן ב-shell של Flink SQL. עבור חילוץ שאלות, אני מקים את המודל בהתאם.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
עם המודל המוכן, אני משתמש בפונקציה המובנית של Flink ml_predict כדי לייצר שאלות מחומר המקור, כותב את הפלט לזרם שנקרא mined-questions, שמסונכרן עם MongoDB לשימוש מאוחר יותר.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink גם עוזר לעקוב מתי כל חומרי המחקר עברו עיבוד, ומפעיל את יצירת התקציר מחקר. זה מתבצע על ידי כתיבה לזרם completed-requests ברגע שכתובות ה-URL בmined-questions תואמות לאלה בזרם המקורות המלאים.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
כאשר הודעות נכתבות לcompleted-requests, ה-ID הייחודי עבור חבילת המחקר נשלח ליצור סוכן תקציר מחקר.
סוכן יצירת תקצירי מחקר
סוכן זה לוקח את כל חומרי המחקר הרלוונטיים ביותר הזמינים ומשתמש ב-LLM כדי ליצור תקציר מחקר. להלן הזרימה הכללית של האירועים המתרחשים כדי ליצור תקציר מחקר.

דיאגרמת זרימה עבור סוכן יצירת תקצירי מחקר
בואו נבצע ניתוח של כמה מהשלבים הללו. כדי לבנות את הפנייה עבור ה-LLM, אני משלב את השאלות שנחצבו, נושא, שם אורח, שם חברה, פנייה מערכתית להכוונה, והקשר שנשמר בבסיס הנתונים הווקטורי שהוא החיוני ביותר לסמנטיקה דומה לנושא הפודקאסט.
מכיוון שאוסף המחקרים מכיל מידע קונטקסטואלי מוגבל, קשה לחלץ את ההקשר הרלוונטי ביותר ישירות מכתובת האחסון הוקטורית. לפתור את זה, אני משתמש ב-LLM כדי ליצור שאילתת חיפוש לאיתור התוכן המתאים ביותר, כפי שמוצג בצומת "צור שאילתת חיפוש" בתרשים.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
באמצעות השאילתה שנוצרה על ידי ה-LLM, אני יוצר השקעה ומחפש את מסד הנתונים של MongoDB דרך אינדקס וקטור, מסננת לפי ה-bundleId על מנת להגביל את החיפוש לחומרים הרלוונטיים לפרק הפודקאסט הספציפי.
עם המידע הקונטקסטואלי הטוב ביותר שמזוהה, אני בונה הזמנה ויוצר את התקציר המחקרי, שמאפשר את התוצאה ב-MongoDB כדי שיוצג על ידי אפליקציית הרשת.
דברים לשים לב ביישום
כתבתי גם את היישום הקדמי של PodPrep AI והאג׳נטים ב-Javascript, אך בסקנריו בעולם אמיתי, האג׳נט כנראה יהיה בשפה שונה כמו Python. בנוסף, לצורך פשטות, ה-פונקציות לעיבוד כתובות URL ויצירת אינדקסים וקטורים וה-אג׳נט ליצירת תקציר מחקר נמצאים באותה פרויקט ורצים על אותו שרת רשת. במערכת ייצור אמיתית, יכולות אלה להיות פונקציות ללא שרת, רצות באופן עצמאי.
מחשבות סופיות
בניית PodPrep AI מבליטה כיצד ארכיטקטורת מבוססת אירועים מאפשרת ליישומי AI בעולם האמיתי להתרחב ולהסתגל בצורה חלקה. עם Flink ו-Confluent, יצרתי מערכת שמעבדת נתונים בזמן אמת, מפעילה תהליך ניהולי מופעל על ידי AI ללא תלות קשה. הגישה המנותקת הזאת מאפשרת לרכיבים לפעול באופן עצמאי, אך להישאר מחוברים דרך זרמי אירועים — שקריטיים ליישומים מורכבים ומבוזרים בהם צוותים שונים נוהגים בחלקים שונים של המגדר.
בסביבת המובנים ב- AI של היום, גישה לנתונים טריים בזמן אמת במערכות שונות היא חיונית. EDA משמשת כ "מערכת עצבים מרכזית" עבור הנתונים, מאפשרת שילוב חלק וגמישות עם צמיחת המערכת.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink