













ארגונים מתחילים את קבלת הזרמת הנתונים שלהם עם אשף Kafka יחיד להרצת המקרים השימוש הראשוני. הצורך בשלטון נתונים ואבטחה רחב-קבוצתיים אך דרישות שונות ל-SLAs, לקיצוב זמן תגובה ולתשתיות מכניסים קלאסטרים חדשים של Kafka. קלאסטרים מרובים של Kafka הם הכלל, לא החריג. המקרים השימוש כוללים אינטגרציה היברידית, איגוד, העברה ושחזור אסונות. פוסט הבלוג הזה חוקר סיפורי הצלחה בעולם האמיתי ואסטרטגיות של קלאסטרים להתקנות שונות של Kafka בתעשיות שונות.

Apache Kafka: התקן המובהק לארכיטקטורות מבוססות ארועים ולזרמת נתונים
Apache Kafka הוא פלטפורמת זרימת ארועים מבוזרת ופתוחת מקור המיועדת לעיבוד נתונים בקצב גבוה ובלטנציה נמוכה. זה מאפשר לך לפרסם, להירשם אל, לאחסן ולעבד זרמים של רשומות בזמן אמת.
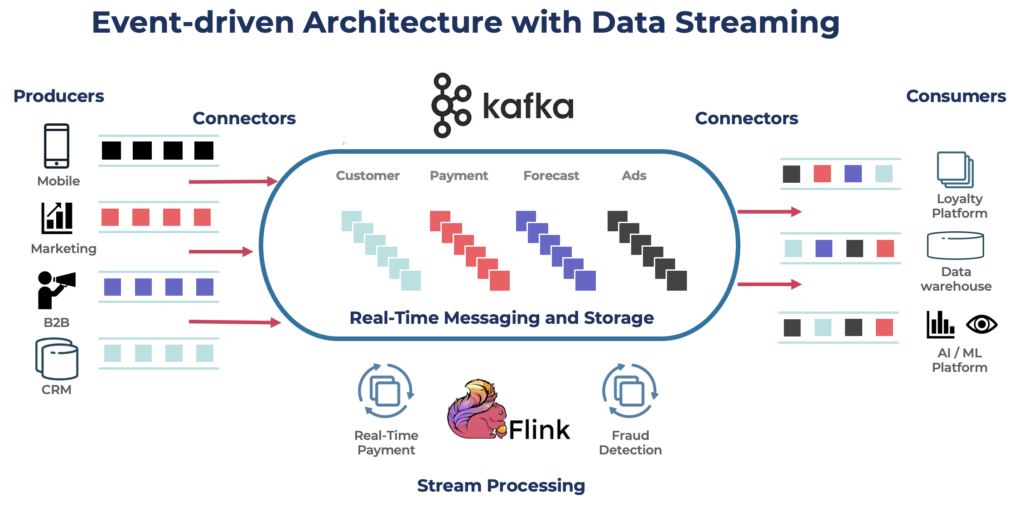
Kafka הוא בחירה פופולרית עבור בניית צינורות נתונים בזמן אמת ויישומי זרימה. פרוטוקול Kafka הפך לתקן דה פקטו עבור זרימת אירועים במגוון מסגרות, פתרונות ושירותי ענן. הוא תומך בעומסי עבודה אופרציונליים ואנליטיים עם תכונות כמו אחסון עמיד, גמישות ועמידות בפני תקלות. Kafka כולל רכיבים כמו Kafka Connect לאינטגרציה ו-Kafka Streams לעיבוד זרימה, מה שהופך אותו לכלי גמיש למגוון תרחישי שימוש המבוססים על נתונים. במובנים השונים של העברת נתונים.
בעוד ש-Kafka עשוי להיות מוכר למקרים בזמן אמת, הרבה פרוייקטים משתמשים בפלטפורמת הזרימת נתונים לצורך עדכון נתונים בכל הארכיטקטורה הארגונית, כולל מסדי נתונים, אגמי נתונים, מערכות ישנות, Open APIs ויישומים ענן-ניתנים לקנייה.
סוגי אשכולות Apache Kafka שונים
Kafka הוא מערכת מבוזרת. הגדרת ייצוב כוח ייצור דורשת לפחות ארבעה סוחרים. לכן, רוב האנשים מניחים באופן אוטומטי שכל מה שנדרש הוא אשכול מבוזר יחיד שתורם כאשר מוסיפים כניסה ותרחישי שימוש. זה אינו שגוי בהתחלה. אך…
אשכול Kafka אחד אינו התשובה הנכונה לכל מקרה שימוש. תכונות שונות משפיעות על ארכיטקטורת האשכול של Kafka:
- זמינות: אפס זמן פעולה? SLA של 99.99% זמינות? אנליטיקה לא-קריטית?
- לטנסי: עיבוד קצה אל קצה בפחות מ-100 מילישניות (כולל עיבוד)? צינור הנתונים של מחסן הנתונים אורך 10 דקות? נסיעה בזמן לעיבוד מחדש של אירועים היסטוריים?
- עלות: ערך לעומת עלות? עלות כוללת של בעלות המוצר (TCO) חשובה. לדוגמה, בענן הציבורי, הרשתות יכולות להיות עד 80% מעלות קאפקה הכוללות!
- אבטחה ופרטיות הנתונים: פרטיות הנתונים (נתוני PCI, תקנות GDPR, וכו')? מינהל הנתונים והתאמה לתקנות? הצפנת קצה אל קצה על רמת התכונה? הבאת המפתח שלך? גישה ציבורית ושיתוף נתונים? סביבת קצה באוויר מופרדת?
- כלכלה וגודל הנתונים: עסקאות קריטיות (בדרך כלל נמוכות בנפח)? זרימות נתונים גדולות (קליקסטרים, חיישני IoT, לוגים לאבטחה, וכו')?
נושאים קשורים כמו מערכת פנים לענן נתונים, אזורית לגלובלית, ועוד מגבלות רבות אחרות משפיעות גם על ארכיטקטורת ה-Kafka.
אסטרטגיות וארכיטקטורות של אשף Kafka
אשף Kafka יחיד הוא לעתים תחילה הנקודת ההתחלה הנכונה למסע הזרמת הנתונים שלך. הוא יכול להטעין מגוון שימושים מקרים שונים בתחומי עסקים שונים ולעבד גיגה-בייטים לשנייה (אם נהוג ומתייחס בדרך הנכונה).
עם זאת, לפי דרישות הפרויקט שלך, תצטרך ארכיטקטורת עסקית עם מספר אשפי Kafka. הנה כמה דוגמאות נפוצות:
- ארכיטקטורת היברידית: אינטגרציה של נתונים וסנכרון נתונים חד-או דו-כיווני בין מרכזי נתונים מרובים. לעיתים קרובות, קישוריות בין מרכז נתונים במקום לשירות ענן ציבורי. העברת נתונים ממערכות ישנות לניתוח בענן היא אחת התרחישים הנפוצים ביותר. אפשר גם תקשורת פקודה ושליטה, כלומר, שליחת החלטות/המלצות/עסקאות אל סביבה אזורית (לדוגמה, אחסון תשלום או הזמנה מאפליקצית נייד במחשב מרכזי).
- רב-אזורים/רב-עננים: שיתוף נתונים עבור תקינות, עלויות, או סיבות שמירת פרטיות נתונים. שיתוף נתונים כולל רק חלק מהאירועים, ולא את כל נושאי ה-Kafka. התחום הרפואי הוא רק אחד מהתעשיות שהולכות בכיוון זה.
- שחזור תקלות: שכפול של נתונים חיוניים במצב פעיל-פעיל או פעיל-פסיבי בין מרכזי נתונים שונים או אזורי ענן. כולל אסטרטגיות וכלים לפעולת העברה ולמנגנוני חזרה לפעולה במקרה של אסון כדי להבטיח רציפות עסקית ותואם תקנים.
- צבירה: אשכולות אזוריים לעיבוד מקומי (לדוגמה, עיבוד מוקדם, ETL בזמן אמת, יישומים עסקיים לעיבוד זרמים) ושיתוף נתונים מקובצים אל מרכז הנתונים הגדול או לענן. חנויות קמעונית הן דוגמה מצוינת.
- העברה: מודרניזציה של טכנולוגיות מידע עם העברת מערכת ממוקמת במקום לענן או מתוך קוד פתוח באחריות עצמית אל SaaS מנוהלת באופן מלא. העברות כאלה ניתן לבצע ללא הפסקה בתקופת הפעולה או אובדן נתונים בזמן שהעסק ממשיך בפעילותו במהלך העברה.
- קצה (מנותק/מופרד מרשת): אבטחה, עלות, או לטנציה דורשים פיתוח בקצה (Edge), לדוגמה במפעל או בחנות קמעונאית. תעשיות מסוימות ממנותחות בסביבות בטיחותיות עם שער חומים חומי חומים חומי חומים וסוגיה דאיוד.
- שרת יחיד: לא מהימן, אך מספיק לתרגילים כגון הטמעת שרת Kafka במכונה או במחשב תעשייתי אישי (IPC) ושיבוץ נתונים מכלוליים לתוך אשכול Kafka לניתוחי ענן גדולים. דוגמה טובה היא התקנת זרימת נתונים (כולל אינטגרציה ועיבוד) על מחשבו של חייל בשדה קרב.
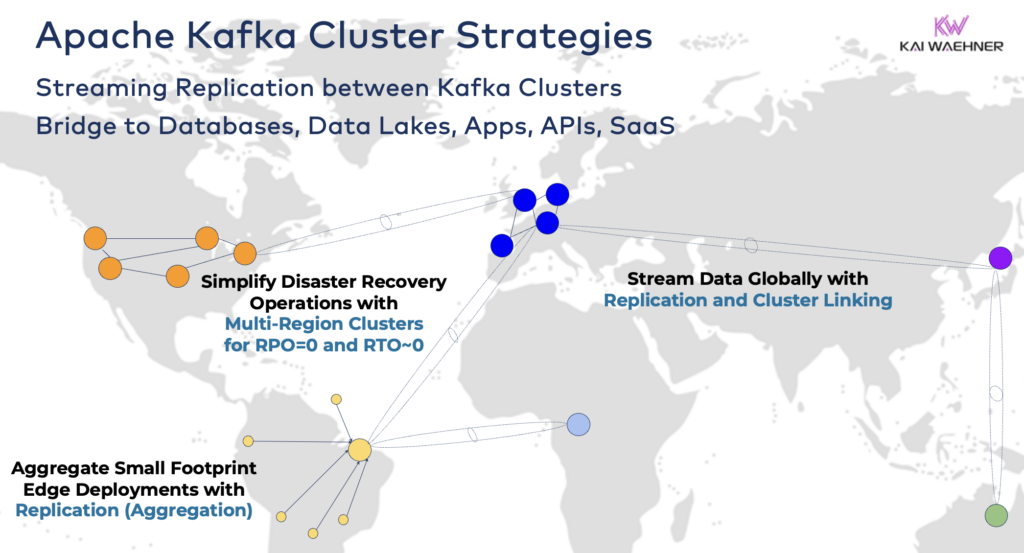
חיבור בין אשכולי Kafka היברידיים
אפשר לשלב אפשרויות אלו. לדוגמה, שרת יחיד בקצה כמובן מעתיק חלק מנתונים מסודרים למרכז נתונים רחוק. אשכולות היברידיים מצוידים בארכיטקטורות שונות בהתאם לאופן בו הם מחוברים: חיבורים דרך האינטרנט הציבורי, קישור פרטי, VPC פירינג, שער המעבר, וכו'.
הייתי רואה את פיתוח ענני Confluent במשך השנים, וסיכמתי כמה זמן הנדסי צריך להיות מוקצה לבטיחות ולתקשורת. עם זאת, חיסרונן של גשרי בטיחות הם המונעים העיקריים לקבלת שירות ענן של Kafka. לכן, אין דרך להעביר על ספק מגוון גשרי בטיחות בין אשכולי Kafka מעבר לאינטרנט הציבורי בלבד.
ישנן אפילו מקרים בהם ארגונים זקוקים לשכפל נתונים ממרכז הנתונים לענן, אך שירות הענן אינו מורשה להפעיל את החיבור. Confluent בנו תכונת מסוימת, "קישור שנפתח על ידי המקור," עבור דרישות האבטחה האלה, כאשר המקור (כלומר, אשף ה-Kafka במתוך המקום) תמיד מפעיל את החיבור – גם על פי שאשפי ה-Kafka בעננים צורכים את הנתונים:
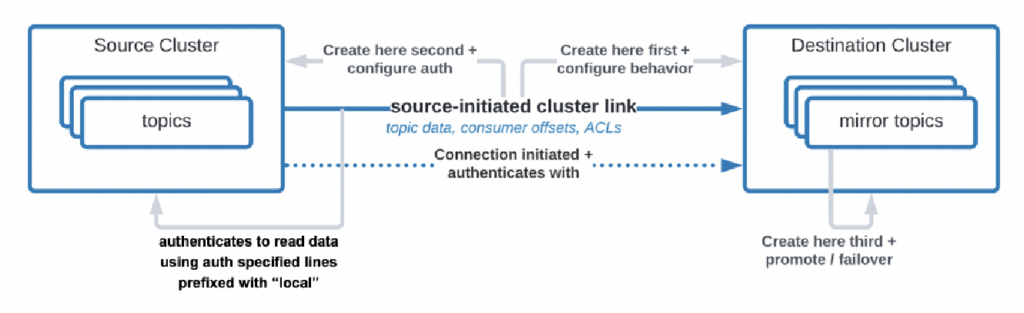 מקור: Confluent
מקור: Confluent
כפי שניתן לראות, הדבר מורכב במהירות. מצא את המומחים הנכונים שיסייעו לך מההתחלה, ולא לאחר שכבר הצפת את האשפים והיישומים הראשונים.
לפני זמן רב, תיארתי כבר במצגת מפורטת את תבניות הארכיטקטורה עבור פיזור נתונים, שוליים, וגלובליים של Apache Kafka. ראה במצגת השקופיות ובהקלטת הווידאו לפרטים נוספים אודות אפשרויות ההטייה והפשיטות.
RPO נגד RTO = אובדן נתונים נגד זמן עצירה
RPO ו-RTO הם שני KPIs חיוניים שעליך לדון בהם לפני קביעת אסטרטגית אשף Kafka:
- RPO (Recovery Point Objective) היא כמות האובדן של נתונים המקסימלית שניתן לקבל ביחד עם זמן, מציינת באיזו תדירות צריך לבצע גיבויים כדי למזער את האובדן של נתונים.
- זמן השחזור המטרתי (RTO – Recovery Time Objective) היא המשך הזמן המקסימלי שהכללת מדריג עליו לשחזר את פעילות העסק לאחר הפסקה. יחד, הם עוזרים לארגונים לתכנן את אסטרטגיות הגיבוי של הנתונים שלהם ואת אסטרטגיות השחזור מאסונות כדי לאזן בין עלות והשפעה תפעולית.
בעוד שרבים מתחילים עם המטרה ש-RPO = 0 ו-RTO = 0, הם מתבררים מהר כמה קשה (אך לא בלתי אפשרי) להשיג זאת. עליך להחליט כמה נתונים אתה יכול לאבד באסון. עליך לצור תוכנית לשחזור מאסון אם תתרחש מצוקה. צוותי המשפטים וההתאמה לתקנות יצטרכו לספר לך אם זה מקובל לאבד כמה סטים של נתונים במקרה של אסון או לא. עליך לדון באתגרים אלו ובאתגרים רבים אחרים כאשר אתה מעריך את אסטרטגיית האשכול שלך ב-Kafka.
השכפול בין אשכולי Kafka באמצעות כלים כמו MIrrorMaker או Cluster Linking הוא אסינכרוני ו-RPO > 0. רק אשכול Kafka מתוח מספק RPO = 0.
אשכול Kafka מתוח: אפס אובדן נתונים עם שכפול סינכרוני בין מרכזי נתונים
רוב ההתקנות עם מספר אשכולי Kafka משתמשות בשכפול אסינכרוני בין מרכזי נתונים או עננים באמצעות כלים כמו MirrorMaker או Confluent Cluster Linking. זה מספיק טוב לרוב מקרי השימוש. אך במקרה של אסון, אתה מאבד מספר הודעות. ה-RPO הוא > 0.
אשכול Kafka מתוח מפרסם סוחרי Kafka של אשכול יחיד במרכזי נתונים שלושה. השכפול הוא סינכרוני (כך Kafka משכפל נתונים בתוך אשכול אחת) ומבטיח אפס אובדן נתונים (RPO = 0) – אפילו במקרה של אסון!
למה לא תעשה תמיד אשכולות מתוחים?
- נדרשת נמוכה (<~50 מילישניות) וחיבור יציב בין מרכזי נתונים.
- נדרשים שלוש (!) מרכזי נתונים; שניים לא מספיק מאחר ורוב המערכות חייבות לאשר כתיבות וקריאות על מנת להבטיח את אמינות המערכת.
- הם קשים להקמה, הפעלה וניטור והרבה קשה יותר מאשר אשכול בתוך מרכז נתונים אחד.
- העלות מול התמורה לא שווה במקרים רבים; במהלך אסון אמיתי, רוב הארגונים ותרחישים נתקלים בבעיות גדולות יותר מאשר לאבד מספר הודעות (גם אם זו נתונים חיוניים כמו תשלום או הזמנה).
כדי להיות ברור, בענן הציבורי, אזור בדרך כלל מכיל שלושה מרכזי נתונים (= אזורי זמינות). לכן, בענן, זה תלוי ב- SLAs שלך אם אזור ענן אחד מחשב כאשכול נמשך או לא. רוב ההצעות של SaaS Kafka ממוקמות באשכול נמשך כאן.
אך, בתרחישי עמיתות רבים אינם רואים את אשכול Kafka באזור ענן אחד כמספיק טוב להבטיח SLAs והמשך פעילות עסקית אם אסון תתרחש.
Confluent בנו מוצר מוקדש כדי לפתור (חלק מ-) מאתגרים אלה: אשכולי רב-אזורים (MRC). הוא מספק יכולות לשכפול סינכרוני ואסינכרוני בתוך אשכול Kafka נמשך.
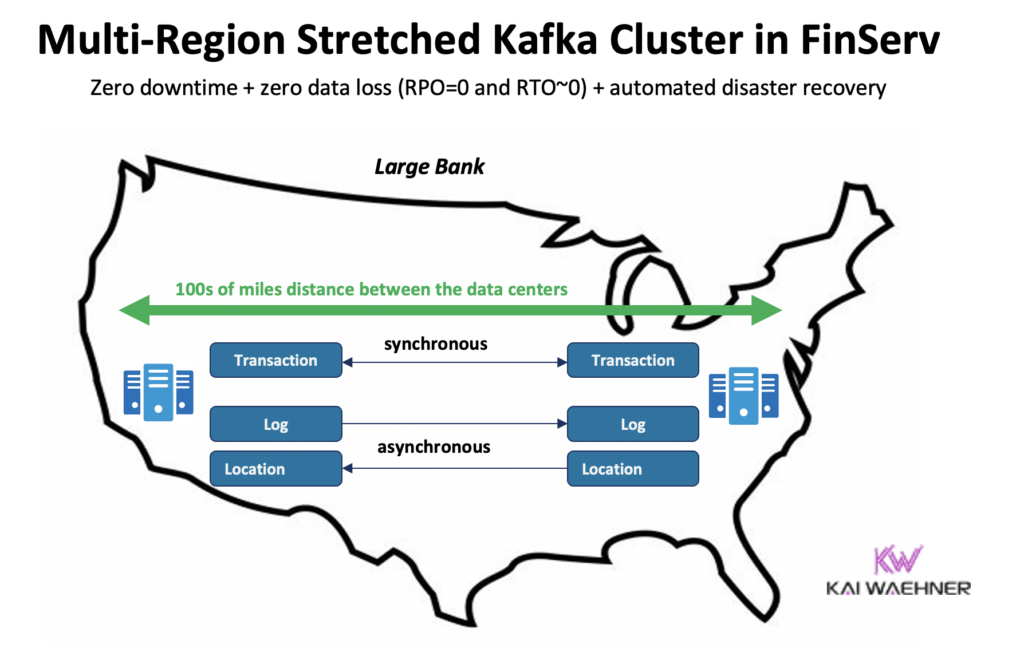
לדוגמה, בתרחיש של שירותים פיננסיים, MRC משכפל באופן סינכרוני עסקאות בעלות נתונים נמוכים אך לוגים בעלי נתונים גבוהים באופן אסינכרוני:
- טופלות עסקאות 'תשלום' הנכנסות ממזרח ארה"ב וממערב ארה"ב עם שכפול סינכרוני מלא
- מידע על 'לוג' ו'מיקום' באותו אשף משתמש באסינכרוניות – מותאמת ללטנציה
- שחזור תקלות ממוכן (אפס זמן ריבוי, אפס אובדן נתונים)
פרטים נוספים על אשפוזי Kafka ממתוחים נגד שימוש פעיל-פעיל / פעיל-חושפים בין שני אשפוזי Kafka בהרצאתי הגלובלית שליהצגת Kafka.
מחירון הצעות ענן של Kafka (נגד ניהול עצמי)
האיזורים הנ"ל מסבירים למה עליך לשקול ארכיטקטורות שונות של Kafka תלוי בדרישות הפרויקט שלך. אשפוזי Kafka שניהלים עצמית יכולים להיות מוגדרים בדרך שאתה צריך. בענן הציבורי, הצעות ניהול מלא מראות שונות (בדיוק כמו כל SaaS מנוהל באופן מלא אחר). מחירון שונה בגלל שספקי SaaS צריכים להגדיר מגבלות סבירות. הספק חייב לספק SLAs ספציפיות.
נוף השידורים כולל מגוון הצעות ענן של Kafka. הנה דוגמה להצעות הענן הנוכחיות של Confluent, כולל סביבות מרובות שוכנות ומיועדות עם SLAs שונות, תכונות אבטחה ודגמי עלות.
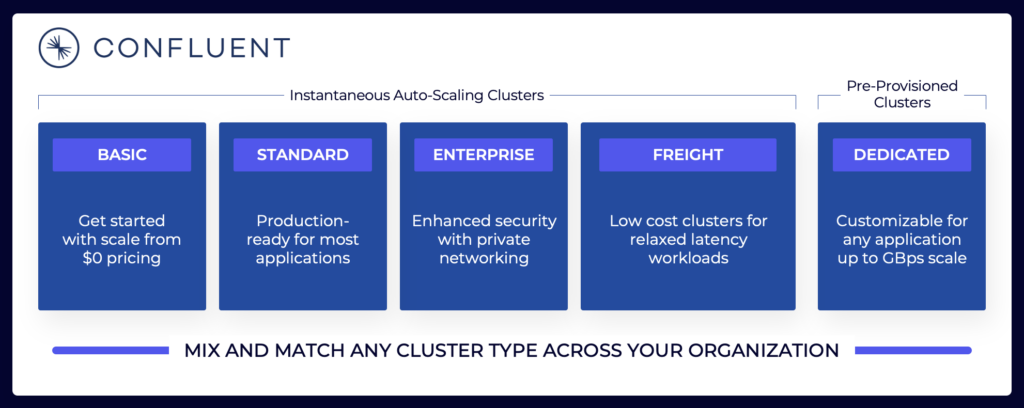 מקור: Confluent
מקור: Confluent
ודא שאתה מעריך ומבין את סוגי הקבוצות השונים מספקי שירותים שונים הזמינים בענן הציבורי, כולל עלויות כוללות, SLAs של זמינות מסופקת, עלויות שיבוץ בין אזורים או ספקי שירותים שונים, וכו'. הפערים והמגבלות לעתים קרובות מוסתרים במכריזים.
לדוגמה, אם אתה משתמש ב-Amazon Managed Streaming for Apache Kafka (MSK), עליך להיות מודע לעובדות ולתנאים המציינים כי "ההתחייבות לשירות אינה חלה על כל אי זמינות, השעייה או הפסקת השירות … שנגרמה על ידי מנוע התוכנה הספציפי של Apache Kafka או Apache Zookeeper שגורמת לכשלון בבקשות."
עם זאת, תמחור ו-SLAs של תמיכה הם רק חלק מהשוואה חיונית אחת. ישנם הרבה "החלטות בנייה נגד רכישה" שעליך לבחור כחלק מהערכת פלטפורמת זרימת נתונים.
אחסון Kafka: אחסון בשכבות ופורמט טבלת Iceberg לאחסון נתונים רק פעם אחת
ה-Apache Kafka הוסיפה אחסון בשכבות כדי להפריד בין חישוב ואחסון. היכולת מאפשרת ארכיטקטורות עסקיות עוצמתיות, אמינות ויעילות מבחינת עלויות יותר. אחסון בשכבות עבור Kafka מאפשר סוג חדש של אשף Kafka: אחסון של פטהבייט של נתונים בלוג המחוון של Kafka בדרך יעילה מבחינת עלויות (כמו באגם הנתונים שלך) עם חותמות זמן וסדר מובטח כדי לחפש אחורה בזמן לצורך עיבוד מחדש של נתונים היסטוריים. KOR Financial הוא דוגמה נהדרת לשימוש ב-Apache Kafka כבסיס נתונים לשמירה לטווח ארוך.
Kafka מאפשרת ארכיטקטורת "הזז שמאלה" לאחסון נתונים פעם אחת בלבד עבור סטים אופרטיביים וניתוחיים:

עם זאת, חשוב לחשוב שוב על מקרים השימוש שתיארתי למעלה עבור מספר קיפקא קפקא שונים. האם עדיין עליך לשכפל נתונים בצורת תצורה במאגר, באגם נתונים או בבית האגם ממרכז נתונים אחד או אזור ענן לאחר? לא. עליך לסנכרן נתונים בזמן אמת, לאחסן את הנתונים פעם אחת (רגילה בד"כ באחסון אובייקטים כמו Amazon S3), ולאחר מכן לחבר את כל מנועי הניתוח כגון Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery, וכו' לפורמט טבלה תקני זה.
סיפורי הצלחה בעולם האמיתי עבור מספר קיפקא קפקא
רוב הארגונים מחזיקים מספר קיפקא קפקא. בקטע זה נבחן ארבע סיפורי הצלחה בתחומים שונים:
- Paypal (שירותי פיננסים) – ארצות הברית: תשלומים מיידיים, מניעת הונאה.
- JioCinema (Telco/Media) – APAC: שילוב נתונים, ניתוחי קליקסטרים, פרסום, התאמה אישית.
- Audi (Automotive/Manufacturing) – EMEA: רכבים מחוברים עם דרישות קריטיות וניתוחיות.
- New Relic (Software/Cloud) – US: ניתוח וניהול ביצועי אפליקציות (APM) ברחבי העולם.
Paypal: הפרדה לפי אזור אבטחה
PayPal היא פלטפורמת תשלומים דיגיטלית שמאפשרת למשתמשים לשלוח ולקבל כסף ברשת בצורה בטוחה ונוחה בזמן אמת. זהו מערכת קפקה סופלית, מותאמת לצמיחה, בטוחה ועומדת בתקנים
במהלך שישי השחור 2022, נפילת תעבורת הקפקה הגיעה לקיצון של כ-1.3 טריליון הודעות יומיות. כיום, ל-PayPal יש 85+ אשכולות קפקה, ובכל עונת החגים הם מגבירים את התשתיות שלהם לטיפול בהתקפת התעבורה. פלטפורמת הקפקה ממשיך לצמוח בצורה חלקה כדי לתמוך בצמיחת התעבורה הזו מבלי לפגוע בעסק שלהם.
היום, ציוד הקפקה של PayPal כולל מעל 1,500 שרתים אשר מאחסנים מעל 20,000 נושאים. האירועים משוכפלים בין האשכולות, מציעים זמינות של 99.99%.
התקנות של אשכולות קפקה מחולקות לאזורי אבטחה שונים בתוך מרכז נתונים:
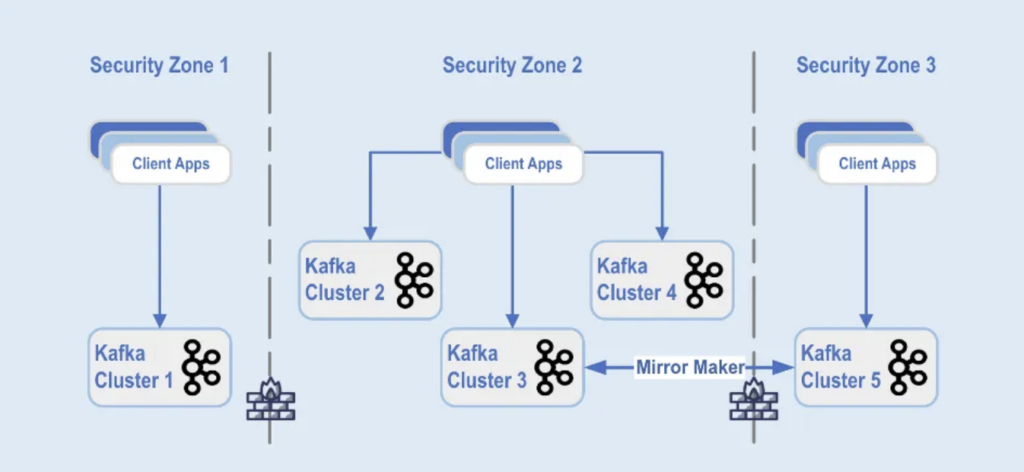 מקור: Paypal
מקור: Paypal
אשכולות ה-Kafka מוצבים בכל אחת מאזורי האבטחה הללו, בהתבסס על סיווג הנתונים ודרישות העסק. השכפול בזמן אמת בעזרת כלים כגון MirrorMaker (בדוגמה זו, פועל על תשתיות ה-Kafka Connect) או Confluent Cluster Linking (שמשתמש בגישה יותר פשוטה ופחות ניתנת לשגיאות ישירות בשימוש בפרוטוקול ה-Kafka לשכפול) משמש לשכפול הנתונים בין מרכזי נתונים, מה שעוזר בשחזור אסונות ובהשגת תקשורת בין אזורי אבטחה.
JioCinema: נפרדות לפי מטרת השימוש ואחריות שירות
JioCinema היא פלטפורמת צפייה בוידאו בצמיחה מהירה בהודו. שירות OTT של חברת הטלקום מכיר במגוון התוכן שלו, כולל ספורט חי כמו הליגה הפרימיירליג של האינדיאנים (IPL) לקריקט, האזור החדש של Anime Hub ותוכניות מקיפות לכיסוי אירועים גדולים כמו אולימפיאדת פריז 2024.
ארכיטקטורת הנתונים משתמשת ב-Apache Kafka, Flink ו-Spark לעיבוד נתונים, כפי שהוצג בכנס ה-Kafka Summit India 2024 בבנגלור:
 מקור: JioCinema
מקור: JioCinema
זרימת נתונים משמשת תפקיד מרכזי במגוון מקרים שונים כדי לשנות את חוויות המשתמש ומסירת התוכן. מעל עשרה מיליון הודעות לשניה משפרות את ניתוחי הנתונים, תובנות המשתמש והמנגנונים למסירת התוכן.
המקרים של שימוש ב-JioCinema כוללים:
- תקשורת בין שירותים
- זרימת קליקים/ניתוח נתונים
- גשש פרסומות
- למידת מכונה ואישיות
קושאל קנדלוול, ראש פלטפורמת נתונים, ניתוחים וצריכה ב-JioCinema, סבר כי לא כל נתונים שווים והעדיפויות וה-SLAs שונים לפי כל מקרה שימוש:
 מקור: JioCinema
מקור: JioCinema
זרימת נתונים היא מסע. דומה לארגונים רבים ברחבי העולם, JioCinema התחילה עם אשף קאפקה גדול אחד בשימוש ב-1000+ נושאי קאפקה ו-100,000+ מחיצות קאפקה למגוון מקרים שונים. במהלך הזמן, פיצול התלונות לגבי מקרים שימוש ו-SLAs פיתח למספר אשפי קאפקה:
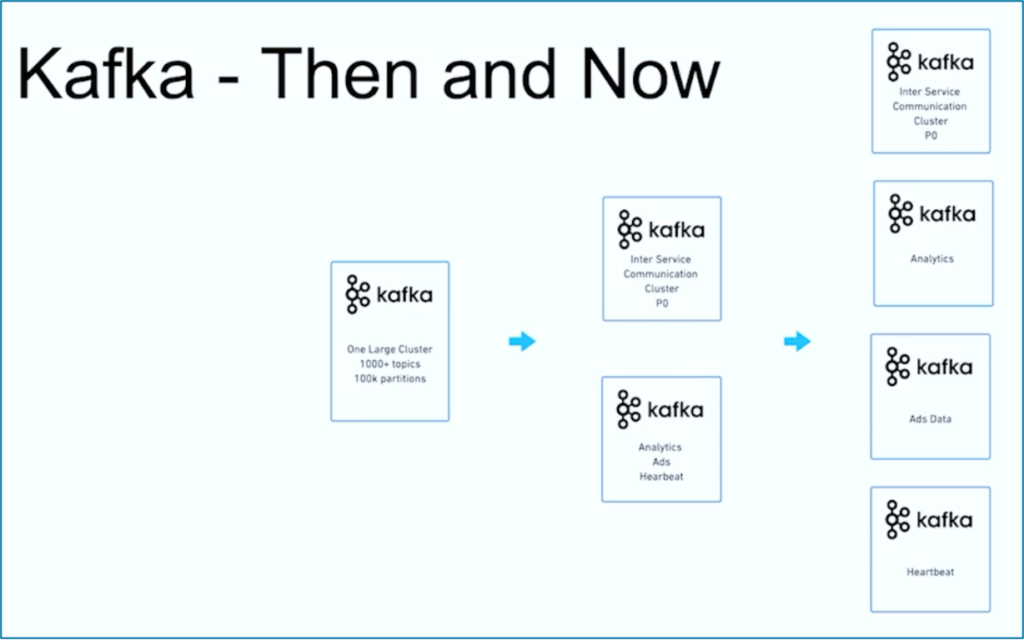 מקור: JioCinema
מקור: JioCinema
הסיפור המוצלח של JioCinema מדגים את התפתחותה המשותפת של ארגון סטרימינג נתונים. בואו נציג דוגמה נוספת שבה הוקמו שני קבוצות Kafka שונות מאוד מראש למטרה אחת.
Audi: פעולות נגד ניתוח לרכבים מחוברים
יצרן הרכב אודי מספק רכבים מחוברים המציעים טכנולוגיה מתקדמת המשלבת חיבור לאינטרנט ומערכות חכמות. רכבי אודי מאפשרים ניווט בזמן אמת, דיאגנוזה מרחוק ובידור ברכב משופר. הרכבים הללו מצוידים בשירותי Audi Connect. התכונות כוללות שיחות חירום, מידע תנועה מקוון ואינטגרציה עם מכשירי בית חכמים, על מנת לשפר את הנוחות והבטיחות של הנהגים.
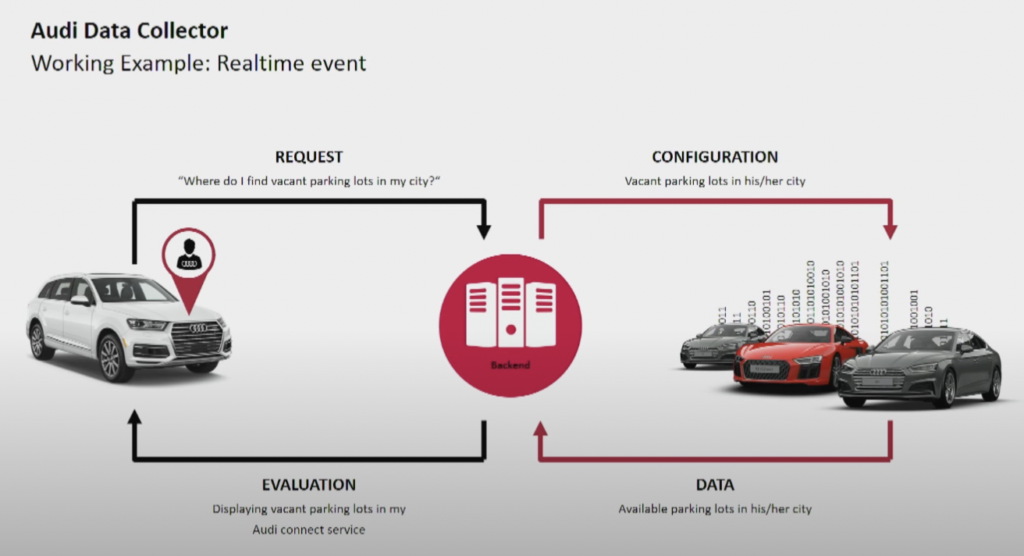 מקור: אודי
מקור: אודי
אודי הציגה את ארכיטקטורת הרכב המחובר שלה בדובר הראשי של כנס ה-Kafka לשנת 2018. ארכיטקטורה העסקית של אודי מתבססת על שני אשכולות Kafka עם SLAs ומטרות שימוש שונות ביותר.
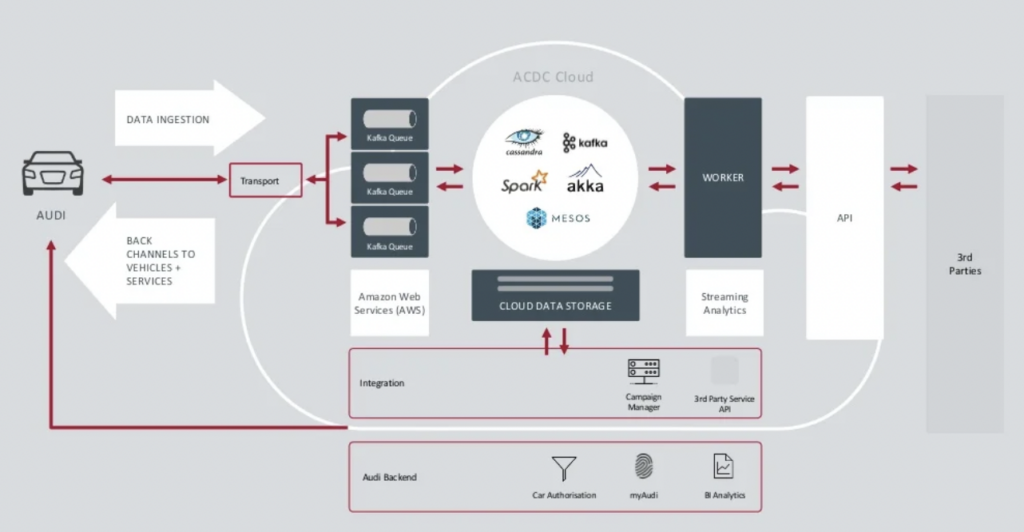 מקור: אודי
מקור: אודי
האשף Data Ingestion המופעל בקלאסטר של Kafka הוא חיוני מאוד. עליו לרוץ 24/7 בקנה מידה גדול. הוא מספק קישוריות לרכבים במיליונים באמצעות Kafka ו־MQTT. ערוצי חזרה מהצד של מערכת המידע לרכב מסייעים בתקשורת עם השירות ובעדכונים מעבר לאוויר (OTA).
האשף ACDC Cloud הוא קלאסטר ה־Kafka לניתוח של ארכיטקטורת הרכב המחובר של Audi. הקלאסטר הוא היסוד של המוקדים הניתוחיים רבים, המעבדים נתוני IoT ולוג בקנה מידה עם פריימוורקים לעיבוד בצורת צ׳אץ' כמו Apache Spark.
הארכיטקטורה כבר הוצגה בשנת 2018. קריאת הסיסמה של Audi, "התקדמות דרך טכנולוגיה," מראה כיצד החברה החילה טכנולוגיה חדשה לחדשנות הרבה לפני שרוב יצרני הרכבים הפיצו תרחישים דומים. כל נתוני החיישנים מרכבי הרכב המחוברים מעובדים בזמן אמת ומאוחסנים לצורך ניתוח ודיווח היסטורי.
New Relic: תצפית בעננים מרביות ברחבי העולם
New Relic היא פלטפורמת תצפית בעננים מבוססת ענן המספקת מוניטורינג בזמן אמת וניתוחים לביצועים ללקוחות ברחבי העולם.
אנדרו הרטנט, סגן נשיא להנדסת תוכנה ב־New Relic, מסביר כיצד זרימת הנתונים חיונית לדגם העסקי כולו של New Relic:
"קפקא הוא המערכת העצבית המרכזית שלנו. זה חלק מכל מה שאנו עושים. רוב השירותים ב-110 צוותי ההנדסה השונים עם מאות שירותים נוגעים בקפקא בדרך מה, בצורה או בצורה אחרת בחברה שלנו, לכן זה באמת חיוני למשימה. מה שחיפשנו היה היכולת לצמוח, ו-Confluent Cloud סיפק את זה."
New Relic מטפל בעד 7 מיליארד נקודות נתונים לדקה ועל דרך זו ממוקם לעזור לספוג 2.5 אקסאבייט של נתונים ב-2023. כאשר New Relic מרחיבה את אסטרטגיות העננים הרבים שלה, צוותים ישתמשו ב-Confluent Cloud כדי לקבל תצוגת חלון יחידה למעלה מכל הסביבות.
"New Relic היא מרובת העננים. אנו רוצים להיות שם בו בו נמצאים הלקוחות שלנו. אנו רוצים להיות באותן סביבות, באותן אזורים, ורצינו שהקפקא שלנו יהיה איתנו." אומר Artnett במחקר מקרה של Confluent.
ציוד מרובה של קפקא הוא הכלל, ולא החריג
ארכיטקטורות שמופעלות על פי אירועים ופריטת לזרימה קיימות כבר כמה עשורים. האימוץ גדל עם סגנונות קוד פתוח כמו Apache Kafka ו-Flink בשילוב עם שירותי ענן מנוהלים במלואם. עוד ועוד ארגונים נאבקים עם הכללתם של הקפקא. שלטונות מידע ברמת הארגון, מרכזות המצווה, אוטומציה של ההצפנה והפעולות, ושיטות הארכיטקטורה הטובות ביותר מסייעים לספק בהצלחה זרימת נתונים עם מספר עריכות של קפקא עבור תחומי עסק עצמאיים או שמשתתפים.
מספר אשכולות Kafka הוא הכלל, לא החריג. מקרים שימוש כמו אינטגרציה היברידית, החלפת אסון, העברת מידע, או אגירות מאפשרים זרימת נתונים בזמן אמת בכל מקום עם תנאי SLA הנדרשים.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies