













Les utilisateurs ont tendance à remarquer plus facilement une baisse de performance à faible concurrence, tandis que les améliorations de performance à forte concurrence sont souvent plus difficiles à percevoir. Par conséquent, maintenir la performance à faible concurrence est crucial, car cela affecte directement l’expérience utilisateur et la volonté de mise à niveau [1].
Selon de nombreux retours d’utilisateurs, après la mise à niveau vers MySQL 8.0, les utilisateurs ont généralement constaté une baisse de performance, en particulier lors des opérations d’insertion par lots et de jointures. Cette tendance à la baisse est devenue plus évidente dans les versions supérieures de MySQL. De plus, certains passionnés de MySQL et testeurs ont signalé une dégradation des performances dans plusieurs tests sysbench après la mise à niveau.
Ces problèmes de performance peuvent-ils être évités ? Ou, plus précisément, comment devrions-nous évaluer scientifiquement la tendance actuelle à la baisse de performance ? Ce sont des questions importantes à considérer.
Bien que l’équipe officielle continue d’optimiser, la détérioration progressive des performances ne peut être ignorée. Dans certains scénarios, il peut sembler qu’il y ait des améliorations, mais cela ne signifie pas que la performance dans tous les scénarios est également optimisée. De plus, il est également facile d’optimiser la performance pour des scénarios spécifiques au prix de dégrader la performance dans d’autres domaines.
Les causes profondes de la baisse de performance de MySQL
En général, à mesure que de plus en plus de fonctionnalités sont ajoutées, la base de code s’agrandit, et avec l’expansion continue des fonctionnalités, la performance devient de plus en plus difficile à contrôler.
Les développeurs MySQL ont souvent du mal à remarquer le déclin des performances, car chaque ajout au code entraîne seulement une très légère diminution des performances. Cependant, au fil du temps, ces petites baisses s’accumulent, conduisant à un effet cumulatif significatif, qui amène les utilisateurs à percevoir une dégradation notable des performances dans les nouvelles versions de MySQL.
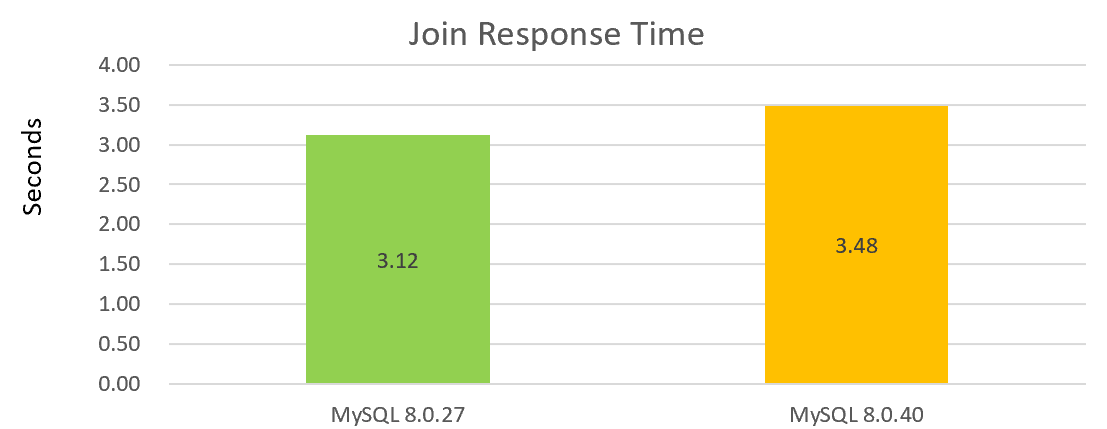
Par exemple, la figure suivante montre les performances d’une simple opération de jointure unique, avec MySQL 8.0.40 montrant un déclin des performances par rapport à MySQL 8.0.27 :
La figure suivante montre le test de performances d’insertion en lot en simple concurrence, avec le déclin des performances de MySQL 8.0.40 par rapport à la version 5.7.44 :
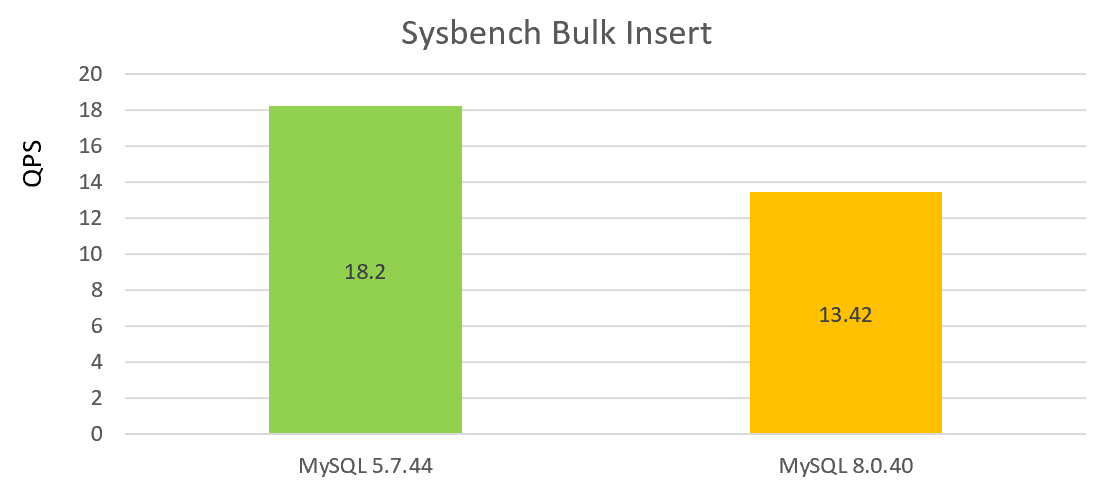
D’après les deux graphiques ci-dessus, on peut constater que les performances de la version 8.0.40 ne sont pas bonnes.
Ensuite, analysons la cause profonde de la dégradation des performances de MySQL au niveau du code. Voici la fonction PT_insert_values_list::contextualize dans MySQL 8.0 :
La fonction correspondante PT_insert_values_list::contextualize dans MySQL 5.7 est la suivante :
De la comparaison des codes, MySQL 8.0 semble avoir un code plus élégant, apparemment en progression.
Malheureusement, bien souvent, ce sont justement les motivations derrière ces améliorations de code qui entraînent la dégradation des performances. L’équipe officielle de MySQL a remplacé la structure de données List précédente par un deque, ce qui est devenu l’une des causes de la dégradation progressive des performances. Jetons un coup d’œil à la documentation de deque :
std::deque (double-ended queue) is an indexed sequence container that allows fast insertion and deletion at both its
beginning and its end. In addition, insertion and deletion at either end of a deque never invalidates pointers or
references to the rest of the elements.
As opposed to std::vector, the elements of a deque are not stored contiguously: typical implementations use a sequence
of individually allocated fixed-size arrays, with additional bookkeeping, which means indexed access to deque must
perform two pointer dereferences, compared to vector's indexed access which performs only one.
The storage of a deque is automatically expanded and contracted as needed. Expansion of a deque is cheaper than the
expansion of a std::vector because it does not involve copying of the existing elements to a new memory location. On
the other hand, deques typically have large minimal memory cost; a deque holding just one element has to allocate its
full internal array (e.g. 8 times the object size on 64-bit libstdc++; 16 times the object size or 4096 bytes,
whichever is larger, on 64-bit libc++).
The complexity (efficiency) of common operations on deques is as follows:
Random access - constant O(1).
Insertion or removal of elements at the end or beginning - constant O(1).
Insertion or removal of elements - linear O(n).
Comme indiqué dans la description ci-dessus, dans des cas extrêmes, conserver un seul élément nécessite d’allouer l’ensemble du tableau, ce qui entraîne une très faible efficacité mémoire. Par exemple, lors d’inserts en masse, où un grand nombre d’enregistrements doivent être insérés, l’implémentation officielle stocke chaque enregistrement dans une deque séparée. Même si le contenu de l’enregistrement est minimal, une deque doit toujours être allouée. L’implémentation de la deque de MySQL alloue 1 Ko de mémoire pour chaque deque afin de supporter des recherches rapides.
The implementation is the same as classic std::deque: Elements are held in blocks of about 1 kB each.
L’implémentation officielle utilise 1 Ko de mémoire pour stocker les informations d’index, et même si la longueur de l’enregistrement n’est pas grande mais qu’il y a de nombreux enregistrements, les adresses d’accès mémoire peuvent devenir non contiguës, ce qui entraîne une mauvaise compatibilité avec le cache. Ce design visait à améliorer la compatibilité avec le cache, mais il n’a pas été entièrement efficace.
Il convient de noter que l’implémentation originale utilisait une structure de données List, où la mémoire était allouée via un pool de mémoire, offrant un certain niveau de compatibilité avec le cache. Bien que l’accès aléatoire soit moins efficace, l’optimisation pour l’accès séquentiel aux éléments de la List améliore considérablement les performances.
Lors de la mise à niveau vers MySQL 8.0, les utilisateurs ont observé une baisse significative des performances des inserts par lots, et l’un des principales causes était le changement substantiel dans les structures de données sous-jacentes.
De plus, bien que l’équipe officielle ait amélioré le mécanisme de journalisation redo, cela a également conduit à une diminution de l’efficacité de l’opération de validation MTR. Par rapport à MySQL 5.7, le code ajouté réduit considérablement les performances des validations individuelles, même si le débit d’écriture global a été grandement amélioré.
Examinons l’opération centrale execute de la validation MTR dans MySQL 5.7.44 :
Examinons l’opération de base execute de la validation MTR dans MySQL 8.0.40 :
En comparaison, il est clair qu’avec MySQL 8.0.40, l’opération d’exécution dans la validation MTR est devenue beaucoup plus complexe, avec plus d’étapes impliquées. Cette complexité est l’une des principales causes de la baisse des performances en écriture à faible concurrence.
En particulier, les opérations m_impl->m_log.for_each_block(write_log) et log_wait_for_space_in_log_recent_closed(*log_sys, handle.start_lsn) ont des surcoûts significatifs. Ces changements ont été apportés pour améliorer les performances en haute concurrence, mais ils ont eu pour conséquence une baisse des performances en basse concurrence.
La priorisation du mode haute concurrence du journal de réexécution entraîne de mauvaises performances pour les charges de travail à faible concurrence. Bien que l’introduction de innodb_log_writer_threads visait à atténuer les problèmes de performances en basse concurrence, cela n’affecte pas l’exécution des fonctions mentionnées ci-dessus. Comme ces opérations sont devenues plus complexes et nécessitent des validations MTR fréquentes, les performances ont considérablement chuté.
Examinons l’impact de la fonctionnalité d’ajout/suppression instantanée sur les performances. Voici la fonction rec_init_offsets_comp_ordinary dans MySQL 5.7 :
La fonction rec_init_offsets_comp_ordinary dans MySQL 8.0.40 est la suivante :
À partir du code ci-dessus, il est clair qu’avec l’introduction de la fonctionnalité de colonne d’ajout/suppression instantanée, la fonction rec_init_offsets_comp_ordinary est devenue sensiblement plus complexe, introduisant plus d’appels de fonction et ajoutant une instruction switch qui impacte sévèrement l’optimisation du cache. Comme cette fonction est appelée fréquemment, elle a un impact direct sur les performances de la mise à jour de l’index, des insertions par lot et des jointures, entraînant une baisse significative des performances.
De plus, le déclin des performances dans MySQL 8.0 ne se limite pas à ce qui précède ; il existe de nombreux autres domaines qui contribuent à la dégradation globale des performances, en particulier l’impact sur l’expansion des fonctions en ligne. Par exemple, le code suivant affecte l’expansion des fonctions en ligne :
Selon nos tests, l’instruction ib::fatal interfère fortement avec l’optimisation en ligne. Pour les fonctions fréquemment accédées, il est conseillé d’éviter les instructions qui interfèrent avec l’optimisation en ligne.
Ensuite, examinons une autre problématique similaire. La fonction row_sel_store_mysql_field est fréquemment appelée, avec row_sel_field_store_in_mysql_format étant une fonction critique à l’intérieur de celle-ci. Le code spécifique est le suivant :
La fonction row_sel_field_store_in_mysql_format appelle en fin de compte row_sel_field_store_in_mysql_format_func.
La fonction row_sel_field_store_in_mysql_format_func ne peut pas être en ligne en raison de la présence du code ib::fatal.
Les fonctions inefficaces fréquemment appelées, exécutées des dizaines de millions de fois par seconde, peuvent avoir un impact considérable sur les performances des jointures.
Poursuivons l’exploration des raisons de la baisse de performance. L’optimisation des performances officielle suivante est en fait l’une des causes fondamentales de la baisse de performance des jointures. Bien que certaines requêtes puissent être améliorées, elles restent néanmoins parmi les raisons de la dégradation des performances des opérations de jointure ordinaires.
Les problèmes de MySQL vont au-delà de cela. Comme indiqué dans les analyses ci-dessus, la baisse de performance de MySQL n’est pas sans cause. Une série de petits problèmes, lorsqu’ils s’accumulent, peuvent entraîner une dégradation notable des performances que les utilisateurs constatent. Cependant, ces problèmes sont souvent difficiles à identifier, ce qui rend encore plus difficile leur résolution.
La soi-disant « optimisation prématurée » est la racine de tous les maux, et elle ne s’applique pas au développement MySQL. Le développement de bases de données est un processus complexe, et négliger les performances au fil du temps rend les améliorations de performances ultérieures nettement plus difficiles.
Solutions pour atténuer la baisse de performance de MySQL
Les principales raisons de la baisse des performances en écriture sont liées aux problèmes de validation MTR, aux ajouts/suppressions instantanés de colonnes, et à plusieurs autres facteurs. Il est difficile d’optimiser ceux-ci de manière traditionnelle. Cependant, les utilisateurs peuvent compenser la baisse de performance grâce à l’optimisation PGO. Avec une stratégie appropriée, les performances peuvent généralement être maintenues stables.
Pour la dégradation des performances de l’insertion par lots, notre version open-source [2] remplace la deque officielle par une implémentation de liste améliorée. Cela adresse principalement les problèmes d’efficacité mémoire et peut partiellement atténuer le déclin des performances. En combinant l’optimisation PGO avec notre version open-source, les performances de l’insertion par lots peuvent approcher celles de MySQL 5.7.

Les utilisateurs peuvent également tirer parti de plusieurs threads pour le traitement par lots simultané, en exploitant pleinement la meilleure concurrence du journal de réexécution, ce qui peut considérablement augmenter les performances de l’insertion par lots.
En ce qui concerne les problèmes de mise à jour d’index, en raison de l’ajout inévitable de nouveau code, l’optimisation PGO peut aider à atténuer ce problème. Notre version PGO [2] peut considérablement atténuer ce problème.
Pour les performances en lecture, en particulier les performances de jointure, nous avons apporté des améliorations substantielles, notamment en corrigeant les problèmes en ligne et en effectuant d’autres optimisations. Avec l’ajout de PGO, les performances de jointure peuvent être augmentées de plus de 30% par rapport à la version officielle.
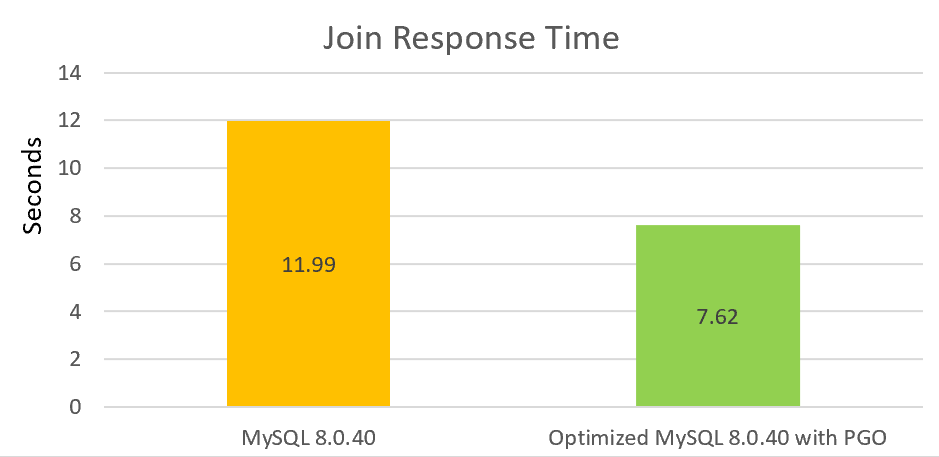
Nous continuerons à investir du temps dans l’optimisation des performances à faible concurrence. Ce processus est long mais implique de nombreux domaines nécessitant des améliorations.
La version open-source est disponible pour les tests, et les efforts se poursuivront pour améliorer les performances de MySQL.
Références
[1] Bin Wang (2024). L’art de la résolution de problèmes en génie logiciel : Comment améliorer MySQL.
Source:
https://dzone.com/articles/mysql-80-performance-degradation-analysis