













Le retard de réplication dans PostgreSQL se produit lorsque les modifications apportées sur le serveur principal prennent du temps à se refléter sur le serveur réplique. Que vous utilisiez la réplication en continu ou logique, le retard peut affecter les performances, la cohérence et la disponibilité du système. Cet article couvre les types de réplication, leurs différences, les causes du retard, les formules mathématiques pour l’estimation du retard, les techniques de surveillance et les stratégies pour minimiser le retard de réplication.
Types de réplication dans PostgreSQL
Réplication en continu
La réplication en continu envoie en continu les journaux d’écriture anticipée (WAL) des modifications du serveur principal à un ou plusieurs serveurs répliques en quasi temps réel. La réplique applique les modifications séquentiellement au fur et à mesure de leur réception. Cette méthode réplique l’ensemble de la base de données et garantit que les répliques restent synchronisées.
Avantages
- Faible latence avec une synchronisation en quasi temps réel.
- Efficace pour la réplication complète de la base de données.
Inconvénients
- Les répliques sont en lecture seule, donc toutes les transactions d’écriture doivent aller au nœud principal.
- Si la connexion réseau se rompt, le retard peut augmenter considérablement.
Réplication logique
La réplication logique transfère des modifications au niveau des données plutôt qu’au niveau des données WAL (Write-Ahead Log) de bas niveau. Elle permet une réplication sélective, où seules des tables spécifiques ou des parties d’une base de données sont répliquées. La réplication logique utilise un processus de décodage logique pour convertir les modifications WAL en modifications de type SQL.
Avantages
- Permet la réplication sélective de tables ou de schémas spécifiques.
- Prend en charge des répliques écrites avec des options de résolution de conflits.
Inconvénients
- Latence plus élevée en raison de la surcharge du décodage logique.
- Moins efficace que la réplication par flux pour de grands ensembles de données.
Comment se produit le retard de réplication
Le retard de réplication se produit lorsque le taux auquel les modifications sont générées sur le serveur principal dépasse le taux auquel elles peuvent être traitées et appliquées au serveur de réplique. Cet déséquilibre peut se produire en raison de divers facteurs sous-jacents, chacun contribuant à des retards dans la synchronisation des données. Les causes les plus courantes du retard de réplication sont :
Latence réseau
La latence réseau fait référence au temps que metent les données pour voyager du serveur principal au serveur de réplique. Les segments WAL (Write-Ahead Log) sont continuellement transmis sur le réseau pendant la réplication par flux. Même de légers retards dans la transmission réseau peuvent s’accumuler, provoquant un retard de la réplique.
Causes
- Temps de réponse (RTT) réseau élevés.
- Plus de bande passante pour gérer de grands volumes de données WAL.
- Congestion réseau ou perte de paquets.
Si le serveur principal génère des changements significatifs pendant les heures de pointe du trafic, un réseau lent ou surchargé peut causer un goulot d’étranglement, empêchant la réplique de recevoir les changements WAL.
Solution
Utilisez des connexions réseau à faible latence et à haut débit et activez la compression des WAL (wal_compression = on) pour réduire la taille des données pendant la transmission.
Goulots d’étranglement E/S
Les goulots d’étranglement E/S se produisent lorsque le disque d’un serveur de réplique est trop lent pour écrire les changements WAL entrants. La réplication en continu repose sur l’écriture des changements sur le disque avant leur application, donc tout retard dans le sous-système E/S peut entraîner un retard accumulé.
Causes
- Disques durs (HDD) lents ou surchargés.
- Débit d’écriture sur disque insuffisant.
- Conflit de disque avec d’autres processus.
- Si le serveur de réplique utilise des disques durs classiques (HDD) au lieu de disques à semi-conducteurs (SSD), les changements WAL peuvent ne pas être écrits assez rapidement pour suivre les changements de données, ce qui fait que la réplique prend du retard sur le serveur principal.
Solution
Pour optimiser l’E/S disque d’une réplique, utilisez des SSD pour des vitesses d’écriture plus rapides et isolez les processus de réplication des autres tâches intensives en écriture sur disque.
Contraintes CPU/Mémoire
Les processus de réplication nécessitent du CPU et de la mémoire pour décoder, écrire et appliquer les changements. Si un serveur de réplique manque de puissance de traitement ou de mémoire suffisante, il peut avoir du mal à suivre les modifications entrantes, ce qui entraîne un décalage de réplication.
Causes
- Cœurs de CPU limités ou processeurs lents.
- Mémoire insuffisante pour les tampons WAL.
- D’autres processus consomment des ressources CPU ou mémoire.
- Si la réplique traite de grandes transactions ou exécute des requêtes en même temps que la réplication, le CPU peut devenir saturé, ralentissant le processus de réplication.
Solution
Allouer plus de cœurs de CPU et de mémoire au serveur de réplication. Augmenter la taille des wal_buffers pour améliorer l’efficacité du traitement WAL.
Charges Lourdes sur le Serveur Principal
Un décalage de réplication peut également se produire lorsque le serveur principal génère trop de changements trop rapidement pour que la réplique puisse les gérer. Les grandes transactions, les insertions en masse ou les mises à jour fréquentes peuvent submerger la réplication.
Causes
- Importations de données en masse ou grandes transactions.
- Mises à jour fréquentes sur de grandes tables.
- Charges de travail à haute concurrence sur le serveur principal.
- La charge de transaction peut être trop importante si le serveur principal traite plusieurs grandes transactions simultanément, comme lors d’une importation de données en masse. Le volume de données WAL peut dépasser ce que la réplique peut traiter en temps réel, augmentant le décalage.
Solution
Optimisez les transactions en regroupant plus de mises à jour mineures et en évitant les transactions de longue durée. Si une synchronisation stricte n’est pas essentielle, utilisez la réplication asynchrone pour réduire la charge de réplication.
Conflit de ressources
Le conflit de ressources se produit lorsque plusieurs processus se disputent les mêmes ressources, telles que le CPU, la mémoire ou les entrées/sorties disque. Cela peut se produire soit sur le serveur primaire, soit sur le serveur de réplica et entraîner des retards dans le traitement de la réplication.
Causes
- D’autres processus consomment les entrées/sorties disque, le CPU ou la mémoire.
- Des tâches d’arrière-plan telles que des sauvegardes ou des analyses s’exécutent simultanément.
- Conflit réseau entre le trafic de réplication et d’autres transferts de données.
- Si le serveur de réplica exécute également des sauvegardes ou des requêtes analytiques, la concurrence pour les ressources CPU et disque pourrait ralentir le processus de réplication.
Solution
Isoler les charges de travail de réplication des autres processus intensifs en ressources. Planifiez les sauvegardes et les analyses pendant les heures creuses pour éviter les interférences avec la réplication.
Formule mathématique pour le retard de réplication
Utilisez la formule suivante pour calculer le retard de réplication:

Dans la réplication logique, le décodage logique consomme du temps supplémentaire:

Surveillance du retard de réplication
Surveillance de la réplication en continu
La vue pg_stat_replication peut être utilisée pour surveiller le délai de réplication en continu. Elle offre des informations sur l’état et le décalage entre les serveurs primaire et de réplication.
SELECT application_name, state,
pg_size_pretty(sent_lsn - write_lsn) AS lag_bytes,
sync_state
FROM pg_stat_replication;
sent_lsn: Dernier emplacement WAL envoyé à la réplica.write_lsn: Dernier emplacement WAL écrit sur la réplica.lag_bytes: La différence entre les deux indique le décalage.
Surveillance de la Réplication Logique
La réplication logique peut être surveillée en utilisant la vue pg_stat_subscription.
SELECT subscription_name, active,
pg_size_pretty(pg_current_wal_lsn() - replay_lsn) AS lag_bytes
FROM pg_stat_subscription;
Exemple: Visualisation du Délai de Réplication
Le fragment de code Python suivant visualise le délai de réplication en continu et logique au fil du temps.
import matplotlib.pyplot as plt
time = ['12:00', '12:10', '12:20', '12:30', '12:40', '12:50', '13:00']
streaming_lag = [0.5, 0.6, 0.4, 0.7, 1.0, 0.9, 0.6]
logical_lag = [2.0, 2.5, 3.0, 2.8, 3.5, 4.0, 3.2]
plt.plot(time, streaming_lag, label='Streaming Replication Lag', marker='o')
plt.plot(time, logical_lag, label='Logical Replication Lag', marker='s')
plt.xlabel('Time')
plt.ylabel('Lag (seconds)')
plt.title('Replication Lag Over Time')
plt.legend()
plt.grid(True)
# Save the plot as an image file
plt.savefig('replication_lag_plot.png')
print("Plot saved as replication_lag_plot.png")
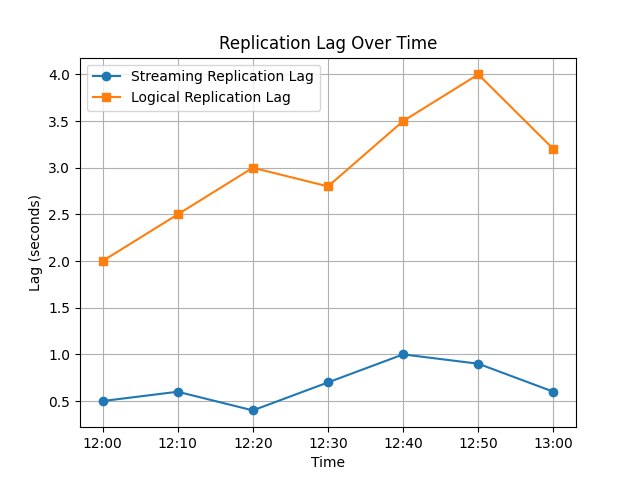
Le graphique résultant compare les performances de la réplication en continu et logique. La réplication logique a tendance à avoir un délai plus variable en raison des frais de décodage et de traitement.
Comment Réduire le Délai de Réplication
1. Optimisez la Configuration WAL
- Augmentez
wal_bufferspour stocker plus de données WAL en mémoire. - Définissez
wal_writer_delaysur une valeur plus basse (par exemple, 10 ms) pour écrire plus rapidement les données WAL.
wal_buffers = 64MB
wal_writer_delay = 10ms
2. Améliorer les performances réseau
- Utilisez des connexions réseau à faible latence et à haut débit entre le primaire et les réplicas.
- Compressez les données WAL pendant la transmission pour réduire le temps de transfert :
wal_compression = on.
3. Utilisez la réplication asynchrone (si possible)
-
La réplication asynchrone réduit le délai en ne attendant pas la confirmation des changements par le réplica, mais introduit un risque de perte de données.
ALTER SYSTEM SET synchronous_commit = 'off';
4. Activer l’application parallèle dans la réplication logique
-
PostgreSQL 14+ permet l’application parallèle des changements logiques, réduisant le délai pour les grandes transactions.
ALTER SUBSCRIPTION my_subscription SET (parallel_apply = on);
5. Allouer plus de ressources aux réplicas
- Assurez-vous que la réplique dispose de suffisamment de CPU et de mémoire pour traiter rapidement les modifications WAL.
- Utilisez des SSD pour un accès disque plus rapide sur la réplique.
6. Transactions par lots
-
Regroupez plusieurs mises à jour mineures en moins de transactions pour minimiser les frais généraux.
Exemples du monde réel
Réduction du décalage de réplication en streaming
Une entreprise exploitant un cluster PostgreSQL à fort trafic a rencontré un décalage de réplication pendant les heures de pointe. Ils ont réduit de moitié le décalage de réplication en augmentant wal_buffers à 64 Mo et en réduisant wal_writer_delay à 10 ms. Le passage à une connexion réseau à haute vitesse a réduit le décalage à moins d’une seconde.
Réduction du décalage de réplication logique
Un système avec plusieurs abonnements logiques a connu un décalage lors de charges de travail d’écriture élevées. L’activation de l’application parallèle dans PostgreSQL 14 a réparti la charge de travail entre de nombreux travailleurs, réduisant le décalage de réplication de 4 secondes à moins d’une seconde.
Conclusion
Le décalage de réplication est un problème critique qui affecte la performance et la cohérence des systèmes PostgreSQL. La réplication en streaming offre une faible latence mais nécessite que l’ensemble de la base de données soit répliqué, tandis que la réplication logique offre de la flexibilité mais avec des frais généraux plus élevés. Une surveillance régulière à l’aide de pg_stat_replication et pg_stat_subscription permet aux administrateurs de détecter et de réduire le décalage.
L’optimisation des configurations WAL, l’amélioration des performances réseau, l’utilisation d’applications parallèles et l’allocation de ressources suffisantes peuvent réduire significativement les retards. Un réglage adéquat garantit la synchronisation des réplicas et assure une haute disponibilité et performance du système.
Source:
https://dzone.com/articles/understanding-and-reducing-postgresql-replication-lag