













Qu’est-ce que Elasticsearch ?
Elasticsearch est un moteur de recherche et d’analyse distribué et open-source construit sur la bibliothèque Apache Lucene. Elasticsearch propose également une recherche vectorielle et une génération améliorée de récupération (RAG) , prenant en charge de manière transparente les applications d’IA modernes. Les applications peuvent stocker des données structurées et non structurées dans Elasticsearch, avec ou sans un schéma défini, en envoyant des charges JSON vers un cluster Elasticsearch.
Architecture Elasticsearch
Depuis le début, les principaux composants d’un cluster Elasticsearch sont :
Document
Un document est le plus petit enregistrement d’informations stocké par Elasticsearch et est représenté sous forme de JSON. Un document se compose de plusieurs champs (paires clé-valeur) de différents types et peut avoir un schéma prédéfini ou être sans schéma, inférant les types de données de tout nouveau champ indexé.
Index
Un index est une collection logique de documents avec le même schéma, identifiée par un nom d’index.
Shard
Les index Elasticsearch sont divisés en unités gérables appelées shards, qui sont une collection de documents. Les shards sont l’unité de base de la recherche et sont répliqués sur plusieurs nœuds pour la redondance et la tolérance aux pannes.
Nœud
Un nœud est une instance indépendante d’Elasticsearch et gère une collection de fragments qui appartiennent à un ou plusieurs indices. Les nœuds peuvent avoir différents rôles comme nœud de données, nœud maître et nœud d’ingestion.
Cluster
Un cluster Elasticsearch est une collection de nœuds interconnectés. Tous les nœuds d’un cluster peuvent gérer des demandes de clients et communiquer entre eux. Chaque nœud dans un cluster possède un sous-ensemble des fragments qui appartiennent à un index.
Architecture des requêtes
Le diagramme d’architecture suivant décrit le flux d’une requête de recherche :

- L’utilisateur ou l’application effectue une requête de recherche. La requête peut être traitée par n’importe quel nœud du cluster. Le nœud qui gère la demande est le nœud « coordinateur ».
- Le nœud coordinateur diffuse la requête à tous les fragments impliqués et leurs répliques.
- Chaque fragment exécute la requête localement et renvoie un ensemble léger de résultats au nœud coordinateur.
- Le nœud coordinateur fusionne les résultats qu’il reçoit. C’est la fin de la phase de « requête ». La phase de requête identifie les documents essentiels qui constituent le résultat de la recherche, mais le document complet doit encore être récupéré.
- Le nœud coordinateur envoie des demandes de récupération aux fragments propriétaires, qui enrichissent les documents dans l’ensemble de résultats.
- Les documents enrichis sont renvoyés au nœud coordinateur.
- L’ensemble complet des résultats de recherche, classé et enrichi, est renvoyé à l’appelant.
Architecture d’indexation
Le diagramme d’architecture suivant décrit le flux d’une demande d’indexation :
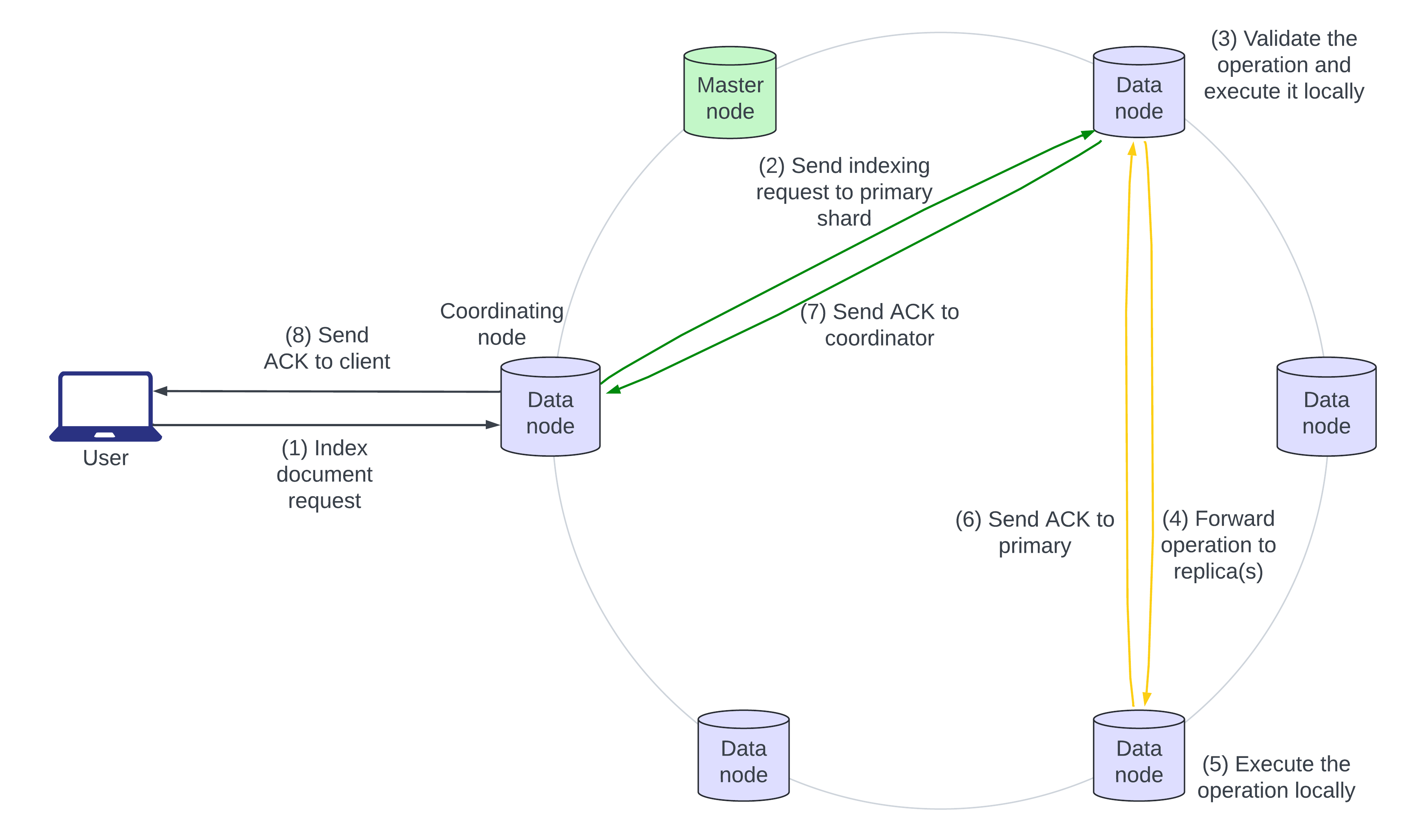
- L’utilisateur envoie un document JSON à Elasticsearch pour l’indexation. Si le document existe déjà, de nouveaux champs sont ajoutés et les champs existants sont écrasés. Le nœud qui reçoit en premier la demande est le nœud « coordinateur ».
- Le nœud coordinateur identifie le fragment principal du document entrant, généralement basé sur l’ID du document, et transmet la demande au nœud de données qui possède le fragment principal.
- Le fragment principal valide l’opération et l’exécute localement.
- Le fragment principal transmet ensuite l’opération à tous ses répliques en parallèle.
- Les répliques des fragments appliquent l’opération localement sur leurs nœuds.
- Les étapes 6, 7 et 8 montrent l’accusé de réception de l’écriture remontant de la réplique du fragment au fragment principal, au nœud coordinateur, puis à l’appelant.
Conclusion
Cet article décrit les différents composants d’un cluster Elasticsearch : documents, index, fragments et nœuds. Il décrit également le cycle de vie d’une demande de recherche et d’une demande d’indexation. Son architecture flexible facilite l’ajout et la suppression de nœuds à mesure que le cluster se développe. Associé à des fonctionnalités telles que l’indexation sans schéma et la prise en charge des fonctionnalités de recherche AI, cela fait d’Elasticsearch la norme de facto pour les organisations ayant besoin de stocker, rechercher et analyser efficacement de gros volumes de données en temps réel.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture