













Shift-left est une approche de développement et d’exploitation de logiciels qui met l’accent sur les tests, la surveillance et l’automatisation plus tôt dans le cycle de vie du développement logiciel. L’objectif de l’approche shift-left est d’empêcher les problèmes avant qu’ils ne se posent en les détectant tôt et en les traitant rapidement.
Lorsque vous identifiez un problème de scalabilité ou un bug tôt, il est plus rapide et plus économique de le résoudre. Déplacer un code inefficace vers des conteneurs cloud peut être coûteux, car cela peut activer l’auto-échelle et augmenter votre facture mensuelle. De plus, vous serez dans un état d’urgence jusqu’à ce que vous puissiez identifier, isoler et corriger le problème.
La Déclaration du Problème
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Voici la chronologie des événements.
Le 6 août à 14:13, l’application a été redémarrée avec un nouveau fichier jar Spring Boot contenant un Tomcat embarqué.
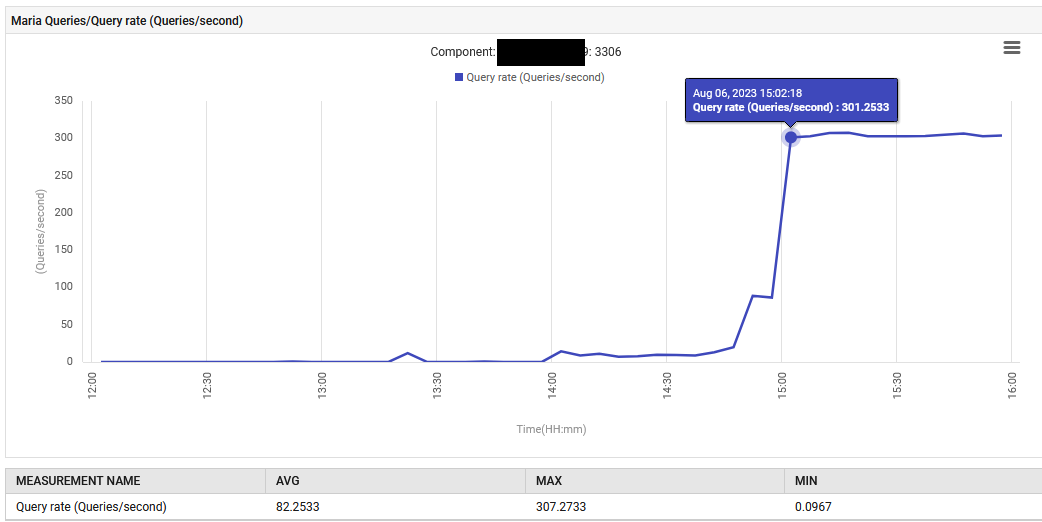
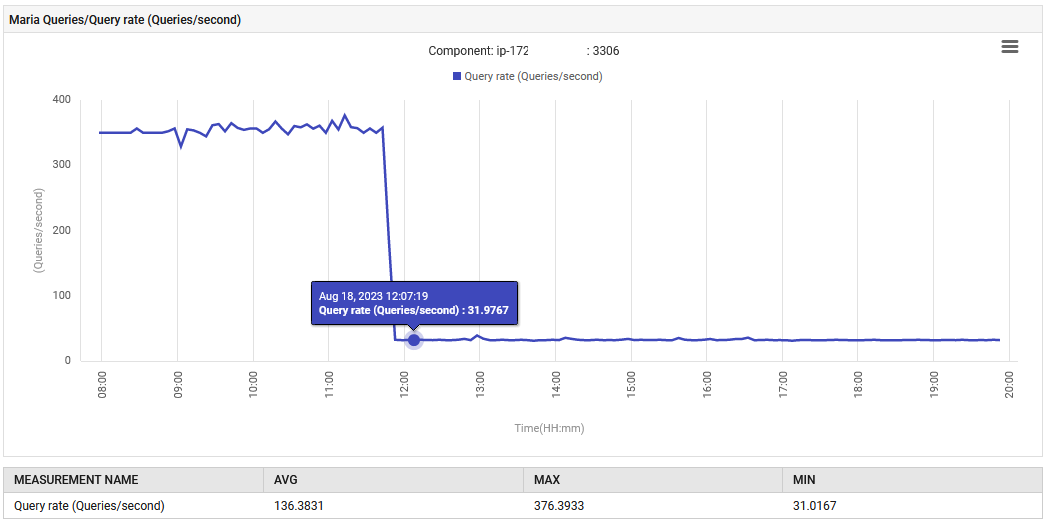
À 14:52, le taux de traitement des requêtes pour MariaDB a augmenté de 0,1 à 88 requêtes par seconde, puis à 301 requêtes par seconde.
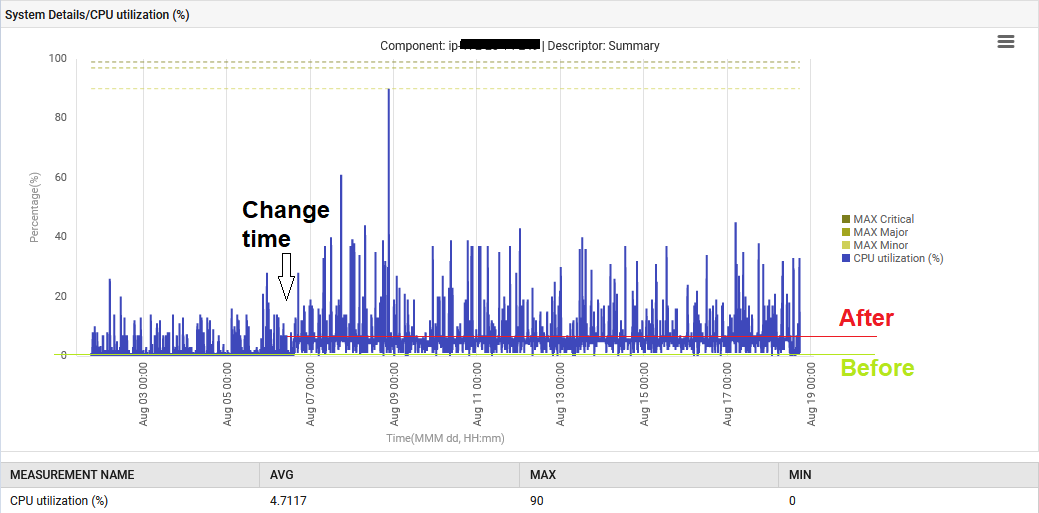
De plus, le système CPU a été élevé de 1% à 6%.
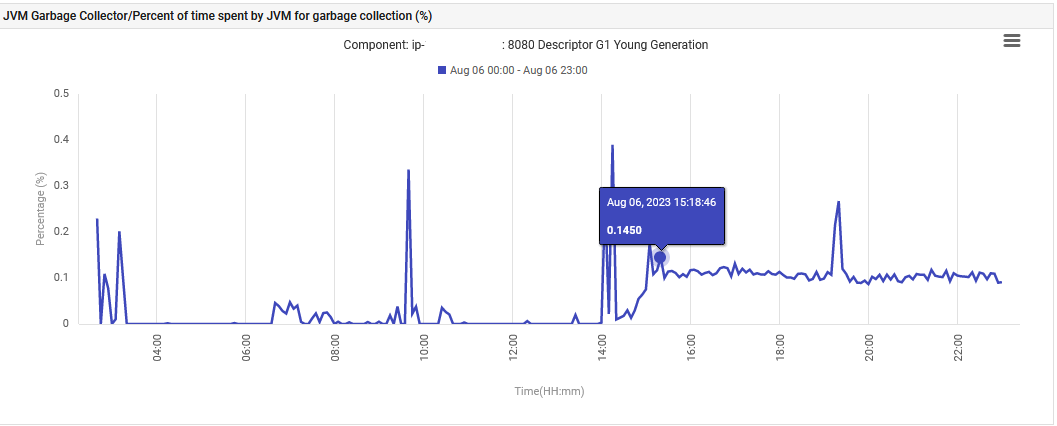
Enfin, le JVM temps consacré à la Collecte de Garbage G1 Young Generation a augmenté de 0% à 0,1% et est resté à ce niveau.
L’application, en phase UAT, émet de manière anormale 300 requêtes/sec, ce qui est bien au-delà de ce pour quoi elle a été conçue. La nouvelle fonctionnalité a entraîné une augmentation des connexions à la base de données, c’est pourquoi l’augmentation des requêtes est si drastique. Cependant, le tableau de bord de surveillance a montré que les mesures problématiques étaient normales avant le déploiement de la nouvelle version.
La Résolution
Il s’agit d’une application Spring Boot qui utilise JPA pour interroger une MariaDB. L’application est conçue pour fonctionner sur deux conteneurs pour une charge minimale mais est prévue pour s’échelonner jusqu’à dix.
Si un seul conteneur peut générer 300 requêtes par seconde, peut-il gérer 3000 requêtes par seconde si les dix conteneurs sont opérationnels? La base de données peut-elle avoir suffisamment de connexions pour répondre aux besoins des autres parties de l’application?
Nous n’avons eu d’autre choix que de retourner à la table du développeur pour inspecter les changements dans Git.
Le nouveau changement prendra quelques enregistrements d’une table et les traitera. Voici ce que nous avons observé dans la classe de service.
List<X> findAll = this.xRepository.findAll();
Non, utiliser la méthode findAll() sans pagination dans CrudRepository de Spring n’est pas efficace. La pagination aide à réduire le temps nécessaire pour récupérer les données à partir de la base de données en limitant la quantité de données récupérées. C’est ce que notre formation principale en RDBMS nous a appris. De plus, la pagination contribue à maintenir un faible usage de la mémoire pour empêcher l’application de planter en raison d’une surcharge de données, ainsi que de réduire l’effort de Garbage Collection de la Java Virtual Machine, comme mentionné dans l’énoncé du problème ci-dessus.
Cette expérience a été menée en utilisant seulement 2 000 enregistrements dans un seul conteneur. Si ce code devait être déployé en production, où il y a environ 200 000 enregistrements dans jusqu’à 10 conteneurs, cela aurait pu causer beaucoup de stress et d’inquiétude à l’équipe ce jour-là.
L’application a été reconstruite avec l’ajout d’une clause WHERE à la méthode.
List<X> findAll = this.xRepository.findAllByY(Y);
Le fonctionnement normal a été restauré. Le nombre de requêtes par seconde a diminué de 300 à 30, et l’effort consacré à la collecte des ordures est revenu à son niveau initial. De plus, l’utilisation du CPU du système a diminué.
Apprentissage et Résumé
Quiconque travaille dans le domaine de l’Ingénierie de la Fiabilité des Sites (SRE) appréciera l’importance de cette découverte. Nous avons pu agir sans avoir à déclencher un signal de gravité 1. Si ce package défectueux avait été déployé en production, il aurait pu déclencher le seuil d’auto-échelle du client, entraînant le lancement de nouveaux conteneurs même sans une charge d’utilisateurs supplémentaire.
Il y a trois principales leçons à retenir de cette histoire.
Premièrement, il est de bonne pratique d’activer une solution d’observabilité dès le début, car elle peut fournir un historique des événements qui peut être utilisé pour identifier d’éventuels problèmes. Sans cet historique, je n’aurais peut-être pas pris au sérieux un pourcentage de Garbage Collection de 0,1% et une consommation de CPU de 6%, et le code aurait pu être libéré en production avec des conséquences désastreuses. Élargir la portée de la solution de surveillance aux serveurs UAT a aidé l’équipe à identifier les causes potentielles et à prévenir les problèmes avant qu’ils ne se produisent.
Deuxièmement, des cas de test liés aux performances doivent exister dans le processus de test, et ils devraient être examinés par quelqu’un ayant de l’expérience en matière d’observabilité. Cela garantira que la fonctionnalité du code est testée, ainsi que ses performances.
Troisièmement, les techniques de suivi des performances cloud-native sont bonnes pour recevoir des alertes concernant une utilisation élevée, la disponibilité, etc. Pour atteindre l’observabilité, vous devrez peut-être avoir les bons outils et compétences en place. Joyeux codage!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c