













Dans cet article, nous passerons en revue comment installer, mettre à jour et supprimer des packages dans Red Hat Enterprise Linux 7. Nous expliquerons également comment automatiser des tâches à l’aide de cron, et nous terminerons ce guide en expliquant comment localiser et interpréter les fichiers journaux système, en mettant l’accent sur l’enseignement de l’importance de ces compétences pour tout administrateur système.

Gestion des packages via Yum
Pour installer un package ainsi que toutes ses dépendances qui ne sont pas déjà installées, vous utiliserez :
# yum -y install package_name(s)
Où nom_du_package(s) représente au moins un vrai nom de package.
Par exemple, pour installer httpd et mlocate (dans cet ordre), tapez :
# yum -y install httpd mlocate
Note : La lettre y dans l’exemple ci-dessus contourne les invites de confirmation que yum présente avant d’effectuer le téléchargement et l’installation réels des programmes demandés. Vous pouvez la laisser de côté si vous le souhaitez.
Par défaut, yum installera le package avec l’architecture correspondant à celle du système d’exploitation, sauf si elle est substituée en ajoutant l’architecture du package à son nom.
Par exemple, sur un système 64 bits, yum install package installera la version x86_64 du package, tandis que yum install package.x86 (si disponible) installera la version 32 bits.
Il y aura des moments où vous voudrez installer un paquet mais que vous ne connaissez pas son nom exact. Les options de recherche tout ou recherche peuvent rechercher les dépôts activés actuellement pour un certain mot-clé dans le nom du paquet et/ou dans sa description, respectivement.
Par exemple,
# yum search log
recherchera les dépôts installés pour les paquets contenant le mot « log » dans leur nom et leur résumé, tandis que
# yum search all log
cherchera le même mot-clé dans la description du paquet et les champs url.
Une fois la recherche renvoyant une liste de paquets, vous voudrez peut-être afficher plus d’informations sur certains d’entre eux avant de les installer. C’est là que l’option info sera utile:
# yum info logwatch
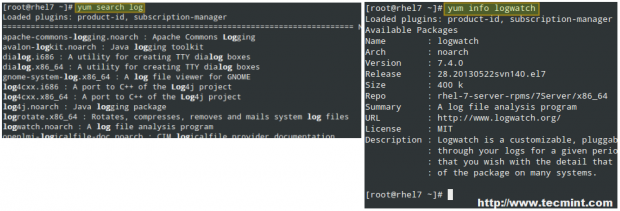
Vous pouvez vérifier régulièrement les mises à jour avec la commande suivante:
# yum check-update
La commande ci-dessus renverra tous les paquets installés pour lesquels une mise à jour est disponible. Dans l’exemple illustré dans l’image ci-dessous, seul rhel-7-server-rpms a une mise à jour disponible:

Vous pouvez ensuite mettre à jour ce paquet seul avec la commande suivante:
# yum update rhel-7-server-rpms
S’il y a plusieurs paquets qui peuvent être mis à jour, yum update les mettra tous à jour en une seule fois.
Et que se passe-t-il lorsque vous connaissez le nom d’un exécutable, comme ps2pdf, mais que vous ne savez pas quel paquet le fournit? Vous pouvez le découvrir avec la commande yum whatprovides "*/[executable]":
# yum whatprovides “*/ps2pdf”

Maintenant, en ce qui concerne la suppression d’un paquet, vous pouvez le faire avec la commande yum remove package. Facile, n’est-ce pas? Cela montre que yum est un gestionnaire de paquets complet et puissant.
# yum remove httpd
Lire aussi: 20 commandes Yum pour gérer la gestion des packages RHEL 7
Bon vieux RPM simple
RPM (alias RPM Package Manager, ou originellement RedHat Package Manager) peut également être utilisé pour installer ou mettre à jour des packages sous forme de packages autonomes .rpm.
Il est souvent utilisé avec les indicateurs -Uvh pour indiquer qu’il doit installer le package s’il n’est pas déjà présent ou tenter de le mettre à jour s’il est installé (-U), produisant une sortie détaillée (-v) et une barre de progression avec des marques de hachage (-h) pendant l’opération. Par exemple,
# rpm -Uvh package.rpm
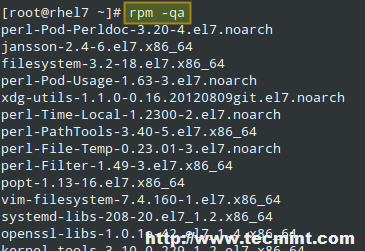
Une autre utilisation typique de rpm est de produire une liste des packages actuellement installés avec la commande rpm -qa (abréviation de query all) :
# rpm -qa
Lire aussi: 20 commandes RPM pour installer des packages dans RHEL 7
Planification des tâches à l’aide de Cron
Linux et d’autres systèmes d’exploitation de type Unix incluent un outil appelé cron qui vous permet de planifier des tâches (c’est-à-dire des commandes ou des scripts shell) pour qu’elles s’exécutent périodiquement. Cron vérifie chaque minute le répertoire /var/spool/cron à la recherche de fichiers portant le nom des comptes dans /etc/passwd.
Lors de l’exécution des commandes, toute sortie est envoyée à l’utilisateur du crontab (ou à l’utilisateur spécifié dans la variable d’environnement MAILTO dans le fichier /etc/crontab, s’il existe).
Les fichiers crontab (créés en tapant crontab -e et en appuyant sur Entrée) ont le format suivant :

Donc, si nous voulons mettre à jour la base de données locale des fichiers (utilisée par locate pour trouver des fichiers par nom ou motif) tous les deuxièmes jours du mois à 2h15 du matin, nous devons ajouter la ligne de crontab suivante :
15 02 2 * * /bin/updatedb
La ligne de crontab ci-dessus signifie : « Exécuter /bin/updatedb le deuxième jour du mois, tous les mois de l’année, quel que soit le jour de la semaine, à 2h15 du matin« . Comme vous l’avez sûrement deviné, le symbole étoile est utilisé comme caractère générique.
Après avoir ajouté une tâche cron, vous pouvez voir qu’un fichier nommé root a été ajouté à l’intérieur de /var/spool/cron, comme nous l’avons mentionné précédemment. Ce fichier répertorie toutes les tâches que le démon crond doit exécuter :
# ls -l /var/spool/cron
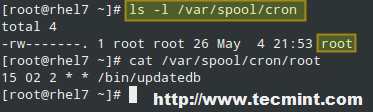
Dans l’image ci-dessus, le crontab de l’utilisateur actuel peut être affiché en utilisant soit cat /var/spool/cron/root, soit
# crontab -l
Si vous avez besoin d’exécuter une tâche de manière plus précise (par exemple, deux fois par jour ou trois fois par mois), cron peut également vous aider à le faire.
Par exemple, pour exécuter /mon/script le 1er et le 15ème de chaque mois et envoyer toute sortie vers /dev/null, vous pouvez ajouter deux lignes crontab comme suit :
01 00 1 * * /myscript > /dev/null 2>&1 01 00 15 * * /my/script > /dev/null 2>&1
Mais pour rendre la tâche plus facile à gérer, vous pouvez combiner les deux entrées en une seule :
01 00 1,15 * * /my/script > /dev/null 2>&1
En suivant l’exemple précédent, nous pouvons exécuter /mon/autre/script à 1h30 le premier jour du mois tous les trois mois :
30 01 1 1,4,7,10 * /my/other/script > /dev/null 2>&1
Mais lorsque vous devez répéter une certaine tâche toutes les « x » minutes, heures, jours ou mois, vous pouvez diviser la position correcte par la fréquence souhaitée. La commande crontab suivante a exactement la même signification que la précédente :
30 01 1 */3 * /my/other/script > /dev/null 2>&1
Ou peut-être avez-vous besoin d’exécuter une certaine tâche à une fréquence fixe ou après le démarrage du système, par exemple. Vous pouvez utiliser l’une des chaînes suivantes au lieu des cinq champs pour indiquer l’heure exacte à laquelle vous souhaitez que votre tâche s’exécute :
@reboot Run when the system boots. @yearly Run once a year, same as 00 00 1 1 *. @monthly Run once a month, same as 00 00 1 * *. @weekly Run once a week, same as 00 00 * * 0. @daily Run once a day, same as 00 00 * * *. @hourly Run once an hour, same as 00 * * * *.
Lire aussi : 11 commandes pour planifier des tâches cron sous RHEL 7
Localisation et vérification des journaux
Les journaux système sont situés (et tournés) dans le répertoire /var/log. Selon la norme de hiérarchie du système de fichiers Linux, ce répertoire contient des fichiers journaux divers, qui sont écrits dans ce répertoire ou dans un sous-répertoire approprié (comme audit, httpd ou samba dans l’image ci-dessous) par les démons correspondants pendant le fonctionnement du système :
# ls /var/log

D’autres journaux intéressants sont dmesg (contient tous les messages de la mémoire tampon de l’anneau du noyau), secure (enregistre les tentatives de connexion nécessitant une authentification utilisateur), messages (messages système) et wtmp (enregistre toutes les connexions et déconnexions des utilisateurs).
Les journaux sont très importants car ils vous permettent d’avoir un aperçu de ce qui se passe en permanence dans votre système, et de ce qui s’est passé dans le passé. Ils représentent un outil inestimable pour dépanner et surveiller un serveur Linux, et sont donc souvent utilisés avec la commande tail -f pour afficher en temps réel les événements au fur et à mesure de leur enregistrement dans un journal.
Par exemple, si vous souhaitez afficher des événements liés au noyau, tapez la commande suivante :
# tail -f /var/log/dmesg
De même si vous souhaitez consulter les accès à votre serveur web :
# tail -f /var/log/httpd/access.log
Résumé
Si vous savez comment gérer efficacement les paquets, planifier des tâches et où chercher des informations sur le fonctionnement actuel et passé de votre système, vous pouvez être assuré de ne pas rencontrer de surprises très souvent. J’espère que cet article vous a aidé à apprendre ou à actualiser vos connaissances sur ces compétences de base.
N’hésitez pas à nous contacter en utilisant le formulaire de contact ci-dessous si vous avez des questions ou des commentaires.
Source:
https://www.tecmint.com/yum-package-management-cron-job-scheduling-monitoring-linux-logs/