













Whisper AI est un modèle avancé de reconnaissance automatique de la parole (ASR) développé par OpenAI qui peut transcrire de l’audio en texte avec une précision impressionnante et prend en charge plusieurs langues. Bien que Whisper AI soit principalement conçu pour le traitement par lots, il peut être configuré pour la transcription en temps réel de la parole en texte sur Linux.
Dans ce guide, nous allons passer par le processus étape par étape d’installation, de configuration et d’exécution de Whisper AI pour la transcription en direct sur un système Linux.
Qu’est-ce que Whisper AI?
Whisper AI est un modèle de reconnaissance vocale open-source entraîné sur un vaste ensemble de données d’enregistrements audio et il est basé sur une architecture d’apprentissage profond qui lui permet de :
- Transcrire la parole en plusieurs langues.
- Gérer efficacement les accents et le bruit de fond.
- Effectuer la traduction de la langue parlée en anglais.
Étant donné qu’il est conçu pour une transcription de haute précision, il est largement utilisé dans :
- Services de transcription en direct (par exemple, pour l’accessibilité).
- Assistants vocaux et automatisation.
- Transcription de fichiers audio enregistrés.
Par défaut, Whisper AI n’est pas optimisé pour le traitement en temps réel. Cependant, avec quelques outils supplémentaires, il peut traiter des flux audio en direct pour une transcription immédiate.
Exigences système de Whisper AI
Avant d’exécuter Whisper AI sur Linux, assurez-vous que votre système répond aux exigences suivantes :
Exigences matérielles :
- CPU : Un processeur multicœur (Intel/AMD).
- RAM : Au moins 8 Go (16 Go ou plus est recommandé).
- GPU : GPU NVIDIA avec CUDA (optionnel mais accélère considérablement le traitement).
- Stockage : Minimum 10 Go d’espace disque libre pour les modèles et les dépendances.
Exigences logicielles :
- Une distribution Linux telle que Ubuntu, Debian, Arch, Fedora, etc.
- Version de Python 3.8 ou supérieure.
- Gestionnaire de paquets Pip pour l’installation des paquets Python.
- FFmpeg pour gérer les fichiers et flux audio.
Étape 1 : Installation des dépendances requises
Avant d’installer Whisper AI, mettez à jour votre liste de paquets et mettez à niveau les paquets existants.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Ensuite, vous devez installer Python 3.8 ou supérieur et le gestionnaire de paquets Pip comme indiqué.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Enfin, vous devez installer FFmpeg, qui est un cadre multimédia utilisé pour traiter les fichiers audio et vidéo.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Étape 2 : Installer Whisper AI sur Linux
Une fois que les dépendances requises sont installées, vous pouvez procéder à l’installation de Whisper AI dans un environnement virtuel qui vous permet d’installer des packages Python sans affecter les packages système.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
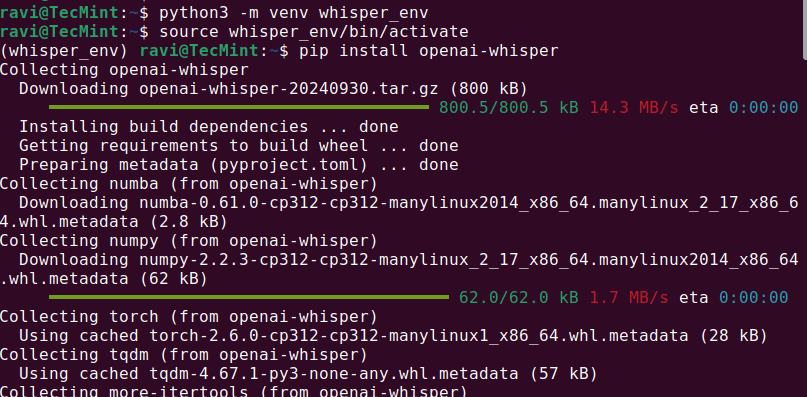
Une fois l’installation terminée, vérifiez si Whisper AI a été correctement installé en exécutant.
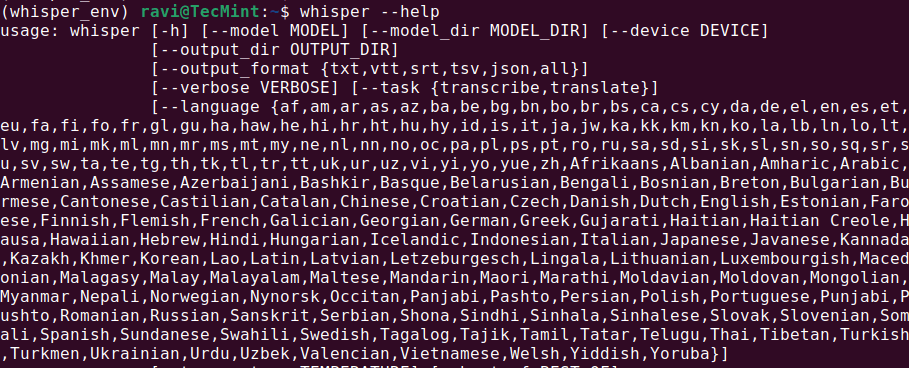
whisper --help
Cela devrait afficher un menu d’aide avec les commandes et options disponibles, ce qui signifie que Whisper AI est installé et prêt à être utilisé.
Étape 3 : Exécution de Whisper AI sous Linux
Une fois Whisper AI installé, vous pouvez commencer à transcrire des fichiers audio en utilisant différentes commandes.
Transcription d’un fichier audio
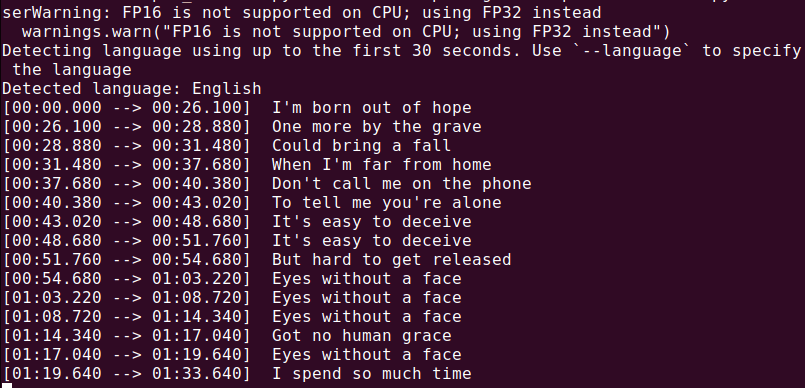
Pour transcrire un fichier audio (audio.mp3), exécutez :
whisper audio.mp3
Whisper va traiter le fichier et générer une transcription au format texte.
Maintenant que tout est installé, créons un script Python pour capturer l’audio de votre microphone et le transcrire en temps réel.
nano real_time_transcription.py
Copiez et collez le code suivant dans le fichier.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Exécutez le script en utilisant Python, qui commencera à écouter l’entrée de votre microphone et affichera le texte transcrit en temps réel. Parlez clairement dans votre microphone, et vous devriez voir les résultats imprimés sur le terminal.
python3 real_time_transcription.py
Conclusion
Whisper AI est un outil puissant de conversion de la parole en texte qui peut être adapté pour une transcription en temps réel sous Linux. Pour de meilleurs résultats, utilisez un GPU et optimisez votre système pour le traitement en temps réel.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/