













Lorsque vous travaillez avec Amazon S3 (Simple Storage Service), vous utilisez probablement la console web S3 pour télécharger, copier ou charger des fichiers dans les compartiments S3. Utiliser la console est tout à fait acceptable, c’est ce pour quoi elle a été conçue au départ.
Surtout pour les administrateurs habitués à cliquer plus avec la souris qu’à utiliser des commandes clavier, la console web est probablement la plus simple. Cependant, les administrateurs finiront par avoir besoin d’effectuer des opérations de fichiers en masse avec Amazon S3, comme le chargement de fichiers non surveillé. L’interface graphique utilisateur n’est pas le meilleur outil pour cela.
Pour de tels besoins d’automatisation avec Amazon Web Services, y compris Amazon S3, l’outil AWS CLI fournit aux administrateurs des options en ligne de commande pour gérer les compartiments et objets Amazon S3.
Dans cet article, vous apprendrez comment utiliser l’outil en ligne de commande AWS CLI pour charger, copier, télécharger et synchroniser des fichiers avec Amazon S3. Vous apprendrez également les bases de la fourniture d’accès à votre compartiment S3 et comment configurer ce profil d’accès pour fonctionner avec l’outil AWS CLI.
Prérequis
Comme il s’agit d’un article explicatif, il y aura des exemples et des démonstrations dans les sections suivantes. Pour que vous puissiez suivre avec succès, vous devrez remplir plusieurs conditions préalables.
- Un compte AWS. Si vous n’avez pas d’abonnement AWS existant, vous pouvez vous inscrire pour un Accès gratuit AWS.
- Un seau AWS S3. Vous pouvez utiliser un seau existant si vous préférez, mais il est recommandé de créer un seau vide à la place. Veuillez vous référer à la Création d’un seau.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- L’outil AWS CLI version 2 doit être installé sur votre ordinateur.
- Dossiers et fichiers locaux que vous téléverserez ou synchroniserez avec Amazon S3
Préparation de votre accès à AWS S3
Supposons que vous avez déjà les prérequis en place. Vous pensez probablement que vous pouvez déjà commencer à utiliser AWS CLI avec votre seau S3. Enfin, ce serait bien si c’était aussi simple, n’est-ce pas ?
Pour ceux d’entre vous qui commencent tout juste à travailler avec Amazon S3 ou AWS en général, cette section vise à vous aider à configurer l’accès à S3 et à configurer un profil AWS CLI.
La documentation complète pour créer un utilisateur IAM dans AWS se trouve dans le lien ci-dessous. Création d’un utilisateur IAM dans votre compte AWS
Création d’un utilisateur IAM avec autorisation d’accès à S3
Lors de l’accès à AWS en utilisant l’interface en ligne de commande, vous devrez créer un ou plusieurs utilisateurs IAM avec suffisamment d’accès aux ressources avec lesquelles vous avez l’intention de travailler. Dans cette section, vous allez créer un utilisateur IAM avec accès à Amazon S3.
Pour créer un utilisateur IAM avec accès à Amazon S3, vous devez d’abord vous connecter à votre console AWS IAM. Sous le groupe de gestion des accès, cliquez sur Utilisateurs. Ensuite, cliquez sur Ajouter un utilisateur.
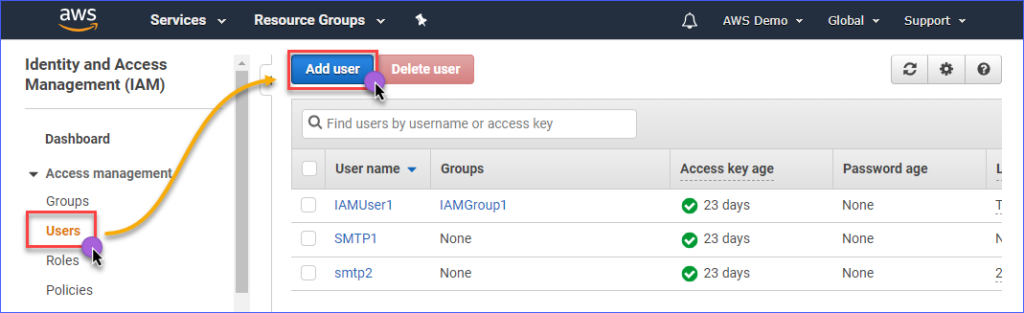
Saisissez le nom de l’utilisateur IAM que vous créez dans la zone Nom de l’utilisateur*, tel que s3Admin. Dans la sélection du Type d’accès*, cochez Accès programmé. Ensuite, cliquez sur le bouton Suivant : Autorisations.

Ensuite, cliquez sur Attacher directement des stratégies existantes. Ensuite, recherchez le nom de la stratégie AmazonS3FullAccess et cochez-la. Lorsque vous avez terminé, cliquez sur Suivant : Balises.

Créer des balises est facultatif dans la page Ajouter des balises, vous pouvez simplement ignorer cela et cliquer sur le bouton Suivant : Examiner.
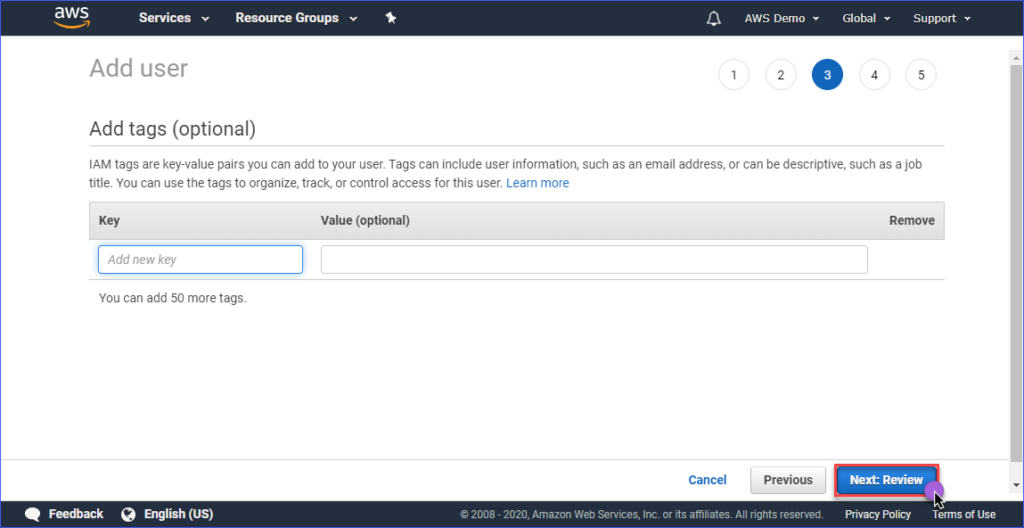
Dans la page Examiner, vous avez un résumé du nouveau compte en cours de création. Cliquez sur Créer un utilisateur.
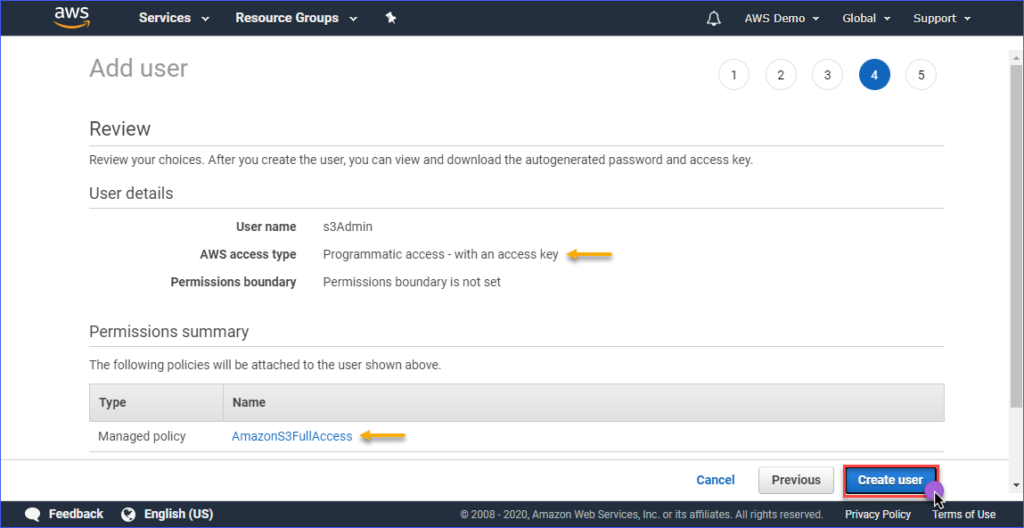
Enfin, une fois que l’utilisateur est créé, vous devez copier l’ID de clé d’accès et les valeurs de la Clé d’accès secrète et les sauvegarder pour une utilisation ultérieure. Notez que c’est la seule fois où vous pouvez voir ces valeurs.
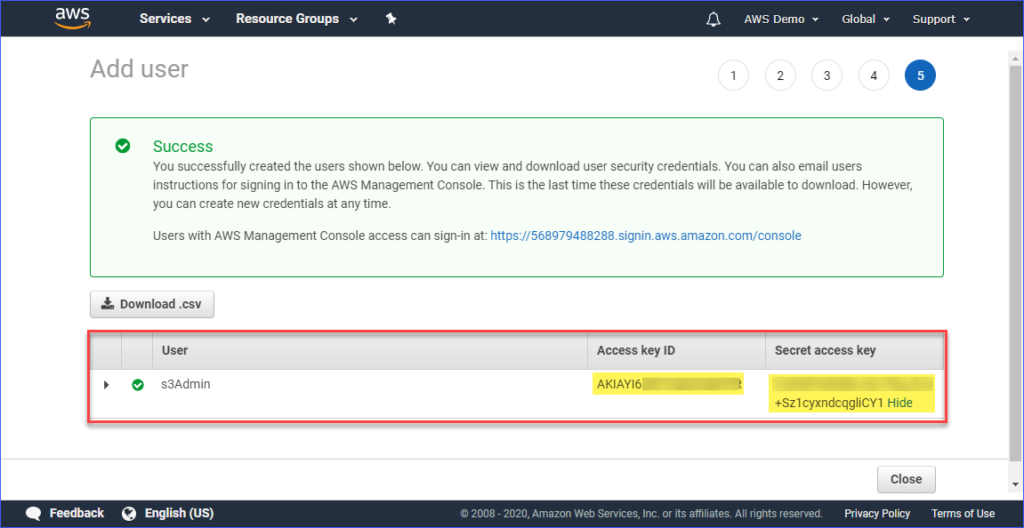
Mise en place d’un profil AWS sur votre ordinateur
Maintenant que vous avez créé l’utilisateur IAM avec l’accès approprié à Amazon S3, la prochaine étape consiste à configurer le profil AWS CLI sur votre ordinateur.
Cette section suppose que vous avez déjà installé l’outil AWS CLI version 2 comme requis. Pour la création du profil, vous aurez besoin des informations suivantes :
- L’ID de clé d’accès de l’utilisateur IAM.
- La clé d’accès secrète associée à l’utilisateur IAM.
- Le nom de la région par défaut correspond à l’emplacement de votre compartiment AWS S3. Vous pouvez consulter la liste des points de terminaison en utilisant ce lien. Dans cet article, le compartiment AWS S3 est situé dans la région Asie-Pacifique (Sydney), et le point de terminaison correspondant est ap-southeast-2.
- Le format de sortie par défaut. Utilisez JSON pour cela.
Pour créer le profil, ouvrez PowerShell et saisissez la commande ci-dessous, puis suivez les invites.
Entrez l’ID de la clé d’accès, la clé d’accès secrète, le nom de la région par défaut, et le nom de sortie par défaut. Référez-vous à la démonstration ci-dessous.

Test de l’accès à l’AWS CLI
Après avoir configuré le profil AWS CLI, vous pouvez confirmer que le profil fonctionne en exécutant la commande ci-dessous dans PowerShell.
La commande ci-dessus devrait afficher la liste des compartiments Amazon S3 que vous avez dans votre compte. La démonstration ci-dessous montre la commande en action. Le résultat indique que la configuration du profil a réussi.

Pour apprendre les commandes AWS CLI spécifiques à Amazon S3, vous pouvez visiter la page de référence des commandes AWS CLI S3.
Gestion des fichiers dans S3
Avec AWS CLI, les opérations de gestion de fichiers courantes peuvent être effectuées comme télécharger des fichiers vers S3, télécharger des fichiers depuis S3, supprimer des objets dans S3 et copier des objets S3 vers un autre emplacement S3. Tout dépend simplement de connaître la bonne commande, syntaxe, paramètres et options.
Dans les sections suivantes, l’environnement utilisé se compose des éléments suivants.
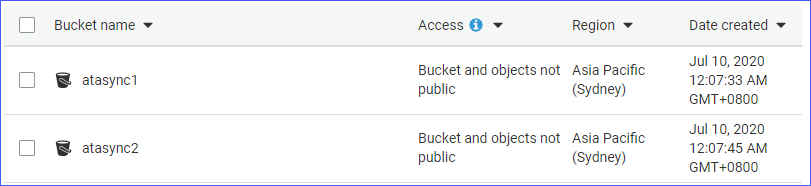
- Deux compartiments S3, nommément atasync1 et atasync2. La capture d’écran ci-dessous montre les compartiments S3 existants dans la console Amazon S3.
- Répertoire local et fichiers situés sous c:\sync.

Chargement de fichiers individuels dans S3
Lorsque vous téléchargez des fichiers vers S3, vous pouvez télécharger un fichier à la fois, ou en téléchargeant plusieurs fichiers et dossiers de manière récursive. Selon vos besoins, vous pouvez choisir l’une ou l’autre option que vous jugez appropriée.
Pour télécharger un fichier vers S3, vous devrez fournir deux arguments (source et destination) à la commande aws s3 cp.
Par exemple, pour télécharger le fichier c:\sync\logs\log1.xml à la racine du compartiment atasync1, vous pouvez utiliser la commande ci-dessous.
Note : Les noms de compartiments S3 sont toujours préfixés par S3:// lorsqu’ils sont utilisés avec AWS CLI
Exécutez la commande ci-dessus dans PowerShell, mais changez la source et la destination qui correspondent à votre environnement. La sortie devrait ressembler à la démonstration ci-dessous.

La démo ci-dessus montre que le fichier nommé c:\sync\logs\log1.xml a été téléchargé sans erreurs vers la destination S3 s3://atasync1/.
Utilisez la commande ci-dessous pour répertorier les objets à la racine du bucket S3.
Exécuter la commande ci-dessus dans PowerShell donnerait une sortie similaire, comme illustré dans la démo ci-dessous. Comme vous pouvez le voir dans la sortie ci-dessous, le fichier log1.xml est présent à la racine de l’emplacement S3.

Téléchargement de plusieurs fichiers et dossiers vers S3 de manière récursive
La section précédente vous a montré comment copier un seul fichier vers un emplacement S3. Que faire si vous devez télécharger plusieurs fichiers à partir d’un dossier et de sous-dossiers ? Vous ne voudriez sûrement pas exécuter la même commande plusieurs fois pour différents noms de fichiers, n’est-ce pas ?
La commande aws s3 cp dispose d’une option pour traiter les fichiers et dossiers de manière récursive, et il s’agit de l’option --recursive.
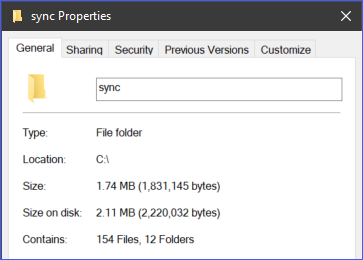
Par exemple, le répertoire c:\sync contient 166 objets (fichiers et sous-dossiers).
En utilisant l’option --recursive, tous les contenus du dossier c:\sync seront téléchargés vers S3 tout en conservant la structure des dossiers. Pour tester, utilisez le code exemple ci-dessous, mais assurez-vous de modifier la source et la destination en fonction de votre environnement.
Vous remarquerez dans le code ci-dessous que la source est c:\sync, et la destination est s3://atasync1/sync. La clé /sync qui suit le nom du bucket S3 indique à AWS CLI de télécharger les fichiers dans le dossier /sync dans S3. Si le dossier /sync n’existe pas dans S3, il sera automatiquement créé.
Le code ci-dessus donnera en sortie ce qui est démontré ci-dessous.

Téléchargement de plusieurs fichiers et dossiers vers S3 de manière sélective
Dans certains cas, télécharger TOUS les types de fichiers n’est pas la meilleure option. Par exemple, lorsque vous devez uniquement télécharger des fichiers avec des extensions de fichier spécifiques (par exemple *.ps1). Deux autres options disponibles pour la commande cp sont --include et --exclude.
Alors que l’utilisation de la commande dans la section précédente inclut tous les fichiers dans le téléchargement récursif, la commande ci-dessous n’inclura que les fichiers qui correspondent à l’extension de fichier *.ps1 et exclura tous les autres fichiers du téléchargement.
La démonstration ci-dessous montre comment le code ci-dessus fonctionne lorsqu’il est exécuté.

Un autre exemple est si vous souhaitez inclure plusieurs extensions de fichier différentes, vous devrez spécifier l’option --include plusieurs fois.
La commande d’exemple ci-dessous n’inclura que les fichiers *.csv et *.png à la commande de copie.
Exécuter le code ci-dessus dans PowerShell vous présenterait un résultat similaire, comme indiqué ci-dessous.

Téléchargement d’objets depuis S3
Basé sur les exemples que vous avez appris dans cette section, vous pouvez également effectuer les opérations de copie dans l’autre sens. Cela signifie que vous pouvez télécharger des objets depuis l’emplacement du bucket S3 vers la machine locale.
Copier depuis S3 vers local vous demanderait de changer les positions de la source et de la destination. La source étant l’emplacement S3, et la destination étant le chemin local, comme celui illustré ci-dessous.
Notez que les mêmes options utilisées lors du téléchargement de fichiers vers S3 s’appliquent également lors du téléchargement d’objets depuis S3 vers local. Par exemple, télécharger tous les objets en utilisant la commande ci-dessous avec l’option --recursive.
Copier des objets entre les emplacements S3
Outre le téléchargement et le téléversement de fichiers et de dossiers, en utilisant AWS CLI, vous pouvez également copier ou déplacer des fichiers entre deux emplacements de bucket S3.
Vous remarquerez la commande ci-dessous utilisant un emplacement S3 comme source et un autre emplacement S3 comme destination.
La démonstration ci-dessous vous montre le fichier source étant copié vers un autre emplacement S3 en utilisant la commande ci-dessus.

Synchronisation de fichiers et de dossiers avec S3
Vous avez appris comment téléverser, télécharger et copier des fichiers dans S3 en utilisant les commandes AWS CLI jusqu’à présent. Dans cette section, vous apprendrez une autre commande d’opération de fichier disponible dans AWS CLI pour S3, qui est la commande sync. La commande sync ne traite que les fichiers mis à jour, nouveaux et supprimés.
Il existe des cas où vous devez maintenir à jour et synchroniser le contenu d’un compartiment S3 avec un répertoire local sur un serveur. Par exemple, vous pouvez avoir l’exigence de synchroniser les journaux de transactions sur un serveur avec S3 à intervalles réguliers.
En utilisant la commande ci-dessous, les fichiers journaux *.XML situés sous le répertoire c:\sync sur le serveur local seront synchronisés avec l’emplacement S3 à s3://atasync1.
La démonstration ci-dessous montre qu’après l’exécution de la commande ci-dessus dans PowerShell, tous les fichiers *.XML ont été téléchargés vers la destination S3 s3://atasync1/.

Synchronisation des nouveaux fichiers et des mises à jour avec S3
Dans cet exemple suivant, on suppose que le contenu du fichier journal Log1.xml a été modifié. La commande sync devrait détecter cette modification et télécharger les modifications apportées au fichier local vers S3, comme le montre la démo ci-dessous.
La commande à utiliser est toujours la même que dans l’exemple précédent.

Comme vous pouvez le voir à partir de la sortie ci-dessus, étant donné que seul le fichier Log1.xml a été modifié localement, il a également été le seul fichier synchronisé vers S3.
Synchronisation des suppressions avec S3
Par défaut, la commande sync ne traite pas les suppressions. Tout fichier supprimé de l’emplacement source n’est pas supprimé à la destination. Enfin, sauf si vous utilisez l’option --delete.
Dans cet exemple suivant, le fichier nommé Log5.xml a été supprimé de la source. La commande de synchronisation des fichiers sera complétée avec l’option --delete, comme indiqué dans le code ci-dessous.
Lorsque vous exécutez la commande ci-dessus dans PowerShell, le fichier supprimé nommé Log5.xml doit également être supprimé à l’emplacement S3 de destination. Le résultat d’échantillon est présenté ci-dessous.

Résumé
Amazon S3 est une excellente ressource pour stocker des fichiers dans le cloud. Avec l’utilisation de l’outil AWS CLI, la manière dont vous utilisez Amazon S3 est encore élargie, ouvrant la possibilité d’automatiser vos processus.
Dans cet article, vous avez appris à utiliser l’outil AWS CLI pour télécharger, télécharger et synchroniser des fichiers et des dossiers entre des emplacements locaux et des compartiments S3. Vous avez également appris que le contenu des compartiments S3 peut également être copié ou déplacé vers d’autres emplacements S3.
Il peut y avoir de nombreux autres scénarios d’utilisation pour utiliser l’outil AWS CLI afin d’automatiser la gestion des fichiers avec Amazon S3. Vous pouvez même essayer de le combiner avec le script PowerShell et créer vos propres outils ou modules réutilisables. Cela dépend de vous de trouver ces opportunités et de montrer vos compétences.