













VAR-As-A-Service est une approche MLOps pour l’unification et la réutilisation de modèles statistiques et de pipelines de déploiement de modèles d’apprentissage automatique. Il s’agit du deuxième d’une série d’articles construits sur ce projet, représentant des expériences avec divers modèles statistiques et d’apprentissage automatique, des pipelines de données mis en œuvre à l’aide d’outils DAG existants, et des services de stockage, tant basés sur le cloud que des solutions locales alternatives. Cet article se concentre sur le stockage des fichiers de modèle en utilisant une approche également applicable et utilisée pour les modèles d’apprentissage automatique. Le stockage mis en place est basé sur MinIO en tant que service de stockage d’objets compatible avec AWS S3. De plus, l’article donne un aperçu des solutions de stockage alternatives et énumère les avantages du stockage basé sur des objets.
Le premier article de la série (Analyse des Séries Temporelles: VARMAX-As-A-Service) compare les modèles statistiques et d’apprentissage automatique en tant que modèles mathématiques et fournit une implémentation complète d’un modèle statistique basé sur VARMAX pour la prévision macroéconomique à l’aide d’une bibliothèque Python appelée statsmodels. Le modèle est déployé en tant que service REST à l’aide de Python Flask et du serveur web Apache, empaqueté dans un conteneur Docker. L’architecture générale de l’application est représentée dans la figure suivante:
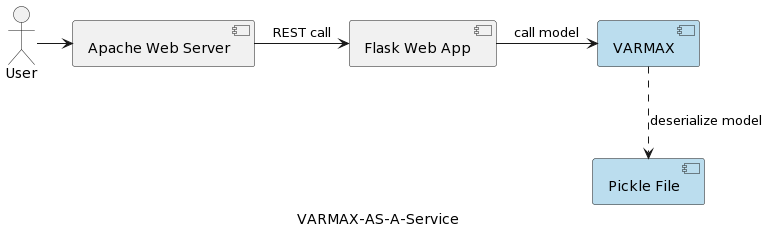
Le modèle est sérialisé en tant que fichier pickle et déployé sur le serveur web en tant que partie du paquetage de service REST. Cependant, dans les projets réels, les modèles sont versionnés, accompagnés d’informations métadonnées, sécurisés, et les expériences de formation doivent être enregistrées et conservées reproductibles. De plus, du point de vue architectural, stocker le modèle dans le système de fichiers à côté de l’application contredit le principe de responsabilité unique. Un bon exemple en est une architecture basée sur les microservices. L’échelle du service de modèle horizontalement signifie que chaque instance de microservice aura sa propre version du fichier pickle physique répliqué sur toutes les instances de service. Cela signifie également que le support de plusieurs versions des modèles nécessitera une nouvelle version et un redéploiement du service REST et de son infrastructure. L’objectif de cet article est de découpler les modèles de l’infrastructure du service web et d’autoriser la réutilisation de la logique du service web avec différentes versions de modèles.
Avant de plonger dans la mise en œuvre, disons quelques mots sur les modèles statistiques et le modèle VAR utilisé dans ce projet. Modèles statistiques sont des modèles mathématiques, tout comme les modèles d’apprentissage automatique. Plus de détails sur la différence entre les deux peuvent être trouvés dans le premier article de la série. Un modèle statistique est généralement spécifié comme une relation mathématique entre une ou plusieurs variables aléatoires et d’autres variables non aléatoires. Auto-régression vectorielle (VAR) est un modèle statistique utilisé pour capturer la relation entre plusieurs quantités au fur et à mesure qu’elles évoluent dans le temps. Les modèles VAR généralisent le modèle auto-régressif à variable unique (AR) en permettant des séries chronologiques multivariées. Dans le projet présenté, le modèle est entraîné pour faire de la prévision pour deux variables. Les modèles VAR sont souvent utilisés en économie et dans les sciences naturelles. En général, le modèle est représenté par un système d’équations, qui dans le projet sont cachées derrière la bibliothèque Python statsmodels.
L’architecture de l’application de service du modèle VAR est représentée dans l’image suivante :
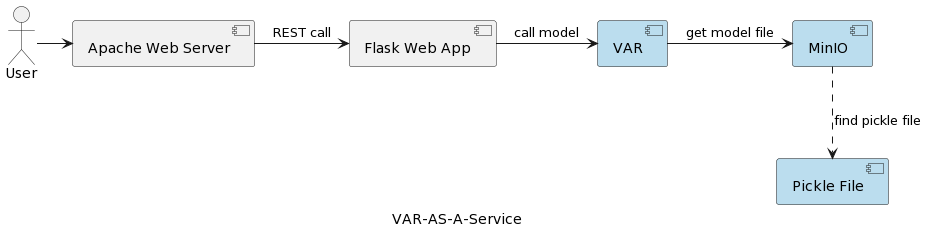
Le composant de runtime VAR représente l’exécution réelle du modèle en fonction des paramètres transmis par l’utilisateur. Il se connecte à un service MinIO via une interface REST, charge le modèle et exécute la prédiction. Par rapport à la solution de l’article précédent, où le modèle VARMAX est chargé et déserialisé au démarrage de l’application, le modèle VAR est lu depuis le serveur MinIO chaque fois qu’une prédiction est déclenchée. Cela se fait au prix d’un temps supplémentaire de chargement et de déserialisation, mais aussi avec l’avantage d’avoir la dernière version du modèle déployé à chaque exécution. De plus, cela permet la version dynamique des modèles, les rendant automatiquement accessibles aux systèmes externes et aux utilisateurs finaux, comme il sera montré plus loin dans l’article. Notez que, en raison de cet surcroît de chargement, la performance du service de stockage sélectionné est d’une grande importance.
Mais pourquoi MinIO et le stockage basé sur des objets en général?
MinIO est une solution d’archivage d’objets à haute performance avec un support natif pour les déploiements Kubernetes qui fournit une API compatible avec Amazon Web Services S3 et prend en charge toutes les fonctionnalités clés de S3. Dans le projet présenté, MinIO est en mode Standalone, composé d’un seul serveur MinIO et d’un seul disque ou volume de stockage sous Linux utilisant Docker Compose. Pour des environnements de développement ou de production étendus, il existe la possibilité d’un mode distribué décrit dans l’article Déployer MinIO en mode distribué.
Jetons un coup d’œil rapide à quelques alternatives de stockage, une description exhaustive pouvant être trouvée ici et ici:
- Stockage de fichiers local/distribué : Le stockage de fichiers local est la solution mise en œuvre dans le premier article, car c’est l’option la plus simple. Le calcul et le stockage sont sur le même système. C’est acceptable pendant la phase de PoC ou pour des modèles très simples prenant en charge une seule version du modèle. Les systèmes de fichiers locaux ont une capacité de stockage limitée et ne conviennent pas pour des jeux de données plus importants dans le cas où nous voulons stocker des métadonnées supplémentaires comme le jeu de données d’entraînement utilisé. Comme il n’y a pas de réplication ni d’auto-échelle, un système de fichiers local ne peut pas fonctionner de manière disponible, fiable et évolutive. Chaque service déployé pour l’échelle horizontale est déployé avec sa propre copie du modèle. De plus, le stockage local est aussi sécurisé que le système hôte l’est. Les alternatives au stockage de fichiers local sont le NAS (stockage rattaché à un réseau), le SAN (réseau de stockage), les systèmes de fichiers distribués (système de fichiers distribué Hadoop (HDFS), système de fichiers Google (GFS), système de fichiers élastique Amazon (EFS) et fichiers Azure). Par rapport au système de fichiers local, ces solutions sont caractérisées par la disponibilité, l’évolutivité et la résilience, mais sont associées au coût d’une complexité accrue.
- Bases de données relationnelles : En raison de la sérialisation binaire des modèles, les bases de données relationnelles offrent la possibilité de stocker des modèles en tant que blob ou données binaires dans les colonnes des tables. Les développeurs de logiciels et de nombreux scientifiques des données sont familiers avec les bases de données relationnelles, ce qui rend cette solution simple. Les versions du modèle peuvent être stockées comme des lignes de table distinctes avec des métadonnées supplémentaires, ce qui est facile à lire à partir de la base de données également. Un inconvénient est que la base de données nécessitera plus d’espace de stockage, et cela affectera les sauvegardes. Avoir de grandes quantités de données binaires dans une base de données peut également avoir un impact sur les performances. De plus, les bases de données relationnelles imposent certaines contraintes sur les structures de données, ce qui peut compliquer le stockage de données hétérogènes comme des fichiers CSV, des images et des fichiers JSON en tant que métadonnées du modèle.
- Stockage d’objets : Le stockage d’objets existe depuis un certain temps, mais a été révolutionné lorsque Amazon l’a transformé en le premier service AWS en 2006 avec le Simple Storage Service (S3). Le stockage d’objets moderne est natif du cloud, et d’autres nuages ont rapidement présenté leurs offres sur le marché. Microsoft propose le stockage Blob Azure, et Google a son service Google Cloud Storage. L’API S3 est la norme de facto pour que les développeurs interagissent avec le stockage dans le cloud, et il existe de nombreuses entreprises qui offrent un stockage compatible S3 pour le cloud public, le cloud privé et les solutions privées sur site. Quelle que soit l’emplacement d’un magasin d’objets, il est accessible via une interface RESTful. Bien que le stockage d’objets supprime le besoin de répertoires, de dossiers et d’autres organisations hiérarchiques complexes, ce n’est pas une bonne solution pour les données dynamiques qui changent constamment car vous devrez réécrire l’objet entier pour le modifier, mais c’est une bonne option pour stocker des modèles sérialisés et les métadonnées du modèle.
A summary of the main benefits of object storage are:
- Évolutivité massive : La taille du stockage d’objets est pratiquement illimitée, de sorte que les données peuvent atteindre des exabytes simplement en ajoutant de nouveaux dispositifs. Les solutions de stockage d’objets offrent également les meilleures performances lorsqu’elles fonctionnent en tant que cluster distribué.
- Réduction de la complexité : Les données sont stockées dans une structure plate. L’absence de complexité des arbres ou des partitions (pas de dossiers ou de répertoires) réduit la complexité de la récupération des fichiers, car il n’est pas nécessaire de connaître l’emplacement exact.
- Recherchabilité : Le métadonnées font partie des objets, ce qui facilite la recherche et la navigation sans avoir besoin d’une application distincte. On peut étiqueter les objets avec des attributs et des informations, telles que la consommation, le coût, et les politiques pour la suppression automatisée, la rétention et l’échelonnement. En raison de l’espace d’adressage plat du stockage sous-jacent (chaque objet n’est présent qu’dans un seul bucket et il n’y a pas de buckets dans les buckets), les magasins d’objets peuvent trouver un objet parmi des milliards d’objets rapidement.
- Résilience : Le stockage d’objets peut répliquer automatiquement les données et les stocker sur plusieurs dispositifs et emplacements géographiques. Cela peut aider à protéger contre les interruptions, à sécuriser contre la perte de données et à soutenir les stratégies de reprise d’activité après sinistre.
- Simplicité : L’utilisation d’une API REST pour stocker et récupérer des modèles implique presque aucune courbe d’apprentissage et rend les intégrations dans les architectures basées sur les microservices une option naturelle.
Il est temps de regarder la mise en œuvre du modèle VAR en tant que service et l’intégration avec MinIO. Le déploiement de la solution présentée est simplifié en utilisant Docker et Docker Compose. L’organisation de tout le projet est la suivante :

Comme dans le premier article, la préparation du modèle comprend quelques étapes écrites dans un script Python appelé var_model.py situé dans un dépôt GitHub dédié GitHub repository:
- Charger les données
- Diviser les données en ensemble d’entraînement et de test
- Préparer les variables endogènes
- Trouver le paramètre de modèle optimal p (les p premiers retards de chaque variable utilisés comme prédicteurs de régression)
- Instancier le modèle avec les paramètres optimaux identifiés
- Sérialiser le modèle instancié dans un fichier pickle
- Stocker le fichier pickle en tant qu’objet versionné dans un bucket MinIO
Ces étapes peuvent également être mises en œuvre comme tâches dans un moteur de workflow (par exemple, Apache Airflow) déclenché par la nécessité de former une nouvelle version du modèle avec des données plus récentes. DAGs et leur application en MLOps seront l’objet d’un autre article.
La dernière étape mise en œuvre dans var_model.py consiste à stocker le modèle sérialisé en tant que fichier pickle dans un bucket S3. En raison de la structure plate du stockage d’objets, le format choisi est :
<nom du bucket>/<nom_fichier>
Cependant, pour les noms de fichiers, il est autorisé d’utiliser une barre oblique pour imiter une structure hiérarchique tout en conservant l’avantage d’une recherche linéaire rapide. La convention pour stocker les modèles VAR est la suivante :
models/var/0_0_1/model.pkl
Le nom du bucket est models, et le nom du fichier est var/0_0_1/model.pkl et dans l’interface utilisateur MinIO, cela ressemble à ceci :

C’est une manière très pratique de structurer divers types de modèles et de versions de modèles tout en conservant les performances et la simplicité du stockage de fichiers plats.
Notez que la gestion des versions des modèles est implémentée en tant que partie du nom du modèle. MinIO fournit également la gestion des versions des fichiers, mais l’approche choisie ici présente certains avantages :
- Prise en charge des versions de snapshot et de remplacement
- Utilisation de la gestion des versions sémantiques (points remplacés par ‘_’ en raison de restrictions)
- Un contrôle accru de la stratégie de gestion des versions
- Découplage du mécanisme de stockage sous-jacent en termes de fonctionnalités de gestion des versions spécifiques
Une fois le modèle déployé, il est temps de l’exposer en tant que service REST à l’aide de Flask et de le déployer à l’aide de docker-compose en exécutant MinIO et un serveur Web Apache. L’image Docker, ainsi que le code du modèle, peuvent être trouvées sur un dépôt GitHub dédié GitHub repository.
Et enfin, les étapes nécessaires pour exécuter l’application sont :
- Déployer l’application :
docker-compose up -d - Exécuter l’algorithme de préparation du modèle :
python var_model.py(nécessite un service MinIO en cours d’exécution) - Vérifier si le modèle a été déployé : http://127.0.0.1:9101/browser
- Tester le modèle :
http://127.0.0.1:80/apidocs
Après le déploiement du projet, l’API Swagger est accessible via <host>:<port>/apidocs (par exemple, 127.0.0.1:80/apidocs). Il existe un point de terminaison pour le modèle VAR représenté à côté des deux autres exposant un modèle VARMAX :
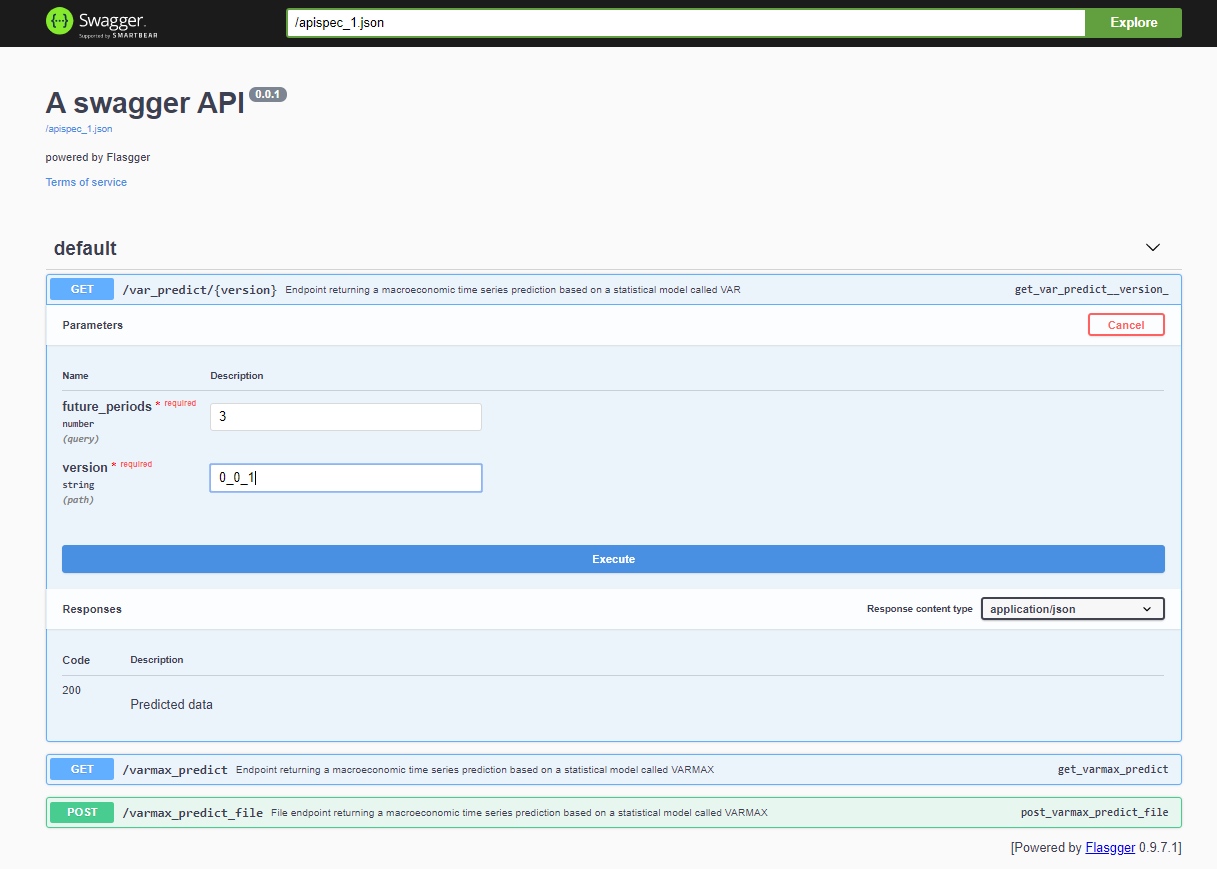
Intérieurement, le service utilise le fichier pickle du modèle déserialisé chargé à partir d’un service MinIO :
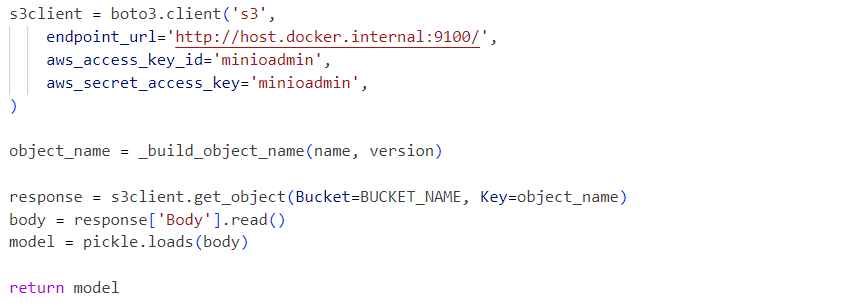
Les requêtes sont envoyées au modèle initialisé comme suit :

Le projet présenté est un workflow de modèle VAR simplifié qui peut être étendu étape par étape avec des fonctionnalités supplémentaires telles que :
- Explorer les formats de sérialisation standard et remplacer le pickle par une solution alternative
- Intégrer des outils de visualisation des données de séries chronologiques comme Kibana ou Apache Superset
- Stocker les données de séries chronologiques dans une base de données de séries chronologiques comme Prometheus, TimescaleDB, InfluxDB, ou un Stockage d’objets tel que S3
- Étendre le pipeline avec des étapes de chargement de données et de prétraitement des données
- Incorporer des rapports de métriques dans le cadre des pipelines
- Mettre en œuvre des pipelines à l’aide d’outils spécifiques comme Apache Airflow ou AWS Step Functions ou des outils plus standards comme Gitlab ou GitHub
- Comparer les performances et la précision des modèles statistiques avec les modèles d’apprentissage machine
- Mettre en œuvre des solutions intégrées cloud de bout en bout, y compris l’Infrastructure-As-Code
- Exposer d’autres modèles statistiques et ML en tant que services
- Mettre en place une API de stockage de modèles qui masque le mécanisme de stockage réel et la version du modèle, stocke les métadonnées du modèle et les données d’entraînement
Ces améliorations futures seront au cœur des prochains articles et projets. Le but de cet article est d’intégrer une API de stockage compatible S3 et d’activer le stockage de modèles versionnés. Cette fonctionnalité sera extraite dans une bibliothèque séparée prochainement. La solution d’infrastructure de bout en bout présentée peut être déployée en production et améliorée dans le cadre d’un processus CI/CD au fil du temps, également en utilisant les options de déploiement distribué de MinIO ou en le remplaçant par AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service