













Quiconque travaillant dans le DevOps aujourd’hui conviendrait probablement que la codification des ressources facilite l’observation, la gouvernance et l’automatisation. Cependant, la plupart des ingénieurs reconnaîtraient également que cette transformation entraîne un nouvel ensemble de défis.
Peut-être que le plus grand défi des opérations IaC est le drift — un scénario où les environnements d’exécution s’écartent de leurs états définis par IaC, créant un problème latent qui pourrait avoir de graves implications à long terme. Ces divergences sapent la cohérence des environnements cloud, entraînant des problèmes potentiels de fiabilité et de maintenabilité de l’infrastructure, voire des risques de sécurité et de conformité significatifs.
Dans un effort pour minimiser ces risques, ceux qui sont responsables de la gestion de ces environnements classifient le drift comme une tâche de haute priorité (et un gouffre de temps majeur) pour les équipes d’opérations d’infrastructure.
Cela a conduit à une adoption croissante d’outils de détection de drift qui signalent les divergences entre la configuration souhaitée et l’état réel de l’infrastructure. Bien qu’efficaces pour détecter le drift, ces solutions se limitent à émettre des alertes et à mettre en évidence les différences de code, sans offrir d’aperçus plus profonds sur la cause profonde.
Pourquoi la Détection de Drift est Insuffisante
L’état actuel de la détection de dérive découle du fait que les dérives se produisent en dehors du pipeline CI/CD établi et sont souvent attribuées à des ajustements manuels, des mises à jour déclenchées par API ou des correctifs d’urgence. En conséquence, ces changements ne laissent généralement pas de trace d’audit dans la couche IaC, créant ainsi un angle mort qui limite les outils à la simple signalisation des divergences de code. Cela laisse aux équipes d’ingénierie de plateforme le soin de spéculer sur l’origine de la dérive et sur la meilleure façon de la résoudre.
Ce manque de clarté rend la résolution de la dérive risquée. Après tout, revenir automatiquement sur des changements sans en comprendre le but — une approche par défaut courante — pourrait ouvrir la boîte de Pandore et déclencher une cascade de problèmes.
Un risque est que cela puisse annuler des ajustements légitimes ou des optimisations, réintroduisant potentiellement des problèmes déjà résolus ou perturbant les opérations d’un outil tiers précieux.
Prenons par exemple un correctif manuel appliqué en dehors du processus IaC habituel pour résoudre un problème de production soudain. Avant de revenir sur de tels changements, il est essentiel de les coder pour préserver leur intention et leur impact, ou de risquer de prescrire un remède qui pourrait s’avérer pire que la maladie.
Détection rencontre le contexte
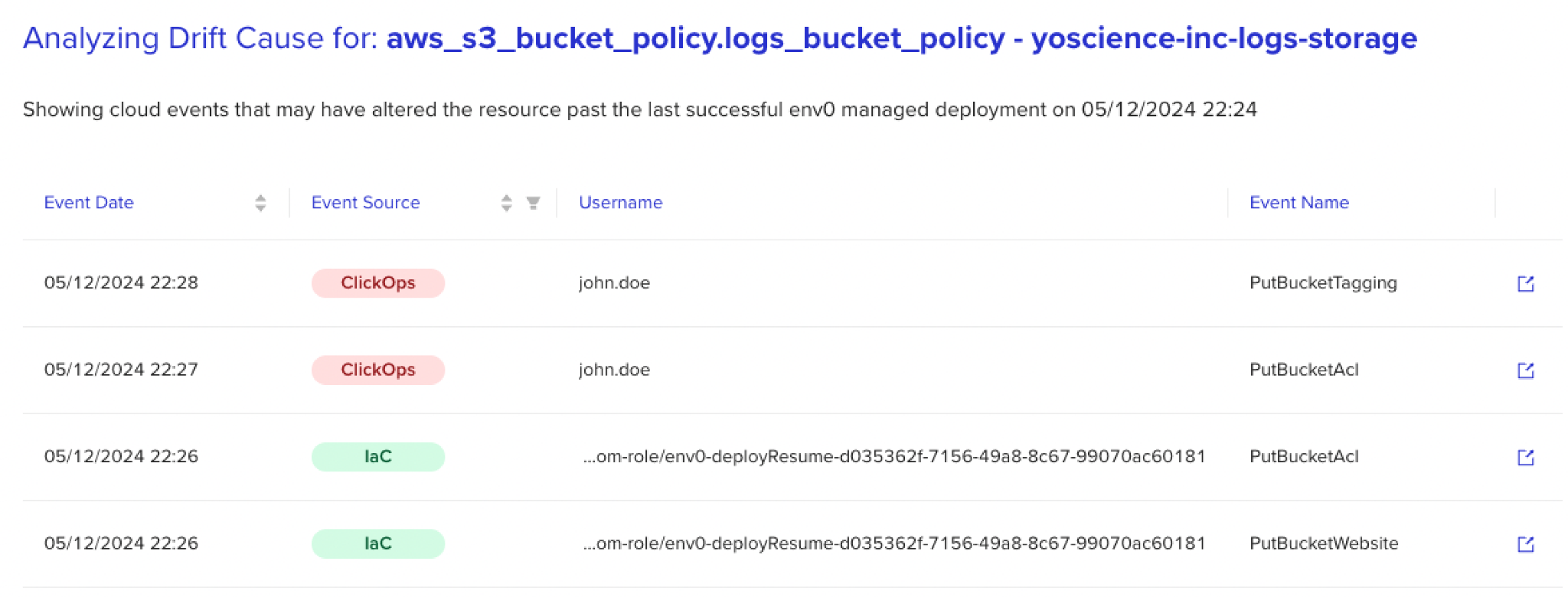
Voir des organisations lutter contre ces dilemmes a inspiré le concept de ‘Drift Cause.’ Ce concept utilise une logique assistée par IA pour trier de grands journaux d’événements et fournir un contexte supplémentaire pour chaque dérive, retraçant les changements jusqu’à leur origine — révélant non seulement le ‘quoi’ mais aussi le ‘qui,’ ‘quand,’ et ‘pourquoi.’
Cette capacité à traiter des journaux non uniformes en masse et à rassembler des données liées à la dérive renverse le processus de réconciliation. Pour illustrer, laissez-moi vous ramener au scénario que j’ai mentionné plus tôt et peindre un tableau de la réception d’une alerte de dérive de votre solution de détection — cette fois avec un contexte supplémentaire.
Maintenant, avec les informations fournies par Drift Cause, vous pouvez non seulement être conscient de la dérive mais aussi zoomer pour découvrir que le changement a été effectué par John à 2 heures du matin, juste au moment où l’application gérait une augmentation de trafic.
Sans cette information, vous pourriez supposer que la dérive est problématique et annuler le changement, perturbant potentiellement des opérations critiques et causant des pannes en aval.
Cependant, avec le contexte supplémentaire, vous pouvez relier les points, contacter John, confirmer que la solution a résolu un problème immédiat, et décider qu’elle ne devrait pas être réconciliée aveuglément. De plus, en utilisant ce contexte, vous pouvez également commencer à penser à l’avenir et introduire des ajustements à la configuration pour ajouter de l’évolutivité et prévenir la récurrence du problème.
Il s’agit d’un exemple simple, bien sûr, mais j’espère qu’il permettra de montrer l’avantage d’avoir un contexte supplémentaire sur la cause profonde – un élément depuis longtemps absent de la détection de dérive, bien qu’il soit standard dans d’autres domaines du débogage et du dépannage. Le but, bien sûr, est d’aider les équipes à comprendre non seulement ce qui a changé, mais pourquoi cela a changé, en les habilitant à prendre la meilleure décision en toute confiance.
Au-delà de la gestion de l’IaC
Mais avoir un contexte supplémentaire pour la dérive, aussi important soit-il, n’est qu’une partie d’un puzzle bien plus vaste. Gérer de vastes flottes de cloud avec des ressources codifiées introduit plus que des défis de dérive, surtout à grande échelle. Les outils de gestion de l’IaC de génération actuelle sont efficaces pour aborder la gestion des ressources, mais la demande d’une plus grande visibilité et d’un plus grand contrôle dans des environnements à l’échelle de l’entreprise introduit de nouvelles exigences et conduit à leur évolution inévitable.
Une direction vers laquelle je vois cette évolution se diriger est la Gestion des Actifs Cloud (CAM), qui suit et gère toutes les ressources dans un environnement cloud – qu’elles soient provisionnées via l’IaC, les APIs ou des opérations manuelles – fournissant une vue unifiée des actifs et aidant les organisations à comprendre les configurations, les dépendances et les risques, tous essentiels pour la conformité, l’optimisation des coûts et l’efficacité opérationnelle.
Alors que la gestion de l’IaC se concentre sur les aspects opérationnels, la gestion des actifs cloud met l’accent sur la visibilité et la compréhension de la posture cloud. Agissant comme une couche d’observabilité supplémentaire, elle comble le fossé entre les flux de travail codifiés et les changements ad hoc, fournissant une vue d’ensemble de l’infrastructure.
1+1 égale trois
La combinaison de la gestion de l’IaC et de la CAM permet aux équipes de gérer la complexité avec clarté et contrôle. À l’approche de la fin de l’année, c’est la ‘saison des prédictions’ — alors voici la mienne. Après avoir passé une grande partie de la dernière décennie à construire et affiner l’une des plateformes de gestion de l’IaC les plus populaires (si je peux me le permettre), je considère cela comme la progression naturelle de notre industrie : combiner la gestion de l’IaC, l’automatisation et la gouvernance avec une visibilité améliorée sur les actifs non codifiés.
Je crois que cette synergie formera la base d’un meilleur cadre de gouvernance cloud — un cadre plus précis, adaptable et résilient. À présent, il est presque acquis que l’IaC est la pierre angulaire de la gestion de l’infrastructure cloud. Pourtant, nous devons également reconnaître que tous les actifs ne seront jamais codifiés. Dans de tels cas, une solution de gestion d’infrastructure de bout en bout ne peut pas se limiter uniquement à la couche IaC.
La prochaine frontière, alors, est d’aider les équipes à élargir la visibilité sur les actifs non codifiés, en veillant à ce qu’à mesure que l’infrastructure évolue, elle continue à fonctionner sans accroc — une dérive réconciliée à la fois et au-delà.
Source:
https://dzone.com/articles/the-problem-of-drift-detection-and-drift-cause-analysis