













Amazon Simple Storage Service (S3) est un service d’objets de stockage hautement évolutif, durable et sécurisé proposé par Amazon Web Services (AWS). S3 permet aux entreprises de stocker et de récupérer n’importe quelle quantité de données à partir de n’importe où sur le web en utilisant ses services de niveau entreprise. S3 est conçu pour être hautement interopérable et s’intègre parfaitement avec d’autres services Amazon Web Services (AWS) et des outils et technologies tierces pour traiter les données stockées dans Amazon S3. L’un d’eux est Amazon EMR (Elastic MapReduce) qui vous permet de traiter de grandes quantités de données à l’aide d’outils open-source tels que Spark.
Apache Spark est un système de calcul distribué open-source utilisé pour le traitement de données à grande échelle. Spark est conçu pour permettre la rapidité et prend en charge divers sources de données, y compris Amazon S3. Spark offre un moyen efficace de traiter de grandes quantités de données et d’effectuer des calculs complexes en un temps minimal.
Memphis.dev est une alternative de nouvelle génération aux brokers de messages traditionnels. Un broker de messages cloud-native simple, robuste et durable, enveloppé dans tout un écosystème qui permet le développement efficace, rapide et fiable de cas d’utilisation basés sur la file d’attente modernes.
Le schéma commun des brokers de messages consiste à supprimer les messages après la période de rétention définie, comme le temps/la taille/le nombre de messages. Memphis propose une deuxième couche de stockage pour une rétention plus longue, voire infinie, pour les messages stockés. Chaque message qui est éjecté de la station migrera automatiquement vers la deuxième couche de stockage, qui dans ce cas est AWS S3.
Dans ce tutoriel, vous serez guidé à travers le processus de configuration d’une station Memphis avec une 2ème classe de stockage connectée à AWS S3. Un environnement sur AWS. Suivi de la création d’un bucket S3, de la configuration d’un cluster EMR, de l’installation et de la configuration d’Apache Spark sur le cluster, de la préparation des données dans S3 pour le traitement, du traitement des données avec Apache Spark, des meilleures pratiques et de l’optimisation des performances.
Configuration de l’Environnement
Memphis
- Pour commencer, d’abord installer Memphis.
- Activer l’intégration AWS S3 via le centre d’intégration de Memphis.
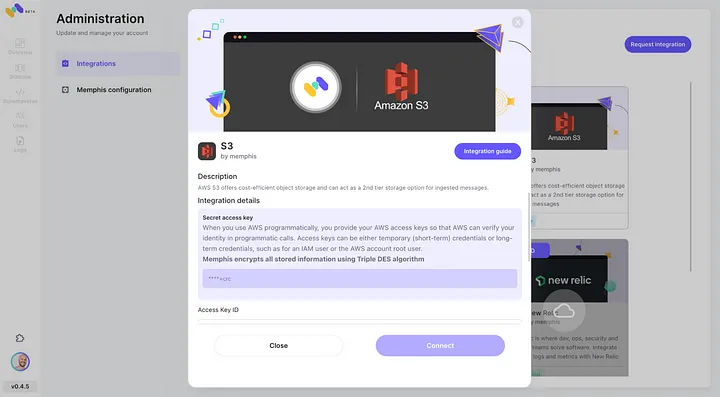
3. Créer une station (sujet) et choisir une politique de rétention.
4. Chaque message dépassant la politique de rétention configurée sera déchargé vers un bucket S3.
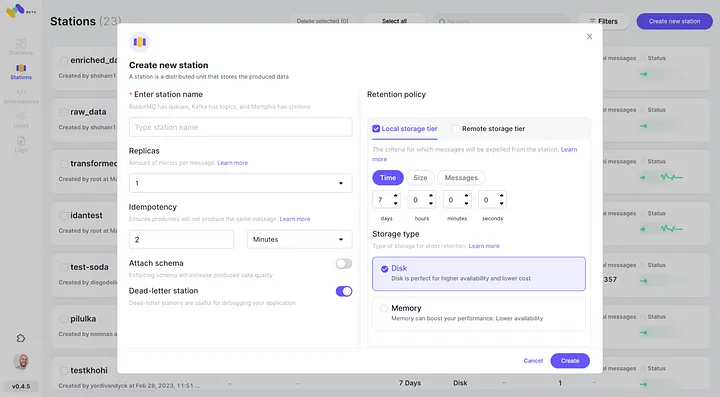
5. Vérifier la nouvelle intégration AWS S3 configurée en tant que 2ème classe de stockage en cliquant sur « Se connecter. »
6. Commencer à produire des événements pour votre nouvelle station Memphis créée.
Créer un Bucket AWS S3
Si vous ne l’avez pas déjà fait, d’abord, vous devez créer un compte AWS. Ensuite, créez un bucket S3 où vous pourrez stocker vos données. Vous pouvez utiliser le AWS Management Console, l’AWS CLI ou un SDK pour créer un bucket. Pour ce tutoriel, vous utiliserez le console de gestion AWS.
Cliquez sur « Créer un bucket. »
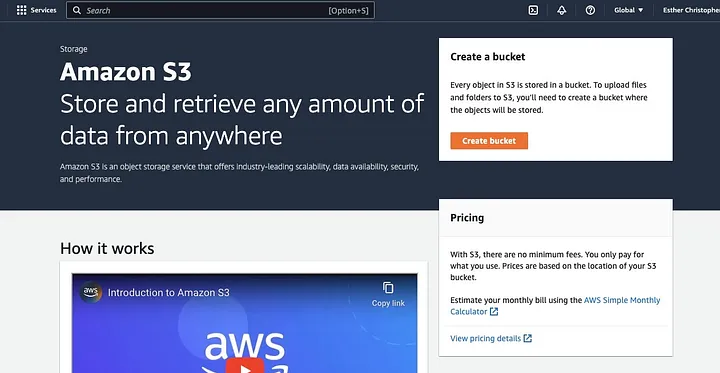
Ensuite, procédez à créer un nom de bucket conforme à la convention de nommage et choisissez la région où vous voulez que le bucket soit situé. Configurez le « Propriété des objets » et « Bloquer tout accès public » selon votre cas d’utilisation.
Assurez-vous de configurer d’autres autorisations de bucket pour permettre à votre application Spark d’accéder aux données. Enfin, cliquez sur le bouton « Créer un bucket » pour créer le bucket.
Configuration d’un Cluster EMR Avec Spark Installé
Amazon Elastic MapReduce (EMR) est un service web basé sur Apache Hadoop qui permet aux utilisateurs de traiter efficacement d’énormes quantités de données en utilisant des technologies big data, y compris Apache Spark. Pour créer un cluster EMR avec Spark installé, ouvrez le console EMR et sélectionnez « Clusters » sous « EMR on EC2 » sur le côté gauche de la page.
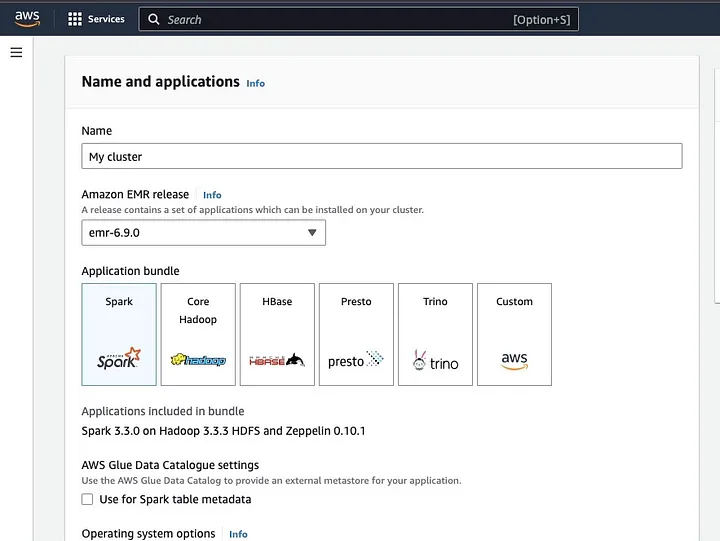
Cliquez sur « Créer un cluster » et attribuez au cluster un nom descriptif. Sous « Application bundle », sélectionnez Spark pour l’installer sur votre cluster.
Faites défiler jusqu’à la section « Logs du cluster » et sélectionnez la case à cocher « Publier les journaux spécifiques au cluster sur Amazon S3 ».
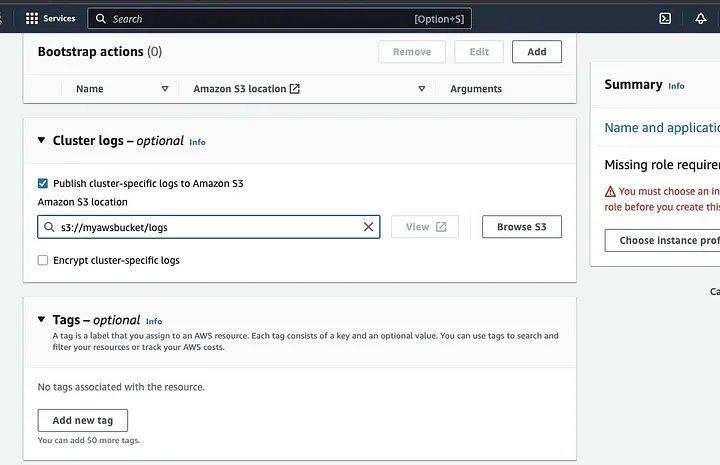
Cela affichera une invite pour saisir l’emplacement Amazon S3 en utilisant le nom du bucket S3 que vous avez créé à l’étape précédente, suivi de /logs, c’est-à-dire s3://myawsbucket/logs. /logs sont requis par Amazon pour créer un nouveau dossier dans votre bucket où Amazon EMR peut copier les fichiers journaux de votre cluster.
Allez à la section « Configuration de la sécurité et des autorisations » et entrez votre paire de clés EC2 ou choisissez l’option de création d’une paire de clés.
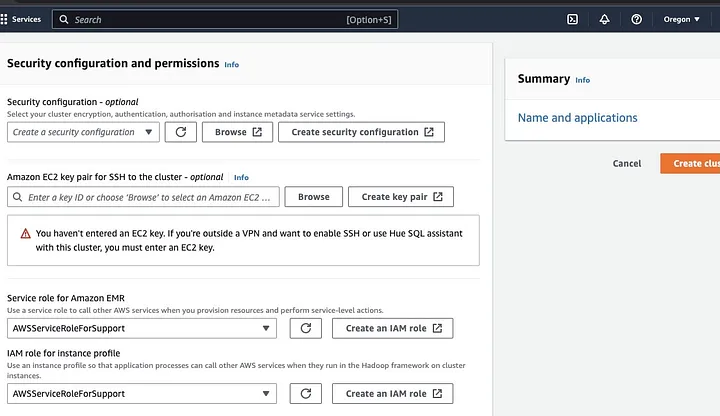
Puis cliquez sur les options déroulantes pour « Rôle de service pour Amazon EMR » et choisissez AWSServiceRoleForSupport. Choisissez la même option déroulante pour « Rôle IAM pour le profil d’instance ». Actualisez l’icône si nécessaire pour obtenir ces options déroulantes.
Enfin, cliquez sur le bouton « Créer un cluster » pour lancer le cluster et surveiller l’état du cluster pour vérifier qu’il a été créé.
Installation et Configuration d’Apache Spark sur un Cluster EMR
Après avoir créé avec succès un cluster EMR, l’étape suivante sera de configurer Apache Spark sur le Cluster EMR. Les clusters EMR offrent un environnement géré pour exécuter des applications Spark sur l’infrastructure AWS, ce qui facilite le lancement et la gestion de clusters Spark dans le cloud. Il configure Spark pour fonctionner avec vos données et vos besoins de traitement, puis soumet des tâches Spark au cluster pour traiter vos données.
Vous pouvez configurer Apache Spark sur le cluster à l’aide du protocole Secure Shell (SSH). Mais d’abord, vous devez autoriser les connexions sécurisées SSH à votre cluster, qui a été défini par défaut lorsque vous avez créé le cluster EMR. Un guide sur la façon d’autoriser les connexions SSH peut être trouvé ici.
Pour créer une connexion SSH, vous devez spécifier le couple de clés EC2 que vous avez sélectionné lors de la création du cluster. Ensuite, connectez-vous au cluster EMR en utilisant l’interpréteur de commandes Spark en vous connectant d’abord au nœud principal. Vous devez d’abord récupérer le DNS public du maître du nœud principal en vous dirigeant à gauche de la console AWS, sous EMR sur EC2, choisissez Clusters, puis sélectionnez le cluster du nom de DNS public que vous souhaitez obtenir.
Sur votre terminal OS, entrez la commande suivante.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemRemplacez ec2-###-##-##-###.compute-1.amazonaws.com par le nom de votre DNS public maître et ~/mykeypair.pem par le nom de fichier et le chemin de votre fichier .pem (Suivez ce guide pour obtenir le fichier .pem ici). Un message de confirmation apparaîtra, à qui votre réponse doit être oui — tapez exit pour fermer la commande SSH.
Préparation des données pour le traitement avec Spark et téléchargement vers le bucket S3
Le traitement des données nécessite une préparation avant de les télécharger pour présenter les données sous un format que Spark peut facilement traiter. Le format utilisé est influencé par le type de données que vous possédez et l’analyse que vous prévoyez d’effectuer. Certains formats utilisés incluent CSV, JSON et Parquet.
Créez une nouvelle session Spark et chargez vos données dans Spark en utilisant l’API pertinente. Par exemple, utilisez la méthode spark.read.csv() pour lire des fichiers CSV dans un DataFrame Spark.
Amazon EMR, un service géré pour les clusters du système d’exploitation Hadoop, peut être utilisé pour traiter les données. Il réduit le besoin de configurer, d’ajuster et de maintenir des clusters. Il intègre également d’autres fonctionnalités avec Amazon SageMaker, par exemple, pour démarrer un travail de formation de modèle SageMaker à partir d’un pipeline Spark dans Amazon EMR.
Une fois vos données prêtes, en utilisant la méthode DataFrame.write.format("s3"), vous pouvez lire un fichier CSV à partir du bucket Amazon S3 dans un DataFrame Spark. Vous devriez avoir configuré vos informations d’identification AWS et disposer de droits d’écriture pour accéder au bucket S3.
Indiquez le bucket S3 et le chemin où vous souhaitez enregistrer les données. Par exemple, vous pouvez utiliser la méthode df.write.format("s3").save("s3://my-bucket/path/to/data") pour enregistrer les données dans le bucket S3 spécifié.
Une fois les données enregistrées dans le bucket S3, vous pouvez les accéder à partir d’autres applications Spark ou outils, ou les télécharger pour une analyse ou un traitement ultérieurs. Pour télécharger le bucket, créez un dossier et choisissez le bucket que vous avez initialement créé. Sélectionnez le bouton Actions, puis cliquez sur « Créer un dossier » dans les éléments déroulants. Vous pouvez maintenant nommer le nouveau dossier.
Pour télécharger les fichiers de données dans le compartiment, sélectionnez le nom du dossier de données.
Dans le Téléchargement – Sélectionnez « Assistant des fichiers » et choisissez Ajouter des fichiers.
Procédez selon les instructions de la console Amazon S3 pour télécharger les fichiers et sélectionnez « Démarrer le téléchargement ».
Il est important de considérer et de s’assurer des meilleures pratiques pour sécuriser vos données avant de les télécharger dans le compartiment S3.
Comprendre les Formats et Schémas de Données
Les formats et schémas de données sont deux concepts liés mais complètement différents et importants en gestion des données. Le format de données fait référence à l’organisation et à la structure des données dans la base de données. Il existe divers formats pour stocker des données, c’est-à-dire CSV, JSON, XML, YAML, etc. Ces formats définissent comment les données doivent être structurées avec les différents types de données et les applications applicables. En même temps, les schémas de données sont la structure de la base de données elle-même. Il définit la mise en page de la base de données et s’assure que les données sont stockées correctement. Un schéma de base de données spécifie les vues, les tables, les index, les types et d’autres éléments. Ces concepts sont importants en analyse et en visualisation de la base de données.
Nettoyage et Prétraitement des Données dans S3
Il est essentiel de vérifier deux fois les erreurs dans vos données avant de les traiter. Pour commencer, accédez au dossier de données dans lequel vous avez enregistré le fichier de données dans votre compartiment S3 et téléchargez-le sur votre machine locale. Ensuite, vous allez charger les données dans l’outil de traitement des données, qui sera utilisé pour nettoyer et prétraiter les données. Pour ce tutoriel, l’outil de prétraitement utilisé est Amazon Athena qui aide à analyser des données structurées et non structurées stockées dans Amazon S3
Allez dans Amazon Athena dans le Console AWS.
Cliquez sur « Créer » pour créer une nouvelle table, puis sur « CRÉER UNE TABLE ».
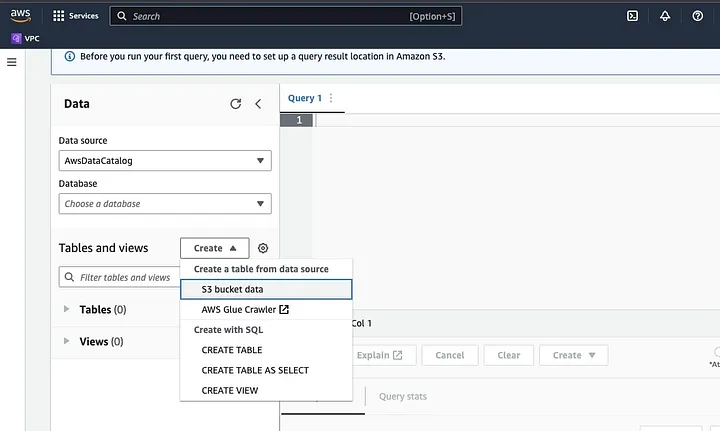
Tapez le chemin de votre fichier de données dans la partie mise en évidence en tant que LOCALISATION.
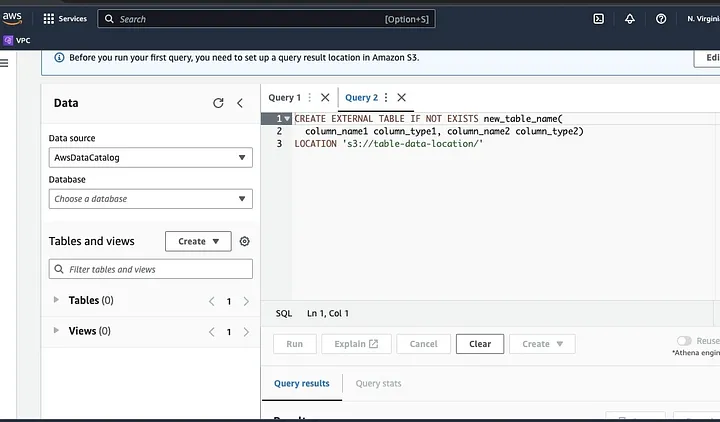
Suivez les invites pour définir le schéma des données et enregistrer la table. Vous pouvez maintenant exécuter une requête pour vérifier que les données sont chargées correctement, puis nettoyer et prétraiter les données
Un exemple:
Cette requête identifie les doublons présents dans les données.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Cet exemple crée une nouvelle table sans les doublons:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Enfin, exportez les données nettoyées vers S3 en vous rendant dans le bucket S3 et le dossier pour télécharger le fichier.
Comprendre le Framework Spark
Le framework Spark est un système de calcul de cluster open source, simple et expressif qui a été créé pour un développement rapide. Il est basé sur le langage de programmation Java et sert d’alternative à d’autres frameworks Java. La caractéristique principale de Spark est ses capacités de calcul de données en mémoire qui accélèrent le traitement de larges ensembles de données.
Configurer Spark pour fonctionner avec S3
Pour configurer Spark pour fonctionner avec S3, commencez par ajouter la dépendance Hadoop AWS à votre application Spark. Faites cela en ajoutant la ligne suivante à votre fichier de construction (par exemple, build.sbt pour Scala ou pom.xml pour Java) :
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Saisez la clé d’accès AWS et le secret clé d’accès dans votre application Spark en définissant les propriétés de configuration suivantes :
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Définissez les propriétés suivantes en utilisant l’objet SparkConf dans votre code :
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Définissez l’URL du point de terminaison S3 dans votre application Spark en définissant la propriété de configuration suivante :
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comRemplacez <REGION> par la région AWS où se trouve votre bucket S3 (par exemple, us-east-1).
Un nom de bucket compatible DNS est requis pour accorder au client S3 dans Hadoop l’accès aux requêtes S3. Si le nom de votre bucket contient des points ou des traits d’union, vous devrez peut-être activer l’accès en style de chemin pour le client S3 dans Hadoop, qui utilise un style de nom de domaine virtuel. Définissez la propriété de configuration suivante pour activer l’accès en style de chemin :
spark.hadoop.fs.s3a.path.style.access trueEnfin, créez une session Spark avec la configuration S3 en définissant le préfixe spark.hadoop dans la configuration Spark :
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()Remplacez les champs de <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY>, et <REGION> par vos identifiants AWS et la région S3.
Pour lire les données depuis S3 dans Spark, la méthode spark.read sera utilisée, puis spécifiez le chemin S3 vers vos données en tant que source d’entrée.
Un exemple de code montrant comment lire un fichier CSV depuis S3 dans un DataFrame dans Spark :
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")Dans cet exemple, remplacez <BUCKET_NAME> par le nom de votre bucket S3 et <FILE_PATH> par le chemin vers votre fichier CSV dans le bucket.
Transformer les données avec Spark
Transformer des données avec Spark fait généralement référence aux opérations sur les données pour nettoyer, filtrer, agréger et joindre les données. Spark met à disposition un ensemble riche d’API pour la transformation des données. Elles incluent les API DataFrame, Dataset et RDD. Certaines des opérations de transformation de données courantes dans Spark incluent le filtrage, la sélection de colonnes, l’agrégation des données, la jointure des données et le tri des données.
Voici un exemple d’opérations de transformation des données:
Trier les données : Cette opération consiste à trier les données en fonction d’une ou de plusieurs colonnes. La méthode orderBy ou sort sur un DataFrame ou un Dataset est utilisée pour trier les données en fonction d’une ou de plusieurs colonnes. Par exemple:
val sortedData = df.orderBy(col("age").desc)Enfin, vous devrez peut-être écrire le résultat de retour sur S3 pour stocker les résultats.
Spark fournit diverses API pour écrire des données sur S3, telles que DataFrameWriter, DatasetWriter et RDD.saveAsTextFile.
Voici un exemple de code montrant comment écrire un DataFrame sur S3 au format Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Remplacez le champ d’entrée du <BUCKET_NAME> par le nom de votre bucket S3 et <OUTPUT_DIRECTORY> par le chemin vers le répertoire de sortie dans le bucket.
La méthode mode spécifie le mode d’écriture, qui peut être Overwrite, Append, Ignore ou ErrorIfExists. La méthode option peut être utilisée pour spécifier diverses options pour le format de sortie, telles que le codec de compression.
Vous pouvez également écrire des données sur S3 dans d’autres formats, tels que CSV, JSON et Avro, en changeant le format de sortie et en spécifiant les options appropriées.
Comprendre la Partition des Données dans Spark
En termes simples, la partition des données dans Spark consiste à diviser le jeu de données en portions plus petites et plus gérables à travers le cluster. L’objectif est d’optimiser les performances, réduire la scalabilité et finalement améliorer la gestion de la base de données. Dans Spark, les données sont traitées en parallèle sur plusieurs clusters. Ceci est rendu possible grâce aux Resilient Distributed Datasets (RDD), qui sont une collection de données massives et complexes. Par défaut, les RDD sont partitionnés sur différents nœuds en raison de leur taille.
Pour fonctionner de manière optimale, il existe des moyens de configurer Spark pour s’assurer que les tâches sont exécutées rapidement et que les ressources sont gérées efficacement. Certains de ceux-ci incluent le cache, la gestion de la mémoire, la sérialisation des données et l’utilisation de mapPartitions() au-dessus de map().
L’interface utilisateur Spark (Spark UI) est une interface graphique basée sur le web qui fournit des informations détaillées sur les performances et l’utilisation des ressources d’une application Spark. Elle comprend plusieurs pages, telles que Vue d’ensemble, Exécuteurs, Étapes et Tâches, qui fournissent des informations sur divers aspects d’une tâche Spark. Spark UI est un outil essentiel pour surveiller et déboguer les applications Spark, car il aide à identifier les goulots d’étranglement des performances et les contraintes des ressources et à résoudre les erreurs. En examinant des métriques telles que le nombre de tâches terminées, la durée de la tâche, l’utilisation du CPU et de la mémoire, et les données de shuffle écrites et lues, les utilisateurs peuvent optimiser leurs tâches Spark et s’assurer qu’elles s’exécutent efficacement.
Conclusion
En résumé, traiter vos données sur AWS S3 à l’aide d’Apache Spark est une manière efficace et évolutive d’analyser de très gros ensembles de données. En utilisant les ressources de stockage et de calcul basées sur le cloud de AWS S3 et d’Apache Spark, les utilisateurs peuvent traiter leurs données rapidement et efficacement sans avoir à s’inquiéter de la gestion de l’architecture.
Dans ce tutoriel, nous avons passé en revue la configuration d’un bucket S3 et d’un cluster Apache Spark sur AWS EMR, la configuration de Spark pour fonctionner avec AWS S3, et l’écriture et l’exécution d’applications Spark pour traiter les données. Nous avons également abordé la partitionnement des données dans Spark, l’interface utilisateur Spark et l’optimisation des performances dans Spark.
Référence
Pour plus de profondeur sur la configuration de spark pour des performances optimales, regardez ici.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark