













Introduction
Le modèle de données relationnel, qui organise les données sous forme de tables de lignes et de colonnes, prédomine dans les outils de gestion de base de données. Aujourd’hui, il existe d’autres modèles de données, notamment NoSQL et NewSQL, mais les systèmes de gestion de base de données relationnelles (SGBDR) restent dominants pour le stockage et la gestion des données à l’échelle mondiale.
Cet article compare et met en contraste trois des SGBDR open-source les plus largement implémentés : SQLite, MySQL, et PostgreSQL. Plus précisément, il explorera les types de données utilisés par chaque SGBDR, leurs avantages et inconvénients, ainsi que les situations où ils sont le mieux optimisés.
A Bit About Database Management Systems
Les bases de données sont des regroupements logiquement modélisés d’informations, ou données. Un système de gestion de base de données (SGBD), quant à lui, est un programme informatique qui interagit avec une base de données. Un SGBD vous permet de contrôler l’accès à une base de données, d’écrire des données, d’exécuter des requêtes et d’effectuer toutes autres tâches liées à la gestion de base de données.
Bien que les systèmes de gestion de bases de données soient souvent désignés sous le nom de « bases de données », les deux termes ne sont pas interchangeables. Une base de données peut être n’importe quelle collection de données, pas seulement celles stockées sur un ordinateur. En revanche, un SGBD fait spécifiquement référence au logiciel qui vous permet d’interagir avec une base de données.
Tous les systèmes de gestion de bases de données ont un modèle sous-jacent qui structure la manière dont les données sont stockées et accessibles. Un système de gestion de base de données relationnelle est un SGBD qui utilise le modèle de données relationnelles. Dans ce modèle relationnel, les données sont organisées en tables. Les tables, dans le contexte des SGBDR, sont plus formellement désignées sous le nom de relations. Une relation est un ensemble de tuples, qui sont les lignes dans une table, et chaque tuple partage un ensemble d’attributs, qui sont les colonnes dans une table :
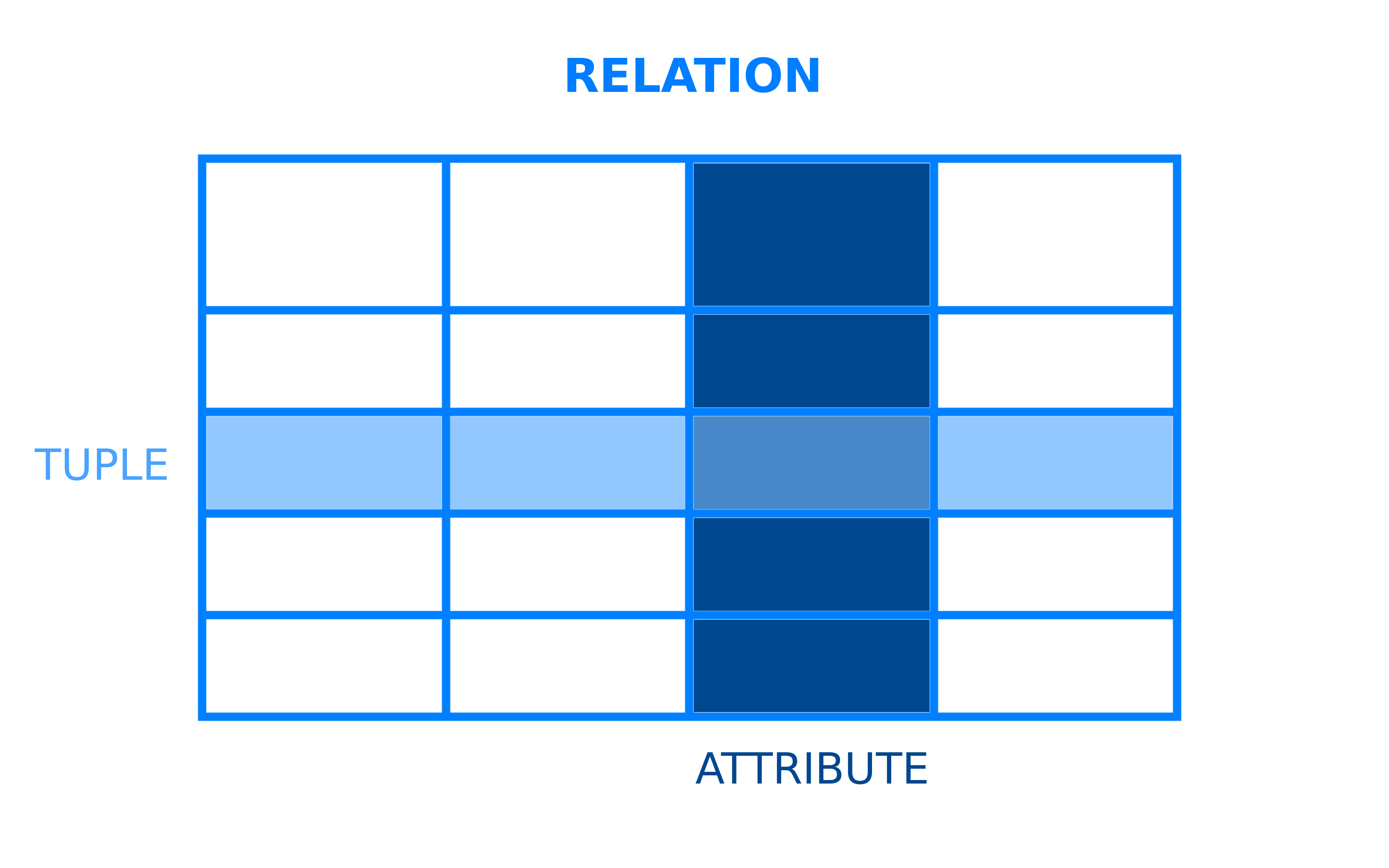
La plupart des bases de données relationnelles utilisent le langage de requête structuré (SQL) pour gérer et interroger les données. Cependant, de nombreux SGBDR utilisent leur propre dialecte particulier de SQL, qui peut avoir certaines limitations ou extensions. Ces extensions comprennent généralement des fonctionnalités supplémentaires qui permettent aux utilisateurs d’effectuer des opérations plus complexes qu’ils ne pourraient le faire avec SQL standard.
Remarque : Le terme « SQL standard » est mentionné à plusieurs reprises dans ce guide. Les normes SQL sont gérées conjointement par l’ Institut national américain des normes (ANSI), l’ Organisation internationale de normalisation (ISO) et la Commission électrotechnique internationale (IEC). Chaque fois que cet article mentionne « SQL standard » ou « la norme SQL », il fait référence à la version actuelle de la norme SQL publiée par ces organismes.
Il convient de noter que la norme SQL complète est vaste et complexe : la conformité complète au noyau SQL:2011 nécessite 179 fonctionnalités. En raison de cela, la plupart des SGBDR ne prennent pas en charge l’ensemble de la norme, bien que certains se rapprochent plus de la conformité complète que d’autres.
Types de données et contraintes
Chaque colonne se voit attribuer un type de données qui dicte quel type d’entrées est autorisé dans cette colonne. Différents SGBDR implémentent différents types de données, qui ne sont pas toujours directement interchangeables. Certains types de données courants incluent les dates, les chaînes de caractères, les entiers et les booléens.
Stocker des entiers dans une base de données est plus nuancé que de mettre des nombres dans une table. Les types de données numériques peuvent être signés, ce qui signifie qu’ils peuvent représenter à la fois des nombres positifs et négatifs, ou non signés, ce qui signifie qu’ils ne peuvent représenter que des nombres positifs. Par exemple, le type de données tinyint de MySQL peut contenir 8 bits de données, ce qui équivaut à 256 valeurs possibles. La plage signée de ce type de données va de -128 à 127, tandis que la plage non signée va de 0 à 255.
Pouvoir contrôler les données autorisées dans une base de données est important. Parfois, un administrateur de base de données imposera une contrainte sur une table pour limiter les valeurs pouvant y être saisies. Une contrainte s’applique généralement à une colonne particulière, mais certaines contraintes peuvent également s’appliquer à une table entière. Voici quelques contraintes couramment utilisées en SQL :
UNIQUE: Appliquer cette contrainte à une colonne garantit que deux entrées dans cette colonne ne sont pas identiques.NOT NULL: Cette contrainte garantit qu’une colonne n’a pas d’entréesNULL.PRIMARY KEY: Une combinaison deUNIQUEet deNOT NULL, la contraintePRIMARY KEYgarantit qu’aucune entrée dans la colonne n’estNULLet que chaque entrée est distincte.FOREIGN KEY: UneFOREIGN KEYest une colonne dans une table qui fait référence à laPRIMARY KEYd’une autre table. Cette contrainte est utilisée pour lier deux tables entre elles. Les entrées dans la colonneFOREIGN KEYdoivent déjà exister dans la colonnePRIMARY KEYparente pour que le processus d’écriture réussisse.CHECK: Cette contrainte limite la plage de valeurs pouvant être entrées dans une colonne. Par exemple, si votre application est destinée uniquement aux résidents de l’Alaska, vous pourriez ajouter une contrainteCHECKsur une colonne de code ZIP pour n’autoriser que des entrées entre 99501 et 99950.
Si vous souhaitez en savoir plus sur les systèmes de gestion de bases de données, consultez notre article sur Une Comparaison des Systèmes et Modèles de Gestion de Bases de Données NoSQL.
Maintenant que nous avons abordé les systèmes de gestion de bases de données relationnelles de manière générale, passons au premier des trois bases de données relationnelles open source que cet article couvrira : SQLite.
SQLite
SQLite est un SGBDR autonome, basé sur des fichiers et entièrement open source, connu pour sa portabilité, sa fiabilité et ses performances élevées même dans des environnements à faible mémoire. Ses transactions sont conformes à ACID, même dans les cas où le système plante ou subit une panne de courant.
Le site web du projet SQLite le décrit comme une base de données « sans serveur ». La plupart des moteurs de base de données relationnelles sont implémentés sous forme de processus serveur dans lesquels les programmes communiquent avec le serveur hôte via une communication interprocessus qui relaie les requêtes. En revanche, SQLite permet à n’importe quel processus accédant à la base de données de lire et d’écrire directement sur le fichier disque de la base de données. Cela simplifie le processus d’installation de SQLite, car il élimine tout besoin de configurer un processus serveur. De même, aucun paramétrage n’est nécessaire pour les programmes qui utiliseront la base de données SQLite : ils ont seulement besoin d’accéder au disque.
SQLite est un logiciel gratuit et open source, et aucune licence spéciale n’est requise pour l’utiliser. Cependant, le projet propose plusieurs extensions — chacune moyennant des frais uniques — qui aident à la compression et au chiffrement. De plus, le projet propose divers packages de support commercial, chacun moyennant des frais annuels.
Types de données pris en charge par SQLite
SQLite permet une variété de types de données, organisés dans les classes de stockage suivantes :
| Data Type | Explanation |
|---|---|
null |
Includes any NULL values. |
integer |
Signed integers, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. |
real |
Real numbers, or floating point values, stored as 8-byte floating point numbers. |
text |
Text strings stored using the database encoding, which can either be UTF-8, UTF-16BE or UTF-16LE. |
blob |
Any blob of data, with every blob stored exactly as it was input. |
Dans le contexte de SQLite, les termes « classe de stockage » et « type de données » sont considérés comme interchangeables. Si vous souhaitez en savoir plus sur les types de données de SQLite et l’affinité des types de SQLite, consultez la documentation officielle de SQLite sur le sujet.
Avantages de SQLite
- Encombrement réduit : Comme son nom l’indique, la bibliothèque SQLite est très légère. Bien que l’espace qu’elle utilise varie en fonction du système où elle est installée, elle peut occuper moins de 600 Ko d’espace. De plus, elle est entièrement autonome, ce qui signifie qu’il n’y a aucune dépendance externe à installer sur votre système pour que SQLite fonctionne.
- Convivial: SQLite est parfois décrit comme une base de données « zéro configuration » prête à l’emploi dès la sortie de la boîte. SQLite ne s’exécute pas en tant que processus serveur, ce qui signifie qu’il n’a jamais besoin d’être arrêté, démarré ou redémarré et ne comporte aucun fichier de configuration à gérer. Ces fonctionnalités contribuent à simplifier le chemin de l’installation de SQLite à son intégration dans une application.
- Portable: Contrairement à d’autres systèmes de gestion de bases de données, qui stockent généralement les données sous forme d’un gros lot de fichiers séparés, une base de données SQLite entière est stockée dans un seul fichier. Ce fichier peut être situé n’importe où dans une hiérarchie de répertoires et peut être partagé via des supports amovibles ou un protocole de transfert de fichiers.
Inconvénients de SQLite
- Concurrence limitée: Bien que plusieurs processus puissent accéder et interroger une base de données SQLite en même temps, seul un processus peut apporter des modifications à la base de données à un moment donné. Cela signifie que bien que SQLite prenne en charge une plus grande concurrence que la plupart des autres systèmes de gestion de bases de données intégrés, il ne peut pas en prendre autant que les SGBDR client/serveur tels que MySQL ou PostgreSQL.
- Aucune gestion des utilisateurs: Les systèmes de bases de données sont souvent accompagnés d’une prise en charge des utilisateurs, ou de connexions gérées avec des privilèges d’accès prédéfinis à la base de données et aux tables. Comme SQLite lit et écrit directement dans un fichier de disque ordinaire, les seules autorisations d’accès applicables sont les autorisations d’accès typiques du système d’exploitation sous-jacent. Cela fait de SQLite un choix peu judicieux pour les applications nécessitant plusieurs utilisateurs avec des autorisations d’accès spéciales.
- Sécurité: Un moteur de base de données utilisant un serveur peut, dans certains cas, offrir une meilleure protection contre les bogues de l’application cliente qu’une base de données sans serveur comme SQLite. Par exemple, les pointeurs égarés dans un client ne peuvent pas corrompre la mémoire sur le serveur. De plus, comme un serveur est un processus persistant unique, une base de données client-serveur peut contrôler l’accès aux données avec plus de précision qu’une base de données sans serveur. Cela permet un verrouillage plus fin et une meilleure concurrence.
Quand utiliser SQLite
- Applications embarquées: SQLite est un excellent choix de base de données pour les applications qui nécessitent la portabilité et qui ne nécessitent pas d’extension future. Les exemples incluent les applications locales monoposte, les applications mobiles ou les jeux.
- Remplacement de l’accès au disque: Dans les cas où une application doit lire et écrire des fichiers directement sur le disque, il peut être bénéfique d’utiliser SQLite pour les fonctionnalités supplémentaires et la simplicité que procure l’utilisation de SQL.
- Test: Pour de nombreuses applications, il peut être excessif de tester leur fonctionnalité avec un SGBD qui utilise un processus serveur supplémentaire. SQLite dispose d’un mode mémoire qui peut être utilisé pour exécuter rapidement des tests sans les surcharges des opérations de base de données réelles, en faisant un choix idéal pour les tests.
Quand ne pas utiliser SQLite
- Travailler avec beaucoup de données: SQLite peut techniquement prendre en charge une base de données allant jusqu’à 140 téraoctets, tant que le lecteur de disque et le système de fichiers prennent également en charge les exigences de taille de la base de données. Cependant, le site web de SQLite recommande que toute base de données approchant 1 téraoctet soit hébergée sur une base de données client-serveur centralisée, car une base de données SQLite de cette taille ou plus serait difficile à gérer.
- Volumes élevés d’écriture: SQLite ne permet qu’une seule opération d’écriture à avoir lieu à un moment donné, ce qui limite considérablement son débit. Si votre application nécessite de nombreuses opérations d’écriture ou plusieurs rédacteurs concurrents, SQLite peut ne pas être adéquat pour vos besoins.
- L’accès réseau est requis: Comme SQLite est une base de données sans serveur, elle ne fournit pas un accès réseau direct à ses données. Cet accès est intégré à l’application. Si les données de SQLite sont situées sur une machine distincte de l’application, cela nécessitera un lien moteur-disque à large bande passante à travers le réseau. Il s’agit d’une solution coûteuse et inefficace, et dans de tels cas, un SGBD client-serveur peut être un meilleur choix.
MySQL
Selon le classement DB-Engines, MySQL est le SGBD relationnel open source le plus populaire depuis que le site a commencé à suivre la popularité des bases de données en 2012. C’est un produit riche en fonctionnalités qui alimente de nombreux sites Web et applications parmi les plus grands du monde, notamment Twitter, Facebook, Netflix et Spotify. Se lancer avec MySQL est relativement simple, en grande partie grâce à sa documentation exhaustive et à sa grande communauté de développeurs, ainsi qu’à l’abondance de ressources liées à MySQL en ligne.
MySQL a été conçu pour la vitesse et la fiabilité, au détriment d’une adhérence complète au standard SQL. Les développeurs de MySQL travaillent continuellement à une adhérence plus étroite au standard SQL, mais il reste en retard par rapport à d’autres implémentations SQL. Cependant, il est livré avec différents modes SQL et extensions qui le rapprochent de la conformité.
Contrairement aux applications utilisant SQLite, les applications utilisant une base de données MySQL y accèdent via un processus daemon séparé. Comme le processus serveur se situe entre la base de données et les autres applications, cela permet un plus grand contrôle sur qui a accès à la base de données.
MySQL a inspiré une multitude d’applications tierces, d’outils et de bibliothèques intégrées qui étendent sa fonctionnalité et facilitent son utilisation. Certains des outils tiers les plus largement utilisés sont phpMyAdmin, DBeaver, et HeidiSQL.
Types de données pris en charge par MySQL
Les types de données de MySQL peuvent être organisés en trois grandes catégories : types numériques, types de date et d’heure, et types de chaîne de caractères.
Types numériques:
| Data Type | Explanation |
|---|---|
tinyint |
A very small integer. The signed range for this numeric data type is -128 to 127, while the unsigned range is 0 to 255. |
smallint |
A small integer. The signed range for this numeric type is -32768 to 32767, while the unsigned range is 0 to 65535. |
mediumint |
A medium-sized integer. The signed range for this numeric data type is -8388608 to 8388607, while the unsigned range is 0 to 16777215. |
int or integer |
A normal-sized integer. The signed range for this numeric data type is -2147483648 to 2147483647, while the unsigned range is 0 to 4294967295. |
bigint |
A large integer. The signed range for this numeric data type is -9223372036854775808 to 9223372036854775807, while the unsigned range is 0 to 18446744073709551615. |
float |
A small (single-precision) floating-point number. |
double, double precision, or real |
A normal sized (double-precision) floating-point number. |
dec, decimal, fixed, or numeric |
A packed fixed-point number. The display length of entries for this data type is defined when the column is created, and every entry adheres to that length. |
bool or boolean |
A Boolean is a data type that only has two possible values, usually either true or false. |
bit |
A bit value type for which you can specify the number of bits per value, from 1 to 64. |
Types de date et d’heure:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
Types de chaîne de caractères:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; entries of this type are padded on the right with spaces to meet the specified length when stored. |
varchar |
A string of variable length. |
binary |
Similar to the char type, but a binary byte string of a specified length rather than a nonbinary character string. |
varbinary |
Similar to the varchar type, but a binary byte string of a variable length rather than a nonbinary character string. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
An enumeration, which is a string object that takes a single value from a list of values that are declared when the table is created. |
set |
Similar to an enumeration, a string object that can have zero or more values, each of which must be chosen from a list of allowed values that are specified when the table is created. |
Avantages de MySQL
- Popularité et facilité d’utilisation: En tant que l’un des systèmes de base de données les plus populaires au monde, il ne manque pas d’administrateurs de base de données ayant de l’expérience avec MySQL. De même, il existe une abondance de documentation imprimée et en ligne sur la manière d’installer et de gérer une base de données MySQL. Cela comprend un certain nombre d’outils tiers – tels que phpMyAdmin – qui visent à simplifier le processus de démarrage avec la base de données.
- Sécurité: MySQL est livré avec un script qui vous aide à améliorer la sécurité de votre base de données en définissant le niveau de sécurité du mot de passe de l’installation, en définissant un mot de passe pour l’utilisateur root, en supprimant les comptes anonymes et en supprimant les bases de données de test qui sont, par défaut, accessibles à tous les utilisateurs. De plus, contrairement à SQLite, MySQL prend en charge la gestion des utilisateurs et vous permet d’accorder des privilèges d’accès utilisateur par utilisateur.
- Vitesse: En choisissant de ne pas implémenter certaines fonctionnalités de SQL, les développeurs de MySQL ont pu prioriser la vitesse. Bien que des tests de référence plus récents montrent que d’autres SGBDR comme PostgreSQL peuvent égaler ou du moins se rapprocher de MySQL en termes de vitesse, MySQL conserve toujours sa réputation de solution de base de données extrêmement rapide.
- Réplication: MySQL prend en charge plusieurs types différents de réplication, qui consiste à partager des informations entre deux hôtes ou plus afin d’améliorer la fiabilité, la disponibilité et la tolérance aux pannes. Cela est utile pour mettre en place une solution de sauvegarde de base de données ou pour mettre à l’échelle horizontalement une base de données.
Inconvénients de MySQL
- Limitations connues: Étant donné que MySQL a été conçu pour la rapidité et la facilité d’utilisation plutôt que pour une conformité SQL complète, il présente certaines limitations fonctionnelles. Par exemple, il ne prend pas en charge les clauses
FULL JOIN. - License et fonctionnalités propriétaires: MySQL est un logiciel à double licence, avec une édition communautaire gratuite et open source sous licence GPLv2 et plusieurs éditions commerciales payantes publiées sous des licences propriétaires. En conséquence, certaines fonctionnalités et plugins ne sont disponibles que pour les éditions propriétaires.
- Développement ralenti: Depuis l’acquisition du projet MySQL par Sun Microsystems en 2008, puis par Oracle Corporation en 2009, les utilisateurs se plaignent que le processus de développement du SGBD a considérablement ralenti, car la communauté n’a plus la possibilité de réagir rapidement aux problèmes et de mettre en œuvre des changements.
Quand utiliser MySQL
- Opérations distribuées: Le support de réplication de MySQL en fait un excellent choix pour les configurations de base de données distribuées telles que les architectures primaire-secondaire ou primaire-primaire.
- Sites web et applications web: MySQL alimente de nombreux sites web et applications à travers Internet. Cela est en grande partie dû à la facilité d’installation et de configuration d’une base de données MySQL, ainsi qu’à sa vitesse globale et à sa scalabilité à long terme.
- Croissance future attendue: Le support de réplication de MySQL peut faciliter la mise à l’échelle horizontale. De plus, il est relativement simple de passer à un produit MySQL commercial, comme MySQL Cluster, qui prend en charge le sharding automatique, un autre processus de mise à l’échelle horizontale.
Quand ne pas utiliser MySQL
- Conformité SQL est nécessaire : Comme MySQL n’essaie pas de mettre en œuvre la norme SQL complète, cet outil n’est pas entièrement conforme à SQL. Si la conformité SQL complète, voire presque complète, est indispensable pour votre cas d’utilisation, vous voudrez peut-être utiliser un SGBDR plus conforme.
- Concurrency et grands volumes de données : Bien que MySQL fonctionne généralement bien avec des opérations de lecture intensives, les lectures-écritures concurrentes peuvent poser problème. Si votre application aura de nombreux utilisateurs écrivant des données en même temps, un autre SGBDR comme PostgreSQL pourrait être un meilleur choix de base de données.
PostgreSQL
PostgreSQL, également connu sous le nom de Postgres, se présente comme « la base de données relationnelle open-source la plus avancée au monde ». Il a été créé dans le but d’être très extensible et conforme aux normes. PostgreSQL est une base de données objet-relationnelle, ce qui signifie que bien qu’il soit principalement une base de données relationnelle, il inclut également des fonctionnalités – comme l’héritage de table et la surcharge de fonctions – qui sont plus souvent associées aux bases de données objet.
Postgres est capable de gérer efficacement plusieurs tâches en même temps, une caractéristique connue sous le nom de concurrency. Il y parvient sans verrous de lecture grâce à sa mise en œuvre du Contrôle de Concurrency Multiversion (MVCC), qui garantit l’atomicité, la cohérence, l’isolation et la durabilité de ses transactions, également appelée conformité ACID.
PostgreSQL n’est pas aussi largement utilisé que MySQL, mais il existe encore un certain nombre d’outils et de bibliothèques tiers conçus pour simplifier le travail avec PostgreSQL, notamment pgAdmin et Postbird.
Types de données pris en charge par PostgreSQL
PostgreSQL prend en charge des types de données numériques, de chaîne de caractères, de date et d’heure comme MySQL. En outre, il prend en charge les types de données pour les formes géométriques, les adresses réseau, les chaînes de bits, les recherches de texte et les entrées JSON, ainsi que plusieurs types de données idiosyncratiques.
Types numériques:
| Data Type | Explanation |
|---|---|
bigint |
A signed 8 byte integer. |
bigserial |
An auto-incrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
A number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An auto-incrementing 2 byte integer. |
serial |
An auto-incrementing 4 byte integer. |
Types de caractères:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Types de date et d’heure:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Types géométriques:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Types d’adresses réseau:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Types de chaînes de bits:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Types de recherches de texte:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
Types JSON:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Autres types de données:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Avantages de PostgreSQL
- Conformité SQL: Plus que SQLite ou MySQL, PostgreSQL vise à respecter étroitement les normes SQL. D’après la documentation officielle de PostgreSQL, PostgreSQL prend en charge 160 des 179 fonctionnalités requises pour une conformité totale à SQL:2011, en plus d’une longue liste de fonctionnalités optionnelles.
- Ouvert et animé par la communauté: Projet entièrement open source, le code source de PostgreSQL est développé par une communauté nombreuse et dévouée. De même, la communauté Postgres maintient et contribue à de nombreuses ressources en ligne décrivant comment travailler avec le SGBD, y compris la documentation officielle, le wiki PostgreSQL, et divers forums en ligne.
- Extensible: Les utilisateurs peuvent étendre PostgreSQL de manière programmable et à la volée grâce à son fonctionnement piloté par le catalogue et son utilisation du chargement dynamique. On peut désigner un fichier de code objet, tel qu’une bibliothèque partagée, et PostgreSQL le chargera selon les besoins.
Inconvénients de PostgreSQL
- Performance mémoire: Pour chaque nouvelle connexion client, PostgreSQL crée un nouveau processus. Chaque nouveau processus se voit allouer environ 10 Mo de mémoire, ce qui peut rapidement s’accumuler pour les bases de données avec de nombreuses connexions. En conséquence, pour les opérations simples à forte lecture, PostgreSQL est généralement moins performant que d’autres SGBDR, comme MySQL.
- Popularité: Bien qu’il soit plus largement utilisé ces dernières années, PostgreSQL a historiquement été en retard par rapport à MySQL en termes de popularité. Une conséquence de cela est qu’il existe encore moins d’outils tiers pouvant aider à gérer une base de données PostgreSQL. De même, il n’y a pas autant d’administrateurs de bases de données ayant de l’expérience dans la gestion d’une base de données Postgres par rapport à ceux ayant de l’expérience avec MySQL.
Quand utiliser PostgreSQL
- L’intégrité des données est importante: PostgreSQL est pleinement conforme à l’ACID depuis 2001 et implémente un contrôle de concurrence multiversion pour garantir que les données restent cohérentes, ce qui en fait un choix judicieux de SGBDR lorsque l’intégrité des données est critique.
- Intégration avec d’autres outils: PostgreSQL est compatible avec un large éventail de langages de programmation et de plateformes. Cela signifie que si vous devez migrer votre base de données vers un autre système d’exploitation ou l’intégrer à un outil spécifique, cela sera probablement plus facile avec une base de données PostgreSQL qu’avec un autre SGBD.
- Opérations complexes: Postgres prend en charge des plans de requête pouvant exploiter plusieurs processeurs pour répondre aux requêtes plus rapidement. Cela, associé à son fort support pour plusieurs rédacteurs simultanés, en fait un excellent choix pour des opérations complexes telles que l’entreposage de données et le traitement de transactions en ligne.
Quand ne pas utiliser PostgreSQL
- La vitesse est impérative: Au détriment de la vitesse, PostgreSQL a été conçu en pensant à l’extensibilité et à la compatibilité. Si votre projet nécessite les opérations de lecture les plus rapides possibles, PostgreSQL peut ne pas être le meilleur choix de SGBD.
- Configurations simples: En raison de son large éventail de fonctionnalités et de sa forte adhérence à SQL standard, Postgres peut être excessif pour des configurations de base de données simples. Pour des opérations intensives en lecture où la vitesse est nécessaire, MySQL est généralement un choix plus pratique.
- Réplication complexe: Bien que PostgreSQL offre un solide support pour la réplication, c’est encore une fonctionnalité relativement nouvelle. Certaines configurations, comme une architecture primaire-primaire, ne sont possibles qu’avec des extensions. La réplication est une fonctionnalité plus mature sur MySQL et de nombreux utilisateurs estiment que la réplication de MySQL est plus facile à mettre en œuvre, en particulier pour ceux qui manquent d’expérience en administration de bases de données et de systèmes.
Conclusion
Aujourd’hui, SQLite, MySQL et PostgreSQL sont les trois systèmes de gestion de bases de données relationnelles open-source les plus populaires au monde. Chacun a ses propres fonctionnalités et limites uniques, et excelle dans des scénarios particuliers. Il y a plusieurs variables à prendre en compte lors du choix d’un SGBDR, et le choix n’est jamais aussi simple que de choisir le plus rapide ou celui avec le plus de fonctionnalités. La prochaine fois que vous aurez besoin d’une solution de base de données relationnelle, assurez-vous de rechercher en profondeur ces outils et d’autres pour trouver celui qui correspond le mieux à vos besoins.
Si vous souhaitez en savoir plus sur SQL et comment l’utiliser pour gérer une base de données relationnelle, nous vous encourageons à consulter notre Guide de gestion d’une base de données SQL. D’autre part, si vous souhaitez en savoir plus sur les bases de données non relationnelles (ou NoSQL), consultez notre Comparaison des systèmes de gestion de base de données NoSQL.