













La Recuperation Augmentée de Génération (RAG)marque une avancée transformative dans les grands modèles de langue naturelle (LLM). Elle combine la capacité de génération des architectures transformatrices avec une recherche d’information dynamique.
Cette intégration permet aux LLM d’accéder et d’intégrer des connaissances externes pertinentes pendant la génération de textes, ce qui donne des sorties plus exactes, contextuelles et factuellement cohérentes.
La transition de systèmes early basés sur des règles à des modèles neuronaux sophistiqués tels que BERT et GPT-3 a ouvert la voie pour RAG, éliminant les limites de la mémoire paramétrique statique. De plus, l’avènement de la RAG multimodale étend ces capacités en intégrant divers types de données telles que les images, l’audio et la vidéo, ce qui enhance la richesse et la pertinence du contenu généré.
Ce changement de paradigme non seulement améliore l’exactitude et l’interprétabilité des sorties des LLM mais aussi appuie les applications innovantes dans divers domaines.
Ce que nous aborderons ici est le suivant :
- Chapitre 1. Introduction à la RAG
– 1.1 Qu’est-ce que la RAG ? Un Aperçu
– 1.2 comment la RAG résout les problèmes complexes - Chapitre 2. Fondements techniques
– 2.1 Passage de l’LM neurale aux RAG
– 2.2 Comprendre la mémoire des RAG : paramétrique versus non paramétrique
– 2.3 RAG multimodales : intégrer plusieurs types de données - Chapitre 3. Mécanismes centraux
– 3.1 L’avantage de combiner l’information de recherche et la génération dans RAG
– 3.2 Stratégies d’intégration pour les récupérateurs et les générateurs - Chapitre 4. Applications et cas d’utilisation
– 4.1 RAG au travail : de la QA à la rédaction créative
– 4.2 RAG pour les langues à ressources faibles : étendre la portée et les capacités - Chapitre 5. Techniques d’optimisation
– 5.1 Techniques d’extraction avancées pour optimiser les systèmes RAG - Chapitre 6. Défis et innovations
– 6.1 Défis actuels et directions futures pour RAG
– 6.2 Accélération matérielle et déploiement efficient de systèmes RAG - Chapitre 7. Pensées conclusives
– 7.1 L’avenir de RAG : conclusions et réflexions
Pré-requis
Pour interagir avec du contenu axé sur les grands modèles de langue naturelle (LLM) comme le système de génération à l’aide de récupération (RAG), deux pré-requis essentiels sont :
- Fondements de l’apprentissage automatique : Comprendre les concepts de base en apprentissage automatique et les algorithmes est crucial, en particulier dans le contexte des architectures de réseaux de neurones.
- Traitement automatique du langage naturel (TALN) : La connaissance des techniques de TALN, y compris le prétraitement du texte, la tokenization et l’utilisation d’embauches, est essentielle pour travailler avec des modèles de langue.
Chapitre 1 : Introduction à RAG
La génération assistée par recherche (RAG) révolutionne le traitement automatique du langage naturel en combinant la recherche d’information et les modèles génératifs. Les systèmes RAG accèdent dynamiquement à des connaissances externes, améliorant l’exactitude et la pertinence du texte généré.
Ce chapitre examine les mécanismes, les avantages et les défis de RAG. Nous plongeons dans les techniques de recherche, l’intégration avec les modèles génératifs et l’impact sur diverses applications.
RAG atténue les hallucinations, incorpore des informations à jour et aborde les problèmes complexes. Nous discutons également des défis tels que la recherche efficiente et les considérations éthiques. Ce chapitre offre une compréhension complète du potentiel transformateur de RAG dans le traitement automatique du langage naturel.
1.1 Qu’est-ce que RAG ? Une vue d’ensemble
La génération assistée par recherche (RAG) représente un changement de paradigme dans le traitement automatique du langage naturel, en intégrant parfaitement les avantages de la recherche d’information et des modèles langagiers génératifs. Les systèmes RAG exploitent des sources de connaissances externes pour améliorer l’exactitude, la pertinence et la cohérence du texte généré, éliminant les limites de la mémoire paramétrique pure des modèles de langage traditionnels. (Lewis et al., 2020)
En utilisant des informations pertinentes dynamiquement pour les intégrer au cours du processus de génération, RAG permet des sorties plus contextualisées et factuellement cohérentes sur un large éventail d’applications, allant des systèmes de réponse à des questions et des systèmes de dialogue à la résumé et à l’écriture créative. (Petroni et al., 2021)
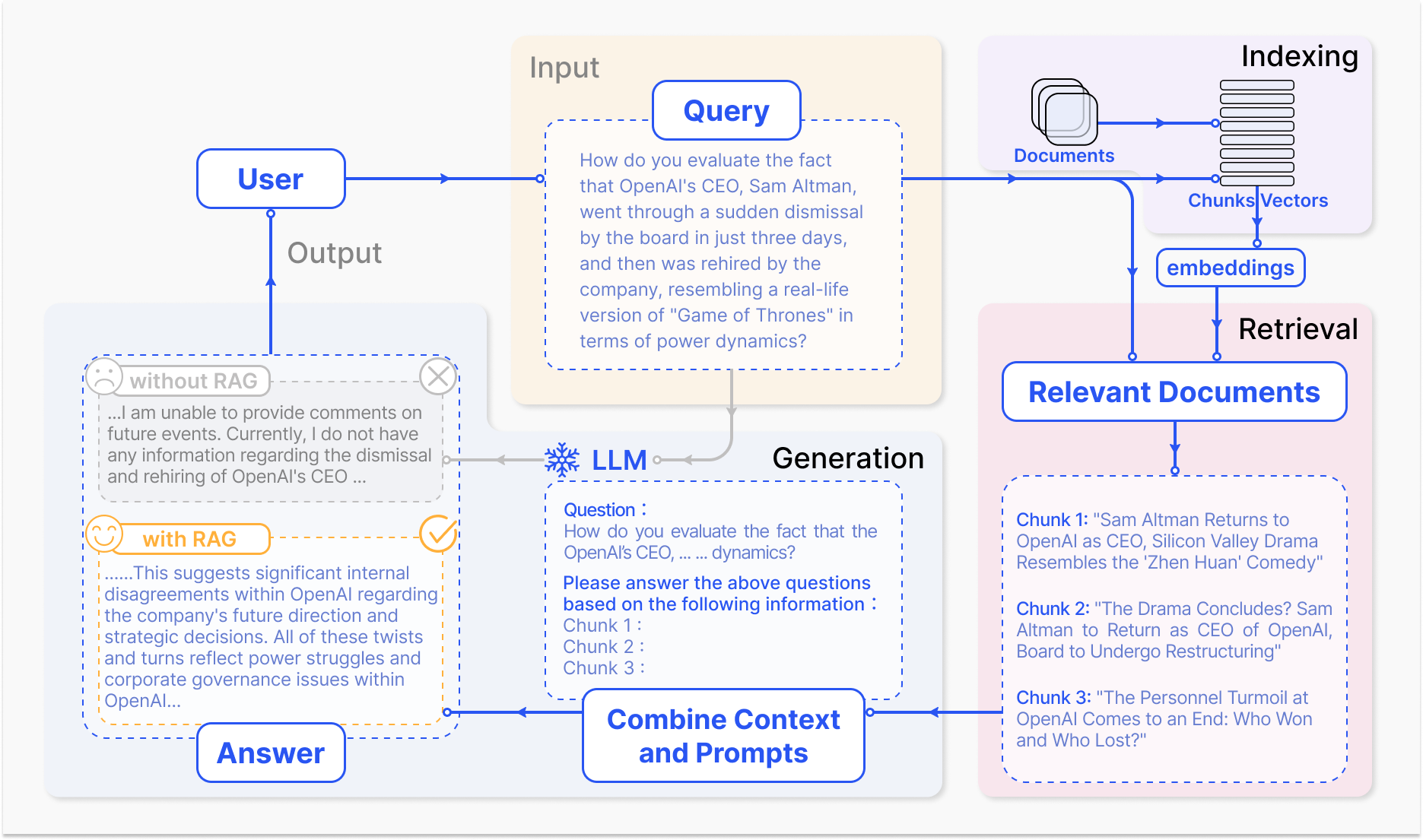
Comment fonctionne un système RAG – arxiv.org
Le mécanisme central de RAG comprend deux composants principaux : le rechercheur et la génération.
Le composant de recherche efficacement traverse de vastes bases de connaissances pour identifier les informations les plus pertinentes en fonction de la requête d’entrée ou du contexte. Des techniques telles que la recherche sparse, qui utilise des index inversés et des correspondances basées sur les mots, et la recherche dense, qui emploie des représentations vectorielles denses et de similarité sémantique, sont employées pour optimiser le processus de recherche. (Karpukhin et al., 2020)
L’information retrouvée est ensuite intégrée au modèle génératif, généralement un grand modèle de langue comme GPT ou T5, qui synthétise le contenu pertinent en une réponse cohérente et fluide. (Izacard & Grave, 2021)
L’intégration de la récupération et de la génération dans RAG offre plusieurs avantages sur les modèles de langue traditionnels. En fixesant le texte généré sur des connaissances externes, RAG réduit significativement la fréquence des hallucinations ou des sorties factuellement incorrectes. (Shuster et al., 2021)
RAG permet également d’intégrer des informations à jour, garantissant que les réponses générées reflètent les dernières connaissances et développements dans un domaine donné. (Lewis et al., 2020) Cette adaptabilité est particulièrement cruciale dans des domaines tels que la santé, les finances et la recherche scientifique, où l’importance de l’information précise et à jour est primordiale. (Petroni et al., 2021)
Cependant, le développement et le déploiement de systèmes RAG posent également d’importantes difficultés. L’extraction efficace de bases de connaissance à grande échelle, la réduction des hallucinations et l’intégration de diverses modalités de données sont parmi les défis techniques qui doivent être réglés. (Izacard & Grave, 2021)
Également, les considérations éthiques, telles que l’assurance d’un accès impartial et équitable aux informations et la génération, sont cruciales pour le déploiement responsable des systèmes RAG. (Bender et al., 2021) L’élaboration de metrics d’évaluation complètes et de cadres qui captent l’interaction entre l’exactitude du rappel et la qualité de la génération est essentielle pour évaluer l’efficacité des systèmes RAG. (Lewis et al., 2020)
Au fil de l’évolution du domaine des RAG, les directions de recherche futures se concentrent sur l’optimisation des processus de rappel, sur l’expansion des capacités multimodales, sur l’élaboration d’architectures modulaires et sur l’établissement de cadres d’évaluation robustes. (Izacard & Grave, 2021) Ces avancées amélioreront l’efficacité, l’exactitude et l’adaptabilité des systèmes RAG, ouvrant la voie vers des applications plus intelligentes et plus polyvalentes en traitement du langage naturel.
Voici un exemple de code Python de base montrant un dispositif de génération assistée par rappel (RAG) en utilisant les bibliothèques populaires LangChain et FAISS :
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Charger et intégrer des documents
loader = TextLoader('your_documents.txt') # Remplacez cette ligne par votre source de document
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Retrouver les documents pertinents
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. Configurer une chaîne RAG
llm = OpenAI(temperature=0.1) # Ajuster la température pour la créativité de la réponse
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. Utiliser le modèle RAG
def get_answer(query):
return chain.run(query)
# Exemple d'utilisation
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
# Exemple d'utilisation Histoire de la société
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
# Exemple d'utilisation Performance financière
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
# Exemple d'utilisation Perspectives d'avenir
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
En exploitant le pouvoir de la récupération et de la génération, RAG promet une immense promesse pour transformer la manière dont nous interagissons avec l’information et laquelle nous générerons, révolutionnant divers domaines et façonnant l’avenir de l’interaction homme-machine.
1.2 comment RAG résout les problèmes complexes
La génération assistée par récupération (RAG) offre une solution puissante aux problèmes complexes que les grands modèles de langue naturelle (LLM) traditionnels peinent à résoudre, en particulier dans les scénarios où il y a de grandes quantités de données non structurées.
Un de ces problèmes est la capacité à engager des conversations significatives sur des documents spécifiques ou des contenus multimédia tels que des vidéos YouTube, sans aucun fine-tuning préalable ou entraînement explicite sur le matériel cible.
Les GLL, malgré leurs impressionnantes capacités génératives, sont limitées par leur mémoire paramétrique, qui est fixée au moment de l’entraînement. (Lewis et al., 2020) Cela signifie qu’elles ne peuvent pas accéder directement ou intégrer de nouvelles informations au-delà de leurs données d’entraînement, ce qui rend difficile de participer à des discussions informées sur des documents ou des vidéos non vus.
Par conséquent, les GLL peuvent générer des réponses inconsistantes, non pertinentes ou erronées factuellement lorsqu’elles sont sollicitées avec des requêtes liées à des contenus spécifiques. (Petroni et al., 2021)
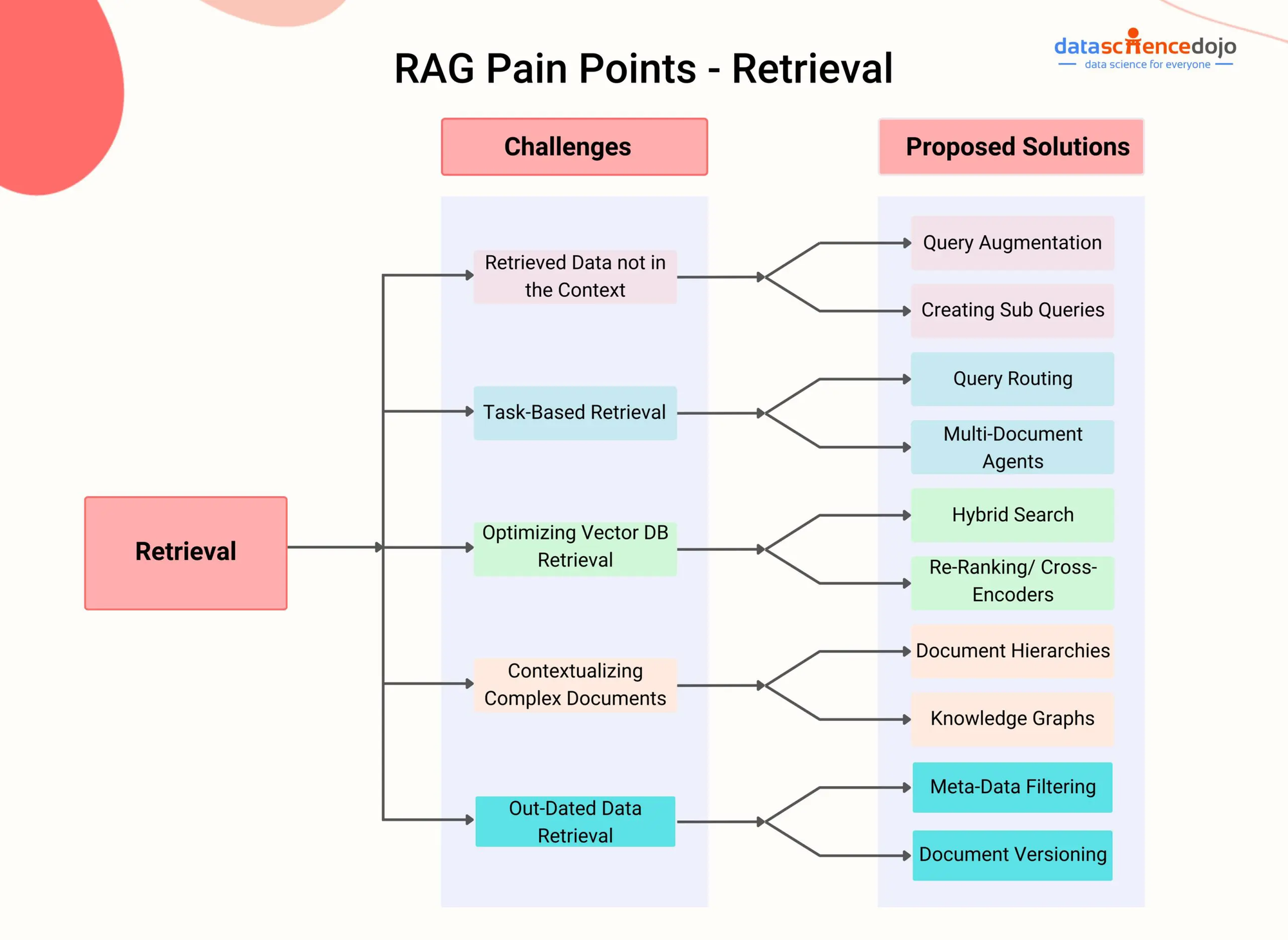
RAG Points d’atteinte – DataScienceDojo
RAG aborde cette limitation en intégrant un composant de récupération qui permet au modèle de dynamiquement accéder et intégrer des informations pertinentes provenant de sources de connaissance externes pendant le processus de génération.
En exploitant des techniques de récupération avancées, telles que la récupération de passages denses (Karpukhin et al., 2020) ou la recherche hybride (Izacard & Grave, 2021), les systèmes RAG peuvent identifier efficacement les passages ou segments les plus pertinents d’un document donné ou d’une vidéo en fonction du contexte conversationnel.
Voici la traduction en français :
Pour commencer, imaginez une situation où un utilisateur souhaite engager une conversation sur une vidéo YouTube spécifique portant sur un sujet scientifique. Un système RAG peut d’abord transcrire le contenu audio de la vidéo puis indexer le texte résultant à l’aide de représentations vectorielles densives.
Ensuite, lorsque l’utilisateur pose une question liée à la vidéo, le composant de recherche du système RAG peut rapidement identifier les passages les plus pertinents de la transcription en fonction de la similarité sémantique entre la requête et le contenu indexé.
Les passages récupérés sont ensuite fournis au modèle générateur, qui synthétise une réponse cohérente et informative qui répond directement à la question de l’utilisateur en se basant sur le contenu de la vidéo. (Shuster et al., 2021)
Cette méthode permet aux systèmes RAG de mener des conversations érudites sur une large gamme de documents et de contenu multimédia sans nécessiter une fine ajustement explicite. En récupérant et en incorporant dynamiquement des informations pertinentes, RAG peut générer des réponses plus précises, contextuellement pertinentes et factuellement cohérentes par rapport aux LLM traditionnelles. (Lewis et al., 2020)
La capacité de RAG à traiter des données non structurées provenant de diverses modalités, telles que le texte, les images et l’audio, le rend une solution polyvalente pour résoudre des problèmes complexes impliquant des sources d’information hétérogènes. (Izacard & Grave, 2021) Avec l’évolution continue des systèmes RAG, leur potentiel pour aborder des problèmes complexes dans des domaines divers est en croissance.
En exploitant des techniques d’indexation avancées et l’intégration multimodale, RAG peut permettre la création d’agents conversationnels plus intelligents et adaptés au contexte, de systèmes de recommandations personnalisés et d’applications axées sur le savoir.
Avec la progression de la recherche dans des domaines tels que l’indexation efficace, l’alignement cross-modal et l’intégration de la récupération et de la génération, RAG jouera sans doute un rôle crucial dans la poussée des frontières de ce qui est possible avec les modèles de langue et l’intelligence artificielle.
Chapitre 2 : Fondements techniques
Ce chapitre plonge dans le monde fascinant de la Recherche-Augmentation Générative Multimodale (RAG), une approche à la pointe qui transcende les limites des modèles traditionnels basés sur le texte.
En intégrant de manière harmonieuse diverses modalités de données telles que les images, l’audio et la vidéo avec les Grands Modèles de Langue (GML), la RAG multimodale donne aux systèmes d’IA la capacité de raisonner sur un paysage informatif plus riche.
Nous explorerons les mécanismes derrière cette intégration, tels que l’apprentissage par contraste et l’attention cross-modal, et comment ils permettent aux GML de générer des réponses plus nuancées et pertinentes dans le contexte.
Bien que les avantages prometteurs de la RAG multimodale, tels que l’amélioration de la précision et le soutien de cas d’utilisation nouveaux tels que la réponse visuelle aux questions, présentent également des défis uniques, y compris la nécessité de jeux de données multimodales à grande échelle, l’complexité calculatoire accrue et le risque de biais dans les informations récupérées.
Comme nous nous lanceons dans cette aventure, nous découvrirons non seulement le potentiel transformatif de la RAG multimodale mais également examiner critiquement les obstacles qui se dressent à notre chemin, ouvrant ainsi la voie vers une meilleure compréhension de ce domaine évoluant rapidement.
2.1 Modèles neuronaux de langue (LM) vers RAG
L’évolution des modèles de langue a été marquée par une progression continue从早期的 systèmes basés sur des règles à des modèles de plus en plus sophistiqués basés sur la statistique et les réseaux de neurones.
Dans les premiers jours, les modèles de langue se firent sur des règles artisanales et des connaissances linguistiques pour générer du texte, ce qui donna des sorties rigides et limitées. L’avènement des modèles statistiques, tels que les modèles d’n-grammes, a introduit une approche basée sur les données qui apprenait des patrons à partir de grands corpus, permettant une génération de langage plus naturelle et cohérente. (Redis)
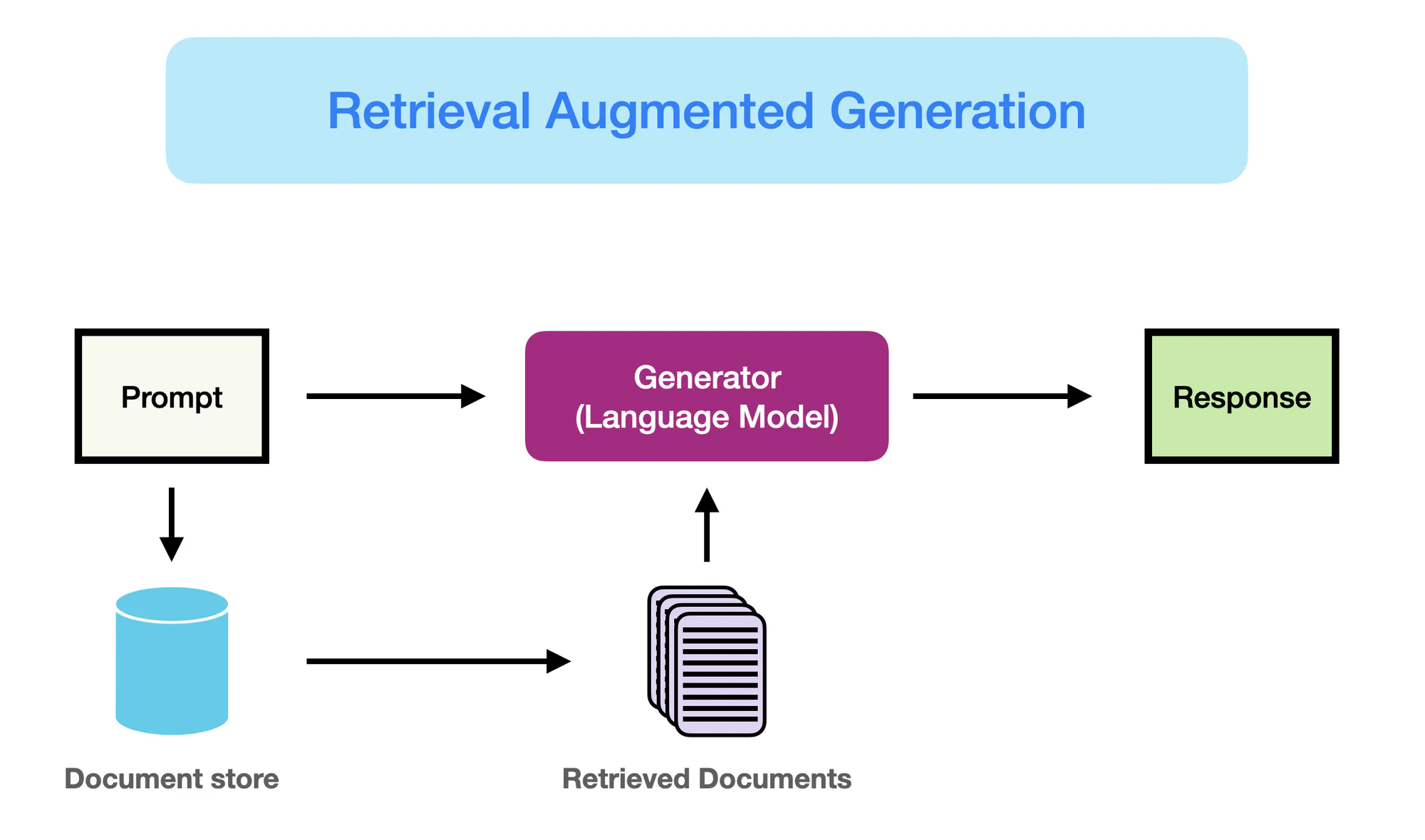
Comment la RAG Fonctionne – promptingguide.ai
Cependant, il fut l’émergence des modèles basés sur le réseau de neurones, en particulier les architectures transformatrices telles que BERT et GPT-3, qui révolutionna le domaine de traitement du langage naturel (TLN).
Ces modèles, connus sous le nom de grands modèles de langue (GML), exploitent les capacités de l’apprentissage profond pour saisir des patrons linguistiques complexes et générer un texte similaire à l’humain avec une fluidité et une cohérence sans précédent. (Yarnit) L’augmentation de la complexité et de l’échelle des GML, avec des modèles tels que GPT-3 revendiquant plus de 175 milliards de paramètres, a permis de développer des capacités remarquables dans des tâches telles que la traduction linguistique, la réponse à des questions et la création de contenu.
Malgré leurs performances impressionnantes, les GML traditionnelles sont limitées par leur dépendance à la mémoire paramétrique pure. (StackOverflow) La connaissance encodée dans ces modèles est statique, limitée par la date de coupure de leur donnée d’entraînement.
Par conséquent, les GML peuvent générer des sorties qui sont factuellement incorrectes ou incompatibles avec les informations les plus récentes. De plus, l’absence d’accès explicite à des sources de connaissance externes limite leur capacité de fournir des réponses précises et pertinentes dans le contexte des requêtes intensives en connaissance.
Le Retrieval Augmented Generation (RAG) apparaît comme une solution innovante qui permet de surmonter ces limitations. En intégrant de manière harmonieuse les capacités d’information de recherche avec la capacité génératrice des GML, RAG permet aux modèles de définir dynamiquement et d’intégrer la connaissance pertinente provenant de sources externes pendant le processus de génération.
Cette fusion de la mémoire paramétrique et non-paramétrique permet aux LLM équipées de RAG de produire des sorties qui sont non seulement fluides et cohérentes, mais également exactes sur le plan des faits et informées contextuellement.
RAG représente une avancée significative dans la génération de langage, en fusionnant les avantages des LLM avec le vaste savoir contenu dans les référentiels externes. En exploitant les meilleurs de chacun des mondes, RAG habilite les modèles à générer du texte plus fiable, informatif et aligné sur le savoir mondial réel.
Ce changement de paradigme ouvre de nouvelles possibilités pour les applications de PNL, de l’interrogation et de la création de contenu aux tâches intensives de connaissances dans des domaines tels que la santé, les finances et la recherche scientifique.
2.2 Mémoire Paramétrique vs Non-Paramétrique
La mémoire paramétrique correspond au savoir stocké dans les paramètres des modèles de langage pré-entraînés, tels que BERT et GPT-4. Ces modèles apprennent à capturer les schémas linguistiques et les relations à partir de vastes quantités de données textuelles pendant l’entraînement, en encodant ce savoir dans leurs millions ou milliards de paramètres.
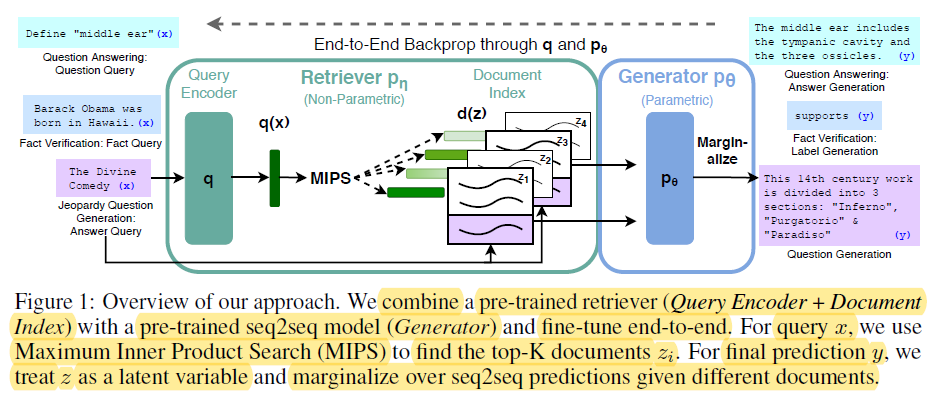
End-t-End Backprop through q and p0 – miro.medium.com
Les avantages de la mémoire paramétrique incluent :
- Fluence : Les modèles de langue pré-entraînés génèrent un texte semblable à l’humain avec une remarquable fluence et cohérence, capturant les nuances et le style naturels de la langue. (Redis et Lewis et al.)
- Généralisation : La connaissance encodée dans les paramètres du modèle permet à celui-ci de généraliser pour de nouvelles tâches et domaines, ce qui permet l’apprentissage de transfert et la capacité d’apprentissage à few-shot. (Redis et Lewis et al.)
Cependant, la mémoire paramétrique a également des limitations significatives :
- Erreurs de fait : Les modèles de langue peuvent générer des sorties qui ne sont pas cohérentes avec les faits du monde réel, car leur connaissance est limitée aux données sur lesquelles ils ont été entraînés.
- Connaissances périmées : La connaissance encodée dans les paramètres du modèle devient périmée au fil du temps, car elle est fixée à l’heure de l’entraînement et n’a pas besoin d’être actualisée pour refléter les mises à jour ou les changements dans le monde réel.
- Coût calculatoire élevé : L’entraînement de grands modèles de langue nécessite une quantité massive de ressources calculatoires et d’énergie, ce qui rend leur actualisation coûteuse et longue.
- Connaissances générales : Les modèles de langue capturent une connaissance large et générale, qui manque la profondeur et la spécificité requise pour de nombreuses applications spécialisées.
En revanche, la mémoire non-paramétrique fait référence à l’utilisation de sources de connaissance explicites, telles que des bases de données, des documents et des graphes de connaissance, pour fournir des informations à jour et précises aux modèles de langue. Ces sources externes constituent une forme complémentaire de mémoire, permettant aux modèles d’accéder et de retrouver l’information pertinente sur demande pendant le processus de génération.
Les avantages de la mémoire non-paramétrique incluent :
- Informations à jour : Les sources de connaissance externes peuvent être facilement mises à jour et maintenues, garantissant que le modèle dispose de l’information la plus récente et la plus précise.
- Réduction des hallucinations : « En retirant des informations pertinentes de sources externes, la RAG réduit significativement la fréquence des hallucinations ou des sorties génératives factuellement incorrectes. » (Lewis et al. et Guu et al.)
- Connaissance spécialisée : La mémoire non paramétrique permet aux modèles de tirer parti du savoir spécialisé provenant de sources spécialisées dans le domaine, ce qui permet d’obtenir des sorties plus précises et pertinentes dans le contexte spécifique d’applications données. (Lewis et al. et Guu et al.)
Les limitations de la mémoire paramétrique soulignent la nécessité d’un changement de paradigme dans la génération de langage.
RAG représente une avancée significative dans le traitement automatique du langage naturel en améliorant les performances des modèles génératifs en intégrant des techniques d’information de recherche. (Redis)
Voici le code Python pour illustrer la distinction entre la mémoire paramétrique et non paramétrique dans le contexte de RAG, avec une sortie clairement mise en avant :
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# Collecte de documents d'exemple (supposons que les documents soient plus importants dans un scénario réel)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. Mémoire non paramétrique (Recherche avec des embeddings)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Mémoire paramétrique (Modèle de langage avec recherche)
llm = OpenAI(temperature=0.1) # Ajustez la température pour la créativité des réponses
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- Requêtes et Réponses ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Sortie :
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
Et c’est ce qui se passe dans ce code :
Mémoire paramétrique :
- Utilise l’énorme connaissance de l’MME pour générer une réponse complète, y compris le fait crucial que le boson de Higgs donne de la masse aux autres particules. L’MME est « paramétrisée » par son approche extensive de données d’entraînement.
Mémoire non paramétrique :
- Effectue une recherche de similarité dans l’espace vectoriel, en trouvant le document le plus pertinent qui répond directement à la question sur l’emplacement du LHC. Il ne synthétise pas de nouvelle information, il ne fait que récupérer le fait pertinent.
Principales différences :
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Stockage des connaissances | Encodé dans les paramètres (poids) du modèle sous forme d’ représentations apprises. | Stocké directement sous forme de texte brut ou d’autres formats (par exemple, les embeddings). |
| Récupération | Utilise la capacité génératrice du modèle pour produire du texte pertinent à la requête en fonction de ses connaissances apprises. | Involue la recherche de documents qui se prêtent fortement à la requête (par exemple, par similarité ou par matching de mots-cles). |
| Flexibilité | Très flexible et capable de générer des réponses novatrices, mais peut également produire des hallucinations (générer des informations incorrectes). | Moins flexible, mais moins susceptible de produire des hallucinations car il repose sur des données existantes. |
| Style de réponse | Peut produire des réponses plus élaborées et plus nuancées, mais potentiellement avec plus d’informations irrelevantes. | Fournit des réponses directes et courtes, mais peut manquer de contexte ou d’élaboration. |
| Coût computationnel | La génération de réponses peut être calculatoirement intensive, en particulier pour de grandes modèles. | La récupération peut être plus rapide, en particulier avec des algorithmes d’indexation et de recherche efficaces. |
En combinant les avantages de la mémoire paramétrique et non-paramétrique, RAG aborde les limitations des modèles de langue traditionnels et permet la génération de sorties plus précises, à jour et contextuellement pertinentes.(Redis, Lewis et al., et Guu et al.)
2.3 RAG multimodal : intégrer le texte
Le RAG multimodal étend le paradigme traditionnel de base sur le texte du RAG en incorporant plusieurs modalités de données, telles que les images, l’audio et la vidéo, pour améliorer les capacités de récupération et de génération des grands modèles de langue (LLMs).
En exploitant des techniques d’apprentissage par contraste, les systèmes RAG multimodaux apprennent à insérer les types de données hétérogènes dans un espace vectoriel partagé, permettant une recherche intermodale fluide. Cela permet aux LLMs de raisonner sur un contexte plus riche, en combinant l’information textuelle avec les indices visuels et auditifs pour générer des sorties plus subtiles et contextuellement pertinentes. (Shen et al.)
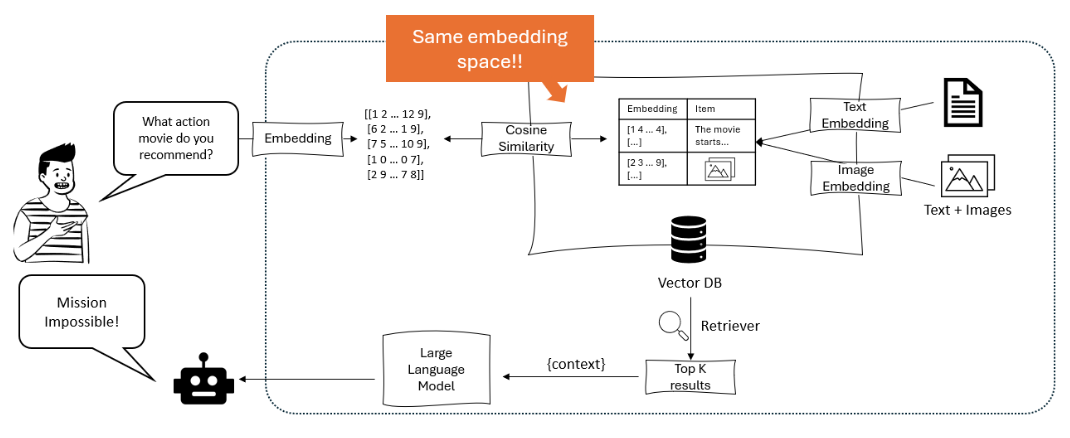
Le diagramme illustre un système de recommandation où un grand modèle de langue traite une requête de l’utilisateur en calculant des embeddings, qui sont ensuite comparés à l’aide de similarité cosinusique dans une base de vecteurs contenant à la fois des embeddings de texte et des embeddings d’images, afin de récupérer et recommander les éléments les plus pertinents. – opendatascience.com
Une approche clé dans les RAG multimodales est l’utilisation de modèles basés sur le transformeur, comme ViLBERT et LXMERT, qui employent des mécanismes d’attention croisée. Ces modèles peuvent se concentrer sur les régions pertinentes dans les images ou sur les segments spécifiques dans l’audio/vidéo en générant du texte, capturant des interactions fines entre les modalités. Cela permet des réponses plus ancrées visuellement et contextuellement. (Protecto.ai)
L’intégration du texte avec d’autres modalités dans les pipelines RAG pose des défis tels que l’alignement de représentations sémantiques sur différents types de données et la gestion des caractéristiques uniques de chacune des modalités pendant le processus d’embedding. Des techniques telles que l’encodage spécifique à la modalité et l’attention croisée sont utilisées pour aborder ces défis. (Zhu et al.)
Cependant, les avantages potentiels des RAG multimodales sont significatifs, y compris une précision améliorée, une contrôle et une interprétabilité accrues des contenus générés, ainsi que la capacité de soutenir de nouveaux cas d’utilisation tels que la réponse à des questions visuelles et la création de contenu multimodal.
Voilà la traduction en français :
Par exemple, Li et al. (2020) ont proposé un cadre multimodal RAG pour la réponse à des questions visuelles, qui récupère des images et des informations textuelles pertinentes pour générer des réponses précises, surpassant les approches antérieures état de l’art sur des benchmarks tels que VQA v2.0 et CLEVR. (MyScale)
Malgré les résultats prometteurs, le RAG multimodal introduit également de nouveaux défis, tels que une complexité computationnelle accrue, la nécessité de datasets multimodaux à grande échelle et le potentiel d’apparition de biais et de bruit dans l’information récupérée.
Les chercheurs explorent activement des techniques pour atténuer ces problèmes, comme les structures d’indexation efficaces, les stratégies d’augmentation de données et les méthodes d’entraînement adversaires. (Sohoni et al.)
Chapitre 3 : Mécanismes de Base du RAG
Ce chapitre explore l’interaction complexe entre les récupérateurs et les modèles génératifs dans les systèmes de Génération Augmentée par Récupération (RAG), en mettant en évidence leurs rôles cruciaux dans l’indexation, la récupération et la synthèse d’informations pour produire des réponses précises et contextuellement pertinentes.
Nous plongeons dans les subtilités des techniques de récupération sparse et dense, en comparant leurs forces et leurs faiblesses dans différents scénarios. De plus, nous examinons diverses stratégies pour intégrer l’information récupérée dans les modèles génératifs, comme la concaténation et l’attention croisée, et discutons de leur impact sur l’efficacité globale des systèmes RAG.
En comprenant ces stratégies d’intégration, vous gagneriez des aperçus précieux sur la manière d’optimiser les systèmes RAG pour des tâches et des domaines spécifiques, ouvrant ainsi la voie à une utilisation plus informée et plus efficace de ce paradigme puissant.
3.1 La puissance de la combinaison de l’information de recherche et de génération dans RAG
Le Génération-Aideée à la Recherche (RAG) représente un puissant paradigme qui intègre parfaitement l’information de recherche avec les modèles de langage génératifs. RAG est composé de deux composants principaux, comme vous pouvez le constater à travers son nom : Recherche et Génération.
Le composant de recherche est chargé d’indexer et de rechercher dans une vaste base de connaissances, tandis que le composant de génération utilise l’information retrouvée pour produire des réponses pertinentes et factuelles dans le contexte. (Redis et Lewis et al.)
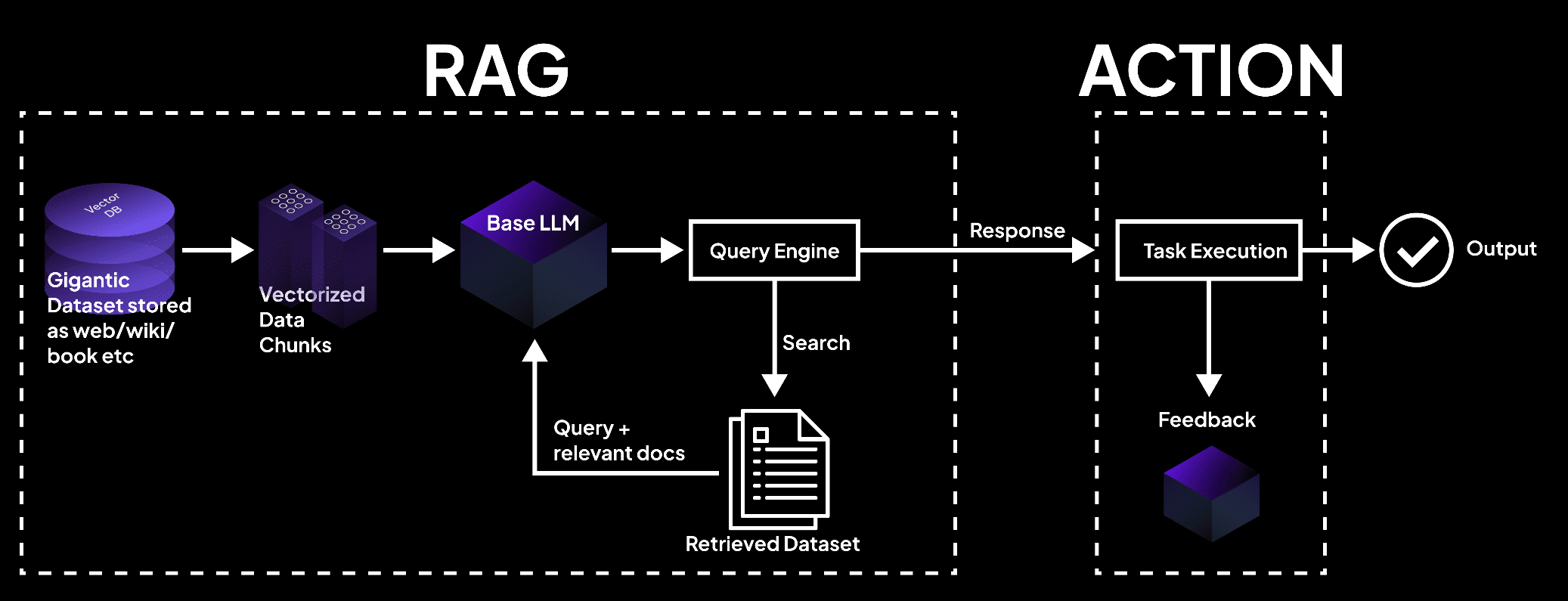
L’image montre un système RAG où une base de vecteurs traite les données en blocs, consultés par un modèle de langage pour retrouver des documents pour l’exécution des tâches et des sorties précises. – superagi.com
Le processus de récupération commence par l’indexation de sources externes de connaissance, telles que des bases de données, des documents et des pages Web. (Redis et Lewis et al.) Les récupérateurs et indexeurs jouent un rôle crucial dans ce processus, en organisant et en stockant l’information de manière efficace dans un format qui facilite la recherche et la récupération rapides.
Lorsqu’une requête est posée au système RAG, le récupérateur cherche dans la base de connaissance indexée pour identifier les informations les plus pertinentes en fonction de la similarité sémantique et d’autres métriques de pertinence.
Une fois que les informations pertinentes sont récupérées, la composante de génération prend le relais. Le contenu récupéré est utilisé pour prompter et guider le modèle de langage génératif, fournissant au modèle les contextes et appuis factuels nécessaires pour générer des réponses précises et informatives.
Le modèle de langage utilise des techniques d’inférence avancées, telles que des mécanismes d’attention et des architectures de transformeurs, pour synthétiser l’information récupérée avec ses connaissances préexistantes et générer du texte cohérent et fluide.
Le flux d’information dans un système RAG peut être illustré de la manière suivante :
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
Les avantages de RAG sont multiples :
Cette fusion de capacités de récupération et de génération permet la création de réponses qui sont non seulement appropriées dans le contexte mais sont également informées par les informations les plus courantes et les plus exactes disponibles. (Guu et al.)
En exploitant des sources de connaissance externes, RAG réduit significativement la fréquence des hallucinations ou des sorties factuellement incorrectes, qui sont des faille courantes des modèles génératifs purement.
De plus, RAG permet l’intégration d’informations à jour, garantissant que les réponses générées reflètent les dernières connaissances et développements dans un domaine donné. Cela est particulièrement crucial dans les domaines tels que la santé, les finances et la recherche scientifique, où l’exactitude et la pertinence des informations sont d’une importance primordiale. (Guu et al. et NVIDIA)
RAG montre également une adaptabilité remarquable, permettant aux modèles de langue de gérer une variété de tâches avec une performance améliorée. En retirant dynamiquement des informations relevantes en fonction de la requête ou du contexte spécifique, RAG donne aux modèles la capacité de générer des réponses adaptées aux exigences uniques de chaque tâche, qu’il s’agisse de répondre à des questions, de générer du contenu ou d’applications spécialisées dans un domaine.
De nombreuses études ont démontré l’efficacité de RAG dans l’amélioration de l’exactitude factuelle, de la pertinence et de l’adaptabilité des modèles de langue génératifs.
Par exemple, Lewis et al. (2020) ont montré que RAG dépassait les modèles génératifs purs sur une série de tâches de réponse à des questions, atteignant des résultats de pointe sur des benchmarks tels que Natural Questions et TriviaQA. (Lewis et al.)
De même, Izacard et Grave (2021) ont démontré la supériorité de RAG par rapport aux modèles de langue traditionnels pour la génération de textes longs cohérents et factuellement cohérents.
La génération assistée par récupération représente une approche révolutionnaire de la génération de langue, en exploitant le pouvoir de la recherche d’information pour améliorer l’exactitude, la pertinence et l’adaptabilité des modèles génératifs.
En intégrant de manière transparente les connaissances externes aux capacités linguistiques préexistantes, RAG ouvre de nouvelles possibilités pour le traitement du langage naturel et prépare la voie vers des systèmes de génération de langue plus intelligents et plus fiables.
3.2 Stratégies d’intégration du retourneur-générateur
Les systèmes de Génération assistée par récupération (RAG) font appel à deux composants clés : les retourneurs et les modèles génératifs. Les retourneurs sont chargés de rechercher et de retourner des informations pertinentes à partir de bases de connaissances à grande échelle de manière efficace.
« Il comporte deux phases principales, l’indexation et la recherche. L’indexation organise les documents pour faciliter une recherche efficace, en utilisant soit des index inversés pour la recherche éparses, soit des encodages de vecteurs denses pour les recherches denses. » (Redis)
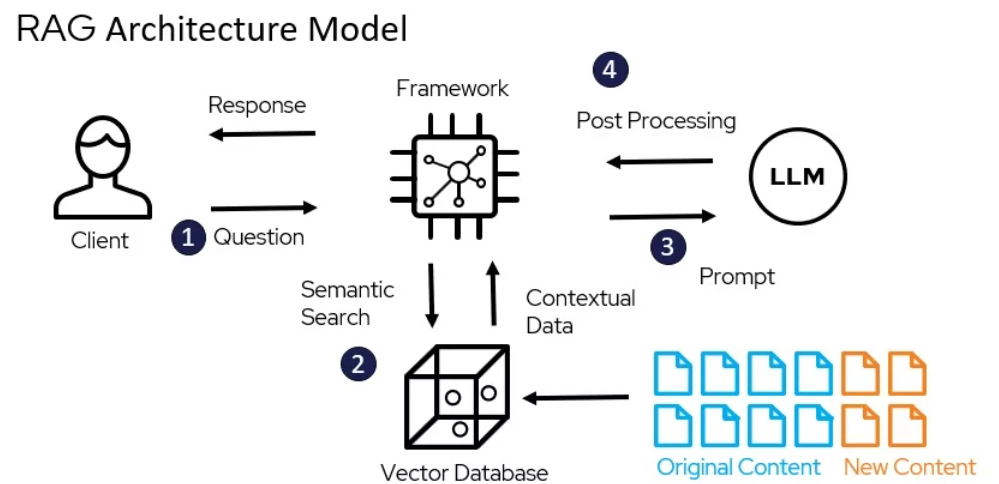
Le modèle architecture de RAG – miro.medium.com
Les techniques de recherche éparses, telles que TF-IDF et BM25, représentent les documents sous forme de vecteurs épars de haute dimension, où chaque dimension correspond à un terme unique de la vocabulary. La pertinence d’un document par rapport à une requête est déterminée par l’overlap des termes, pondérés par leur importance.
Par exemple, en utilisant la populaire bibliothèque Elasticsearch, un rechercheur basé sur TF-IDF peut être mis en œuvre comme suit:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Les techniques de recherche denses, telles que la recherche de passage dense (DPR) et les modèles basés sur BERT, représentent les documents et les requêtes sous forme de vecteurs denses dans un espace d’embaumement continu. La pertinence est déterminée par la similarité cosinus entre les vecteurs de requête et de document.
DPR peut être mis en œuvre en utilisant la bibliothèque Hugging Face Transformers:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
Les modèles génératifs, tels que GPT et T5, sont utilisés dans RAG pour générer des réponses cohérentes et pertinentes à la lumière des informations retrouvées. L’entraînement de ces modèles sur des données spécialisées et l’utilisation de techniques d’ingénierie de déclencheurs peuvent améliorer significativement leur performance dans les systèmes RAG. (Communauté DEV)
Les stratégies d’intégration déterminent comment le contenu récupéré est intégré aux modèles génératifs.
Le composant de génération utilise le contenu récupéré pour formuler des réponses cohérentes et pertinentes au prompt et pendant la phase d’inférence. (Redis)
Deux approches courantes sont la concaténation et l’attention croisée.
La concaténation implique d’ajouter les extraits récupérés à la requête d’entrée, ce qui permet au modèle génératif d’attendre sur l’information pertinente pendant le processus de décodage.
Bien que cette approche soit simple à mettre en œuvre, elle peut avoir du mal avec les longues séquences et l’information non pertinente. (Communauté DEV) Les mécanismes d’attention croisée, tels que RAG-Token et RAG-Sequence, permettent au modèle génératif de s’attendre sélectivement sur les extraits récupérés à chaque étape de décodage.
Cela permet un contrôle plus précis du processus d’intégration, mais entraîne une complexité computationnelle accrue.
Par exemple, RAG-Token peut être mis en œuvre à l’aide de la bibliothèque Hugging Face Transformers :
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
La sélection du retrouveur, du modèle génératif et de la stratégie d’intégration dépend des exigences spécifiques du système RAG, telles que la taille et la nature de la base de connaissance, le compromis souhaité entre l’efficacité et l’efficacité et le domaine d’application cible.
Chapitre 4 : Applications et cas d’utilisation
Ce chapitre examine le potentiel transformatif de la génération assistée par récupération (RAG) dans la révolution des applications de langues peu dotées en ressources et multilingues. Nous plongeons dans des stratégies telles que la traduction des documents sources dans des langues riches en ressources, l’utilisation d’embauches multilingues et l’application du apprentissage fédéré pour surmonter les limitations de données et les différences linguistiques.
De plus, nous abordons le défi crucial de réduire les hallucinations dans les systèmes RAG multilingues pour assurer une génération de contenu précise et fiable. En explorant ces approches innovantes, ce chapitre offre une guide complète sur l’utilisation du pouvoir de la RAG pour une inclusivité et une diversité dans le traitement de la langue.
4.1 Applications de la RAG : de la QA à la rédaction créative
La génération assistée par récupération (RAG) a trouvé de nombreuses applications pratiques dans divers domaines, montrant son potentiel pour révolutionner la manière dont nous interagissons et générer de l’information. En exploitant le pouvoir de la récupération et de la génération, les systèmes RAG ont montré des améliorations significatives en termes d’exactitude, de pertinence et de participation utilisateur.
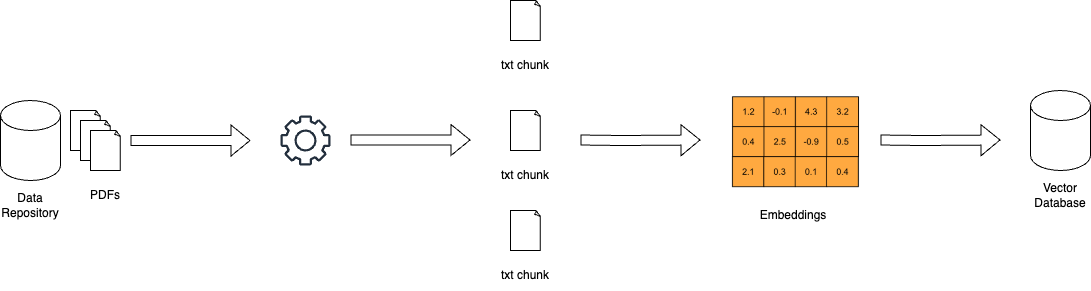
Comment la RAG Fonctionne – miro.medium.com
La Recherche de Questions
RAG a démontré qu’il peut transformer le domaine de la réponse à des questions en retirant des informations pertinentes de sources de connaissance externes et en les intégrant dans le processus de génération, ce qui permet aux systèmes RAG de fournir des réponses plus précises et pertinentes dans le contexte aux requêtes utilisateurs. (LangChain et Django Stars)
Par exemple, Izacard et Grave (2021) ont proposé un modèle basé sur RAG appelé Fusion-in-Decoder (FiD), qui a atteint des performances de pointe sur plusieurs benchmarks de réponse à des questions, y compris Natural Questions et TriviaQA. (Izacard and Grave)
FiD utilise un retrouveur dense pour extraire des passages pertinents et un modèle génératif pour synthétiser les informations retrouvées en une réponse cohérente, dépassant nettement les modèles génératifs purement par une marge significative. (Izacard and Grave)
Les systèmes de dialogue.
RAG a également trouvé des applications dans la création de personnages conversationnels plus engageants et informatifs. En intégrant des connaissances externes à travers la récupération, les systèmes de dialogue basés sur RAG peuvent générer des réponses qui sont non seulement appropriées dans le contexte mais également basées sur des faits. (LlamaIndex et MyScale)
Shuster et al. (2021) ont présenté un système de dialogue basé sur RAG appelé BlenderBot 2.0, qui a montré des capacités de conversation améliorées par rapport à son prédécesseur. (Shuster et al.)
BlenderBot 2.0 récupère des informations pertinentes à partir d’un ensemble diversifié de sources de connaissance, y compris Wikipedia, des articles de presse et des médias sociaux, ce qui lui permet de mener des conversations plus informées et plus cohérentes sur une large gamme de sujets. (Shuster et al.)
Révision
RAG a montré son potentiel dans l’amélioration de la qualité des sommaires générés en incorporant des informations pertinentes à partir de multiples sources. (Hyperight) Pasunuru et al. (2021) ont proposé un modèle de sommaire basé sur RAG appelé PEGASUS-X, qui récupère et intègre des passages pertinents issus de documents externes pour générer des sommaires plus informatifs et plus cohérents.
PEGASUS-X a surpassé les modèles génératifs purement aléatoires sur plusieurs benchmarks de résumé, montrant l’efficacité de la récupération dans l’amélioration de l’exactitude factuelle et de la pertinence des résumés générés.
Écriture créative
Le potentiel de RAG dépasse les domaines factuels pour s’étendre à l’univers de l’écriture créative. En récupérant des passages pertinents à partir d’un corpus diversifié de œuvres littéraires, les systèmes RAG peuvent générer des histoires ou des articles nouveaux et engageants.
Rashkin et al. (2020) ont présenté un modèle d’écriture créative basé sur RAG appelé CTRL-RAG, qui récupère des passages pertinents à partir d’un large jeu de données de fictions et les intègre au processus de génération. CTRL-RAG a montré la capacité à générer des histoires cohérentes et stylistiquement cohérentes, montrant le potentiel de RAG dans les applications créatives.
Études de cas
Plusieurs articles de recherche et projets ont démontré l’efficacité de RAG dans divers domaines.
Par exemple, Lewis et al. (2020) ont présenté le cadre RAG et l’ont appliqué à la réponse à des questions ouvertes, atteignant des performances de pointe sur le benchmark Natural Questions. (Lewis et al.) Ils ont mis en avant les défis de la recherche efficace et l’importance de la fine-tuning du modèle génératif sur les passages récupérés.
Dans un autre cas d’étude, Petroni et al. (2021) ont appliqué RAG à la tâche de vérification des faits, démontrant ainsi sa capacité à retrouver des preuves pertinentes et à générer des jugements précis. Ils ont mis en évidence le potentiel de RAG dans la lutte contre les informations erronées et l’amélioration de la fiabilité des systèmes d’information.
L’impact de RAG sur l’expérience utilisateur et les indicateurs commerciaux a été significatif. En fournissant des réponses plus précises et informatives, les systèmes basés sur RAG ont amélioré la satisfaction des utilisateurs et leur engagement. (LlamaIndex et MyScale)
Dans le cas des agents conversationnels, RAG a permis des interactions plus naturelles et cohérentes, ce qui a augmenté la réduction des utilisateurs et leur loyauté. (LlamaIndex et MyScale) Dans le domaine de la création littéraire, RAG a le potentiel de rationaliser les processus de création de contenu et de générer des idées nouvelles, en économisant temps et ressources pour les entreprises.
Comme vous pouvez le voir, les applications pratiques de RAG couvrent un large éventail de domaines, allant de la réponse à des questions et des systèmes de dialogue à la résumé et à la création littéraire. En exploitant le pouvoir de la récupération et de la génération, RAG a démontré des améliorations significatives en termes de précision, de pertinence et de engagement utilisateur.
Comme ce domaine continue d’évoluer, nous pouvons nous attendre à voir davantage d’applications innovantes de l’IRA (Inférence de Requête Augmentée), transformant notre manière d’interagir et de générer de l’information dans divers contextes.
4.2 IRA pour les langues à ressources limitées et les environnements multilingues
Exploiter le pouvoir de l’Inférence de Requête Augmentée (IRA) pour les langues à ressources limitées et les environnements multilingues n’est pas seulement une opportunité, c’est une nécessité. Avec plus de 7 000 langues parlées dans le monde, dont beaucoup manquent de ressources numériques substantielles, la difficulté est claire : comment assurons-nous que ces langues ne sont pas laissées pour compte dans l’ère numérique ?
La traduction comme pont
Une stratégie efficace consiste à traduire les documents sources dans une langue plus riche en ressources avant l’indexation. Cette méthode utilise les vastes corpus disponibles dans des langues comme l’anglais, améliorant significativement l’exactitude et la pertinence de la récupération.
En traduisant les documents en anglais, vous pouvez utiliser les vastes ressources et les techniques de récupération avancées déjà développées pour les langues à ressources élevées, améliorant ainsi la performance des systèmes d’IRA dans les contextes à ressources limitées.
Embeddings multilingues
Les derniers progrès dans les embeddings multilingues offrent une autre solution prometteuse. En créant des espaces d’embedding partagés pour plusieurs langues, vous pouvez améliorer la performance interlinguale même pour les langues très à faibles ressources.
La recherche a montré que l’intégration de langues intermédiaires avec des embeddings de haute qualité peut combler le fossé entre des paires de langues éloignées, enhancing the overall quality of multilingual embeddings.
Cette méthode non seulement améliore l’exactitude du recherche mais garantit également que le contenu généré est contextuellement pertinent et linguistiquement cohérent.
Apprentissage fédéré
L’apprentissage fédéré propose une approche nouvelle pour surmonter les contraintes de partage de données et les différences linguistiques. En finissant les modèles sur des sources de données décentralisées, vous pouvez protéger la privacy utilisateur tout en améliorant la performance du modèle sur plusieurs langues.
Cette méthode a montré une précision supérieure de 6,9% et une réduction de 99% des paramètres d’entraînement par rapport aux méthodes traditionnelles, ce qui en fait une solution très efficiente et efficace pour les systèmes RAG multilingues.
Atténuation des hallucinations
Un des défis cruciaux dans la mise en œuvre de systèmes RAG dans des environnements multilingues est l’atténuation des hallucinations – des instances où le modèle génère des informations factuellement incorrecte ou irrelevante.
Des techniques RAG avancées, telles que RAG Modulaire, introduisent de nouvelles modules et des stratégies de finition pour aborder ce problème. En mettant à jour en continu la base de connaissances et en employant des critères d’évaluation rigoureux, vous pouvez réduire significativement la fréquence des hallucinations et garantir que le contenu généré est à la fois précis et fiable.
Mise en œuvre pratique
Pour mettre en œuvre ces stratégies efficacement, pensez aux étapes pratiques suivantes :
- Utilisez la traduction : Traduisez les documents de langues à ressources faibles dans une langue à ressources élevées comme l’anglais avant d’indexer.
- Utilisez des Embeduations Multilingues : Intégrez des langues intermédiaires avec de hautes qualités d’embauches pour améliorer les performances cross-linguistiques.
- Adoptez l’Apprentissage Fédéré : Retravailliez les modèles sur des sources de données décentralisées pour améliorer les performances tout en préservant la privacy.
- Atténuez les Hallucinations : Employez des techniques avancées RAG et des mises à jour continues de la base de connaissances pour assurer l’exactitude factuelle.
En adoptant ces stratégies, vous pouvez significativement améliorer les performances des systèmes RAG dans les environnements à ressources faibles et multilingues, en assurant queaucune langue est laissée de côté dans la révolution numérique.
Chapitre 5 : Techniques d’Optimisation
Ce chapitre plonge dans les techniques avancées de recherche sous-jacentes à l’efficacité des systèmes de génération assistée par recherche (RAG). Explorez comment l’optimisation des blocs, l’intégration des métadonnées, l’indexation basée sur le graphe, les techniques d’alignement, la recherche hybride et le ré-évaluation améliorent l’exactitude, la pertinence et la complétude de la recherche d’information.
En comprenant ces méthodes de pointe, vous aurez des aperçus de l’évolution des systèmes RAG de simples moteurs de recherche vers des fournisseurs intelligents d’information capable de comprendre des requêtes complexes et de fournir des réponses précises et pertinentes dans le contexte.
5.1 Techniques Avancées de Recherche pour Optimiser les Systèmes RAG
Les systèmes de génération assistée par recherche (RAG) révolutionnent la manière dont nous accédons et utilisons l’information. Le cœur de ces systèmes réside dans leur capacité à retrouver effectivement des informations pertinentes.
Faisons un peu plus profond dans les techniques avancées de récupération qui permettent aux systèmes RAG de fournir des réponses précises, pertinentes dans le contexte et complètes.
Optimisation des morceaux : maximiser la pertinence par une récupération granulaire
Dans le monde des systèmes RAG, les documents longs peuvent être démesurables. L’optimisation des morceaux répond à ce défi en divisant les textes étendus en unités plus petites et gérables, appelées morceaux. Cette granularité permet aux systèmes de récupération de localiser des sections spécifiques de texte qui correspondent aux termes de la requête, améliorant ainsi la précision et l’efficacité.
L’art de l’optimisation des morceaux consiste à déterminer la taille idéale des morceaux et de l’overlap. Un morceau trop petit peut manquer de contexte, tandis qu’un morceau trop grand peut diluer la pertinence. Le chunking dynamique, une technique qui adapte la taille des morceaux en fonction de la structure et de la sémantique du contenu, assure que chaque morceau est cohérent et meaningfull du point de vue contextuel.
Intégration des métadonnées : exploiter la puissance des balises d’information
Les métadonnées, souvent négligées, accompagnent les documents et peuvent constituer une véritable mine d’or pour les systèmes de récupération. En intégrant des métadonnées telles que le type de document, l’auteur, la date de publication et les tags de sujet, les systèmes RAG peuvent effectuer des recherches plus ciblées.
La récupération par auto-requête, une technique rendue possible par l’intégration des métadonnées, permet au système de générer des requêtes supplémentaires en fonction des résultats initiaux. Ce processus itératif affine la recherche, veillant à ce que les documents récupérés correspondent à la requête mais aussi répondent aux besoins spécifiques et contextuels de l’utilisateur.
Structures d’indexation avancées : réseaux basés sur des graphes pour les requêtes complexes
Les méthodes d’indexation traditionnelles, telles que les indexes inversés et les encodages vecteurs denses, présentent des limitations lors de la gestion de requêtes complexes impliquant plusieurs entités et leurs relations. Les indexations basées sur le graphe offrent une solution en organisant les documents et leurs connexions dans une structure de graphe.
Cette organisation de type graphe permet une navigation et une récupération efficaces de documents liés, même dans des scénarios complexes. L’indexation hiérarchique et la recherche de voisins les plus proches approximatifs améliorent encore la scalabilité et la vitesse des systèmes de récupération basés sur le graphe.
Techniques d’alignement : Assurer l’exactitude et réduire les hallucinations
La crédibilité des systèmes RAG (Relation-aware Generation) repose sur leur capacité à fournir des informations précises. Les techniques d’alignement, telles que la formation par le contre-exemple, traitent ce problème. En exposant le modèle à des scénarios hypothétiques, la formation par le contre-exemple le teach à distinguer entre les faits du monde réel et l’information générée, réduisant ainsi les hallucinations.
Dans les systèmes RAG multimodaux, qui intègrent des informations provenant de diverses sources telles que le texte et les images, l’apprentissage contrasté joue un rôle crucial. Cette technique aligne les représentations sémantiques de différentes modalités de données, garantissant que l’information récupérée est cohérente et intégrée contextuellement.
Recherche hybride : Fusionner la précision des mots-clés avec la compréhension sémantique
La recherche hybride combine les avantages de deux mondes différents : la vitesse et la précision de la recherche de mots-clés avec la compréhension sémantique de la recherche vectorielle. Initialement, une recherche de mots-clés permet rapidement de réduire le nombre de documents potentiels.
Postérieurement, une recherche basée sur les vecteurs refine les résultats en fonction de la similarité sémantique. Cette approche est particulièrement efficace quand les correspondances exactes des mots clés sont essentielles, mais une meilleure compréhension de l’intention de la requête est également nécessaire pour un tirage précis.
Re-ranking : Améliorer la pertinence pour la réponse optimale
Dans la dernière étape du tirage, le re-ranking intervient pour affiner les résultats. Des modèles d’apprentissage automatique, tels que les encodeurs croisés, réévaluent les scores de pertinence des documents retournés. En traitant la requête et les documents ensemble, ces modèles gagnent une meilleure compréhension de leurs relations.
Cette comparaison nuancée s’assure que les documents les mieux classés sont véritablement alignés sur la requête de l’utilisateur et le contexte, offrant une expérience de recherche plus satisfaisante et informatrice.
La force des systèmes RAG réside dans leur capacité à retrouver et présenter l’information de manière transparente. En employant ces techniques de tirage avancées – optimisation des blocs, intégration de métadonnées, indexation basée sur le graphe, techniques d’alignement, recherche hybride et re-ranking – les systèmes RAG deviennent plus que des moteurs de recherche. Ils évoluent en fournisseurs intelligents d’information, capables de comprendre des requêtes complexes, de discerner les nuances et de fournir des réponses précises, pertinentes et fiables.
Chapitre 6 : Défis et innovations
Ce chapitre examine les défis cruciaux et les directions futures dans le développement et la mise en œuvre de systèmes de Génération-Aiguillée par Recherche (RAG).
Nous explorons les complexités de l’évaluation des systèmes RAG, y compris la nécessité d’avoir des métriques complètes et des cadres adaptatifs pour évaluer leurs performances avec précision. Nous abordons également des considérations éthiques telles que la réduction de labiaison et la justice dans l’information de recherche et de génération.
Nous examinons également l’importance de l’accélération matérielle et de stratégies d’implémentation efficaces, en mettant en avant l’utilisation de matériel spécialisé et d’outils d’optimisation tels que Optimum pour améliorer les performances et la scalabilité.
En comprenant ces défis et en explorant des solutions potentielles, ce chapitre fournit une feuille de route complète pour le développement continu et l’implémentation responsable de la technologie RAG.
6.1 Défis et Directions Futures
Les systèmes RAG (Retrieval-Augmented Generation) ont démontré un potentiel remarquable pour améliorer l’exactitude, la pertinence et la cohérence du texte généré. Cependant, le développement et l’implémentation de systèmes RAG posent également des défis importants qui doivent être résolus pour tirer pleinement partie de leur potentiel.
« L’évaluation des systèmes RAG implique donc de considérer un certain nombre de composants spécifiques et la complexité de l’évaluation du système global. » (Salemi et al.)
Défis dans l’Évaluation des Systèmes RAG
L’un des principaux défis techniques dans RAG consiste à assurer une recherche efficace d’informations pertinentes dans des bases de connaissances à grande échelle. (Salemi et al. et Yu et al.)
Avec la taille et la diversité des sources de connaissances continuant à croître, la développation de mécanismes de recherche scalables et robustes est de plus en plus critique. Des techniques telles que l’indexation hiérarchique, la recherche de plus proches voisins approximatifs et les stratégies d’apprentissage adaptative doivent être explorées pour optimiser le processus de recherche.
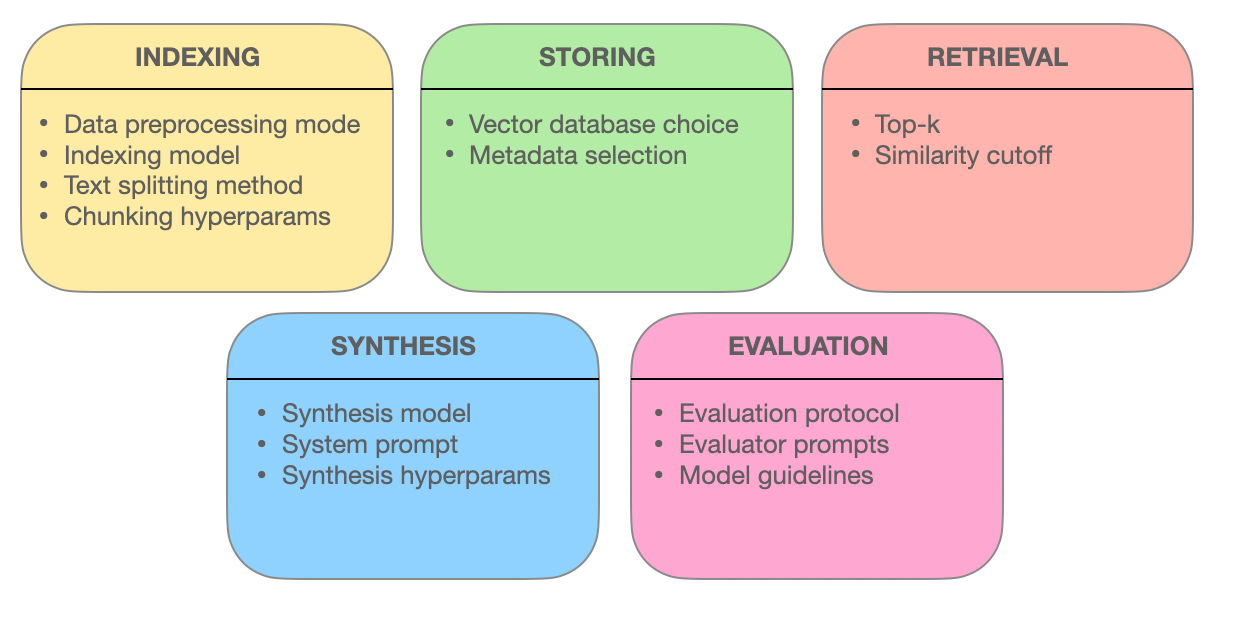
Certains éléments impliqués dans un système RAG – miro.medium.com
Un autre défi significatif consiste à atténuer le problème de hallucination, où le modèle génératif produit des informations factuellement incorrectes ou inconsistes.
Par exemple, un système RAG pourrait générer un événement historique qui n’a jamais eu lieu ou attribuer incorrectement une découverte scientifique. Si la recherche aide à ancrer le texte généré dans les connaissances factuelles, assurer la fidélité et la cohérence de la sortie générée demeure un problème complexe.
Par exemple, un système RAG peut retrouver des informations précises sur une découverte scientifique dans une source fiable comme Wikipédia, mais le modèle génératif pourrait toujours halluciner en combinant incorrectement cette information ou en ajoutant des détails inexistants.
Le développement de mécanismes efficaces pour détecter et prévenir les hallucinations est un domaine de recherche actif. Des techniques telles que la vérification des faits en utilisant des bases de données externes et la vérification de la cohérence par référence croisée à travers plusieurs sources sont explorées. Ces méthodes visent à s’assurer que le contenu généré reste précis et fiable, malgré les défis inhérents à l’alignement des processus de récupération et de génération.
L’intégration de sources diverses, telles que des bases de données structurées, du texte non structuré et des données multimodales, pose des défis supplémentaires dans les systèmes RAG. (Yu et al. et Zilliz) L’alignement des représentations et de la sémantique across different data modalities and knowledge formats nécessite des techniques sophistiquées, telles que l’attention croisée multimodale et l’implémentation des graphes de connaissance. Assurer la compatible et l’interopérabilité des diverses sources de connaissance est crucial pour le fonctionnement efficace des systèmes RAG. (Zilliz)
Au-delà des défis techniques, les systèmes RAG soulèvent également d’importantes considérations éthiques. Assurer un accès à l’information et une génération impartiales et justes est une préoccupation critique. Les systèmes RAG pourraient inadvertamment amplifier les biais présents dans les données d’entraînement ou les sources de connaissance, menant à des sorties discriminatoires ou trompeuses. (Salemi et al. et Banafa)
Développer des techniques pour détecter et atténuer les biais, telles que l’entraînement adversitaire et le recherche à la recherche de justice, est une direction de recherche importante. (Banafa)
Direction de recherche future
Pour aborder les défis de l’évaluation des systèmes RAG, plusieurs solutions potentielles et directions de recherche peuvent être explorées.
Développer des indicateurs d’évaluation complets qui captent l’interaction entre l’exactitude de la récupération et la qualité de la génération est crucial. (Salemi et al.)
Il est nécessaire de définir des métriques qui évaluent la pertinence, la cohérence et la corrélation factuelle du texte généré, en tenant compte de l’efficacité du composant de récupération, (Salemi et al.). Cela nécessite une approche holistiche qui va au-delà des métriques traditionnelles telles que BLEU et ROUGE et intègre l’évaluation humaine et des mesures spécifiques à la tâche.
L’exploration de schémas d’évaluation adaptatifs et en temps réel est une autre direction prometteuse.
Les systèmes RAG fonctionnent dans un environnement dynamique où les sources de connaissance et les exigences utilisateur peuvent évoluer au fil du temps. (Yu et al.) L’élaboration de schémas d’évaluation qui peuvent s’adapter à ces changements et fournir un feedback en temps réel sur la performance du système est essentiel pour l’amélioration continue et le suivi.
Cela pourrait impliquer des techniques telles que l’apprentissage en ligne, l’apprentissage actif et l’apprentissage par réinforcement pour mettre à jour les métriques d’évaluation et les modèles en fonction des retours utilisateurs et du comportement du système. (Yu et al.).
Les efforts collaboratifs entre les chercheurs, les praticiens de l’industrie et les experts du domaine sont nécessaires pour avancer dans le domaine de l’évaluation des systèmes RAG. L’établissement de benchmarks standardisés, de jeux de données et de protocoles d’évaluation peut faciliter la comparaison et la reproductibilité de systèmes RAG dans différents domaines et applications. (Salemi et al. et Banafa)
Le engagement des intervenants, y compris les utilisateurs finaux et les décideurs politiques, est crucial pour s’assurer que le développement et la mise en œuvre de systèmes RAG alignent les valeurs sociétales et les principes éthiques. (Banafa)
Donc, bien que les systèmes RAG aient montré un immense potentiel, résoudre les défis dans leur évaluation est crucial pour leur adoption large et la confiance en eux. En développant des indicateurs d’évaluation complètes, en exploreant des cadres d’évaluation adaptatifs et en temps réel, et en encourageant les efforts collaboratifs, nous pouvons permettre l’arrivée de systèmes RAG plus fiables, impartiaux et efficaces.
Au fil de l’évolution du domaine, il est essentiel de prioritiser les efforts de recherche qui non seulement avancent les capacités techniques des systèmes RAG mais assurent également leur déploiement responsable et éthique dans des applications réelles.
6.2 Accélération matérielle et déploiement efficient des systèmes RAG
L’utilisation d’accélération matérielle est essentielle pour un déploiement efficient des systèmes de génération assistée par récupération (RAG). En déchargant les tâches intensives en calcul sur des matériels spécialisés, vous pouvez améliorer considérablement la performance et la scalabilité de vos modèles RAG.
Exploiter l’accélération matérielle
Les outils d’optimisation matérielle spécifique d’Optimum offrent des avantages substantiels. Par exemple, le déploiement de systèmes RAG sur des processeurs Habana Gaudi peut entraîner une réduction notable de la latence d’inférence, tandis que les optimisations d’Intel Neural Compressor peuvent améliorer les métriques de latence. Le matériel AWS Inferentia, optimisé via Optimum Neuron, peut améliorer les capacités de traitement en charge, rendant votre système RAG plus responsive et efficient.
Optimiser l’utilisation des ressources
L’utilisation efficiente des ressources est cruciale. Les optimisations d’Optimum ONNX Runtime peuvent améliorer l’utilisation de la mémoire, tandis que l’API BetterTransformer peut améliorer l’utilisation du CPU et du GPU. Ces optimisations assurent que votre système RAG fonctionne à son efficacité maximale, réduisant les coûts opérationnels et améliorant les performances.
Scalabilité et flexibilité
Optimum permet une transition fluide entre les accélérateurs matériels différents, permettant une scalabilité dynamique. Cette prise en charge de plusieurs matériels permet de s’adapter aux exigences de calcul variables sans reconfiguration significative. De plus, les fonctionnalités de quantification et de compression de modèles dans Optimum peuvent faciliter des tailles de modèle plus efficientes, rendant le déploiement plus facile et plus économique.
Études de cas et applications réelles
Considérez l’application d’Optimum dans la recherche d’information sur le web dans le secteur de la santé. En exploitant les optimisations spécifiques aux matériels, les systèmes RAG peuvent gérer efficacement de grandes bases de données, offrant une recherche d’information précise et à temps. Cela non seulement améliore la qualité de la prestation des soins de santé mais également l’expérience utilisateur globale.
Pas pratiques pour la mise en œuvre
- Sélectionnez du matériel approprié : Choisissez des accélérateurs matériels tels que Habana Gaudi ou AWS Inferentia en fonction de vos besoins de performance spécifiques.
- Utilisez des outils d’optimisation : Appliquez les outils d’optimisation d’Optimum pour améliorer la latence, la throughput et l’utilisation des ressources.
- Assurez-vous de la scalabilité : Utilisez la prise en charge de plusieurs matériels pour dynamiquement scaler votre système RAG selon vos besoins.
- Optimisez la taille du modèle : Utilisez la quantification et le nettoyage du modèle pour réduire le surcharges calculatoires et faciliter l’implémentation.
En intégrant ces stratégies, vous pouvez significativement améliorer la performance, la scalabilité et l’efficacité de vos systèmes RAG, vous assurant ainsi d’être bien équipés pour gérer les applications complexes et réelles.
Conclusion : Le potentiel transformateur de RAG
La Génération Augmentée par Recherche (RAG) représente un paradigme transformateur dans le traitement du langage naturel, intégrant parfaitement la puissance de la recherche d’information avec les capacités génératrices de grands modèles de langage.
En exploitant des sources de connaissance externes, les systèmes RAG ont montré des améliorations remarquables dans l’exactitude, la pertinence et la cohérence du texte généré dans un large éventail d’applications, allant de la réponse aux questions et des systèmes de dialogue à la synthèse et l’écriture créative.
L’évolution des modèles linguistiques, depuis les systèmes basés sur des règles initiaux jusqu’aux architectures neurales d’avenir telles que BERT et GPT-3, a ouvert la voie à l’émergence de RAG. Les limitations de la mémoire purement paramétrique dans les modèles linguistiques traditionnels, comme les dates de coupure des connaissances et les incohérences factuelles, ont été effectivement traitées par l’intégration de la mémoire non-paramétrique à travers des mécanismes de recherche.
Les composants centraux des systèmes RAG, à savoir les récupérateurs et les modèles générateurs, travaillent en synergie pour produire des sorties contextuellement pertinentes et factuellement solides.
Les récupérateurs, utilisant des techniques telles que la recherche稀疏 (sparse) et dense, cherchent efficacement dans de vastes bases de connaissances pour identifier l’information la plus pertinente. Les modèles générateurs, utilisant des architectures comme GPT et T5, synthesent le contenu récupéré en texte cohérent et fluide.
Les stratégies d’intégration, telles que la concaténation et l’attention croisée, déterminent comment l’information récupérée est incorporée dans le processus de génération.
Les applications pratiques de RAG couvrent des domaines divers, montrant son potentiel pour révolutionner diverses industries.
Dans le domaine de la réponse à des questions, RAG a considérablement amélioré la précision et la pertinence des réponses, permettant une recherche d’information plus informatrice et fiable. Les systèmes de dialogue ont bénéficié de RAG, aboutissant à des conversations plus engageantes et plus cohérentes. Les tâches de synthèse ont vu une qualité et une cohérence accrues grâce à l’intégration d’informations pertinentes provenant de multiples sources. La création narrative a également été explorée, avec les systèmes RAG générant des histoires nouvelles et stylistiquement cohérentes.
Cependant, le développement et l’évaluation des systèmes RAG posent également d’énormes défis. L’extraction efficace de bases de connaissance à grande échelle, la réduction de l’illusionnisme et l’intégration de diverses modalités de données sont parmi les obstacles techniques qui doivent être réglés. Des considérations éthiques, telles que la nécessité d’assurer une recherche et une génération d’information impartiale et juste, sont cruciales pour le déploiement responsable de systèmes RAG.
Pour tirer pleinement partie potentiel de RAG, les futurs travaux de recherche doivent se concentrer sur la définition de critères d’évaluation complets qui captent l’interaction entre l’exactitude de la récupération et la qualité de la génération.
Des cadres d’évaluation adaptatifs et en temps réel qui peuvent gérer la nature dynamique des systèmes RAG sont essentiels pour une amélioration continue et un suivi. Des efforts collaboratifs entre les chercheurs, les praticiens industriels et les experts des domaines sont nécessaires pour établir des benchmarks, des jeux de données et des protocoles d’évaluation standardisés.
Le domaine de la RAG continue de s’évoluer et promet d’importantes améliorations dans la manière dont nous interagissons et générons de l’information. En exploitant les capacités de récupération et de génération, les systèmes RAG sont capables de révolutionner divers domaines, allant de l’indexation de l’information et des agents conversationnels à la création de contenu et à la découverte du savoir.
La Génération Augmentée par Récupération symbolise un progrès significatif sur la voie de l’achat de langage plus intelligent, plus précis et plus pertinent dans le contexte.
En éliminant le fossé entre la mémoire paramétrique et la mémoire non-paramétrique, les systèmes RAG ont ouvert de nouvelles perspectives pour le traitement du langage naturel et ses applications.
Au fil de la recherche et en résolvant les défis, nous pouvons attendre que la RAG joue un rôle de plus en plus important dans la formation de l’interaction homme-machine et de la génération du savoir.
A propos de l’auteur
Vahe Aslanyan ici, au carrefour de la science informatique, des sciences des données et de l’IA. Visitez vaheaslanyan.com pour voir un portefeuille témoignant de précision et de progrès. Mon expérience chevauche le fossé entre le développement full-stack et l’optimisation des produits AI, motivé par la résolution de problèmes de nouvelles manières.
Avec un parcours qui inclut la mise en place d’un bootcamp de data science de leader et de collaboration avec les meilleurs spécialistes de l’industrie, mon attention est toujours concentrée sur l’elevation de l’éducation technique aux normes universelles.
Comment Pouvez-Vous Plonger Plus Profondément?
Après l’étude de ce guide, si vous souhaitez plonger encore plus profondément et que l’apprentissage structuré soit votre style, envisagez de vous joindre à nous à LunarTech, nous proposons des cours individuels et un Bootcamp en Data Science, Machine Learning et AI.
Nous proposons un programme complet offrant une compréhension approfondie des théories, une implémentation pratique des mains dans les mains, un matériel de pratique extensif, et une préparation personnalisée d’entretiens pour vous mettre en route vers le succès à votre propre étape.
Vous pouvez vous inscrire à notre Bootcamp Data Science ultime et profiter d’un essai gratuit pour vous familiariser avec le contenu. Cela a acquis la reconnaissance de être l’un des Meilleurs Bootcamps Data Science de 2023 et a été présenté dans des publications respectées telles que Forbes, Yahoo, Entrepreneur et d’autres. Voilà votre chance de devenir partie d’une communauté qui prospère sur l’innovation et le savoir. Voici le message de bienvenue !
Connectez-vous avec moi.

LunarTechNewsletter
- Suivez-moi sur LinkedIn pour avoir plein de ressources gratuites en SIC, ML et IA
- Visitez mon site personnel
- Abonnez-vous à mon The Data Science and AI Newsletter
Si vous voulez en savoir plus sur une carrière en Science des Données, Apprentissage Automatique et Intelligence Artificielle, et apprendre comment obtenir un emploi en Science des Données, vous pouvez télécharger ce livret gratuit Data Science and AI Career Handbook.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/