













Hibernate
Hibernate ne dispose pas de support de recherche plein texte en soi. Il doit s’appuyer sur le moteur de base de données ou des solutions tierces.
Une extension appelée Hibernate Search s’intègre avec Apache Lucene ou Elasticsearch (il y a également une intégration avec OpenSearch).
Postgres
Postgres a intégré la fonctionnalité recherche plein texte depuis la version 7.3. Bien qu’elle ne puisse rivaliser avec des moteurs de recherche comme Elasticsearch ou Lucene, elle offre une solution flexible et robuste qui peut suffire à répondre aux attentes des utilisateurs d’applications—avec des fonctionnalités comme le stemming, le classement et l’indexation.
Nous allons brièvement expliquer comment effectuer une recherche plein texte dans Postgres. Pour plus d’informations, veuillez consulter la documentation de Postgres. En ce qui concerne le filtrage de texte essentiel, la partie la plus cruciale est l’opérateur mathématique @@.
Il renvoie true si le document (objet de type tsvector) correspond à la requête (objet de type tsquery).
L’ordre n’est pas crucial pour l’opérateur. Donc, peu importe si nous plaçons le document à gauche de l’opérateur et la requête à droite ou dans un ordre différent.
Pour une meilleure démonstration, nous utilisons une table de base de données appelée tweet.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)Avec de telles données :
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');Voyons maintenant à quoi ressemble l’objet tsvector pour la colonne short_content de chaque enregistrement.
SELECT id, to_tsvector('english', short_content) FROM tweet;Sortie :
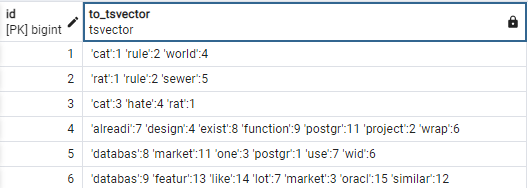
La sortie montre comment to_tsvector convertit la colonne de texte en un objet tsvector pour la configuration de recherche de texte ‘english‘.
Configuration de Recherche de Texte
Le premier paramètre de la fonction to_tsvector passé dans l’exemple ci-dessus était le nom de la configuration de recherche de texte. Dans ce cas, c’était le « english« . Selon la documentation de Postgres, la configuration de recherche de texte est la suivante :
… la fonctionnalité de recherche plein texte inclut la possibilité de faire bien plus de choses : ignorer l’indexation de certains mots (mots vides), traiter les synonymes et utiliser un traitement sophistiqué, par exemple, analyser en fonction de plus que juste l’espace blanc. Cette fonctionnalité est contrôlée par configurations de recherche de texte.
Donc, la configuration est une partie cruciale du processus et vitale pour nos résultats de recherche plein texte. Pour différentes configurations, le moteur Postgres peut renvoyer des résultats différents. Cela n’a pas besoin d’être le cas entre les dictionnaires pour différentes langues. Par exemple, vous pouvez avoir deux configurations pour la même langue, mais une ignore les noms contenant des chiffres (par exemple, certains numéros de série). Si nous passons notre requête le numéro de série spécifique que nous recherchons, qui est obligatoire, nous ne trouverons aucun enregistrement pour la configuration qui ignore les mots avec des chiffres. Même si nous avons de tels enregistrements dans la base de données, veuillez consulter la documentation de configuration pour plus d’informations.
Requête de texte
La requête de texte prend en charge de tels opérateurs que & (ET), | (OU), ! (NON), et <-> (SUIVI PAR). Les trois premiers opérateurs ne nécessitent pas une explication plus approfondie. L’opérateur <-> vérifie si les mots existent et s’ils sont placés dans un ordre spécifique. Ainsi, par exemple, pour la requête « rat <-> cat« , nous nous attendons à ce que le mot « cat » existe, suivi du « rat ».
Exemples
- Contenu qui contient le rat et le chat:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- Contenu qui contient base de données et marché, et le marché est le troisième mot après la base de données:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- Contenu qui contient base de données mais pas Postgres:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- Contenu contenant Postgres ou Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');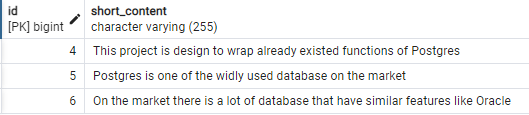
Fonctions enveloppantes
L’une des fonctions enveloppantes qui crée des requêtes textuelles a déjà été mentionnée dans cet article, à savoir la to_tsquery. Il existe d’autres fonctions de ce type comme:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
La plainto_tsquery convertit tous les mots passés en requête où tous les mots sont combinés avec l’opérateur & (AND). Par exemple, l’équivalent de la plainto_tsquery('english', 'Rat cat') est to_tsquery('english', 'Rat & cat').
Pour l’utilisation suivante:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');Nous obtenons le résultat ci-dessous:

phraseto_tsquery
La phraseto_tsquery convertit tous les mots passés en requête où tous les mots sont combinés avec l’opérateur <-> (SUIVI PAR). Par exemple, l’équivalent de la phraseto_tsquery('english', 'cat rule') est to_tsquery('english', 'cat <-> rule').
Pour l’utilisation suivante:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');Nous obtenons le résultat ci-dessous:

websearch_to_tsquery
La websearch_to_tsquery utilise une syntaxe alternative pour créer une requête textuelle valide.
- Unquoted text: Convertit une partie de la syntaxe de la même manière que
plainto_tsquery - Quoted text: Convertit une partie de la syntaxe de la même manière que
phraseto_tsquery - OR: Convertit en «
|» (OR) operator - «
-« : Identique à «!» (NOT) operator
Par exemple, l’équivalent de la websearch_to_tsquery('english', '"cat rule" or database -Postgres') est to_tsquery('english', 'cat <-> rule | database & !Postgres').
Pour l’utilisation suivante:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');Nous obtenons le résultat ci-dessous:

Postgres and Hibernate Native Support
Comme mentionné dans l’article, Hibernate seul ne dispose pas de support de recherche plein texte. Il doit s’appuyer sur le support du moteur de base de données. Cela signifie que nous sommes autorisés à exécuter des requêtes SQL natives comme indiqué dans les exemples ci-dessous:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}Hibernate With posjsonhelper Library
La bibliothèque posjsonhelper est un projet open-source qui ajoute un support pour les requêtes Hibernate pour les fonctions JSON de PostgreSQL et la recherche plein texte.
Pour le projet Maven, nous devons ajouter les dépendances ci-dessous :
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>Pour utiliser des composants qui existent dans la bibliothèque posjsonhelper, nous devons les enregistrer dans le contexte Hibernate.
Cela signifie qu’il doit y avoir une implémentation spécifiée de org.hibernate.boot.model.FunctionContributor. La bibliothèque dispose d’une implémentation de cette interface, à savoir com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor.
A file with the name « org.hibernate.boot.model.FunctionContributor » under the « resources/META-INF/services » directory is required to use this implementation.
Il existe une autre façon d’enregistrer le composant de posjsonhelper, qui peut être effectuée par programmation. Pour voir comment procéder, consultez ce lien.
À présent, nous pouvons utiliser des opérateurs de recherche plein texte dans les requêtes Hibernate.
PlainToTSQueryFunction
Il s’agit d’un composant qui enveloppe la fonction plainto_tsquery.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Pour une configuration avec la valeur 'english', le code va générer l’instruction ci-dessous :
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
Ce composant encapsule la fonction phraseto_tsquery.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Pour la configuration avec la valeur 'english', le code va générer l’instruction ci-dessous:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
Ce composant encapsule la fonction websearch_to_tsquery.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Pour la configuration avec la valeur 'english', le code va générer l’instruction ci-dessous:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)Requêtes HQL
Tous les composants mentionnés peuvent être utilisés dans des requêtes HQL. Pour voir comment cela peut être fait, veuillez cliquer sur ce lien.
Pourquoi utiliser la bibliothèque posjsonhelper alors que nous pouvons utiliser l’approche native avec Hibernate?
Bien que concaténer dynamiquement une chaîne censée être une requête HQL ou SQL puisse sembler facile, mettre en œuvre des prédicats serait une meilleure pratique, surtout lorsque vous devez gérer des critères de recherche basés sur des attributs dynamiques de votre API.
Conclusion
Comme mentionné dans l’article précédent, le support de recherche plein texte de Postgres peut être une bonne alternative pour des moteurs de recherche importants comme Elasticsearch ou Lucene, dans certains cas. Cela pourrait nous épargner la décision d’ajouter des solutions tierces à notre pile technologique, qui pourrait également ajouter plus de complexité et de coûts supplémentaires.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6