













Cas classique 1
De nombreux professionnels des logiciels manquent de connaissances approfondies sur le raisonnement logique du TCP/IP, ce qui conduit souvent à identifier mal des problèmes comme des problèmes mystérieux. Certains sont découragés par la complexité de la littérature sur le réseau TCP/IP, tandis que d’autres sont induits en erreur par des détails confus dans Wireshark. Par exemple, un DBA confronté à des problèmes de performance pourrait mal interpréter les données de capture de paquets dans Wireshark, concluant à tort que les retransmissions TCP en sont la cause.

Étant donné que la retransmission est suspectée, il est essentiel de comprendre sa nature. La retransmission implique fondamentalement une retransmission par timeout. Pour confirmer si la retransmission est effectivement la cause, des informations liées au temps sont nécessaires, ce qui n’est pas fourni dans la capture d’écran ci-dessus. Après avoir demandé une nouvelle capture d’écran au DBA, les informations d’horodatage ont été incluses.

Lors de l’analyse des paquets réseau, les informations d’horodatage sont cruciales pour un raisonnement logique précis. Une différence de temps dans la plage des microsecondes entre deux paquets dupliqués suggère soit une retransmission par timeout, soit une capture de paquets dupliqués. Dans un environnement LAN typique avec un temps de réponse aller-retour (RTT) d’environ 100 microsecondes, où les retransmissions TCP nécessitent au moins un RTT, une retransmission se produisant à seulement 1/100 du RTT indique probablement une capture de paquets dupliqués plutôt qu’une retransmission par timeout réelle.
Cas classique 2
Un autre cas classique illustre l’importance du raisonnement logique dans l’analyse des problèmes réseau.
Un jour, un développeur commercial est venu en courant, disant qu’un script programmé utilisant le middleware de base de données MySQL avait échoué dans les premières heures du matin sans réponse. En entendant parler du problème, j’ai vérifié les journaux d’erreurs du middleware de base de données MySQL mais n’ai trouvé aucun indice précieux. Alors, j’ai demandé aux développeurs s’ils pouvaient reproduire le problème, sachant qu’une fois reproductible, un problème devient plus facile à résoudre.
Les développeurs ont essayé plusieurs fois de reproduire le problème mais n’ont pas réussi. Cependant, ils ont fait une nouvelle découverte : ils ont constaté qu’exécuter les mêmes requêtes SQL pendant la journée entraînait des temps de réponse différents par rapport au début de la matinée. Ils soupçonnaient que lorsque la réponse SQL était lente, le middleware de base de données MySQL bloquait la session et ne renvoyait pas de résultats au client.
Sur la base de cette idée, l’équipe des opérations de base de données a été chargée de modifier le SQL du script pour simuler une réponse SQL lente. En conséquence, le middleware de base de données MySQL a renvoyé les résultats sans rencontrer le problème de blocage observé dans les premières heures du matin.
Pendant un certain temps, la cause profonde n’a pas pu être identifiée, et les développeurs ont découvert un problème fonctionnel avec le middleware de base de données MySQL. Par conséquent, les développeurs et les opérations DBA sont devenus plus convaincus que le middleware de base de données MySQL retardait les réponses. En réalité, ces problèmes n’étaient pas liés aux temps de réponse du middleware de base de données MySQL.
À partir des événements du premier jour, le problème s’est effectivement produit. Tous les intervenants ont essayé de déterminer la cause, faisant diverses suppositions, mais la véritable raison est restée insaisissable.
Le lendemain, les développeurs ont signalé que le problème de script était réapparu tôt le matin, mais ils n’ont pas pu le reproduire pendant la journée. Se sentant sous pression car le script devait bientôt être utilisé en ligne, les développeurs se sont plaints de la situation. Ma seule suggestion était qu’ils utilisent le script pendant la journée pour éviter les problèmes tôt le matin. Toutes les suspicions étant concentrées sur le middleware de base de données MySQL, il était difficile d’analyser le problème sous d’autres angles.
En tant que développeur responsable du middleware de base de données MySQL, de tels problèmes mystérieux ne peuvent pas être facilement négligés. Les ignorer pourrait affecter l’utilisation ultérieure du middleware de base de données MySQL, et il y a aussi une pression de la direction pour résoudre rapidement le problème. Finalement, il a été décidé de mettre en place une solution d’analyse de capture de paquets à faible coût : pendant l’exécution du script tôt le matin, des captures de paquets seraient effectuées sur le serveur pour analyser ce qui se passait à ce moment-là. L’objectif était de déterminer si le middleware de base de données MySQL n’envoyait pas du tout de réponse ou s’il envoyait une réponse que le script client ne recevait pas. Une fois qu’il serait confirmé que le middleware de base de données MySQL avait bien envoyé une réponse, le problème ne serait pas attribué aux développeurs du middleware de base de données MySQL.
Le troisième jour, les développeurs ont signalé que le problème du petit matin ne s’était pas reproduit, et l’analyse de la capture de paquets a confirmé que le problème ne s’était pas produit. Après mûre réflexion, il semblait improbable que le problème soit uniquement lié au middleware de la base de données MySQL : les occurrences fréquentes tôt le matin et les occurrences rares en journée étaient déconcertantes. La seule action à entreprendre était d’attendre que le problème se reproduise et de l’analyser en se basant sur les captures de paquets.
Le quatrième jour, le problème n’est pas réapparu.
Cependant, le cinquième jour, le problème est finalement réapparu, donnant de l’espoir pour sa résolution.
Les fichiers de capture de paquets sont nombreux. Tout d’abord, demandez aux développeurs de fournir l’horodatage du problème, puis recherchez à travers les données étendues de capture de paquets pour identifier la requête SQL qui a causé le problème. Le résultat final est le suivant :
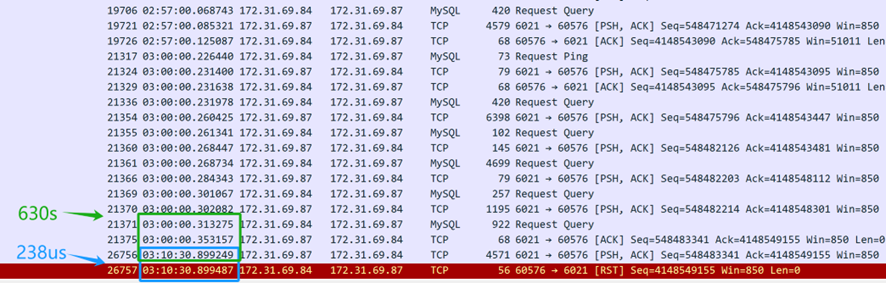
D’après le contenu de la capture de paquets ci-dessus (capturé depuis le serveur), il apparaît que la requête SQL a été envoyée à 3 heures du matin. Le middleware de la base de données MySQL a pris 630 secondes (03:10:30.899249-03:00:00.353157) pour renvoyer la réponse SQL au client, indiquant que le middleware de la base de données MySQL a effectivement répondu à la requête SQL. Cependant, seulement 238 microsecondes plus tard (03:10:30.899487-03:10:30.899249), la couche TCP du serveur a reçu un paquet de réinitialisation, ce qui était suspectement rapide. Il est important de noter que ce paquet de réinitialisation ne peut pas être immédiatement supposé provenir du client.
Tout d’abord, il est nécessaire de confirmer qui a envoyé le paquet de réinitialisation — soit c’était envoyé par le client, soit par un dispositif intermédiaire en cours de route. Étant donné que la capture de paquets a été réalisée uniquement du côté du serveur, les informations sur la situation des paquets du client ne sont pas disponibles. En analysant les fichiers de capture de paquets du côté du serveur et en appliquant un raisonnement logique, l’objectif est d’identifier la cause profonde du problème.
Si l’on suppose que le client a envoyé une réinitialisation, cela impliquerait que la couche TCP du client ne reconnaît plus l’état TCP de cette connexion — passant d’un état établi à un état inexistant. Ce changement d’état TCP notifierait l’application cliente d’un problème de connexion, entraînant une erreur immédiate dans le script client. Cependant, en réalité, le script client attend toujours que la réponse revienne. Par conséquent, l’hypothèse selon laquelle le client a envoyé une réinitialisation n’est pas valide — le client n’a pas envoyé de réinitialisation. La connexion du client est toujours active, mais du côté du serveur, la connexion correspondante a été terminée par la réinitialisation.
Qui a donc envoyé la réinitialisation ? Le principal suspect est l’environnement cloud d’Amazon. Sur la base de cette analyse de capture de paquets, les opérations DBA ont interrogé le service client d’Amazon et ont reçu les informations suivantes :
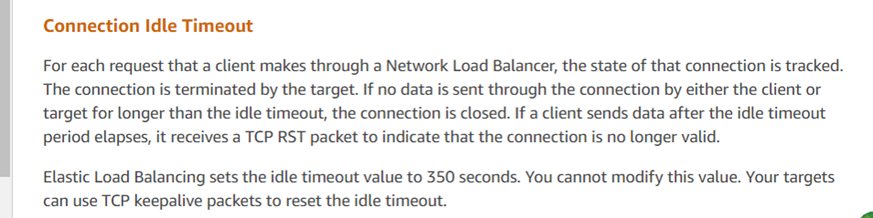
La réponse du service client concorde avec les résultats de l’analyse, indiquant que l’ELB d’Amazon (Elastic Load Balancer, similaire à LVS) a mis fin de force à la session TCP. Selon leurs retours, si une réponse dépasse le seuil de 350 secondes (tel qu’observé dans la capture de paquets à 630 secondes), le dispositif ELB d’Amazon envoie un reset à la partie répondante (dans ce cas, le serveur). Les scripts clients déployés par les développeurs n’ont pas reçu le reset et ont erronément supposé que la connexion au serveur était toujours active. Les recommandations officielles pour de tels problèmes incluent l’utilisation de mécanismes de maintien de la connexion TCP pour atténuer ces problèmes.
Avec la réponse officielle obtenue, le problème a été considéré comme entièrement résolu.
Ce cas spécifique illustre comment les problèmes en ligne peuvent être très complexes, nécessitant la capture d’informations critiques — dans ce cas, des données de capture de paquets — pour comprendre la situation telle qu’elle s’est produite. Grâce au raisonnement logique et à l’application du reductio ad absurdum, la cause profonde a été identifiée.
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems