













Apprendre Linux est l’une des compétences les plus précieuses de l’industrie technique. Elle peut vous aider à accomplir vos tâches plus rapidement et plus efficacement. Beaucoup des serveurs les plus puissants et des supercalculateurs du monde fonctionnent avec Linux.
En vous dotant pour votre rôle actuel, l’apprentissage de Linux peut également vous aider à passer à d’autres carrières techniques telles que DevOps, Cybersécurité et Cloud Computing.
Dans ce manuel, vous apprendrez les bases de la ligne de commande Linux, puis passerás aux sujets plus avancés tels que le scripting shell et l’administration système. Que vous soyez nouveau en Linux ou que vous l’ayez utilisé pendant des années, ce livre contient quelque chose pour vous.
Note importante : Tous les exemples dans ce livre sont présentés sous Ubuntu 22.04.2 LTS (Jammy Jellyfish). La plupart des outils de ligne de commande sont relativement les mêmes dans d’autres distributions. Cependant, certaines applications graphiques et commandes peuvent différer si vous travaillez sur une autre distribution Linux.
Table des matières
-
Partie 2 : Introduction à la console Bash et aux commandes système
-
Partie 5 : Les fondamentaux de l’édition de texte sous Linux
Partie 1 : Introduction à Linux
1.1. Commencer avec Linux
Qu’est-ce que Linux ?
Linux est un système d’exploitation open source basé sur le système d’exploitation Unix. Il a été créé par Linus Torvalds en 1991.
Open source signifie que le code source du système d’exploitation est accessible au public. Cela permet à anyone de modifier le code original, de le personnaliser, et de distribuer le nouveau système d’exploitation à des utilisateurs potentiels.
Pourquoi devriez-vous apprendre sur Linux ?
Dans le paysage actuel des centres de données, Linux et Microsoft Windows sont les principaux concurrents, avec Linux dominant nettement.
Voici plusieurs raisons convaincantes d’apprendre Linux :
-
Compte tenu de la prévalence du hébergement Linux, il est fort probable que votre application sera hébergée sur Linux. Donc, apprendre Linux en tant que développeur devient de plus en plus précieux.
-
Avec la montée en flèche du cloud computing, il est très probable que vos instances cloud dépendront de Linux.
-
Linux sert de fondation pour de nombreux systèmes d’exploitation pour les objets connectés (IoT) et les applications mobiles.
-
Dans le domaine de l’IT, il y a de nombreuses opportunités pour ceux qui sont compétents en Linux.
Qu’est-ce que signifie que Linux est un système d’exploitation open source ?
Premièrement, qu’est-ce que le logiciel open source ? Le logiciel open source est un logiciel dont le code source est accessible librement, permettant à toute personne de l’utiliser, de le modifier et de le distribuer.
Chaque fois que du code source est créé, il est automatiquement considéré comme protégé par le droit d’auteur, et sa distribution est régie par le titulaire des droits d’auteur par l’intermédiaire de licences de logiciel.
En revanche, à la différence du logiciel open source, le logiciel privé ou de source fermée restreint l’accès à son code source. Seuls les créateurs peuvent le voir, le modifier ou le distribuer.
Linux est principalement open source, ce qui signifie que son code source est librement disponible. Toute personne peut le voir, le modifier et le distribuer. Les développeurs du monde entier peuvent contribuer à son amélioration. Cela pose les bases de la collaboration qui est une importante caractéristique du logiciel open source.
Cette approche collaborative a conduit à l’adoption large de Linux sur les serveurs, les ordinateurs de bureau, les systèmes embarqués et les appareils mobiles.
L’aspect le plus intéressant de Linux étant open source est que n’importe qui peut adapter le système d’exploitation à leurs besoins spécifiques sans être limité par les limitations de logiciel privé.
Chrome OS utilisé par les Chromebooks est basé sur Linux. Android, qui anime de nombreux smartphones dans le monde, est également basé sur Linux.
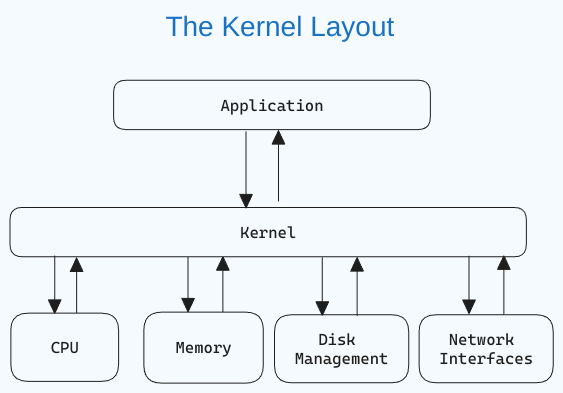
Qu’est-ce qu’un noyau Linux ?
Le noyau est le composant central d’un système d’exploitation qui gère les opérations de l’ordinateur et de son matériel. Il gère les opérations de mémoire et le temps CPU.
Le noyau agit en tant que pont entre les applications et le niveau matériel de traitement des données par l’intermédiaire de la communication inter-processus et des appels système.
Le noyau est chargé en mémoire premièrement lorsque le système d’exploitation démarre et reste là jusqu’à ce que le système soit arrêté. Il est responsable de tâches telles que la gestion du disque, la gestion des tâches et la gestion de la mémoire.
Si vous êtes curieux de savoir comment le noyau Linux ressemble, voici le lien GitHub.
Qu’est-ce qu’une distribution Linux ?
À ce stade, vous savez que vous pouvez réutiliser le code du noyau Linux, le modifier et créer un nouveau noyau. Vous pouvez également combiner différentes utilitaires et logiciels pour créer un système d’exploitation entièrement nouveau.
Une distribution Linux, ou distro, est une version du système d’exploitation Linux qui inclut le noyau Linux, des utilitaires systèmes et d’autres logiciels. En étant open source, une distribution Linux est un effort collaboratif impliquant plusieurs communautés indépendantes de développement open source.
Qu’est-ce que signifie que une distribution est issue d’une autre ? Lorsque vous dites qu’une distribution est « issue » d’une autre, la nouvelle distribution est construite sur la base ou la structure de la distribution originale. Cette issue peut inclure l’utilisation du même système de gestion des paquets (plus sur cela plus tard), de la même version du noyau et parfois des mêmes outils de configuration.
Aujourd’hui, il y a des milliers de distributions Linux à choisir parmi, offrant des objectifs et des critères différents pour la sélection et le soutien du logiciel fourni par leur distribution.
Les distributions varient d’une à l’autre, mais elles ont généralement plusieurs caractéristiques communes :
-
Une distribution se compose d’un noyau Linux.
-
Elle permet le fonctionnement de programmes de l’espace utilisateur.
-
Une distribution peut être petite et destinée à une seule fin ou inclure des milliers de programmes open-source.
-
Il devrait être fourni quelque moyen pour installer et mettre à jour la distribution et ses composants.
Si vous consultez la Timeline des Distributions Linux, vous verrez deux grandes distributions : Slackware et Debian. Plusieurs distributions en sont issues, par exemple Ubuntu et Kali, qui sont issues de Debian.
Quelles sont les avantages de cette dérivation ? Il existe plusieurs avantages à la dérivation. Les distributions dérivées peuvent tirer parti de la stabilité, de la sécurité et des grandes dépôts de logiciels de la distribution parentale.
Lors de la construction sur une base existante, les développeurs peuvent concentrer leur focus et leur effort entièrement sur les fonctionnalités spécialisées de la nouvelle distribution. Les utilisateurs de distributions dérivées peuvent bénéficier de la documentation, de la support communautaire et des ressources déjà disponibles pour la distribution parentale.
Certaines distributions Linux populaires sont :
-
Ubuntu
: L’une des distributions Linux les plus utilisées et populaires. Elle est user-friendly et recommandée pour les débutants. En savoir plus sur Ubuntu ici.
-
Linux Mint : Basée sur Ubuntu, Linux Mint offre une expérience utilisateur-friendly avec un focus sur l’appui aux médias multimédias. En savoir plus sur Linux Mint ici.
-
Arch Linux : Populaire auprès d’utilisateurs expérimentés, Arch est une distribution légère et flexible destinée aux utilisateurs qui préfèrent une approche de bricolage. En savoir plus sur Arch Linux ici.
-
Manjaro: Basé sur Arch Linux, Manjaro offre une expérience utilisateur-friendly avec des logiciels pré-installés et des outils de gestion du système aisés. En savoir plus sur Manjaro ici.
-
Kali Linux: Kali Linux offre un ensemble complet d’outils de sécurité et se concentre principalement sur la cybersécurité et le hacking. En savoir plus sur Kali Linux ici.
Comment installer et accéder au Linux
La meilleure façon d’apprendre est de mettre en pratique les concepts au fur et à mesure. Dans cette section, nous apprendrons comment installer Linux sur votre machine afin que vous puissiez suivre. Vous apprendrez également comment accéder au Linux sur un ordinateur Windows.
Je vous recommande de suivre l’une des méthodes mentionnées dans cette section pour accéder au Linux afin que vous puissiez suivre.
Installer Linux en tant que système d’exploitation principal
Installer Linux en tant que système d’exploitation principal est la méthode la plus efficace pour utiliser Linux, car vous pouvez utiliser la pleine puissance de votre machine.
Dans cette section, vous apprendrez comment installer Ubuntu, qui est l’une des distributions Linux les plus populaires. J’ai omis d’aborder d’autres distributions pour le moment, afin de conserver la simplicité. Vous pouvez explorer d’autres distributions une fois que vous serez à l’aise avec Ubuntu.
-
Étape 1 – Télécharger le fichier ISO d’Ubuntu : Allez sur le site web officiel et téléchargez le fichier ISO. Assurez-vous de sélectionner une version stable étiquetée « LTS ». LTS signifie Long Term Support, ce qui veut dire que vous pouvez recevoir gratuitement des mises à jour de sécurité et de maintenance pendant une longue période (habituellement 5 ans).
-
Étape 2 – Créer une clé USB bootable : Il existe de nombreuses softwares qui permettent de créer une clé USB bootable. Je recommande l’utilisation de Rufus, car il est assez simple à utiliser. Vous pouvez le télécharger à ici.
-
Étape 3 – Démarrez à partir de la clé USB : Une fois votre clé USB bootable prête, insérez-la et démarrez à partir de la clé USB. Le menu de démarrage dépend de votre ordinateur portable. Vous pouvez rechercher sur Google le menu de démarrage pour le modèle de votre ordinateur portable.
-
Étape 4 – Suivez les instructions. Une fois le processus de démarrage lancé, sélectionnez
essayer ou installer ubuntu.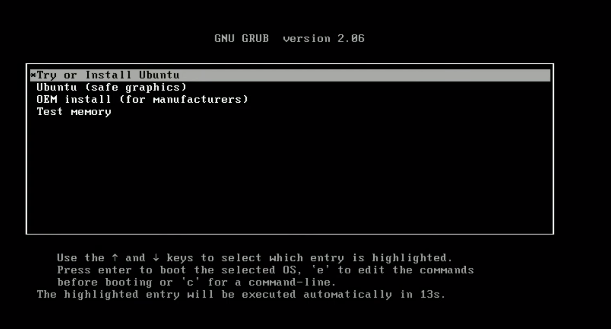
Le processus prendra un certain temps. Une fois l’interface graphique apparue, vous pouvez sélectionner la langue, la disposition du clavier et continuer. Entrez votre identifiant et votre nom. N’oubliez pas vos identifiants car vous en aurez besoin pour vous connecter à votre système et accéder à tous les privilèges. Attendez la fin de l’installation.
-
Étape 5 – Redémarrez : Cliquez sur redémarrer maintenant et retirez la clé USB.
-
Étape 6 – Connexion : Connectez-vous en utilisant les identifiants que vous avez entrés plus tôt.
Et voilà ! Maintenant, vous pouvez installer des applications et personnaliser votre bureau.

Pour une installation avancée, vous pouvez explorer les sujets suivants :
-
Le partitionnement du disque.
-
Configurer la mémoire de swap pour activer le mode hibernation.
Accéder au terminal
Une partie importante de ce guide est de savoir à propos du terminal où vous allez exécuter toutes les commandes et où les choses se passent magiquement. Vous pouvez rechercher le terminal en appuyant sur la touche « Windows » et en tapant « Terminal ». Vous pouvez coller le Terminal dans la docke où se trouvent d’autres applications pour un accès facile.
💡 La raccourci pour ouvrir le terminal est
ctrl+alt+t
Vous pouvez également ouvrir le terminal à l’intérieur d’un dossier. Cliquez droit où vous êtes et cliquez sur « Ouvrir dans le Terminal ». Cela ouvrira le terminal dans le même chemin.
Comment utiliser Linux sur une machine Windows
Il arrive parfois que vous ayez besoin d’exécuter à la fois Linux et Windows côte à côte. Heureusement, il existe plusieurs moyens de profiter des deux mondes sans avoir besoin d’ordinateurs différents pour chaque système d’exploitation.
Dans cette section, vous explorerez plusieurs méthodes pour utiliser Linux sur une machine Windows. Certaines sont basées sur le navigateur ou sur le cloud et n’ont pas besoin d’installation de système d’exploitation avant d’être utilisées.
Option 1 : « Dual-boot » Linux + Windows Avec un double démarrage, vous pouvez installer Linux à côté de Windows sur votre ordinateur, ce qui vous permet de choisir quelle système d’exploitation utiliser au démarrage.
Cela nécessite de partitionner votre disque dur et d’installer Linux sur une partition distincte. Avec cette approche, vous ne pouvez utiliser qu’un seul système d’exploitation à la fois.
Option 2 : Utilisez le Windows Subsystem for Linux (WSL) Le Windows Subsystem for Linux fournit une couche de compatible qui permet de faire fonctionner nativement les exécutables binaires Linux sous Windows.
Utiliser WSL offre quelques avantages. La configuration pour WSL est simple et ne prend pas beaucoup de temps. Elle est légère en comparaison avec les VM où vous devez affecter des ressources à l’ordinateur hôte. Vous n’avez pas besoin d’installer d’ISO ou de disque virtuel pour les machines Linux, qui tendent généralement à être de gros fichiers. Vous pouvez utiliser Windows et Linux côte à côte.
Comment installer WSL2
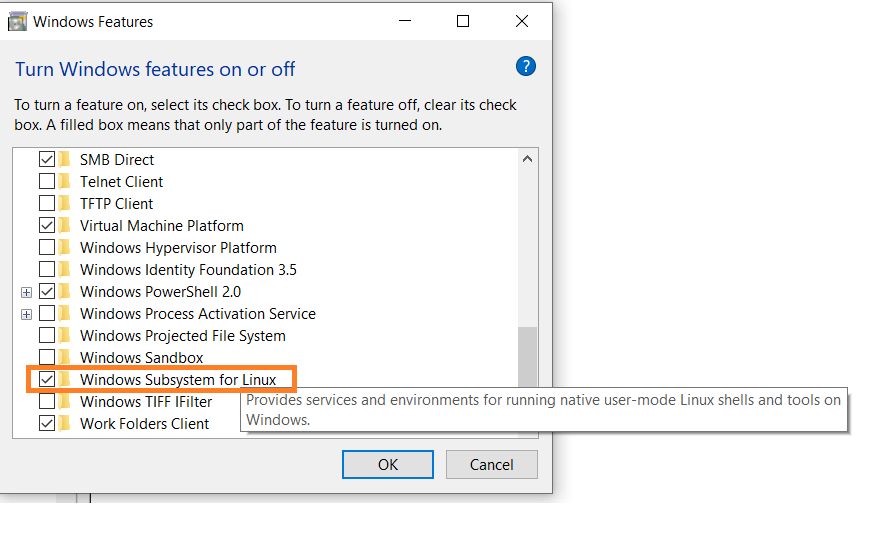
Tout d’abord, activez l’option Windows Subsystem for Linux dans les paramètres.
-
Allez à Démarrer. Recherchez « Activer ou désactiver les fonctionnalités Windows. »
-
Cochez l’option « Windows Subsystem for Linux » si elle n’est pas déjà cochée.
-
Ensuite, ouvrez votre terminal et fournissez les commandes d’installation.
-
Ouvrir le Prompt de commandes en tant que administrateur :

-
Exécuter la commande ci-dessous :
wsl --install
Ceci est la sortie :
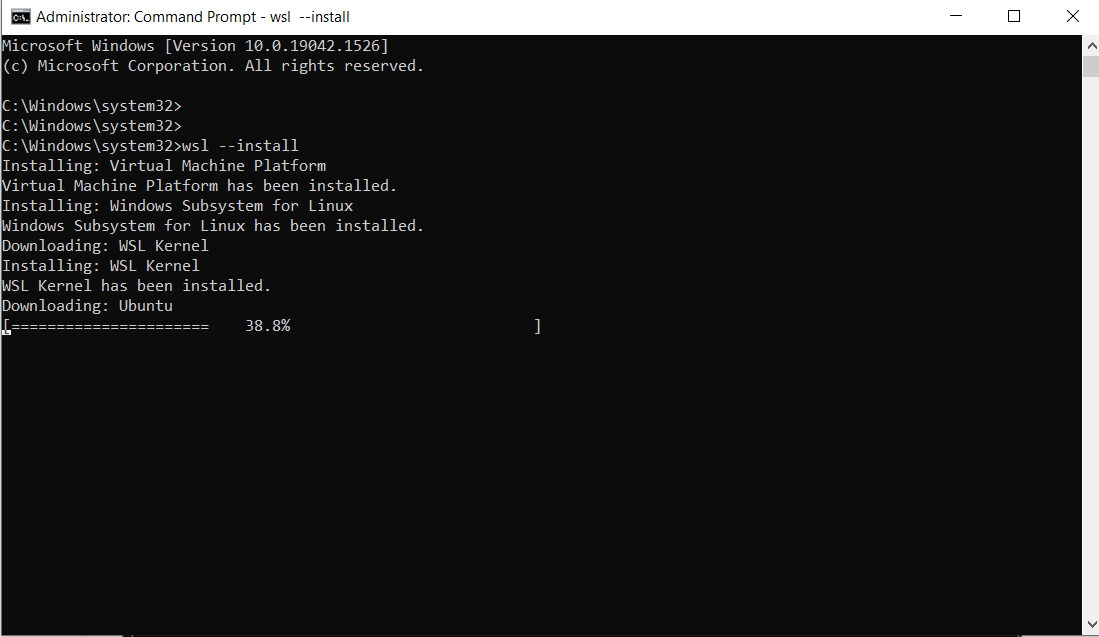
Remarque : Par défaut, Ubuntu sera installé.
- Une fois l’installation terminée, vous devrez redémarrer votre machine Windows. Donc, redémarrez votre machine Windows.
Après le redémarrage, vous pourriez voir une fenêtre comme celle-ci :
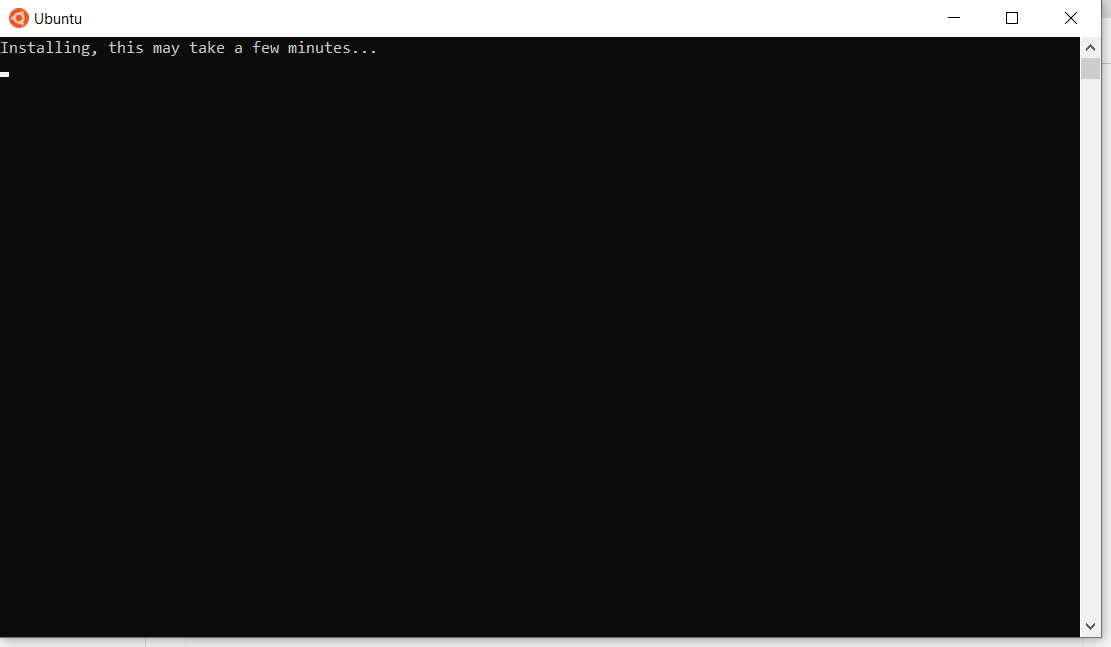
Une fois l’installation d’Ubuntu terminée, vous serez invité à entrer votre nom d’utilisateur et votre mot de passe.

Et, voilà ! Vous êtes prêt à utiliser Ubuntu.
Lancez Ubuntu en cherchant dans le menu Démarrer.
Et voici que vous avez lancé votre instance d’Ubuntu.

Option 3 : Utiliser une Machine Virtuelle (VM)
Une machine virtuelle (VM) est une emulation logicielle d’un système d’exploitation physique. Elle permet de faire fonctionner plusieurs systèmes d’exploitation et applications simultanément sur une seule machine physique.
Vous pouvez utiliser des logiciels de virtualisation tels que Oracle VirtualBox ou VMware pour créer une machine virtuelle exécutant Linux dans votre environnement Windows. Cela vous permet de faire fonctionner Linux en tant que système d’exploitation invité en parallèle avec Windows.
Le logiciel de VM offre des options pour allouer et gérer les ressources matériels pour chaque VM, incluant les cœurs CPU, la mémoire, l’espace disque et la bande passante réseau. Vous pouvez ajuster ces allocations en fonction des besoins des systèmes d’exploitation invités et des applications.
Voici certaines des options courantes disponibles pour la virtualisation :
Option 4 : Utiliser une Solution Basée sur le Navigateur
Les solutions basées sur le navigateur sont particulièrement utiles pour les tests rapides, l’apprentissage ou l’accès aux environnements Linux à partir d’appareils qui ne disposent pas de Linux installé.
Vous pouvez utiliser des éditeurs de code en ligne ou des terminaux basés sur le web pour accéder à Linux. Notez que généralement, vous n’avez pas les privilèges d’administration complète dans ces cas.
Editeurs de code en ligne
Les éditeurs de code en ligne offrent des éditeurs avec des terminaux Linux intégrés. Bien que leur principal objectif soit de coder, vous pouvez également utiliser le terminal Linux pour exécuter des commandes et effectuer des tâches.
Replit est un exemple d’éditeur de code en ligne, où vous pouvez écrire votre code et accéder à la console Linux en même temps.
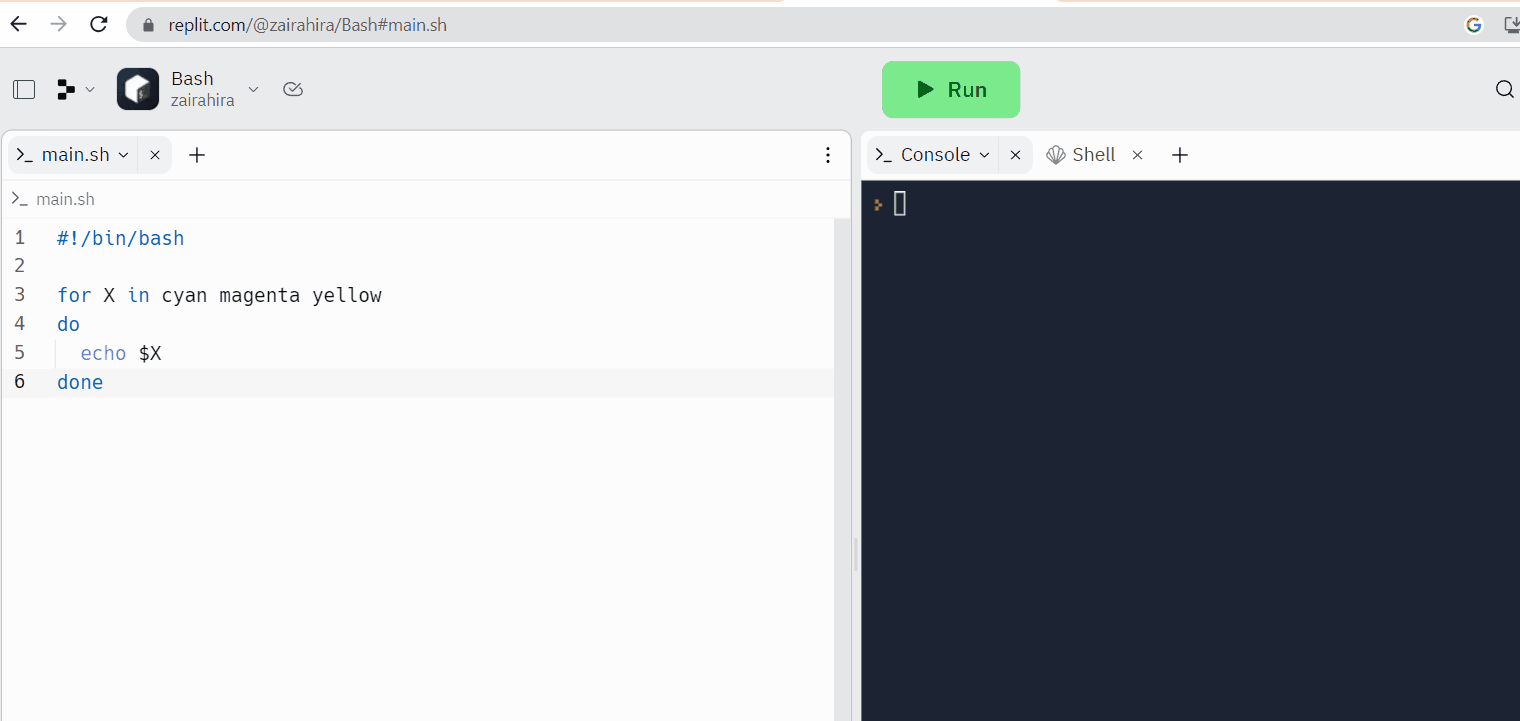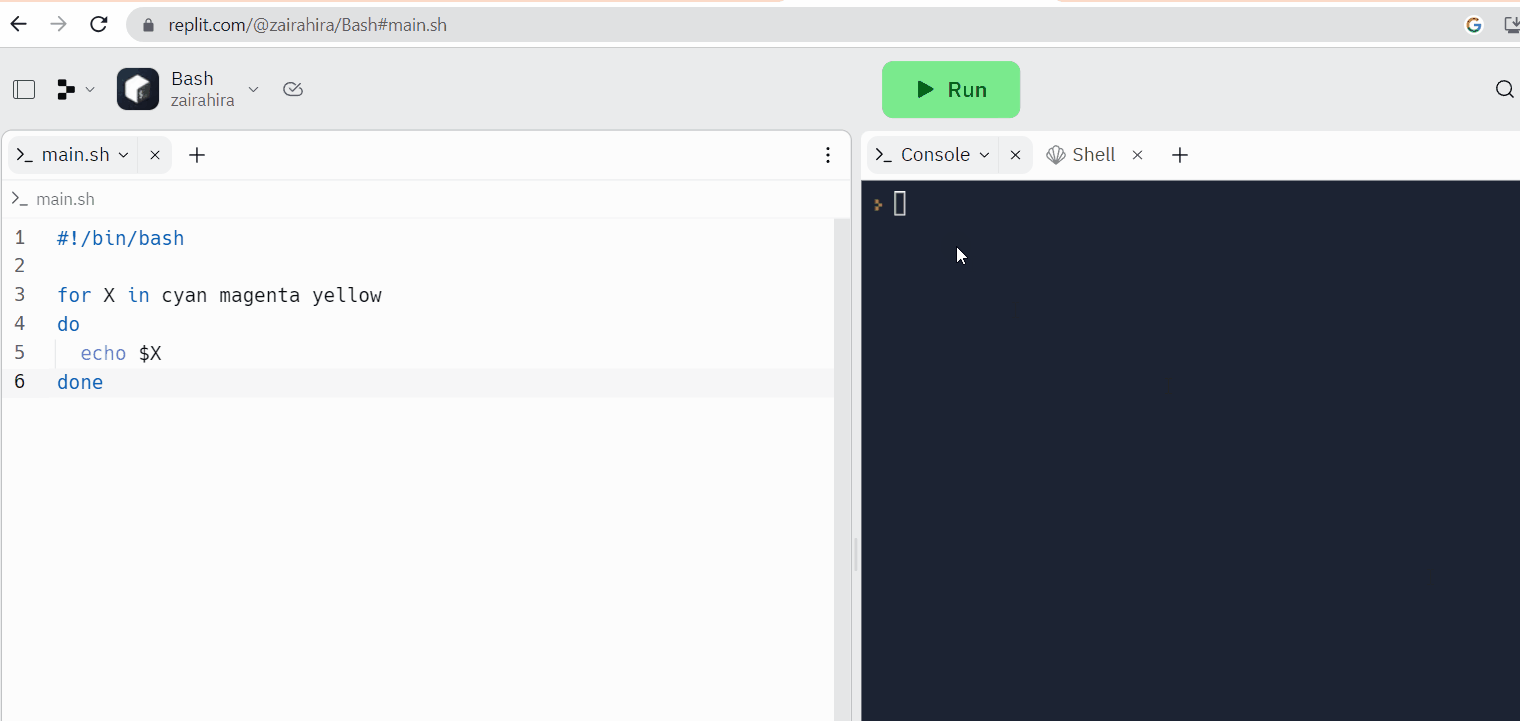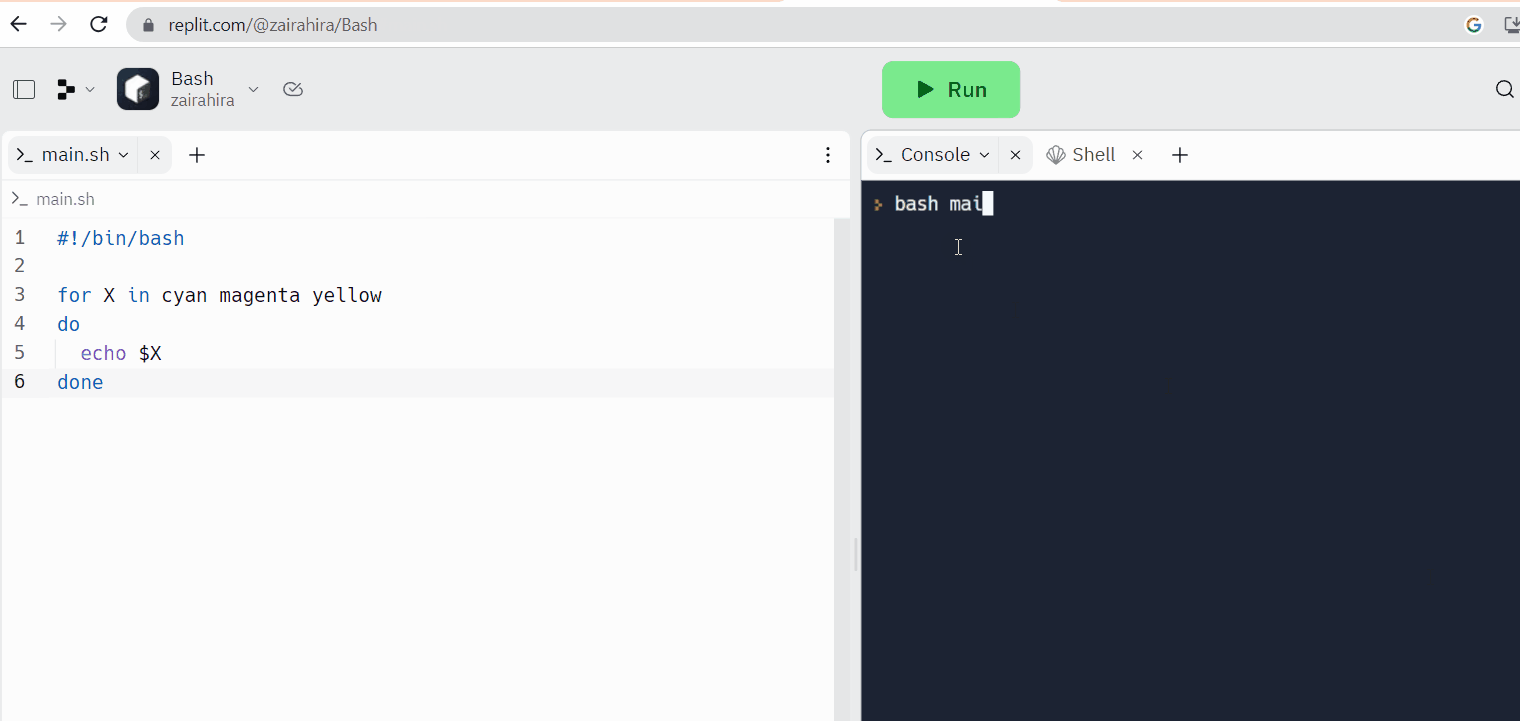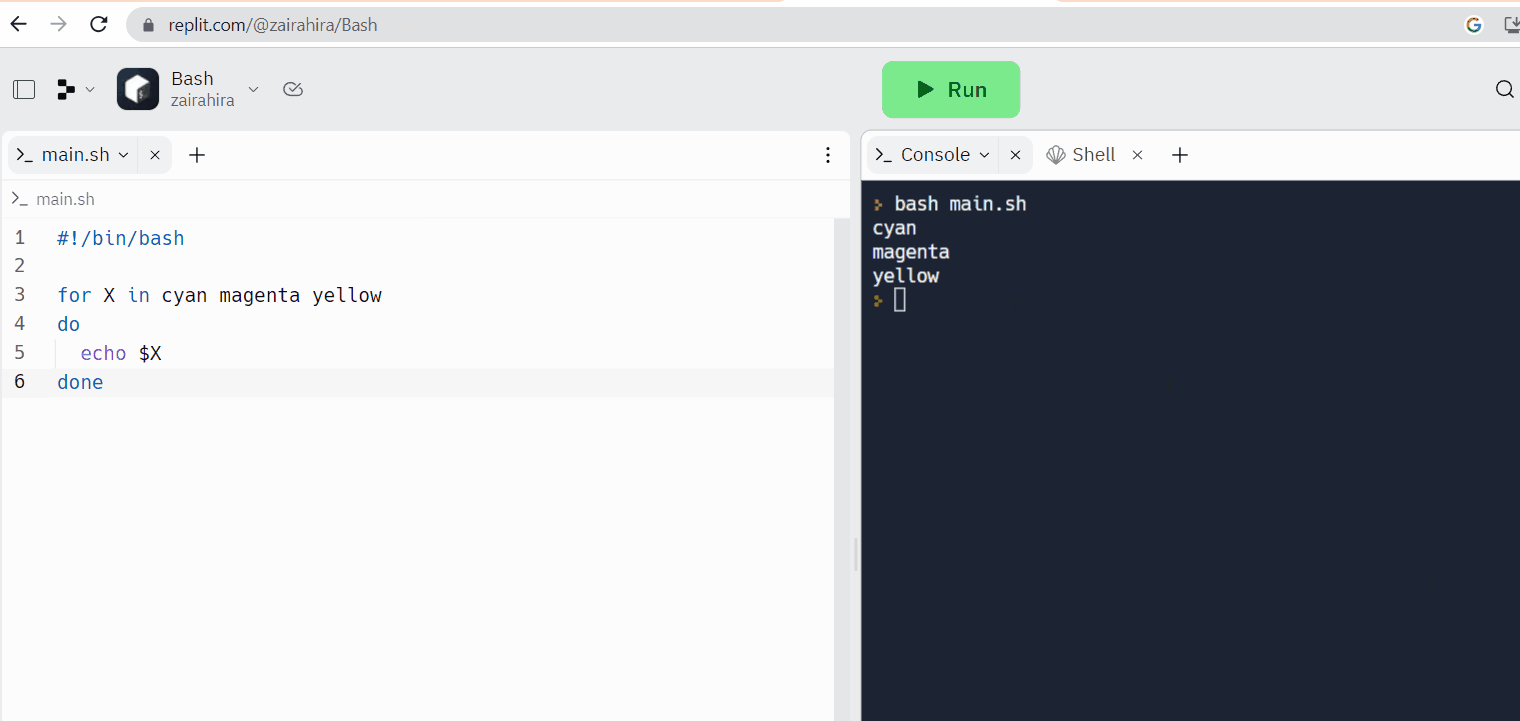
Terminaux Linux en ligne :
Les terminaux Linux en ligne vous permettent d’accéder à une interface de ligne de commande Linux directement depuis votre navigateur. Ces terminaux offrent une interface Web pour une console Linux, ce qui vous permet d’exécuter des commandes et de travailler avec les utilitaires Linux.
Un exemple de ce genre est JSLinux. L’image ci-dessous montre un environnement Linux prêt à l’utiliser :
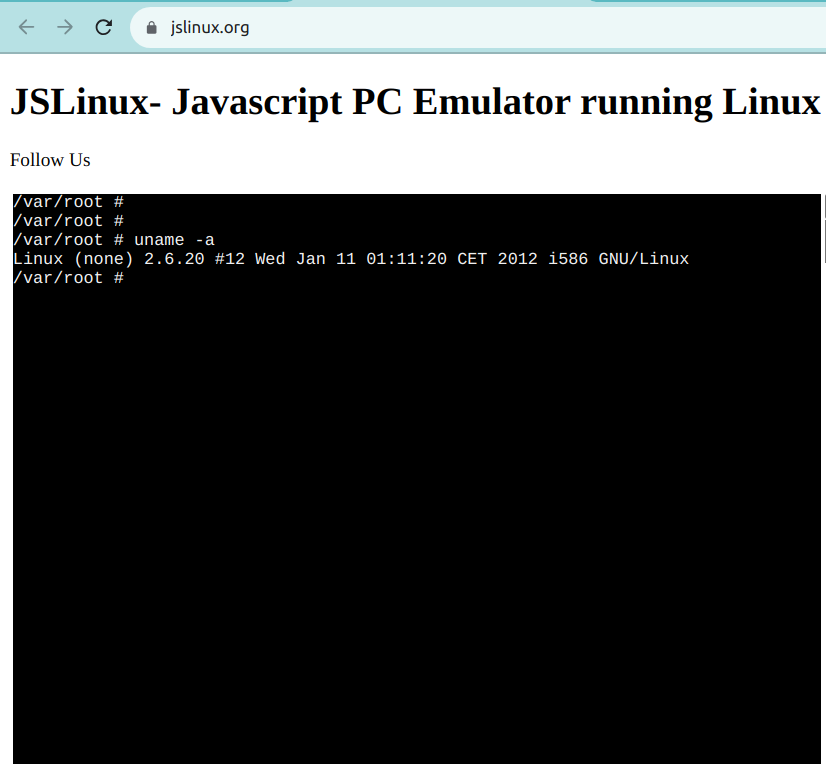
Option 5 : Utiliser une solution cloud
Plutôt que de faire tourner Linux directement sur votre machine Windows, vous pouvez envisager d’utiliser des environnements Linux cloud ou des serveurs virtuels privés (VPS) pour accéder et travailler avec Linux à distance.
Des services tels que Amazon EC2, Microsoft Azure ou DigitalOcean fournissent des instances Linux que vous pouvez connecter à partir de votre ordinateur Windows. Notez que certains de ces services offrent des niveaux gratuits, mais ils ne sont généralement pas gratuits à long terme.
Partie 2 : Introduction à la Console Bash et aux Commands Systèmes
2.1. Démarrage avec la console Bash
Introduction à la console Bash
La ligne de commande Linux est fournie par un programme appelé la shell. Au fil des ans, le programme shell a évolué pour répondre à diverses options.
Les utilisateurs différents peuvent être configurés pour utiliser différentes shells. Cependant, la plupart des utilisateurs préfèrent rester avec la shell par défaut actuelle. La shell par défaut pour de nombreuses distributions Linux est la GNU Bourne-Again Shell (bash). Bash succède à la Bourne shell (sh).
Pour savoir quelle est votre shell actuel, ouvrez votre terminal et entrez la commande suivante :
echo $SHELL
Analyse de la commande :
-
La commande
echoest utilisée pour afficher sur le terminal. -
La variable spéciale
$SHELLcontient le nom de la shell actuelle.
Dans mon configuration, la sortie est /bin/bash. Cela signifie que je utilise la shell bash.
# sortie
echo $SHELL
/bin/bash
Bash est très puissant car il peut simplifier certaines opérations difficiles à accomplir efficacement avec une interface graphique (ou IGU). Rappelez-vous que la plupart des serveurs n’ont pas d’IGU et qu’il est préférable d’apprendre à utiliser les pouvoirs d’une interface en ligne de commande (CLI).
Terminal vs Shell
Les termes « terminal » et « shell » sont souvent utilisés interchangeablement, mais ils se réfèrent à des parties différentes de l’interface en ligne de commande.
Le terminal est l’interface que vous utilisez pour interagir avec la console. La console est l’interpréteur de commandes qui traite et exécute vos commandes. Vous apprendrez davantage sur les consoles dans la Partie 6 du guide.
Qu’est-ce qu’un prompt ?
Lorsque une console est utilisée interactivement, elle affiche un $ lorsqu’elle attend une commande de l’utilisateur. Cela s’appelle le prompt de la console.
[username@host ~]$
Si la console est exécutée en tant que root (vous apprendrez davantage sur l’utilisateur root plus tard), le prompt est changé en #.
[root@host ~]#
2.2. Structure d’une commande
Une commande est un programme qui effectue une opération spécifique. Une fois que vous avez accès à la console, vous pouvez entrer n’importe quelle commande après le signe $ et voir la sortie sur le terminal.
Généralement, les commandes Linux suivent ce schéma :
command [options] [arguments]
Voici la décomposition du schéma précédent :
-
command: C’est le nom de la commande que vous voulez exécuter.ls(liste),cp(copie) etrm(suppression) sont des commandes communes de Linux. -
[options]
: Les options, ou drapeaux, sont souvent précédés d’un tiret (-) ou d’un double tiret (–) et modifient le comportement de la commande. Ils peuvent changer la manière dont la commande fonctionne. Par exemple,
ls -autilise l’option
-apour afficher les fichiers cachés dans le répertoire courant. -
[arguments]
: Les arguments sont les entrées pour les commandes qui en ont besoin. Cela pourrait être des noms de fichiers, des noms d’utilisateurs ou d’autres données sur lesquelles la commande agira. Par exemple, dans la commande
cat access.log,
catest la commande etaccess.logest l’entrée. Par conséquent, la commandecataffiche le contenu du fichieraccess.log.
Les options et les arguments ne sont pas requis pour toutes les commandes. Certaines commandes peuvent être exécutées sans aucune option ou argument, tandis que d’autres peuvent nécessiter l’une ou les deux pour fonctionner correctement. Vous pouvez toujours vous référer au manuel de la commande pour vérifier les options et arguments qu’il supporte.
💡Astuce : Vous pouvez consulter le manuel d’une commande en utilisant la commande man.
Vous pouvez accéder à la page de manuel de la commande ls en tapant man ls, et ça ressemblera à ceci :

Les pages de manuel sont un excellent moyen rapide de accéder à la documentation. Je recommande vivement d’aller chercher dans les pages de manuel pour les commandes que vous utilisez le plus.
2.3. Commandes Bash et touches de raccourci
Lorsque vous êtes dans le terminal, vous pouvez accélérer vos tâches en utilisant des raccourcis.
Voici quelques des raccourcis les plus communs du terminal :
| Opération | Raccourci |
| Rechercher la commande précédente | Flèche haute |
| Aller au début de la mot précédent | Ctrl+Flèche gauche |
| Effacer les caractères du curseur à la fin de la ligne de commande | Ctrl+K |
| Completer les commandes, les noms de fichiers et les options | Appuyer sur Tab |
| Aller au début de la ligne de commande | Ctrl+A |
| Afficher la liste des commandes précédentes | history |
2.4. Identifiant Vous-Même : La commande whoami
Vous pouvez obtenir le nom d’utilisateur avec lequel vous êtes connecté en utilisant la commande whoami. Cette commande est utile lorsque vous changez entre différents utilisateurs et que vous voulez confirmer l’utilisateur actuel.
Juste après le signe $, tapez whoami et appuyez sur Entrée.
whoami
C’est ce que j’ai obtenu comme sortie.
zaira@zaira-ThinkPad:~$ whoami
zaira
Partie 3 : Comprendre votre système Linux
3.1. Découvrir votre OS et les spécifications
Afficher des informations système à l’aide de la commande uname
Vous pouvez obtenir des informations système détaillées à l’aide de la commande uname.
Lorsque vous fournissez l’option -a, elle affiche toutes les informations système.
uname -a
# output
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
Dans l’affichage ci-dessus,
-
Linux: Indique le système d’exploitation. -
zaira: représente le nom d’hôte de la machine. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2: Fournit des informations sur la version du noyau, la date de construction et d’autres détails supplémentaires. -
x86_64 x86_64 x86_64: Indique l’architecture du système. -
GNU/Linux: représente le type de système d’exploitation.
Découvrez les détails de l’architecture du CPU en utilisant la commande lscpu
La commande lscpu sous Linux est utilisée pour afficher des informations sur l’architecture du CPU. Lorsque vous exécutez lscpu dans le terminal, elle fournit des détails tels que :
-
L’architecture du CPU (par exemple, x86_64)
-
Mode(s) d’opération du CPU (par exemple, 32-bit, 64-bit)
-
Ordre des octets (par exemple, Little Endian)
-
Processeur(s) (nombre de CPUs), et ainsi de suite
Faisons un essai :
lscpu
# sortie
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Cela fut une quantité importante d’informations, mais utile également ! Rappelez-vous, vous pouvez toujours repérer les informations pertinentes en utilisant des drapeaux spécifiques. Consultez le manuel de la commande avec man lscpu.
Partie 4 : Gérer les fichiers depuis la ligne de commande
4.1. La hiérarchie du système de fichiers Linux
Tous les fichiers sous Linux sont stockés dans un système de fichiers. Ils suivent une structure en arbre inversé car la racine est située au sommet.
Le / est le répertoire racine et le point de départ du système de fichiers. Le répertoire racine contient tous les autres répertoires et fichiers du système. Le caractère / sert également de séparateur entre les noms de chemin. Par exemple, /home/alice forme un chemin complet.
Voici la traduction de ce texte en français :
L’image ci-dessous montre l’hierarchie complète du système de fichiers. Chaque répertoire a une finalité précise.
Notez que cette liste n’est pas exhaustive et que différentes distributions peuvent avoir des configurations différentes.
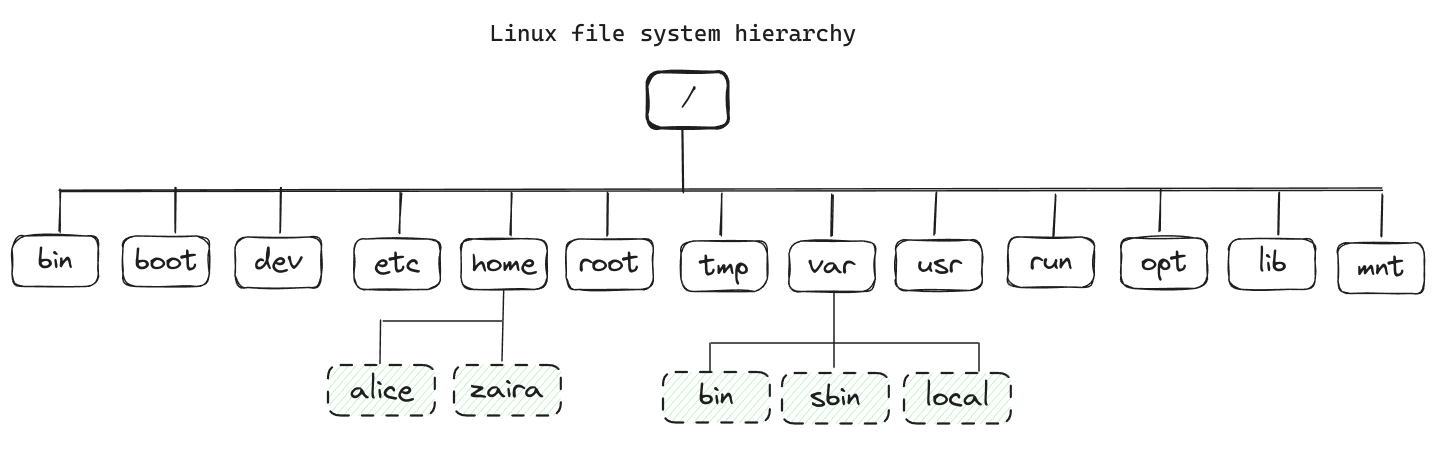
Voici un tableau montrant l’objet de chaque répertoire :
| Emplacement | Objectif |
| /bin | Binaries des commandes essentielles |
| /boot | Fichiers statiques du chargeur d’amorçage, nécessaires pour démarrer le processus d’amorçage. |
| /etc | Configuration spécifique à l’hôte du système |
| /home | Répertoires personnels des utilisateurs |
| /root | Répertoire personnel de l’utilisateur administratif root |
| /lib | Bibliothèques partagées essentielles et modules du noyau |
| /mnt | Point de montage pour monter un système de fichiers temporairement |
| /opt | Paquets d’applications externes |
| /usr | Logiciels installés et bibliothèques partagées |
| /var | Données variables persistantes entre les démarrages |
| /tmp | Fichiers temporaires accessibles à tous les utilisateurs |
💡 Truc : Vous pouvez en apprendre davantage sur le système de fichiers en utilisant la commande man hier.
Vous pouvez vérifier votre système de fichiers en utilisant la commande tree -d -L 1. Vous pouvez modifier le drapeau -L pour changer la profondeur de l’arbre.
tree -d -L 1
# output
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Cette liste n’est pas exhaustive et les différentes distributions et systèmes peuvent être configurés différemment.
4.2. Naviguer dans le système de fichiers Linux
Chemin absolu vs chemin relatif
Le chemin absolu est le chemin complet de la racine du dossier jusqu’au fichier ou dossier. Il commence toujours par un /. Par exemple, /home/john/documents.
Le chemin relatif, quant à lui, est le chemin du dossier courant jusqu’au fichier ou dossier de destination. Il ne commence pas par un /. Par exemple, documents/travail/projet.
Localiser votre dossier courant en utilisant la commande pwd
Il est facile de se perdre dans le système de fichiers Linux, surtout si vous êtes nouveau sur la ligne de commande. Vous pouvez localiser votre dossier courant en utilisant la commande pwd.
Voici un exemple :
pwd
# sortie
/home/zaira/scripts/python/free-mem.py
Changer de dossier en utilisant la commande cd
La commande pour changer de dossier est cd et elle signifie « change directory » (changer de dossier). Vous pouvez utiliser la commande cd pour naviguer vers un autre dossier.
Vous pouvez utiliser un chemin relatif ou un chemin absolu.
Par exemple, si vous voulez naviguer dans la structure de fichiers ci-dessous (en suivant les lignes rouges) :
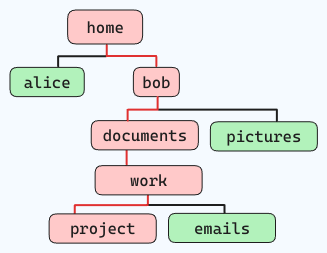
et que vous êtes situé dans « home », la commande serait comme cela :
cd home/bob/documents/work/project
Quelques raccourcis cd couramment utilisés sont les suivants :
| Commande | Description |
cd .. |
Revenir d’un répertoire |
cd ../.. |
Revenir de deux répertoires |
cd or cd ~ |
Aller au répertoire personnel |
cd - |
Aller à l’ancien chemin |
4.3. Gérer les fichiers et les répertoires
Lorsque vous trabaliez avec des fichiers et des répertoires, vous pourriez souhaiter les copier, les déplacer, les supprimer et créer de nouveaux fichiers et répertoires. Voici quelques commandes qui pourront vous aider à cet effet.
💡Astuce: Vous pouvez différencier un fichier d’un dossier en voyant la première lettre de l’affichage de ls -l. Un '-' représente un fichier et un 'd' représente un dossier.
Créer de nouveaux dossiers à l’aide de la commande mkdir
Vous pouvez créer un dossier vide en utilisant la commande mkdir.
# Crée un dossier vide nommé "foo" dans le dossier courant
mkdir foo
Vous pouvez également créer des dossiers récursivement en utilisant l’option -p.
mkdir -p tools/index/helper-scripts
# Sortie de l'application tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Créer de nouveaux fichiers à l’aide de la commande touch
La commande touch crée un fichier vide. Vous pouvez l’utiliser ainsi:
# Crée un fichier vide "file.txt" dans le dossier courant
touch file.txt
Les noms de fichiers peuvent être chainés ensemble si vous souhaitez créer plusieurs fichiers en une seule commande.
# Crée des fichiers vides "file1.txt", "file2.txt" et "file3.txt" dans le dossier courant
touch file1.txt file2.txt file3.txt
Suppression de fichiers et dossiers à l’aide des commandes rm et rmdir
Vous pouvez utiliser la commande rm pour supprimer à la fois des fichiers et des dossiers non vides.
| Commande | Description |
rm file.txt |
Supprime le fichier file.txt |
rm -r directory |
Supprime le dossier directory et son contenu |
rm -f file.txt |
Supprime le fichier file.txt sans demande de confirmation |
rmdir directory |
Supprime un dossier vide |
🛑 Notez que vous devriez utiliser le drapeau -f avec prudence car vous ne serez pas invité à confirmer la suppression d’un fichier. De plus, faites attention lors de l’exécution de commandes rm dans le dossier root car cela pourrait entraîner la suppression de fichiers système importants.
Copie de fichiers à l’aide de la commande cp
Pour copier des fichiers sous Linux, utilisez la commande cp.
- Syntaxe pour copier des fichiers :
cp source_file destination_du_fichier
Cette commande copie un fichier nommé file1.txt vers un nouvel emplacement /home/adam/logs.
cp file1.txt /home/adam/logs
La commande cp crée également une copie d’un fichier avec le nom fourni.
Ce commande copie un fichier nommé file1.txt vers un autre fichier nommé file2.txt dans le même dossier.
cp file1.txt file2.txt
Déplacer et renommer des fichiers et dossiers en utilisant le commande mv
Le commande mv est utilisée pour déplacer des fichiers et dossiers d’un dossier à un autre.
Syntaxe pour déplacer des fichiers :mv source_fichier destination_dossier
Exemple : Déplacer un fichier nommé file1.txt vers un dossier nommé backup :
mv file1.txt backup/
Pour déplacer un dossier et son contenu :
mv dir1/ backup/
Renommer des fichiers et dossiers sous Linux est également effectué avec le commande mv.
Syntaxe pour renommer des fichiers :mv ancien_nom nouveau_nom
Exemple : Renommer un fichier de file1.txt en file2.txt :
mv file1.txt file2.txt
Renommer un dossier de dir1 en dir2 :
mv dir1 dir2
4.4. Trouver des Fichiers et Dossiers en Utilisant la Commande find
La commande find vous permet de rechercher efficacement des fichiers, des dossiers et des périphériques de caractères et de blocs.
Voici la syntaxe de base de la commande find :
find /path/ -type f -name file-to-search
Où,
-
/pathest le chemin où le fichier est attendu d’être trouvé. C’est le point de départ de la recherche de fichiers. Le chemin peut également être/ou.qui représente respectivement la racine et le dossier courant. -typereprésente les descripteurs de fichiers. Ils peuvent être n’importe lesquels des options ci-dessous :
f– Fichier normal tels que les fichiers de texte, les images et les fichiers cachés.
d– Répertoire. Ces sont les dossiers en cours de considération.
l– Lien symbolique. Les liens symboliques pointent vers des fichiers et sont similaires aux raccourcis.
c– Périphériques de caractères. Les fichiers utilisés pour accéder à des périphériques de caractères sont appelés fichiers de périphériques de caractères. Les pilotes communiquent avec les périphériques de caractères en envoyant et en reçchant des caractères individuels (octets, bytes). Exemples : claviers, cartes son, souris.
b– Périphériques blocs. Les fichiers utilisés pour accéder à des périphériques blocs sont appelés fichiers de périphériques blocs. Les pilotes communiquent avec les périphériques blocs en envoyant et en reçant des blocs entiers de données. Exemples : USB et CD-ROM.-
-nameest le nom du type de fichier que vous voulez rechercher.
Comment rechercher des fichiers par nom ou extension
Supposons qu’il nous faut trouver des fichiers contenant « style » dans leur nom. Nous utiliserons la commande suivante :
find . -type f -name "style*"
#output
./style.css
./styles.css
Maintenant, disons que nous souhaitons trouver des fichiers avec une extension spécifique telle que .html. Nous modifierons la commande comme suit :
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
Comment rechercher des fichiers cachés
Le point au début du nom de fichier représente les fichiers cachés. Ils sont normalement cachés mais peuvent être affichés avec ls -a dans le répertoire courant.
On peut modifier la commande find comme montré ci-dessous pour rechercher des fichiers cachés :
find . -type f -name ".*"
Lister et trouver les fichiers cachés
ls -la
# contenu du dossier
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# sortie de la commande find
./.bash_logout
./.bashrc
./.bash_history
Vous pouvez voir ci-dessus une liste des fichiers cachés dans mon dossier personnel.
Comment rechercher des fichiers journaux et des fichiers de configuration
Les fichiers journaux ont généralement l’extension .log, et on peut les trouver comme ceci :
find . -type f -name "*.log"
De même, on peut rechercher des fichiers de configuration de cette manière :
find . -type f -name "*.conf"
Comment rechercher d’autres fichiers par type
On peut rechercher des fichiers de blocs de caractères en fournissant c à -type :
find / -type c
De même, on peut trouver des fichiers de blocs de périphériques en utilisant b :
find / -type b
Comment rechercher des répertoires
Dans l’exemple ci-dessous, nous recherchons les dossiers en utilisant le drapeau -type d.
ls -l
# liste du contenu des dossiers
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# sortie de la recherche de répertoire
.
./webp
./images
./style
./hosts
Comment rechercher des fichiers par taille
Une utilisation incroyablement utile de la commande find est de lister les fichiers en fonction d’une taille particulière.
find / -size +250M
Voici, nous listons les fichiers dont la taille dépasse 250MB.
Les autres unités incluent :
-
G: GigaOctets. -
M: MegaBytes. -
K: KiloBytes -
c: bytes.
Il faut simplement remplacer par l’unité pertinente.
find <directory> -type f -size +N<Unit Type>
Comment rechercher des fichiers par leur temps de modification
En utilisant le drapeau -mtime, vous pouvez filtrer des fichiers et dossiers en fonction de leur temps de modification.
find /path -name "*.txt" -mtime -10
Par exemple,
-
-mtime +10 signifie que vous recherchez un fichier modifié il y a 10 jours.
-
-mtime -10 signifie moins de 10 jours.
-
-mtime 10 Si vous omettez + ou -, cela signifie exactement 10 jours.
4.5. Commandes de base pour afficher des fichiers
Concaténer et afficher les fichiers à l’aide de la commande cat
La commande cat en Linux est utilisée pour afficher le contenu d’un fichier. Elle peut également être utilisée pour concaténer des fichiers et créer de nouveaux fichiers.
Voici la syntaxe de base de la commande cat :
cat [options] [file]
La manière la plus simple d’utiliser cat est sans aucun argument ou option. Cela affichera le contenu du fichier sur le terminal.
Par exemple, si vous voulez consulter le contenu d’un fichier nommé file.txt, vous pouvez utiliser la commande suivante :
cat file.txt
Cela affichera l’ensemble du contenu du fichier sur le terminal en une seule fois.
Pour afficher les fichiers texte de manière interactive en utilisant less et more
Alors que cat affiche le contenu du fichier entier, less et more permettent de consulter le contenu d’un fichier de manière interactive. Cela est utile lorsque vous souhaitez faire des défilements dans un grand fichier ou rechercher du contenu spécifique.
La syntaxe de la commande less est la suivante :
less [options] [file]
La commande more est similaire à less mais offre moins de fonctionnalités. Elle est utilisée pour afficher le contenu d’un fichier par écran.
La syntaxe de la commande more est la suivante :
more [options] [file]
Pour les deux commandes, vous pouvez utiliser la barre d'espace pour défiler d’un écran, la touche Entrée pour défiler d’une ligne et la touche q pour quitter l’afficheur.
Pour aller vers l’arrière, vous pouvez utiliser la touche b, et pour aller vers l’avant, vous pouvez utiliser la touche f.
Affichage de la dernière partie des fichiers en utilisant tail
Il arrive que vous ayez juste besoin de visualiser les dernières lignes d’un fichier plutôt que l’ensemble du fichier. La commande tail dans Linux est utilisée pour afficher la dernière partie d’un fichier.
Par exemple, tail file.txt affichera par défaut les 10 dernières lignes du fichier file.txt.
Si vous voulez afficher un nombre différent de lignes, vous pouvez utiliser l’option -n suivie du nombre de lignes que vous voulez afficher.
# Afficher les 50 dernières lignes du fichier file.txt
tail -n 50 file.txt
💡Astuce : Une autre utilisation de la commande tail est son option suivi (-f). Cette option permet de visualiser le contenu d’un fichier au fur et à mesure de son écriture. C’est une utilité utile pour afficher et surveiller les fichiers journaliers en temps réel.
Affichage du début des fichiers à l’aide de head
Comme tail affiche la dernière partie d’un fichier, vous pouvez utiliser la commande head sous Linux pour afficher le début d’un fichier.
Par exemple, head file.txt affichera par défaut les 10 premières lignes du fichier file.txt.
Pour modifier le nombre de lignes affichées, vous pouvez utiliser l’option -n suivie du nombre de lignes que vous voulez afficher.
Compte des mots, lignes et caractères à l’aide de wc
Vous pouvez compter les mots, lignes et caractères dans un fichier à l’aide de la commande wc.
Par exemple, l’exécution de wc syslog.log m’a donné l’output suivant :
1669 9623 64367 syslog.log
Dans l’output ci-dessus,
-
1669représente le nombre de lignes dans le fichiersyslog.log. -
9623représente le nombre de mots dans le fichiersyslog.log. -
64367représente le nombre de caractères dans le fichiersyslog.log.
Donc, la commande wc syslog.log a compté 1669 lignes, 9623 mots et 64367 caractères dans le fichier syslog.log.
Comparaison de fichiers ligne par ligne en utilisant diff
La comparaison et la recherche de différences entre deux fichiers sont des tâches courantes sous Linux. Vous pouvez comparer deux fichiers directement depuis la ligne de commande en utilisant la commande diff.
La syntaxe de base de la commande diff est :
diff [options] file1 file2
Ici, nous avons deux fichiers, hello.py et also-hello.py, que nous comparons en utilisant la commande diff :
# contenu de hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# contenu de also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Vérifiez si les fichiers sont les mêmes ou non
diff -q hello.py also-hello.py
# Sortie
Files hello.py and also-hello.py differ
- Regardez comment les fichiers diffèrent. Pour cela, vous pouvez utiliser le drapeau
-upour obtenir une sortie unifiée :
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- Dans l’output ci-dessus :
--- hello.py 2024-05-24 18:31:29.891690478 +0500indique le fichier en cours de comparaison et son horodatage.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500indique l’autre fichier en cours de comparaison et son horodatage.@@ -3,4 +3,5 @@montre les numéros de lignes où les modifications se produisent. Dans ce cas, il indique que les lignes 3 à 4 du fichier original se sont modifiées en lignes 3 à 5 du fichier modifié.user = input(Enter your name: )est une ligne du fichier original.print(greet(user))est une autre ligne du fichier original.
+print("Nice to meet you")est la ligne additionnelle dans le fichier modifié.
diff -y hello.py also-hello.py
Pour visualiser le différentiel dans un format côte à côte, vous pouvez utiliser le drapeau -y :
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Output
- Dans la sortie :
- Les lignes identiques dans les deux fichiers sont affichées côte à côte.
Les lignes différentes sont affichées avec le symbole > indiquant que la ligne n’est présente que dans l’un des fichiers.
Partie 5 : Les principes essentiels de l’édition de texte sous Linux
Les compétences en édition de texte en ligne de commande sont parmi les compétences les plus cruciales sous Linux. Dans cette section, vous apprendrez à utiliser deux éditeurs de texte populaires sous Linux : Vim et Nano.
Je suggère que vous maîtrisiez l’éditeur de texte de votre choix et que vous le suiviez. Cela vous sauvera du temps et vous rendra plus productif. Vim et Nano sont de bonnes sélections car ils sont présents sur la plupart des distributions Linux.
5.1. Maîtriser Vim : Le guide complet
Introduction à Vim
- Vim est un outil d’édition de texte populaire pour la ligne de commande. Vim est doté de ses avantages : il est puissant, personnalisable et rapide. Voici quelques raisons pour lesquelles vous devriez envisager d’apprendre Vim :
- La plupart des serveurs sont accessibles via une CLI, donc en administrant le système, vous n’avez pas nécessairement la commodité d’une IU. Mais Vim est là pour vous – il sera toujours présent.
- Vim utilise une approche axée sur le clavier, car il est conçu pour être utilisé sans souris, ce qui peut accélérer considérablement les tâches d’édition une fois que vous aurez appris les raccourcis clavier. Cela rend également Vim plus rapide que les outils avec interface graphique.
- Certaines utilitaires Linux, par exemple pour éditer les emplois cron, fonctionnent dans le même format d’édition que Vim.
Vim est adapté à tous – aux débutants et aux utilisateurs avancés. Vim permet des recherches de chaînes complexes, le highlighting des recherches et beaucoup plus. Grâce aux plugins, Vim offre des fonctionnalités avancées aux développeurs et administrateurs systèmes, notamment la complétion de code, le highlighting syntaxique, la gestion de fichiers, le contrôle de version et plus encore.
Vim existe en deux variantes : Vim (vim) et Vim tiny (vi). Vim tiny est une version plus petite de Vim qui manque certaines fonctionnalités de Vim.
Comment commencer à utiliser vim
vim your-file.txt
Commencez à utiliser Vim avec ce commande :
your-file.txt peut être soit un nouveau fichier ou un fichier existant que vous voulez éditer.
Naviguant dans Vim : Maîtriser les mouvements et les modes de commandes
Dans les premiers jours de l’interface en ligne de commande, les claviers n’avaient pas de touches fléchées. Par conséquent, la navigation était effectuée à l’aide de l’ensemble des touches disponibles, hjkl en faisant partie.
En étant centré sur le clavier, l’utilisation des touches hjkl peut grandement accélérer les tâches d’édition de texte.
Note :Bien que les touches fléchées fonctionnent parfaitement bien, vous pouvez toujours expérimenter avec les touches hjkl pour naviguer. Certains trouvent cette façon de naviguer efficiente.

💡Astuce : Pour vous rappeler de la séquence hjkl, utilisez ceci : hang back, jump down, kick up, leap forward.
Les trois modes de Vim
- Vous devez connaître les trois modes d’opération de Vim et comment basculer entre eux. Les frappes clavier se comportent différemment dans chaque mode de commande. Les trois modes sont les suivants :
- Mode commande.
- Mode édition.
Mode visuel.
Mode Commande. Lorsque vous lancez Vim, vous êtes par défaut dans le mode commande. Ce mode vous permet d’accéder aux autres modes.
⚠ Pour basculer vers d’autres modes, vous devez d’abord être dans le mode commande
Mode Édition
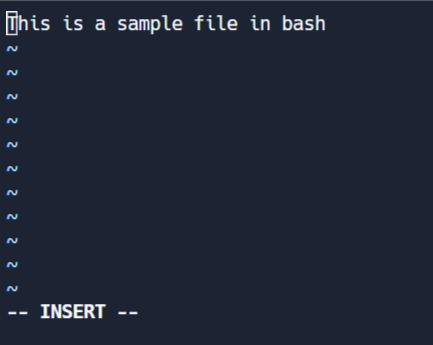
Ce mode vous permet de faire des modifications au fichier. Pour entrer dans le mode édition, appuyez sur I lorsque vous êtes dans le mode commande. Notez le changement à '-- INSERT' en bas de l’écran.
Mode visuel
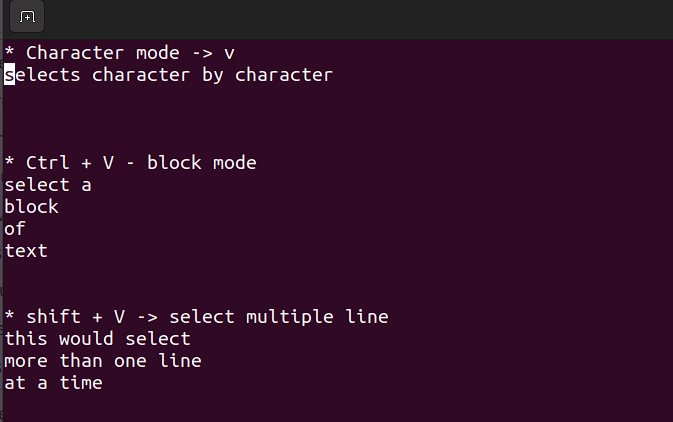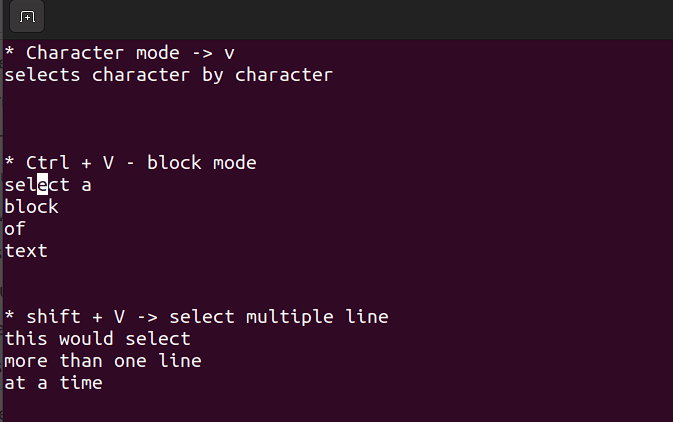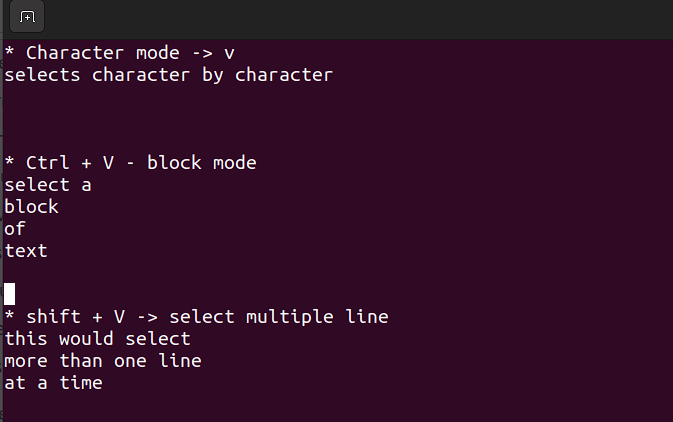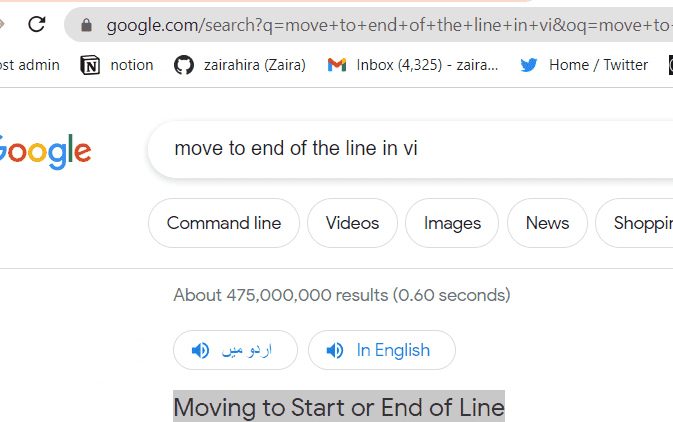
- Ce mode vous permet de travailler sur un seul caractère, un bloc de texte ou des lignes de texte. Faisons-en une décomposition en étapes simples. Souvenez-vous, utilisez les combinaisons ci-dessous lorsque vous êtes en mode commande.
Maj + V→ Sélectionner plusieurs lignes.Ctrl + V→ Mode bloc
V → Mode caractère
Le mode visuel est utile lorsque vous devez copier, coller ou éditer des lignes en quantité.
Mode de commande étendu.
Le mode de commande étendu vous permet de réaliser des opérations avancées telles que la recherche, l’affichage des numéros de ligne et la mise en surbrillance du texte. Nous aborderons le mode étendu dans la prochaine section.
Pour rester à jour, si vous oubliez votre mode actuel, appuyez simplement sur ESC deux fois et vous serez de retour en mode Commande.
Édition efficace dans Vim : Copier/coller et rechercher
1.Comment copier et coller dans Vim
- Le copier-coller est connu sous le nom de ‘剪切’ et ‘粘贴’ en Linux. Pour copier-coller, suivez ces étapes :
- Sélectionnez du texte en mode visuel.
- Appuyez sur
'y'pour copier/épingler.
Déplacez votre curseur à l’emplacement requis et appuyez sur 'p'.
2. Comment rechercher du texte dans Vim
Vous pouvez rechercher n’importe quelle série de chaînes de caractères dans Vim en utilisant le caractère / en mode commande. Pour effectuer une recherche, tapez /chaîne-à-trouver.
En mode commande, tapez :set hls et appuyez sur entrée. Recherchez en utilisant /chaîne-à-trouver. Cela mettra le texte en surbrillance.
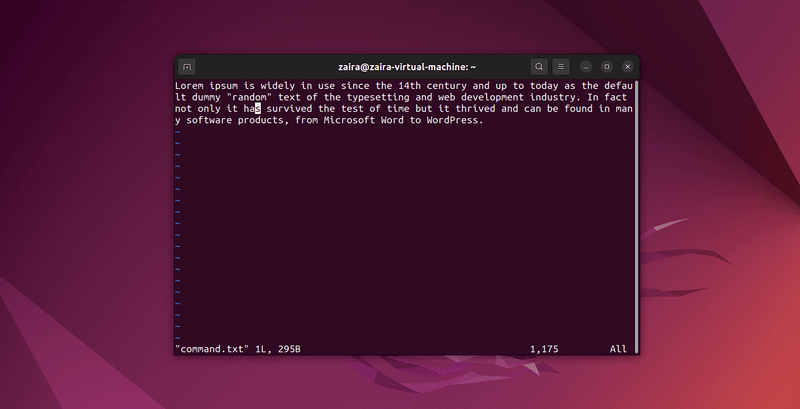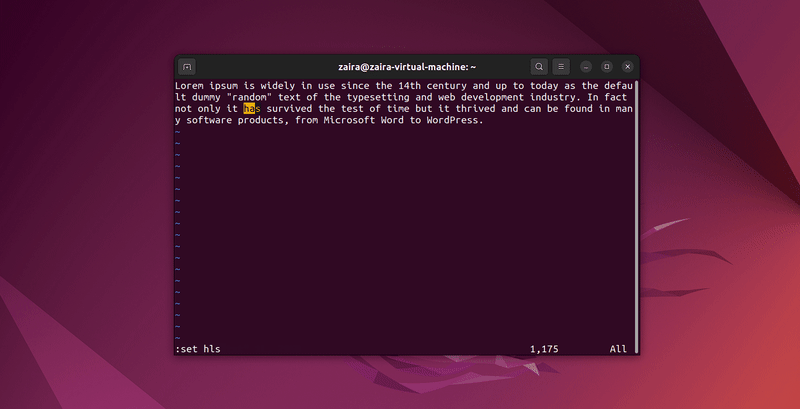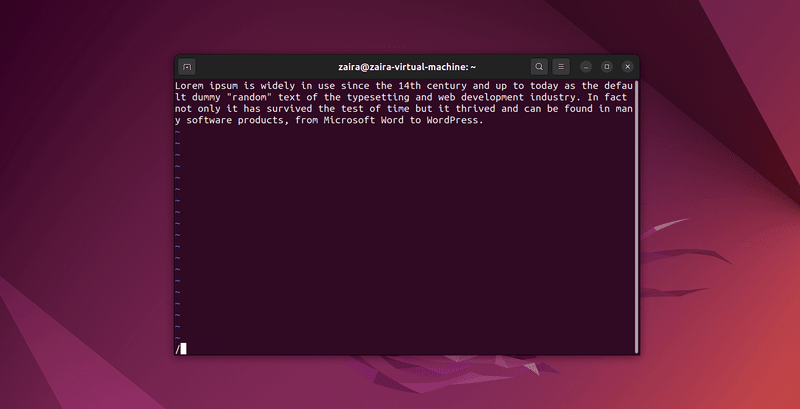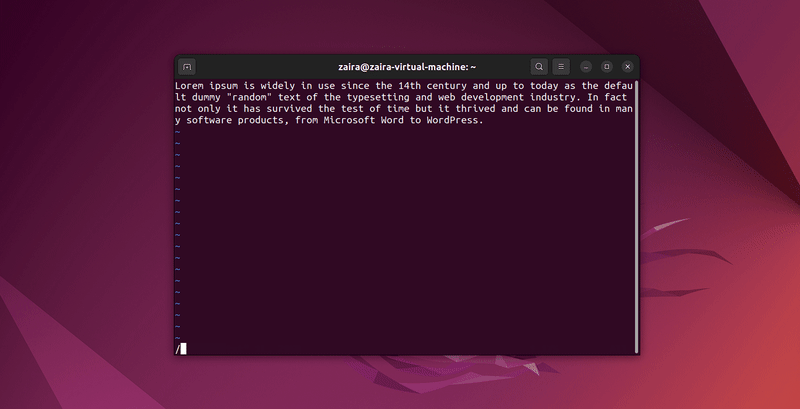
Exemples de recherches :
3. Comment quitter Vim
- D’abord, allez au mode commande (en appuyant deux fois sur Échap) et utilisez ensuite ces drapeaux :
- Quitter sans sauver →
:q!
Quitter et sauver → :wq!
Raccourcis dans Vim : accélérer l’édition
- Note : Tous ces raccourcis fonctionnent uniquement en mode commande.
Ctrl+u: Aller vers le haut d’une demi-pageP: Coller au-dessus du curseur:%s/old/new/g: Remplacer toutes les occurrences deoldparnewdans le fichier:q!: Quitter sans enregistrer
Ctrl+w suivi de h/j/k/l : Naviguer entre les fenêtres divisées
5.2. Maîtriser Nano
Se lancer avec Nano : L’éditeur de texte convivial
Nano est un éditeur de texte convivial et facile à utiliser, parfait pour les débutants. Il est pré-installé sur la plupart des distributions Linux.
nano
Pour créer un nouveau fichier avec Nano, utilisez la commande suivante :
nano filename
Pour commencer à éditer un fichier existant avec Nano, utilisez la commande suivante :
Liste des raccourcis clavier dans Nano
Faisons connaissance avec les raccourcis clavier les plus importants de Nano. Vous utiliserez ces raccourcis pour effectuer diverses opérations telles que l’enregistrement, la sortie, la copie, le collage, et plus encore.
Écrire dans un fichier et enregistrer
Une fois que vous avez ouvert Nano en utilisant le commande nano, vous pouvez commencer à écrire du texte. Pour enregistrer le fichier, appuyez sur Ctrl+O. Vous serez invité à entrer le nom du fichier. Appuyez sur Enter pour enregistrer le fichier.
Quitter nano
Vous pouvez quitter Nano en appuyant sur Ctrl+X. Si vous avez des modifications non enregistrées, Nano vous demandera de sauvegarder les modifications avant de quitter.
Copier et coller
Pour sélectionner une région, utilisez ALT+A. Un marqueur apparaîtra. Utilisez les flèches pour sélectionner le texte. Une fois sélectionné, quittez le marqueur en utilisant ALT+^.
Pour copier le texte sélectionné, appuyez sur Ctrl+K. Pour coller le texte copié, appuyez sur Ctrl+U.
Couper et coller
Sélectionnez la région avec ALT+A. Une fois sélectionné, coupez le texte avec Ctrl+K. Pour coller le texte coupé, appuyez sur Ctrl+U.
Navigation
Utilisez Alt \ pour aller au début du fichier.
Utilisez Alt / pour aller à la fin du fichier.
Affichage des numéros de ligne
Lorsque vous ouvrez un fichier avec nano -l filename, vous pouvez afficher les numéros de ligne à gauche du fichier.
Recherche
Vous pouvez rechercher un numéro de ligne spécifique en utilisant ALt + G. Entrez le numéro de ligne à la promesse et appuyez sur Enter.
Vous pouvez également lancer une recherche pour une chaîne de caractères en utilisant CTRL + W et en appuyant sur Entrée. Si vous voulez rechercher en arrière, vous pouvez appuyer sur Alt+W après avoir lancé la recherche avec Ctrl+W.
- Récapitulatif des raccourcis claviers dans Nano
Ctrl+J: Justifier le paragraphe actuelCtrl+J: Justifier le paragraphe actuelCtrl+V: Faire défiler vers le bas d’une pageCtrl+\: Rechercher et remplacer
Alt+E : Répéter l’opération annulée
Partie 6 : Scripture en Bash
6.1. Définition de la scripture en Bash
Un script en Bash est un fichier contenant une suite de commandes exécutées par le programme Bash ligne par ligne. Il permet de réaliser une série d’actions, telles que naviguer vers un répertoire spécifique, créer un dossier et lancer un processus à l’aide de la ligne de commande.
Enregistrer les commandes dans un script permet de répéter plusieurs fois la même séquence d’étapes et d’exécuter celles-ci en lançant le script.
6.2 Avantages du scriptage Bash
Le scriptage Bash est une puissante et polyvalente solution pour automatiser les tâches de gestion de système, gérer les ressources systèmes et effectuer d’autres tâches courantes dans les systèmes Unix/Linux.
- Certains avantages du scriptage de shell sont :
- Automatisation : Les scripts shell permettent de programmer des tâches et des processus répétitifs, ce qui économise du temps et réduit le risque d’erreurs qui pourraient survenir lors de l’exécution manuelle.
- Portabilité : Les scripts shell peuvent être exécutés sur diverses plateformes et systèmes d’exploitation, y compris Unix, Linux, macOS et même Windows à travers l’utilisation d’émulateurs ou de machines virtuelles.
- Flexibilité : Les scripts shell sont hautement personnalisables et peuvent être facilement modifiés pour s’adapter à des exigences spécifiques. Ils peuvent également être combinés avec d’autres langages de programmation ou outils pour créer des scripts plus puissants.
- Accessibilité : Les scripts shell sont faciles à écrire et n’ont pas besoin d’outils spéciaux ou de logiciels. Ils peuvent être édités à l’aide de n’importe quel éditeur de texte, et la plupart des systèmes d’exploitation disposent d’un interpréteur de shell intégré.
- Intégration : Les scripts shell peuvent être intégrés avec d’autres outils et applications, telles que des bases de données, des serveurs Web et des services cloud, permettant de réaliser des tâches d’automatisation et de gestion système plus complexes.
Débogage : Les scripts shell sont faciles à débugger, et la plupart des shells disposent d’outils de débogage et de rapport d’erreurs intégrés qui peuvent aider à identifier et à corriger les problèmes rapidement.
6.3. Aperçu du Shell Bash et de l’interface en ligne de commande
Les termes « shell » et « bash » sont souvent utilisés de manière interchangeable. Cependant, il existe une petite différence entre les deux.
Le terme « shell » désigne un programme qui fournit une interface en ligne de commande pour interagir avec un système d’exploitation. Bash (Bourne-Again SHell) est l’une des shells Unix/Linux les plus utilisées et est la shell par défaut dans de nombreuses distributions Linux.
Jusqu’à maintenant, les commandes que vous avez entrées étaient essentiellement entrées dans une « shell ».
Bash est une des nombreuses shells disponibles, telles que la shell Korn (ksh), la shell C (csh) et la shell Z (zsh). Chaque shell a sa propre syntaxe et jeux de fonctions, mais elles partagent toutes la même intention de fournir une interface en ligne de commande pour interagir avec le système d’exploitation.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
Vous pouvez déterminer le type de votre shell en utilisant la commande ps :
En résumé, tandis que « shell » est un terme large qui s’applique à tout programme offrant une interface en ligne de commande, « Bash » est une shell spécifique largement utilisée dans les systèmes Unix/Linux.
Note : Dans cette section, nous utiliserons la « shell bash ».
6.4. Comment créer et exécuter des scripts Bash
Conventions de nommage des scripts
Selon les conventions de nommage, les scripts Bash se terminent par .sh. Cependant, les scripts Bash peuvent fonctionner parfaitement sans l’extension sh.
Ajout de l’indicateur de charge
Les scripts Bash commencent par un shebang. Le shebang est une combinaison de bash # et bang ! suivi du chemin vers la console de Bash. C’est la première ligne du script. Le shebang indique à la console de l’exécuter via la shell Bash. Le shebang est simplement un chemin absolu vers l’interpréteur Bash.
#!/bin/bash
Voici un exemple de la déclaration shebang.
which bash
Vous pouvez trouver votre propre chemin vers la console Bash (qui peut être différente de celle ci-dessus) à l’aide de la commande :
Créer votre premier script Bash
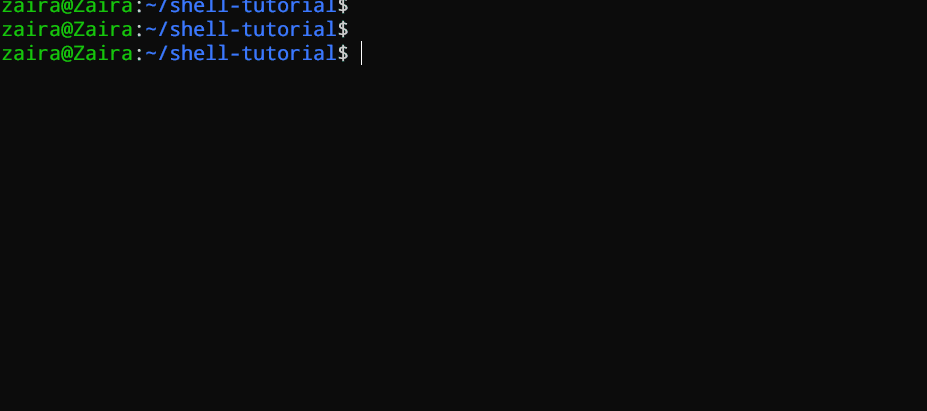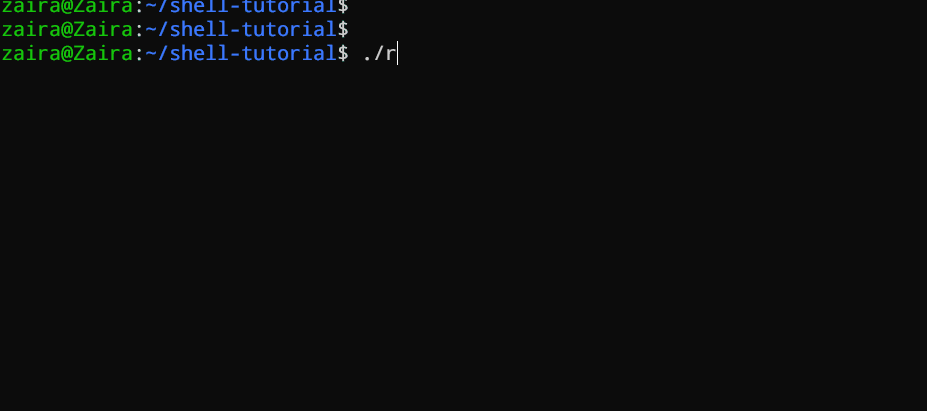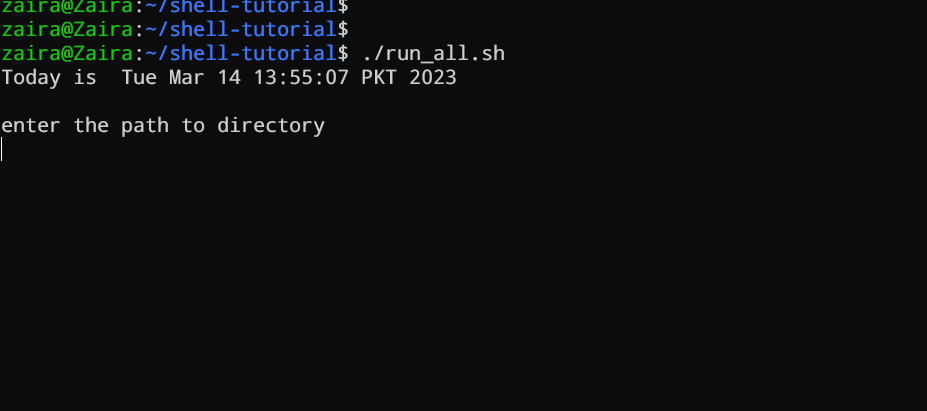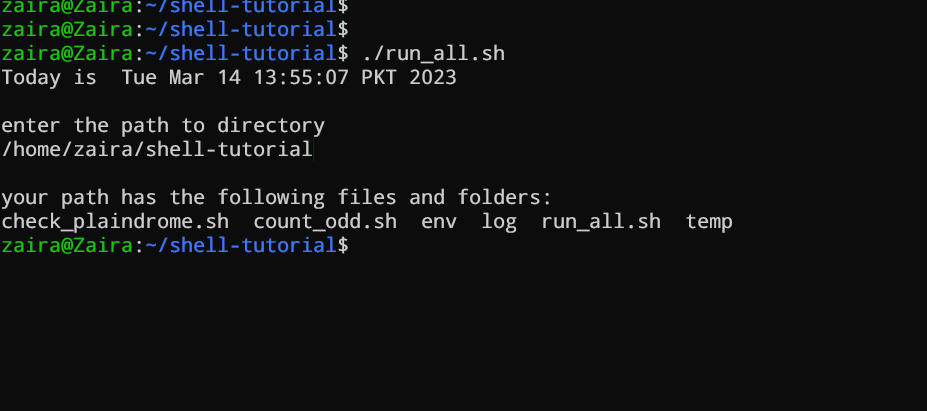
Notre premier script demande à l’utilisateur d’entrer un chemin. En retour, les contenu seront listés.
vim run_all.sh
Créez un fichier nommé run_all.sh à l’aide de n’importe quel éditeur de votre choix.
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
Ajoutez les commandes suivantes dans votre fichier et enregistrez-le :
1 Allons examiner le script ligne par ligne. Je présente à nouveau le même script, mais cette fois-ci avec les numéros de ligne.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- Ligne #1 : Le shebang (
#!/bin/bash) pointe vers le chemin de la console Bash. - Ligne #2 : La commande
echoaffiche la date et l’heure actuelles sur le terminal. Notez quedateest dans des backticks. - Ligne #4 : Nous voulons que l’utilisateur entre un chemin valide.
- Ligne #5 : La commande
readlit l’entrée et l’enregistre dans la variablethe_path.
ligne #8 : La commande ls prend la variable contenant le chemin enregistré et affiche les fichiers et dossiers courants.
Exécution du script Bash
chmod u+x run_all.sh
Pour rendre le script exécutable, affectez les droits d’exécution à votre utilisateur en utilisant cette commande :
- Ici,
chmodmodifie la propriété d’un fichier pour l’utilisateur actuel :u.+xajoute les droits d’exécution à l’utilisateur actuel. Cela signifie que l’utilisateur propriétaire du fichier peut maintenant exécuter le script.
run_all.sh est le fichier que nous souhaitons exécuter.
- Vous pouvez exécuter le script en utilisant l’une des méthodes mentionnées :
sh run_all.shbash run_all.sh
./run_all.sh
Voyons-le en action 🚀
6.5. Principes de scripting Bash
Commentaires dans les scripts Bash
Les commentaires commencent avec un # dans les scripts Bash. Cela signifie que toute ligne commençant par un # est un commentaire et sera ignorée par l’interpréteur.
Les commentaires sont très utiles pour documenter le code, et il est une bonne pratique d’en ajouter pour aider les autres à comprendre le code.
Voici des exemples de commentaires :
# Ceci est un exemple de commentaire
# Les deux lignes suivantes seront ignorées par l’interpréteur
Variables et types de données dans Bash
Les variables vous permettent de stocker des données. Vous pouvez utiliser les variables pour lire, accéder et manipuler les données à travers votre script.
Il n’y a pas de types de données dans Bash. Dans Bash, une variable est capable de stocker des valeurs numériques, des caractères individuels ou des chaînes de caractères.
- Dans Bash, vous pouvez utiliser et définir les valeurs des variables de la façon suivante :
country=Netherlands
Affectez directement la valeur :
same_country=$country
2. Affectez la valeur en fonction de la sortie obtenue d’un programme ou d’une commande, en utilisant la substitution de commande. Notez que $ est requis pour accéder à la valeur d’une variable existante.
Cela affecte la valeur de country à la nouvelle variable same_country.
country=Netherlands
echo $country
Pour accéder à la valeur de la variable, ajoutez $ à son nom.
Netherlands
new_country=$country
echo $new_country
# Sortie
Netherlands
# Sortie
Au-dessus, vous pouvez voir un exemple d’affectation et d’affichage de valeurs de variables.
Conventions de nommage des variables
- En écriture de scripts Bash, les conventions de nommage des variables sont les suivantes :
- Les noms de variables doivent commencer par une lettre ou un soulignement (
_). - Les noms de variables peuvent contenir des lettres, des chiffres et des soulignements (
_). - Les noms de variables sont sensibles à la casse.
- Les noms de variables ne devraient pas contenir d’espaces ou de caractères spéciaux.
- Utilisez des noms descriptifs qui reflètent la destination de la variable.
Évitez d’utiliser des mots réservés, tels que if, then, else, fi, etc., comme noms de variables.
name
count
_var
myVar
MY_VAR
Voici quelques exemples de noms de variables valides en Bash :
Et voici quelques exemples de noms de variables invalides :
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# noms de variables invalides
Suivre ces conventions de nommage aide à rendre les scripts Bash plus lisibles et plus faciles à maintenir.
Entrées et sorties dans les scripts Bash
Récupération d’entrées
- Dans cette section, nous discuterons quelques méthodes pour fournir des entrées à nos scripts.
Lire l’entrée utilisateur et l’enregistrer dans une variable
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
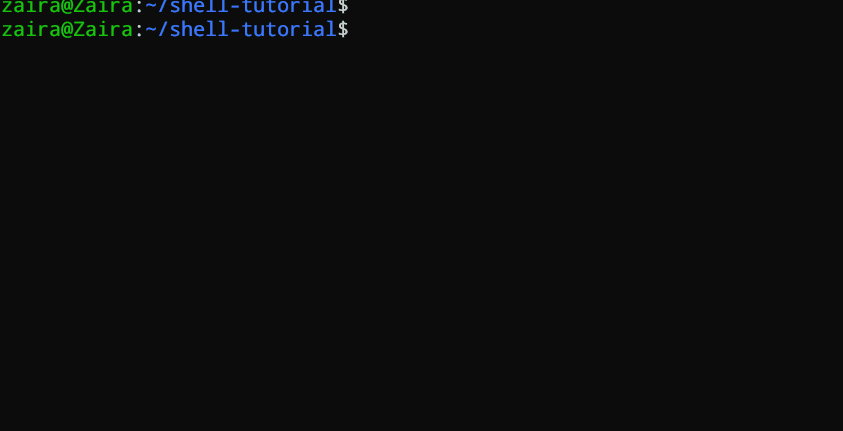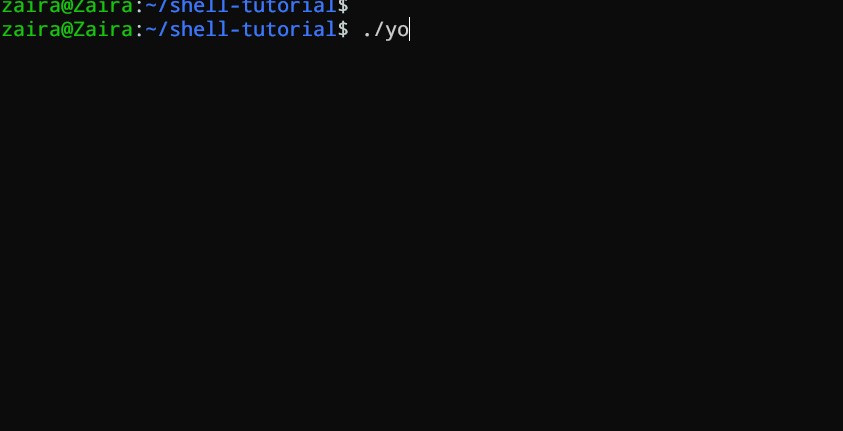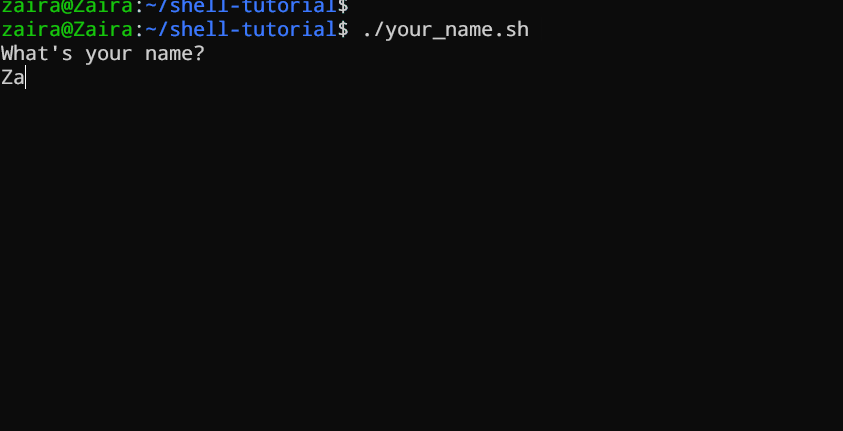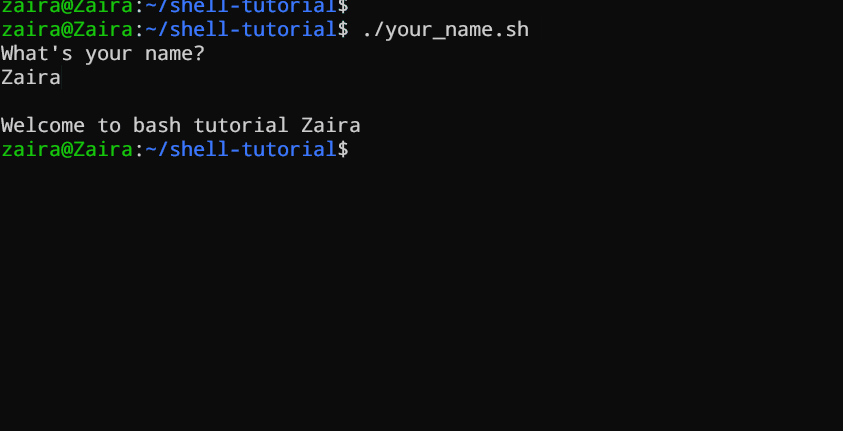
Nous pouvons lire l’entrée de l’utilisateur en utilisant la commande read.
2. Lire depuis un fichier
while read line
do
echo $line
done < input.txt
Ce code lit chaque ligne d’un fichier nommé input.txt et l’affiche sur le terminal. Nous étudierons les boucles while plus loin dans cette section.
3. Arguments de ligne de commande
Dans un script Bash ou une fonction, $1 désigne l’argument initial fourni, $2 désigne le second argument, et ainsi de suite.
#!/bin/bash
echo "Hello, $1!"
Ce script prend un nom en argument de ligne de commande et affiche une salutation personnalisée.
Nous avons fourni Zaira en tant qu’argument du script.
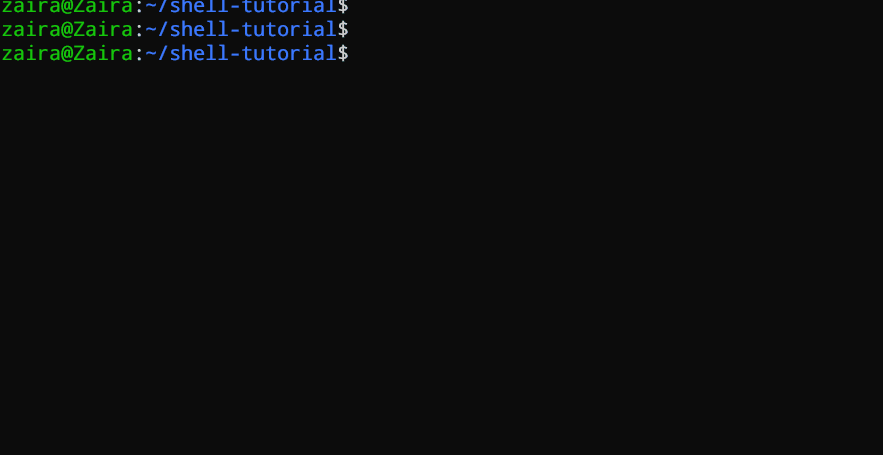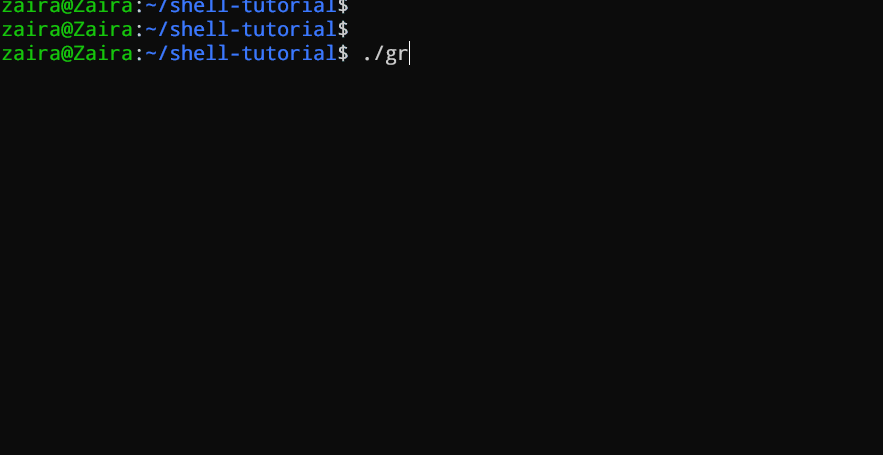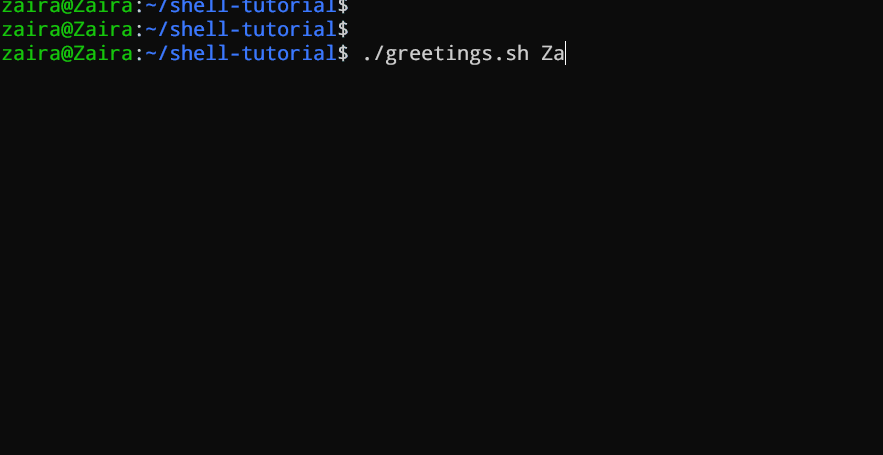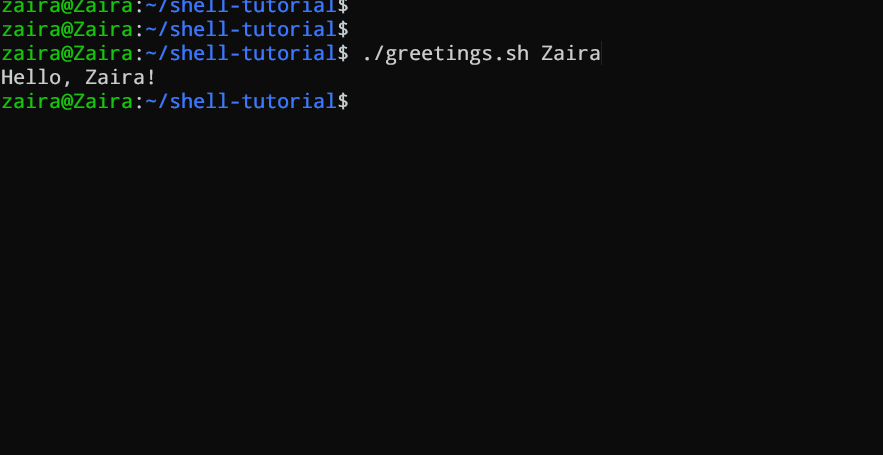
Sortie :
Affichage de la sortie
- Dans cette section, nous discuterons quelques méthodes pour obtenir des sorties de scripts.
echo "Hello, World!"
Affichage sur le terminal :
Ceci affiche le texte « Bonjour, le monde ! » sur le terminal.
echo "This is some text." > output.txt
2. Ecriture dans un fichier :
Ceci écrit le texte « Ceci est du texte. » dans un fichier nommé output.txt. Notez que l’opérateur > écrasera le fichier s’il contient déjà du contenu.
echo "More text." >> output.txt
3. Ajout à un fichier :
Cet appel ajoute le texte « Plus de texte. » à la fin du fichier output.txt.
ls > files.txt
4. Rediriger la sortie :
Ceci liste les fichiers du répertoire courant et écrit la sortie dans un fichier nommé files.txt. Vous pouvez rediriger la sortie de n’importe quelle commande vers un fichier de cette manière.
Vous apprendrez en détail sur la redirection de sortie dans la section 8.5.
Énoncés conditionnels (if/else)
Des expressions qui produisent un résultat booléen, soit vrai ou faux, sont appelés conditions. Il existe plusieurs façons d’évaluer les conditions, y compris l’instruction if, if-else, if-elif-else et les conditions imbriquées.
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Syntaxe :
Syntaxe des énoncés conditionnels du shell bash
if [ $a -gt 60 -a $b -lt 100 ]
Nous pouvons utiliser les opérateurs logiques tels que ET (-a) et OU (-o) pour effectuer des comparaisons de plus grande importance.
Cet énoncé vérifie si les deux conditions sont true : a est supérieur à 60 ET b est inférieur à 100.
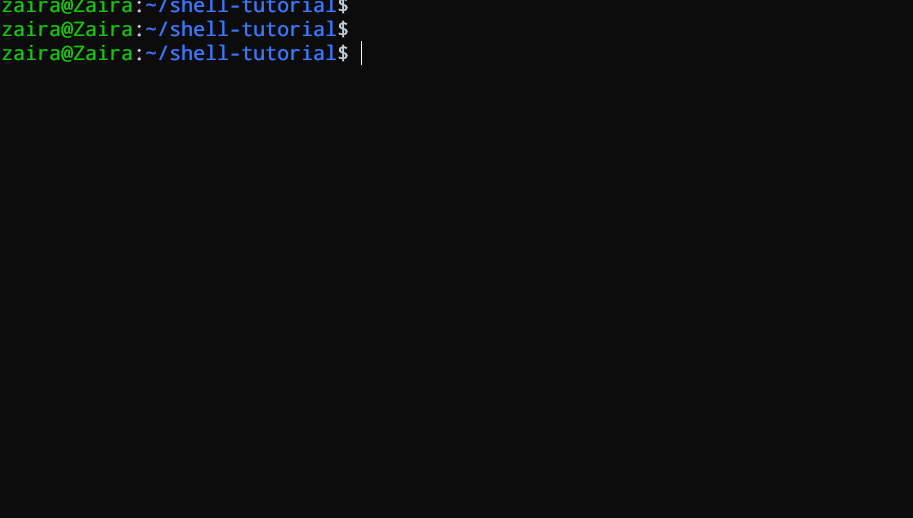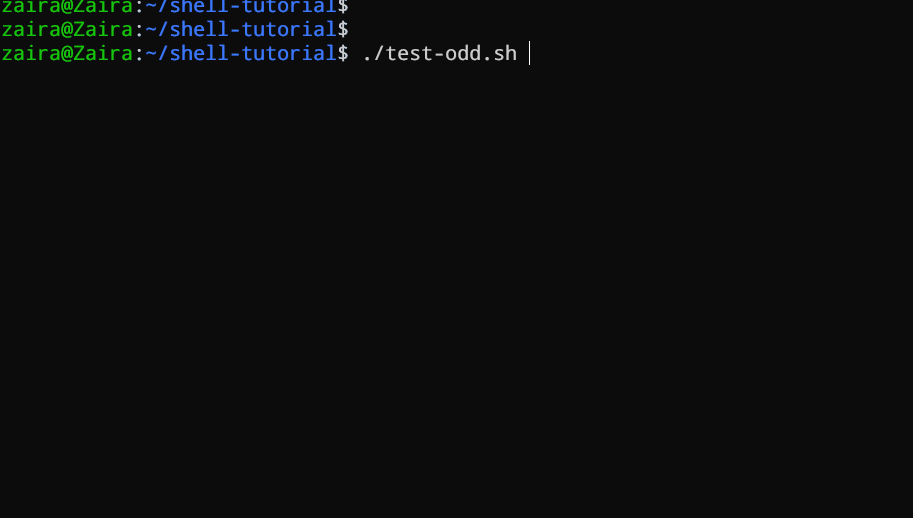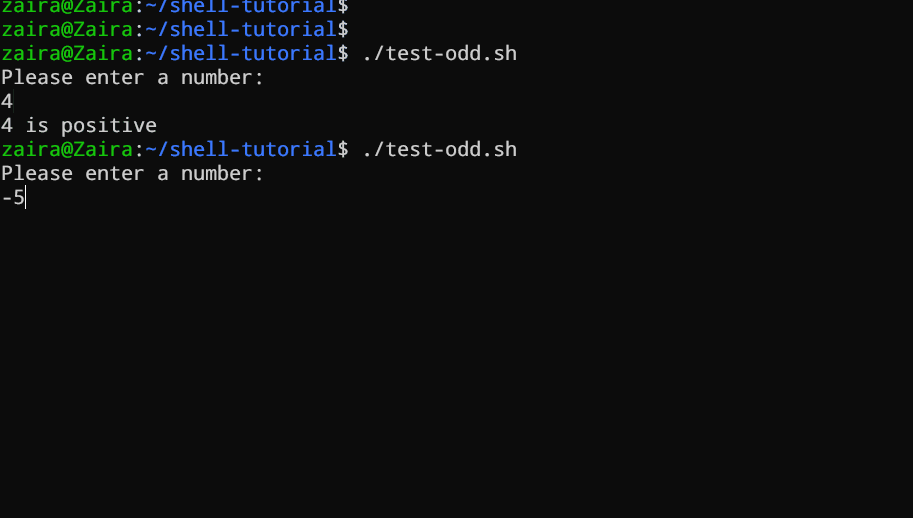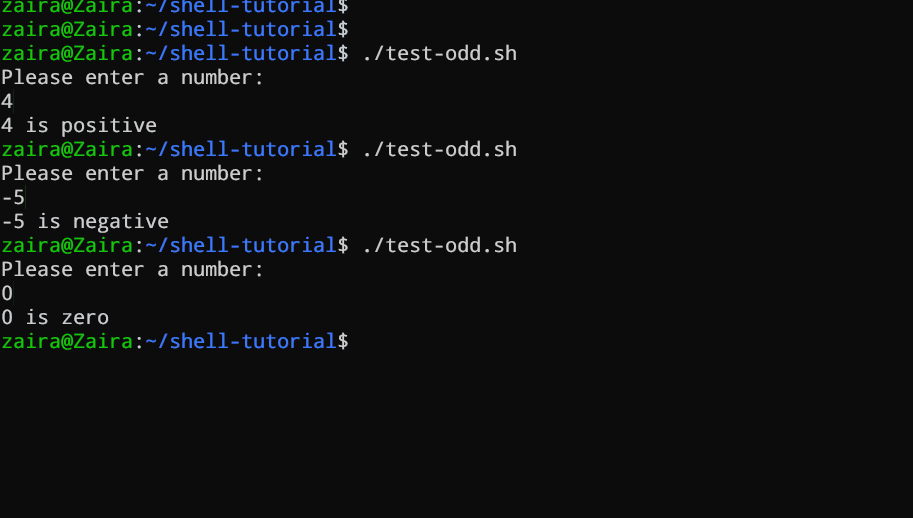
#!/bin/bash
Voyons un exemple d'un script Bash qui utilise les instructions if, if-else et if-elif-else pour déterminer si un nombre saisi par l'utilisateur est positif, négatif ou nul :
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# Script pour déterminer si un nombre est positif, négatif ou nul
Le script demande d’abord à l’utilisateur d’entrer un nombre. Ensuite, il utilise une instruction if pour vérifier si le nombre est supérieur à 0. Si c’est le cas, le script affiche que le nombre est positif. Si le nombre n’est pas supérieur à 0, le script passe à la prochaine instruction, qui est une instruction if-elif.
Ici, le script vérifie si le nombre est inférieur à 0. Si c’est le cas, le script affiche que le nombre est négatif.
Finalement, si le nombre n’est ni supérieur à 0 ni inférieur à 0, le script utilise une instruction else pour afficher que le nombre est zéro.
Voir en action 🚀
Boucles et branches en Bash
Boucle while
Les boucles while vérifient une condition et bouclent jusqu’à ce que la condition reste true. Il faut fournir une instruction de compteur qui incrémente le compteur pour contrôler l’exécution de la boucle.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
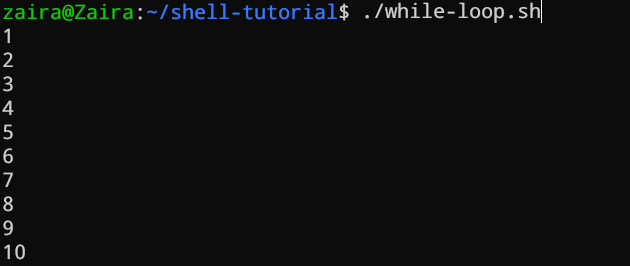
Dans l’exemple ci-dessous, (( i += 1 )) est l’instruction de compteur qui incrémente la valeur de i. La boucle s’exécutera exactement 10 fois.
Boucle for
La boucle for, tout comme la boucle while, vous permet d’exécuter des instructions un certain nombre de fois. Chaque boucle diffère dans sa syntaxe et son utilisation.
#!/bin/bash
for i in {1..5}
do
echo $i
done

Dans l’exemple ci-dessous, la boucle itérera 5 fois.
États du cas
case expression in
pattern1)
Dans Bash, les instructions case sont utilisées pour comparer une valeur donnée à une liste de patrons et exécuter un bloc de code en fonction du premier patron qui correspond. La syntaxe d'une instruction case en Bash est la suivante :
;;
pattern2)
# code à exécuter si l'expression correspond au patron1
;;
pattern3)
# code à exécuter si l'expression correspond au patron2
;;
*)
# code à exécuter si l'expression correspond au patron3
;;
esac
# code à exécuter si aucun des patrons précédents n’ correspond à l’expression
Dans cet exemple, « expression » est la valeur que nous voulons comparer, et « pattern1 », « pattern2 », « pattern3 », etc., sont les patrons auxquels nous voulons les comparer.
Le double point-virgule « ;; » sépare chaque bloc de code à exécuter pour chaque patron. L’astérisque « * » représente le cas par défaut, qui est exécuté si aucun des patrons spécifiés n’ correspond à l’expression.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Voyons un exemple :
Dans cet exemple, puisque la valeur de fruit est apple, le premier patron correspond et le bloc de code qui affiche This is a red fruit. est exécuté. Si la valeur de fruit était au lieu de cela banana, le second patron correspondrait et le bloc de code qui affiche This is a yellow fruit. serait exécuté, et ainsi de suite.
Si la valeur de fruit ne correspond à aucun des patrons spécifiés, le cas par défaut est exécuté, qui affiche Unknown fruit.
Partie 7 : Gestion des paquets logiciels sous Linux.
Linux est fourni avec plusieurs programmes intégrés. Cependant, vous pourriez avoir besoin d’installer de nouveaux programmes en fonction de vos besoins. Vous pourriez également avoir besoin de mettre à niveau les applications existantes.
7.1. Paquets et gestion de paquets
Qu’est-ce qu’un paquet ?
Un paquet est une collection de fichiers groupés ensemble. Ces fichiers sont essentiels pour que un programme puisse s’exécuter. Ces fichiers contiennent les fichiers exécutables du programme, les bibliothèques et d’autres ressources.
En plus des fichiers nécessaires pour l’exécution du programme, les paquets contiennent également des scripts d’installation, qui copient les fichiers à l’endroit où ils sont nécessaires. Un programme peut contenir beaucoup de fichiers et de dépendances. Avec les paquets, il est plus facile de gérer tous les fichiers et dépendances en une seule fois.
Quelle est la différence entre le code source et le code binaire ?
Les programmeurs écrivent le code source dans un langage de programmation. Ce code source est ensuite compilé en code machine que le ordinateur peut comprendre. Le code compilé est appelé code binaire.
Lorsque vous téléchargez un paquet, vous pouvez soit obtenir le code source ou le code binaire. Le code source est le code lisible par l’homme qui peut être compilé en code binaire. Le code binaire est le code compilé que l’ordinateur peut comprendre.
Les paquets source peuvent être utilisés avec tout type d’ordinateur si le code source est compilé correctement. En revanche, le binaire est le code compilé spécifique à un type de machine ou d’architecture particulière.
uname -m
Vous pouvez trouver l'architecture de votre machine en utilisant la commande uname -m.
x86_64
# sortie
Dépendances de packages
Les programmes partagent souvent des fichiers. Au lieu d’inclure ces fichiers dans chaque paquet, un paquet distinct peut les fournir à tous les programmes.
Pour installer un programme qui a besoin de ces fichiers, vous devez également installer le paquet les contenant. Cela s’appelle une dépendance de package. Spécifier les dépendances permet de rendre les paquets plus petits et plus simples en réduisant les duplications.
Lors de l’installation d’un programme, ses dépendances doivent également être installées. La plupart des dépendances requises sont généralement déjà installées, mais quelques-unes supplémentaires peuvent être nécessaires. Donc, ne soyez pas surpris si plusieurs autres paquets sont installés avec votre paquet choisi. Ces sont les dépendances nécessaires.
Gestionnaires de packages
Linux propose un système complet de gestion de packages pour installer, mettre à jour, configurer et retirer des logiciels.
Avec la gestion des packages, vous pouvez accéder à une base organisée de milliers de paquets de logiciels tout en ayant la capacité de résoudre les dépendances et de vérifier les mises à jour du logiciel.
Les paquets peuvent être gérés à l’aide de utilitaires en ligne de commande qui peuvent être facilement automatisés par les administrateurs systèmes ou par l’interface graphique.
Canaux de logiciels/référentiels
⚠️ La gestion des paquets est différente pour les différentes distributions. Ici, nous utilisons Ubuntu.
L’installation du logiciel est un peu différente sous Linux par rapport à Windows et Mac.
Linux utilise des référentiels pour stocker les paquets de logiciels. Un référentiel est une collection de paquets de logiciels disponibles pour l’installation à travers un gestionnaire de packages.
Un gestionnaire de paquets stocke également un index de tous les paquets disponibles dans un dépôt. Parfois, l’index est reconstruit pour s’assurer qu’il est à jour et savoir quels paquets ont été mis à jour ou ajoutés au canal depuis la dernière vérification.
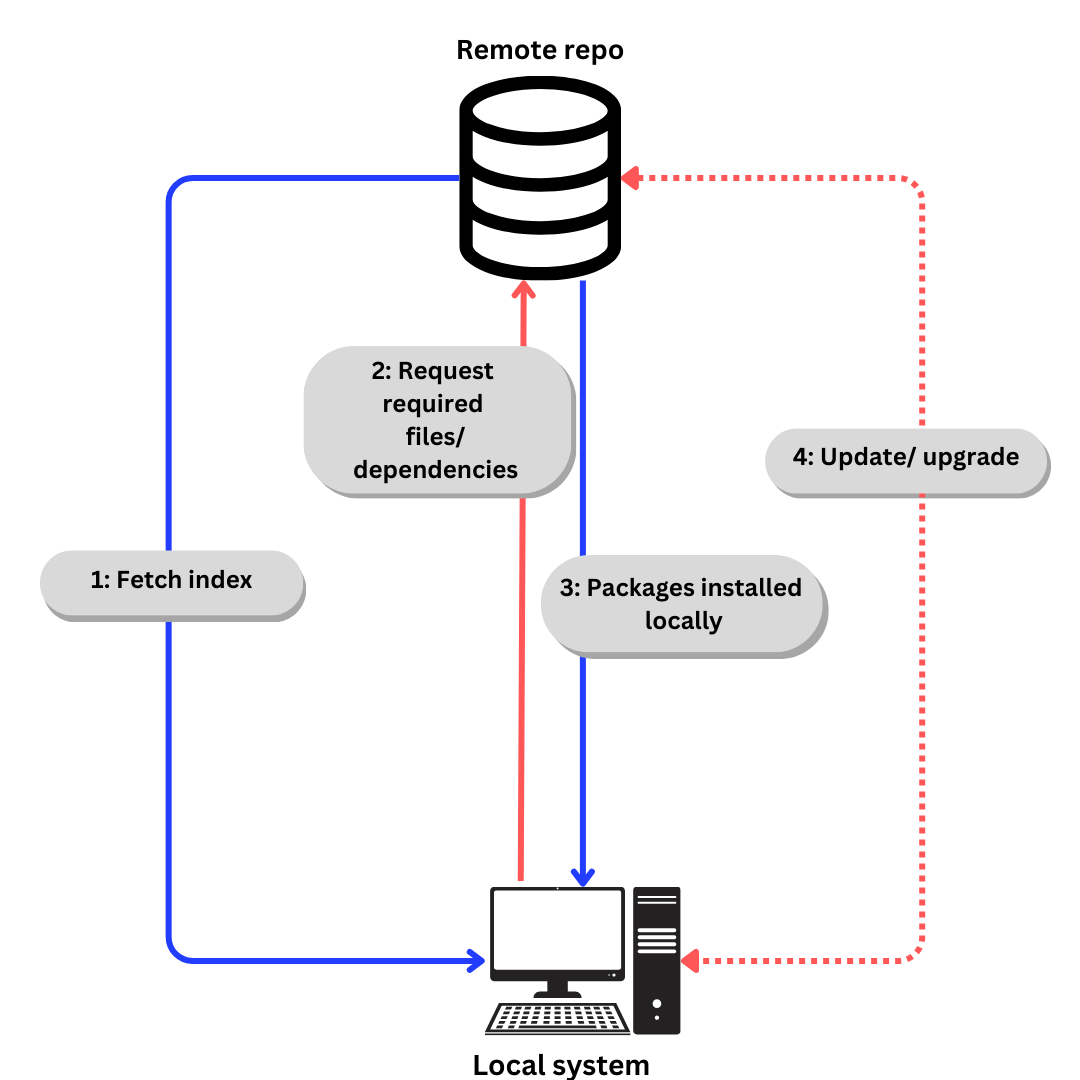
Le processus générique de téléchargement du logiciel depuis un dépôt ressemble à ceci :
- Si nous parlons spécifiquement d’Ubuntu,
- L’index est récupéré à l’aide de
apt update.(aptest expliqué dans la prochaine section). - Les fichiers requis/les dépendances demandées selon l’index à l’aide de
apt install - Les paquets et dépendances sont installés localement.
Mettez à jour les dépendances et les paquets lorsque nécessaire à l’aide de apt update et de apt upgrade
Sur les dérivés de Debian, vous pouvez enregistrer la liste des dépôts (référentiels) dans /etc/apt/sources.list.
7.2. Installer un paquet via la ligne de commande
La commande apt est une puissante interface en ligne de commande qui fonctionne avec le « Advanced Packaging Tool (APT) » d’Ubuntu.
apt, ainsi que les commandes qu’il emsemble, offrent les moyens d’installer de nouveaux paquets logiciels, de mettre à jour les paquets logiciels existants, de mettre à jour l’index de la liste des paquets et même d’upgrader l’ensemble du système Ubuntu.
Pour afficher les journaux d’installation utilisant apt, vous pouvez consulter le fichier /var/log/dpkg.log.
Voici les utilisations de la commande apt :
Installer des paquets
sudo apt install htop
Par exemple, pour installer le paquet htop, vous pouvez utiliser la commande suivante :
Mettre à jour l’index de la liste des paquets
sudo apt update
L’index de la liste des paquets est une liste de tous les paquets disponibles dans les dépôts. Pour mettre à jour l’index de liste local, vous pouvez utiliser la commande suivante :
Mettre à niveau les paquets
Les paquets installés sur votre système peuvent recevoir des mises à jour contenant des correctifs de bugs, des patchs de sécurité et de nouvelles fonctionnalités.
sudo apt upgrade
Pour mettre à niveau les paquets, vous pouvez utiliser la commande suivante :
Supprimer des paquets
sudo apt remove htop
Pour supprimer un paquet, comme htop, vous pouvez utiliser la commande suivante :
7.3. Installer un Paquet via une Méthode Graphique Avancée – Synaptic
Si vous n’êtes pas à l’aise avec la ligne de commande, vous pouvez utiliser une application graphique pour installer des paquets. Vous pouvez obtenir les mêmes résultats que la ligne de commande, mais avec une interface graphique.
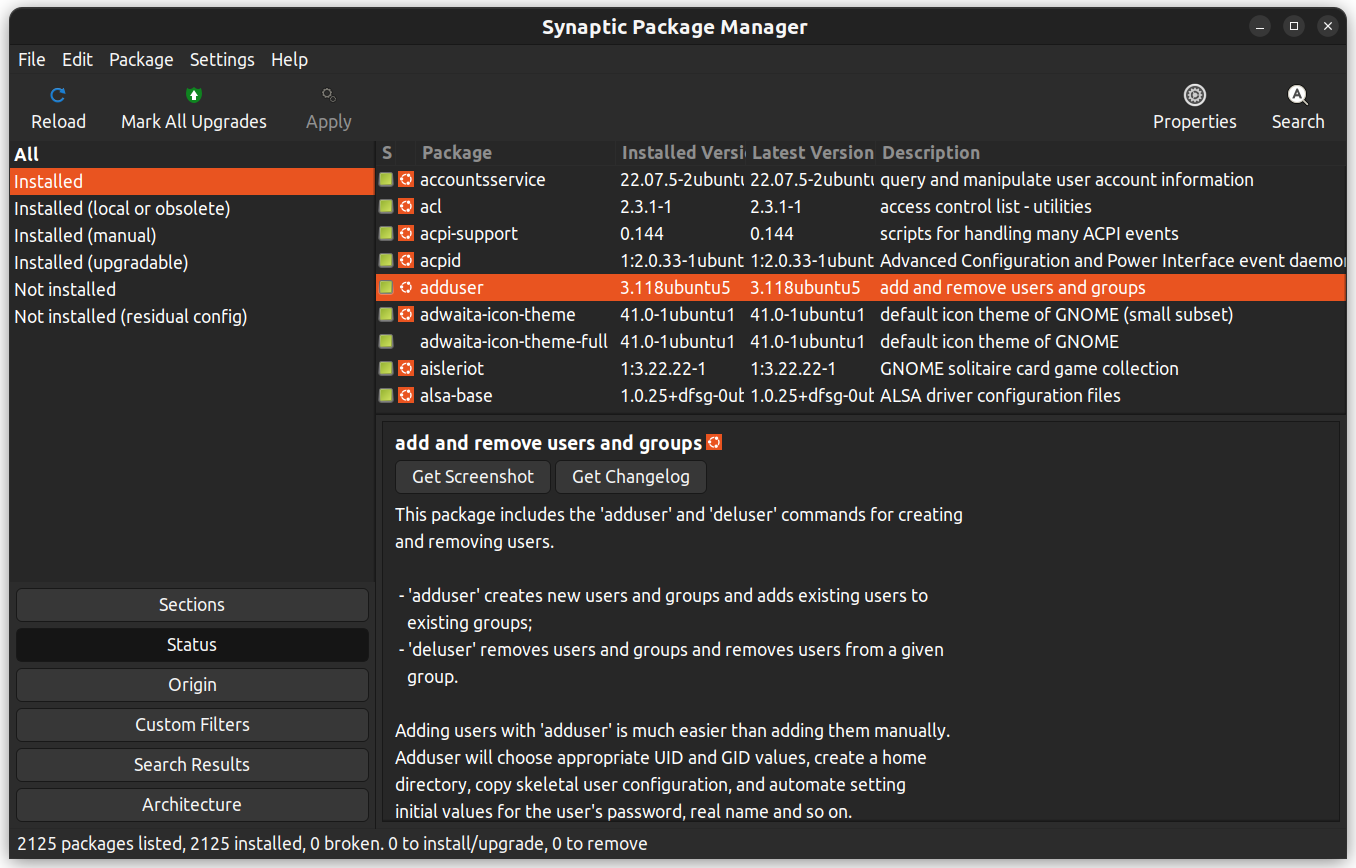
Synaptic est une application de gestion de paquets graphique qui aide à lister les paquets installés, leur état, les mises à jour en attente, etc. Elle offre des filtres personnalisés pour vous aider à réduire les résultats de recherche.
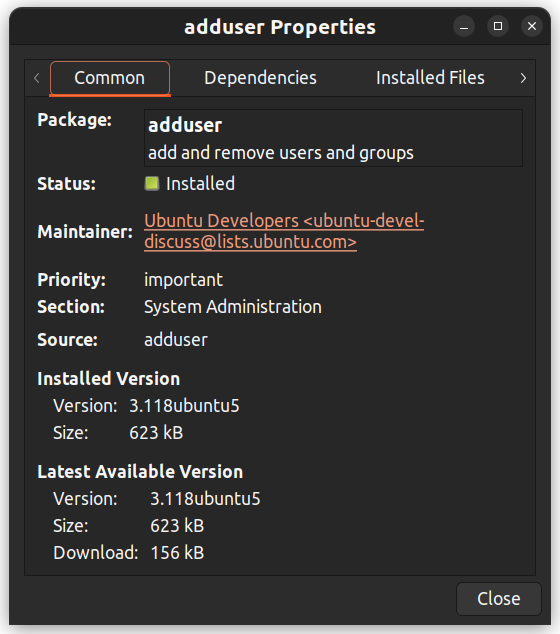
Vous pouvez également cliquer avec le bouton droit sur un paquet et visualiser d’autres détails tels que les dépendances, le maintainer, la taille et les fichiers installés.
7.4. Installation de paquets téléchargés à partir d’un site Web
Vous pouvez également souhaiter installer un paquet que vous avez téléchargé à partir d’un site Web plutôt que d’un dépôt de logiciels. Ces paquets sont appelés fichiers .deb.
cd directory
sudo dpkg -i package_name.deb
En utilisantdpkgpour installer des paquets :dpkg est une interface en ligne de commande utilisée pour installer des paquets. Pour installer un paquet avec dpkg, ouvrez le Terminal et tapez ce qui suit :
Remarque : Remplacez « répertoire » par le répertoire où le paquet est stocké et « nom_du_paquet » par le nom de fichier du paquet.
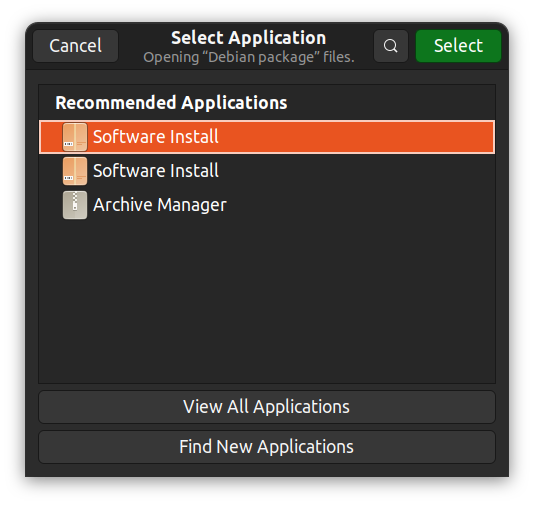
De manière alternative, vous pouvez cliquer avec le bouton droit, sélectionnez « Ouvrir avec une autre application » et choisissez une application graphique de votre choix.
💡 Astuce : Dans Ubuntu, vous pouvez voir une liste des paquets installés avec dpkg --list.
Partie 8 : Sujets avancés sur Linux
8.1. Gestion des utilisateurs
Il peut y avoir plusieurs utilisateurs avec différents niveaux d’accès sur un système. Sur Linux, l’utilisateur root a le niveau d’accès le plus élevé et peut effectuer n’importe quelle opération sur le système. Les utilisateurs réguliers ont des accès limités et ne peuvent effectuer que les opérations pour lesquelles ils ont été autorisés.
Qu’est-ce qu’un utilisateur ?
Un compte utilisateur permet de séparer différentes personnes et programmes qui peuvent exécuter des commandes.
Les humains identifieront les utilisateurs par un nom, car les noms sont faciles à traiter. Toutefois, le système identifie les utilisateurs par un numéro unique appelé l’ID utilisateur (UID).
Lorsque les utilisateurs humains se connectent en utilisant le nom d’utilisateur fourni, ils doivent utiliser un mot de passe pour autoriser leur propre session.
Les comptes utilisateurs constituent les fondations de la sécurité système. La propriété des fichiers est également associée aux comptes utilisateurs et elle impose un contrôle d’accès aux fichiers. Chaque processus est associé à un compte utilisateur qui fournit un niveau de contrôle pour les administrateurs.
- Il existe trois types de comptes utilisateurs principaux :
- Superutilisateur : Le superutilisateur a un accès complet au système. Le nom du superutilisateur est
root. Il possède unUIDégal à 0. - Utilisateur système : L’utilisateur système a des comptes utilisateurs utilisés pour exécuter les services système. Ces comptes sont utilisés pour exécuter les services système et ne sont pas destinés à une interaction humaine.
Utilisateur ordinaire : Les utilisateurs ordinaires sont des utilisateurs humains qui disposent de l’accès au système.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
La commande id affiche l’identifiant utilisateur et le numéro de groupe de l’utilisateur courant.
id username
Pour afficher les informations de base d’un autre utilisateur, passer le nom d’utilisateur en argument à la commande id.
ps -u
Pour afficher des informations liées aux utilisateurs pour les processus, utilisez la commande ps avec l'option -u.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# Sortie
Par défaut, les systèmes utilisent le fichier /etc/passwd pour stocker les informations utilisateur.
root:x:0:0:root:/root:/bin/bash
Voici une ligne du fichier /etc/passwd :
- Le fichier
/etc/passwdcontient les informations suivantes sur chaque utilisateur : - Nom d’utilisateur :
root– Le nom d’utilisateur du compte utilisateur. - Mot de passe :
x– Le mot de passe crypté pour le compte utilisateur stocké dans le fichier/etc/shadowpour des raisons de sécurité. - ID utilisateur (UID) :
0– L’identificateur numérique unique pour le compte utilisateur. - ID groupe (GID) :
0– L’identificateur numérique unique pour le groupe principal du compte utilisateur. - Informations de l’utilisateur :
root– Le nom réel pour le compte utilisateur. - Répertoire personnel :
/root– Répertoire personnel de l’compte utilisateur.
Shell : /bin/bash – Shell par défaut pour l’compte utilisateur. Un utilisateur du système pourrait utiliser /sbin/nologin si les connexions interactives sont interdites pour cet utilisateur.
Qu’est-ce qu’un groupe ?
Un groupe est une collection d’comptes utilisateurs qui partagent l’accès et les ressources. Les groupes ont des noms de groupe pour les identifier. Le système identifie les groupes par un numéro unique appelé l’ID de groupe (GID).
Par défaut, les informations sur les groupes sont stockées dans le fichier /etc/group.
adm:x:4:syslog,john
Voici une entrée du fichier /etc/group :
- Voici le détail des champs dans l’entrée donnée :
- Nom du groupe :
adm– Le nom du groupe. - Mot de passe :
x– Le mot de passe du groupe est stocké dans le fichier/etc/gshadowpour des raisons de sécurité. Le mot de passe est facultatif et est vide si non configuré. - ID de groupe (GID) :
4– L’identifiant numérique unique pour le groupe.
Membres du groupe : syslog,john – La liste des noms d’utilisateurs qui sont membres du groupe. Dans ce cas, le groupe adm a deux membres : syslog et john.
Dans cette entrée spécifique, le nom du groupe est adm, l’ID de groupe est 4, et le groupe a deux membres : syslog et john. Le champ mot de passe est généralement défini sur x pour indiquer que le mot de passe du groupe est stocké dans le fichier /etc/gshadow.
- Les groupes sont divisés en ‘principaux‘ et ‘supplémentaires‘.
- Groupe principal : Chaque utilisateur est assigné par défaut à un seul groupe principal. Ce groupe a généralement le même nom que l’utilisateur et est créé lors de la création du compte utilisateur. Les fichiers et dossiers créés par l’utilisateur sont généralement détenus par ce groupe principal.
Groupes supplémentaires : Ces groupes supplémentaires permettent aux utilisateurs de se retrouver dans plus d’un groupe en plus de leur groupe primaire. Les utilisateurs peuvent être membres de plusieurs groupes supplémentaires. Ces groupes permettent à un utilisateur de disposer des permissions sur les ressources partagées entre ces groupes. Ils facilitent l’accès aux ressources partagées sans affecter les permissions de fichier du système et en conservant la sécurité intégrée. Alors qu’un utilisateur doit appartenir à un seul groupe primaire, l’appartenance à des groupes supplémentaires est optionnelle.
Le contrôle d’accès : trouver et comprendre les permissions de fichier
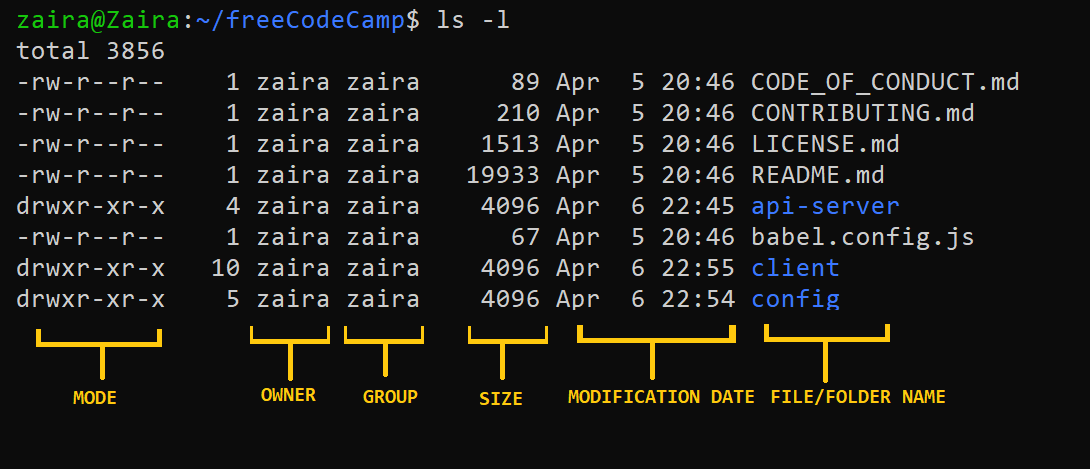
La propriété du fichier peut être consultée en utilisant la commande ls -l. La première colonne de la sortie de la commande ls -l montre les permissions du fichier. Les autres colonnes montrent le propriétaire du fichier et le groupe auquel appartient le fichier.

Examinons plus précisément la colonne mode :
- Mode définit deux choses :
- Type de fichier : Le type de fichier définit le type du fichier. Pour les fichiers normaux contenant des données simples, il est vide
-. Pour d’autres types spéciaux de fichiers, le symbole est différent. Pour un dossier qui est un fichier spécial, il estd. Les fichiers spéciaux sont traités différemment par le système d’exploitation.
Classes de permissions : Le prochain ensemble de caractères définit les permissions pour l’utilisateur, le groupe et les autres respectivement.
– Utilisateur : C’est le propriétaire d’un fichier et le propriétaire du fichier appartient à cette classe.
– Groupe : Les membres du groupe du fichier appartiennent à cette classe
– Autres : Tous les utilisateurs qui ne font pas partie des classes utilisateur ou groupe appartiennent à cette classe.
✨Astuce : Le propriétaire du dossier peut être consulté en utilisant la commande ls -ld.
Comment lire les permissions symboliques ou les permissions rwx
- La représentation
rwxest connue sous le nom de représentation symbolique des permissions. Dans l’ensemble de permissions, rsignifie lire et est indiqué à la première place du triplet.wsignifie écrire et est indiqué à la deuxième place du triplet.
x signifie exécuter et est indiqué à la troisième place du triplet.
Lire :
Pour les fichiers normaux, les permissions de lecture permettent uniquement d’ouvrir et de lire le fichier, sans pouvoir le modifier.
De même pour les dossiers, les permissions de lecture permettent de lister le contenu du dossier sans pouvoir le modifier.
Écrire :
Lorsque les fichiers disposent de permissions d’écriture, l’utilisateur peut modifier (éditer, supprimer) le fichier et le sauvegarder.
Pour les dossiers, les permissions d’écriture permettent à un utilisateur de modifier leur contenu (créer, supprimer et renommer les fichiers à l’intérieur) et modifier le contenu des fichiers auxquels ils disposent de permissions d’écriture.
Exemples de permissions sous Linux
- Maintenant que nous savons comment lire les permissions, voyons quelques exemples.
-
-rw-rw-r--: Un fichier ouvert à la modification par son propriétaire et son groupe, mais pas par les autres.
drwxrwx---: Un répertoire modifiable par son propriétaire et son groupe.
Exécuter:
Pour les fichiers, les permissions d’exécution permettent au utilisateur d’exécuter un script exécutable. Pour les répertoires, l’utilisateur peut y accéder et avoir accès aux détails des fichiers dans le répertoire.
Comment modifier les permissions de fichier et de propriétaire sous Linux en utilisant chmod et chown
Maintenant que nous connaissons les bases de la propriété et des permissions, voyons comment nous pouvons modifier les permissions en utilisant la commande chmod.
chmod permissions filename
Syntaxe dechmod:
- Où,
permissionspeuvent être lecture, écriture, exécution ou une combinaison d’entre elles.
nom_du_fichier est le nom du fichier pour lequel les permissions doivent être modifiées. Ce paramètre peut également être une liste de fichiers pour modifier les permissions en masse.
- Nous pouvons modifier les permissions en utilisant deux modes :
- Mode symbolique :Cette méthode utilise des symboles comme
u,g,opour représenter les utilisateurs, les groupes et les autres. Les permissions sont représentées parr, w, xpour respectivement lire, écrire et exécuter. Vous pouvez modifier les permissions en utilisant +, – et =.
Mode absolu :Cette méthode représente les permissions sous forme de nombres octaux à trois chiffres allant de 0-7.
Maintenant, examinons-les en détail.
Comment modifier les permissions en utilisant le mode symbolique
| Le tableau ci-dessous résume la représentation des utilisateurs : | REPRÉSENTATION DE L’UTILISATEUR |
| u | DESCRIPTION |
| g | utilisateur/proprétaire |
| o | groupe |
autres
| Nous pouvons utiliser des opérateurs mathématiques pour ajouter, retirer et assigner des permissions. Le tableau ci-dessous présente un résumé : | OPÉRATEUR |
| DESCRIPTION | + |
| Ajoute une permission à un fichier ou un répertoire | – |
| Retire la permission | \= |
Définit la permission si elle n’est pas déjà présente. Remplace également les permissions si elles ont été définies auparavant.
Exemple :
Supposons que j’ai un script et que je veuille le rendre exécutable pour le propriétaire du fichier zaira.

Les permissions actuelles du fichier sont les suivantes:
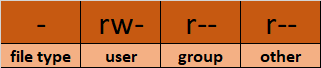
Divisons les permissions comme suit:
chmod u+x mymotd.sh
Pour ajouter les droits d’exécution (x) au propriétaire (u) en utilisant le mode symbolique, nous pouvons utiliser la commande ci-dessous:
Sortie :
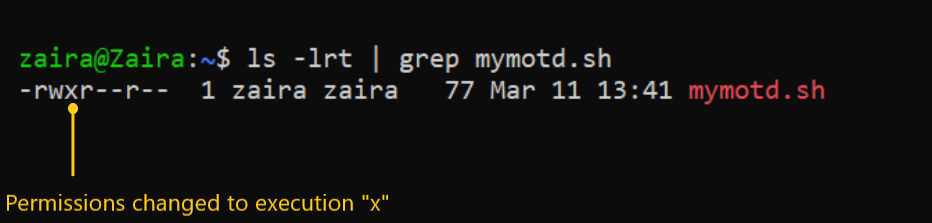
Maintenant, nous pouvons voir que les permissions d’exécution ont été ajoutées pour le propriétaire zaira.
- Exemples supplémentaires pour changer les permissions via la méthode symbolique :
- Suppression des permissions de
lectureetécriturepour legroupeet lesautres:chmod go-rw. - Suppression des permissions de
lecturepour lesautres:chmod o-r.
Attribuer la permission d’écriture au groupe et remplacer la permission existante : chmod g=w.
Comment changer les permissions en utilisant le mode absolu
Le mode absolu utilise des nombres pour représenter les permissions et des opérateurs mathématiques pour les modifier.
| Le tableau ci-dessous montre comment nous pouvons assigner les permissions pertinentes : | PERMISSION |
| FOURNIR LES PERMISSIONS | lire |
| ajouter 4 | écrire |
| ajouter 2 | exécuter |
ajouter 1
| Les permissions peuvent être révoquées en utilisant la soustraction. Le tableau ci-dessous montre comment vous pouvez retirer les permissions pertinentes. | PERMISSION |
| RÉVOKER LES PERMISSIONS | lire |
| soustraire 4 | écrire |
| soustraire 2 | exécuter |
soustraire 1
- EXEMPLE :
Affectez lire (ajouter 4) pour utilisateur, lire (ajouter 4) et exécuter (ajouter 1) pour le groupe, et seulement exécuter (ajouter 1) pour les autres.
chmod 451 nom-du-fichier
C’est ainsi que nous avons effectué le calcul :
- Notez que c’est la même chose que
r--r-x--x.
Enlevez les droits d’exécution aux autres et au groupe.
- Pour enlever l’exécution aux
autreset augroupe, soustraisez 1 de la partie exécuter des derniers deux octets.
Affectez lecture, écriture et exécution à utilisateur, lecture et exécution à groupe et uniquement lecture à les autres.

Cela serait identique à rwxr-xr--.
Comment modifier la propriété d’ownership en utilisant la commande chown
Ensuite, nous apprendrons comment modifier la propriété de ownership d’un fichier. Vous pouvez modifier la propriété de ownership d’un fichier ou d’un dossier en utilisant la commande chown. Dans certains cas, la modification de la propriété de ownership nécessite des permissions de sudo.
chown user filename
Syntaxe de chown:
Comment modifier la propriété d’ownership utilisateur avec chown
Transférez la propriété de l’utilisateur zaira à l’utilisateur news.

chown news mymotd.sh
Commande de modification de la propriété de ownership : sudo chown news mymotd.sh.

Sortie :
Comment modifier la propriété utilisateur et groupe simultanément
chown user:group filename
Nous pouvons également utiliser chown pour modifier l’utilisateur et le groupe simultanément.
Comment modifier la propriété du dossier
chown -R admin /opt/script
Vous pouvez modifier la propriété récursivement pour les contenus dans un dossier. L’exemple ci-dessous change la propriété du dossier /opt/script pour autoriser l’utilisateur admin.
Comment modifier la propriété de groupe
chown :admins /opt/script
Dans le cas où nous n’avons besoin que de modifier le propriétaire du groupe, nous pouvons utiliser chown en précédant le nom du groupe d’un冒号 :
Comment passer d’un utilisateur à un autre
[user01@host ~]$ su user02
Password:
[user02@host ~]$
Vous pouvez basculer entre les utilisateurs en utilisant la commande su.
Comment obtenir l’accès de superutilisateur
Le superutilisateur ou l’utilisateur root a les droits les plus élevés sur un système Linux. L’utilisateur root peut exécuter toutes les opérations sur le système. L’utilisateur root peut accéder à tous les fichiers et dossiers, installer et supprimer des logiciels, et modifier ou ignorer les configurations systèmes.
Avec beaucoup de pouvoir vient beaucoup de responsabilité. Si l’utilisateur root est compromise, quelqu’un pourrait acquérir le contrôle complet sur le système. Il est recommandé d’utiliser le compte root uniquement lorsque nécessaire.
[user01@host ~]$ su
Password:
[root@host ~]Si vous omettez le nom d'utilisateur, la commande su bascule par défaut sur le compte root.
#
Une autre variante de la commande su est su -. La commande su bascule sur le compte root mais ne change pas les variables d’environnement. La commande su - bascule sur le compte root et change les variables d’environnement pour celles de l’utilisateur cible.
Exécuter des commandes avec sudo
Pour exécuter des commandes en tant que superutilisateur sans basculer sur le compte superutilisateur, vous pouvez utiliser la commande sudo. La commande sudo permet de exécuter des commandes avec des privilèges élevés.
Exécuter des commandes avec sudo est une option plus sécurisée que d’exécuter les commandes en tant que superutilisateur. Cela est dû au fait que seuls un ensemble spécifique d’utilisateurs peut être autorisé à exécuter des commandes avec sudo. Cela est défini dans le fichier /etc/sudoers.
Également, sudo enregistre toutes les commandes exécutées avec elle, fournissant ainsi une trace d’audit de qui a exécuté quelles commandes et quand.
cat /var/log/auth.log | grep sudo
Sur Ubuntu, vous pouvez trouver les journaux d’audit ici :
user01 is not in the sudoers file. This incident will be reported.
Pour un utilisateur qui n’a pas accès à sudo, cela est signalé dans les journaux et affiche un message comme celui-ci :
Gestion des comptes utilisateurs locaux
Création d’utilisateurs depuis la ligne de commande
sudo useradd username
La commande utilisée pour ajouter un nouvel utilisateur est :
Cette commande configure le répertoire personnel de l’utilisateur et crée un groupe privé désigné par le nom d’utilisateur de l’utilisateur. Actuellement, le compte manque d’un mot de passe valide, empêchant l’utilisateur de se connecter jusqu’à ce qu’un mot de passe soit créé.
Modification d’utilisateurs existants
La commande usermod est utilisée pour modifier les utilisateurs existants. Voici quelques options courantes utilisées avec la commande usermod :
- Voici quelques exemples de la commande
usermodsous Linux : - Changer le nom d’utilisateur de login :
- Changer le répertoire personnel d’un utilisateur :
- Ajouter un utilisateur à un groupe supplémentaire :
- Changer la shell d’un utilisateur :
- Verrouiller le compte d’un utilisateur :
- Déverrouiller le compte d’un utilisateur :
- Fixer une date d’expiration pour un compte utilisateur :
- Changer l’ID utilisateur (UID) d’un utilisateur :
- Changer le groupe primaire d’un utilisateur :
Retirer un utilisateur d’un groupe supplémentaire :
Suppression d’utilisateurs
- La commande
userdelest utilisée pour supprimer un compte utilisateur et les fichiers associés du système. sudo userdel nom_utilisateur: supprime les détails de l’utilisateur de/etc/passwdmais conserve le dossier personnel de l’utilisateur.
La commande sudo userdel -r nom_utilisateur supprime les détails de l’utilisateur de /etc/passwd et efface également le dossier personnel de l’utilisateur.
Changement des mots de passe utilisateur
- La commande
passwdest utilisée pour changer le mot de passe d’un utilisateur.
sudo passwd nom_utilisateur : définit le mot de passe initial ou modifie le mot de passe existant de nom_utilisateur. Elle est également utilisée pour changer le mot de passe de l’utilisateur actuellement connecté.
8.2 Se connecter à des serveurs distants via SSH
Accéder à des serveurs distants est l’une des tâches fondamentales pour les administrateurs systèmes. Vous pouvez vous connecter à différents serveurs ou accéder aux bases de données à travers votre machine locale et exécuter des commandes, tout en utilisant SSH.
Qu’est-ce que le protocole SSH ?
SSH signifie Secure Shell. Il s’agit d’un protocole de communication cryptographique qui permet une communication sécurisée entre deux systèmes.
Le port par défaut pour SSH est le 22.
- Les deux participants lors de la communication via SSH sont :
- Le serveur : la machine à laquelle vous souhaitez accéder.
Le client : le système à partir duquel vous accédez au serveur.
- La connexion à un serveur se déroule en suivant les étapes suivantes :
- Initiate Connection: The client sends a connection request to the server.
- Exchange of Keys: The server sends its public key to the client. Both agree on the encryption methods to use.
- Session Key Generation: The client and server use the Diffie-Hellman key exchange to create a shared session key.
- Authentification du client : Le client se connecte au serveur en utilisant un mot de passe, une clé privée ou une autre méthode.
Communication sécurisée : Après l’authentification, le client et le serveur communiquent de manière sécurisée avec chiffrement.
Comment se connecter à un serveur distant en utilisant SSH ?
La commande ssh est un utilitaire intégré dans Linux et également celui par défaut. Elle rend l’accès aux serveurs assez simple et sécurisé.
Voici, nous parlons de la façon dont le client établirait une connexion avec le serveur.
- Avant de vous connecter à un serveur, vous devez disposer des informations suivantes :
- L’adresse IP ou le nom de domaine du serveur.
- Le nom d’utilisateur et le mot de passe du serveur.
Le numéro de port auquel vous avez accès sur le serveur.
ssh username@server_ip
La syntaxe de base de la commande ssh est la suivante :
ssh [email protected]
Par exemple, si votre nom d’utilisateur est john et que l’IP du serveur est 192.168.1.10, la commande serait :
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ Après cela, vous serez invité à entrer le mot de passe secret. Votre écran ressemblera à cela :
# commencez à entrer des commandes
Maintenant, vous pouvez exécuter les commandes pertinentes sur le serveur 192.168.1.10.
ssh -p port_number username@server_ip
⚠️ Le port par défaut pour SSH est 22 mais il est également vulnérable, car les hackers essaieront probablement d’y entrer en premier. Votre serveur peut exposer un autre port et partager l’accès avec vous. Pour vous connecter à un port différent, utilisez le drapeau -p.
8.3. Analyse et parsing avancés de journaux
Les fichiers journaux, lorsqu’ils sont configurés, sont générés par votre système pour une variété d’raisons utiles. Ils peuvent être utilisés pour suivre les événements systèmes, surveiller les performances systèmes et résoudre les problèmes. Ils sont particulièrement utiles pour les administrateurs systèmes, car ils peuvent suivre les erreurs des applications, les événements réseaux et l’activité des utilisateurs.
Voici un exemple de fichier journal :
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# fichier journal de l’exemple
- Un fichier journal contient généralement les colonnes suivantes :
- Date et heure : La date et l’heure à laquelle l’événement s’est produit.
- Niveau de journalisation : La gravité de l’événement (INFO, DEBUG, AVERTISSEMENT, ERREUR).
- Composant : Le composant du système qui a généré l’événement (Démarrage, Configuration, Base de données, Utilisateur, Sécurité, Réseau, Courriel, API, Session, Arrêt).
- Message : Une description de l’événement qui s’est produit.
Informations supplémentaires : Informations supplémentaires liées à l’événement.
Dans les systèmes en temps réel, les fichiers de journaux tendent généralement à être longs de milliers de lignes et sont générés chaque seconde. Ils peuvent être très verbeux en fonction de la configuration. Chaque colonne dans un fichier de journal est une information qui peut être utilisée pour retracer les problèmes. Cela rend les fichiers de journal difficiles à lire et à comprendre manuellement.
C’est à ce moment-là que la analyse des journaux intervient. L’analyse des journaux est le processus d’extraction d’informations utiles à partir des fichiers de journal. Il consiste à diviser les fichiers de journal en plus petites parties plus faciles à gérer et à extraire l’information pertinente.
Les informations filtrées peuvent également être utiles pour la création de alertes, de rapports et de tableaux de bord.
Dans cette section, vous explorerez quelques techniques pour analyser les fichiers de journal sous Linux.
Extraction de texte à l’aide de grep
Grep est une utilité intégrée Bash. Il signifie « global regular expression print » (affichez la correspondance de toute expression régulière). Grep est utilisé pour trouver des chaînes dans des fichiers.
- Voici quelques utilisations courantes de
grep: - Cette commande recherche « search_string » dans le fichier nommé
filename. - Cette commande recherche «
search_string» dans tous les fichiers du répertoire spécifié et de ses sous-répertoires. - Cette commande effectue une recherche insensible à la casse pour « search_string » dans le fichier nommé
filename. - Cette commande affiche les numéros de ligne ainsi que les lignes correspondantes dans le fichier nommé
fichier.txt. - Cette commande compte le nombre de lignes contenant « mot_à_chercher » dans le fichier nommé
fichier.txt. - Cette commande affiche toutes les lignes qui ne contiennent pas la « chaîne_de_recherche » dans le fichier nommé
nom_du_fichier. - Cette commande recherche le mot entier « mot » dans le fichier nommé
nom_du_fichier.
Cette commande permet l’utilisation d’expressions régulières étendues pour des correspondances de modèles plus complexes dans le fichier nommé nom_du_fichier.
💡 Astuce : Si il y a plusieurs fichiers dans un dossier, vous pouvez utiliser la commande ci-dessous pour trouver la liste des fichiers contenant les chaînes désirées.
grep -l "String to Match" /path/to/directory
# trouver la liste des fichiers contenant les chaînes désirées
Extraction de texte à l’aide de sed
sed signifie « éditeur de flux ». Il traite les données par flux, ce qui signifie qu’il lit les données ligne par ligne. sed vous permet de rechercher des modèles et d’effectuer des actions sur les lignes qui correspondent à ces modèles.
Syntaxe de base desed:
sed [options] 'command' file_name
La syntaxe de base de sed est la suivante :
Dans cet exemple, commande est utilisée pour effectuer des opérations telles que la substitution, la suppression, l’insertion et ainsi de suite sur les données de texte. Le nom de fichier est le nom du fichier que vous voulez traiter.
sedutilisation :
1. Substitution :
sed 's/old-text/new-text/' filename
Le drapeau s est utilisé pour remplacer du texte. Le ancien-texte est remplacé par nouveau-texte :
sed 's/error/warning/' system.log
Par exemple, pour changer toutes les occurrences de « erreur » en « avertissement » dans le fichier de journalisation system.log :
2. Affichage des lignes contenant un patron spécifique :
sed -n '/pattern/p' filename
Utilisez sed pour filtrer et afficher les lignes correspondant à un patron spécifique :
sed -n '/ERROR/p' system.log
Par exemple, pour trouver toutes les lignes contenant « ERREUR » :
3. Suppression des lignes contenant un patron spécifique :
sed '/pattern/d' filename
Vous pouvez supprimer les lignes de la sortie qui correspondent à un patron spécifique :
sed '/DEBUG/d' system.log
Par exemple, pour supprimer toutes les lignes contenant « DEBUG » :
4. Extraction de champs spécifiques d’une ligne de journal :
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
Vous pouvez utiliser des expressions rationnelles pour extraire des parties de chaînes de caractères. Supposons que chaque ligne de journal commence par une date au format « AAAA-MM-JJ ». Vous pourriez extraire juste la date de chaque ligne :
Analyse de texte avec awk
awk a la capacité de diviser aisément chaque ligne en champs. Il est bien adapté pour traiter des textes structurés tels que les fichiers de journaux.
Syntaxe de base deawk
awk 'pattern { action }' file_name
La syntaxe de base de awk est la suivante :
Dans ceci, motif est une condition que doit remplir chaque ligne pour que l’action soit executée. Si le motif est omis, l’action est executée sur chaque ligne.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- Dans les exemples à venir, vous utiliserez ce fichier de journal comme exemple :
Accéder aux colonnes à l’aide deawk
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
Les champs dans awk (séparés par des espaces par défaut) peuvent être accessibles en utilisant $1, $2, $3, et ainsi de suite.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# sortie
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # sortie
awk '/ERROR/ { print $0 }' logfile.log
Imprimer les lignes contenant un patron spécifique (par exemple, ERREUR)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# sortie
- Ceci imprimera toutes les lignes contenant « ERREUR ».
awk '{ print $1, $2 }' logfile.log
Extraire le premier champ (Date et Heure)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# sortie
- Cela extraira les deux premiers champs de chaque ligne, qui dans ce cas seraient la date et l’heure.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
Récapituler les occurrences de chaque niveau de journal
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# Sortie
- La sortie sera un résumé du nombre d’occurrences de chaque niveau de journalisation.
awk '{ $3="INFO"; print }' sample.log
Filtrer des champs spécifiques (par exemple, où le 3ème champ est INFO)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# Sortie
Cette commande extraira toutes les lignes où le 3ème champ est « INFO ».
💡 Astuce : Le séparateur par défaut dans awk est un espace. Si votre fichier de journal utilise un séparateur différent, vous pouvez le spécifier en utilisant l’option -F. Par exemple, si votre fichier de journal utilise une virgule comme séparateur, vous pouvez utiliser awk -F, '{ print $1 }' fichierlog.log pour extraire le premier champ.
Le traitement de fichiers de journal avec cut
La commande cut est une commande simple mais puissante utilisée pour extraire des sections de texte de chaque ligne d’entrée. Comme les fichiers de journal sont structurés et chaque champ est délimité par un caractère spécifique, tel qu’un espace, une tabulation ou un délimiteur personnalisé, cut fait un excellent travail d’extraction de ces champs spécifiques.
cut [options] [file]
La syntaxe de base de la commande cut est :
- Certaines options couramment utilisées pour la commande cut :
-d: Spécifie un délimiteur utilisé comme séparateur de champs.-f: Sélectionne les champs à afficher.
-c : Spécifie les positions des caractères.
cut -d ' ' -f 1 logfile.log
Par exemple, la commande ci-dessous extraira le premier champ (séparé par un espace) de chaque ligne du fichier de logs :
Exemples d’utilisationcutpour l’analyse des logs
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
En supposant que vous avez un fichier de logs structuré comme suit, où les champs sont séparés par un espace :
cutpeut être utilisé de la manière suivante :
cut -d ' ' -f 2 system.log
Extraction de l'heure à partir de chaque entrée de journal :
08:23:01
08:24:15
08:25:02
...
# Sortie
- Cette commande utilise un espace comme séparateur et sélectionne le second champ, qui est le composant de l’heure de chaque entrée de journal.
cut -d ' ' -f 4 system.log
Extraction des adresses IP des journaux :
192.168.1.10
192.168.1.10
10.0.0.5
# Sortie
- Cette commande extrait le quatrième champ, qui est l’adresse IP de chaque entrée de journal.
cut -d ' ' -f 3 system.log
Extraction des niveaux de journal (INFO, WARNING, ERROR) :
INFO
WARNING
ERROR
# Sortie
- Cela extrait le troisième champ qui contient le niveau de journal.
Combinaisoncutavec d’autres commandes :
grep "ERROR" system.log | cut -d ' ' -f 1,2
La sortie d'autres commandes peut être acheminée à la commande cut. Disons que vous voulez filtrer les journaux avant de les couper. Vous pouvez utiliser grep pour extraire les lignes contenant "ERROR" puis utiliser cut pour obtenir des informations spécifiques dans ces lignes :
2024-04-25 08:25:02
# Sortie
- Cette commande filtre d’abord les lignes contenant « ERREUR », puis extrait la date et l’heure de ces lignes.
Extraction de multiples champs :
cut -d ' ' -f 1,2,3 system.log`
Il est possible d'extraire plusieurs champs en même temps en spécifiant un intervalle ou une liste des champs séparés par des virgules :
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# Sortie
La commande ci-dessus extrait les trois premiers champs de chaque entrée de journal qui sont la date, l’heure et le niveau de journalisation.
Analyse de fichiers de journaux avec sort et uniq
Trier et enlever les doublons sont des opérations courantes lors de la manipulation de fichiers de journaux. Les commandes sort et uniq sont des commandes puissantes utilisées pour trier et enlever les doublons de l’entrée respectivement.
Syntaxe de base de sort
sort [options] [file]
La commande sort organise les lignes de texte alphabétiquement ou numériquement.
- Certaines options clés pour la commande sort :
-n: Tri du fichier en supposant que le contenu est numérique.-r: Inverse l’ordre de tri.-k: Spécifie une clé ou numéro de colonne pour trier sur.
-u : Tri et enlève les lignes dupliquées.
La commande uniq est utilisée pour filtrer ou compter et rapporter les lignes répétées dans un fichier.
uniq [options] [input_file] [output_file]
La syntaxe de uniq est :
- Certaines options clés pour la commande
uniqsont : -c: Préfixe les lignes par le nombre d’occurrences.-d: Ne publie que les lignes duplicatives.
-u : Ne publie que les lignes uniques.
Exemples d’utilisation de sort et uniq ensemble pour la lecture de journaux
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Supposons les entrées de journal suivantes pour ces démonstrations :
sort system.log
Tri des entrées de journal par date :
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Sortie
- Ce tri alphabetique des entrées de journal les trie effectivement par date si la date est le premier champ.
sort system.log | uniq
Tri et suppression des lignes duplicatives :
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Sortie
- Cette commande trie le fichier de journal et le ledit au
uniq, en supprimant les lignes duplicatives.
sort system.log | uniq -c
Compte des occurrences de chaque ligne :
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# Sortie
- Trie les entrées de journal puis compte chaque ligne unique. Selon la sortie, la ligne
'2024-04-25 INFO User logged in successfully.'a apparu 2 fois dans le fichier.
sort system.log | uniq -u
Identification d'enregistrements de journal uniques:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# Sortie
- Cette commande affiche les lignes qui sont uniques.
sort -k2 system.log
Tri par niveau de journal:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# Sortie
Le tri est basé sur le deuxième champ, qui est le niveau de journal.
8.4. Gestion des processus Linux via la ligne de commande
- Un processus est une instance en cours d’exécution d’un programme. Un processus se compose de :
- Un espace d’adresse de la mémoire allouée.
- Des états de processus.
Des propriétés telles que la propriété, les attributs de sécurité et l’utilisation des ressources.
- Un processus a également un environnement composé de :
- Variables locales et globales
- Le contexte de planification actuel
Ressources système allouées, telles que les ports réseau ou les descripteurs de fichiers.
Lorsque vous exécutez la commande ls -l, le système d’exploitation crée un nouveau processus pour exécuter la commande. Le processus a un ID, un état et s’exécute jusqu’à ce que la commande soit complétée.
Comprendre la création de processus et leur cycle de vie.
Dans Ubuntu, toutes les processus proviennent du processus système initial nommé systemd, qui est le premier processus lancé par le noyau au démarrage.
Le processus systemd possède un identifiant de processus (PID) de 1 et est responsable de l’initialisation du système, du démarrage et de la gestion des autres processus, ainsi que de l’ handling des services système. Tous les autres processus sur le système sont des descendants de systemd.
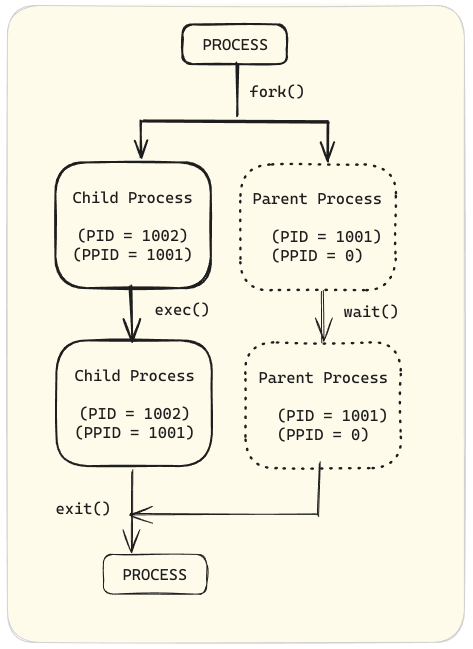
Un processus parent duplique son propre espace d’adresse pour créer une nouvelle structure de processus (enfant). Chaque nouveau processus est assigné un identifiant de processus unique (PID) pour le suivi et les raisons de sécurité. Le PID et l’identifiant de processus du parent (PPID) font partie de l’environnement du nouveau processus. Tout processus peut créer un processus enfant.
Grâce à la routine de duplication, un processus enfant hérite des identités de sécurité, des descripteurs de fichier précédents et actuels, des privilèges de port et de ressources, des variables d’environnement et du code du programme du processus parent. L’enfant peut alors exécuter son propre code de programme.
En général, un processus parent dort tandis que l’enfant s’exécute, en plaçant une demande (wait) pour être notifié lorsque l’enfant est terminé.
Lorsque le processus enfant se termine, il a déjà fermé ou éliminé ses ressources et son environnement. La seule ressource restante, appelée une « zombie », est une entrée dans la table des processus. Le parent, signalé comme étant réveillé lorsque l’enfant quitte, nettoie la table des processus de l’entrée de l’enfant, libérant ainsi la dernière ressource du processus enfant. Le processus parent continue ensuite l’exécution de son propre code de programme.
Comprendre les états des processus.

Les processus sous Linux adoptent différents états au cours de leur cycle de vie. L’état d’un processus indique ce que le processus est actuellement en train de faire et comment il interagit avec le système. Les processus transitionnent entre les états en fonction de leur statut d’exécution et de l’algorithme de planification du système.
| Les processus d’un système Linux peuvent être dans l’un des états suivants : | État |
| Description | (new) |
| État initial quand un processus est créé par une appel système fork. | Exécutable (prêt) (R) |
| Le processus est prêt à s’exécuter et attend d’être planifié sur un processeur CPU. | Exécutable (utilisateur) (R) |
| Le processus s’exécute en mode utilisateur, en cours d’exécuter des applications utilisateur. | Exécutable (noyau) (R) |
| Le processus s’exécute en mode noyau, en traitant des appels système ou des interruptions matérielles. | En attente (S) |
| Le processus attend un événement (par exemple, une opération d’E/S) pour s’achever et peut être aisément réveillé. | En attente (non interrompible) (D) |
| Le processus est dans un état d’attente non interrompible, en attente de une condition spécifique (généralement une E/S) pour s’achever, et ne peut pas être interrompu par des signaux. | En attente (sommeil disque) (K) |
| Le processus attend que les opérations d’E/S disque soient terminées. | En attente (inactif) (I) |
| Le processus est inactif, ne fait aucun travail, et attend qu’un événement se produise. | Arrêté (T) |
| L’exécution du processus a été arrêtée, généralement par un signal, et peut être reprise plus tard. | Zombie (Z) |
Le processus a terminé l’exécution mais conserve toujours une entrée dans la table des processus, en attendant que son parent lise son état de sortie.
| Les processus passent entre ces états de la manière suivante : | Transition |
| Description | Fork |
| Créé un nouveau processus à partir d’un processus parent, passant de (nouveau) à Exécutable (prêt) (R). | Planification |
| Le planificateur sélectionne un processus exécutable, le passant à l’état En cours d’exécution (utilisateur) ou En cours d’exécution (noyau). | Exécution |
| Le processus passe d’Exécutable (prêt) (R) à En cours d’exécution (noyau) (R) lorsqu’il est planifié pour l’exécution. | Préemption ou Réplanification |
| Le processus peut être préempté ou réplanifié, revenant à l’état Exécutable (prêt) (R). | Appel système |
| Le processus effectue une appel système, passant de En cours d’exécution (utilisateur) (R) à En cours d’exécution (noyau) (R). | Retour |
| Le processus termine un appel système et retourne à En cours d’exécution (utilisateur) (R). | Attente |
| Le processus attend un événement, passant d’En cours d’exécution (noyau) (R) à l’une des états De sommeil (S, D, K ou I). | Événement ou Signal |
| Le processus est réveillé par un événement ou une signalisation, le ramenant d’un état de veille vers un état exécutable (prêt) (R). | Suspendre |
| Le processus est suspendu, passant d’un état en cours d’exécution (kernel) ou prêt à un état arrêté (T). | Reprendre |
| Le processus est repris, passant d’un état arrêté (T) vers un état exécutable (prêt) (R). | Sortir |
| Le processus se termine, passant d’un état en cours d’exécution (utilisateur) ou en cours d’exécution (kernel) vers un état fantôme (Z). | Recueillir |
Le processus parent lit le statut de sortie du processus fantôme, le retirant de la table des processus.
Comment afficher les processus
zaira@zaira:~$ ps aux
Vous pouvez utiliser la commande ps en combinaison avec plusieurs options pour afficher les processus sur un système Linux. La commande ps est utilisée pour afficher des informations sur un sélection d'processus actifs. Par exemple, ps aux affiche tous les processus en cours d'exécution sur le système.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Sortie
- La sortie ci-dessus montre une capture instantanée des processus en cours d’exécution sur le système. Chaque ligne représente un processus avec les colonnes suivantes :
UTILISATEUR: L’utilisateur qui possède le processus.PID: L’ID du processus.%CPU: L’utilisation du CPU du processus.%MEM: L’utilisation de la mémoire du processus.VSZ: La taille de la mémoire virtuelle du processus.RSS: La taille du ensemble résident, c’est-à-dire la mémoire physique non échangeée que task a utilisée.TTY: Le terminal de contrôle du processus. Une?indique qu’il n’y a pas de terminal de contrôle.Ss: Le leader de session. Il s’agit d’un processus qui a commencé une session, et il est le leader d’un groupe de processus et peut contrôler les signaux du terminal. Le premierSindique l’état de veille, et le secondsindique qu’il est un leader de session.DEBUT: Le temps ou la date de démarrage du processus.TEMPS: Le temps CPU cumulé.
COMMANDE : La commande qui a lancé le processus.
Processus en arrière-plan et en avant-plan
Dans cette section, vous apprendrez comment vous pouvez contrôler les tâches en les exécutant en arrière-plan ou en avant-plan.
Une tâche est un processus lancé par une console. Lorsque vous exécutez une commande dans le terminal, elle est considérée comme une tâche. Une tâche peut tourner en avant-plan ou en arrière-plan.
- Pour démontrer la gestion, vous allez d’abord créer 3 processus et les exécuter ensuite en arrière-plan. Par la suite, vous afficherez les processus et les alternerez entre l’avant-plan et l’arrière-plan. Vous verrez comment les mettre en veille ou les arrêter complètement.
Créer trois processus
Ouvrez un terminal et lancez trois processus de longue durée. Utilisez la commande sleep, qui permet de maintenir le processus en fonction pendant un nombre spécifié de secondes.
sleep 300 &
sleep 400 &
sleep 500 &
# Executez la commande sleep pour 300, 400 et 500 secondes
- Le caractère
&à la fin de chaque commande permet de déplacer le processus en arrière-plan.
Afficher les tâches en arrière-plan
jobs
Utilisez la commande jobs pour afficher la liste des tâches en arrière-plan.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- La sortie devrait ressembler à ceci :
Transférer une tâche en arrière-plan en avant-plan
fg %1
Pour transférer une tâche en arrière-plan en avant-plan, utilisez la commande fg suivie du numéro de la tâche. Par exemple, pour transférer la première tâche (sleep 300) en avant-plan :
- Cela amènera la tâche
1en avant-plan.
Transférer une tâche en avant-plan en arrière-plan
Tout en travaillant à l’avant-plan, vous pouvez suspendre ce travail en appuyant sur Ctrl+Z pour le suspendre.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
Un travail suspendu ressemblera à ceci :
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# Travail suspendu
Maintenant, utilisez la commande bg pour reprendre le travail avec l'ID 1 en arrière-plan.
# Appuyez sur Ctrl+Z pour suspendre le travail de l'avant-plan
bg %1
- # Puis, le relancez en arrière-plan
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Affichez à nouveau les travaux
- Dans cet exercice, vous :
- Démarrez trois processus arrière-plan avec des commandes sleep.
- Utilisez les jobs pour afficher la liste des travaux en arrière-plan.
- Affichez un travail à l’avant-plan avec
fg %job_number. - Suspendez le travail avec
Ctrl+Zet le replacez en arrière-plan avecbg %job_number.
Utilisez à nouveau les jobs pour vérifier l’état des travaux en arrière-plan.
Maintenant, vous savez comment contrôler les travaux.
Tuer les processus
Il est possible de terminer un processus non responsable ou non désiré en utilisant la commande kill. La commande kill envoie un signal à un ID de processus, lui demandant de se terminer.
Plusieurs options sont disponibles avec la commande kill.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# Options disponibles avec kill
- Voici quelques exemples de la commande
killsous Linux : - Cette commande envoie le signal par défaut
SIGTERMau processus ayant le PID 1234, l’ayant à se terminer. - Cette commande envoie le signal par défaut
SIGTERMà tous les processus ayant le nom spécifié. - Cette commande envoie le signal
SIGKILLau processus avec le PID 1234, l’arrêtant de force. - Cette commande envoie le signal
SIGSTOPau processus avec le PID 1234, le arrêtant.
Cette commande envoie le signal par défaut SIGTERM à tous les processus possédés par l’utilisateur spécifié.
Ces exemples montrent diverses manières d’utiliser la commande kill pour gérer les processus dans un environnement Linux.
Voici l’information sur les options de la commande kill et les signaux sous forme de tableau : Ce tableau résume les options de commande kill et les signaux les plus communs utilisés dans Linux pour gérer les processus. |
Commande / Option | Signal |
| Description | kill |
SIGTERM |
| Demande que le processus se termine avec grâce (signal par défaut). | kill -9 |
SIGKILL |
| Force le processus à se terminer immédiatement sans nettoyage. | kill -SIGKILL |
SIGKILL |
| Force le processus à se terminer immédiatement sans nettoyage. | kill -15 |
SIGTERM |
Envoie explicitement le signal SIGTERM pour demander une arrêt avec grâce. |
kill -SIGTERM |
SIGTERM |
Envoie explicitement le signal SIGTERM pour demander une arrêt avec grâce. |
kill -1 |
SIGHUP |
| Signifie traditionnellement « hang up »; peut être utilisé pour recharger les fichiers de configuration. | kill -SIGHUP |
SIGHUP |
| Traditionnellement, il s’agit de « hang up »; peut être utilisé pour recharger les fichiers de configuration. | kill -2 <pid> |
SIGINT |
Demande au processus de se terminer (même que presser Ctrl+C dans le terminal). |
kill -SIGINT <pid> |
SIGINT |
Demande au processus de se terminer (même que presser Ctrl+C dans le terminal). |
kill -3 <pid> |
SIGQUIT |
| Fait terminer le processus et produit un core dump pour le debug. | kill -SIGQUIT <pid> |
SIGQUIT |
| Fait terminer le processus et produit un core dump pour le debug. | kill -19 <pid> |
SIGSTOP |
| Met en pause le processus. | kill -SIGSTOP <pid> |
SIGSTOP |
| Met en pause le processus. | kill -18 <pid> |
SIGCONT |
| Reprend un processus mis en pause. | kill -SIGCONT <pid> |
SIGCONT |
| Reprend un processus mis en pause. | killall <name> |
Variable |
| Envoie un signal à tous les processus du nom donné. | killall -9 <name> |
SIGKILL |
| Voici la traduction en français :
Tue tous les processus portant le nom donné. |
pkill <modèle> |
Variable |
| Envoie un signal aux processus en fonction d’une correspondance de modèle. | pkill -9 <modèle> |
SIGKILL |
| Tue de force tous les processus correspondant au modèle. | xkill |
SIGKILL |
Utilitaire graphique qui permet de tuer le processus correspondant en cliquant sur une fenêtre.
8.5. Flux d’entrée et de sortie standards dans Linux
- La lecture d’une entrée et l’écriture d’une sortie font partie intégrante de la compréhension de la ligne de commande et du script d’interpréteur. Dans Linux, chaque processus a trois flux par défaut :
- Le descripteur de fichier pour
stdinest0. - Sortie standard (
stdout) : Il s’agit de la sortie par défaut où un processus écrit son sortie. Par défaut, la sortie standard est l’interface terminal. La sortie peut également être redirigée vers un fichier ou un autre programme. Le descripteur de fichier pourstdoutest1.
Sortie d’erreur standard (stderr) : Il s’agit de l’intervalle d’erreur par défaut où un processus écrit ses messages d’erreur. Par défaut, la sortie d’erreur standard est l’interface terminal, ce qui permet de voir les messages d’erreur même si stdout est redirigée. Le descripteur de fichier pour stderr est 2.
Redirection et canaux d’appels
Redirection : Vous pouvez rediriger les intervalles d'erreur et de sortie vers des fichiers ou d'autres commandes. Par exemple :
ls > output.txt
# Redirection de stdout vers un fichier
ls non_existent_directory 2> error.txt
# Redirection de stderr vers un fichier
ls non_existent_directory > all_output.txt 2>&1
# Redirection de stdout et stderr vers un fichier
- Dans la dernière commande,
ls non_existent_directory: affiche le contenu d’un répertoire nommé non_existent_directory. Comme ce répertoire n’existe pas, la commandelsgénérera un message d’erreur.> all_output.txt: L’opérateur>redirige la sortie standard (stdout) de la commandelsvers le fichierall_output.txt. Si le fichier n’existe pas, il sera créé. Si il existe déjà, son contenu sera écrasé.
2>&1:: Ici, 2 représente le descripteur de fichier pour l’erreur standard (stderr). &1 représente le descripteur de fichier pour la sortie standard (stdout). Le caractère & est utilisé pour indiquer que 1 n’est pas un nom de fichier mais un descripteur de fichier.
Donc, 2>&1 signifie « rediriger stderr (2) vers l’emplacement actuel de stdout (1), » ce qui, dans ce cas, est le fichier all_output.txt. Par conséquent, les deux sorties (si il y en avait) et les messages d’erreur de ls seront écrits dans all_output.txt.
Pipelines :
ls | grep image
Vous pouvez utiliser les tubes (|) pour passer la sortie d'un ordre comme entrée pour un autre :
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Sortie
8.6 Automatisation sous Linux – Automatiser des tâches avec des emplois cron
Cron est une utilité puissante pour la planification de tâches disponible dans les systèmes d’exploitation Unix-like. En configurant cron, vous pouvez établir des tâches automatisées qui s’exécutent sur une base quotidienne, hebdomadaire, mensuelle ou à d’autres horaires spécifiques. Les capacités d’automatisation fournies par cron jouent un rôle crucial dans l’administration des systèmes Linux.
Le démon crond (un type de programme informatique qui s’exécute en arrière-plan) permet la fonctionnalité de cron. Cron lit les crontab (tables de cron) pour exécuter des scripts prédéfinis.
En utilisant une syntaxe spécifique, vous pouvez configurer un emploi cron pour planifier les scripts ou d’autres commandes pour s’exécuter automatiquement.
Quelles sont les tâches cron sous Linux ?
Toutes les tâches que vous programmez via les crons sont appelées des emplois cron.
Maintenant, voyons comment les emplois cron fonctionnent.
Comment contrôler l’accès aux crons
Afin d’utiliser les emplois cron, un administrateur doit autoriser l’ajout d’emplois cron pour les utilisateurs dans le fichier /etc/cron.allow.
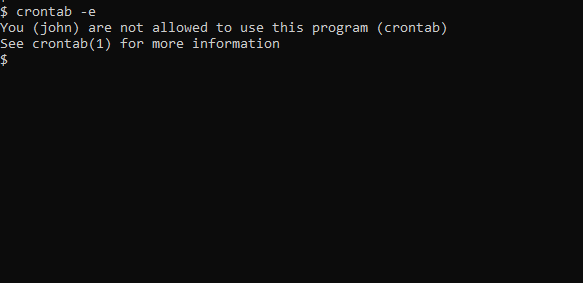
Si vous obtenez un avertissement comme celui-ci, c’est que vous n’avez pas l’autorisation d’utiliser cron.
![]()
Pour autoriser John à utiliser les crons, ajoutez son nom dans /etc/cron.allow. Créez le fichier s’il n’existe pas. Cela permettra à John de créer et de modifier des emplois de cron.
Les utilisateurs peuvent également être refusés l’accès à l’emploi de cron en entrant leurs noms d’utilisateur dans le fichier /etc/cron.d/cron.deny.
Comment ajouter des emplois de cron sous Linux
Premièrement, pour utiliser les emplois de cron, vous devez vérifier le statut du service cron. Si le cron n'est pas installé, vous pouvez facilement le télécharger via le gestionnaire de paquets. Utilisez juste cette commande pour vérifier :
sudo systemctl status cron.service
# Vérifier le service cron sur un système Linux
Syntaxe des emplois de cron
- Les crontabs utilisent les flags suivants pour ajouter et lister les emplois de cron :
crontab -e: édite les entrées de crontab pour ajouter, supprimer ou modifier des emplois de cron.crontab -l: liste tous les emplois de cron pour l’utilisateur actuel.crontab -u username -l: liste les crons d’un autre utilisateur.
crontab -u username -e : édite les crons d’un autre utilisateur.
Lorsque vous listez les crons et qu'ils existent, vous verrez quelque chose comme ceci :
* * * * * sh /path/to/script.sh
# Exemple de tâche planifiée (cron job)
- Dans l’exemple ci-dessus,
* représente les minutes, heures, jours, mois et jours de la semaine respectivement. Voir les détails de ces valeurs ci-dessous : |
VALEUR | |
| DESCRIPTION | Minutes | 0-59 |
| La commande sera exécutée à la minute spécifique. | Heures | 0-23 |
| La commande sera exécutée à l’heure spécifique. | Jours | 1-31 |
| Les commandes seront exécutées dans ces jours du mois. | Mois | 1-12 |
| Le mois pendant lequel les tâches doivent être exécutées. | Jours de la semaine | 0-6 |
- Jours de la semaine où les commandes seront exécutées. Ici, 0 est dimanche.
shsignifie que le script est un script bash et doit être exécuté à partir de/bin/bash.
/path/to/script.sh spécifie le chemin vers le script.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
Voici un résumé de la syntaxe de la tâche planifiée (cron job) :
Exemples de tâches planifiées
| Voici quelques exemples de planification de tâches cron. | HORAIRE |
| VALEUR PRÉVUE | 5 0 * 8 * |
| A 00:05 en août. | 5 4 * * 6 |
| A 04:05 le samedi. | 0 22 * * 1-5 |
A 22:00 tous les jours de la semaine du lundi au vendredi.
Il est acceptable que vous ne soyez pas capable de comprendre tout cela en une seule fois. Vous pouvez pratiquer et générer des horaires cron avec le site web crontab guru.
Comment configurer un job cron
- Dans cette section, nous verrons un exemple de la façon de planifier une simple script avec un job cron.
#!/bin/bash
echo `date` >> date-out.txt
Créez un script appelé date-script.sh qui affiche la date et l’heure système et l’ajoute au fichier. Le script est montré ci-dessous :
chmod 775 date-script.sh
2. Donnez au script des droits d’exécution en le rendant exécutable.
3. Ajoutez le script dans le crontab en utilisant crontab -e.
*/1 * * * * /bin/sh /root/date-script.sh
Ici, nous l’avons programmé pour s’exécuter tous les minutes.
cat date-out.txt
4. Vérifiez le contenu du fichier date-out.txt. Selon le script, la date système devrait être imprimée dans ce fichier tous les minutes.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# sortie
Comment dépaner les crons
Les crons sont très utiles, mais ils ne fonctionnent pas toujours comme prévu. Heureusement, il existe quelques méthodes efficaces que vous pouvez utiliser pour le dépannage.
1. Vérifiez le calendrier.
Tout d’abord, vous pouvez essayez de vérifier le calendrier de planification des crons. Vous pouvez le faire avec la syntaxe que vous avez vue dans les sections précédentes.
2. Vérifier les journaux cron.
Tout d’abord, vous devez vérifier si le cron s’est exécuté à l’heure prévue ou non. Sur Ubuntu, vous pouvez vérifier cela à partir des journaux cron situés à /var/log/syslog.
Si une entrée est présente dans ces journaux à l’heure correcte, cela signifie que le cron s’est exécuté selon le calendrier que vous avez configuré.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
Voici les journaux de l’exemple de tâche cron. Notez la première colonne qui montre l’horodatage. Le chemin du script est également mentionné à la fin de la ligne. Les lignes 1, 3 et 5 montrent que le script s’est exécuté comme prévu.
3. Rediriger l’affichage du cron vers un fichier.
Vous pouvez rediriger l'affichage d'une tâche cron vers un fichier et vérifier le fichier pour toute erreur possible.
* * * * * sh /path/to/script.sh &> log_file.log
# Rediriger l’affichage du cron vers un fichier
8.7. Basiques de réseautique sous Linux
Linux offre un certain nombre de commandes pour afficher des informations relatives à la réseau. Dans cette section, nous discuterons brièvement quelques-unes de ces commandes.
Afficher les interfaces réseau avec ifconfig
ifconfig
La commande ifconfig donne des informations sur les interfaces réseau. Voici un exemple d'affichage :
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# Sortie
L’affichage de la commande ifconfig montre les interfaces réseau configurées sur le système, en plus de détails tels que les adresses IP, les adresses MAC, les statistiques des paquets et plus.
Ces interfaces peuvent être des périphériques physiques ou virtuels.
Pour extraire les adresses IPv4 et IPv6, vous pouvez utiliser ip -4 addr et ip -6 addr, respectivement.
Afficher l’activité réseau avecnetstat
La commande netstat montre l’activité et les statistiques réseau en fournissant les informations suivantes :
- Voici quelques exemples d’utilisation de la commande
netstaten ligne de commande : - Afficher toutes les sockets en écoute et non en écoute :
- Afficher uniquement les ports en écoute :
- Afficher les statistiques réseau :
- Afficher la table de routage :
- Afficher les connexions TCP :
- Afficher les connexions UDP :
- Afficher les interfaces réseau :
- Afficher les PID et les noms des programmes pour les connexions :
- Afficher les statistiques pour un protocole spécifique (par exemple, TCP) :
Afficher des informations étendues :
Vérifier la connectivité réseau entre deux appareils en utilisant ping
ping google.com
ping est utilisé pour tester la connectivité réseau entre deux appareils. Il envoie des paquets ICMP vers l’appareil cible et attend une réponse.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping teste si vous obtenez une réponse sans avoir un timeout.
— google.com ping statistiques —
Vous pouvez arrêter la réponse en utilisant Ctrl + C.
Tester les points de terminaison avec la commande curl
- La commande
curlsignifie « client URL ». Elle est utilisée pour transférer des données vers ou à partir d’un serveur. Elle peut également être utilisée pour tester les points de terminaison d’API, ce qui aide dans la détection des problèmes systèmes et d’applications.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- Par exemple, vous pouvez utiliser
http://www.official-joke-api.appspot.com/pour expérimenter avec la commandecurl.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
La commande curl sans aucune option utilise la méthode GET par défaut.
curl -oenregistre la sortie dans le fichier mentionné.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# enregistre la sortie dans random_joke.json
curl -I ne récupère que les en-têtes.
8.8. Résolution des problèmes sous Linux : outils et techniques
Rapport d’activité du système avec sar
La commande sar sous Linux est un outil puissant pour la collecte, l’affichage et la sauvegarde des informations d’activité du système. Elle fait partie du paquet sysstat et est largement utilisée pour le suivi du rendement du système au fil du temps.
Pour utiliser sar, vous devez d’abord installer sysstat en utilisant sudo apt install sysstat.
Une fois installé, démarrez le service avec sudo systemctl start sysstat.
Vérifiez le statut avec sudo systemctl status sysstat.
sar [options] [interval] [count]
Une fois le statut actif, le système commence à collecter divers statistiques que vous pouvez utiliser pour accéder et analyser les données historiques. Nous verrons cela en détail bientôt.
sar -u 1 3
La syntaxe de la commande sar est comme suit :
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Par exemple, sar -u 1 3 affichera les statistiques de utilisation du CPU toutes les secondes pour trois fois.
# Sortie
Voici quelques cas d’utilisation courants et des exemples de comment utiliser la commande sar.
sar peut être utilisé pour diverses fins :
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. Utilisation de la mémoire
Pour vérifier l’utilisation de la mémoire (libre et utilisée), utilisez :
Cette commande affiche les statistiques de la mémoire toutes les secondes trois fois.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. Utilisation de l’espace de swap
Pour afficher les statistiques d’utilisation de l’espace de swap, utilisez :
Cette commande aide à surveiller l’utilisation du swap, ce qui est crucial pour les systèmes qui manquent de mémoire physique.
sar -d 1 3
3. Chargement des périphériques I/O
Pour rapporter l’activité pour les périphériques bloc et les partitions de périphériques bloc :
Cette commande fournit des statistiques détaillées sur les transferts de données vers et depuis les périphériques bloc, et est utile pour diagnostiquer les goulets d’étranglement I/O.
sar -n DEV 1 3
5. Statistiques réseau
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Pour afficher les statistiques réseau, telles que le nombre de paquets reçus (transmis) par l’interface réseau :
# -n DEV indique à sar de rapporter les interfaces de périphériques réseau
Cela affiche les statistiques réseau toutes les secondes pendant trois secondes, aidant à surveiller le trafic réseau.
- 6. Données historiques
- # valables sont « true » et « false ». Veuillez ne pas mettre d’autres valeurs, elles
- Configurer l’intervalle de collecte de données : Editez la configuration de la tâche cron pour définir l’intervalle de collecte de données.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
Remplacez <DD> par le jour du mois pour lequel vous souhaitez afficher les données.
Dans la commande ci-dessous, /var/log/sysstat/sa04 fournit les statistiques pour le 4e jour du mois en cours.
sar -I SUM 1 3
7. Interruptions de CPU en temps réel
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Pour observer les interruptions par seconde servies par le CPU, utilisez cette commande :
# Sortie
Cette commande aide à surveiller la fréquence avec laquelle le CPU traite les interruptions, ce qui peut être crucial pour la réglage de la performance en temps réel.
Ces exemples montrent comment vous pouvez utiliser sar pour surveiller divers aspects de la performance du système. L’utilisation régulière de sar peut aider à identifier les points d’arrêt du système et à s’assurer que les applications fonctionnent efficacement.
8.9. Stratégie générale de dépannage pour les serveurs
Pourquoi devons-nous comprendre la surveillance ?
La surveillance est un aspect important de l’administration du système. Les applications critiques exigent un niveau de proactive élevé pour prévenir les échecs et réduire l’impact des pannes.
Linux offre des outils très puissants pour mesurer la santé du système. Dans cette section, vous apprendrez les diverses méthodes disponibles pour vérifier la santé de votre système et identifier les points d’arrêt.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
Trouver l’average de charge et l’uptime du système
Les redémarrages du système peuvent arriver, ce qui peut parfois jambler certaines configurations. Pour vérifier combien de temps la machine a été en service, utilisez la commande : uptime. En plus de l’uptime, la commande affiche également l’average de charge.
L’average de charge est le chargement du système au cours des dernières 1, 5 et 15 minutes. Un coup d’œil rapide indique si le chargement du système semble augmenter ou diminuer avec le temps.
Note : La file d’attente idéale du CPU est 0. Cela n’est possible que lorsqu’il n’y a pas de files d’attente en attente de traitement par le CPU.
lscpu
Le chargement par CPU peut être calculé en divisant l'average de charge par le nombre total de CPU disponibles.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Pour trouver le nombre de CPU, utilisez la commande lscpu.
# sortie
Si la charge moyenne semble augmenter et ne baisse pas, les CPU sont surchargés. Il y a un processus qui est bloqué ou il y a une fuite de mémoire.
free -mh
Calcul de la mémoire libre
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
Parfois, une utilisation élevée de la mémoire peut causer des problèmes. Pour vérifier la mémoire disponible et la mémoire utilisée, utilisez la commande free.
# sortie
Calcul de l’espace disque
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Pour assurer que le système est en bonne santé, n’oubliez pas l’espace disque. Pour lister tous les points de montage disponibles et leur pourcentage respectif d’utilisation, utilisez la commande ci-dessous. Idéalement, l’espace disque utilisé ne devrait pas dépasser 80%.
La commande df fournit des informations détaillées sur l’espace disque.
Détermination des états des processus
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Les états des processus peuvent être surveillés pour identifier un processus bloqué avec un usage élevé de mémoire ou de CPU.
On a vu précédemment que la commande ps donne des informations utiles sur un processus. Jetez un œil aux colonnes CPU et MEM.
Surveillance en temps réel du système
La surveillance en temps réel donne un aperçu de l’état réel du système.
Un outil que vous pouvez utiliser pour cela est la commande top.
La commande top affiche une vue dynamique des processus du système, affichant un en-tête de synthèse suivi d’une liste de processus ou de threads. Contrairement à son homologue statique ps, top rafraîchit constamment les statistiques du système.
Avec top, vous pouvez bien voir les détails organisés dans une fenêtre compacte. Plusieurs drapeaux, raccourcis et méthodes de surbrillance accompagnent top.
Vous pouvez également tuer des processus en utilisant top. Pour cela, appuyez sur k et then entrez l’id du processus.
Interprétation des journaux
Les journaux système et applications contiennent tonnes d’information sur ce que le système subit. Ils contiennent des informations utiles et des codes d’erreur qui pointent vers les erreurs. Si vous recherchez des codes d’erreur dans les journaux, l’identification des problèmes et le temps de correction peuvent être grandement réduits.
Analyse des ports réseau
L’aspect réseau ne devrait pas être négligé car les problèmes réseau sont communs et peuvent impacter le système et les flux de trafic. Les problèmes réseau courants incluent l’épuisement des ports, le congestion des ports, les ressources non libérées, etc.
| Pour identifier de tels problèmes, nous devons comprendre les états des ports. | Certains des états des ports sont expliqués brièvement ici : |
| État | Description |
| LISTEN | Représente les ports qui attendent une demande de connexion de n’importe quel port distant TCP. |
| ESTABLISHED | Représente les connexions qui sont ouvertes et que les données reçues peuvent être livrées à la destination. |
| TIME WAIT | Représente le temps d’attente pour s’assurer de l’acquiescement de sa demande de terminaison de connexion. |
FIN WAIT2
Représente l’attente d’une demande de terminaison de connexion du TCP distant.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Explorons comment analyser les informations portuaires sous Linux.
Intervalles de ports : Les intervalles de ports sont définis dans le système et peuvent être augmentés ou diminués en conséquence. Dans l’extrait ci-dessous, l’intervalle est de 15000 à 65000, ce qui représente un total de 50000 (65000 – 15000) de ports disponibles. Si le nombre de ports utilisés atteint ou dépasse ce plafond, il y a un problème.
L’erreur signalée dans les journaux dans de tels cas peut être Échec de l'appel à la socket sur le port ou Trop de connexions.
Identification de la perte de paquets
Dans la surveillance du système, nous devons nous assurer que la communication sortante et entrante sont intacts.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Une commande utile est ping. ping frappe le système de destination et ramène la réponse en retour. Notez les dernières lignes de statistiques qui montrent le pourcentage de perte de paquets et le temps.
# ping adresse IP de destination
Les paquets peuvent également être capturés en temps réel à l’aide de tcpdump. Nous y reviendrons plus tard.
Rassemblement de statistiques pour une autopsie des problèmes
- Il est toujours une bonne pratique de rassembler certaines statistiques qui seront utiles pour identifier la cause racine plus tard. Habituellement, après un redémarrage du système ou du service, nous perdons l’écranshapshot et les journaux précédents.
Voici quelques méthodes pour capturer un écranshot du système.
- Backup des journaux
Avant de faire des modifications, copiez les fichiers journaux dans un autre emplacement. Cela est essentiel pour comprendre dans quelle condition le système était au moment de l’incident. Parfois, les fichiers journaux sont la seule fenêtre pour observer les états passés du système car d’autres statistiques de runtime sont perdues.
sudo tcpdump -i any -w
Pistage TCP
Tcpdump est une utilité en ligne de commande qui vous permet de capturer et d'analyser le trafic réseau entrant et sortant. Elle est principalement utilisée pour aider à résoudre les problèmes de réseau. Si vous pensez que le trafic système est touché, effectuez un tcpdump comme suit :
# Où,
# -i any capture le trafic de toutes les interfaces
# -w spécifie le nom de fichier de sortie
# Arrêtez la commande après quelques minutes car la taille du fichier peut augmenter
# utilisez l’extension de fichier .pcap
Une fois que le tcpdump est capturé, vous pouvez utiliser des outils comme Wireshark pour analyser visuellement le trafic.
Conclusion
Merci d’avoir lu ce livre jusqu’à la fin. Si vous l’avez trouvé utile, envisagez de le partager avec les autres.
Ce livre ne se termine pas ici, cependant. Je continuerai à le perfectionner et à ajouter de nouveaux matériels dans l’avenir. Si vous avez trouvé des problèmes ou si vous aimeriez proposer des améliorations, n’hésitez pas à ouvrir un PR/ Issue.
- Reste connecté et poursuivez votre parcours d’apprentissage !
-
LinkedIn : Je partage des articles et des publications techniques là-bas. Laissez une recommandation sur LinkedIn et appuyez sur mes compétences pertinentes.
Accédez à du contenu exclusif : Pour de l’aide individuelle et accéder à du contenu exclusif, allez ici.
Accédez à du contenu exclusif : Pour de l’aide individuelle et accéder à du contenu exclusif, allez ici.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/