













L’auteur de ce post remet en question la perspective présentée dans un article de MinIO, qui suggère que POSIX n’est pas un ajustement approprié pour les magasins d’objets. Il a mené des tests approfondis impliquant MinIO s3fs-fuse et JuiceFS. Les résultats indiquent que MinIO et JuiceFS offrent une excellente performance tandis que s3fs-fuse est en retard. Dans les scénarios d’écrasement de petits fichiers, JuiceFS FUSE-POSIX surpasse les autres solutions.
Récemment, j’ai découvert un article sur le blog de MinIO intitulé « Mettre un système de fichiers sur un magasin d’objets est une mauvaise idée. Voici pourquoi. » L’auteur a utilisé s3fs-fuse comme exemple pour illustrer les défis de performance rencontrés lors de l’accès aux données MinIO en utilisant des méthodes POSIX (Portable Operating System Interface), soulignant que la performance était nettement en retard par rapport à l’accès direct à MinIO. L’auteur attribue ces problèmes de performance à des défauts inhérents à POSIX. Cependant, notre expérience diffère quelque peu de cette conclusion.
POSIX est une norme utile et largement adoptée. Le développement de logiciels conformes à POSIX garantit la compatibilité et la portabilité entre différents systèmes d’exploitation. La plupart des applications dans divers secteurs suivent la norme POSIX. Avec l’avancement des technologies du cloud computing, des données massives et de l’IA, ainsi que la croissance du volume de données stockées, la demande pour des solutions de stockage élastique comme les magasins d’objets ne cesse de croître. Bien que des magasins d’objets comme MinIO fournissent des SDK dans plusieurs langues, de nombreuses applications traditionnelles peinent à adapter leur code pour utiliser les API de stockage d’objets. Cela a conduit à divers produits de stockage mettant en œuvre des interfaces POSIX au-dessus des magasins d’objets pour répondre à cette demande inflexible.
De nombreux produits dans l’industrie, tels que Ceph, JuiceFS et Weka, ont réussi à mettre en œuvre des interfaces POSIX sur les magasins d’objets. Ces solutions ont de larges bases d’utilisateurs et de nombreux cas d’étude réussis, et elles se démarquent en termes de performance.
Bien qu’il soit vrai que POSIX présente une complexité significative, les problèmes associés ne sont pas insurmontables. Avec respect et désir de vérifier ces affirmations, j’ai mis en place un environnement de test, utilisé les mêmes données d’échantillon et méthodes de test que dans l’article MinIO, et effectué une validation.
Comparaison des produits et objectifs de test
Pour fournir une évaluation complète, j’ai introduit JuiceFS dans la comparaison.
JuiceFS est un système de fichiers distribué open-source et cloud-native. Il utilise le stockage d’objets comme couche de stockage de données et dépend d’une base de données distincte pour stocker les métadonnées. Il propose divers moyens d’accès, y compris l’API POSIX, l’API S3, le pilote CSI, l’API HDFS et WebDAV, ainsi que des mécanismes uniques de fragmentation des données, de mise en cache et de lecture/écriture concurrente. JuiceFS est un système de fichiers, fondamentalement différent des outils comme s3fs-fuse, qui convertissent simplement le stockage d’objets en protocoles POSIX.
En introduisant JuiceFS dans la comparaison, j’ai cherché à évaluer objectivement les avantages et les inconvénients de la mise en œuvre de protocoles comme POSIX au-dessus du stockage d’objets.
I conducted the following two tests on MinIO, JuiceFS, and s3fs-fuse:
- Écriture d’un fichier de 10 GB
- Réécriture de petits fichiers avec Pandas
Les trois solutions ont utilisé une instance MinIO déployée sur des serveurs séparés comme stockage de base. Pour les échantillons de test, un fichier de 10 GB a été utilisé, qui était le même fichier CSV mentionné dans l’article MinIO.
Tous les environnements, logiciels, scripts et données d’échantillon de cet article sont accompagnés de code complet et d’instructions pour vous assurer que vous pouvez reproduire l’environnement et les résultats des tests.
Configuration du serveur et de l’environnement de test
Deux serveurs cloud configurés de manière identique:
- Système: Ubuntu 22.04 x64
- CPU: 8 cœurs
- RAM: 16 Go
- SSD: 500 Go
- Réseau: VPC
Les informations pour chaque serveur:
| Server | IP | Purpose |
|---|---|---|
| Server A | 172.16.254.18 | Deploying the MinIO instance |
| Server B | 172.16.254.19 | As the test environment |
Préparation du Serveur A
1. J’ai déployé MinIO sur le serveur A en utilisant Docker avec les commandes suivantes :
# Créer un répertoire dédié et naviguer vers celui-ci.
mkdir minio && cd minio
# Créer un fichier de configuration.
mkdir config
touch config/minio
2. J’ai écrit les informations suivantes dans le fichier config/minio :
MINIO_ROOT_USER=admin
MINIO_ROOT_PASSWORD=abc123abc
MINIO_VOLUMES="/mnt/data"
3. J’ai créé le conteneur MinIO :
sudo docker run -d --name minio \
-p 9000:9000 \
-p 9090:9090 \
-v /mnt/minio-data:/mnt/data \
-v ./config/minio:/etc/config.env \
-e "MINIO_CONFIG_ENV_FILE=/etc/config.env" \
--restart unless-stopped \
minio/minio server --console-address ":9090"
4. Sur la Console Web de MinIO, j’ai pré-créé trois buckets :
| Bucket name | Purpose |
|---|---|
| test-minio | For testing MinIO |
| test-juicefs | For testing JuiceFS |
| test-s3fs | For testing s3fs-fuse |
Préparation du serveur B
1. J’ai téléchargé l’échantillon de test de 10 Go.
curl -LO https://data.cityofnewyork.us/api/views/t29m-gskq/rows.csv?accessType=DOWNLOAD
2. J’ai installé le client mc.
mc est un gestionnaire de fichiers en ligne de commande développé par le projet MinIO. Il permet d’effectuer des opérations de lecture et d’écriture sur les stockages d’objets locaux et compatibles S3 dans la ligne de commande Linux. La commande mc cp fournit des mises à jour en temps réel sur la progression et la vitesse pendant la copie des données, facilitant l’observation de divers tests.
Remarque : Pour maintenir l’équité des tests, les trois approches ont utilisé
mcpour les tests d’écriture de fichiers.
# Télécharger mc.
wget https://dl.min.io/client/mc/release/linux-amd64/mc
# Vérifier la version de mc.
mc -v
mc version RELEASE.2023-09-20T15-22-31Z (commit-id=38b8665e9e8649f98e6162bdb5163172e6ecc187)
Runtime: go1.21.1 linux/amd64
# Installer mc.
sudo install mc /usr/bin
# Définir un alias pour MinIO.
mc alias set my http://172.16.254.18:9000 admin abc123abc
3. J’ai téléchargé s3fs-fuse.
sudo apt install s3fs
# Vérifier la version.
s3fs --version
Amazon Simple Storage Service File System V1.93 (commit:unknown) with OpenSSL
# Définir la clé d'accès du stockage d'objets.
echo admin:abc123abc > ~/.passwd-s3fs
# Modifier les permissions du fichier de clé.
chmod 600 ~/.passwd-s3fs
# Créer le répertoire de montage.
mkdir mnt-s3fs
# Monter le stockage d'objets.
s3fs test-s3fs:/ /root/mnt-s3fs -o url=http://172.16.254.18:9000 -o use_path_request_style
4. J’ai installé JuiceFS.
I used the official script to install the latest JuiceFS Community Edition.
# Script d'installation en un clic
curl -sSL https://d.juicefs.com/install | sh -
# Vérifier la version.
juicefs version
juicefs version 1.1.0+2023-09-04.08c4ae6
5. J’ai créé un système de fichiers. JuiceFS est un système de fichiers qui doit être créé avant utilisation. En plus du stockage d’objets, il nécessite une base de données en tant qu’outil métadonnées. Il prend en charge diverses bases de données. Ici, j’ai utilisé Redis couramment utilisé en tant qu’outil métadonnées.
Note : J’ai installé Redis sur le serveur A, accessible via
172.16.254.18:6379sans mot de passe. Le processus d’installation est omis ici. Vous pouvez vous référer à la documentation Redis pour plus de détails.
# Créer le système de fichiers.
juicefs format --storage minio \
--bucket http://172.16.254.18:9000/test-juicefs \
--access-key admin \
--secret-key abc123abc \
--trash-days 0 \
redis://172.16.254.18/1 \
myjfs
6. J’ai accédé à JuiceFS en utilisant les méthodes POSIX et S3 API plus couramment utilisées et j’ai testé leurs performances.
# Créer les répertoires de montage.
mkdir ~/mnt-juicefs
# Monter le système de fichiers en mode POSIX.
juicefs mount redis://172.16.254.18/1 /root/mnt-juicefs
# Accéder au système de fichiers en utilisant la méthode S3 API.
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=abc123abc
juicefs gateway redis://172.16.254.18/1 0.0.0.0:9000
# Définir un alias pour la méthode S3 API JuiceFS dans mc.
mc alias set juicefs http://172.16.254.18:9000 admin abc123abc
Note : Le Gateway JuiceFS peut également être déployé sur le serveur A ou sur tout autre serveur accessible à Internet puisqu’il expose une API S3 basée sur le réseau.
Tests et Résultats
Voici un bref résumé de mes tests et résultats:
| Test | MinIO | S3FS-FUSE | JuiceFS (FUSE) |
JuiceFS (S3 gateway) |
|---|---|---|---|---|
| Writing a 10 GB file | 0m27.651s | 3m6.380s | 0m28.107s | 0m28.091s |
| Overwriting small files with Pandas | 0.83s | 0.78s | 0.46s | 0.96s |
Test 1 : Écriture d’un fichier de 10 Go
Ce test avait pour objectif d’évaluer les performances de l’écriture de gros fichiers. Plus le temps nécessaire est court, meilleures sont les performances. J’ai utilisé la commande time pour mesurer la durée des opérations d’écriture, fournissant trois métriques :
réel: Le temps réel de début à la fin de la commande. Il inclut toutes les périodes d’attente, telles que l’attente des opérations d’E/S pour se terminer, l’attente des commutations de processus, et l’attente des ressources.utilisateur: Le temps d’exécution en mode utilisateur, indiquant le temps CPU utilisé pour exécuter le code utilisateur. Il représente généralement la charge de travail computationnelle de la commande.système: Le temps d’exécution en mode noyau, indiquant le temps CPU utilisé pour exécuter le code du noyau. Il représente généralement la charge de travail liée aux appels système, comme les E/S de fichiers et la gestion des processus.
MinIO
I ran the following command to perform a copy test:
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv my/test-minio/
Résultats de l’écriture d’un fichier de 10 GB directement sur MinIO:
real 0m27.651s
user 0m10.767s
sys 0m5.439s
s3fs-fuse
I ran the following command to perform a copy test:
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv /root/mnt-s3fs/
Résultats de l’écriture d’un fichier de 10 GB directement sur s3fs-fuse:
real 3m6.380s
user 0m0.012s
sys 0m5.459s
Note : Bien que le temps d’écriture était de 3 minutes et 6 secondes pour
s3fs-fuse, il n’y a eu aucun échec d’écriture tel qu’il est décrit dans l’article de MinIO.
JuiceFS
I tested the performance of JuiceFS for large file writes using both the POSIX and S3 API methods:
# Test d'écriture POSIX
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv /root/mnt-juicefs/
# Test d'écriture API S3
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv juicefs/myjfs/
Résultats pour l’écriture POSIX de JuiceFS d’un fichier de 10 GB:
real 0m28.107s
user 0m0.292s
sys 0m6.930s
Résultats pour l’écriture API S3 de JuiceFS d’un fichier de 10 GB:
real 0m28.091s
user 0m13.643s
sys 0m4.142s
Résumé des résultats d’écriture de gros fichiers
La figure suivante montre les résultats des tests:
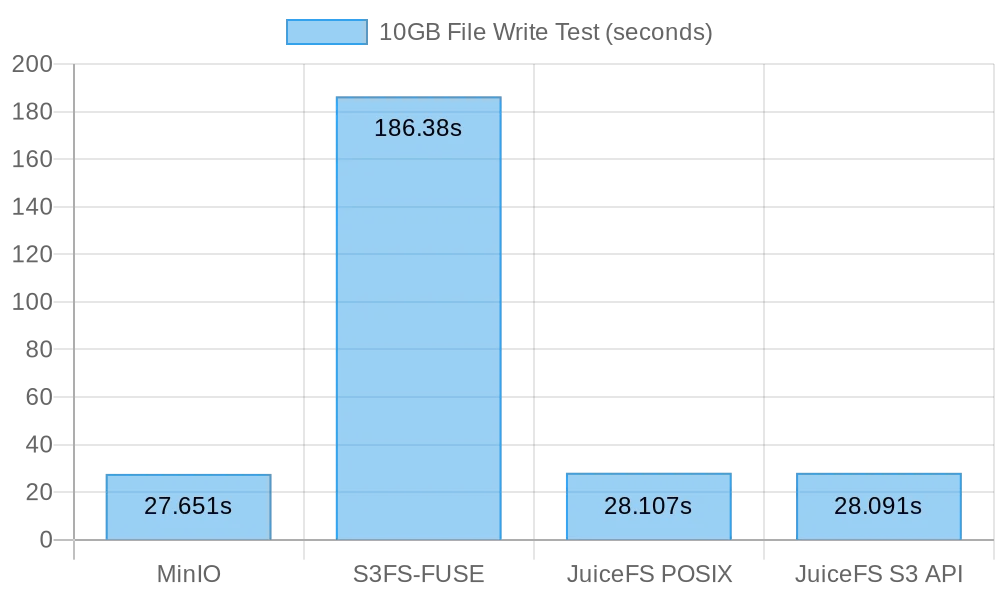
Les résultats des tests montrent que l’écriture directe sur MinIO et JuiceFS a donné des performances comparables, terminant la tâche en environ 30 secondes. En revanche, s3fs-fuse a pris plus de 3 minutes pour écrire un fichier de 10 GB, soit environ six fois plus lentement que les deux premiers.
Lors de l’écriture de gros fichiers, mc utilise l’API Multipart pour télécharger des fichiers en morceaux vers l’interface S3. En revanche, s3fs-fuse ne peut écrire que dans POSIX en un seul thread. JuiceFS divise également automatiquement les gros fichiers en morceaux et les écrit de manière concurrentielle dans MinIO lors d’écritures séquentielles, garantissant une performance comparable à celle des écritures directes dans MinIO. S3FS, quant à lui, écrit d’abord sur un disque cache en un seul thread, puis télécharge le fichier en morceaux dans MinIO, ce qui entraîne des temps d’écriture plus longs.
Selon le calcul, il a fallu 30 secondes pour écrire un fichier de 10 Go, la vitesse moyenne était de 333 Mo/s. Cela était limité par la bande passante des SSD de serveur cloud. Ces résultats de test indiquaient que MinIO et JuiceFS pouvaient maximiser la bande passante locale SSD, et leur performance s’améliorerait avec l’amélioration des disques de serveur cloud et de la bande passante réseau.
Test 2 : Écrasement de petits fichiers avec Pandas
Ce test a évalué les performances des systèmes de stockage d’objets dans des scénarios d’écrasement de petits fichiers. Les scripts de test pour chaque logiciel différaient légèrement. Vous pouvez trouver tous les code de script ici.
MinIO
I got the test script and ran the test:
# Obtenir le script de test.
curl -LO https://gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-minio.py
# Exécuter le test.
python3 pandas-minio.py
Le résultat était le suivant:
Execution time: 0.83 seconds
s3fs-fuse
I got the test script and ran the test:
# Obtenir le script de test.
curl -LO gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-s3fs.py
# Exécuter le test.
python3 pandas-s3fs.py
Le résultat du test était le suivant:
Execution time: 0.78 seconds
JuiceFS POSIX
I got the test script and ran the test:
# Obtenir le script de test.
curl -LO gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-juicefs-posix.py
# Exécuter le test.
python3 pandas-juicefs-posix.py
Le résultat du test était le suivant:
Execution time: 0.43 seconds
JuiceFS S3 API
I got the test script and ran the test:
# Obtenir le script de test.
curl -LO https://gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-juicefs-s3api.py
# Exécuter le test.
python3 pandas-juicefs-s3api.py
Le résultat du test était le suivant:
Execution time: 0.86 seconds
Résumé des Écrasements de Fichiers Petits par Pandas
La figure suivante présente les résultats du test:
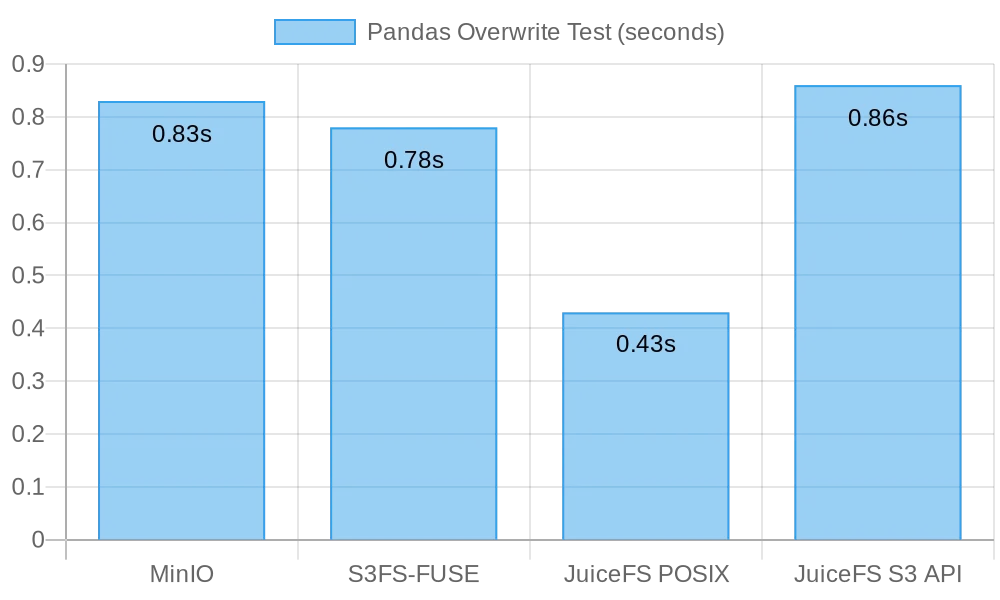
Dans ce test, JuiceFS FUSE-POSIX a démontré la vitesse la plus rapide, près de deux fois plus rapide que les autres solutions. MinIO, s3fs-fuse, et JuiceFS S3 Gateway présentent une performance similaire. Du point de vue des écrasements de fichiers petits, l’interface POSIX s’est avérée plus efficace, offrant de meilleures performances que les interfaces de stockage d’objets.
Problèmes et Analyse
Problème 1: Pourquoi S3FS Était-il Si Lent?
Analyse: D’après les données de test, il est clair que lors de l’écriture du même fichier de 10 Go, S3FS a mis 3 minutes, tandis que MinIO et JuiceFS ont tous deux terminé la tâche en environ 30 secondes. Cette différence de performance significative était principalement due à des implémentations techniques différentes. Lorsque s3fs-fuse écrit un fichier, il écrit d’abord le fichier dans un fichier temporaire local, puis l’upload en morceaux vers le stockage d’objets. S’il n’y a pas suffisamment d’espace disque local, il upload de manière synchrone. Il doit copier des données entre le disque local et le stockage S3. Par conséquent, les gros fichiers ou un grand nombre de fichiers entraînent une dégradation des performances.
De plus, S3FS repose sur les capacités de gestion des métadonnées du stockage d’objets sous-jacent. Lorsqu’il traite un grand nombre de fichiers, les interactions fréquentes avec le stockage d’objets pour récupérer les métadonnées ont un impact significatif sur les performances. En termes simples, plus la taille des fichiers et la quantité totale de fichiers écrits sur S3FS sont importantes, plus l’impact sur les performances est proportionnellement élevé.
Problème 2 : Pourquoi JuiceFS était-il plus rapide ?
Analyse : Dans le test, à la fois JuiceFS et S3FS ont utilisé FUSE pour la lecture et l’écriture. JuiceFS a utilisé pleinement la bande passante du disque comme MinIO, mais n’a pas rencontré les problèmes de performances que connaît S3FS.
La réponse réside dans leurs architectures techniques respectives. Alors que les données sont traitées à travers la couche FUSE lors de l’écriture de fichiers, JuiceFS utilise des techniques de haute concurrence, de mise en cache et de fragmentation des données pour réduire l’overhead de communication entre la couche FUSE et le stockage d’objets sous-jacent. Cela permet à JuiceFS de gérer plus de requêtes de lecture et d’écriture pour les fichiers simultanément, réduisant ainsi les temps d’attente et la latence de transmission.
De plus, JuiceFS utilise une base de données dédiée (dans ce cas, Redis) pour gérer les métadonnées. Lorsqu’il s’agit d’un très grand nombre de fichiers, un moteur de métadonnées indépendant peut effectivement soulager la charge de travail, permettant ainsi une localisation des fichiers plus rapide.
Conclusion
Les tests ci-dessus démontrent qu’utiliser le stockage d’objets comme base et mettre en place une interface POSIX en plus ne nécessite pas une perte de performance. Que ce soit pour écrire de gros fichiers ou de petits fichiers, JuiceFS affiche une performance comparable à l’écriture directe sur MinIO sans aucune dégradation de la performance du stockage d’objets sous-jacent en raison de l’accès POSIX. De plus, en termes de réécriture de tableaux Pandas, la performance JuiceFS FUSE-POSIX reste cohérente et dépasse même MinIO presque deux fois.
Les résultats des tests indiquent que certains logiciels, comme s3fs-fuse, peuvent subir une dégradation des performances lors de la conversion entre l’API S3 et les interfaces POSIX. Bien qu’il puisse être un outil pratique pour l’accès temporaire à S3, pour une utilisation à long terme stable et hautes performances, une recherche et une validation soigneuses sont nécessaires pour sélectionner des solutions plus appropriées.
Pour un archivage de fichiers non structurés simple, l’utilisation directe de MinIO ou de stockage d’objets cloud est une bonne option. Cependant, pour les scénarios qui impliquent un stockage et un traitement de données à grande échelle, tels que l’entraînement de modèles d’IA, l’analyse de big data, la persistance des données Kubernetes et d’autres opérations fréquentes de lecture et d’écriture, JuiceFS offre une gestion indépendante des métadonnées, des capacités de lecture et d’écriture concurrentes, et des mécanismes de mise en cache qui assurent une performance supérieure. Il s’agit d’une solution de système de fichiers hautes performances à prendre en considération.
Source:
https://dzone.com/articles/is-posix-really-unsuitable-for-object-stores-a-dat