













Qu’est-ce qu’Elasticsearch ?
Elasticsearch est un moteur de recherche et d’analyse hautement évolutif et distribué, construit sur la bibliothèque de recherche Apache Lucene. Il est conçu pour gérer de grandes quantités de données structurées, semi-structurées et non structurées, ce qui le rend bien adapté à une grande variété d’utilisations, notamment les moteurs de recherche, l’analyse des journaux, le commerce électronique et l’analyse de la sécurité.
Elasticsearch utilise une architecture distribuée qui lui permet de stocker et de traiter de grandes quantités de données sur plusieurs nœuds d’un cluster. Les données sont indexées et stockées dans des fragments, qui sont distribués sur les nœuds pour améliorer l’évolutivité et la tolérance aux pannes. Elasticsearch prend également en charge la recherche et l’analyse en temps réel, permettant aux utilisateurs de poser des requêtes et d’analyser les données presque en temps réel.
L’une des principales caractéristiques de Elasticsearch est sa puissance en matière de recherche. Il prend en charge une grande variété de requêtes de recherche, y compris la recherche plein texte, la recherche géospatiale, etc. Il offre également un soutien pour des fonctionnalités d’analyse avancées telles que les agrégations, les métriques et la visualisation des données.
Elasticsearch est souvent utilisé conjointement avec d’autres outils dans la pile Elastic, y compris Logstash pour la collecte et le traitement des données et Kibana pour la visualisation et l’analyse des données. Ensemble, ces outils offrent une solution complète pour la recherche et l’analyse qui peut être utilisée pour une grande variété d’applications et d’utilisations.
Qu’est-ce qu’Apache Lucene ?
Apache Lucene est une bibliothèque de recherche open-source qui offre des capacités de recherche et d’indexation de texte puissantes. Elle est largement utilisée par les développeurs et les organisations pour créer des applications de recherche, allant des moteurs de recherche aux plateformes e-commerce.
Lucene fonctionne en indexant le contenu textuel des documents et en stockant l’index sous une forme structurée qui peut être recherchée efficacement. L’index est composé d’une série de listes inversées, qui fournissent des correspondances entre les termes et les documents qui les contiennent. Lorsqu’une requête de recherche est soumise, Lucene utilise l’index pour rapidement récupérer les documents correspondant à la requête.
En plus de ses capacités de base de recherche et d’indexation, Lucene propose un éventail de fonctionnalités avancées, notamment le support de la recherche floue et de la recherche spatiale. Elle fournit également des outils pour mettre en évidence les résultats de recherche et classer les résultats de recherche en fonction de la pertinence.
Lucene est utilisé par un large éventail d’organisations et de projets, y compris Elasticsearch. Son riche ensemble de fonctionnalités, sa flexibilité et son extensibilité en font une option populaire pour la construction d’applications de recherche de toutes sortes.
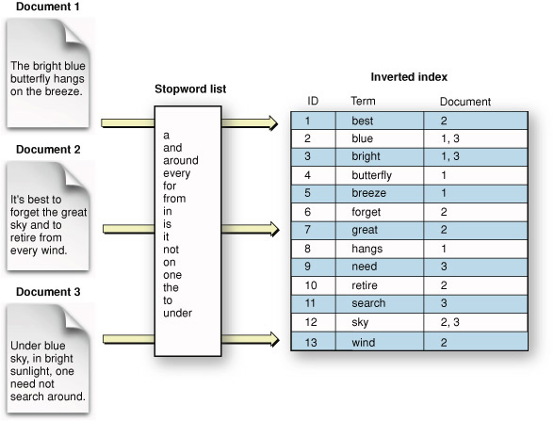
Qu’est-ce qu’un index inversé?
L’index inversé de Lucene est une structure de données utilisée pour rechercher et récupérer efficacement des données textuelles à partir d’une collection de documents. L’index inversé est une caractéristique centrale de Lucene et est utilisé pour stocker les termes et les documents associés qui composent l’index.
L’Index inversé offre plusieurs avantages par rapport à d’autres stratégies de recherche. Premièrement, il permet une récupération rapide et efficace des documents en fonction des termes de recherche. Deuxièmement, il peut gérer de grandes quantités de données textuelles, ce qui en fait un choix idéal pour les cas d’utilisation avec de grandes collections de documents. Enfin, il prend en charge un large éventail de fonctionnalités de recherche avancées, telles que la correspondance floue et le stemming, qui peuvent améliorer la précision et la pertinence des résultats de recherche.
Pourquoi Elasticsearch?
Il y a plusieurs raisons pour lesquelles Elasticsearch est une option populaire pour la construction d’applications de recherche et d’analyse :
Facile à mettre à l’échelle (Distribué) : Elasticsearch est conçu pour être échelonnable horizontalement dès le départ. Chaque fois que vous avez besoin d’augmenter la capacité, ajoutez simplement plus de nœuds, et laissez le cluster se réorganiser lui-même pour tirer parti de l’équipement supplémentaire.
Un serveur peut contenir une ou plusieurs parties d’un ou plusieurs index, et chaque fois que de nouveaux nœuds sont introduits dans le cluster, ils sont simplement ajoutés à la fête. Chaque tel index, ou partie de celui-ci, est appelé un fragment, et les fragments Elasticsearch peuvent être déplacés facilement dans le cluster.
Tout est à une requête JSON (API RESTful) : Elasticsearch est piloté par API. Presque toute action peut être effectuée en utilisant une simple API RESTful en utilisant JSON sur HTTP. Les réponses sont toujours au format JSON.
Puissance libérée de Lucene sous le capot : Elasticsearch utilise Lucene en interne pour développer ses capacités de recherche distribuée et d’analyse de pointe. Étant donné que Lucene est une technologie stable et éprouvée, et qu’elle est constamment enrichie de nouvelles fonctionnalités et de meilleures pratiques, avoir Lucene comme moteur sous-jacent qui alimente Elasticsearch.
Excellent DSL de requête : L’API REST expose un DSL de requête très complexe et performant qui est très facile à utiliser. Chaque requête n’est qu’un objet JSON qui peut contenir pratiquement tout type de requête ou même plusieurs d’entre elles combinées. L’utilisation de requêtes filtrées, avec certaines requêtes exprimées comme des filtres Lucene, permet de tirer parti du cache et donc d’accélérer les requêtes courantes ou complexes avec des parties pouvant être réutilisées.
Multitenance : Plusieurs index peuvent être stockés sur une installation Elasticsearch – nœud ou cluster. Le plus intéressant est que vous pouvez interroger plusieurs index avec une seule requête simple.
Prise en charge des fonctionnalités de recherche avancées (Texte intégral) : Elasticsearch utilise Lucene en coulisse pour fournir les capacités de recherche plein texte les plus puissantes disponibles dans tout produit open-source. La recherche est dotée de support multilingue, d’un langage de requête puissant, de support pour la géolocalisation, de suggestions contextuelles « Est-ce que vous voulez dire », d’autocomplétion et de snippets de recherche. Prise en charge des scripts dans les filtres et les scoreurs.
Configurable et extensible : De nombreuses configurations Elasticsearch peuvent être modifiées pendant que Elasticsearch est en cours d’exécution, mais certaines nécessiteront un redémarrage (et, dans certains cas, une réindexation). La plupart des configurations peuvent également être modifiées en utilisant l’API REST.
Document Oriented: Stockez des entités complexes du monde réel dans Elasticsearch sous forme de documents JSON structurés. Par défaut, tous les champs sont indexés et tous les index peuvent être utilisés dans une seule requête pour retourner des résultats à une vitesse vertigineuse.
Schema Free: Elasticsearch vous permet de démarrer facilement. Envoyez un document JSON, et il essaiera de détecter la structure des données, d’indexer les données et de les rendre recherchables.
Gestion des Conflits: La gestion des versions optimiste peut être utilisée là où c’est nécessaire pour s’assurer que les données ne sont jamais perdues à cause de changements conflictuels provenant de plusieurs processus.
Communauté Active: La communauté, en plus de créer de beaux outils et plugins, est très serviable et solidaire. L’ambiance générale est superbe, et c’est un critère important pour tout projet de logiciel libre. Il y a également quelques livres en cours d’écriture par des membres de la communauté et de nombreux articles de blog sur le net partageant des expériences et des connaissances.
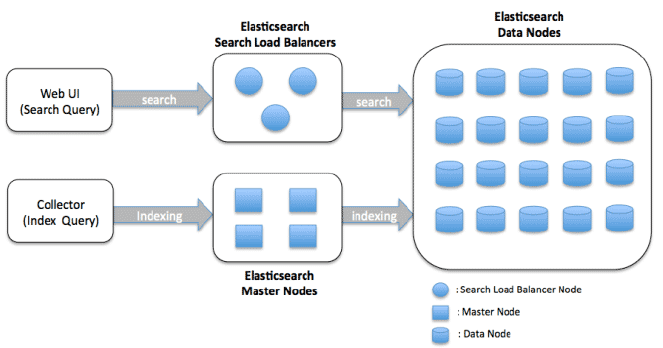
Architecture Elasticsearch
Les principaux composants de l’architecture Elasticsearch sont:
Noeud: Un nœud est une instance d’Elasticsearch qui stocke des données et fournit des capacités de recherche et d’indexation. Les nœuds peuvent être configurés pour être soit un nœud maître, soit un nœud de données, ou les deux. Les nœuds maîtres sont responsables de la gestion au niveau du cluster, tandis que les nœuds de données stockent les données et effectuent les opérations de recherche.
Cluster: Un cluster est un groupe d’un ou plusieurs nœuds travaillant ensemble pour stocker et traiter des données. Un cluster peut contenir plusieurs index (collections de documents) et des shards (un moyen de distribuer des données sur plusieurs nœuds).
Index: Un index est une collection de documents qui partagent une structure similaire. Chaque document est représenté comme un objet JSON et contient un ou plusieurs champs. Elasticsearch indexe par défaut tous les champs, ce qui facilite la recherche et l’analyse des données.
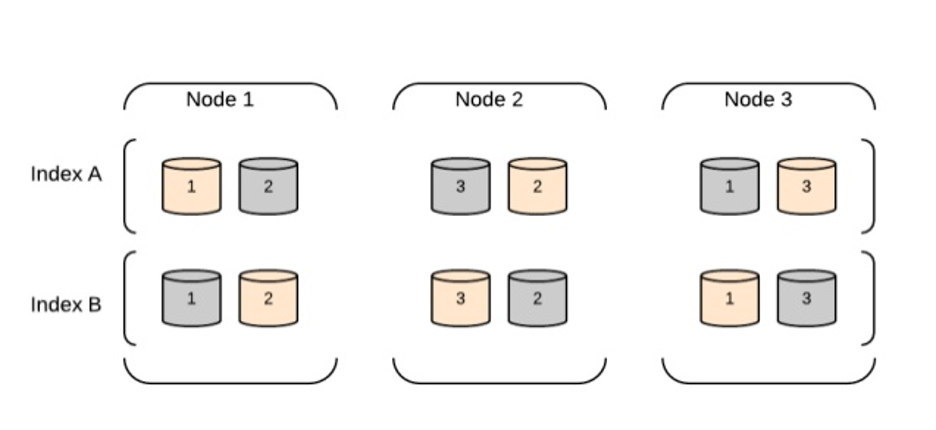
Shards: Un index peut être divisé en plusieurs shards, qui sont essentiellement des sous-ensembles plus petits de l’index. Le partitionnement permet le traitement parallèle des données et le stockage distribué sur plusieurs nœuds.
Replicas: Elasticsearch peut créer des réplicas de chaque shard pour fournir une tolérance aux pannes et une haute disponibilité. Les réplicas sont des copies du shard original et peuvent être situés sur différents nœuds.
Architecture de cluster de nœuds de données
Les nœuds de données sont responsables du stockage et de l’indexation des données, ainsi que de l’exécution des opérations de recherche et d’agrégation. L’architecture est conçue pour être évolutive et distribuée, permettant l’échelle horizontale en ajoutant plus de nœuds au cluster.
Voici les principaux composants d’une architecture de cluster de nœuds de données Elasticsearch:
Nœud de données: Un nœud est une instance d’Elasticsearch qui stocke des données et fournit des capacités de recherche et d’indexation. Dans un cluster de nœuds de données, chaque nœud est responsable du stockage d’une partie des données de l’index et de servir des requêtes de recherche contre ces données.
État du cluster: L’état du cluster est une structure de données qui contient des informations sur le cluster, y compris la liste des nœuds, des indices, des shards et leurs emplacements. Le nœud maître est responsable de la maintenance de l’état du cluster et de sa distribution à tous les autres nœuds du cluster.
Découverte et transport : Les nœuds dans un cluster Elasticsearch communiquent entre eux en utilisant deux protocoles : la découverte et le transport. Le protocole de découverte est responsable de la découverte des nouveaux nœuds qui rejoignent le cluster ou des nœuds qui ont quitté le cluster. Le protocole de transport est responsable de l’envoi et de la réception de données entre les nœuds.
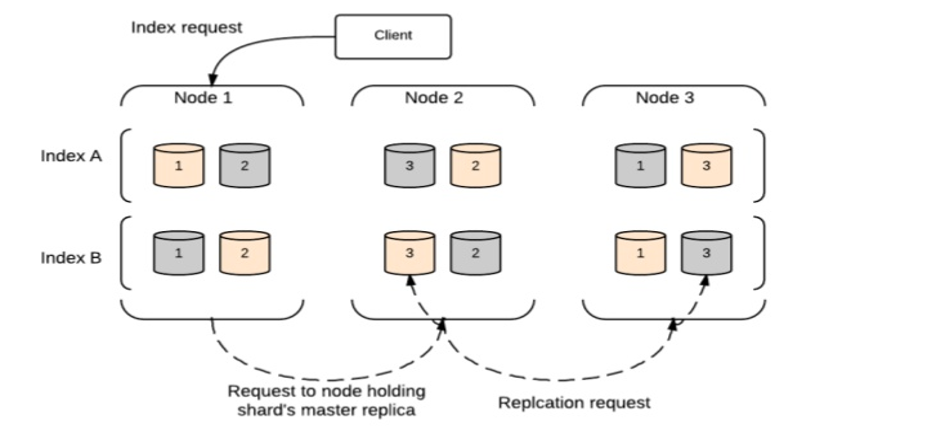
Requête d’indexation
La requête d’indexation est exécutée comme indiqué dans le diagramme de blocs dans Elasticsearch.
Qui utilise Elasticsearch ?
Quelques entreprises et organisations qui utilisent Elasticsearch :
Netflix : Netflix utilise Elasticsearch pour alimenter son moteur de recherche et de recommandations, permettant aux utilisateurs de trouver rapidement du contenu à regarder.
GitHub : GitHub utilise Elasticsearch pour offrir des capacités de recherche rapides et efficaces à travers leurs dépôts de code, problèmes et demandes de tirage.
Uber : Uber utilise Elasticsearch pour alimenter sa plateforme d’analyse en temps réel, lui permettant de suivre et d’analyser les données sur son service de mise en relation en temps réel.
Wikipedia : Wikipedia utilise Elasticsearch pour alimenter son moteur de recherche et fournir des résultats de recherche rapides et précis aux utilisateurs.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1