













Introduction
Tout système informatique bénéficie d’une administration et d’une surveillance appropriées. Surveiller le fonctionnement de votre système vous aidera à découvrir rapidement les problèmes et à les résoudre.
Il existe de nombreuses utilitaires en ligne de commande créés à cet effet. Ce guide vous présentera quelques-unes des applications les plus utiles à avoir dans votre boîte à outils.
Prérequis
Pour suivre ce guide, vous aurez besoin d’un accès à un ordinateur exécutant un système d’exploitation basé sur Linux. Il peut s’agir soit d’un serveur privé virtuel auquel vous avez accédé avec SSH, soit de votre machine locale. Notez que ce tutoriel a été validé avec un serveur Linux exécutant Ubuntu 20.04, mais les exemples donnés devraient fonctionner sur un ordinateur exécutant n’importe quelle version de n’importe quelle distribution Linux.
Si vous prévoyez d’utiliser un serveur distant pour suivre ce guide, nous vous encourageons à d’abord compléter notre Guide de Configuration Initiale du Serveur. Cela vous configurera un environnement de serveur sécurisé, comprenant un utilisateur non root avec des privilèges sudo et un pare-feu configuré avec UFW, que vous pourrez utiliser pour développer vos compétences Linux.
Étape 1 – Comment voir les processus en cours d’exécution sous Linux
Vous pouvez voir tous les processus en cours d’exécution sur votre serveur en utilisant la commande top:
Outputtop - 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
Les premières lignes de sortie fournissent des statistiques système, telles que la charge CPU/mémoire et le nombre total de tâches en cours d’exécution.
Vous pouvez voir qu’il y a 1 processus en cours d’exécution et 55 processus qui sont considérés comme endormis car ils n’utilisent pas activement les cycles CPU.
Le reste de la sortie affichée montre les processus en cours d’exécution et leurs statistiques d’utilisation. Par défaut, top trie automatiquement ces processus par utilisation CPU, vous pouvez donc voir les processus les plus occupés en premier. top continuera de s’exécuter dans votre shell jusqu’à ce que vous l’arrêtiez en utilisant la combinaison de touches standard Ctrl+C pour quitter un processus en cours d’exécution. Cela envoie un signal kill, indiquant au processus de s’arrêter de manière propre s’il en est capable.
Une version améliorée de top, appelée htop, est disponible dans la plupart des dépôts de paquets. Sur Ubuntu 20.04, vous pouvez l’installer avec apt:
Après cela, la commande htop sera disponible:
Output Mem[||||||||||| 49/995MB] Load average: 0.00 0.03 0.05
CPU[ 0.0%] Tasks: 21, 3 thr; 1 running
Swp[ 0/0MB] Uptime: 00:58:11
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1259 root 20 0 25660 1880 1368 R 0.0 0.2 0:00.06 htop
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 /sbin/init
311 root 20 0 17224 636 440 S 0.0 0.1 0:00.07 upstart-udev-brid
314 root 20 0 21592 1280 760 S 0.0 0.1 0:00.06 /sbin/udevd --dae
389 messagebu 20 0 23808 688 444 S 0.0 0.1 0:00.01 dbus-daemon --sys
407 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.02 rsyslogd -c5
408 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
409 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
406 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.04 rsyslogd -c5
553 root 20 0 15180 400 204 S 0.0 0.0 0:00.01 upstart-socket-br
htop offre une meilleure visualisation des threads CPU multiples, une meilleure prise en charge des couleurs dans les terminaux modernes et plus d’options de tri, entre autres fonctionnalités. Contrairement à top, il n’est pas toujours installé par défaut, mais peut être considéré comme un remplacement direct. Vous pouvez quitter htop en appuyant sur Ctrl+C comme avec top.
Voici quelques raccourcis clavier qui vous aideront à utiliser htop de manière plus efficace:
- M: Sort processes by memory usage
- P: Sort processes by processor usage
- ?: Accéder à l’aide
- k: Kill current/tagged process
- F2: Configurer htop. Vous pouvez choisir les options d’affichage ici.
- /:: Rechercher des processus
Il existe de nombreuses autres options auxquelles vous pouvez accéder via l’aide ou la configuration. Ceux-ci devraient être vos premiers arrêts dans l’exploration de la fonctionnalité d’htop. À l’étape suivante, vous apprendrez à surveiller votre bande passante réseau.
Étape 2 – Comment surveiller votre bande passante réseau
Si votre connexion réseau semble surutilisée et que vous ne savez pas quelle application en est responsable, un programme appelé nethogs est un bon choix pour le découvrir.
Sous Ubuntu, vous pouvez installer nethogs avec la commande suivante:
Après cela, la commande nethogs sera disponible:
OutputNetHogs version 0.8.0
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec
nethogs associe chaque application à son trafic réseau.
Il n’y a que quelques commandes que vous pouvez utiliser pour contrôler nethogs:
- M: Change displays between “kb/s”, “kb”, “b”, and “mb”.
- R: Sort by traffic received.
- S: Sort by traffic sent.
- Q: quit
iptraf-ng est une autre façon de surveiller le trafic réseau. Il offre plusieurs interfaces de surveillance interactives différentes.
Note: IPTraf nécessite une taille d’écran d’au moins 80 colonnes sur 24 lignes.
Sur Ubuntu, vous pouvez installer iptraf-ng avec la commande suivante:
iptraf-ng doit être exécuté avec des privilèges root, donc vous devez le précéder de sudo:
Vous serez présenté avec un menu qui utilise un framework d’interface en ligne de commande populaire appelé ncurses.
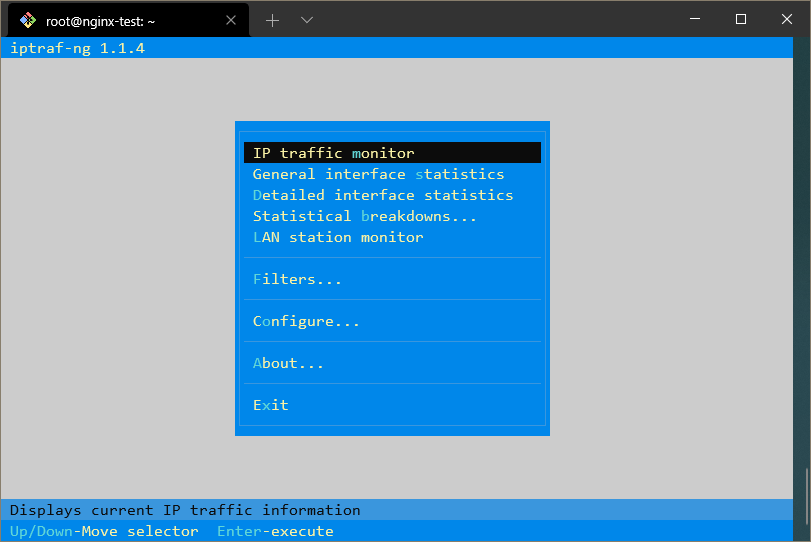
Avec ce menu, vous pouvez sélectionner quelle interface vous souhaitez accéder.
Par exemple, pour obtenir un aperçu de tout le trafic réseau, vous pouvez sélectionner le premier menu, puis « Toutes les interfaces ». Cela vous donnera un écran qui ressemble à ceci:
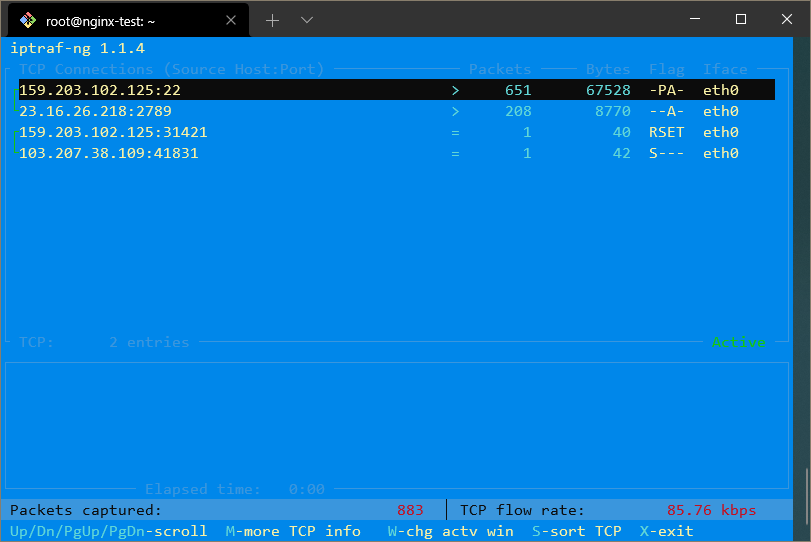
Ici, vous pouvez voir quelles adresses IP vous communiquez sur toutes vos interfaces réseau.
Si vous souhaitez que ces adresses IP soient résolues en domaines, vous pouvez activer la résolution DNS inverse en sortant de l’écran de trafic, en sélectionnant Configurer et en activant la résolution DNS inverse.
Vous pouvez également activer les noms de services TCP/UDP pour voir les noms des services exécutés au lieu des numéros de port.
Avec ces deux options activées, l’affichage peut ressembler à ceci:
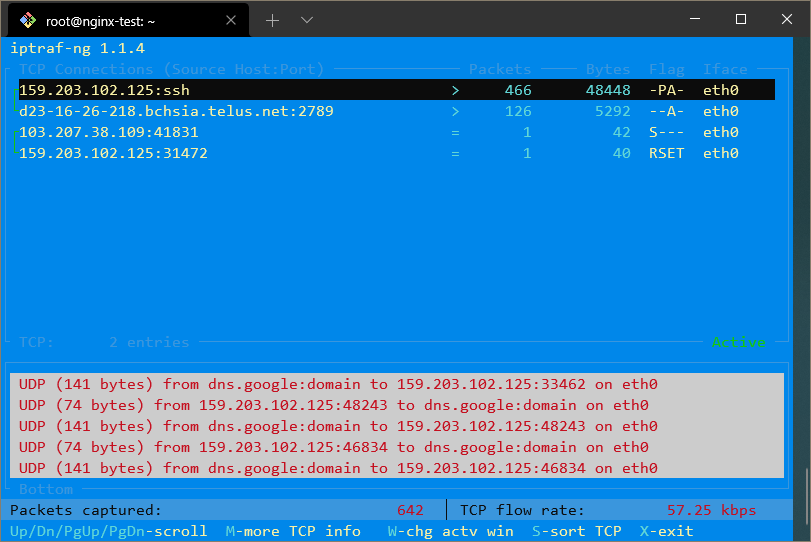
La commande netstat est un autre outil polyvalent pour recueillir des informations sur le réseau.
netstat est installé par défaut sur la plupart des systèmes modernes, mais vous pouvez l’installer vous-même en le téléchargeant depuis les dépôts de packages par défaut de votre serveur. Sur la plupart des systèmes Linux, y compris Ubuntu, le package contenant netstat est net-tools :
Par défaut, la commande netstat seule affiche une liste des sockets ouverts :
OutputActive Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .
Si vous ajoutez une option -a, elle listera tous les ports, en écoute ou non :
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .
Si vous souhaitez filtrer pour voir uniquement les connexions TCP ou UDP, utilisez respectivement les drapeaux -t ou -u :
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Consultez les statistiques en passant le drapeau « -s » :
OutputIp:
13500 total packets received
0 forwarded
0 incoming packets discarded
13500 incoming packets delivered
3078 requests sent out
16 dropped because of missing route
Icmp:
41 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
echo requests: 1
echo replies: 40
. . .
Si vous souhaitez mettre à jour continuellement la sortie, vous pouvez utiliser le drapeau -c. Il existe de nombreuses autres options disponibles pour netstat que vous pouvez apprendre en consultant sa page de manuel.
Dans la prochaine étape, vous apprendrez quelques façons utiles de surveiller l’utilisation de votre disque.
Étape 3 – Comment surveiller l’utilisation de votre disque
Pour un aperçu rapide de l’espace disque restant sur vos lecteurs connectés, vous pouvez utiliser le programme df.
Sans aucune option, sa sortie ressemble à ceci :
OutputFilesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm
Cela affiche l’utilisation du disque en octets, ce qui peut être un peu difficile à lire.
Pour résoudre ce problème, vous pouvez spécifier une sortie dans un format lisible par l’homme :
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
Si vous souhaitez voir l’espace disque total disponible sur tous les systèmes de fichiers, vous pouvez passer l’option --total. Cela ajoutera une ligne en bas avec des informations de résumé :
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
total 32G 1.2G 29G 4%
df peut fournir une vue d’ensemble utile. Une autre commande, du, donne un décompte par répertoire.
du analysera l’utilisation pour le répertoire actuel et tous les sous-répertoires. La sortie par défaut de du s’exécutant dans un répertoire personnel presque vide ressemble à ceci :
Output4 ./.cache
8 ./.ssh
28 .
Encore une fois, vous pouvez spécifier une sortie lisible par l’homme en lui passant -h :
Output4.0K ./.cache
8.0K ./.ssh
28K .
Pour voir les tailles de fichiers ainsi que les répertoires, tapez ce qui suit :
Output0 ./.cache/motd.legal-displayed
4 ./.cache
4 ./.ssh/authorized_keys
8 ./.ssh
4 ./.profile
4 ./.bashrc
4 ./.bash_history
28 .
Pour obtenir un total en bas, vous pouvez ajouter l’option -c :
Output4 ./.cache
8 ./.ssh
28 .
28 total
Si vous êtes uniquement intéressé par le total et non par les détails, vous pouvez exécuter :
Output28 .
Il existe également une interface ncurses pour du, appelée de manière appropriée ncdu, que vous pouvez installer :
Cela représentera graphiquement votre utilisation du disque :
Output--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history
Vous pouvez parcourir le système de fichiers en utilisant les flèches haut et bas et en appuyant sur Entrée sur n’importe quelle entrée de répertoire.
Dans la dernière section, vous apprendrez comment surveiller l’utilisation de votre mémoire.
Étape 4 – Comment surveiller l’utilisation de votre mémoire
Vous pouvez vérifier l’utilisation actuelle de la mémoire sur votre système en utilisant la commande free.
Lorsqu’il est utilisé sans options, la sortie ressemble à ceci :
Output total used free shared buff/cache available
Mem: 1004896 390988 123484 3124 490424 313744
Swap: 0 0 0
Pour afficher dans un format plus lisible, vous pouvez passer l’option -m pour afficher la sortie en mégaoctets :
Output total used free shared buff/cache available
Mem: 981 382 120 3 478 306
Swap: 0 0 0
La ligne Mem comprend la mémoire utilisée pour le tampon et le cache, qui est libérée dès que nécessaire à d’autres fins. Swap est la mémoire qui a été écrite dans un fichier d'échange sur le disque afin de conserver la mémoire active.
Enfin, la commande vmstat peut produire diverses informations sur votre système, y compris la mémoire, le swap, les entrées/sorties sur disque et les informations sur le CPU.
Vous pouvez utiliser la commande pour obtenir une autre vue sur l’utilisation de la mémoire :
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 99340 123712 248296 0 0 0 1 9 3 0 0 100 0
Vous pouvez voir cela en mégaoctets en spécifiant les unités avec le drapeau -S :
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 96 120 242 0 0 0 1 9 3 0 0 100 0
Pour obtenir des statistiques générales sur l’utilisation de la mémoire, tapez :
Output 495 M total memory
398 M used memory
252 M active memory
119 M inactive memory
96 M free memory
120 M buffer memory
242 M swap cache
0 M total swap
0 M used swap
0 M free swap
. . .
Pour obtenir des informations sur l’utilisation du cache des processus système individuels, tapez :
OutputCache Num Total Size Pages
ext4_groupinfo_4k 195 195 104 39
UDPLITEv6 0 0 768 10
UDPv6 10 10 768 10
tw_sock_TCPv6 0 0 256 16
TCPv6 11 11 1408 11
kcopyd_job 0 0 2344 13
dm_uevent 0 0 2464 13
bsg_cmd 0 0 288 14
. . .
Cela vous donnera des détails sur le type d’informations stockées dans le cache.
Conclusion
En utilisant ces outils, vous devriez commencer à pouvoir surveiller votre serveur à partir de la ligne de commande. Il existe de nombreux autres utilitaires de surveillance utilisés à des fins différentes, mais ceux-ci sont un bon point de départ.
Ensuite, vous voudrez peut-être apprendre sur la gestion des processus Linux en utilisant ps, kill et nice.