













L’utilisation de la surveillance informatique dans l’infrastructure d’une organisation peut améliorer sa fiabilité et aider à prévenir les problèmes sérieux, les défaillances et les temps d’arrêt. Il existe différentes approches pour mettre en œuvre la surveillance informatique, en utilisant des outils dédiés ou des fonctionnalités natives. Avec l’une ou l’autre approche, vous pouvez consulter les données de surveillance au besoin ou configurer des alertes automatiques et des rapports pour être informé des événements importants. Cet article de blog explique comment améliorer la stratégie de surveillance informatique en utilisant des alarmes et des rapports.
L’importance de la surveillance informatique et des rapports pour les entreprises
La surveillance informatique est cruciale pour les organisations car elle aide à garantir que l’infrastructure informatique fonctionne correctement et de manière fiable.
- Optimisation du temps de fonctionnement et de la fiabilité. Les systèmes informatiques critiques nécessitent généralement un fonctionnement 24h/24. Ces systèmes sont utilisés dans des industries telles que la santé, la finance et d’autres fournisseurs de services où les temps d’arrêt peuvent entraîner des conséquences graves. Heureusement, il est possible de prévenir de tels problèmes si vous mettez en place et configurez correctement un système de surveillance informatique.
La détection proactive des problèmes aide les administrateurs à découvrir les problèmes potentiels tels que les surcharges de serveur, les erreurs d’application, les problèmes matériels et la dégradation des performances à temps avant qu’ils ne conduisent à des défaillances majeures. Cette approche proactive permet aux administrateurs d’interagir et de prendre des mesures correctives avant d’avoir un impact négatif sur les serveurs, les machines virtuelles (VM), les opérations commerciales et les utilisateurs finaux. Recevoir des rapports indiquant des problèmes potentiels rend la surveillance informatique et l’administration plus efficaces.
- Renforcement de la sécurité. La surveillance des TI est utilisée pour détecter les tentatives d’accès non autorisées, le trafic réseau inhabituel et d’autres activités suspectes qui peuvent être un indicateur d’une cyberattaque. Cette approche permet aux administrateurs de détecter les menaces de sécurité à temps. Certains secteurs doivent se conformer aux exigences réglementaires qui nécessitent une surveillance continue des systèmes informatiques pour éviter des pénalités.
- Amélioration des performances et de l’efficacité. Les administrateurs peuvent optimiser l’utilisation des ressources sur les serveurs, les machines virtuelles et l’équipement réseau en configurant la surveillance et les alertes des TI. Configurer les outils de surveillance des TI pour suivre l’utilisation du CPU, de la mémoire et de la bande passante en vue d’une analyse ultérieure de ces données vous permet de mieux comprendre ce qu’il faut améliorer. En conséquence, les organisations peuvent optimiser leurs ressources et réduire les gaspillages pour atteindre une haute efficacité dans leurs systèmes informatiques. Cela aide également les administrateurs à identifier les goulots d’étranglement et à améliorer les performances.
- Améliorer la continuité des activités et la récupération après sinistre. La détection précoce des pannes est l’une des principales raisons pour lesquelles les administrateurs d’organisations devraient configurer des systèmes de surveillance informatique avec notifications. Cette approche peut détecter tôt les signes de corruption des données, de plantage d’applications et de pannes matérielles pour éviter la perte de données. Prévenir la perte de données est nécessaire pour maintenir la continuité des activités. En utilisant des outils de surveillance avec des notifications configurées, les administrateurs peuvent s’assurer que les systèmes de sauvegarde et les plans de récupération après sinistre sont testés et fonctionnent correctement. Cela peut être une assurance qu’une entreprise peut récupérer rapidement des données et des charges de travail en cas de sinistre.
- Améliorer l’expérience client. Les clients s’attendent à ce que les services soient disponibles à tout moment. Configurer des systèmes de surveillance informatique pour surveiller les serveurs, les VM, l’équipement réseau et les applications liées au fonctionnement du site web aide à garantir que les sites web et les services sont toujours disponibles pour les clients. Non seulement la disponibilité des ressources, mais la performance est également surveillée pour atteindre le meilleur service.
Recevoir des rapports contenant des informations sur les problèmes peut mener à une résolution rapide. Les rapports incluent les informations nécessaires aux administrateurs pour résoudre les problèmes le plus rapidement possible. Ces actions minimisent l’impact négatif sur les clients et, par conséquent, les clients ont une expérience positive.
- Gestion des coûts. La configuration d’une surveillance proactive peut prévenir les temps d’arrêt. Les temps d’arrêt imprévus peuvent être coûteux car une organisation perd des revenus et doit dépenser des ressources pour récupérer des données et l’infrastructure. La surveillance avec des notifications d’alerte permet aux administrateurs de résoudre le problème aussi rapidement que possible et de réduire le risque de temps d’arrêt.
Comprendre les alarmes dans la surveillance informatique
Configurer des alarmes pour les systèmes de surveillance informatique améliore le temps de réaction des administrateurs pour prendre conscience du problème et le résoudre plus rapidement. Si seules des ressources comme des pages web avec des graphiques et des statistiques sont configurées, alors l’administrateur système peut ne remarquer les problèmes que lorsqu’il consulte la page web avec les informations de surveillance. Les administrateurs ont un large éventail de tâches différentes et ne peuvent généralement pas surveiller en continu une page web avec l’état de l’infrastructure informatique.
Lorsque des alarmes sont configurées, les administrateurs reçoivent un message de notification concernant le problème, un problème potentiel, une panne ou d’autres événements critiques ou suspects dès que possible. Un intervalle de temps peut généralement être configuré, par exemple, un message peut être envoyé dans 1 minute ou dans 5 minutes après qu’un problème a été détecté par le système de surveillance.
En conséquence, l’administrateur système peut remarquer le problème plus rapidement et réagir pour le résoudre et éviter les conséquences négatives. Différentes méthodes de notification peuvent être utilisées, telles que les notifications par e-mail, SMS, Skype, etc., en fonction du logiciel de surveillance informatique.
Qu’est-ce que les alarmes et pourquoi sont-elles importantes ?
Les alarmes sont des notifications qui se déclenchent lorsqu’un événement spécifique se produit et que les conditions ou seuils appropriés sont atteints dans le système informatique. Ces conditions peuvent être basées sur différents événements, y compris :
- Problèmes de performance : Utilisation élevée du processeur, épuisement de la mémoire, temps de réponse lents
- Seuils de ressources : Espace disque faible, saturation de la bande passante réseau
- Pannes système : Pannes de serveur, erreurs d’application, interruptions de service
- Incidents de sécurité : Tentatives d’accès non autorisées, détection de logiciels malveillants, trafic réseau inhabituel
- Événements opérationnels : Échecs de sauvegarde, redémarrages de service, changements de configuration
Lorsqu’une alarme est déclenchée, le système de surveillance génère une alerte, et cette alerte est envoyée à l’utilisateur concerné, principalement l’administrateur informatique, par divers canaux. Ces alertes contiennent des informations sur le problème, y compris sa gravité, le système ou le composant affecté et les actions recommandées.
Métriques clés à surveiller
Utilisation du CPU. Surveiller l’utilisation du CPU est nécessaire pour s’assurer qu’il y a suffisamment de ressources pour les serveurs et les systèmes en termes de puissance de traitement. Cela est important pour gérer les charges de travail sans être surchargé. Une utilisation élevée du CPU peut être un signal que le système est surchargé. Une faible utilisation du CPU indique qu’il y a suffisamment de ressources ou que les ressources CPU sont sous-utilisées.
Utilisation de la mémoire (RAM). Les applications et les services ont besoin de suffisamment de mémoire pour un fonctionnement fluide, et le paramètre de mémoire est critique dans ce contexte. Les administrateurs doivent surveiller l’utilisation de la RAM pour prévenir les goulets d’étranglement de la mémoire, qui peuvent provoquer une dégradation des performances et même des plantages du système. Faites attention à une utilisation excessive de la mémoire, à une allocation de mémoire insuffisante et aux fuites de mémoire.
Utilisation du disque et performance I/O. L’espace disque et la performance des entrées/sorties (I/O) sont des métriques critiques pour le stockage des données. Il est recommandé de surveiller ces paramètres pour prévenir les problèmes liés au stockage, y compris les problèmes de performance. Faites attention à une utilisation élevée du disque, à une croissance rapide de l’espace disque utilisé, à une latence élevée lors de la lecture/écriture de données, et à des temps d’attente I/O fréquents. Un comportement anormal concernant ces paramètres peut indiquer des problèmes potentiels de stockage.
Bande passante réseau et latence. Les performances du réseau ont un impact sur toutes les opérations dans un bureau ou un datacenter car les ordinateurs, les serveurs et les machines virtuelles sont connectés les uns aux autres via le réseau. Les performances du réseau sont cruciales pour les services fournis aux clients. La surveillance de la bande passante réseau et de la latence vous permet de détecter les goulots d’étranglement et autres problèmes et de les résoudre à temps pour utiliser efficacement les ressources du réseau. Surveillez une utilisation élevée du réseau, la perte de paquets et une latence élevée car ces indicateurs sont des signes de performances lentes et de problèmes de connectivité réseau.
Disponibilité des services et des processus. Des processus importants s’exécutent dans les systèmes d’exploitation sur les serveurs ou les machines virtuelles, et ils doivent être disponibles pour répondre aux besoins de l’entreprise. La surveillance des services et de leur disponibilité garantit que les services critiques sont opérationnels. Pour garantir la disponibilité du service, les administrateurs doivent surveiller le temps de disponibilité, les fréquences de redémarrage des services et les échecs de processus.
Performances de la base de données. Les bases de données font souvent partie de solutions plus complexes, y compris des applications web. De plus, la plupart des solutions logicielles pour un usage interne dans les organisations nécessitent des bases de données. Pour ces raisons, il est important de surveiller les performances et la disponibilité de la base de données. La surveillance des bases de données garantit que les données sont accessibles et que les opérations associées se déroulent correctement. Lors de la surveillance d’une base de données, concentrez-vous sur les temps de réponse des requêtes, les requêtes lentes, les verrous de base de données et l’utilisation du pool de connexions, car ces métriques sont essentielles pour la santé de la base de données.
Rapports pour la surveillance informatique
La génération de rapports est utilisée pour fournir des informations structurées et exploitables à partir de l’énorme quantité de données collectées par les outils de surveillance. Le reporting transforme les données brutes en informations lisibles et compréhensibles pour les personnes travaillant dans une organisation, principalement pour les administrateurs informatiques. Après avoir vérifié les rapports, les administrateurs et la direction peuvent prendre des décisions éclairées. Cela permet aux équipes informatiques d’optimiser les performances, de prévenir les problèmes et d’améliorer la continuité des activités.
Les rapports peuvent mettre en évidence des anomalies qui ne sont pas perceptibles lors de la recherche des alarmes. Les données des rapports sont agrégées pour plus de commodité afin d’éviter la nécessité de rechercher manuellement les indicateurs clés et d’organiser les données collectées. En conséquence, les administrateurs ont une vue d’ensemble de haut niveau de l’ensemble de l’infrastructure et des composants les plus importants. Être informé des conditions ayant conduit à un incident peut être utilisé par les administrateurs pour une réponse rapide aux incidents et pour mettre en œuvre des mesures préventives.
Surveillance avec NAKIVO Backup & Replication
NAKIVO Backup & Replication peut vous aider à surveiller les éléments de votre infrastructure informatique. Allez dans la section Surveillance dans l’interface web, ajoutez les éléments surveillés et consultez les graphiques affichant les indicateurs pris en charge de l’infrastructure VMware vSphere.
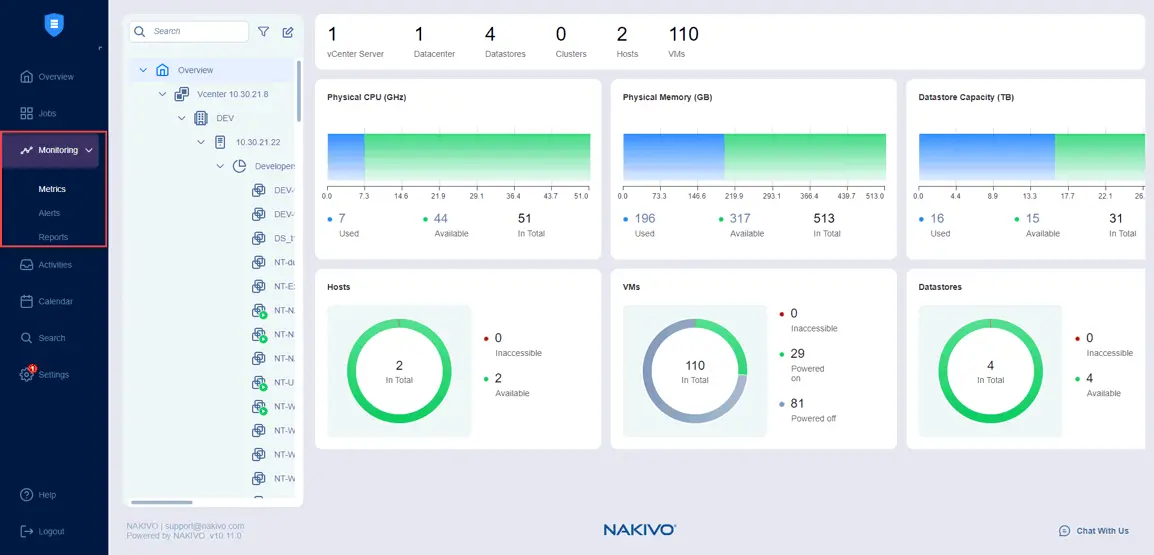
Vous pouvez sélectionner des éléments à surveiller, tels que des hôtes ESXi ou des clusters, des VM VMware et des datastores dans Surveillance > Indicateurs.
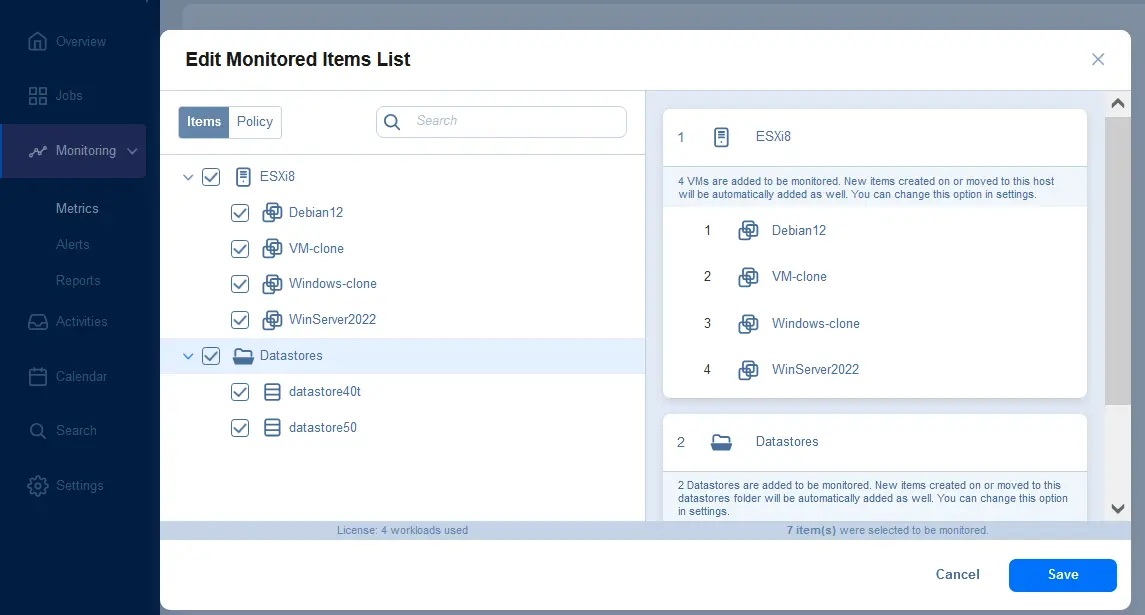
Configurer des alertes dans la solution NAKIVO
Vous pouvez configurer des alertes dans la solution NAKIVO pour être informé des problèmes potentiels le plus tôt possible, ce qui vous permet de les résoudre rapidement avant qu’ils ne conduisent à des conséquences graves.
- Allez dans Surveillance > Alertes, sélectionnez l’onglet Gestion des modèles d’alerte et cliquez sur + pour ajouter des alertes pour des éléments spécifiques.
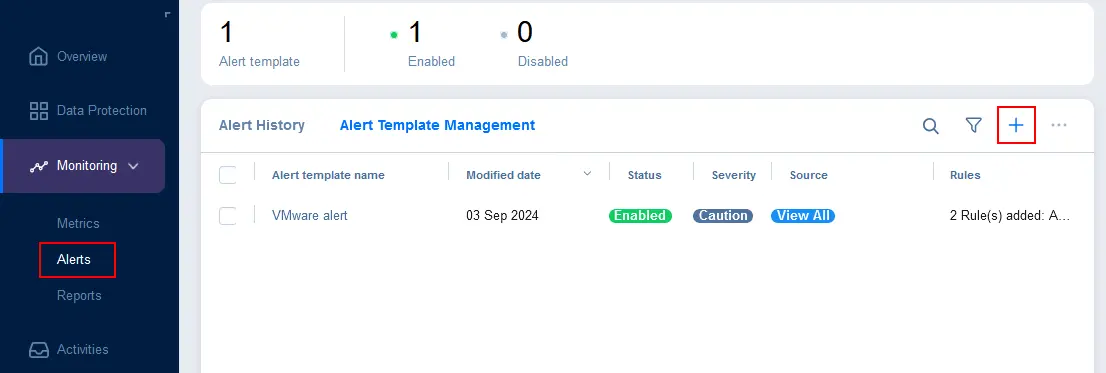
- Sélectionnez les éléments surveillés pour lesquels l’alerte doit être déclenchée. Vous pouvez sélectionner des hôtes ESXi, des machines virtuelles (VM) ou des magasins de données. Cliquez sur Suivant pour continuer.
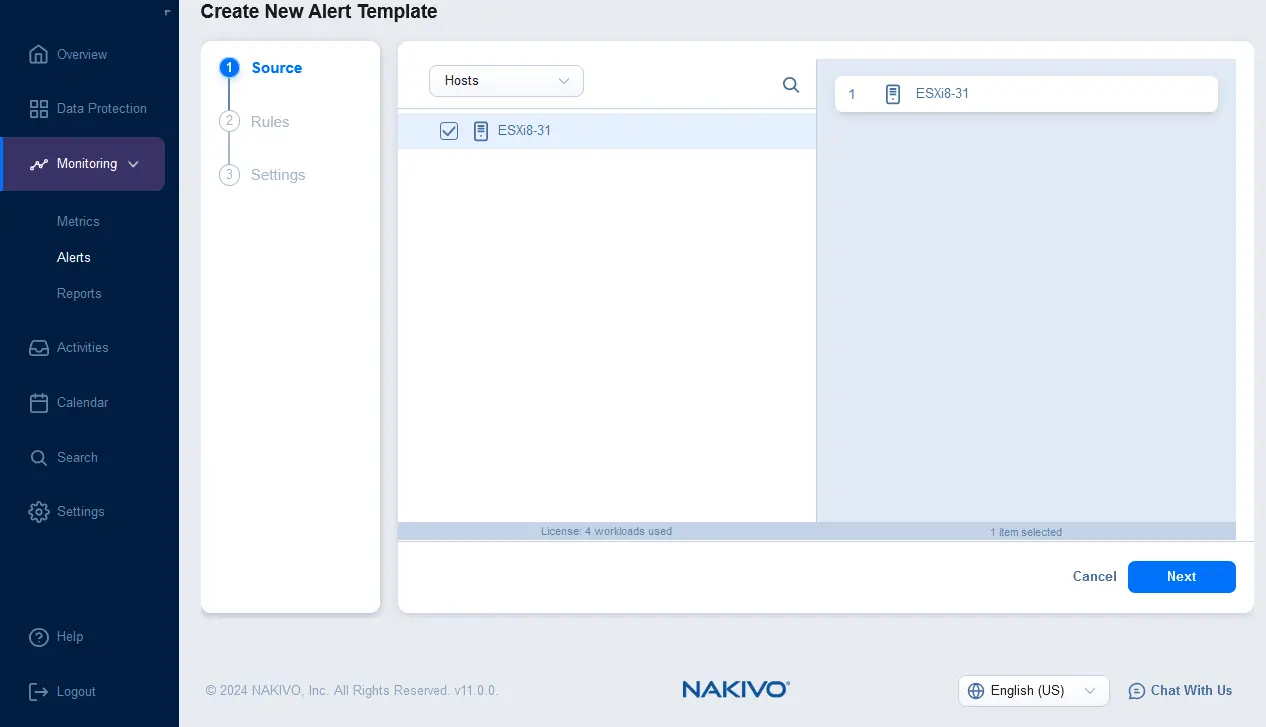
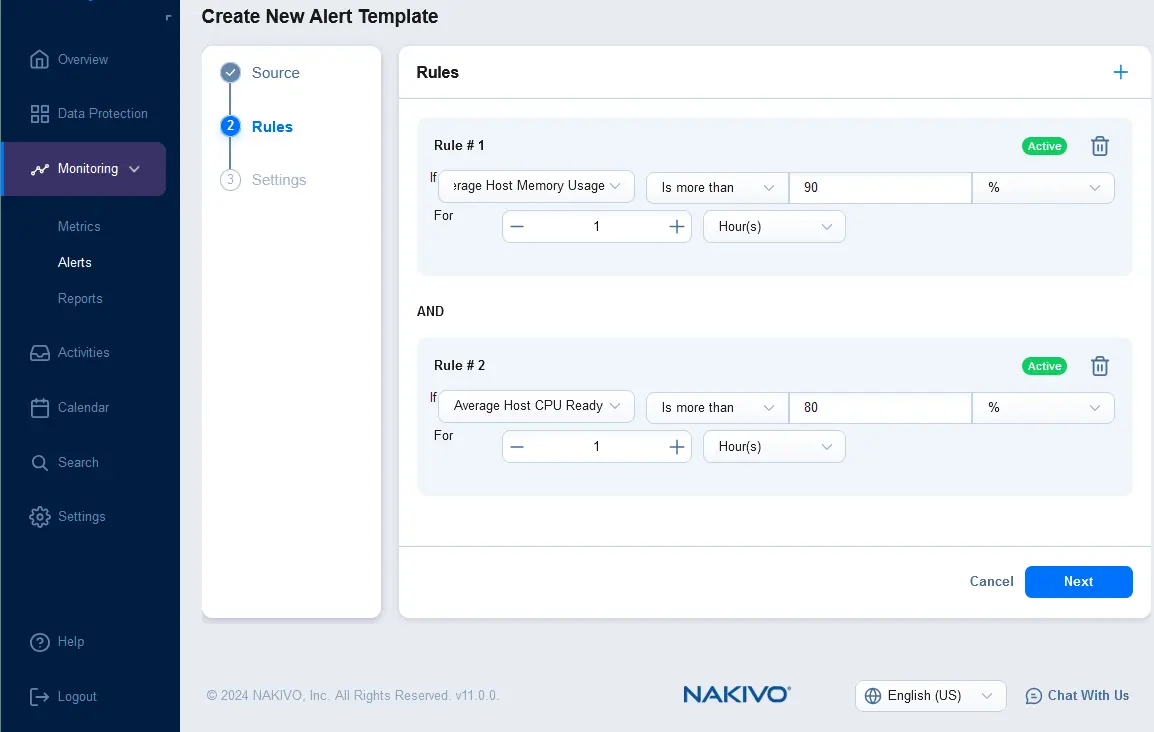
- Configurez des règles pour un nouveau modèle d’alerte. Cliquez sur + et sélectionnez la condition de règle. Par exemple, vous pouvez définir un modèle de règle d’alerte qui doit être déclenché si l’utilisation moyenne de la mémoire de l’hôte dépasse 90 % pendant 1 heure. Vous pouvez ajouter plusieurs règles pour un modèle d’alerte.
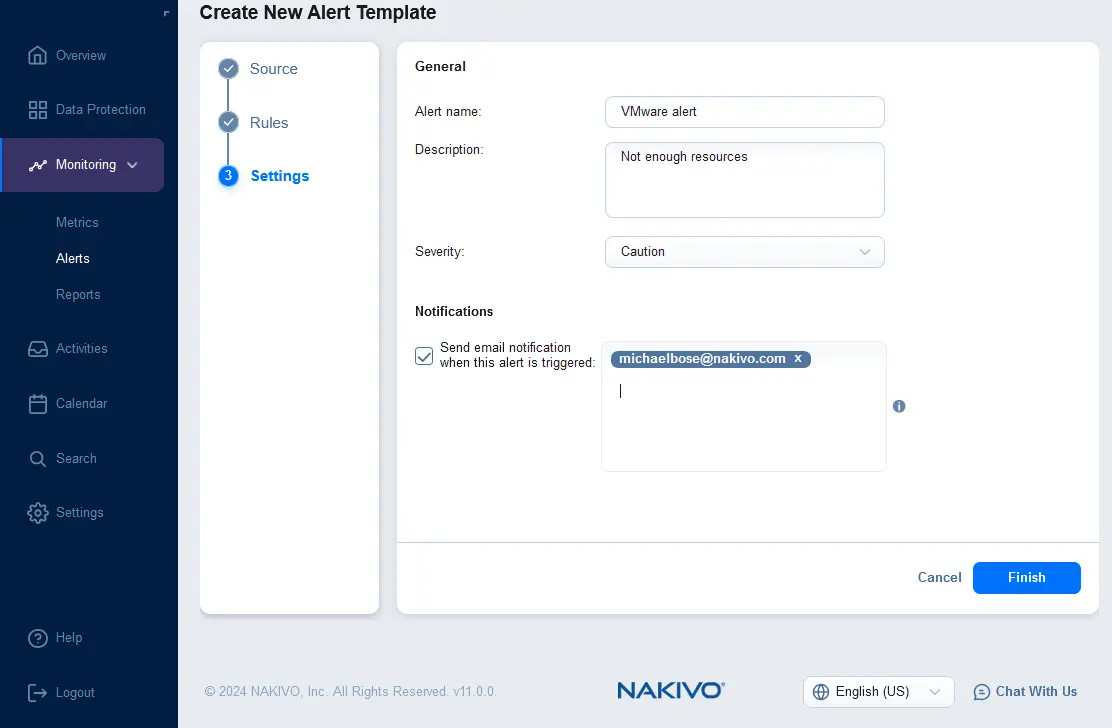
- Configurer les paramètres du modèle d’alerte. Entrez le nom et la description de l’alerte, et sélectionnez la gravité. Vous pouvez cocher la case pour envoyer une notification par e-mail lorsque cette alerte est déclenchée et entrer les adresses e-mail des destinataires qui devraient recevoir les notifications d’alerte. Cliquez sur Terminer.
Configuration des rapports dans la solution NAKIVO
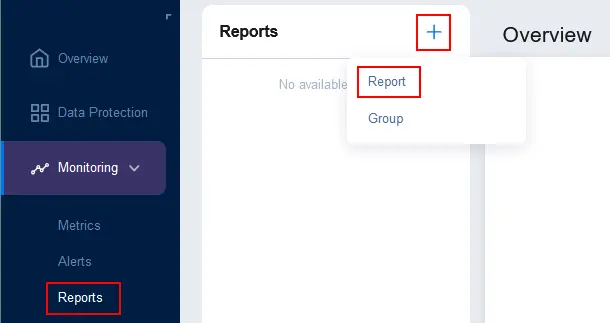
- Pour configurer des rapports, allez dans Surveillance > Rapports, cliquez sur + et appuyez sur Rapport.
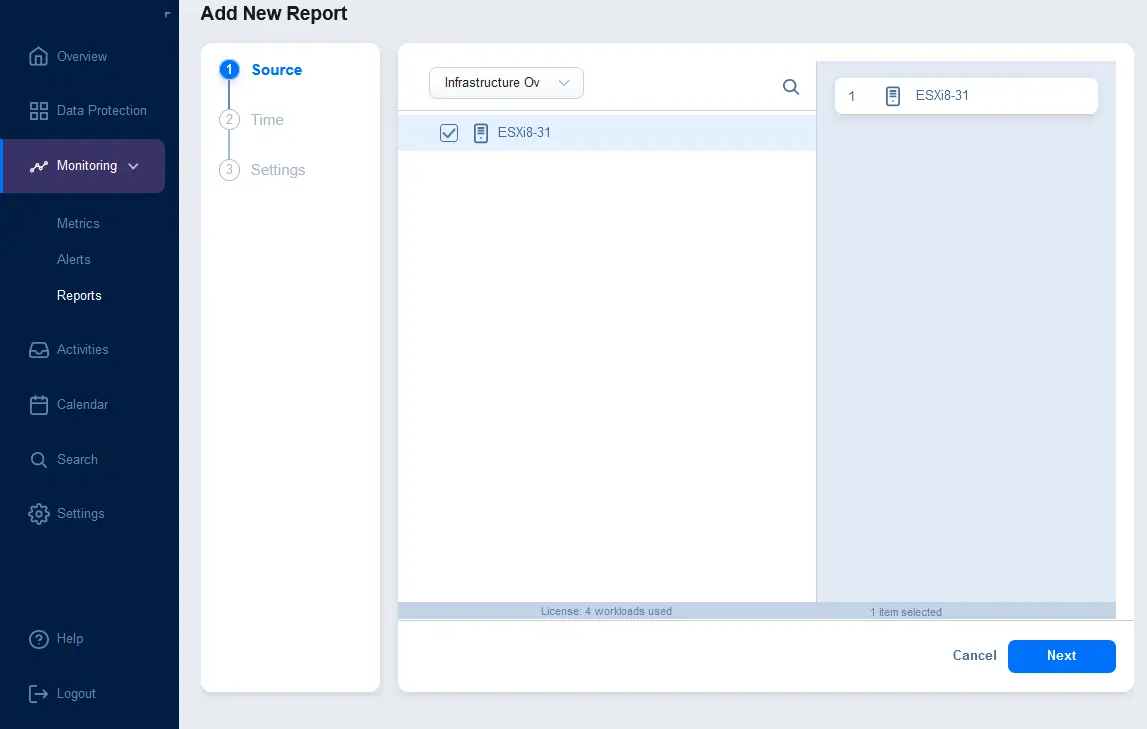
- Vous pouvez sélectionner l’un des types de sources pris en charge :
- Aperçu de l’infrastructure – informations sur les serveurs vCenter, les hôtes ESXi gérés par vCenter et les hôtes ESXi autonomes
- Performance des VM
- Capacité du datastore
- Performance des hôtes
- Rapport de protection
Une fois le type de source sélectionné, sélectionnez les éléments à inclure dans le rapport. Dans la capture d’écran ci-dessous, vous pouvez voir qu’Aperçu de l’infrastructure est sélectionné dans la liste déroulante et qu’un hôte ESXi est sélectionné pour être inclus dans le rapport. Cliquez sur Suivant pour continuer.
- Configurez les plages de dates et d’heures pour le rapport. Par exemple, vous pouvez créer un rapport pour les 30 derniers jours.
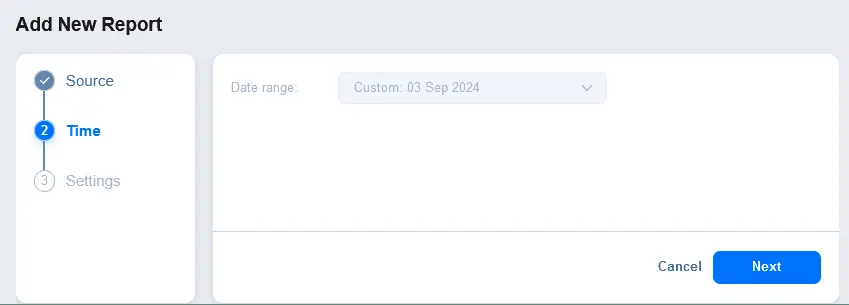
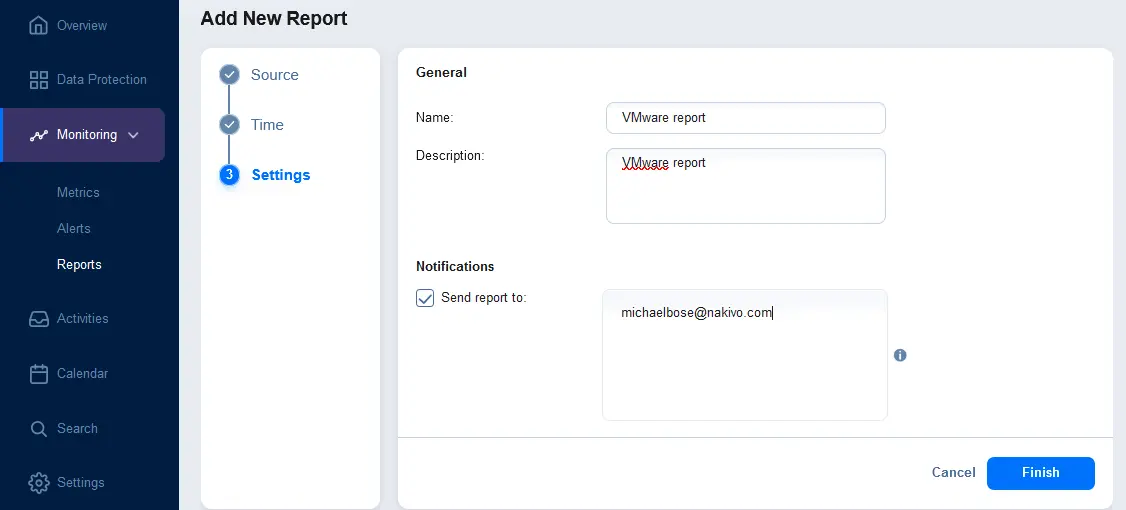
- Configurez les paramètres du rapport. Entrez un nom de rapport affiché et une description. En option, dans la section Notifications, sélectionnez la case à cocher pour envoyer un rapport aux adresses e-mail spécifiées. Entrez une adresse e-mail et appuyez sur Entrée pour appliquer cette adresse e-mail. Vous pouvez entrer plusieurs adresses e-mail. Cliquez sur Terminer pour enregistrer les paramètres de création du rapport.
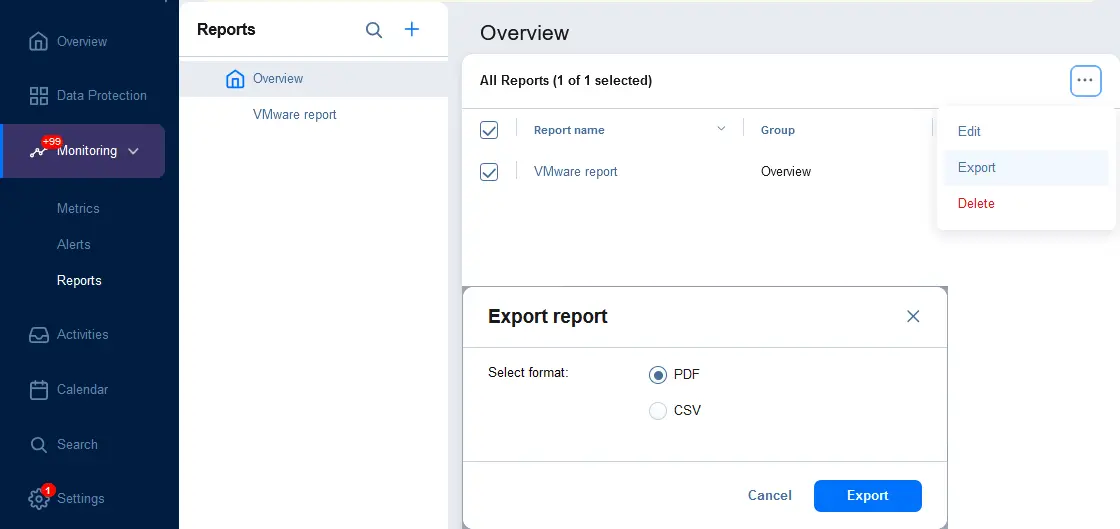
- Vous pouvez exporter des rapports dans un fichier. Allez à Surveillance > Rapports et sélectionnez les rapports que vous souhaitez exporter (sélectionnez les cases à cocher). Cliquez sur le bouton … (plus d’options), cliquez sur Exporter, et dans la boîte de dialogue, sélectionnez le format de fichier (PDF ou CSV). Cliquez sur Exporter.
Conclusion
La surveillance des infrastructures informatiques peut améliorer l’efficacité de l’administration, garantir la continuité des affaires et réduire les coûts. Il est recommandé de configurer les outils de surveillance informatique pour envoyer des alertes et des rapports afin de répondre rapidement aux incidents afin de prévenir les problèmes potentiels et de résoudre les problèmes existants dès que possible. Utilisez NAKIVO Backup & Replication pour protéger vos données, y compris les machines virtuelles VMware, ainsi que pour surveiller votre infrastructure vSphere et vos travaux de protection des données.
Source:
https://www.nakivo.com/blog/how-to-use-alarms-and-reporting-for-it-monitoring/