













Statut: Obsolète
Cet article est obsolète et n’est plus maintenu.
Raison
Les étapes de ce tutoriel fonctionnent toujours, mais produiront une configuration qui est désormais inutilement difficile à maintenir.
Voir à la place
Cet article peut encore être utile comme référence, mais peut ne pas suivre les meilleures pratiques. Nous recommandons fortement d’utiliser un article plus récent.
Introduction
Outre la traçabilité et la journalisation, la surveillance et l’alerte sont des composants essentiels d’une pile d’observabilité Kubernetes. La configuration de la surveillance pour votre cluster Kubernetes DigitalOcean vous permet de suivre votre utilisation des ressources, d’analyser et de déboguer les erreurs d’application.
A monitoring system usually consists of a time-series database that houses metric data and a visualization layer. In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack.
Une solution de surveillance populaire est la pile open-source Prometheus, Grafana et Alertmanager, déployée aux côtés de kube-state-metrics et de node_exporter pour exposer les métriques d’objets Kubernetes au niveau du cluster ainsi que les métriques au niveau de la machine telles que l’utilisation du CPU et de la mémoire.
Déployer cette pile de surveillance sur un cluster Kubernetes nécessite la configuration de composants individuels, de manifestes, de métriques Prometheus et de tableaux de bord Grafana, ce qui peut prendre un certain temps. Le Guide de démarrage rapide de la surveillance du cluster Kubernetes DigitalOcean, publié par l’équipe de développement communautaire de l’éducation des développeurs de DigitalOcean, contient des manifestes entièrement définis pour une pile de surveillance de cluster Prometheus-Grafana-Alertmanager, ainsi qu’un ensemble d’alertes préconfigurées et de tableaux de bord Grafana. Il peut vous aider à démarrer rapidement et constitue une base solide à partir de laquelle construire votre pile d’observabilité.
Dans ce tutoriel, nous déploierons cette pile préconfigurée sur DigitalOcean Kubernetes, accéderons aux interfaces Prometheus, Grafana et Alertmanager, et décrirons comment la personnaliser.
Prérequis
Avant de commencer, vous aurez besoin d’un cluster Kubernetes DigitalOcean à votre disposition, ainsi que des outils suivants installés dans votre environnement de développement local :
- L’interface de ligne de commande
kubectlinstallée sur votre machine locale et configurée pour se connecter à votre cluster. Vous pouvez en savoir plus sur l’installation et la configuration dekubectldans sa documentation officielle. - Le système de contrôle de version git installé sur votre machine locale. Pour apprendre à installer git sur Ubuntu 18.04, consultez Comment installer Git sur Ubuntu 18.04.
- L’outil Coreutils base64 installé sur votre machine locale. Si vous utilisez une machine Linux, il sera très probablement déjà installé. Si vous utilisez OS X, vous pouvez utiliser
openssl base64, qui est installé par défaut.
<$>[note]
Note: Le démarrage rapide de la surveillance du cluster a été testé uniquement sur les clusters Kubernetes de DigitalOcean. Pour utiliser le démarrage rapide avec d’autres clusters Kubernetes, des modifications des fichiers de manifestation peuvent être nécessaires.
<$>
Étape 1 — Clonage du référentiel GitHub et configuration des variables d’environnement
Pour commencer, clonez le référentiel GitHub du suivi de cluster Kubernetes DigitalOcean sur votre machine locale à l’aide de git :
Ensuite, accédez au référentiel :
Vous devriez voir la structure de répertoire suivante :
OutputLICENSE
README.md
changes.txt
manifest
Le répertoire manifest contient des manifestes Kubernetes pour tous les composants de la pile de suivi, y compris les comptes de service, les déploiements, les ensembles d’états, les configurations, etc. Pour en savoir plus sur ces fichiers de manifeste et comment les configurer, passez à Configuration de la pile de suivi.
Si vous souhaitez simplement démarrer les choses, commencez par définir les variables d’environnement APP_INSTANCE_NAME et NAMESPACE, qui seront utilisées pour configurer un nom unique pour les composants de la pile et configurer l’Espace de noms dans lequel la pile sera déployée :
Dans ce tutoriel, nous définissons APP_INSTANCE_NAME sur sammy-cluster-monitoring, qui précédera tous les noms d’objets Kubernetes de la pile de surveillance. Vous devriez substituer un préfixe descriptif unique pour votre pile de surveillance. Nous définissons également l’Espace de noms sur default. Si vous souhaitez déployer la pile de surveillance dans un Espace de noms autre que default, assurez-vous de le créer d’abord dans votre cluster :
Vous devriez voir la sortie suivante :
Outputnamespace/sammy created
Dans ce cas, la variable d’environnement NAMESPACE a été définie sur sammy. Tout au long du reste du tutoriel, nous supposerons que NAMESPACE a été défini sur default.
Maintenant, utilisez la commande base64 pour encoder en base64 un mot de passe Grafana sécurisé. Assurez-vous de substituer un mot de passe de votre choix pour votre_mot_de_passe_grafana :
Si vous utilisez macOS, vous pouvez substituer la commande openssl base64 qui est installée par défaut.
À ce stade, vous avez récupéré les manifestes Kubernetes de la pile et configuré les variables d’environnement requises, vous êtes donc maintenant prêt à substituer les variables configurées dans les fichiers de manifeste Kubernetes et à créer la pile dans votre cluster Kubernetes.
Étape 2 — Création de la pile de surveillance
Le dépôt de démarrage rapide de surveillance Kubernetes de DigitalOcean contient des manifestes pour les composants de surveillance, de collecte et de visualisation suivants :
- Prometheus est une base de données de séries temporelles et un outil de surveillance qui fonctionne en interrogeant les points de terminaison des métriques et en collectant et en traitant les données exposées par ces points de terminaison. Il vous permet d’interroger ces données en utilisant PromQL, un langage de requête de données de séries temporelles. Prometheus sera déployé dans le cluster en tant que StatefulSet avec 2 répliques qui utilise des Volumes Persistants avec le Stockage en Bloc de DigitalOcean. De plus, un ensemble préconfiguré d’Alertes, de Règles et de Tâches Prometheus sera stocké sous forme de ConfigMap. Pour en savoir plus sur ceux-ci, passez à la section Prometheus de Configuration de la pile de surveillance.
- Alertmanager, généralement déployé aux côtés de Prometheus, forme la couche d’alerte de la pile, traitant les alertes générées par Prometheus et les dédupliquant, les regroupant et les routant vers des intégrations telles que l’email ou PagerDuty. Alertmanager sera installé en tant que StatefulSet avec 2 réplicas. Pour en savoir plus sur Alertmanager, consultez Alerting dans la documentation de Prometheus.
- Grafana est un outil de visualisation de données et d’analyse qui vous permet de créer des tableaux de bord et des graphiques pour vos données de métriques. Grafana sera installé en tant que StatefulSet avec une réplica. De plus, un ensemble préconfiguré de tableaux de bord générés par kubernetes-mixin sera stocké sous forme de ConfigMap.
- kube-state-metrics est un agent supplémentaire qui écoute le serveur API Kubernetes et génère des métriques sur l’état des objets Kubernetes tels que les déploiements et les pods. Ces métriques sont servies en texte clair sur des points de terminaison HTTP et consommées par Prometheus. kube-state-metrics sera installé en tant que Deployment auto-évolutif avec une réplica.
- node-exporter, un exportateur Prometheus qui s’exécute sur les nœuds du cluster et fournit des métriques OS et matériel telles que l’utilisation du CPU et de la mémoire à Prometheus. Ces métriques sont également servies en texte clair sur des points de terminaison HTTP et consommées par Prometheus. node-exporter sera installé en tant que DaemonSet.
Par défaut, en plus de gratter les métriques générées par node-exporter, kube-state-metrics et les autres composants mentionnés ci-dessus, Prometheus sera configuré pour gratter les métriques des composants suivants :
- kube-apiserver, le serveur API Kubernetes.
- kubelet, l’agent principal du nœud qui interagit avec kube-apiserver pour gérer les Pods et les conteneurs sur un nœud.
- cAdvisor, un agent de nœud qui découvre les conteneurs en cours d’exécution et collecte leurs métriques d’utilisation CPU, mémoire, système de fichiers et réseau.
Pour en savoir plus sur la configuration de ces composants et des tâches de grattage de Prometheus, passez directement à Configuration de la pile de surveillance. Nous allons maintenant substituer les variables d’environnement définies à l’étape précédente dans les fichiers de manifeste du dépôt, et concaténer les manifestes individuels en un seul fichier maître.
Commencez par utiliser awk et envsubst pour remplir les variables APP_INSTANCE_NAME, NAMESPACE et GRAFANA_GENERATED_PASSWORD dans les fichiers de manifeste du dépôt. Après avoir substitué les valeurs des variables, les fichiers seront combinés et enregistrés dans un fichier de manifeste maître appelé sammy-cluster-monitoring_manifest.yaml.
Vous devriez envisager de stocker ce fichier dans un contrôle de version afin de pouvoir suivre les modifications apportées à la pile de surveillance et revenir à des versions précédentes. Si vous le faites, assurez-vous de nettoyer la variable admin-password du fichier afin de ne pas enregistrer votre mot de passe Grafana dans le contrôle de version.
Maintenant que vous avez généré le fichier de manifeste maître, utilisez kubectl apply -f pour appliquer le manifeste et créer la pile dans l’espace de noms que vous avez configuré:
Vous devriez voir une sortie similaire à ce qui suit:
Outputserviceaccount/alertmanager created
configmap/sammy-cluster-monitoring-alertmanager-config created
service/sammy-cluster-monitoring-alertmanager-operated created
service/sammy-cluster-monitoring-alertmanager created
. . .
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/sammy-cluster-monitoring-prometheus-config created
service/sammy-cluster-monitoring-prometheus created
statefulset.apps/sammy-cluster-monitoring-prometheus created
Vous pouvez suivre la progression du déploiement de la pile en utilisant kubectl get all. Une fois que tous les composants de la pile sont RUNNING, vous pouvez accéder aux tableaux de bord Grafana préconfigurés via l’interface web de Grafana.
Étape 3 — Accès à Grafana et Exploration des Données Métriques
Le manifeste du service Grafana expose Grafana en tant que Service ClusterIP, ce qui signifie qu’il est uniquement accessible via une adresse IP interne au cluster. Pour accéder à Grafana en dehors de votre cluster Kubernetes, vous pouvez soit utiliser kubectl patch pour mettre à jour le Service en place vers un type orienté vers l’extérieur tel que NodePort ou LoadBalancer, soit utiliser kubectl port-forward pour rediriger un port local vers un port Pod Grafana. Dans ce tutoriel, nous redirigerons les ports, vous pouvez donc passer à Redirection d’un port local pour accéder au service Grafana. La section suivante sur l’exposition de Grafana à l’extérieur est incluse à des fins de référence.
Exposition du service Grafana à l’aide d’un équilibreur de charge (optionnel)
Si vous souhaitez créer un équilibreur de charge DigitalOcean pour Grafana avec une adresse IP publique externe, utilisez kubectl patch pour mettre à jour le Service Grafana existant en place vers le type de service LoadBalancer:
La commande patch de kubectl vous permet de mettre à jour les objets Kubernetes sur place pour apporter des modifications sans avoir à redéployer les objets. Vous pouvez également modifier directement le fichier de manifeste principal, en ajoutant un paramètre type: LoadBalancer à la spécification du service Grafana. Pour en savoir plus sur kubectl patch et les types de services Kubernetes, vous pouvez consulter les ressources Update API Objects in Place Using kubectl patch et Services dans la documentation officielle de Kubernetes.
Après avoir exécuté la commande ci-dessus, vous devriez voir ce qui suit :
Outputservice/sammy-cluster-monitoring-grafana patched
Cela peut prendre plusieurs minutes pour créer le Load Balancer et lui attribuer une adresse IP publique. Vous pouvez suivre sa progression en utilisant la commande suivante avec le drapeau -w pour surveiller les changements :
Une fois que le Load Balancer DigitalOcean a été créé et qu’une adresse IP externe lui a été attribuée, vous pouvez récupérer son adresse IP externe en utilisant les commandes suivantes :
Vous pouvez désormais accéder à l’interface utilisateur de Grafana en naviguant sur http://SERVICE_IP/.
Transfert d’un port local pour accéder au service Grafana
Si vous ne souhaitez pas exposer le service Grafana publiquement, vous pouvez également rediriger le port local 3000 directement vers un pod Grafana dans le cluster en utilisant kubectl port-forward.
Vous devriez voir la sortie suivante :
OutputForwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Cela redirigera le port local 3000 vers le containerPort 3000 du pod Grafana sammy-cluster-monitoring-grafana-0. Pour en savoir plus sur la redirection des ports dans un cluster Kubernetes, consultez Utiliser la redirection de port pour accéder aux applications dans un cluster.
Rendez-vous sur http://localhost:3000 dans votre navigateur web. Vous devriez voir la page de connexion Grafana suivante :

Pour vous connecter, utilisez le nom d’utilisateur par défaut admin (si vous n’avez pas modifié le paramètre admin-user) et le mot de passe que vous avez configuré à l’étape 1.
Vous serez dirigé vers le Tableau de bord d’accueil suivant :
Dans la barre de navigation de gauche, sélectionnez le bouton Tableaux de bord, puis cliquez sur Gérer :
Vous serez dirigé vers l’interface de gestion des tableaux de bord suivante, qui répertorie les tableaux de bord configurés dans le manifeste dashboards-configmap.yaml :
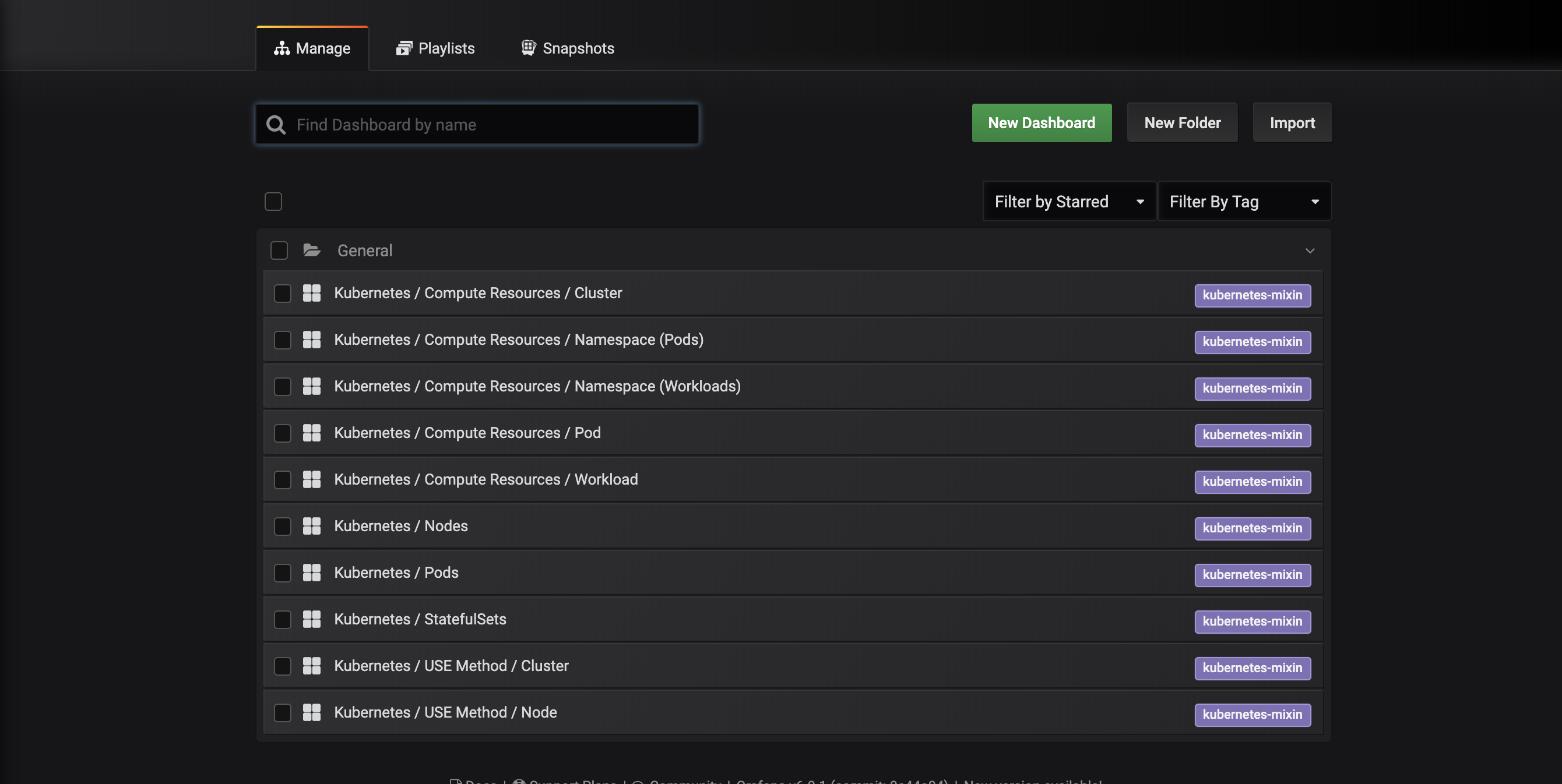
Ces tableaux de bord sont générés par kubernetes-mixin, un projet open source qui vous permet de créer un ensemble standardisé de tableaux de bord Grafana de surveillance de cluster et d’alertes Prometheus. Pour en savoir plus, consultez le dépôt GitHub de kubernetes-mixin.
Cliquez sur le tableau de bord Kubernetes / Nodes, qui visualise l’utilisation du CPU, de la mémoire, du disque et du réseau pour un nœud donné :
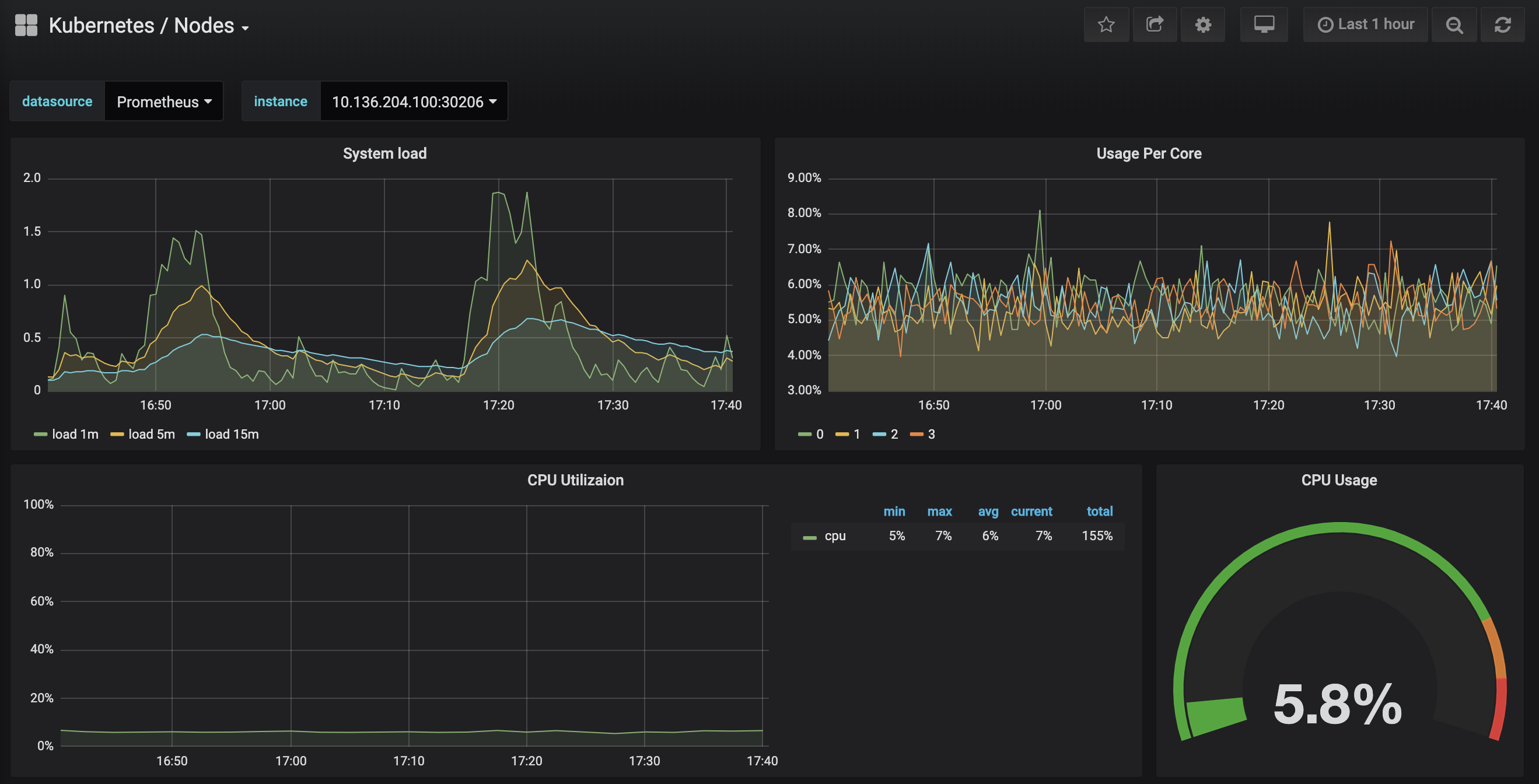
Expliquer comment utiliser ces tableaux de bord dépasse le cadre de ce tutoriel, mais vous pouvez consulter les ressources suivantes pour en savoir plus :
- Pour en savoir plus sur la méthode USE pour analyser les performances d’un système, vous pouvez consulter la page La méthode Utilisation, Saturation et Erreurs (USE) de Brendan Gregg.
- Le Livre des SRE de Google est une autre ressource utile, en particulier le chapitre 6 : Surveillance des systèmes distribués.
- Pour apprendre à créer vos propres tableaux de bord Grafana, consultez la page Prise en main de Grafana.
À l’étape suivante, nous suivrons un processus similaire pour nous connecter et explorer le système de surveillance Prometheus.
Étape 4 — Accès à Prometheus et Alertmanager
Pour se connecter aux Pods Prometheus, nous pouvons utiliser kubectl port-forward pour rediriger un port local. Si vous avez fini d’explorer Grafana, vous pouvez fermer le tunnel de redirection de port en appuyant sur CTRL-C. Alternativement, vous pouvez ouvrir un nouveau shell et créer une nouvelle connexion de redirection de port.
Commencez par répertorier les Pods en cours d’exécution dans l’espace de noms default:
Vous devriez voir les Pods suivants :
Outputsammy-cluster-monitoring-alertmanager-0 1/1 Running 0 17m
sammy-cluster-monitoring-alertmanager-1 1/1 Running 0 15m
sammy-cluster-monitoring-grafana-0 1/1 Running 0 16m
sammy-cluster-monitoring-kube-state-metrics-d68bb884-gmgxt 2/2 Running 0 16m
sammy-cluster-monitoring-node-exporter-7hvb7 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-c2rvj 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-w8j74 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-0 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-1 1/1 Running 0 16m
Nous allons rediriger le port local 9090 vers le port 9090 du Pod sammy-cluster-monitoring-prometheus-0 :
Vous devriez voir la sortie suivante :
OutputForwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Cela indique que le port local 9090 est redirigé avec succès vers le Pod Prometheus.
Visitez http://localhost:9090 dans votre navigateur Web. Vous devriez voir la page Graphique Prometheus suivante :

À partir de là, vous pouvez utiliser PromQL, le langage de requête Prometheus, pour sélectionner et agréger des métriques de séries temporelles stockées dans sa base de données. Pour en savoir plus sur PromQL, consultez L’interrogation de Prometheus dans la documentation officielle de Prometheus.
Dans le champ Expression, tapez kubelet_node_name et appuyez sur Exécuter. Vous devriez voir une liste de séries temporelles avec la métrique kubelet_node_name qui rapporte les nœuds de votre cluster Kubernetes. Vous pouvez voir quel nœud a généré la métrique et quel job a collecté la métrique dans les étiquettes de la métrique :

Enfin, dans la barre de navigation supérieure, cliquez sur Statut puis sur Cibles pour voir la liste des cibles que Prometheus a été configuré pour collecter. Vous devriez voir une liste de cibles correspondant à la liste des points de terminaison de surveillance décrite au début de Étape 2.
Pour en savoir plus sur Prometheus et comment interroger les métriques de votre cluster, consultez la documentation officielle de Prometheus.
Pour vous connecter à Alertmanager, qui gère les alertes générées par Prometheus, nous suivrons un processus similaire à celui que nous avons utilisé pour nous connecter à Prometheus. En général, vous pouvez explorer les alertes Alertmanager en cliquant sur Alertes dans la barre de navigation supérieure de Prometheus.
Pour vous connecter aux Pods Alertmanager, nous utiliserons à nouveau kubectl port-forward pour rediriger un port local. Si vous avez terminé d’explorer Prometheus, vous pouvez fermer le tunnel de redirection de port en appuyant sur CTRL-C ou ouvrir un nouvel shell pour créer une nouvelle connexion.
Nous allons faire avancer le port local 9093 vers le port 9093 du Pod sammy-cluster-monitoring-alertmanager-0:
Vous devriez voir la sortie suivante :
OutputForwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
Cela indique que le port local 9093 est redirigé avec succès vers un Pod Alertmanager.
Visitez http://localhost:9093 dans votre navigateur Web. Vous devriez voir la page suivante des Alertes d’Alertmanager :
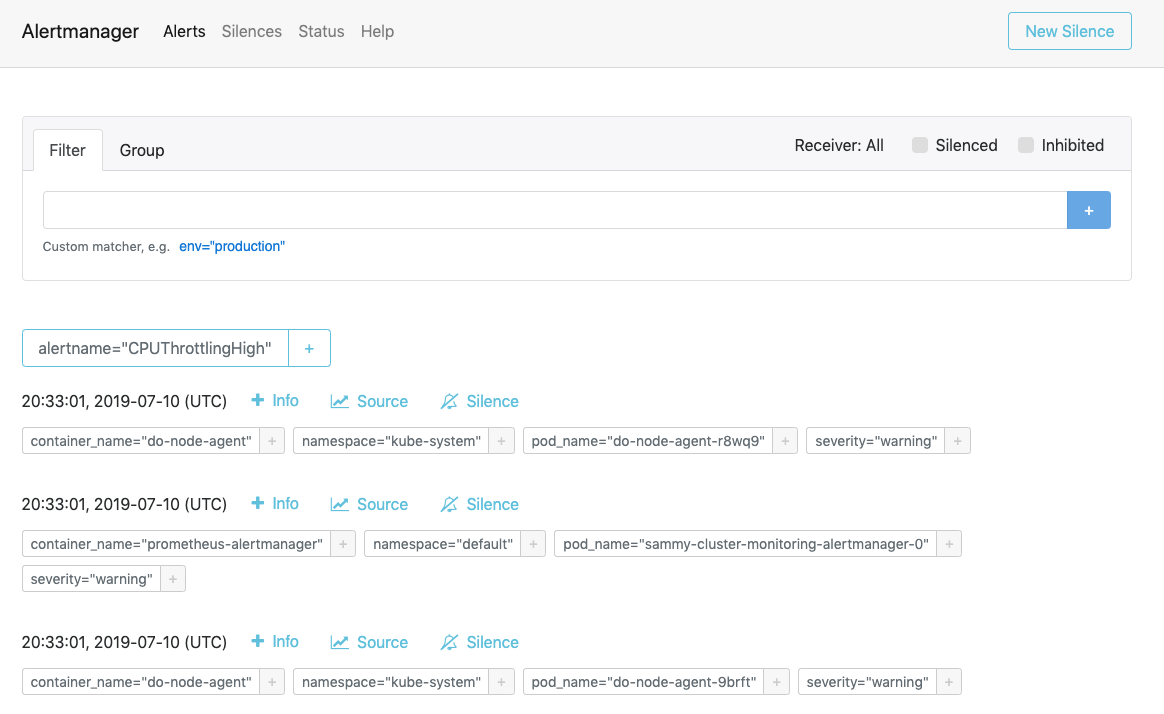
À partir de là, vous pouvez explorer les alertes déclenchées et éventuellement les mettre en sourdine. Pour en savoir plus sur Alertmanager, consultez la documentation officielle d’Alertmanager.
Dans la prochaine étape, vous apprendrez comment configurer et éventuellement mettre à l’échelle certains des composants de la pile de surveillance.
Étape 6 — Configuration de la pile de surveillance (optionnel)
Les manifestes inclus dans le référentiel de démarrage rapide de surveillance de cluster Kubernetes de DigitalOcean peuvent être modifiés pour utiliser différentes images de conteneur, différents nombres de répliques de Pod, différents ports et fichiers de configuration personnalisés.
Dans cette étape, nous fournirons un aperçu général de l’objectif de chaque manifeste, puis nous montrerons comment mettre à l’échelle Prometheus jusqu’à 3 répliques en modifiant le fichier de manifeste principal.
Pour commencer, naviguez dans le sous-répertoire manifests du dépôt et répertoriez le contenu du répertoire :
Outputalertmanager-0serviceaccount.yaml
alertmanager-configmap.yaml
alertmanager-operated-service.yaml
alertmanager-service.yaml
. . .
node-exporter-ds.yaml
prometheus-0serviceaccount.yaml
prometheus-configmap.yaml
prometheus-service.yaml
prometheus-statefulset.yaml
Ici, vous trouverez des manifestes pour les différents composants de la pile de surveillance. Pour en savoir plus sur des paramètres spécifiques dans les manifestes, cliquez sur les liens et consultez les commentaires inclus dans les fichiers YAML :
Alertmanager
-
alertmanager-0serviceaccount.yaml: Le compte de service Alertmanager, utilisé pour donner aux Pods Alertmanager une identité Kubernetes. Pour en savoir plus sur les comptes de service, consultez Configurer les comptes de service pour les Pods. -
alertmanager-configmap.yaml: Un ConfigMap contenant un fichier de configuration minimal pour Alertmanager, appeléalertmanager.yml. La configuration d’Alertmanager dépasse le cadre de ce tutoriel, mais vous pouvez en apprendre davantage en consultant la section Configuration de la documentation d’Alertmanager. -
alertmanager-operated-service.yaml: Le servicemeshd’Alertmanager, qui est utilisé pour router les demandes entre les Pods d’Alertmanager dans la configuration actuelle à haute disponibilité avec 2 réplicas. -
alertmanager-service.yaml: Le service Alertmanagerweb, qui est utilisé pour accéder à l’interface web d’Alertmanager, que vous avez peut-être effectuée lors de l’étape précédente. -
alertmanager-statefulset.yaml: Le StatefulSet d’Alertmanager, configuré avec 2 répliques.
Grafana
-
dashboards-configmap.yaml: Un ConfigMap contenant les tableaux de bord de surveillance Grafana préconfigurés en JSON. Générer un nouvel ensemble de tableaux de bord et d’alertes à partir de zéro dépasse le cadre de ce tutoriel, mais pour en savoir plus, vous pouvez consulter le dépôt GitHub kubernetes-mixin. -
grafana-0serviceaccount.yaml: Le compte de service Grafana. -
grafana-configmap.yaml: Un ConfigMap contenant un ensemble par défaut de fichiers de configuration minimal de Grafana. -
grafana-secret.yaml: Un secret Kubernetes contenant l’utilisateur admin et le mot de passe Grafana. Pour en savoir plus sur les Secrets Kubernetes, consultez Secrets. -
grafana-service.yaml: Le manifeste définissant le Service Grafana. -
grafana-statefulset.yaml: Le StatefulSet de Grafana, configuré avec 1 réplica, qui n’est pas scalable. Mettre à l’échelle Grafana dépasse le cadre de ce tutoriel. Pour apprendre comment créer une configuration Grafana hautement disponible, vous pouvez consulter Comment configurer Grafana pour une haute disponibilité dans la documentation officielle de Grafana.
kube-state-metrics
-
kube-state-metrics-0serviceaccount.yaml: Le compte de service et le ClusterRole de kube-state-metrics. Pour en savoir plus sur les ClusterRoles, consultez Rôle et ClusterRole dans la documentation de Kubernetes. -
kube-state-metrics-deployment.yaml: Le manifeste principal de déploiement kube-state-metrics, configuré avec 1 réplique dynamiquement scalable en utilisantaddon-resizer. -
kube-state-metrics-service.yaml: Le Service exposant le Déploiementkube-state-metrics.
node-exporter
-
node-exporter-0serviceaccount.yaml: Le compte de service node-exporter. -
node-exporter-ds.yaml: Le manifeste DaemonSet de node-exporter. Étant donné que node-exporter est un DaemonSet, un Pod node-exporter s’exécute sur chaque nœud du cluster.
###Prometheus
-
prometheus-0serviceaccount.yaml: Le compte de service Prometheus, le rôle de cluster et la liaison de rôle de cluster. -
prometheus-configmap.yaml: Un ConfigMap qui contient trois fichiers de configuration:alerts.yaml: Contient un ensemble prédéfini d’alertes générées parkubernetes-mixin(qui a également été utilisé pour générer les tableaux de bord Grafana). Pour en savoir plus sur la configuration des règles d’alerte, consultez Règles d’alerte dans la documentation de Prometheus.prometheus.yaml: Fichier de configuration principal de Prometheus. Prometheus a été préconfiguré pour collecter toutes les composantes répertoriées au début de Étape 2. La configuration de Prometheus dépasse le cadre de cet article, mais pour en savoir plus, vous pouvez consulter Configuration dans la documentation officielle de Prometheus.rules.yaml: Un ensemble de règles d’enregistrement Prometheus qui permettent à Prometheus de calculer des expressions fréquemment nécessaires ou coûteuses en calcul, et de sauvegarder leurs résultats sous forme d’un nouvel ensemble de séries temporelles. Ceux-ci sont également générés parkubernetes-mixin, et leur configuration dépasse le cadre de cet article. Pour en savoir plus, vous pouvez consulter Règles d’enregistrement dans la documentation officielle de Prometheus.
-
prometheus-service.yaml: Le service qui expose l’ensemble d’états de Prometheus. -
prometheus-statefulset.yaml: L’ensemble d’états de Prometheus, configuré avec 2 réplicas. Ce paramètre peut être ajusté en fonction de vos besoins.
Exemple : Ajustement de Prometheus
Pour démontrer comment modifier la pile de surveillance, nous allons augmenter le nombre de réplicas de Prometheus de 2 à 3.
Ouvrez le fichier manifeste principal sammy-cluster-monitoring_manifest.yaml avec votre éditeur préféré :
Faites défiler jusqu’à la section de l’ensemble d’états de Prometheus du manifeste :
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 2
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Changez le nombre de réplicas de 2 à 3 :
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 3
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Lorsque vous avez terminé, enregistrez et fermez le fichier.
Appliquez les changements en utilisant kubectl apply -f:
Vous pouvez suivre la progression en utilisant kubectl get pods. En utilisant cette même technique, vous pouvez mettre à jour de nombreux paramètres de Kubernetes et une grande partie de la configuration de cette pile d’observabilité.
Conclusion
Dans ce tutoriel, vous avez installé une pile de surveillance Prometheus, Grafana et Alertmanager dans votre cluster Kubernetes DigitalOcean avec un ensemble standard de tableaux de bord, de règles Prometheus et d’alertes.
Vous pouvez également choisir de déployer cette pile de surveillance en utilisant le gestionnaire de packages Kubernetes Helm. Pour en savoir plus, consultez Comment configurer la surveillance du cluster Kubernetes de DigitalOcean avec Helm et Prometheus. Une autre façon d’obtenir une pile similaire en marche est d’utiliser la solution Ensemble de surveillance Kubernetes du Marketplace DigitalOcean, actuellement en version bêta.
Le référentiel de démarrage rapide de surveillance de cluster Kubernetes de DigitalOcean est largement basé sur et modifié à partir de la solution click-to-deploy Prometheus de la Google Cloud Platform. Un manifeste complet des modifications et des changements apportés au référentiel d’origine se trouve dans le fichier changes.md du référentiel de démarrage rapide.