













Clause de non-responsabilité : Toutes les opinions exprimées dans le blog appartiennent uniquement à l’auteur et non nécessairement à l’employeur de l’auteur ou à tout autre groupe ou individu. Cet article n’est pas une promotion pour une plateforme de gestion de données/cloud. Toutes les images et les API sont publiquement disponibles sur le site web Azure/Databricks.
Qu’est-ce que la surveillance de Lakehouse de Databricks?
Dans mes autres articles, j’ai décrit ce qu’étaient Databricks et Unity Catalog, et comment créer un catalogue à partir de zéro en utilisant un script. Dans cet article, je décrirai la fonctionnalité de surveillance de Lakehouse disponible dans la plateforme Databricks et comment activer la fonctionnalité à l’aide de scripts.
La surveillance de Lakehouse fournit des profils de données et des métriques liées à la qualité des données pour les Delta Live Tables dans Lakehouse. La surveillance de Lakehouse de Databricks offre un aperçu complet des données telles que les changements dans le volume des données, les changements dans la distribution numérique, le % de valeurs nulles et de zéros dans les colonnes, et la détection d’anomalies catégorielles au fil du temps.
Pourquoi utiliser la surveillance de Lakehouse?
La surveillance de vos données et des performances de votre modèle ML fournit des mesures quantitatives qui vous aident à suivre et à confirmer la qualité et la cohérence de vos données et des performances de votre modèle au fil du temps.
Voici un aperçu des principales fonctionnalités :
- Suivi de la qualité des données et de l’intégrité des données : Suit le flux de données à travers les pipelines, garantit l’intégrité des données et fournit une visibilité sur la manière dont les données ont évolué au fil du temps, 90e centile d’une colonne numérique, % de colonnes nulles et à zéro, etc.
- Dérives des données au fil du temps : Fournit des mesures pour détecter les dérives des données entre les données actuelles et une référence connue, ou entre les fenêtres temporelles successives des données
- Distribution statistique des données : Fournit un changement de distribution numérique des données au fil du temps qui répond à la question de quelle est la distribution des valeurs dans une colonne catégorielle et en quoi elle diffère du passé
- Performances du modèle ML et dérive des prédictions : Entrées du modèle ML, prédictions et tendances de performance au fil du temps
Comment ça fonctionne
Le suivi de Lakehouse de Databricks fournit les types d’analyses suivants : séries temporelles, instantané et inférence.
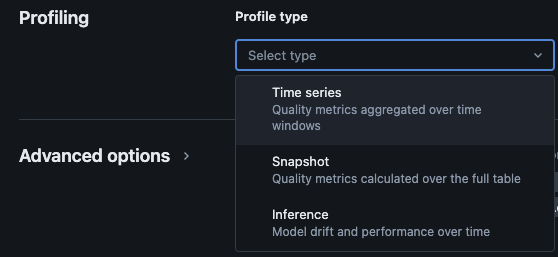
Types de profils pour la surveillance
Lorsque vous activez la surveillance du lac pour une table dans le catalogue Unity, cela crée deux tables dans le schéma de surveillance spécifié. Vous pouvez interroger et créer des tableaux de bord (Databricks fournit un tableau de bord configurable par défaut) et des notifications sur les tables pour obtenir des informations statistiques et de profil complètes sur vos données au fil du temps.
- Tableau de métriques de dérive : Le tableau de métriques de dérive contient des statistiques liées à la dérive des données au fil du temps. Il capture des informations telles que les différences de comptage, les différences de moyenne, les différences en % de valeurs nulles et zéros, etc.
- Tableau de métriques de profil : Le tableau de métriques de profil contient des statistiques récapitulatives pour chaque colonne et pour chaque combinaison de fenêtre temporelle, tranche et colonnes de regroupement. Pour l’analyse des journaux d’inférence, le tableau d’analyse contient également des métriques de précision du modèle.
Comment activer la surveillance du lac via des scripts
Prérequis
- Le catalogue Unity, le schéma et les tables Delta Live sont présents.
- L’utilisateur est le propriétaire de la table Delta Live.
- Pour les clusters Azure Databricks privés, la connectivité privée à partir du calcul sans serveur est configurée.
Étape 1 : Créer un notebook et installer le SDK Databricks
Créez un notebook dans l’espace de travail Databricks. Pour créer un notebook dans votre espace de travail, cliquez sur le « + » Nouveau dans la barre latérale, puis choisissez Notebook.
Un notebook vide s’ouvre dans l’espace de travail. Assurez-vous que Python est sélectionné comme langage du notebook.
Copiez et collez le code ci-dessous dans la cellule du notebook, puis exécutez-la.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Étape 2 : Créer des variables
Copiez et collez le code ci-dessous dans la cellule du notebook, puis exécutez-la.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Étape 3 : Créer un schéma de surveillance
Copiez et collez le code ci-dessous dans la cellule du notebook, puis exécutez-la. Ce code va créer le schéma de surveillance s’il n’existe pas déjà.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Étape 4 : Créer un moniteur
Copiez et collez le code ci-dessous dans la cellule du notebook, puis exécutez-la. Ce code va créer la surveillance Lakehouse pour toutes les tables à l’intérieur du schéma.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Validation
Après l’exécution réussie du script, vous pouvez naviguer vers catalogue -> schéma -> table et aller à l’onglet « Qualité » dans la table pour voir les détails de la surveillance. 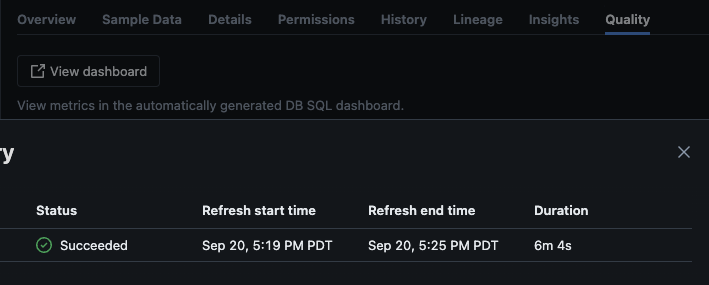
Si vous cliquez sur le bouton « View dashboard » dans le coin supérieur gauche de la page Monitoring, le tableau de bord de surveillance par défaut s’ouvrira. Initialement, les données seront vides. Au fur et à mesure que la surveillance se déroule selon le planning, au fil du temps, elle remplira toutes les valeurs statistiques, de profil et de qualité des données.
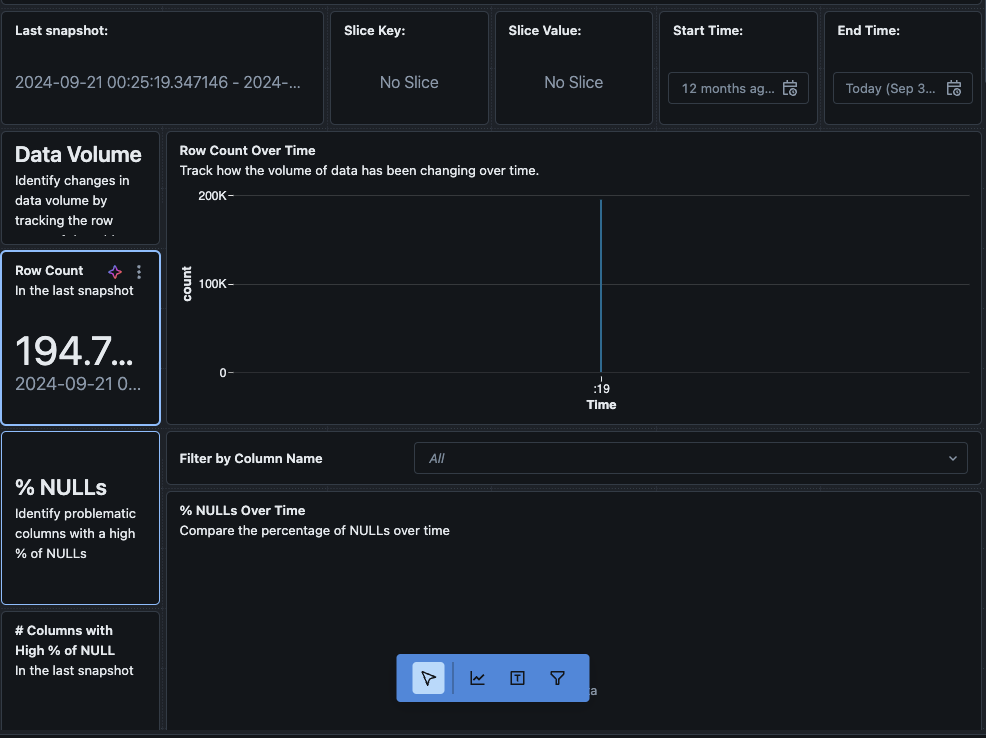
Vous pouvez également accéder à l’onglet « Data » dans le tableau de bord. Databricks propose par défaut une liste de requêtes pour obtenir la dérive et d’autres informations de profil. Vous pouvez également créer vos propres requêtes selon vos besoins pour obtenir une vue globale de vos données au fil du temps.
Conclusion
La surveillance Lakehouse de Databricks offre une manière structurée de suivre la qualité des données, les indicateurs de profil et de détecter les dérives des données au fil du temps. En activant cette fonctionnalité via des scripts, les équipes peuvent obtenir des informations sur le comportement des données et garantir la fiabilité de leurs pipelines de données. Le processus de configuration décrit dans cet article fournit une base pour maintenir l’intégrité des données et soutenir les efforts d’analyse de données continus.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring