













Dans la Partie 1, nous avons couvert plusieurs sujets clés. Je vous recommande de le lire, car la partie suivante s’appuie dessus.
En guise de rappel rapide, dans la partie 1, nous avons envisagé nos données d’un point de vue global et différencié les données internes des données externes. Nous avons également discuté des schémas et des contrats de données et de la manière dont ils fournissent les moyens de négocier, de modifier et d’évoluer nos flux au fil du temps. Enfin, nous avons abordé les types d’événements Fact (État) et Delta. Les événements Fact sont les meilleurs pour communiquer l’état et découpler les systèmes, tandis que les événements Delta tendent à être utilisés davantage pour les données internes, comme dans le sourcing d’événements et d’autres cas d’utilisation fortement couplés.
Les Tables Normalisées Font des Flux Normalisés
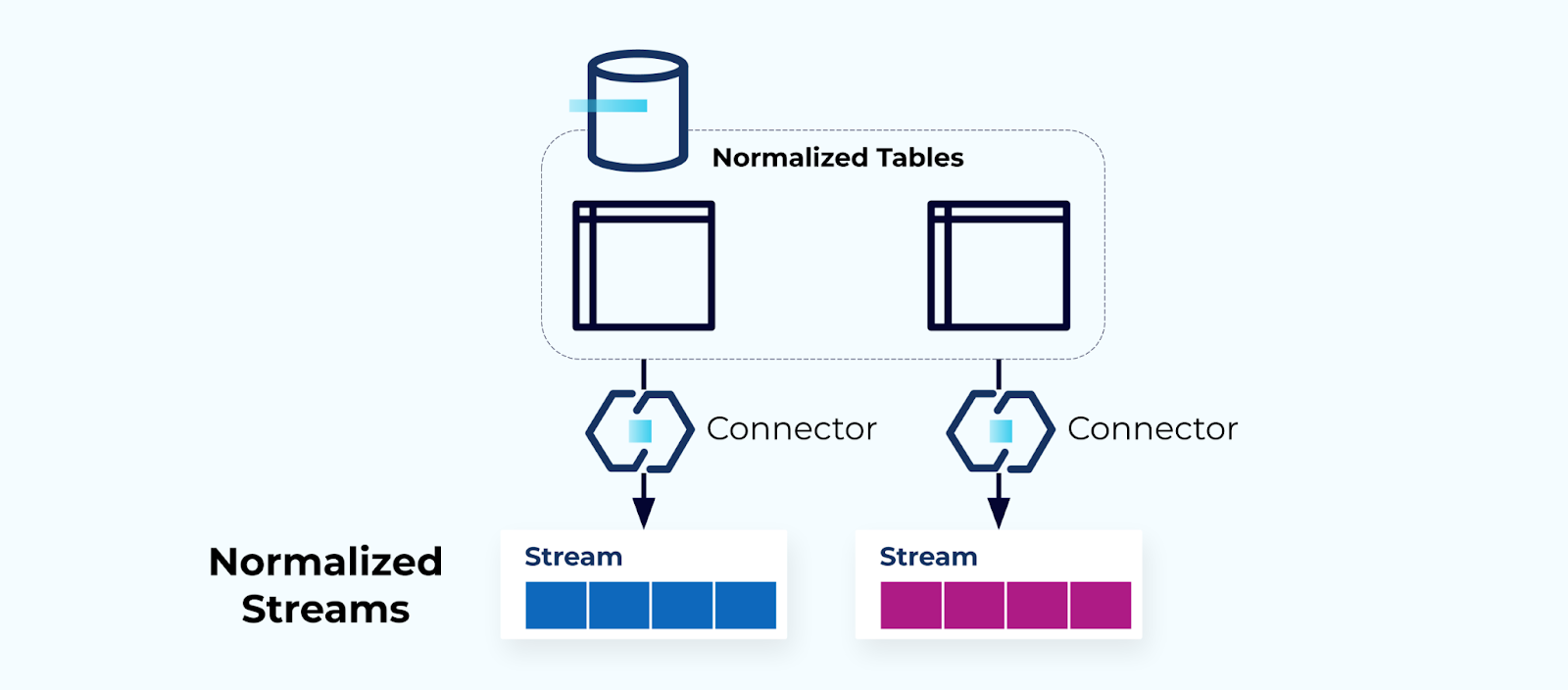
Les tables normalisées mènent à des flux d’événements normalisés. Les connecteurs (par exemple, CDC) extraient les données directement de la base de données dans un ensemble miroir de flux d’événements. Ce n’est pas idéal, car cela crée une forte dépendance entre les tables internes de la base de données et les flux d’événements externes.
Considérez un simple élément de e-commerce Article et ses tables associées Marque et Statut Fiscal.
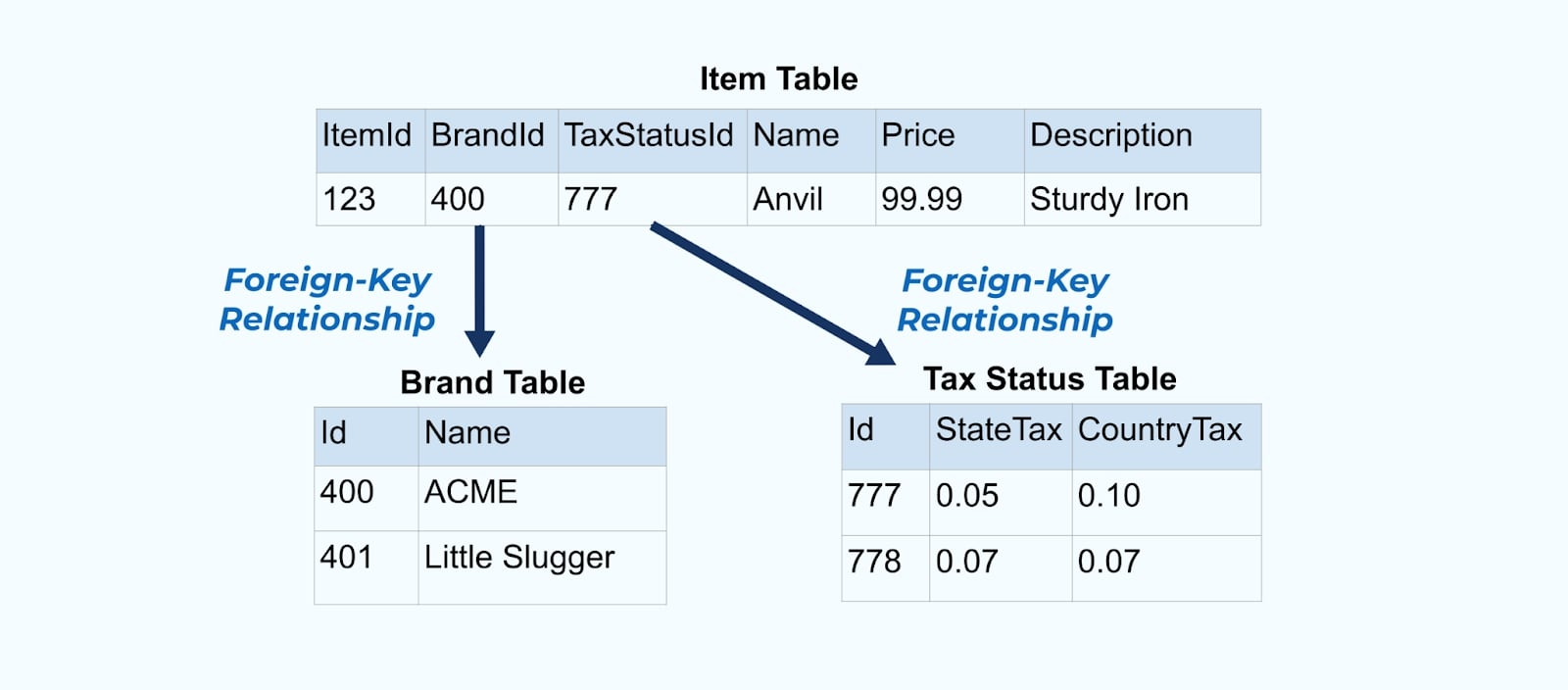
Les tables Marque et Statut Fiscal se rapportent à la table Article par des relations de clé étrangère. Bien que nous ne montrions qu’un seul article dans la table, vous aurez probablement des milliers (ou des millions), en fonction des produits que vous vendez.
Il est courant de configurer un connecteur pour chaque table, d’extraire les données de la table, de les composer en événements, et d’écrire chaque table dans un flux d’événements dédié.
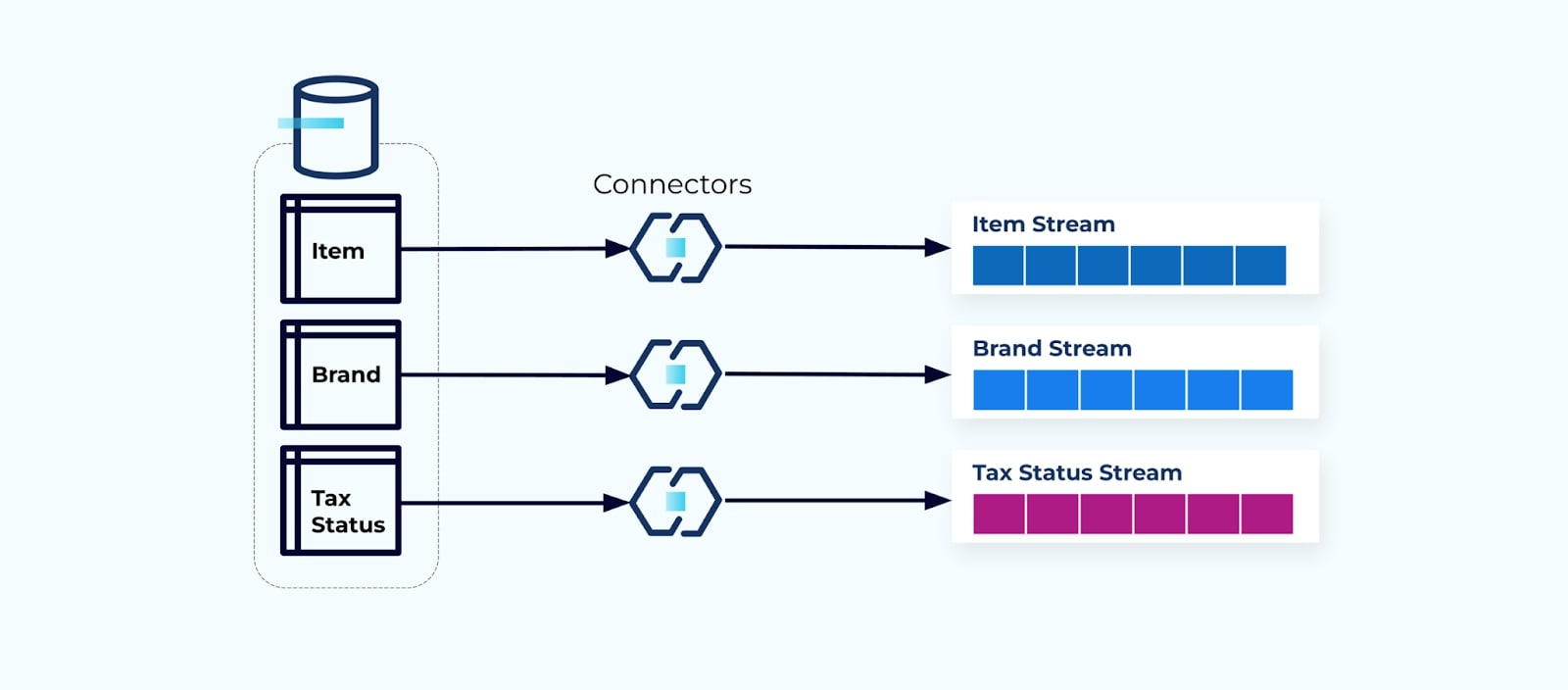
Exposer les tables sous-jacentes dans la base de données conduit à un flux d’événements correspondant par table. Bien que ce soit facile à mettre en place ainsi, cela conduit à plusieurs problèmes, qui peuvent être résumés soit comme un problème de couplage problème, soit comme un problème de coût problème. Examinons chacun d’eux.
Problème : Les consommateurs se couplent au modèle interne
Exposer la table source Item telle quelle force les consommateurs à s’y coupler directement. Les changements au modèle de données du système source auront un impact sur les consommateurs en aval.
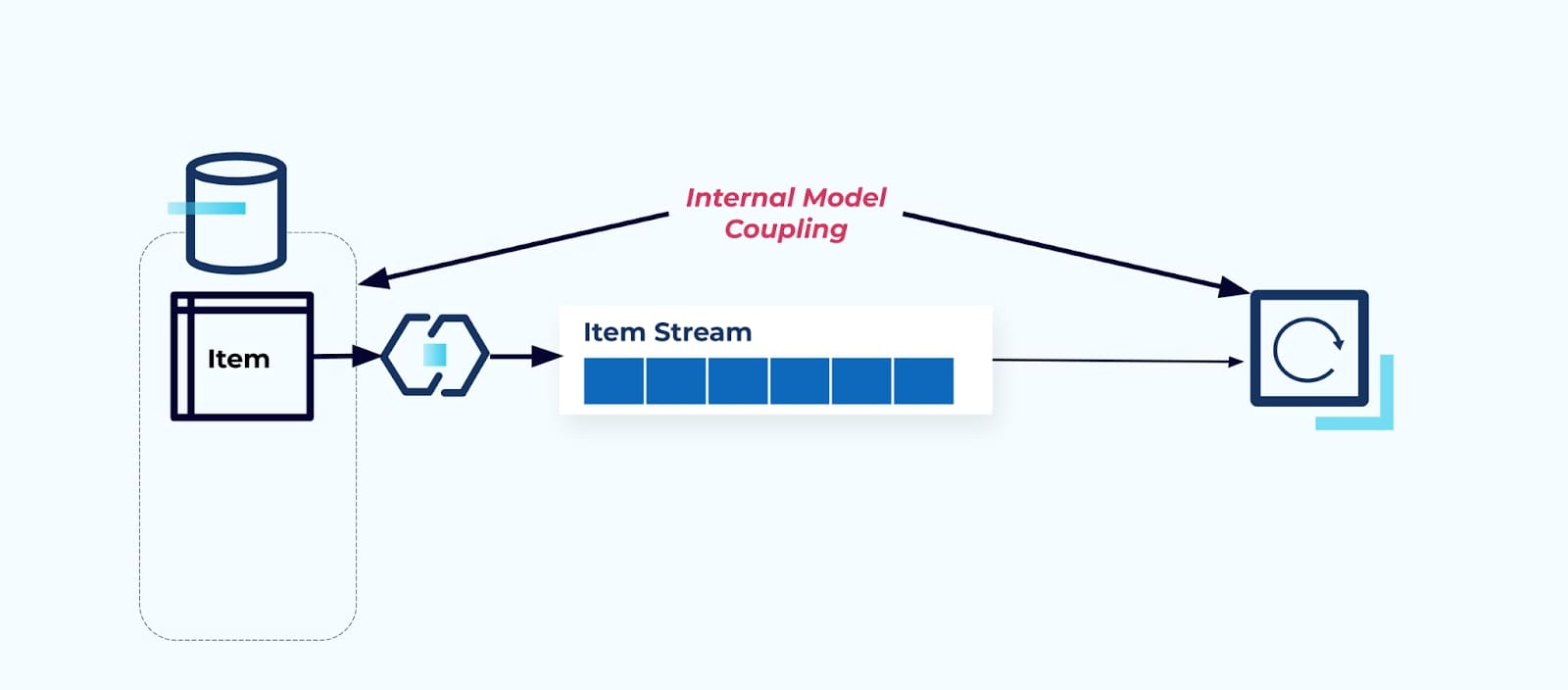
Supposons que nous refactorions la table Item pour extraire Pricing dans sa propre table.
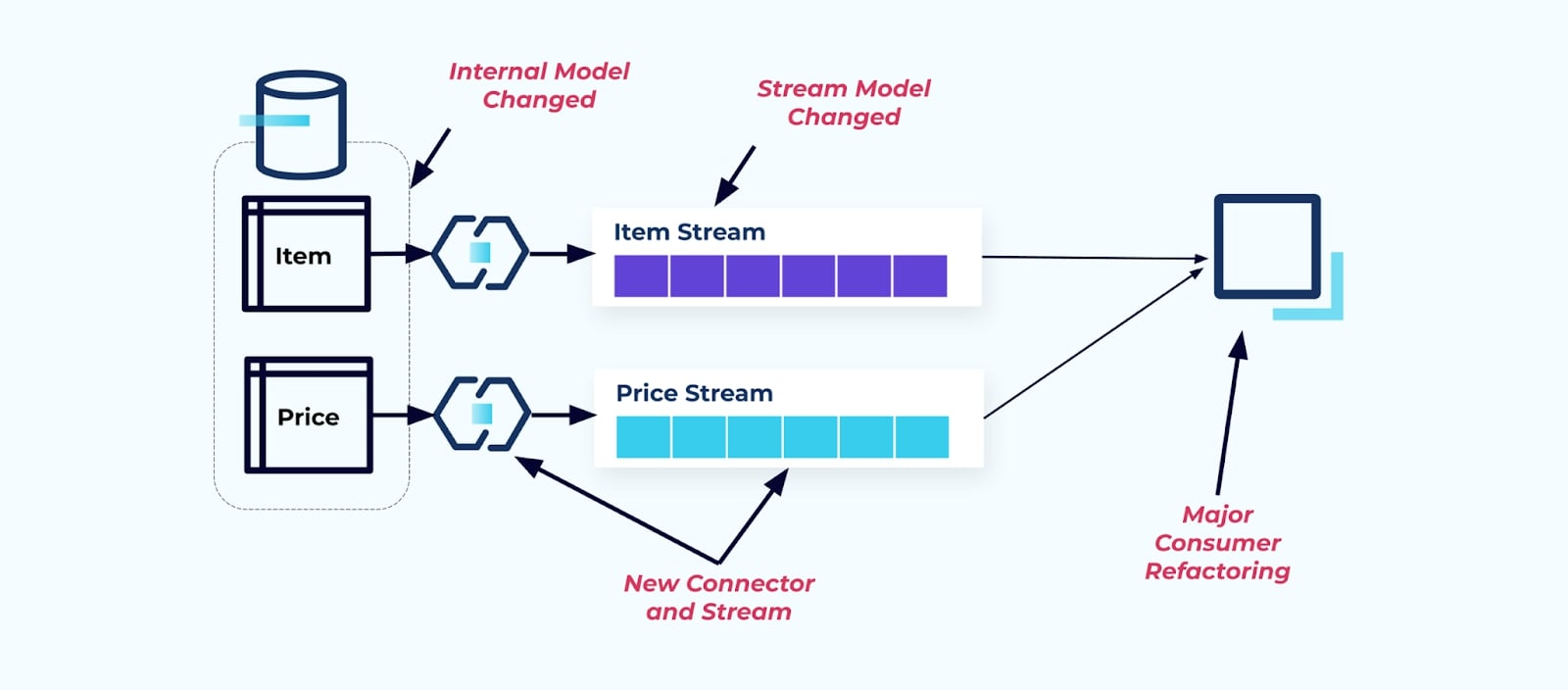
Le refactoring des tables sources entraîne une rupture du contrat de données pour le flux d’articles. Le consommateur n’est plus fourni avec les mêmes données d’article qu’il attendait à l’origine. Nous devons également créer un nouveau connecteur — un nouveau flux de Prix — et, enfin, refactoriser notre logique de consommateur pour le faire fonctionner à nouveau. Renommer des colonnes, changer des valeurs par défaut et changer les types de colonnes sont d’autres formes de modifications cassantes introduites par un couplage étroit sur le modèle de données interne.
Problème : Les jointures en streaming sont (généralement) coûteuses
Les bases de données relationnelles sont conçues pour résoudre rapidement et à moindre coût les jointures. Malheureusement, ce n’est pas le cas des jointures en streaming.
Considérez deux services qui souhaitent accéder à un Article, à sa Taxe et à ses informations de Marque. Si les données sont déjà écrites dans leur flux correspondant, alors chaque consommateur (à droite sur l’image ci-dessous) devra calculer les mêmes jointures pour dénormaliser l’Article, la Marque et la Taxe.
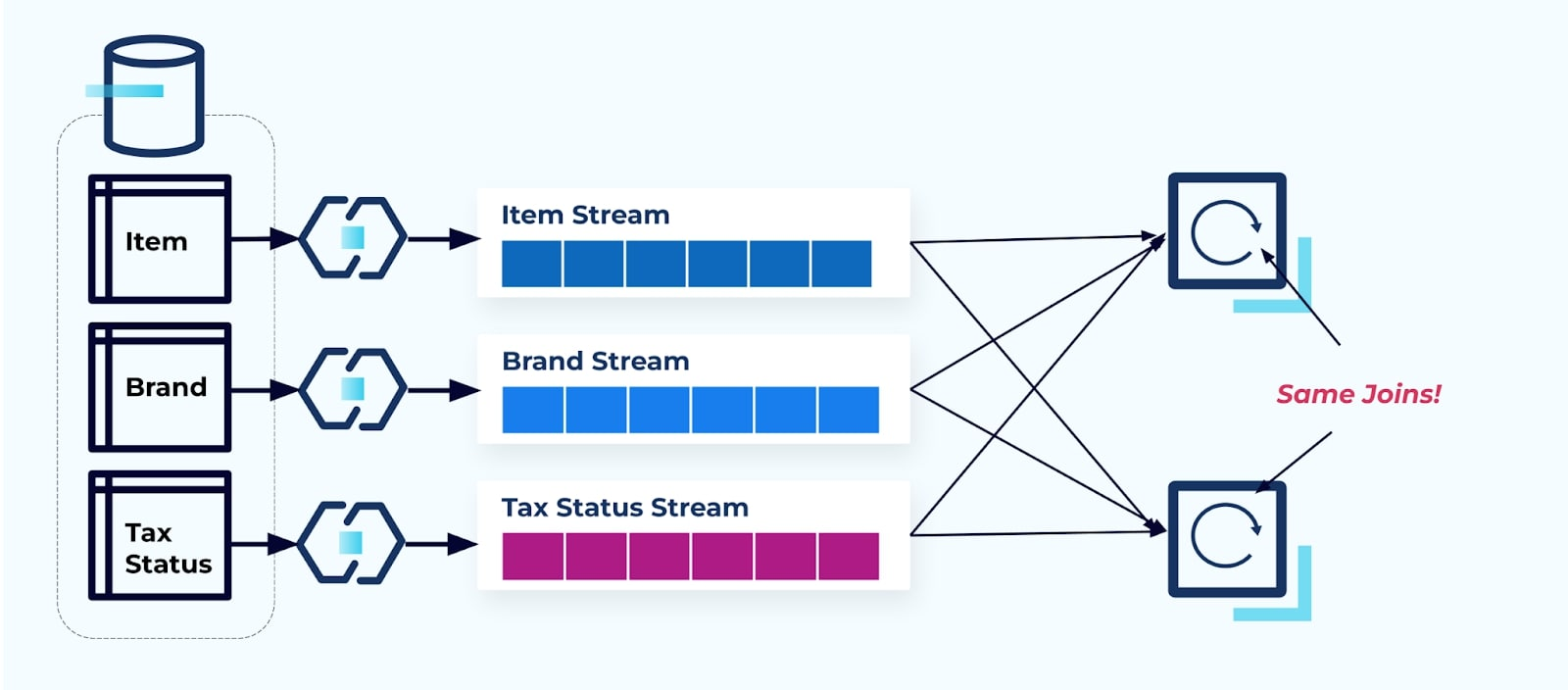
Cette stratégie peut entraîner des coûts élevés, tant en heures de développement pour écrire les applications qu’en coûts de serveur pour calculer les jointures. La résolution des jointures de flux à grande échelle peut entraîner beaucoup de réorganisation des données, ce qui engendre des coûts en puissance de traitement, en réseau et en stockage. De plus, tous les frameworks de traitement de flux ne supportent pas les jointures, surtout sur les clés étrangères. Parmi ceux qui le font, comme Flink, Spark, KSQL ou Kafka Streams (par exemple), vous vous retrouverez limité à un sous-ensemble de langages de programmation (Java, Scala, Python).
Solution : Servir des Données Dénormalisées Est le Meilleur Choix
En principe, rendez les flux d’événements faciles à utiliser pour vos consommateurs. Dénormalisez les données avant de les rendre disponibles pour les consommateurs en utilisant une couche d’abstraction et créez un modèle externe explicite contrat de données (données à l’extérieur) pour que les consommateurs s’y couplent.
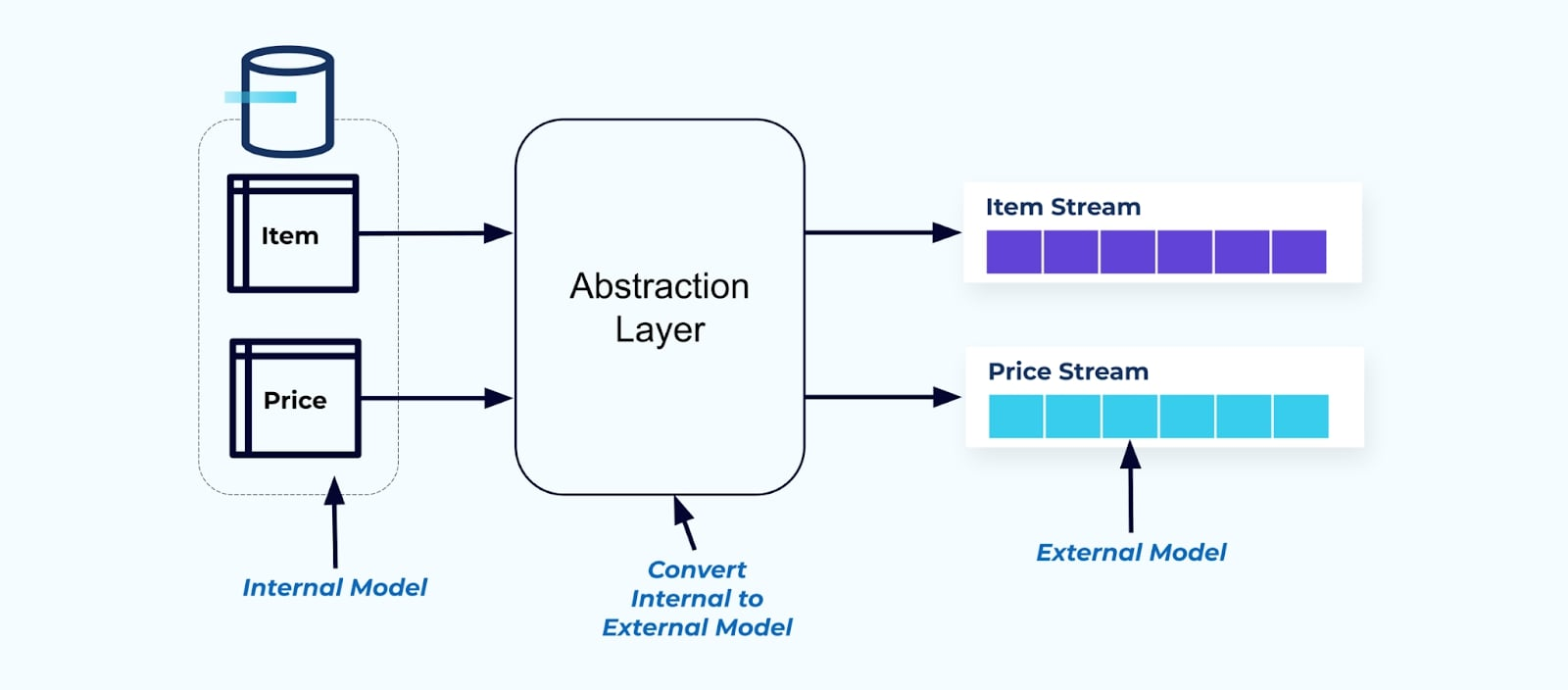
Les changements au modèle interne restent isolés dans les systèmes sources. Les consommateurs obtiennent un contrat de données bien défini pour s’y coupler. Les modifications apportées au modèle source peuvent avancer sans entrave, à condition que le système source maintienne le contrat de données pour les consommateurs.
Mais où dénormalisons-nous ? Deux options :
- Reconstruire en dehors du système source via un service de jointure spécialement conçu.
- Lors de la création de l’événement dans le système source en utilisant le modèle Transactional Outbox.
Examinons chaque solution à tour de rôle.
Option 1 : Dénormaliser en Utilisant un Service de Jointure Spécialement Conçu
Dans cet exemple, les flux à gauche reflètent les tables dont ils proviennent dans la base de données.
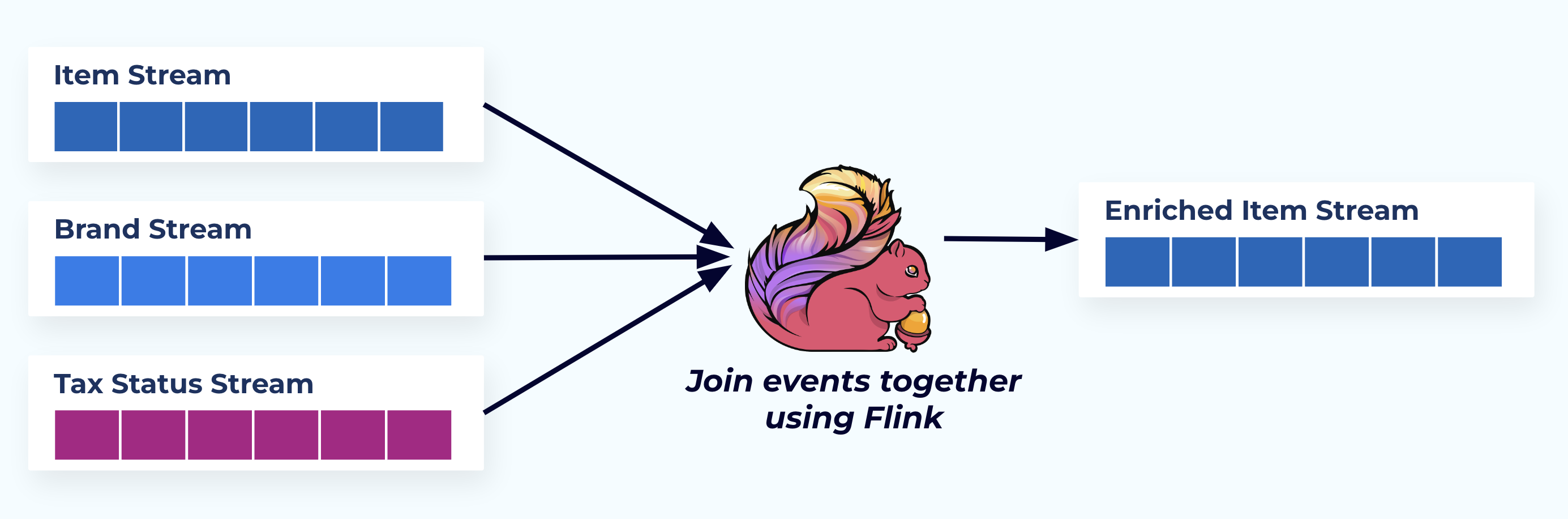
Nous lions les événements à l’aide d’une application spécialement conçue (ou une requête SQL en streaming) basée sur les relations de clé étrangère et émettons un flux d’éléments enrichis unique.

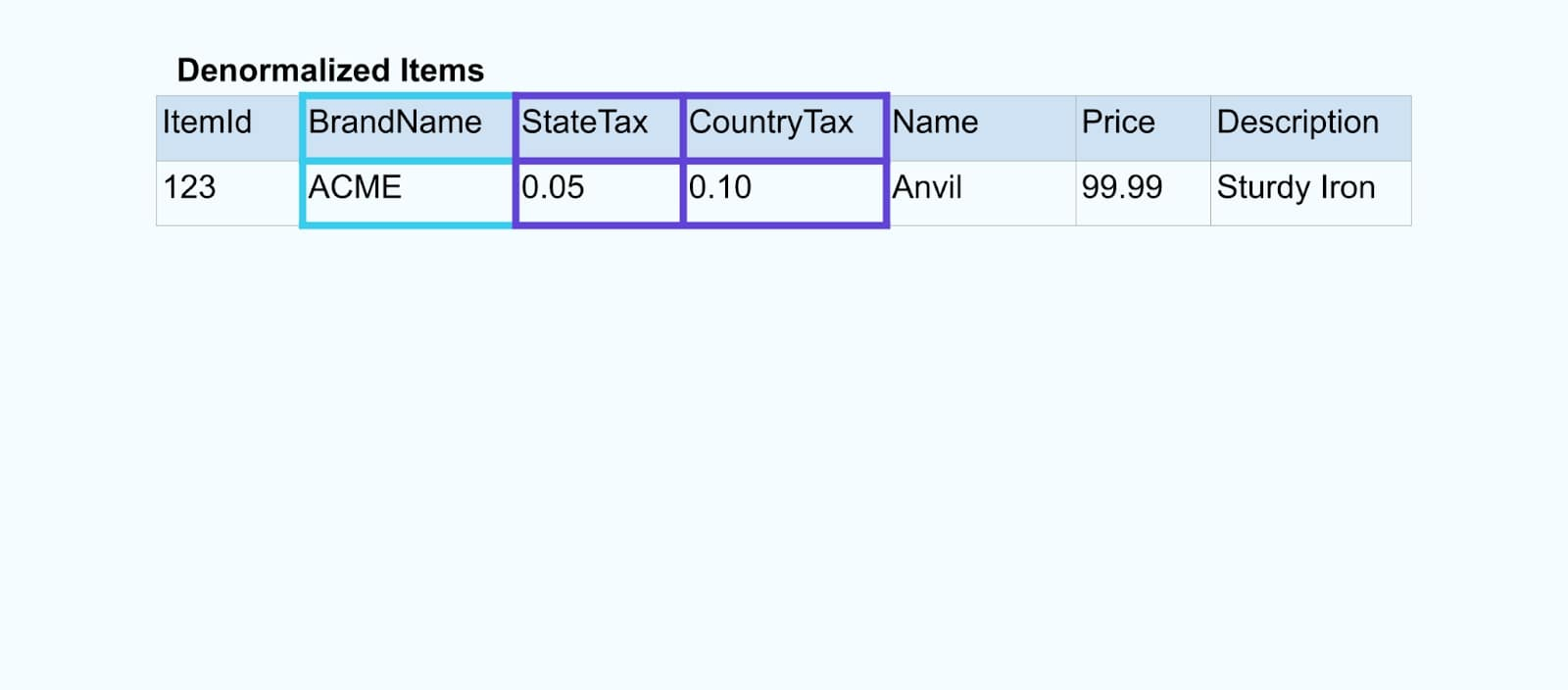
Logiquement, nous résolvons les relations et compressons les données en une seule ligne dénormalisée.
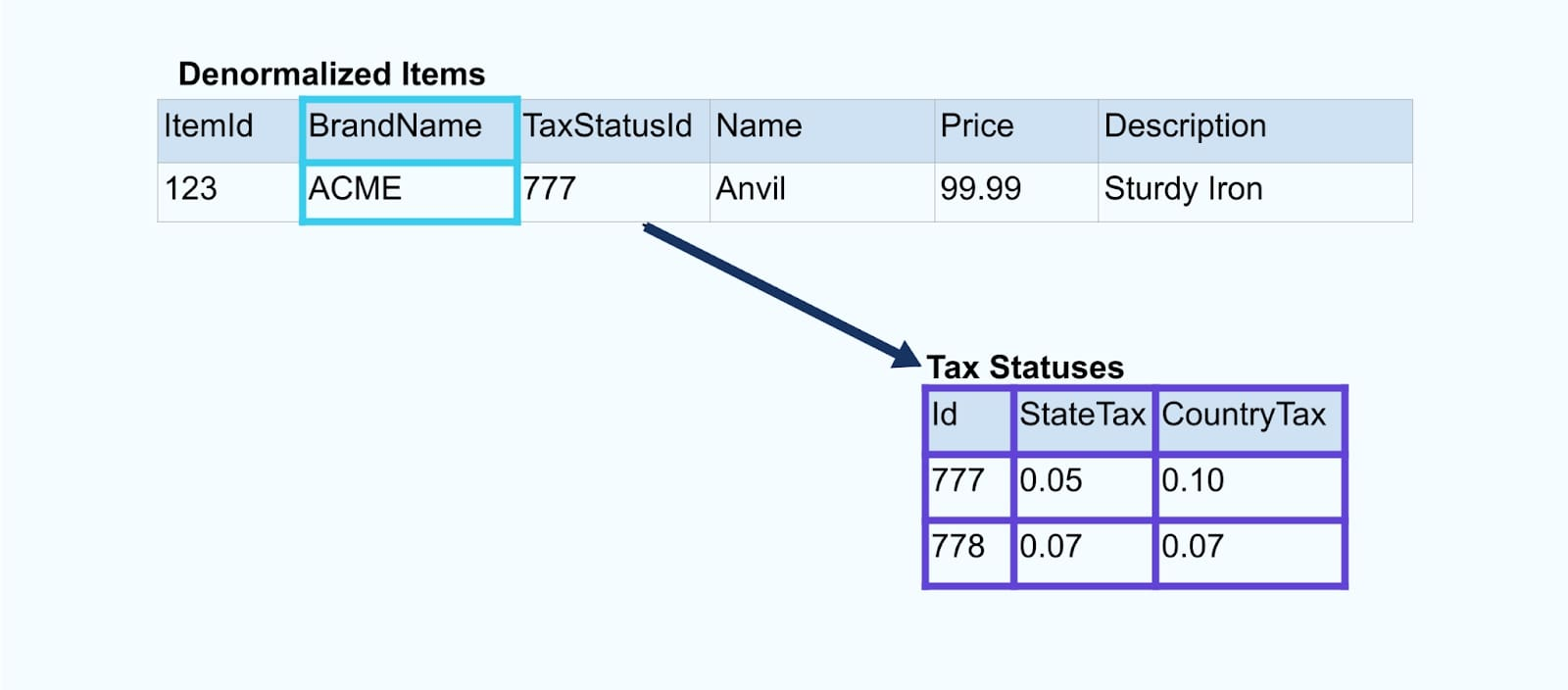
Les joiners spécialement conçus s’appuient sur des frameworks de traitement de flux comme Apache Kafka Streams et Apache Flink pour résoudre à la fois les joints de clé primaire et de clé étrangère. Ils matérialisent les données de flux dans des formats de table internes durables, permettant à l’application de joiner de joindre des événements sur n’importe quelle période – pas seulement ceux limités par une fenêtre de temps.
Les joiners utilisant Flink ou Kafka Streams sont également remarquablement évolutifs — ils peuvent s’adapter à la charge et gérer des volumes massifs de trafic.
Un conseil : Ne mettez aucune logique métier dans le joiner. Pour réussir dans ce modèle, les données jointes doivent représenter fidèlement la source, simplement comme un résultat dénormalisé. Laissez les consommateurs en aval appliquer leur propre logique métier, en utilisant les données dénormalisées comme une seule source de vérité.
Si vous ne souhaitez pas utiliser un joiner en aval, il existe d’autres options. Examinons le modèle de boîte de sortie transactionnelle ensuite.
Option 2 : Modèle de Boîte de Sortie Transactionnelle
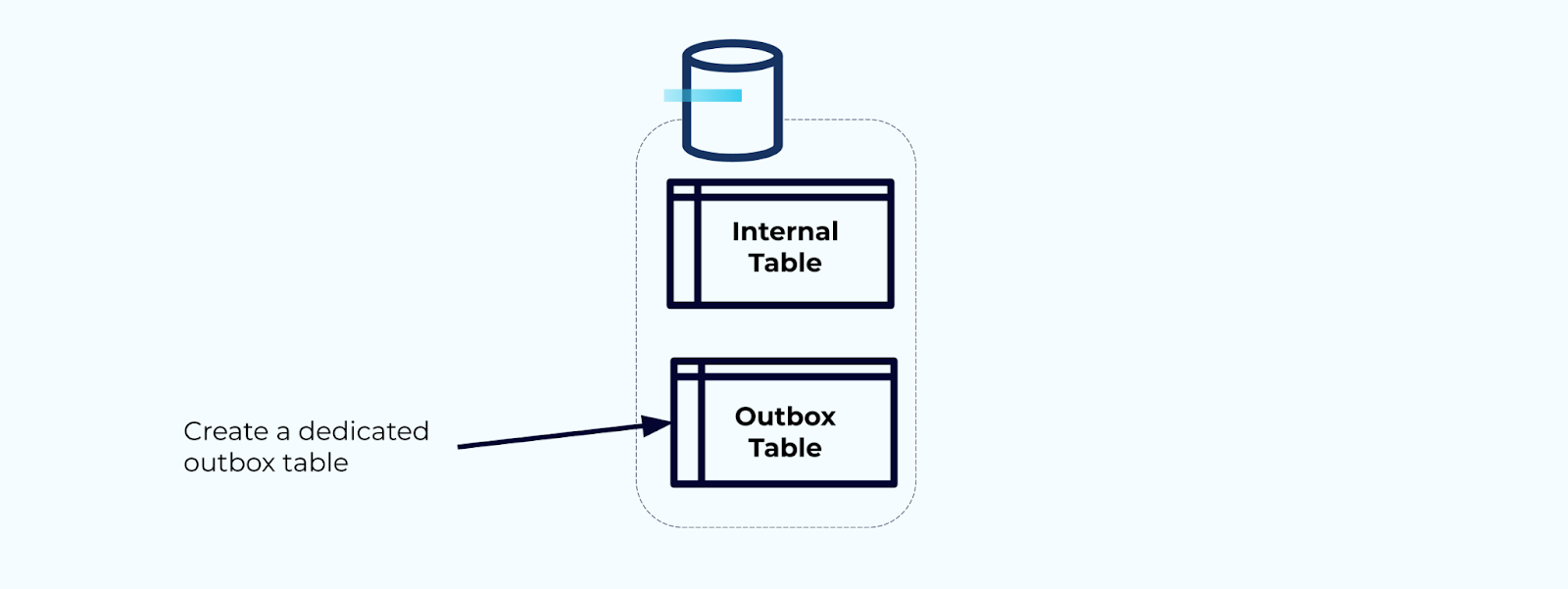
Tout d’abord, créez une table de boîte de sortie dédiée pour écrire des événements dans le flux.
Deuxièmement, encapsulez toutes les mises à jour nécessaires des tables internes dans une transaction. Les transactions garantissent que toute mise à jour effectuée sur la table interne sera également écrite dans la table de la boîte d’envoi.
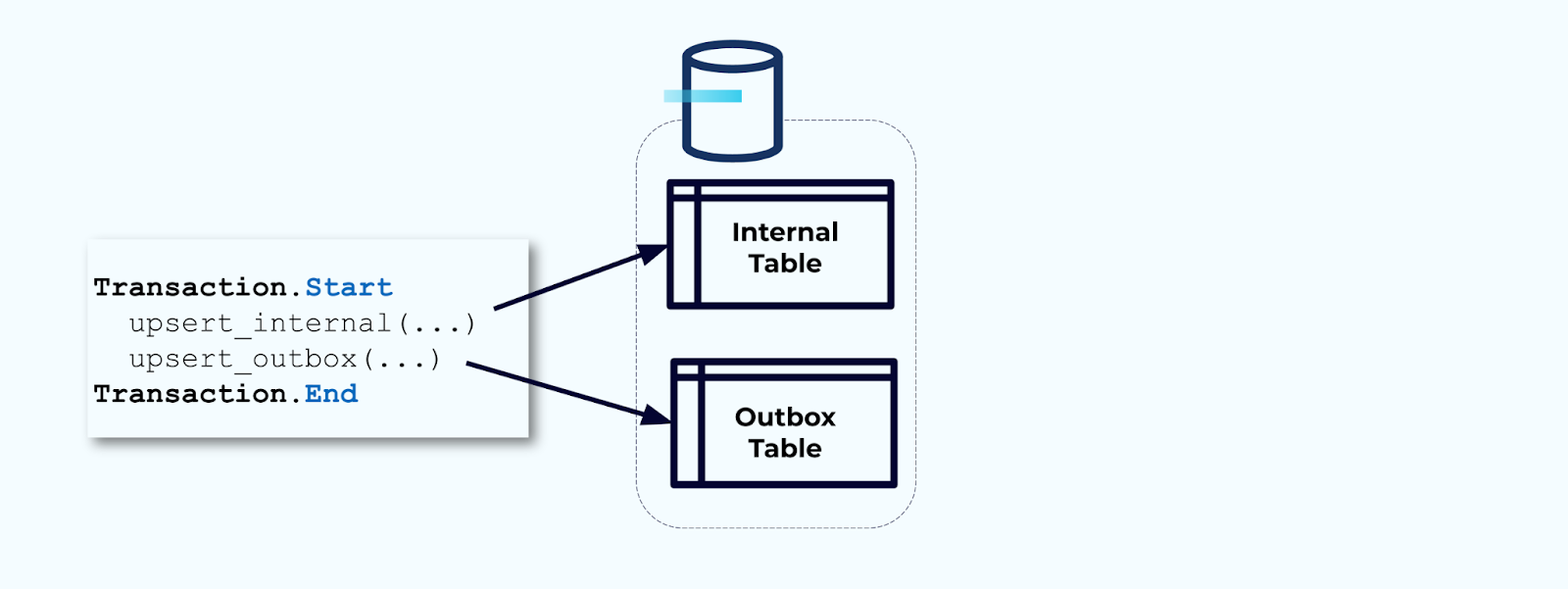
La boîte d’envoi vous permet d’isoler le modèle de données interne puisque vous pouvez joindre et transformer les données avant de les écrire dans votre boîte d’envoi. La boîte d’envoi agit comme une couche d’abstraction entre vos données internes et les données externes, servant de contrat de données pour vos consommateurs.
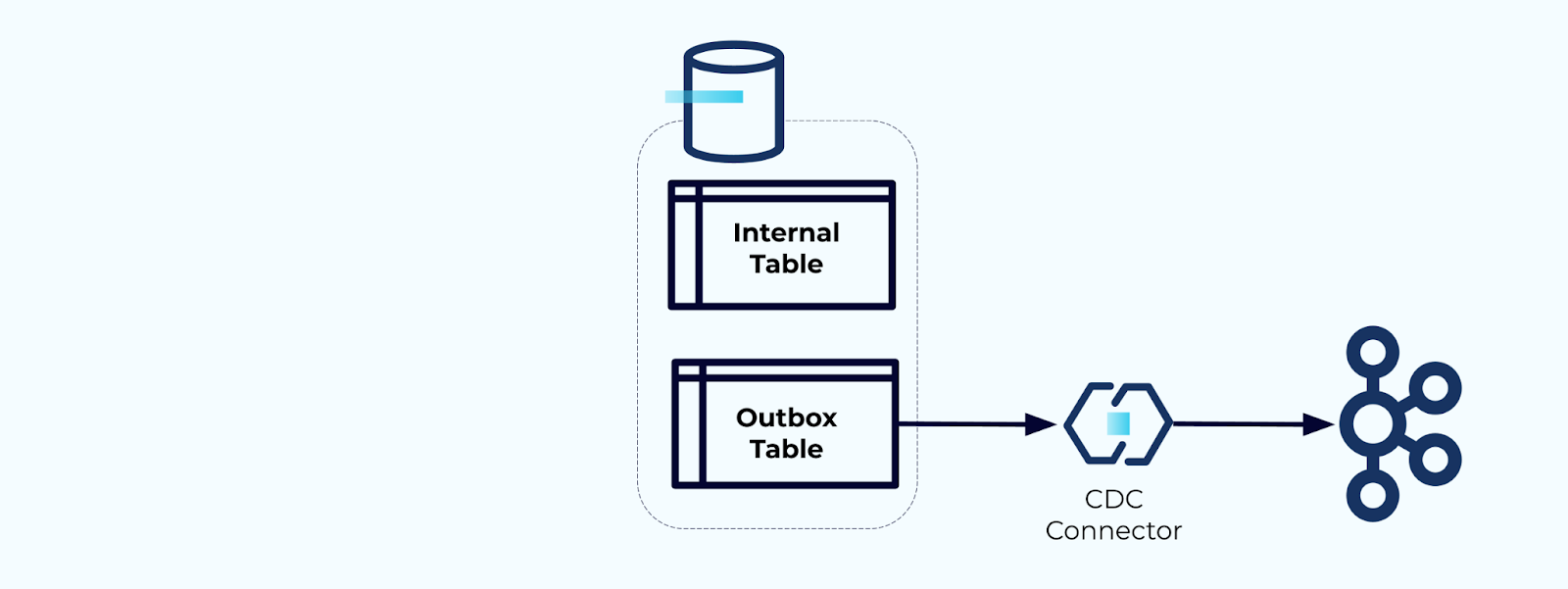
Enfin, vous pouvez utiliser un connecteur pour transférer les données de la boîte d’envoi vers Kafka.
Vous devez vous assurer que la boîte d’envoi ne grandit pas indéfiniment — soit supprimez les données après qu’elles ont été capturées par le CDC, soit périodiquement avec une tâche planifiée.
Exemple : Dénormalisation des événements de suivi du comportement des utilisateurs
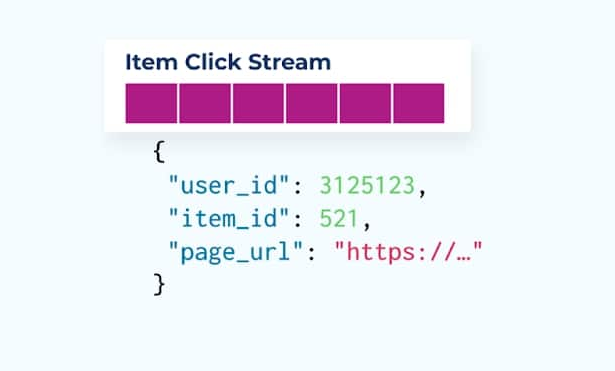
Suivre le comportement des utilisateurs sur vos pages web et applications est une source courante d’événements normalisés – pensez à Google Analytics ou aux options internes de première partie. Mais nous n’incluons pas toutes les informations dans l’événement ; au lieu de cela, nous nous limitons aux identifiants (plus rapide, plus petit, moins cher), en dénormalisant après la création des faits.
Considérez un flux d’événements de clics sur des articles détaillant quand un utilisateur a cliqué sur un article tout en naviguant sur des articles de commerce électronique. Notez que cet événement de clic sur un article ne contient pas des informations plus riches sur l’article telles que le nom, le prix et la description, mais seulement des ids de base.
La première chose que beaucoup de consommateurs de flux de clics font est de le joindre au flux de faits sur les articles. Et comme vous traitez de nombreux événements de clic, vous découvrez qu’il finit par utiliser une grande quantité de ressources informatiques. Une application Flink spécialement conçue peut joindre les clics sur les articles avec les données détaillées des articles et les émettre vers un flux enrichi de clics sur les articles.
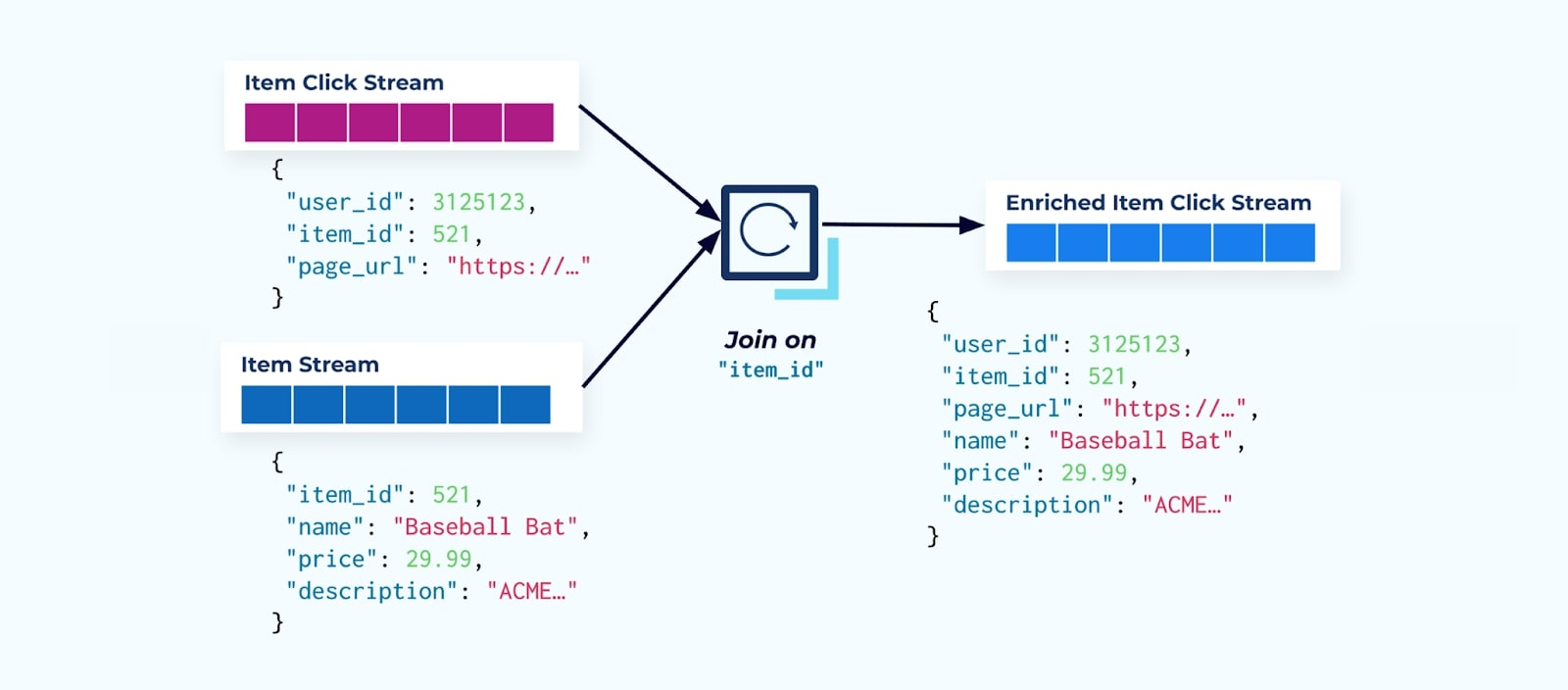
Les grandes entreprises avec plusieurs divisions (et systèmes) verront probablement leurs données provenir de différentes sources, et le fait de joindre après coup en utilisant un assembleur de flux est le résultat le plus probable.
Considérations sur les Dimensions à Changement Lent
Nous avons déjà discuté des considérations de performance relatives à l’écriture d’événements contenant de grands ensembles de données (par exemple, de grands blocs de texte) et des domaines de données qui changent fréquemment (par exemple, l’inventaire des articles). Maintenant, nous allons examiner les dimensions à changement lent (SCD), souvent indiquées via une relation de clé étrangère, car celles-ci peuvent être une autre source de volumes de données significatifs.
Revenons à notre exemple d’article. Disons que vous avez une opération qui met à jour la Table des Articles. Nous allons renommer l’article de Enclume à Enclume en Fer.
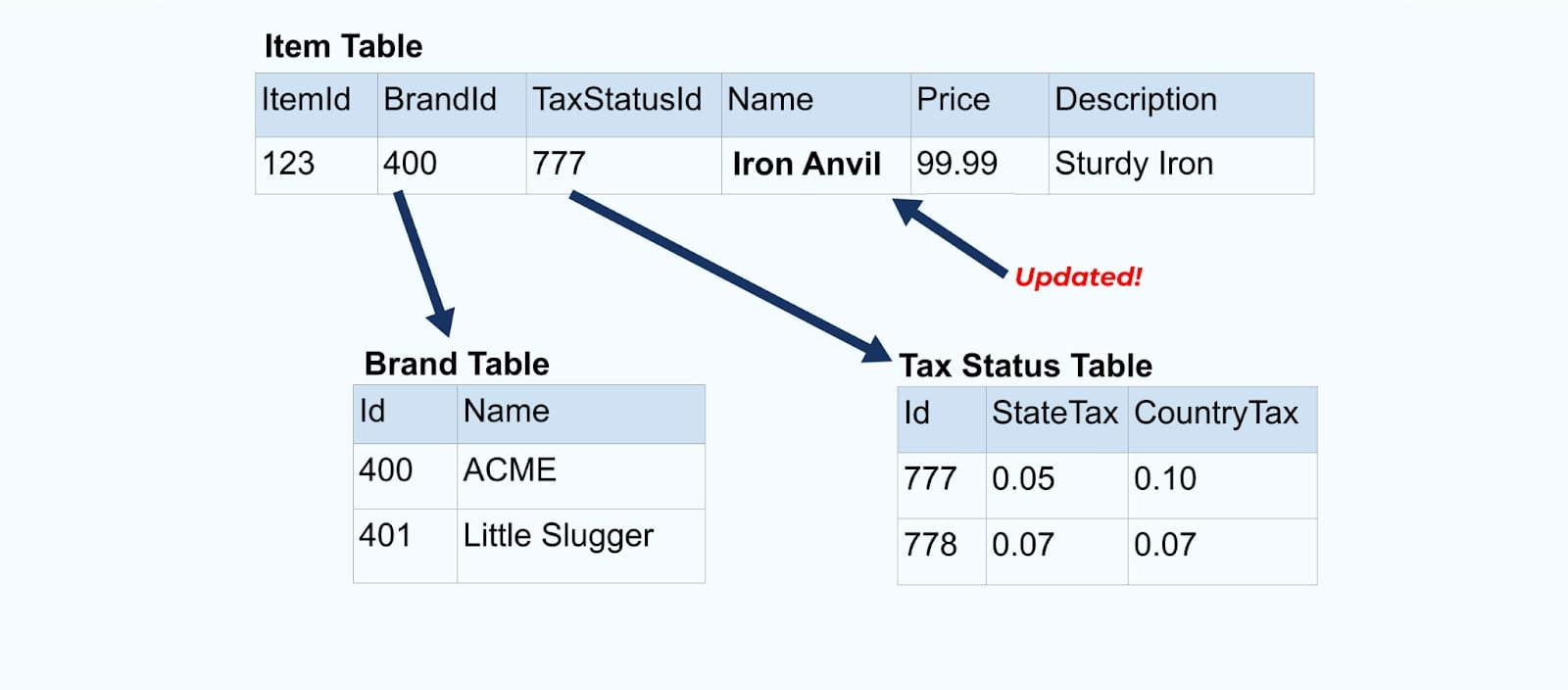
Upon updating the data in the database, we also emit the updated item (say via the outbox pattern), complete with the denormalized tax status and brand table.
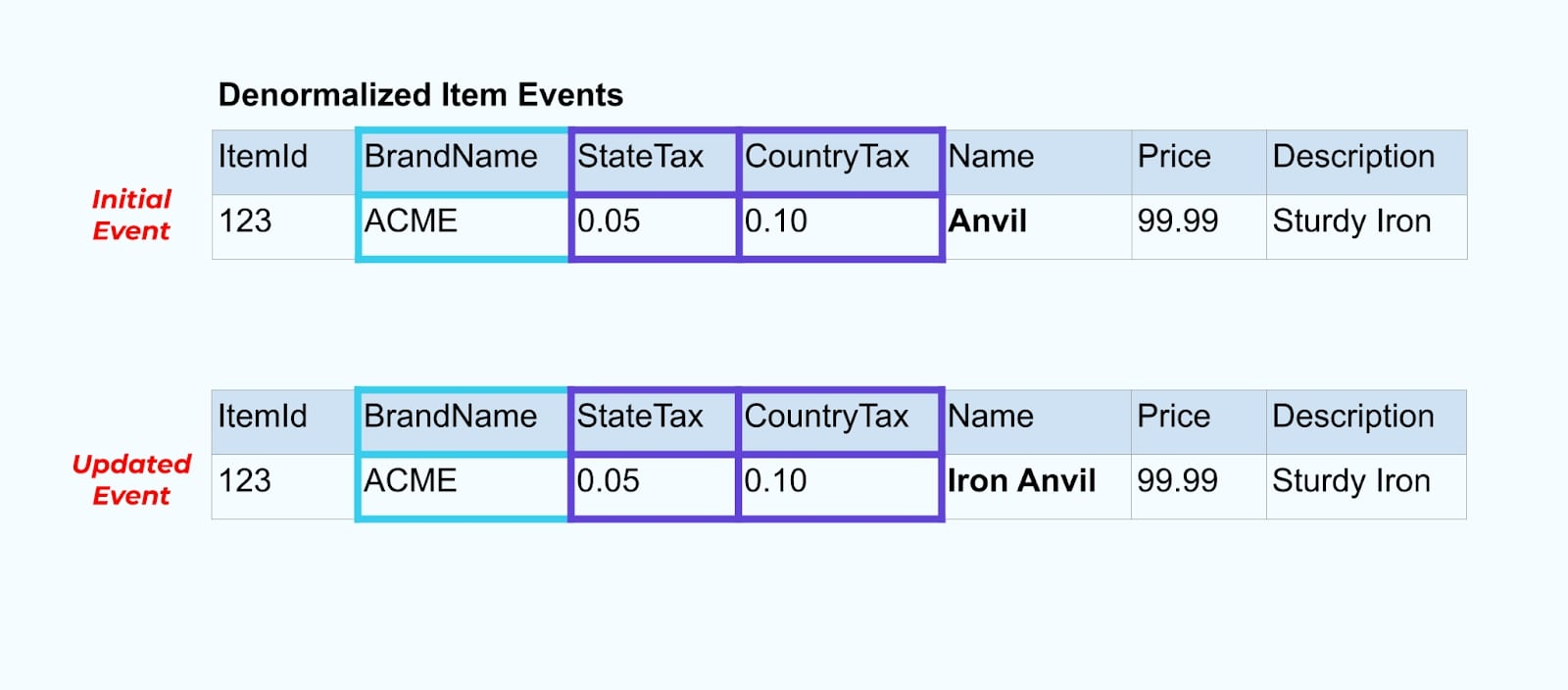
Cependant, nous devons également considérer ce qui se passe lorsque nous changeons des valeurs dans les tables de marque ou de taxe. Mettre à jour une de ces dimensions à changement lent peut entraîner un nombre significativement élevé de mises à jour pour tous les articles affectés.
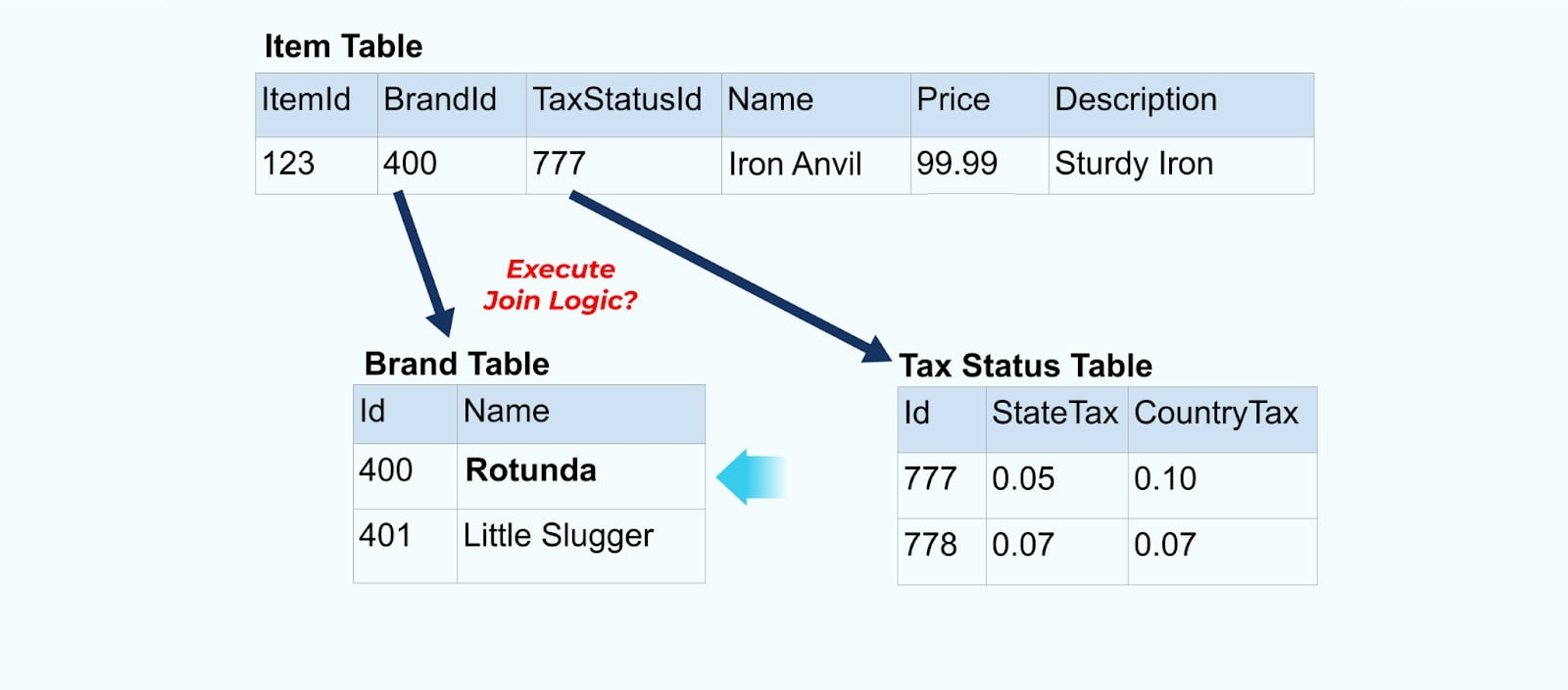
Par exemple, la société ACME subit un rebranding et adopte un nouveau nom de marque, passant de ACME à Rotunda. Nous produisons un autre événement pour ItemId=123.
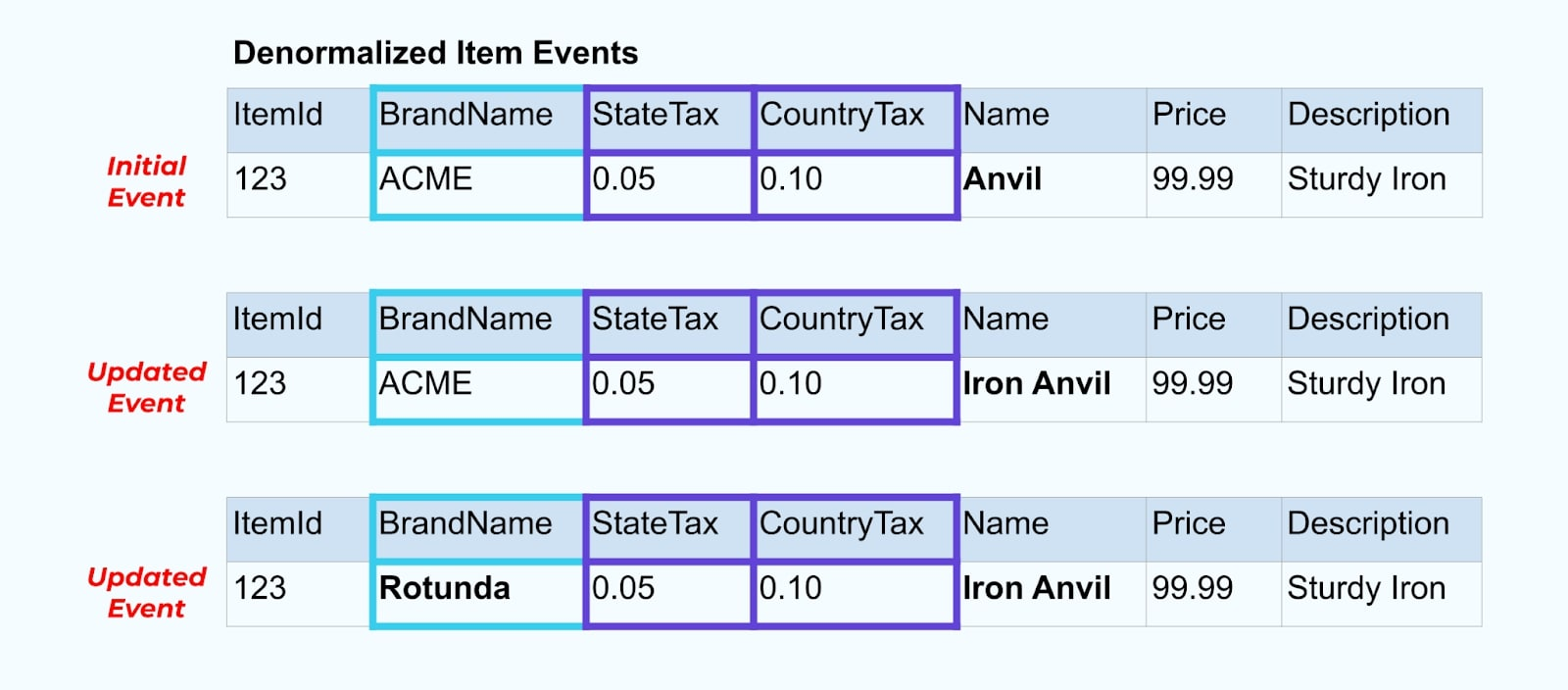
Cependant, Rotunda (anciennement ACME) a probablement des centaines (ou des milliers) d’articles qui sont également mis à jour par ce changement, résultant en un nombre correspondant d’événements d’articles enrichis mis à jour.
Lors de la dénormalisation des SCD et des relations de clé étrangère, gardez à l’esprit l’impact qu’un changement dans le SCD peut avoir sur le flux d’événements dans son ensemble. Vous pouvez décider de renoncer à la dénormalisation et de laisser cela à la charge du consommateur dans le cas où le changement du SCD entraîne des millions ou des milliards d’événements mis à jour.
Résumé
La dénormalisation facilite l’utilisation des données par les consommateurs, mais elle se fait au détriment d’un traitement en amont plus important et d’une sélection minutieuse des données à inclure. Les consommateurs peuvent avoir plus de facilité à développer des applications et peuvent choisir parmi une gamme plus large de technologies, y compris celles qui ne supportent pas nativement les jointures en streaming.
La normalisation des données en amont fonctionne bien lorsque les données sont petites et rarement mises à jour. Les tailles d’événements plus grandes, les mises à jour fréquentes et les SCD sont tous des facteurs à surveiller lors de la détermination de ce qu’il faut dénormaliser en amont et de ce qu’il faut laisser aux consommateurs pour qu’ils le fassent eux-mêmes.
En fin de compte, choisir quelles données inclure dans un événement et quelles données laisser de côté est un équilibre entre les besoins des consommateurs, les capacités des producteurs et les relations uniques du modèle de données. Mais le meilleur point de départ est de comprendre les besoins de vos consommateurs et l’isolement du modèle de données interne de votre système source.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2