













Introduction
Rails est un framework d’applications web écrit en Ruby. Il adopte une approche opiniâtre pour le développement d’applications, supposant que les conventions établies servent le mieux les développeurs lorsqu’il y a un objectif commun. Rails propose donc des conventions pour gérer le routage, les données avec état, la gestion des ressources, et plus encore, afin de fournir les fonctionnalités de base dont la plupart des applications web ont besoin.
Rails suit le modèle architectural modèle-vue-contrôleur (MVC), qui sépare la logique de l’application, située dans les modèles, de son routage et de la présentation des informations. Cette structure organisationnelle — ainsi que d’autres conventions permettant aux développeurs d’extraire du code dans helpers et partials — garantit que le code de l’application n’est pas répété inutilement.
Dans ce tutoriel, vous allez créer une application Rails qui permettra aux utilisateurs de publier des informations sur les requins et leur comportement. Ce sera un bon point de départ pour le développement futur d’applications.
Prérequis
Pour suivre ce tutoriel, vous aurez besoin :
- D’une machine locale ou d’un serveur de développement fonctionnant sous Ubuntu 18.04. Votre machine de développement doit disposer d’un utilisateur non root avec des privilèges administratifs et un pare-feu configuré avec
ufw. Pour obtenir des instructions sur la mise en place de cela, consultez notre tutoriel Configuration initiale du serveur avec Ubuntu 18.04. - Node.js et npm installés sur votre machine locale ou votre serveur de développement. Ce tutoriel utilise Node.js version 10.16.3 et npm version 6.9.0. Pour obtenir des conseils sur l’installation de Node.js et npm sur Ubuntu 18.04, suivez les instructions de la section “Installation à l’aide d’un PPA” de Comment installer Node.js sur Ubuntu 18.04.
- Ruby, rbenv, et Rails sont installees sur votre machine locale ou serveur de développement en suivant les étapes 1-4 dans Comment Installer Ruby on Rails avec rbenv sur Ubuntu 18.04. Cet tutoriel utilise Ruby 2.5.1, rbenv 1.1.2, et Rails 5.2.0.
Étape 1 — Installation de SQLite3
Avant de créer notre application Rails requin, nous devons assurer que nous disposons d’une base de données pour stocker des données utilisateur. Rails est configuré par défaut à utiliser SQLite et cela est souvent une bonne sélection en milieu de développement. Puisque notre application ne nécessite pas une haute flexibilité programmatique pour l’extensibilité des données, SQLite suffira généralement. Comme notre application n’utilisera pas de données complexes qui nécessiteront une extension programmable avancée, SQLite sera souvent la meilleure option.
Tout d’abord, mettez à jour votre index de paquets :
Ensuite, installez les packages sqlite3 et libsqlite3-dev :
sudo apt install sqlite3 libsqlite3-dev
Ceci va installer SQLite ainsi que ses fichiers nécessaires de développement.
Vérifiez votre version pour confirmer que l’installation a été réussie :
Output3.22.0 2018-01-22 18:45:57 0c55d179733b46d8d0ba4d88e01a25e10677046ee3da1d5b1581e86726f2alt1
Avec SQLite installé, vous pouvez commencer à développer votre application.
Étape 2 — Création d’un nouveau projet Rails
Avec notre base de données installée, nous pouvons créer un nouveau projet Rails et examiner un peu le code réutilisable par défaut que Rails nous fournit avec la commande rails new.
Créez un projet appelé sharkapp avec la commande suivante :
Vous verrez une bonne quantité de sortie vous indiquant ce que Rails crée pour votre nouveau projet. La sortie ci-dessous met en évidence certains fichiers, répertoires et commandes significatifs :
Output create
. . .
create Gemfile
. . .
create app
. . .
create app/controllers/application_controller.rb
. . .
create app/models/application_record.rb
. . .
create app/views/layouts/application.html.erb
. . .
create config
create config/routes.rb
create config/application.rb
. . .
create config/environments
create config/environments/development.rb
create config/environments/production.rb
create config/environments/test.rb
. . .
create config/database.yml
create db
create db/seeds.rb
. . .
run bundle install
. . .
Bundle complete! 18 Gemfile dependencies, 78 gems now installed.
Use `bundle info [gemname]` to see where a bundled gem is installed.
. . .
* bin/rake: Spring inserted
* bin/rails: Spring inserted
La sortie mise en évidence ici vous indique que Rails a créé les éléments suivants :
Gemfile: Ce fichier liste les dépendances de gemmes pour votre application. Une gemme est un package logiciel Ruby, et un Gemfile vous permet de gérer les besoins logiciels de votre projet.app: Le répertoireappest l’endroit où réside le code principal de votre application. Cela inclut les modèles, les contrôleurs, les vues, les assets, les helpers et les mailers qui constituent l’application elle-même. Rails vous fournit un code réutilisable au niveau de l’application pour le modèle MCV pour commencer dans des fichiers commeapp/models/application_record.rb,app/controllers/application_controller.rb, etapp/views/layouts/application.html.erb.config: Ce répertoire contient les paramètres de configuration de votre application :config/routes.rb: Les déclarations de routes de votre application se trouvent dans ce fichier.config/application.rb: Les paramètres généraux pour les composants de votre application sont situés dans ce fichier.
config/environments: Ce répertoire est l’endroit où se trouvent les paramètres de configuration pour vos environnements. Rails inclut trois environnements par défaut :development,productionettest.config/database.yml: Les paramètres de configuration de la base de données se trouvent dans ce fichier, qui est divisé en quatre sections :default,development,productionettest. Grâce au Gemfile qui est fourni avec la commanderails new, qui incluait la gemsqlite3, notre fichierconfig/database.ymla déjà son paramètreadapterdéfini sursqlite3, spécifiant que nous utiliserons une base de données SQLite avec cette application.db: Ce dossier comprend un répertoire pour les migrations de base de données appelémigrate, ainsi que les fichiersschema.rbetseeds.rb.schema.dbcontient des informations sur votre base de données, tandis queseeds.rbest l’endroit où vous pouvez placer des données de départ pour la base de données.
Enfin, Rails exécute la commande bundle install pour installer les dépendances listées dans votre Gemfile.
Une fois tout configuré, naviguez jusqu’au répertoire sharkapp:
Vous pouvez maintenant démarrer le serveur Rails pour vous assurer que votre application fonctionne, en utilisant la commande rails server. Si vous travaillez sur votre machine locale, tapez:
Rails se lie à localhost par défaut, vous pouvez donc accéder à votre application en naviguant dans votre navigateur vers locahost:3000, où vous verrez l’image suivante:

Si vous travaillez sur un serveur de développement, assurez-vous d’abord que les connexions sont autorisées sur le port 3000:
Ensuite, démarrez le serveur avec l’indicateur --binding pour vous lier à l’IP de votre serveur:
Naviguez vers http://your_server_ip:3000 dans votre navigateur, où vous verrez le message de bienvenue de Rails.
Une fois que vous avez parcouru les environs, vous pouvez arrêter le serveur avec CTRL+C.
Avec votre application créée et en place, vous êtes prêt à commencer à construire à partir du gabarit Rails pour créer une application unique.
Étape 3 — Scaffolding de l’application
Pour créer notre application d’information sur les requins, nous aurons besoin de créer un modèle pour gérer les données de notre application, des vues pour permettre l’interaction des utilisateurs avec ces données, et un contrôleur pour gérer la communication entre le modèle et les vues. Pour construire ces éléments, nous utiliserons la commande rails generate scaffold, qui nous fournira un modèle, une migration de base de données pour modifier le schéma de la base de données, un contrôleur, un ensemble complet de vues pour gérer les opérations Créer, Lire, Mettre à jour et Supprimer (CRUD) pour l’application, et des modèles pour les partiels, les aides et les tests.
Étant donné que la commande generate scaffold fait tellement de travail pour nous, nous examinerons de plus près les ressources qu’elle crée pour comprendre le travail que Rails effectue sous le capot.
Notre commande generate scaffold comprendra le nom de notre modèle et les champs que nous souhaitons dans notre table de base de données. Rails utilise Active Record pour gérer les relations entre les données de l’application, structurées en objets avec des modèles, et la base de données de l’application. Chacun de nos modèles est une classe Ruby, tout en héritant de la classe ActiveRecord::Base. Cela signifie que nous pouvons travailler avec notre classe de modèle de la même manière que nous travaillerions avec une classe Ruby, tout en tirant parti des méthodes d’Active Record. Active Record s’assurera ensuite que chaque classe est mappée à une table dans notre base de données, et chaque instance de cette classe à une ligne dans cette table.
Tapez la commande suivante pour générer un modèle Shark, un contrôleur et les vues associées :
Avec name:string et facts:text, nous fournissons à Rails des informations sur les champs que nous aimerions avoir dans notre table de base de données et le type de données qu’ils doivent accepter. Les deux nous donneront de l’espace pour entrer ce que nous souhaitons, bien que text permettra plus de caractères pour les faits sur les requins.
Lorsque vous tapez cette commande, vous verrez à nouveau une longue liste de sortie qui explique tout ce que Rails génère pour vous. La sortie ci-dessous met en évidence certaines des choses les plus importantes pour notre configuration :
Output invoke active_record
create db/migrate/20190804181822_create_sharks.rb
create app/models/shark.rb
. . .
invoke resource_route
route resources :sharks
invoke scaffold_controller
create app/controllers/sharks_controller.rb
invoke erb
create app/views/sharks
create app/views/sharks/index.html.erb
create app/views/sharks/edit.html.erb
create app/views/sharks/show.html.erb
create app/views/sharks/new.html.erb
create app/views/sharks/_form.html.erb
. . .
Rails a créé le modèle à app/models/shark.rb et une migration de base de données pour l’accompagner : db/migrate/20190804181822_create_sharks.rb. L’horodatage de votre fichier de migration sera différent de ce que vous voyez ici.
Il a également créé un contrôleur, app/controllers/sharks_controller.rb, ainsi que les vues associées aux opérations CRUD de notre application, regroupées sous app/views/sharks. Parmi ces vues se trouve une partial, _form.html.erb, qui contient du code utilisé dans plusieurs vues.
Enfin, Rails a ajouté une nouvelle route récupérable, resources :sharks, à config/routes.rb. Cela permet au routeur Rails de faire correspondre les requêtes HTTP entrantes avec le contrôleur sharks et ses vues associées.
Bien que Rails ait effectué une grande partie du travail de construction du code de notre application pour nous, il est utile de jeter un coup d’œil à certains fichiers pour comprendre ce qui se passe.
Tout d’abord, examinons le fichier du contrôleur avec la commande suivante :
Outputclass SharksController < ApplicationController
before_action :set_shark, only: [:show, :edit, :update, :destroy]
# GET /sharks
# GET /sharks.json
def index
@sharks = Shark.all
end
# GET /sharks/1
# GET /sharks/1.json
def show
end
# GET /sharks/new
def new
@shark = Shark.new
end
# GET /sharks/1/edit
def edit
end
# POST /sharks
# POST /sharks.json
def create
@shark = Shark.new(shark_params)
respond_to do |format|
if @shark.save
format.html { redirect_to @shark, notice: 'Shark was successfully created.' }
format.json { render :show, status: :created, location: @shark }
else
format.html { render :new }
format.json { render json: @shark.errors, status: :unprocessable_entity }
end
end
end
# PATCH/PUT /sharks/1
# PATCH/PUT /sharks/1.json
def update
respond_to do |format|
if @shark.update(shark_params)
format.html { redirect_to @shark, notice: 'Shark was successfully updated.' }
format.json { render :show, status: :ok, location: @shark }
else
format.html { render :edit }
format.json { render json: @shark.errors, status: :unprocessable_entity }
end
end
end
# DELETE /sharks/1
# DELETE /sharks/1.json
def destroy
@shark.destroy
respond_to do |format|
format.html { redirect_to sharks_url, notice: 'Shark was successfully destroyed.' }
format.json { head :no_content }
end
end
private
# Utiliser des callbacks pour partager la configuration commune ou les contraintes entre les actions.
def set_shark
@shark = Shark.find(params[:id])
end
# Ne jamais faire confiance aux paramètres venant de l'internet effrayant, autoriser uniquement ceux de la liste blanche.
def shark_params
params.require(:shark).permit(:name, :facts)
end
end
Le contrôleur est responsable de la gestion de la manière dont les informations sont récupérées et transmises à son modèle associé, et de la manière dont elles sont associées à des vues particulières. Comme vous pouvez le voir, notre contrôleur sharks inclut une série de méthodes qui correspondent à peu près aux opérations CRUD standard. Cependant, il y a plus de méthodes que de fonctions CRUD, pour permettre l’efficacité en cas d’erreurs.
Par exemple, considérons la méthode create :
. . .
def create
@shark = Shark.new(shark_params)
respond_to do |format|
if @shark.save
format.html { redirect_to @shark, notice: 'Shark was successfully created.' }
format.json { render :show, status: :created, location: @shark }
else
format.html { render :new }
format.json { render json: @shark.errors, status: :unprocessable_entity }
end
end
end
. . .
Si une nouvelle instance de la classe Shark est sauvegardée avec succès, redirect_to générera une nouvelle requête qui sera dirigée vers le contrôleur. Ce sera une requête GET, et elle sera traitée par la méthode show, qui montrera à l’utilisateur le requin qu’il vient d’ajouter.
En cas d’échec, Rails rendra à nouveau le modèle app/views/sharks/new.html.erb au lieu de faire une autre requête au routeur, donnant ainsi aux utilisateurs une autre chance de soumettre leurs données.
En plus du contrôleur des requins, Rails nous a fourni un modèle pour une vue index, qui correspond à la méthode index dans notre contrôleur. Nous utiliserons cela comme vue racine de notre application, il est donc utile de jeter un coup d’œil.
Tapez ce qui suit pour afficher le fichier :
Output<p id="notice"><%= notice %></p>
<h1>Sharks</h1>
<table>
<thead>
<tr>
<th>Name</th>
<th>Facts</th>
<th colspan="3"></th>
</tr>
</thead>
<tbody>
<% @sharks.each do |shark| %>
<tr>
<td><%= shark.name %></td>
<td><%= shark.facts %></td>
<td><%= link_to 'Show', shark %></td>
<td><%= link_to 'Edit', edit_shark_path(shark) %></td>
<td><%= link_to 'Destroy', shark, method: :delete, data: { confirm: 'Are you sure?' } %></td>
</tr>
<% end %>
</tbody>
</table>
<br>
<%= link_to 'New Shark', new_shark_path %>
La vue index parcourt les instances de notre classe Shark, qui ont été mappées à la table sharks dans notre base de données. En utilisant le templating ERB, la vue affiche chaque champ de la table associé à une instance individuelle de requin : name et facts.
La vue utilise ensuite l’aide link_to pour créer un hyperlien, avec la chaîne fournie comme texte du lien et le chemin fourni comme destination. Les chemins eux-mêmes sont rendus possibles grâce aux aides qui sont devenues disponibles lorsque nous avons défini la route sharks avec la commande rails generate scaffold.
En plus de regarder notre vue index, nous pouvons également examiner la vue new pour voir comment Rails utilise les partiels dans les vues. Tapez ce qui suit pour afficher le modèle app/views/sharks/new.html.erb :
Output<h1>New Shark</h1>
<%= render 'form', shark: @shark %>
<%= link_to 'Back', sharks_path %>
Bien que ce modèle puisse sembler manquer de champs de saisie pour une nouvelle entrée de requin, la référence à render 'form' nous indique que le modèle intègre la partial _form.html.erb, qui extrait le code répété dans différentes vues.
En examinant ce fichier, nous obtiendrons une vision complète de la manière dont une nouvelle instance de requin est créée :
Output<%= form_with(model: shark, local: true) do |form| %>
<% if shark.errors.any? %>
<div id="error_explanation">
<h2><%= pluralize(shark.errors.count, "error") %> prohibited this shark from being saved:</h2>
<ul>
<% shark.errors.full_messages.each do |message| %>
<li><%= message %></li>
<% end %>
</ul>
</div>
<% end %>
<div class="field">
<%= form.label :name %>
<%= form.text_field :name %>
</div>
<div class="field">
<%= form.label :facts %>
<%= form.text_area :facts %>
</div>
<div class="actions">
<%= form.submit %>
</div>
<% end %>
Ce modèle utilise le form_with assistant de formulaire. Les assistants de formulaire sont conçus pour faciliter la création d’objets nouveaux à partir des entrées utilisateur en utilisant les champs et la portée de modèles spécifiques. Ici, form_with prend model: shark comme argument, et l’objet constructeur de formulaire nouvellement créé possède des entrées de champ qui correspondent aux champs dans la table sharks. Ainsi, les utilisateurs ont des champs de formulaire pour entrer à la fois un nom de requin et des faits sur le requin.
Soumettre ce formulaire créera une réponse JSON avec les données de l’utilisateur que le reste de votre application peut accéder via la méthode params, qui crée un objet ActionController::Parameters avec ces données.
Maintenant que vous savez ce que rails generate scaffold a produit pour vous, vous pouvez passer à la définition de la vue racine de votre application.
Étape 4 — Création de la Vue Racine de l’Application et Test de la Fonctionnalité
Idéalement, vous souhaitez que la page d’accueil de votre application corresponde à la racine de l’application, afin que les utilisateurs puissent immédiatement saisir l’objectif de l’application.
Il existe plusieurs façons de gérer cela : par exemple, vous pourriez créer un contrôleur Welcome et une vue index associée, qui offrirait aux utilisateurs une page d’accueil générique pouvant également rediriger vers différentes parties de l’application. Cependant, dans notre cas, le fait que les utilisateurs arrivent sur notre vue index des requins sera suffisamment explicite sur l’objectif de l’application pour l’instant.
Pour configurer cela, vous devrez modifier les paramètres de routage dans config/routes.rb pour spécifier la racine de l’application.
Ouvrez config/routes.rb pour édition, en utilisant nano ou votre éditeur préféré :
Le fichier ressemblera à ceci :
Rails.application.routes.draw do
resources :sharks
# Pour plus de détails sur le DSL disponible dans ce fichier, voir http://guides.rubyonrails.org/routing.html
end
Sans définir quelque chose de plus spécifique, la vue par défaut à http://localhost:3000 ou http://votre_ip_serveur:3000 sera la page de bienvenue Rails par défaut.
Pour mapper la vue racine de l’application à la vue index du contrôleur sharks, vous devez ajouter la ligne suivante au fichier:
Rails.application.routes.draw do
resources :sharks
root 'sharks#index'
# Pour plus de détails sur le DSL disponible dans ce fichier, consultez http://guides.rubyonrails.org/routing.html
end
Maintenant, lorsque les utilisateurs naviguent vers la racine de votre application, ils verront une liste complète des requins et auront la possibilité de créer une nouvelle entrée de requin, de consulter les entrées existantes et de modifier ou supprimer des entrées données.
Enregistrez le fichier et quittez votre éditeur une fois l’édition terminée. Si vous avez utilisé nano pour éditer le fichier, vous pouvez le faire en appuyant sur CTRL+X, Y, puis ENTER.
Vous pouvez maintenant exécuter vos migrations avec la commande suivante:
Vous verrez une sortie confirmant la migration.
Redémarrez votre serveur Rails. Si vous travaillez localement, tapez:
Sur un serveur de développement, tapez:
Naviguez vers localhost:3000 si vous travaillez localement, ou http://votre_serveur_ip:3000 si vous travaillez sur un serveur de développement.
La page d’accueil de votre application ressemblera à ceci:

Pour créer un nouveau requin, cliquez sur le lien Nouveau Requin en bas de la page, qui vous dirigera vers la route sharks/new:
Ajoutons quelques informations de démonstration pour tester notre application. Entrez « Grand Blanc » dans le champ Nom et « Effrayant » dans le champ Faits:
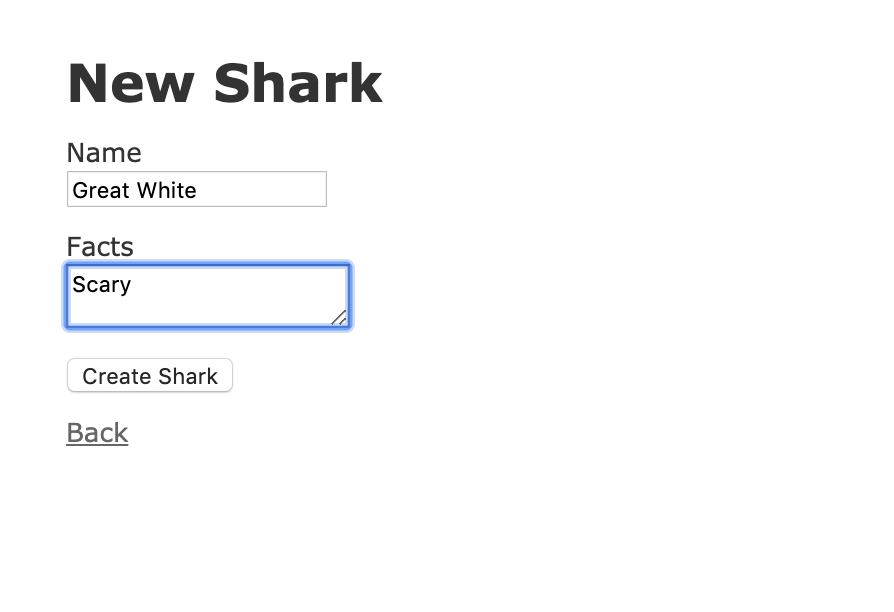
Cliquez sur le bouton Créer pour créer le requin.
Cela vous dirigera vers la route show, qui, grâce au filtre before_action, est configurée avec la méthode set_shark, qui récupère l’id du requin que nous venons de créer :
class SharksController < ApplicationController
before_action :set_shark, only: [:show, :edit, :update, :destroy]
. . .
def show
end
. . .
private
# Utiliser des rappels pour partager une configuration commune ou des contraintes entre les actions.
def set_shark
@shark = Shark.find(params[:id])
end
. . .

Vous pouvez tester la fonction d’édition maintenant en cliquant sur Modifier sur votre entrée de requin. Cela vous amènera à la route edit pour ce requin :

Modifiez les faits sur le Grand Blanc pour qu’ils lisent « Grand » au lieu de « Effrayant » et cliquez sur Mettre à jour le Requin. Cela vous ramènera à la route show :

Enfin, en cliquant sur Retour, vous serez redirigé vers votre vue index mise à jour :

Maintenant que vous avez testé les fonctionnalités de base de votre application, vous pouvez ajouter des validations et des contrôles de sécurité pour rendre tout plus sécurisé.
Étape 5 — Ajout de Validations
Votre application sur les requins peut accepter des entrées des utilisateurs, mais imaginez un cas où un utilisateur tente de créer un requin sans ajouter de faits à celui-ci, ou crée une entrée pour un requin déjà présent dans la base de données. Vous pouvez créer des mécanismes pour vérifier les données avant qu’elles ne soient entrées dans la base de données en ajoutant des validations à vos modèles. Puisque la logique de votre application se trouve dans ses modèles, valider les entrées de données ici fait plus de sens que de le faire ailleurs dans l’application.
Notez que nous n’aborderons pas l’écriture de tests de validation dans ce tutoriel, mais vous pouvez en savoir plus sur les tests en consultant la documentation de Rails.
Si vous n’avez pas encore arrêté le serveur, faites-le en tapant CTRL+C.
Ouvrez votre fichier de modèle shark.rb:
Actuellement, le fichier nous indique que la classe Shark hérite de ApplicationRecord, qui hérite à son tour de ActiveRecord::Base:
class Shark < ApplicationRecord
end
Ajoutons d’abord quelques validations à notre champ name pour confirmer que le champ est rempli et que l’entrée est unique, empêchant ainsi les doublons:
class Shark < ApplicationRecord
validates :name, presence: true, uniqueness: true
end
Ensuite, ajoutez une validation pour le champ facts pour s’assurer qu’il est également rempli:
class Shark < ApplicationRecord
validates :name, presence: true, uniqueness: true
validates :facts, presence: true
end
Nous sommes moins préoccupés par l’unicité des faits, tant qu’ils sont associés à des entrées de requins uniques.
Enregistrez et fermez le fichier lorsque vous avez terminé.
Redémarrez votre serveur une fois de plus avec rails s ou rails s --binding=your_server_ip, selon que vous travaillez localement ou avec un serveur de développement.
Accédez à la racine de votre application à l’adresse http://localhost:3000 ou http://your_server_ip:3000.
Cliquez sur Nouveau Requin. Dans le formulaire, ajoutez “Grand Blanc” au champ Nom et “Grandes Dents” au champ Faits, puis cliquez sur Créer Requin. Vous devriez voir l’avertissement suivant :
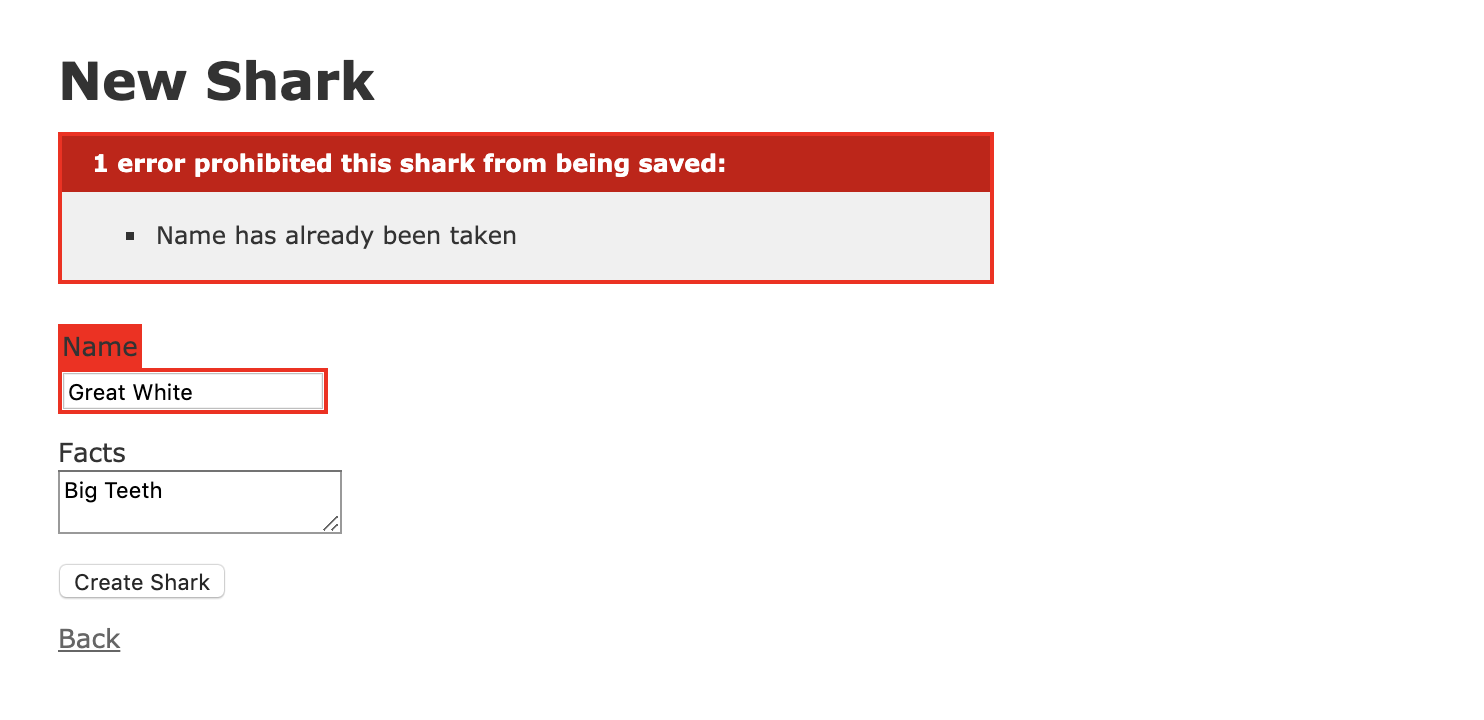
Voyons maintenant si nous pouvons vérifier notre autre validation. Cliquez sur Retour pour revenir à la page d’accueil, puis sur Nouveau Requin à nouveau. Dans le nouveau formulaire, entrez “Requin-Tigre” dans le champ Nom, et laissez Faits vide. Cliquer sur Créer Requin déclenchera l’avertissement suivant :
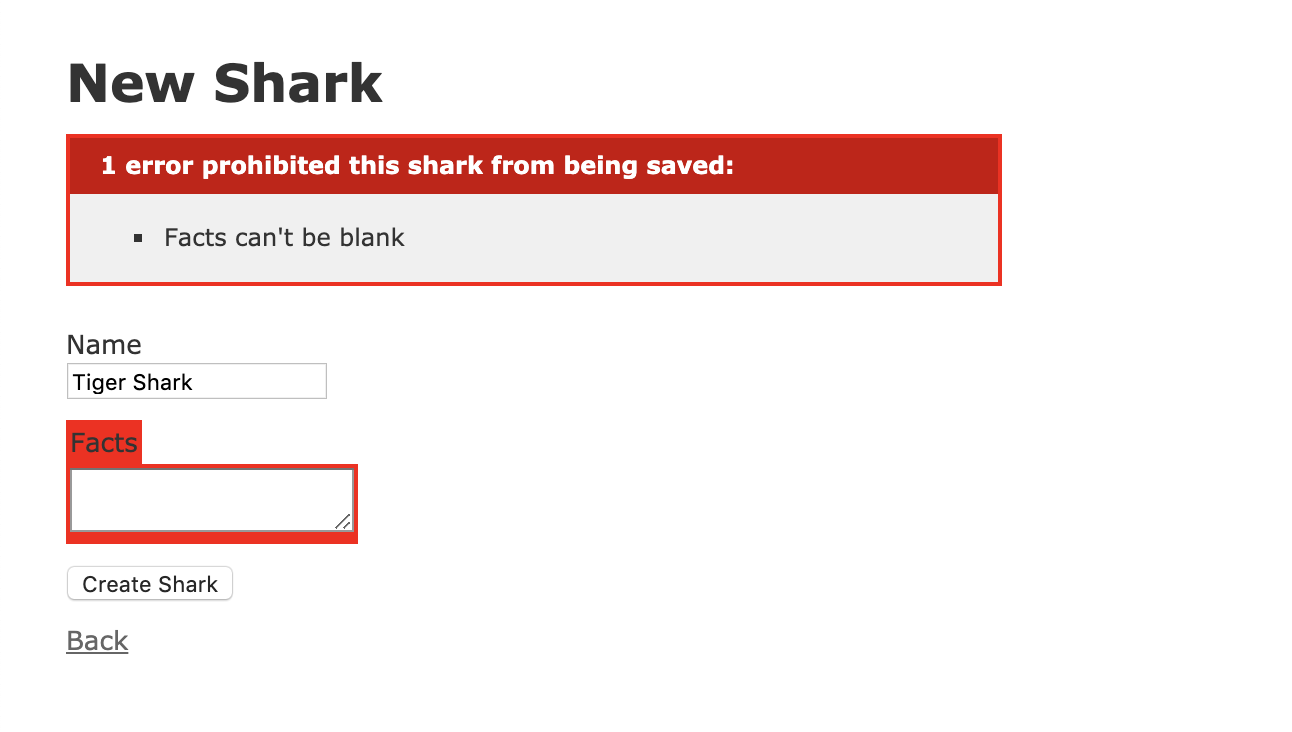
Avec ces modifications, votre application a quelques validations en place pour assurer la cohérence des données enregistrées dans la base de données. Vous pouvez maintenant vous concentrer sur les utilisateurs de votre application et définir qui peut modifier les données de l’application.
Étape 6 — Ajout de l’Authentification
Avec les validations en place, nous avons certaines garanties concernant les données enregistrées dans la base de données. Mais qu’en est-il des utilisateurs ? Si nous ne voulons pas que n’importe quel utilisateur ajoute à la base de données, nous devrions ajouter des mesures d’authentification pour garantir que seuls les utilisateurs autorisés peuvent ajouter des requins. Pour ce faire, nous utiliserons la méthode http_basic_authenticate_with, qui nous permettra de créer une combinaison nom d’utilisateur et mot de passe pour authentifier les utilisateurs.
Il existe de nombreux moyens pour authentifier les utilisateurs avec Ruby on Rails, y compris l’utilisation des gemmes bcrypt ou devise. Pour l’instant, nous ajouterons une méthode à notre contrôleur d’application qui sera appliquée aux actions sur toute notre application. Cela sera utile si vous ajoutez plus tard des contrôleurs supplémentaires dans l’application.
Arrêter votre serveur à nouveau avec CTRL+C.
Ouvrez le fichier qui définit la classe ApplicationController:
Dans ce fichier, vous verrez la définition de la classe ApplicationController qui hérite des autres contrôleurs de votre application:
class ApplicationController < ActionController::Base
end
A l’intérieur, vous trouverez la définition de la classe ApplicationController qui est héritée par les autres contrôleurs de votre application. Afin d’authentifier les utilisateurs, ajoutez le code suivant au fichier:
class ApplicationController < ActionController::Base
http_basic_authenticate_with name: 'sammy', password: 'shark', except: [:index, :show]
end
En outre, en fournissant ici un nom d’utilisateur et un mot de passe, nous avons également restreint l’authentification en spécifiant les routes où elle ne devrait pas être nécessaire: index et show. Une autre façon de faire ceci serait de écrire only: [:create, :update, :destroy]. De cette manière, tous les utilisateurs pourront regarder tous les requins et lire des faits sur certains requins. Quand il s’agit de modifier du contenu du site, cependant, les utilisateurs doivent prouver qu’ils disposent de l’accès.
Dans une configuration plus robuste, vous ne voudriez pas coder en dur des valeurs de cette manière, mais à des fins de démonstration, cela vous permettra de voir comment vous pouvez inclure l’authentification pour les routes de votre application. Cela vous permet également de voir comment Rails stocke les données de session par défaut dans les cookies : une fois que vous vous êtes authentifié sur une action spécifiée, vous ne serez pas tenu de vous authentifier à nouveau dans la même session.
Enregistrez et fermez app/controllers/application_controller.rb lorsque vous avez terminé de modifier. Vous pouvez maintenant tester l’authentification en action.
Démarrez le serveur avec soit rails s ou rails s --binding=your_server_ip et naviguez vers votre application à soit http://localhost:3000 ou http://your_server_ip:3000.
Sur la page d’accueil, cliquez sur le bouton Nouveau Shark. Cela déclenchera la fenêtre d’authentification suivante :
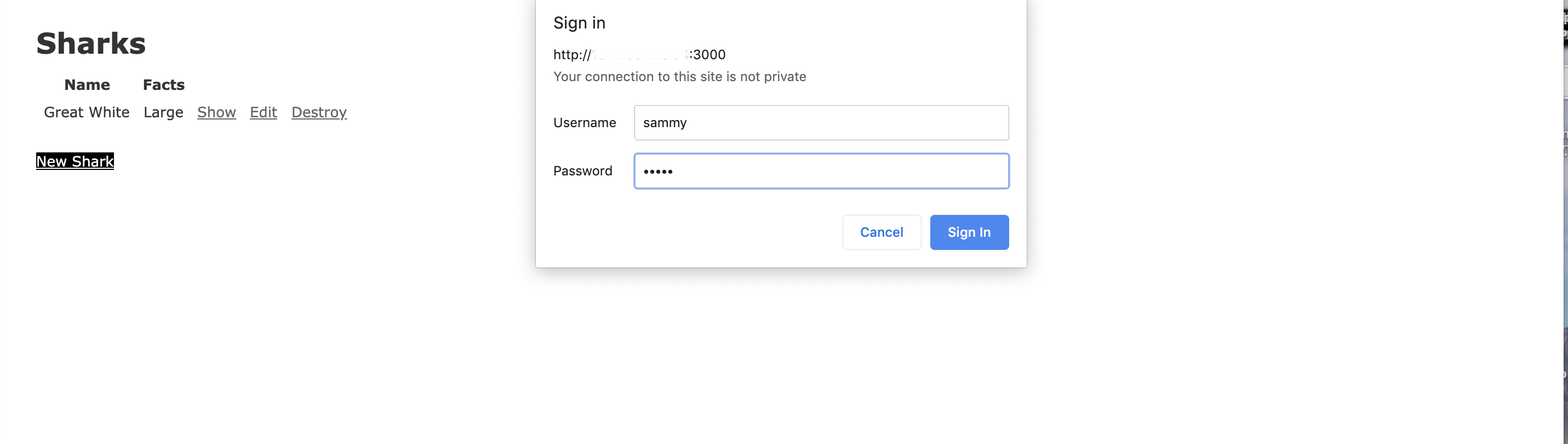
Si vous entrez la combinaison nom d’utilisateur et mot de passe que vous avez ajoutée à app/controllers/application_controller.rb, vous serez en mesure de créer en toute sécurité un nouveau requin.
Vous avez maintenant une application requin opérationnelle, complète avec des validations de données et un schéma d’authentification de base.
Conclusion
L’application Rails que vous avez créée dans ce tutoriel est un point de départ que vous pouvez utiliser pour un développement plus poussé. Si vous êtes intéressé par l’exploration de l’écosystème Rails, la documentation du projet est un excellent point de départ.
Vous pouvez également en savoir plus sur l’ajout de ressources imbriquées à votre projet en lisant Comment créer des ressources imbriquées pour une application Ruby on Rails, qui vous montrera comment développer les modèles et les routes de votre application.
De plus, vous pourriez souhaiter explorer comment mettre en place un frontend plus robuste pour votre projet avec un framework comme React. Comment configurer un projet Ruby on Rails avec un frontend React offre des conseils sur la façon de le faire.
Si vous souhaitez explorer différentes options de bases de données, vous pouvez également consulter Comment utiliser PostgreSQL avec votre application Ruby on Rails sur Ubuntu 18.04, qui explique comment travailler avec PostgreSQL au lieu de SQLite. Vous pouvez également consulter notre bibliothèque de tutoriels PostgreSQL pour en apprendre davantage sur l’utilisation de cette base de données.
Source:
https://www.digitalocean.com/community/tutorials/how-to-build-a-ruby-on-rails-application