













Introduction
Tout comme toute autre configuration, les données dans un cluster Kubernetes peuvent être exposées au risque de perte. Pour éviter les problèmes sérieux, il est essentiel d’avoir un plan de récupération des données à portée de main. Une manière simple et efficace de le faire est de faire des sauvegardes, en veillant à ce que vos données soient en sécurité en cas d’événements inattendus. Les sauvegardes peuvent être exécutées ponctuellement ou planifiées. Il est conseillé d’avoir des sauvegardes planifiées pour garantir que vous disposez d’une sauvegarde récente sur laquelle vous pouvez facilement revenir.
Velero – un outil open-source conçu pour aider aux opérations de sauvegarde et de restauration pour les clusters Kubernetes. Il est idéal pour le cas d’utilisation de la récupération après sinistre, ainsi que pour la capture instantanée de l’état de votre application avant d’effectuer des opérations système sur votre cluster, comme les mises à niveau. Pour plus de détails sur ce sujet, veuillez visiter la page officielle Comment fonctionne Velero.
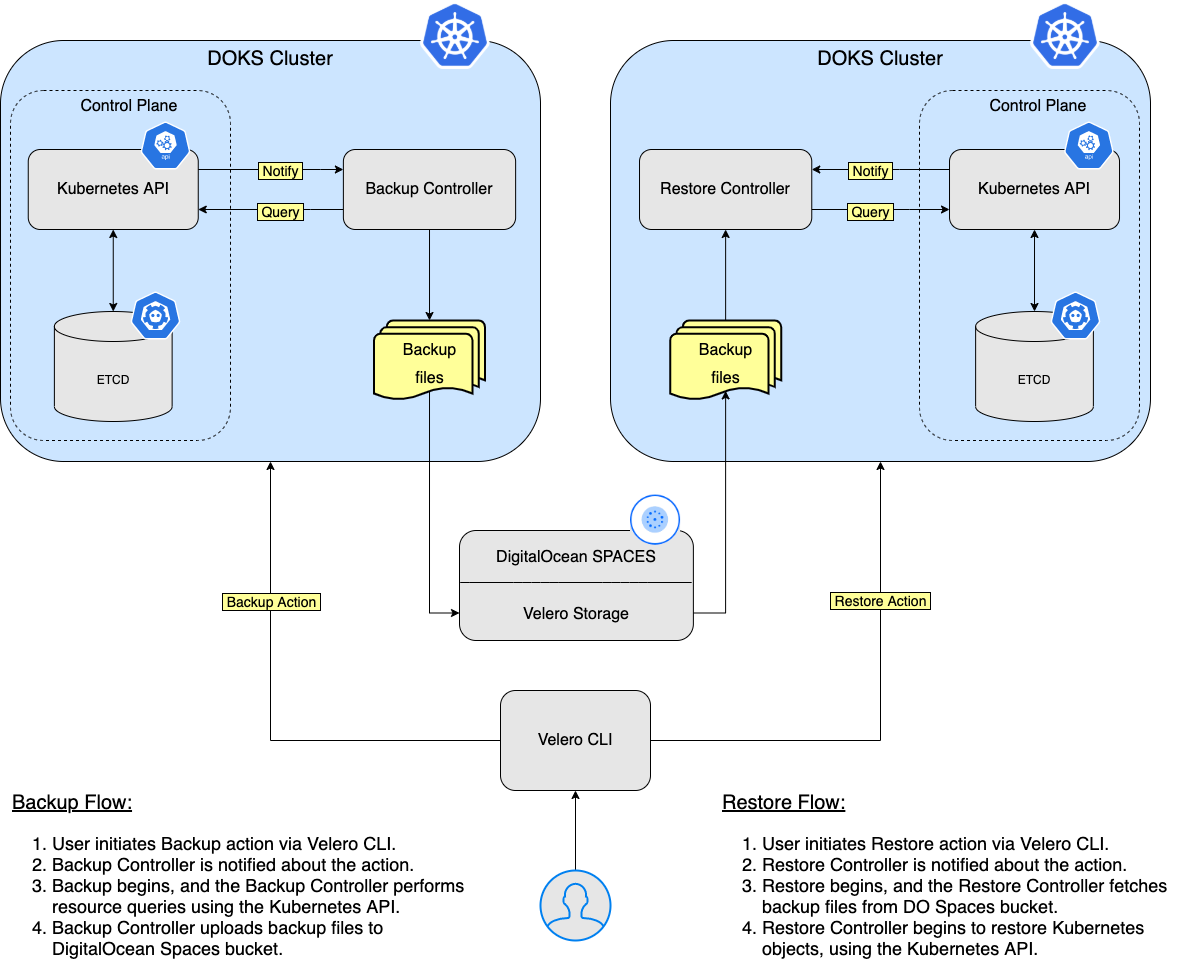
Dans ce tutoriel, vous apprendrez comment déployer Velero sur votre cluster Kubernetes, créer des sauvegardes et récupérer à partir d’une sauvegarde en cas de problème. Vous pouvez sauvegarder l’intégralité de votre cluster ou choisir facultativement un espace de noms ou un sélecteur d’étiquette pour sauvegarder votre cluster.
Table des matières
- Prérequis
- Étape 1 – Installation de Velero à l’aide de Helm
- Étape 2 – Exemple de sauvegarde et de restauration de l’espace de noms
- Étape 3 – Exemple de sauvegarde et de restauration de l’ensemble du cluster
- Étape 4 – Sauvegardes planifiées
- Étape 5 – Suppression des sauvegardes
Prérequis
Pour accomplir ce tutoriel, vous avez besoin de ce qui suit :
- A DO Spaces Bucket and access keys. Save the access and secret keys in a safe place for later use.
- A DigitalOcean API token for Velero to use.
- A Git client, to clone the Starter Kit repository.
- Helm pour gérer les versions et les mises à jour de Velero.
- Doctl pour l’interaction avec l’API DigitalOcean.
- Kubectl pour l’interaction avec Kubernetes.
- Client Velero pour gérer les sauvegardes Velero.
Étape 1 – Installation de Velero à l’aide de Helm
Dans cette étape, vous déploierez Velero et tous les composants requis, afin qu’il puisse effectuer des sauvegardes de vos ressources de cluster Kubernetes (y compris les PV). Les données de sauvegarde seront stockées dans le compartiment DO Spaces créé précédemment dans la section Prérequis.
Tout d’abord, clonez le dépôt Git du Starter Kit et changez le répertoire vers votre copie locale :
Ensuite, ajoutez le dépôt Helm et répertoriez les charts disponibles :
La sortie ressemble à ce qui suit :
NAME CHART VERSION APP VERSION DESCRIPTION
vmware-tanzu/velero 2.29.7 1.8.1 A Helm chart for velero
Le chart d’intérêt est vmware-tanzu/velero, qui installera Velero sur le cluster. Veuillez visiter la page velero-chart pour plus de détails sur ce chart.
Ensuite, ouvrez et inspectez le fichier de valeurs Helm de Velero fourni dans le dépôt Starter Kit en utilisant un éditeur de votre choix (de préférence avec prise en charge de la validation YAML).
Ensuite, veuillez remplacer les espaces réservés <> en conséquence pour votre compartiment Velero DO Spaces (comme le nom, la région et les secrets). Assurez-vous de fournir également votre jeton d’API DigitalOcean (DIGITALOCEAN_TOKEN key).
Enfin, installez Velero en utilisant helm :
A specific version of the Velero Helm chart is used. In this case 2.29.7 is picked, which maps to the 1.8.1 version of the application (see the output from Step 2.). It’s a good practice in general to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
Maintenant, vérifiez votre déploiement Velero en exécutant :
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
velero velero 1 2022-06-09 08:38:24.868664 +0300 EEST deployed velero-2.29.7 1.8.1
La sortie ressemble à ce qui suit (la colonne STATUS devrait afficher deployed) :
Ensuite, vérifiez que Velero est opérationnel :
NAME READY UP-TO-DATE AVAILABLE AGE
velero 1/1 1 1 67s
La sortie ressemble à ce qui suit (les pods de déploiement doivent être dans l’état Ready):
Si vous souhaitez approfondir, vous pouvez consulter les composants côté serveur de Velero:
- Explorez les pages d’aide de la CLI Velero pour voir quelles commandes et sous-commandes sont disponibles. Vous pouvez obtenir de l’aide pour chacune en utilisant le drapeau
--help: - Listez toutes les commandes disponibles pour
Velero:
Listez les options de commande backup pour Velero:
Velero utilise plusieurs CRD (Custom Resource Definitions) pour représenter ses ressources telles que les sauvegardes, les planifications de sauvegarde, etc. Vous découvrirez chacun dans les prochaines étapes du tutoriel, ainsi que quelques exemples de base.
Étape 2 – Exemple de sauvegarde et de restauration de l’espace de noms
Dans cette étape, vous apprendrez comment effectuer une sauvegarde ponctuelle pour un espace de noms complet à partir de votre cluster DOKS et le restaurer ensuite en vous assurant que toutes les ressources sont recréées. L’espace de noms en question est ambassador.
Création de la sauvegarde de l’espace de noms Ambassador
Tout d’abord, initiez la sauvegarde :
Ensuite, vérifiez que la sauvegarde a été créée :
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 29d default <none>
La sortie ressemble à ceci :
Puis, après quelques instants, vous pouvez l’inspecter :
Name: ambassador-backup
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
...
-
La sortie ressemble à ceci :
-
Recherchez la ligne
Phase. Elle devrait indiquerTerminée. - Vérifiez également qu’aucune erreur n’est signalée.
Un nouvel objet de sauvegarde Kubernetes est créé :
~ kubectl get backup/ambassador-backup -n velero -o yaml
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
velero.io/source-cluster-k8s-gitversion: v1.21.2
velero.io/source-cluster-k8s-major-version: "1"
velero.io/source-cluster-k8s-minor-version: "21"
...
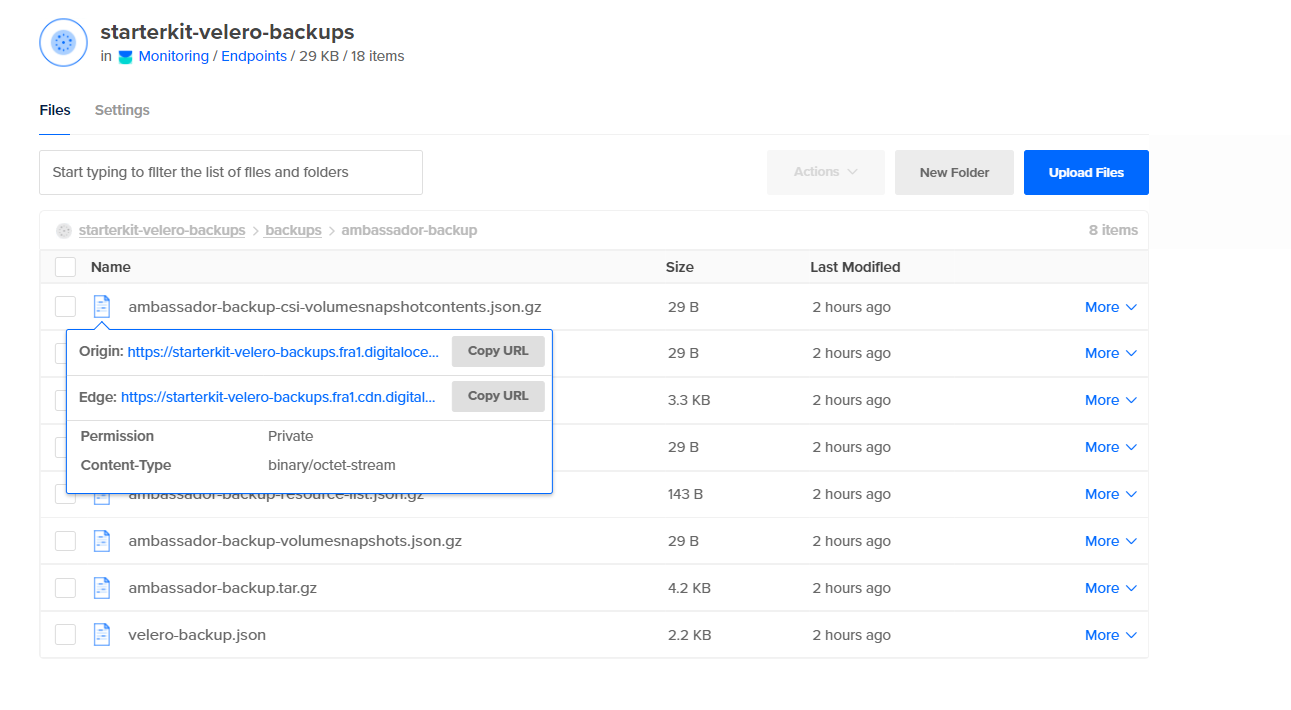
Enfin, jetez un œil au compartiment DO Spaces et vérifiez s’il y a un nouveau dossier nommé backups qui contient les éléments créés pour votre ambassador-backup:
Suppression de l’espace de noms et des ressources de l’Ambassadeur
Tout d’abord, simulez un désastre en supprimant intentionnellement l’espace de noms ambassador:
Ensuite, vérifiez que l’espace de noms a été supprimé (la liste des espaces de noms ne devrait pas afficher ambassador):
Enfin, vérifiez que le point de terminaison des services backend echo et quote est DOWN. Veuillez vous référer à Création des services backend de l’Empilement des Bords de l’Ambassadeur concernant les applications backend utilisées dans le tutoriel du Kit de Démarrage. Vous pouvez utiliser curl pour tester (ou vous pouvez utiliser votre navigateur web):
Restauration de la Sauvegarde de l’Espace de Noms de l’Ambassadeur
Restaurez le ambassador-backup:
Important: Lorsque vous supprimez l’espace de noms ambassador, la ressource du répartiteur de charge associée au service ambassadeur sera également supprimée. Ainsi, lorsque vous restaurez le service ambassador, le répartiteur de charge sera recréé par DigitalOcean. Le problème ici est que vous obtiendrez une NOUVELLE adresse IP pour votre répartiteur de charge, donc vous devrez ajuster les enregistrements A pour diriger le trafic vers vos domaines hébergés sur le cluster.
Vérification de la Restauration de l’Espace de Noms Ambassador
Pour vérifier la restauration de l’espace de noms ambassador, vérifiez la ligne Phase de la sortie de la commande de restauration ambassador-backup. Elle devrait indiquer Terminé (veuillez également prendre note de la section Avertissements – cela indique si quelque chose s’est mal passé) :
Ensuite, vérifiez que toutes les ressources ont été restaurées pour l’espace de noms ambassador. Recherchez les pods ambassador, les services et les déploiements.
NAME READY STATUS RESTARTS AGE
pod/ambassador-5bdc64f9f6-9qnz6 1/1 Running 0 18h
pod/ambassador-5bdc64f9f6-twgxb 1/1 Running 0 18h
pod/ambassador-agent-bcdd8ccc8-8pcwg 1/1 Running 0 18h
pod/ambassador-redis-64b7c668b9-jzxb5 1/1 Running 0 18h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ambassador LoadBalancer 10.245.74.214 159.89.215.200 80:32091/TCP,443:31423/TCP 18h
service/ambassador-admin ClusterIP 10.245.204.189 <none> 8877/TCP,8005/TCP 18h
service/ambassador-redis ClusterIP 10.245.180.25 <none> 6379/TCP 18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ambassador 2/2 2 2 18h
deployment.apps/ambassador-agent 1/1 1 1 18h
deployment.apps/ambassador-redis 1/1 1 1 18h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ambassador-5bdc64f9f6 2 2 2 18h
replicaset.apps/ambassador-agent-bcdd8ccc8 1 1 1 18h
replicaset.apps/ambassador-redis-64b7c668b9 1 1 1 18h
La sortie ressemble à ceci :
Obtenir les hôtes ambassadeur :
NAME HOSTNAME STATE PHASE COMPLETED PHASE PENDING AGE
echo-host echo.starter-kit.online Ready 11m
quote-host quote.starter-kit.online Ready 11m
La sortie ressemble à ceci :
ÉTAT devrait être Prêt et la colonne NOM D'HÔTE devrait pointer vers le nom d’hôte qualifié.
Obtenir les mappages ambassadeur :
NAME SOURCE HOST SOURCE PREFIX DEST SERVICE STATE REASON
ambassador-devportal /documentation/ 127.0.0.1:8500
ambassador-devportal-api /openapi/ 127.0.0.1:8500
ambassador-devportal-assets /documentation/(assets|styles)/(.*)(.css) 127.0.0.1:8500
ambassador-devportal-demo /docs/ 127.0.0.1:8500
echo-backend echo.starter-kit.online /echo/ echo.backend
quote-backend quote.starter-kit.online /quote/ quote.backend
La sortie ressemble à ceci (notez le echo-backend qui est mappé sur l’hôte echo.starter-kit.online et le préfixe source /echo/, de même pour quote-backend):
Enfin, après avoir reconfiguré votre équilibreur de charge et les paramètres de domaine DigitalOcean, veuillez vérifier que le point de terminaison des services backend echo et quote est UP. Reportez-vous à Création des services backend du stack de bordure Ambassador.
Dans l’étape suivante, vous simulerez une catastrophe en supprimant intentionnellement votre cluster DOKS.
Étape 3 – Exemple de sauvegarde et restauration de l’ensemble du cluster
Dans cette étape, vous simulerez un scénario de reprise après sinistre. Le cluster DOKS complet sera supprimé, puis restauré à partir d’une sauvegarde précédente.
Création de la sauvegarde du cluster DOKS
Tout d’abord, créez une sauvegarde pour l’ensemble du cluster DOKS :
Ensuite, vérifiez que la sauvegarde a été créée et qu’aucune erreur n’est signalée. La commande suivante répertorie toutes les sauvegardes disponibles :
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
all-cluster-backup Completed 0 0 2021-08-25 19:43:03 +0300 EEST 29d default <none>
La sortie ressemble à ceci :
Enfin, inspectez l’état de la sauvegarde et les journaux (vérifiez qu’aucune erreur n’est signalée) :
Important : Chaque fois que vous détruisez un cluster DOKS sans spécifier le drapeau --dangerous à la commande doctl et ensuite le restaurer, le même répartiteur de charge avec la même IP est recréé. Cela signifie que vous n’avez pas besoin de mettre à jour vos enregistrements DNS A de DigitalOcean.
Mais lorsque le drapeau --dangerous est appliqué à la commande doctl, le répartiteur de charge existant sera détruit et un nouveau répartiteur de charge avec une nouvelle IP externe sera créé lorsque Velero restaurera votre contrôleur d’entrée. Donc, assurez-vous de mettre à jour vos enregistrements DNS A de DigitalOcean en conséquence.
Tout d’abord, supprimez l’intégralité du cluster DOKS (assurez-vous de remplacer les espaces réservés <> en conséquence).
Pour supprimer le cluster Kubernetes sans détruire le répartiteur de charge associé, exécutez :
Ou pour supprimer le cluster Kubernetes ainsi que le répartiteur de charge associé :
Ensuite, recréez le cluster, comme décrit dans Configurer DigitalOcean Kubernetes. Il est important de s’assurer que le nouveau nombre de nœuds du cluster DOKS est égal ou supérieur à l’original.
Ensuite, installez Velero CLI et le serveur, comme décrit dans la section Prérequis et dans Étape 1 – Installation de Velero à l’aide de Helm respectivement. Il est important d’utiliser la même version du Helm Chart.
Enfin, restaurez tout en exécutant la commande suivante :
Vérification de l’état des applications du cluster DOKS
Tout d’abord, vérifiez la ligne Phase de la sortie de la commande de description de la restauration all-cluster-backup. (Remplacez les marqueurs <> en conséquence). Elle devrait indiquer Terminé.
Ensuite, vérifiez toutes les ressources du cluster en exécutant :
Maintenant, les applications côté serveur devraient également répondre aux requêtes HTTP. Veuillez vous référer à Création des services côté serveur de l’ambassadeur Edge Stack concernant les applications utilisées dans le tutoriel du Kit de démarrage.
Dans la prochaine étape, vous apprendrez comment effectuer des sauvegardes planifiées (ou automatiques) pour vos applications de cluster DOKS.
Étape 4 – Sauvegardes Planifiées
Effectuer des sauvegardes automatiquement selon un calendrier est une fonctionnalité vraiment utile. Cela vous permet de remonter dans le temps et de restaurer le système à un état de fonctionnement précédent en cas de problème.
La création d’une sauvegarde planifiée est un processus très simple. Un exemple est fourni ci-dessous pour un intervalle de 1 minute (l’espace de noms kube-system a été choisi).
Tout d’abord, créez l’horaire :
schedule="*/1 * * * *"
Le format de tâche cron Linux est également pris en charge :
Ensuite, vérifiez que l’horaire a été créé :
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kube-system-minute-backup Enabled 2021-08-26 12:37:44 +0300 EEST @every 1m 720h0m0s 32s ago <none>
La sortie ressemble à ceci :
Ensuite, inspectez toutes les sauvegardes après une minute environ :
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
kube-system-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:20 +0300 EEST 29d default <none>
kube-system-minute-backup-20210826093744 Completed 0 0 2021-08-26 12:37:44 +0300 EEST 29d default <none>
La sortie ressemble à ceci :
Vérification de l’état de sauvegarde planifiée
Tout d’abord, vérifiez la ligne Phase d’une des sauvegardes (veuillez remplacer les espaces réservés <> en conséquence). Elle devrait indiquer Terminée.
Restauration de la sauvegarde planifiée
Pour restaurer les sauvegardes d’une minute auparavant, veuillez suivre les mêmes étapes que celles que vous avez apprises dans les étapes précédentes de ce tutoriel. C’est une bonne façon de mettre en pratique et de tester l’expérience que vous avez accumulée jusqu’à présent.
Dans l’étape suivante, vous apprendrez comment supprimer manuellement ou automatiquement des sauvegardes spécifiques que vous avez créées au fil du temps.
Étape 5 – Suppression des sauvegardes
Si vous n’avez pas besoin des sauvegardes plus anciennes, vous pouvez libérer des ressources à la fois sur le cluster Kubernetes et sur le compartiment Velero DO Spaces.
Suppression manuelle d’une sauvegarde
Tout d’abord, choisissez une sauvegarde d’une minute, par exemple, et exécutez la commande suivante (veuillez remplacer les espaces réservés <> en conséquence):
Maintenant, vérifiez qu’il a disparu de la sortie de la commande velero backup get. Il devrait également être supprimé du bucket DO Spaces.
Ensuite, vous allez supprimer plusieurs sauvegardes à la fois en utilisant un sélecteur. La sous-commande velero backup delete fournit un indicateur appelé --selector. Il vous permet de supprimer plusieurs sauvegardes à la fois en fonction des étiquettes Kubernetes. Les mêmes règles s’appliquent que pour les sélecteurs d’étiquettes Kubernetes.
D’abord, listez les sauvegardes disponibles :
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 23d default <none>
backend-minute-backup-20210826094116 Completed 0 0 2021-08-26 12:41:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826094016 Completed 0 0 2021-08-26 12:40:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093816 Completed 0 0 2021-08-26 12:38:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093716 Completed 0 0 2021-08-26 12:37:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093616 Completed 0 0 2021-08-26 12:36:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093509 Completed 0 0 2021-08-26 12:35:09 +0300 EEST 24d default <none>
La sortie ressemble à ceci :
Ensuite, dites que vous voulez supprimer tous les éléments backend-minute-backup-*. Choisissez une sauvegarde dans la liste et inspectez les Labels :
Name: backend-minute-backup-20210826094116
Namespace: velero
Labels: velero.io/schedule-name=backend-minute-backup
velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: backend
Excluded: <none>
...
La sortie ressemble à ceci (remarquez la valeur de l’étiquette velero.io/schedule-name) :
Ensuite, vous pouvez supprimer toutes les sauvegardes qui correspondent à la valeur backend-minute-backup de l’étiquette velero.io/schedule-name :
Enfin, vérifiez que tous les éléments backend-minute-backup-* ont disparu de la sortie de la commande velero backup get, ainsi que du bucket DO Spaces.
Suppression automatique des sauvegardes via TTL
- Lorsque vous créez une sauvegarde, vous pouvez spécifier un TTL (Time To Live), en utilisant le drapeau
--ttl. Si Velero constate qu’une ressource de sauvegarde existante a expiré, il supprime : - La ressource
Backup - Le fichier de sauvegarde du stockage d’objet cloud
storage - Toutes les instantanés de
PersistentVolume
Toutes les Restores associées
Le drapeau TTL permet à l’utilisateur de spécifier la période de rétention de la sauvegarde avec la valeur spécifiée en heures, minutes et secondes sous la forme --ttl 24h0m0s. Si non spécifié, une valeur TTL par défaut de 30 jours sera appliquée.
Tout d’abord, créez la sauvegarde ambassador, en utilisant une valeur TTL de 3 minutes:
Ensuite, inspectez la sauvegarde ambassador:
Name: ambassador-backup-3min-ttl
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
Resources:
Included: *
Excluded: <none>
Cluster-scoped: auto
Label selector: <none>
Storage Location: default
Velero-Native Snapshot PVs: auto
TTL: 3m0s
...
A new folder should be created in the DO Spaces Velero bucket as well, named ambassador-backup-3min-ttl.
La sortie ressemble à ceci (remarquez la section Namespaces -> Included – elle devrait afficher ambassador, et le champ TTL est défini sur 3ms0):
Enfin, après environ trois minutes, la sauvegarde et les ressources associées devraient être automatiquement supprimées. Vous pouvez vérifier que l’objet de sauvegarde a été détruit en utilisant : velero backup describe ambassador-backup-3min-ttl. Cela devrait échouer avec une erreur indiquant que la sauvegarde n’existe plus. Le dossier correspondant ambassador-backup-3min-ttl du bucket Velero DO Spaces sera également supprimé.
Pour aller plus loin, vous pouvez explorer toutes les options de suppression de sauvegarde velero backup delete, via :
Dans ce tutoriel, vous avez appris comment effectuer des sauvegardes ponctuelles ainsi que planifiées, et restaurer tout. Avoir des sauvegardes planifiées en place est très important car cela vous permet de revenir à un instantané précédent si quelque chose se passe mal en cours de route. Vous avez également parcouru un scénario de récupération après sinistre.
- En savoir plus
- Sauvegarde et restauration des données DOKS en utilisant Velero
- Sauvegardes de Kubernetes gérées par DigitalOcean avec SnapShooter
Restaurer des volumes à partir de snapshots dans des clusters Kubernetes