













L’auteur a choisi le Fonds pour les Logiciels Libres et Open Source pour recevoir un don dans le cadre du programme Écrire pour les Dons.
Introduction
La surveillance de base de données est le processus continu de suivi systématique de diverses mesures qui montrent comment la base de données fonctionne. En observant les données de performance, vous pouvez obtenir des informations précieuses et identifier d’éventuels goulots d’étranglement, ainsi que trouver d’autres moyens d’améliorer les performances de la base de données. Ces systèmes mettent souvent en œuvre une alerte qui notifie les administrateurs lorsque les choses tournent mal. Les statistiques recueillies peuvent être utilisées non seulement pour améliorer la configuration et le flux de travail de la base de données, mais aussi ceux des applications clientes.
L’avantage d’utiliser la pile Elastic (ELK stack) pour surveiller votre base de données gérée est son excellent support pour la recherche et la capacité à ingérer de nouvelles données très rapidement. Il n’excellente pas dans la mise à jour des données, mais ce compromis est acceptable à des fins de surveillance et de journalisation, où les données passées sont presque jamais modifiées. Elasticsearch offre un moyen puissant d’interroger les données, que vous pouvez utiliser via Kibana pour mieux comprendre le fonctionnement de la base de données à travers différentes périodes. Cela vous permettra de corréler la charge de la base de données avec des événements réels pour obtenir des informations sur l’utilisation de la base de données.
Dans ce tutoriel, vous importerez les métriques de la base de données, générées par la commande INFO de Redis, dans Elasticsearch via Logstash. Cela implique de configurer Logstash pour exécuter périodiquement la commande, analyser sa sortie et l’envoyer immédiatement après à Elasticsearch pour l’indexation. Les données importées peuvent ensuite être analysées et visualisées dans Kibana. À la fin du tutoriel, vous disposerez d’un système automatisé récupérant les statistiques de Redis pour une analyse ultérieure.
Prérequis
- Un serveur Ubuntu 18.04 avec au moins 8 Go de RAM, des privilèges root et un compte secondaire non root. Vous pouvez configurer cela en suivant ce guide de configuration initiale du serveur. Pour ce tutoriel, l’utilisateur non root est
sammy. - Java 8 installé sur votre serveur. Pour les instructions d’installation, visitez Comment installer Java avec
aptsur Ubuntu 18.04 et suivez les commandes décrites dans la première étape. Vous n’avez pas besoin d’installer le Kit de développement Java (JDK). - Nginx installé sur votre serveur. Pour un guide sur la manière de le faire, consultez le tutoriel Comment installer Nginx sur Ubuntu 18.04.
- Elasticsearch et Kibana installés sur votre serveur. Effectuez les deux premières étapes du tutoriel Comment installer Elasticsearch, Logstash et Kibana (Elastic Stack) sur Ubuntu 18.04.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- Redli installé sur votre serveur selon le tutoriel Comment se connecter à une base de données gérée sur Ubuntu 18.04.
Étape 1 — Installation et Configuration de Logstash
Dans cette section, vous installerez Logstash et le configurerez pour extraire des statistiques de votre cluster de bases de données Redis, puis les analyserez pour les envoyer à Elasticsearch pour l’indexation.
Commencez par installer Logstash avec la commande suivante :
Une fois Logstash installé, activez le service pour qu’il démarre automatiquement au démarrage :
Avant de configurer Logstash pour extraire les statistiques, voyons à quoi ressemblent les données elles-mêmes. Pour vous connecter à votre base de données Redis, rendez-vous dans votre Panneau de Contrôle de Base de Données Gérée, et sous le panneau Détails de Connexion, sélectionnez Flags dans le menu déroulant :
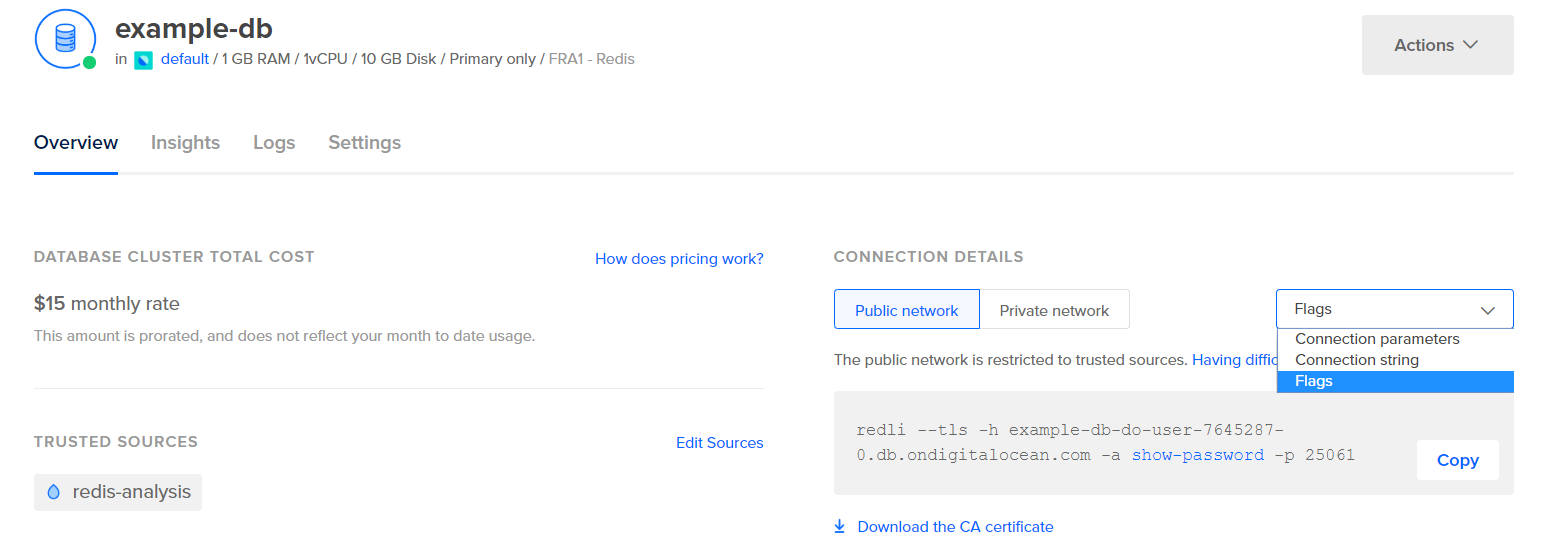
Vous verrez une commande préconfigurée pour le client Redli, que vous utiliserez pour vous connecter à votre base de données. Cliquez sur Copier et exécutez la commande suivante sur votre serveur, en remplaçant redli_flags_command par la commande que vous venez de copier :
Comme la sortie de cette commande est longue, nous expliquerons cela en plusieurs parties.
Dans la sortie de la commande info de Redis, les sections sont marquées avec #, ce qui signifie un commentaire. Les valeurs sont renseignées sous la forme de clé:valeur, ce qui les rend relativement faciles à analyser.
La section Serveur contient des informations techniques sur la construction de Redis, telles que sa version et le commit Git sur lequel elle est basée, tandis que la section Clients fournit le nombre de connexions actuellement ouvertes.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Mémoire confirme la quantité de RAM allouée à Redis, ainsi que la quantité maximale de mémoire qu’il peut utiliser. S’il commence à manquer de mémoire, il libérera des clés en utilisant la stratégie que vous avez spécifiée dans le Panneau de contrôle (indiquée dans le champ maxmemory_policy dans cette sortie).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
Dans la section Persistance, vous pouvez voir la dernière fois que Redis a sauvegardé les clés qu’il stocke sur le disque, et si cela a été réussi. La section Stats fournit des chiffres liés aux connexions client et en cluster, au nombre de fois où la clé demandée a été (ou n’a pas été) trouvée, etc.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
En regardant le rôle sous Réplication, vous saurez si vous êtes connecté à un nœud principal ou à un nœud répliqué. Le reste de la section fournit le nombre de répliques connectées actuellement et la quantité de données que la réplique ne possède pas par rapport au principal. Il peut y avoir des champs supplémentaires si l’instance à laquelle vous êtes connecté est une réplique.
Remarque : Le projet Redis utilise les termes « maître » et « esclave » dans sa documentation et dans diverses commandes. DigitalOcean préfère généralement les termes alternatifs « primaire » et « réplique ». Ce guide utilisera par défaut les termes « primaire » et « réplique » chaque fois que possible, mais notez qu’il existe quelques instances où les termes « maître » et « esclave » sont inévitablement utilisés.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
Sous CPU, vous verrez la quantité de puissance du système (used_cpu_sys) et de l’utilisateur (used_cpu_user) que Redis consomme actuellement. La section Cluster ne contient qu’un seul champ unique, cluster_enabled, qui sert à indiquer que le cluster Redis est en cours d’exécution.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# Erreurs
# Cluster
cluster_enabled:0
# Keyspace
Logstash sera chargé d’exécuter périodiquement la commande info sur votre base de données Redis (similaire à ce que vous venez de faire), d’analyser les résultats et de les envoyer à Elasticsearch. Vous pourrez ensuite y accéder ultérieurement depuis Kibana.
Vous stockerez la configuration pour l’indexation des statistiques Redis dans Elasticsearch dans un fichier nommé redis.conf sous le répertoire /etc/logstash/conf.d, où Logstash stocke les fichiers de configuration. Lorsqu’il est lancé en tant que service, il les exécutera automatiquement en arrière-plan.
Créez redis.conf en utilisant votre éditeur préféré (par exemple, nano) :
Ajoutez les lignes suivantes :
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
N’oubliez pas de remplacer redis_flags_command par la commande indiquée dans le panneau de contrôle que vous avez utilisé précédemment à l’étape.
Vous définissez une entrée, qui est un ensemble de filtres qui seront exécutés sur les données collectées, et une sortie qui enverra les données filtrées à Elasticsearch. L’entrée se compose de la commande exec, qui exécutera une commande sur le serveur périodiquement, après un temps défini intervalle (exprimé en secondes). Il spécifie également un paramètre type qui définit le type de document lorsqu’il est indexé dans Elasticsearch. Le bloc exec transmet un objet contenant deux champs, commande et message string. Le champ commande contiendra la commande qui a été exécutée, et le champ message contiendra sa sortie.
Il y a deux filtres qui s’exécuteront séquentiellement sur les données collectées à partir de l’entrée. Le filtre kv signifie filtre clé-valeur, et est intégré à Logstash. Il est utilisé pour analyser les données sous la forme générale de cléséparateur_de_valeurvaleur et fournit des paramètres pour spécifier ce qui est considéré comme des séparateurs de valeur et de champ. Le séparateur de champ concerne les chaînes qui séparent les données formatées sous la forme générale les unes des autres. Dans le cas de la sortie de la commande Redis INFO, le séparateur de champ (field_split) est une nouvelle ligne, et le séparateur de valeur (value_split) est :. Les lignes qui ne suivent pas la forme définie seront jetées, y compris les commentaires.
Pour configurer le filtre kv, vous passez : au paramètre value_split, et \r\n (signifiant une nouvelle ligne) au paramètre field_split. Vous lui ordonnez également de supprimer les champs command et message de l’objet de données actuel en les passant à remove_field sous forme d’éléments d’un tableau, car ils contiennent des données qui sont maintenant inutiles.
Le filtre kv représente la valeur qu’il a analysée en tant que type chaîne de caractères (texte) par conception. Cela pose un problème car Kibana ne peut pas facilement traiter les types de chaînes de caractères, même s’il s’agit en réalité d’un nombre. Pour résoudre cela, vous utiliserez du code Ruby personnalisé pour convertir les chaînes contenant uniquement des chiffres en nombres, si possible. Le deuxième filtre est un bloc ruby qui fournit un paramètre code acceptant une chaîne contenant le code à exécuter.
event est une variable que Logstash fournit à votre code, et contient les données actuelles dans le pipeline de filtres. Comme mentionné précédemment, les filtres s’exécutent les uns après les autres, ce qui signifie que le filtre Ruby recevra les données analysées du filtre kv. Le code Ruby lui-même convertit l’event en un Hash et parcourt les clés, puis vérifie si la valeur associée à la clé pourrait être représentée comme un entier ou comme un flottant (un nombre avec des décimales). Si c’est le cas, la valeur de la chaîne est remplacée par le nombre analysé. Lorsque la boucle se termine, elle imprime un message (Filtre Ruby terminé) pour signaler la progression.
La sortie envoie les données traitées à Elasticsearch pour l’indexation. Le document résultant sera stocké dans l’index redis_info, défini dans l’entrée et passé en paramètre au bloc de sortie.
Enregistrez et fermez le fichier.
Vous avez installé Logstash en utilisant apt et l’avez configuré pour demander périodiquement des statistiques à Redis, les traiter et les envoyer à votre instance Elasticsearch.
Étape 2 — Test de la configuration de Logstash
Maintenant, vous allez tester la configuration en exécutant Logstash pour vérifier qu’il extraira correctement les données.
Logstash prend en charge l’exécution d’une configuration spécifique en passant son chemin de fichier au paramètre -f. Exécutez la commande suivante pour tester votre nouvelle configuration à partir de la dernière étape:
Cela peut prendre un certain temps pour afficher la sortie, mais vous verrez bientôt quelque chose de similaire à ce qui suit:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Vous verrez le message Filtre Ruby terminé être imprimé à intervalles réguliers (fixés à 10 secondes dans l’étape précédente), ce qui signifie que les statistiques sont envoyées à Elasticsearch.
Vous pouvez quitter Logstash en cliquant sur CTRL + C sur votre clavier. Comme mentionné précédemment, Logstash exécutera automatiquement tous les fichiers de configuration trouvés sous /etc/logstash/conf.d en arrière-plan lorsqu’il est démarré en tant que service. Exécutez la commande suivante pour le démarrer:
Vous avez exécuté Logstash pour vérifier s’il peut se connecter à votre cluster Redis et collecter des données. Ensuite, vous explorerez certaines des données statistiques dans Kibana.
Étape 3 — Exploration des données importées dans Kibana
Dans cette section, vous explorerez et visualiserez les données statistiques décrivant les performances de votre base de données dans Kibana.
Dans votre navigateur web, accédez à votre domaine où vous avez exposé Kibana dans le cadre des prérequis. Vous verrez la page d’accueil par défaut :
Avant d’explorer les données que Logstash envoie à Elasticsearch, vous devrez d’abord ajouter l’index redis_info à Kibana. Pour ce faire, sélectionnez d’abord Explorer par moi-même sur la page d’accueil, puis ouvrez le menu hamburger dans le coin supérieur gauche. Sous Analytics, cliquez sur Découvrir.
Kibana vous demandera ensuite de créer un nouveau motif d’index :
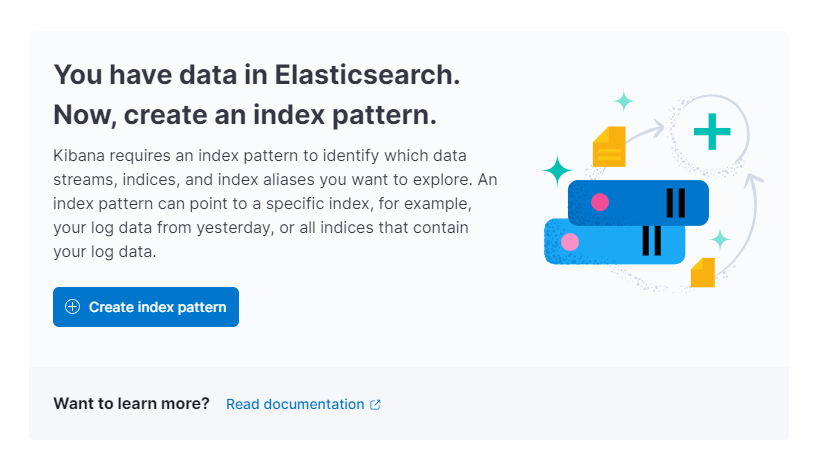
Cliquez sur Créer un motif d’index. Vous verrez un formulaire pour créer un nouveau Motif d’index. Les motifs d’index dans Kibana fournissent un moyen d’extraire des données de plusieurs index Elasticsearch à la fois et peuvent être utilisés pour explorer un seul index.

À droite, Kibana répertorie tous les index disponibles, tels que redis_info que vous avez configuré Logstash à utiliser. Tapez-le dans le champ de texte Nom et sélectionnez @timestamp dans le menu déroulant comme champ Timestamp. Lorsque vous avez terminé, appuyez sur le bouton Créer un motif d’index ci-dessous.
Pour créer et voir des visualisations existantes, ouvrez le menu hamburger. Sous Analytique, sélectionnez Tableau de bord. Lorsqu’il se charge, appuyez sur Créer une visualisation pour commencer à en créer une nouvelle :
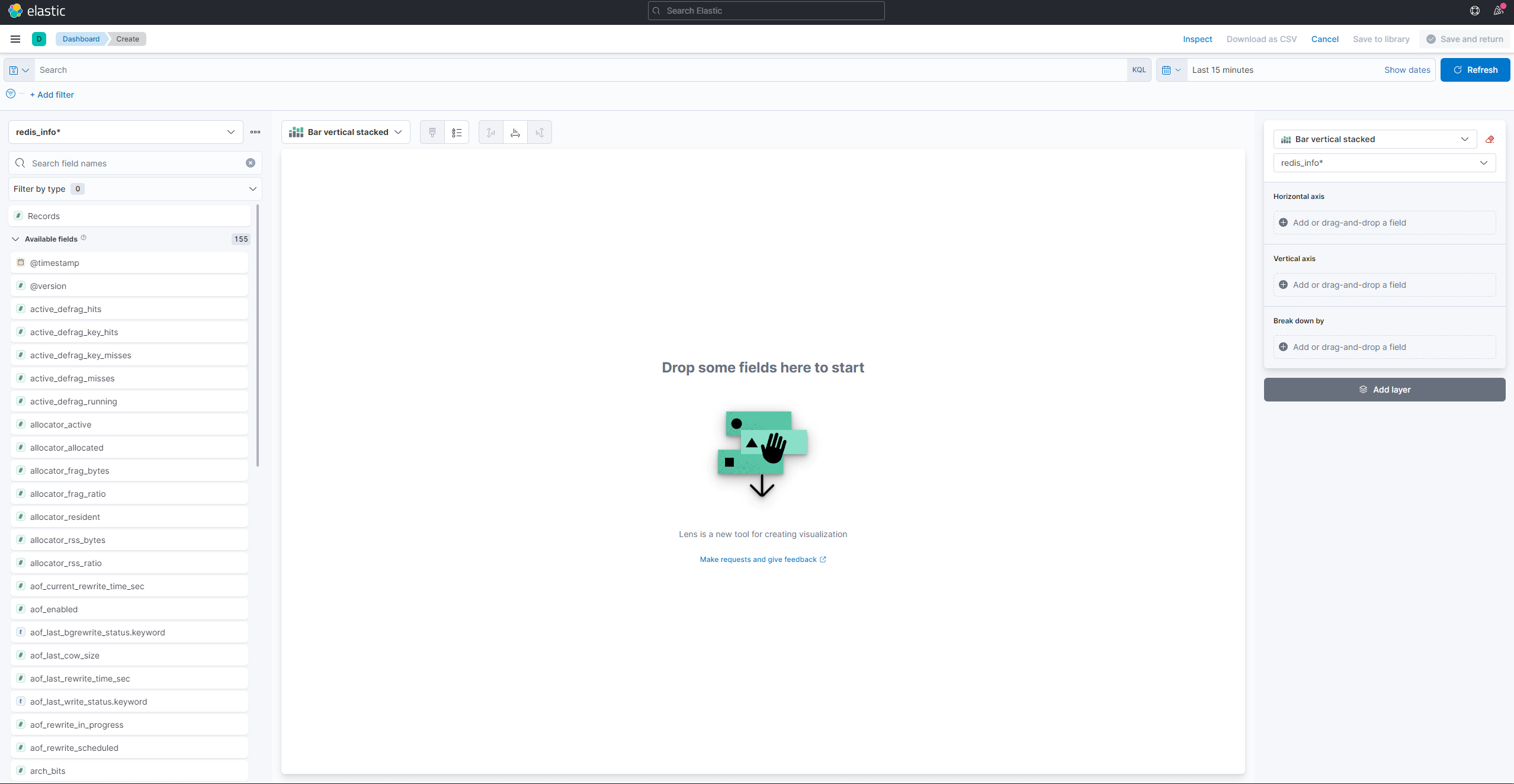
Le panneau latéral gauche fournit une liste de valeurs que Kibana peut utiliser pour dessiner la visualisation, qui sera affichée dans la partie centrale de l’écran. Dans le coin supérieur droit de l’écran se trouve le sélecteur de plage de dates. Si le champ @timestamp est utilisé dans la visualisation, Kibana ne montrera que les données appartenant à l’intervalle de temps spécifié dans le sélecteur de plage.
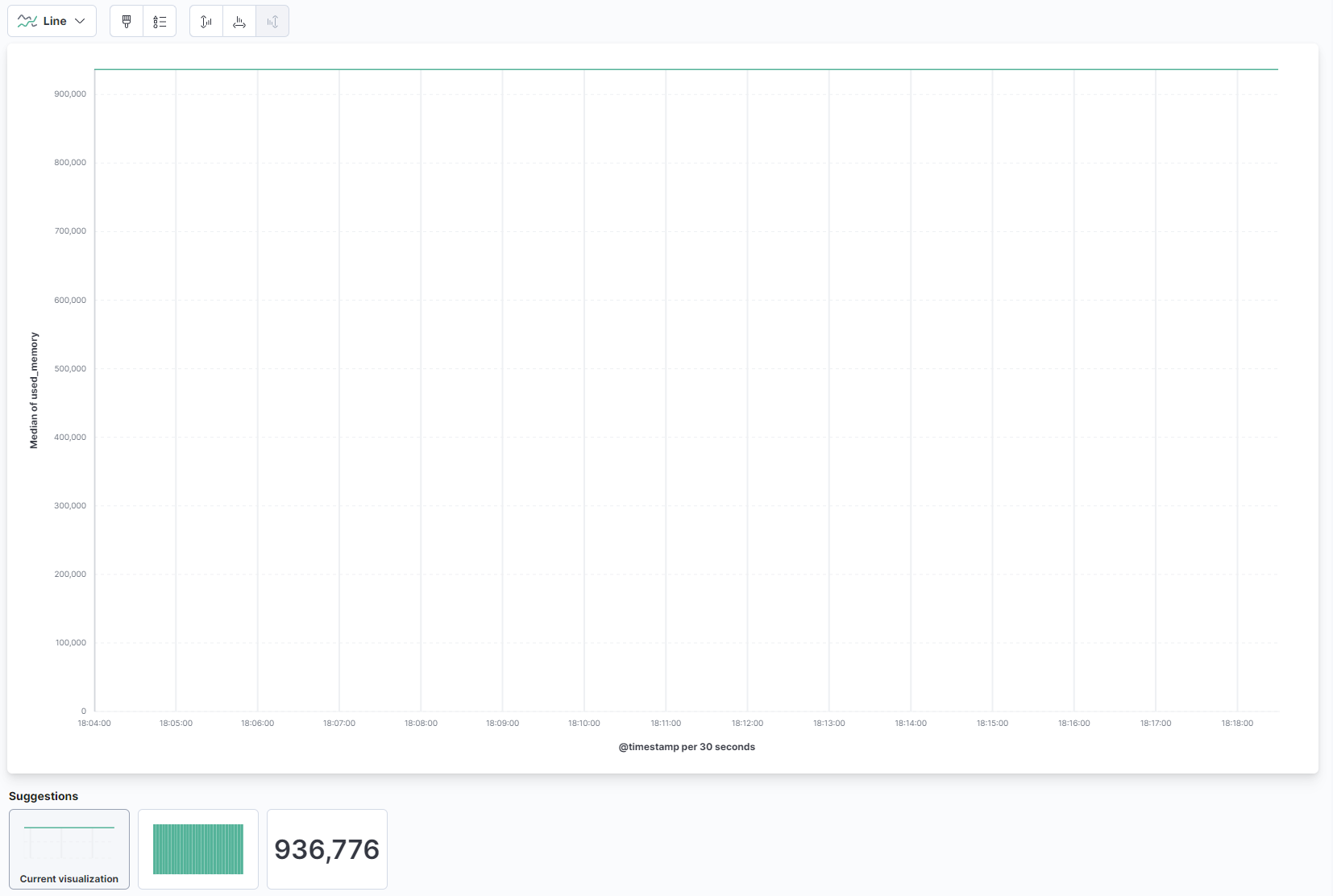
Dans le menu déroulant de la partie principale de la page, sélectionnez Ligne sous la section Ligne et aire. Ensuite, trouvez le champ used_memory dans la liste à gauche et faites-le glisser vers la partie centrale. Vous verrez bientôt une visualisation en ligne de la quantité médiane de mémoire utilisée au fil du temps :
À droite, vous pouvez configurer comment les axes horizontal et vertical sont traités. Là, vous pouvez définir l’axe vertical pour afficher les valeurs moyennes au lieu de la médiane en appuyant sur l’axe affiché :
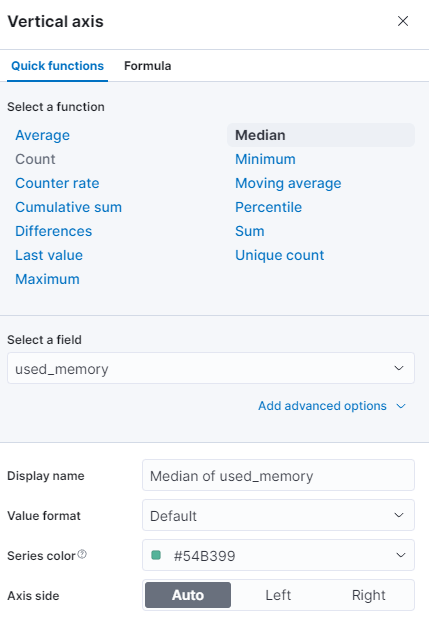
Vous pouvez sélectionner une fonction différente ou fournir la vôtre :
Le graphique sera immédiatement actualisé avec les valeurs mises à jour.
À cette étape, vous avez visualisé l’utilisation de la mémoire de votre base de données Redis gérée à l’aide de Kibana. Cela vous permettra de mieux comprendre comment votre base de données est utilisée, ce qui vous aidera à optimiser les applications clientes, ainsi que votre base de données elle-même.
Conclusion
Vous avez maintenant installé la pile Elastic sur votre serveur et configuré pour extraire régulièrement des données statistiques de votre base de données Redis gérée. Vous pouvez analyser et visualiser les données à l’aide de Kibana ou d’un autre logiciel approprié, ce qui vous aidera à recueillir des informations précieuses et des corrélations réelles sur les performances de votre base de données.
Pour plus d’informations sur ce que vous pouvez faire avec votre base de données Redis gérée, consultez la documentation du produit. Si vous souhaitez présenter les statistiques de la base de données à l’aide d’un autre type de visualisation, consultez la documentation de Kibana pour plus d’instructions.