













L’avènement du système de fichiers distribués Apache Hadoop (HDFS) a révolutionné le stockage, le traitement et l’analyse des données pour les entreprises, accélérant la croissance des big data et apportant des changements transformateurs à l’industrie.
Initialement, Hadoop intégrait le stockage et le calcul, mais l’émergence du cloud computing a conduit à la séparation de ces composants. Le stockage d’objets est apparu comme une alternative à HDFS mais présentait des limitations. Pour compléter ces limitations, JuiceFS, un système de fichiers distribués open-source de haute performance, offre des solutions rentables pour les scénarios intensifs en données comme le calcul, l’analyse et la formation. La décision d’adopter la séparation stockage-calcul dépend de facteurs tels que la scalabilité, la performance, le coût et la compatibilité.
Dans cet article, nous allons passer en revue l’architecture Hadoop, discuter de l’importance et de la faisabilité de la découplage stockage-calcul, et explorer les solutions disponibles sur le marché, en mettant en évidence leurs avantages et inconvénients respectifs. Notre objectif est de fournir des informations et des idées aux entreprises en cours de transformation architecturale de la séparation stockage-calcul.
Caractéristiques de conception de l’architecture Hadoop
Hadoop en tant que cadre tout-en-un
En 2006, Hadoop a été lancé comme un cadre tout-en-un composé de trois éléments:
- MapReduce pour le calcul
- YARN pour la planification des ressources
- HDFS pour le stockage de fichiers distribués
 Core components of Hadoop
Core components of HadoopComposants de calcul divers
Parmi ces trois composants, la couche de calcul a connu un développement rapide. Au départ, il n’y avait que MapReduce, mais l’industrie a rapidement assisté à l’émergence de divers frameworks comme Tez et Spark pour le calcul, Hive pour le data warehousing, et des moteurs de requête comme Presto et Impala. En conjonction avec ces composants, il existe de nombreux outils de transfert de données comme Sqoop.

HDFS Dominé le Système de Stockage
Sur environ dix ans, HDFS, le système de fichiers distribué, a continué à dominer le système de stockage. Il était le choix par défaut pour presque tous les composants de calcul. Tous les composants mentionnés ci-dessus dans l’écosystème big data ont été conçus pour l’API HDFS. Certains composants tirent profondément parti des capacités spécifiques d’HDFS. Par exemple:
- HBase utilise les capacités d’écriture à faible latence d’HDFS pour leurs journaux d’amorçage.
- MapReduce et Spark ont fourni des fonctionnalités de localité des données.
Les choix de conception de ces composants big data, basés sur l’API HDFS, ont soulevé des défis potentiels pour déployer des plateformes de données sur le cloud.
Architecture Couplée Stockage-Calcul
Le diagramme suivant présente une partie de l’architecture simplifiée d’HDFS, qui couple le calcul avec le stockage.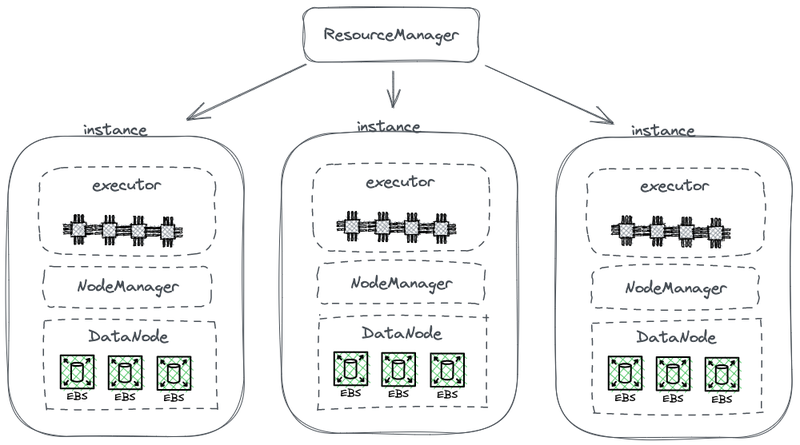
Architecture Hadoop couplée stockage-calcul
Dans ce diagramme, chaque nœud sert d’HDFS DataNode pour stocker des données. De plus, YARN déploie un processus Node Manager sur chaque nœud. Cela permet à YARN de reconnaître le nœud comme faisant partie de ses ressources gérées pour les tâches de calcul. Cette architecture permet au stockage et au calcul de coexister sur la même machine, et les données peuvent être lues à partir du disque pendant le calcul.
Pourquoi Hadoop Couplé Stockage et Calcul
Hadoop a couplé le stockage et le calcul en raison des limitations de la communication réseau et du matériel lors de sa phase de conception.
En 2006, le cloud computing était encore à ses débuts, et Amazon venait de lancer son premier service. Dans les centres de données, les cartes réseau prévalentes fonctionnaient principalement à 100 Mbps. Les disques de données utilisés pour les charges de travail big data atteignaient un débit d’environ 50 MB/s, soit 400 Mbps en termes de bande passante réseau.
Considérant un nœud avec huit disques fonctionnant à pleine capacité, plusieurs gigabits par seconde de bande passante réseau étaient nécessaires pour une transmission de données efficace. Malheureusement, la capacité maximale des cartes réseau était limitée à 1 Gbps. Par conséquent, la bande passante réseau par nœud était insuffisante pour utiliser pleinement les capacités de tous les disques dans le nœud. En conséquence, si les tâches de calcul étaient à un bout du réseau et que les données se trouvaient sur des nœuds de données à l’autre bout, la bande passante réseau était un goulot d’étranglement significatif.
Pourquoi le découplage stockage-calcul est nécessaire
De 2006 à environ 2016, les entreprises ont été confrontées aux problèmes suivants:
- La demande en puissance de calcul et en stockage dans les applications était déséquilibrée, et leurs taux de croissance différaient. Alors que les données des entreprises augmentaient rapidement, la nécessité de puissance de calcul n’augmentait pas autant. Ces tâches, développées par des humains, ne se multipliaient pas exponentiellement en peu de temps. Cependant, les données générées à partir de ces tâches s’accumulaient rapidement, possiblement de manière exponentielle. De plus, certaines données pourraient ne pas être immédiatement utiles à l’entreprise, mais elles seraient précieuses à l’avenir. Par conséquent, les entreprises ont stocké les données de manière exhaustive pour explorer leur potentiel de valeur.
- Pendant l’échelle, les entreprises ont dû élargir à la fois le calcul et le stockage simultanément, ce qui a souvent conduit à des ressources informatiques gaspillées. La topologie matérielle de l’architecture de stockage-calcul couplée a affecté l’expansion de capacité. Lorsque la capacité de stockage était insuffisante, nous devions non seulement ajouter des machines, mais également mettre à niveau les CPU et la mémoire, car les nœuds de données dans l’architecture couplée étaient responsables du calcul. Par conséquent, les machines étaient généralement équipées d’une puissance de calcul et d’une configuration de stockage bien équilibrées, offrant une capacité de stockage suffisante avec une puissance de calcul comparable. Cependant, la demande réelle en puissance de calcul n’a pas augmenté comme prévu. En conséquence, l’augmentation de la puissance de calcul a entraîné un grand gaspillage pour les entreprises.
- Équilibrer le calcul et le stockage et sélectionner des machines appropriées est devenu difficile. L’utilisation des ressources de l’ensemble du cluster en termes de stockage et d’E/S pourrait être très déséquilibrée, et ce déséquilibre s’aggravait à mesure que le cluster devenait plus grand. De plus, l’achat de machines appropriées était difficile, car les machines devaient trouver un équilibre entre les exigences de calcul et de stockage.
- Comme les données pouvaient être distribuées de manière inégale, il était difficile d’effectuer un planification efficace des tâches de calcul sur les instances où se trouvaient les données. La stratégie de planification de la localité des données peut ne pas résoudre efficacement les scénarios du monde réel en raison de la possibilité de distribution inégale des données. Par exemple, certains nœuds pourraient devenir des points chauds locaux, nécessitant plus de puissance de calcul. En conséquence, même si les tâches sur la plateforme big data étaient planifiées sur ces nœuds chauds, les performances E/S pourraient encore devenir un facteur limitant.
Pourquoi découpler le stockage et le calcul est réalisable
La possibilité de séparer le stockage et le calcul a été rendue possible grâce aux avancées dans le matériel et le logiciel entre 2006 et 2016. Ces avancées incluent:
Cartes réseau
L’adoption de cartes réseau 10 Gb est devenue généralisée, avec une disponibilité croissante de capacités plus élevées telles que 20 Gb, 40 Gb, et même 50 Gb dans les centres de données et les environnements cloud. Dans les scénarios d’IA, des cartes réseau de capacité 100 GB sont également utilisées. Cela représente une augmentation significative de la bande passante réseau de plus de 100 fois.
Disques
De nombreuses entreprises dépendent encore de solutions basées sur des disques pour le stockage dans de grands clusters de données. Le débit des disques a doublé, passant de 50 Mo/s à 100 Mo/s. Une instance équipée d’une carte réseau de 10 Go peut supporter un débit maximal d’environ 12 disques. Ceci est suffisant pour la plupart des entreprises, et donc, la transmission réseau n’est plus un goulot d’étranglement.
Logiciels
L’utilisation d’algorithmes de compression efficaces tels que Snappy, LZ4, et Zstandard et de formats de stockage en colonnes comme Avro, Parquet, et Orc a encore atténué la pression I/O. Le goulot d’étranglement dans le traitement des big data a évolué de l’I/O vers les performances du CPU.
Comment mettre en œuvre la séparation stockage-calcul
Première tentative : Déploiement indépendant de HDFS dans le Cloud
Déploiement indépendant de HDFS
Depuis 2013, des tentatives ont été faites dans l’industrie pour séparer le stockage et le calcul. La première approche est assez simple, impliquant le déploiement indépendant de HDFS sans l’intégrer aux travailleurs de calcul. Cette solution n’a introduit aucun nouveau composant dans l’écosystème Hadoop.
Comme le montre le diagramme ci-dessous, le NodeManager n’était plus déployé sur les DataNodes. Cela indiquait que les tâches de calcul n’étaient plus envoyées aux DataNodes. Le stockage est devenu un cluster distinct, et les données nécessaires aux calculs étaient transmises sur le réseau, soutenues par des cartes réseau 10 Gb end-to-end. (Notez que les lignes de transmission réseau ne sont pas marquées sur le diagramme.)

Bien que cette solution ait abandonné la localité des données, le plus ingénieux design de HDFS, la vitesse accrue de la communication réseau a considérablement facilité la configuration du cluster. Cela a été démontré par des expériences menées par Davies, le co-fondateur de Juicedata, et ses coéquipiers pendant leur séjour chez Facebook en 2013. Les résultats ont confirmé la faisabilité du déploiement et de la gestion indépendants des nœuds de calcul.
Cependant, cette tentative n’a pas été développée davantage. La principale raison est les défis posés par le déploiement de HDFS dans le cloud.
Défis du Déploiement de HDFS dans le Cloud
Le déploiement de HDFS dans le cloud rencontre les problèmes suivants:
- Le mécanisme de multi-réplication de HDFS peut augmenter le coût des entreprises dans le cloud : Auparavant, les entreprises utilisaient des disques nus pour construire un système HDFS dans leurs centres de données. Pour atténuer le risque de dommages aux disques, HDFS a mis en place un mécanisme de multi-réplication pour garantir la sécurité et la disponibilité des données. Cependant, lors du transfert de données vers le cloud, les fournisseurs de cloud proposent déjà des disques cloud protégés par le mécanisme de multi-réplication. Par conséquent, les entreprises doivent répliquer les données trois fois dans le cloud, ce qui entraîne une augmentation significative des coûts.
- Options limitées pour le déploiement sur disques nus : Bien que les fournisseurs de cloud offrent certains types de machines avec disques nus, les options disponibles sont limitées. Par exemple, sur 100 types de machines virtuelles disponibles dans le cloud, seuls 5 à 10 types de machines supportent les disques nus. Cette sélection limitée peut ne pas répondre aux exigences spécifiques des clusters d’entreprise.
- Incapacité à exploiter les avantages uniques du cloud : Le déploiement de HDFS dans le cloud nécessite la création manuelle de machines, le déploiement, la maintenance, la surveillance et les opérations sans la commodité de l’échelle élastique et du modèle pay-as-you-go. Ce sont les avantages clés du calcul en nuage. Par conséquent, déployer HDFS dans le cloud tout en réalisant la séparation entre stockage et calcul n’est pas facile.
Limitations de HDFS
HDFS présente lui-même ces limitations :
- Les NameNodes ont une scalabilité limitée : Les NameNodes dans HDFS ne peuvent se développer que verticalement et ne peuvent pas se développer de manière distribuée. Cette limitation impose une contrainte sur le nombre de fichiers pouvant être gérés dans un seul cluster HDFS.
- Stocker plus de 500 millions de fichiers entraîne des coûts d’exploitation élevés :D’après notre expérience, il est généralement facile d’exploiter et de maintenir HDFS avec moins de 300 millions de fichiers. Lorsque le nombre de fichiers dépasse 500 millions, il est nécessaire d’implémenter le mécanisme HDFS Federation. Cependant, cela entraîne des coûts d’exploitation et de gestion importants.
- Une utilisation élevée des ressources et une charge lourde sur le NameNode affectent la disponibilité du cluster HDFS :Lorsqu’un NameNode consomme trop de ressources avec une charge élevée, une collecte complète des déchets (GC) peut être déclenchée. Cela affecte la disponibilité de l’ensemble du cluster HDFS. Le système de stockage peut connaître une interruption de service, le rendant incapable de lire des données, et il n’y a aucun moyen d’intervenir dans le processus GC. La durée de la gèle du système ne peut pas être déterminée. Cela a été un problème persistant dans les clusters HDFS à forte charge.
Cloud Public + Stockage d’objets
Avec l’avancement du cloud computing, les entreprises ont désormais la possibilité d’utiliser le stockage d’objets comme alternative à HDFS. Le stockage d’objets est spécifiquement conçu pour stocker des données non structurées à grande échelle, offrant une architecture pour un chargement et téléchargement de données faciles. Il fournit une capacité de stockage hautement évolutive, garantissant une efficacité des coûts.
Avantages du stockage d’objets en remplacement de HDFS
Le stockage d’objets a gagné en popularité, démarré par AWS et adopté par la suite par d’autres fournisseurs de cloud en remplacement de HDFS. Les avantages suivants sont notables:
- Orienté service et prêt à l’emploi : Le stockage d’objets nécessite aucune mise en œuvre, surveillance ou tâches de maintenance, offrant une expérience pratique et conviviale.
- Mise à l’échelle élastique et paiement à l’utilisation : Les entreprises paient pour le stockage d’objets en fonction de leur utilisation réelle, éliminant ainsi le besoin de planification de capacité. Elles peuvent créer un bucket de stockage d’objets et stocker autant de données que nécessaire sans se soucier des limitations de capacité de stockage.
Inconvénients du stockage d’objets
Cependant, lors de l’utilisation du stockage d’objets pour soutenir des systèmes de données complexes comme Hadoop, les défis suivants se posent :
Inconvénient n°1 : Faible performance de l’affichage des fichiers
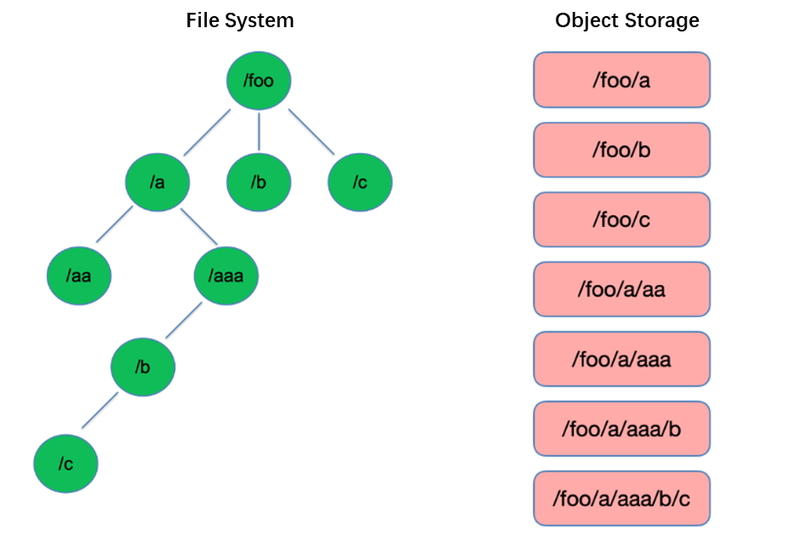
L’affichage est l’une des opérations les plus basiques dans le système de fichiers. Il est léger et rapide dans des structures arborescentes comme HDFS.
En revanche, le stockage d’objets adopte une structure plate et nécessite l’indexation avec des clés (identificateurs uniques) pour stocker et récupérer des milliers voire des milliards d’objets. En conséquence, lors de l’exécution d’une opération de liste, le stockage d’objets ne peut rechercher que dans cet index, ce qui entraîne une performance nettement inférieure à celle des structures arborescentes.
Inconvénient n°2 : Absence de capacité de renommage atomique, affectant la performance et la stabilité des tâches
Dans les modèles de calcul de type extraction, transformation, chargement (ETL), chaque sous-tâche écrit ses résultats dans un répertoire temporaire. Lorsque l’ensemble de la tâche est terminé, le répertoire temporaire peut être renommé en nom de répertoire final.
Ces opérations de renommage sont atomiques et rapides dans des systèmes de fichiers comme HDFS, et elles garantissent les transactions. Cependant, comme le stockage d’objets n’a pas de structure de répertoire native, gérer une opération de renommage est un processus simulé qui implique une copie considérable de données internes. Ce processus peut être chronophage et ne fournit pas de garanties transactionnelles.
Lorsque les utilisateurs utilisent le stockage d’objets, ils utilisent couramment le format de chemin d’accès à partir des systèmes de fichiers traditionnels comme clé pour les objets, tel que « /order/2-22/8/10/detail. » Lors d’une opération de renommage, il devient nécessaire de rechercher tous les objets dont les clés contiennent le nom du répertoire et de copier tous les objets en utilisant le nouveau nom de répertoire comme clé. Ce processus implique la copie de données, ce qui entraîne une performance significativement inférieure par rapport aux systèmes de fichiers, potentiellement plus lente d’un ou deux ordres de grandeur.
De plus, en l’absence de garanties transactionnelles, il existe un risque d’échec pendant le processus, ce qui peut aboutir à des données incorrectes. Ces différences apparemment mineures ont des implications pour la performance et la stabilité de l’ensemble du pipeline de tâches.
Inconvénient n°3 : Le mécanisme de cohérence éventuelle affecte la correction des données et la stabilité des tâches
Par exemple, lorsque plusieurs clients créent des fichiers simultanément sous un chemin d’accès, la liste des fichiers obtenue via l’API List peut ne pas inclure immédiatement tous les fichiers créés. Il faut du temps pour que les systèmes internes du stockage d’objets atteignent la cohérence des données. Cette façon d’accéder aux données est couramment utilisée dans le traitement des données ETL, et la cohérence éventuelle peut impacter la correction des données et la stabilité des tâches.
Pour résoudre le problème de l’incapacité du stockage d’objets à maintenir une forte cohérence des données, AWS a lancé un produit appelé EMRFS. Son approche consiste à utiliser une base de données DynamoDB supplémentaire. Par exemple, lorsque Spark écrit un fichier, il écrit également simultanément une copie de l’indexation du fichier dans DynamoDB. Un mécanisme est ensuite mis en place pour appeler en continu l’API List du stockage d’objets et comparer les résultats obtenus avec les résultats stockés dans la base de données jusqu’à ce qu’ils soient identiques, moment auquel les résultats sont renvoyés. Cependant, la stabilité de ce mécanisme n’est pas suffisante car elle peut être influencée par la charge de la région où se trouve le stockage d’objets, ce qui entraîne des performances variables. Ainsi, ce n’est pas une solution idéale.
Inconvénient #4 : Compatibilité limitée avec les composants Hadoop
HDFS était le choix de stockage principal aux premiers stades de l’écosystème Hadoop, et divers composants ont été développés sur la base de l’API HDFS. L’introduction du stockage d’objets a entraîné des changements dans la structure de stockage des données et les API.
Les fournisseurs de cloud doivent modifier les connecteurs entre les composants et le stockage d’objets cloud, ainsi que patcher les composants de niveau supérieur pour garantir la compatibilité. Cette tâche impose une charge de travail considérable sur les fournisseurs de cloud public.
En conséquence, le nombre de composants de calcul pris en charge dans les plateformes de big data proposées par les fournisseurs de cloud public est limité, généralement incluant seulement quelques versions de Spark, Hive et Presto. Cette limitation pose des défis pour le déplacement des plateformes de big data vers le cloud ou pour les utilisateurs ayant des exigences spécifiques pour leur propre distribution et composants.
Pour tirer parti des performances puissantes de l’objet de stockage tout en préservant la fiabilité des systèmes de fichiers, les entreprises peuvent utiliser le stockage d’objets + JuiceFS.
Stockage d’objets + JuiceFS
Lorsque les utilisateurs souhaitent effectuer des calculs complexes, des analyses et des formations sur le stockage d’objets, le stockage d’objets seul peut ne pas suffire à répondre aux exigences des entreprises. C’est une motivation clé derrière le développement de Juicedata de JuiceFS, qui vise à compléter les limitations du stockage d’objets.
JuiceFS est un système de fichiers distribué à haute performance, open-source, conçu pour le cloud. Avec le stockage d’objets, JuiceFS fournit des solutions rentables pour les scénarios intensifs en données tels que le calcul, l’analyse et la formation.
Fonctionnement de JuiceFS + Stockage d’objets
Le diagramme ci-dessous montre le déploiement de JuiceFS dans un cluster Hadoop.
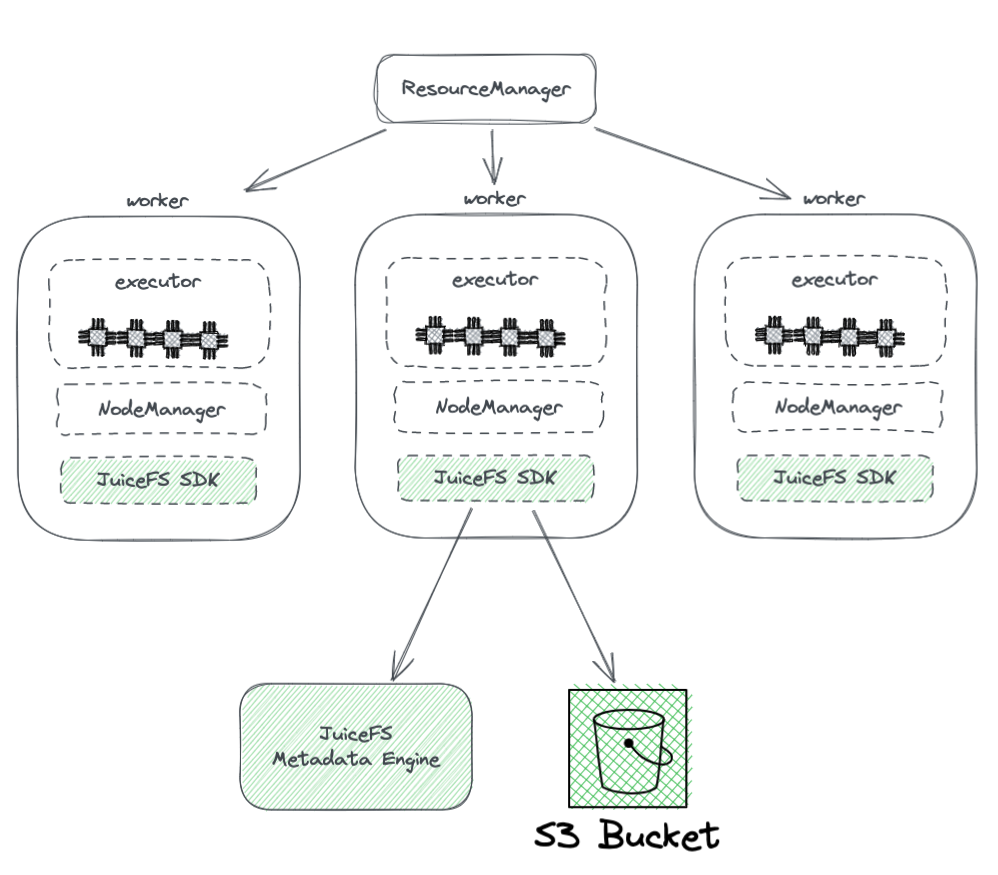
À partir du diagramme, nous pouvons voir ce qui suit:
- Tous les nœuds de travail gérés par YARN portent un SDK Hadoop JuiceFS, qui peut garantir la pleine compatibilité avec HDFS.
- L’SDK accède à deux composants :
-
Moteur de métadonnées JuiceFS : Le moteur de métadonnées joue le rôle de contrepartie au NameNode d’HDFS. Il stocke les informations métadonnées de l’ensemble du système de fichiers, y compris les comptes de répertoires, les noms de fichiers, les autorisations et les horodatages, et résout les défis de scalabilité et de GC auxquels est confronté le NameNode d’HDFS.
-
Bucket S3 : Les données sont stockées dans le bucket S3, qui peut être considéré comme équivalent au DataNode d’HDFS. Il peut être utilisé comme un grand nombre de disques, gérant les tâches de stockage et de réplication des données.
-
-
JuiceFS se compose de trois composants :
- JuiceFS Hadoop SDK
- Moteur de métadonnées
- Bucket S3
Avantages de Juicefs par rapport à l’utilisation directe de stockage d’objets
JuiceFS offre plusieurs avantages par rapport à l’utilisation directe de stockage d’objets :
- Compatibilité complète avec HDFS : Cela est réalisé grâce à la conception initiale de JuiceFS pour supporter pleinement POSIX. L’API POSIX couvre une plus grande complexité et une plus grande couverture que HDFS.
- Capacité à utiliser avec HDFS et stockage d’objets existants : Grâce à la conception du système Hadoop, JuiceFS peut être utilisé aux côtés des systèmes de stockage d’objets et HDFS existants sans avoir besoin d’une remise complète. Dans un cluster Hadoop, plusieurs systèmes de fichiers peuvent être configurés, permettant à JuiceFS et HDFS de coexister et de collaborer. Cette architecture élimine la nécessité d’une remise complète des clusters HDFS existants, ce qui impliquerait un effort et des risques importants. Les utilisateurs peuvent intégrer progressivement JuiceFS en fonction de leurs besoins d’application et de la situation du cluster.
- Performance puissante des métadonnées : JuiceFS sépare le moteur de métadonnées de S3 et ne dépend plus des performances de métadonnées S3. Cela garantit une performance optimale des métadonnées. Lors de l’utilisation de JuiceFS, les interactions avec le stockage d’objets sous-jacent sont simplifiées en opérations de base telles que Get, Put et Delete. Cette architecture surmonte les limitations de performance des métadonnées de stockage d’objets et élimine les problèmes liés à la cohérence éventuelle.
- Prise en charge de la Rename atomique: JuiceFS prend en charge les opérations Rename atomiques en raison de son moteur de métadonnées indépendant. Le cache améliore la performance d’accès des données chaudes et fournit la fonctionnalité de localité des données : Avec le cache, les données chaudes n’ont plus besoin d’être récupérées à partir du stockage d’objets via le réseau à chaque fois. De plus, JuiceFS met en œuvre l’API de localité des données spécifique à HDFS, de sorte que tous les composants de niveau supérieur qui prennent en charge la localité des données peuvent retrouver la sensibilité à l’affinité des données. Cela permet à YARN de prioriser l’ordonnancement des tâches sur les nœuds où le cache a été établi, ce qui entraîne une performance globale comparable à celle de HDFS avec stockage et calcul couplés.
- JuiceFS est compatible avec POSIX, ce qui facilite son intégration avec des applications liées à l’apprentissage machine et aux IA.
Conclusion
Avec l’évolution des exigences des entreprises et les avancées technologiques, l’architecture du stockage et du calcul a connu des changements, passant de la liaison à la séparation.
Il existe diverses approches pour réaliser la séparation du stockage et du calcul, chacune ayant ses propres avantages et inconvénients. Ces options vont de la mise en place de HDFS dans le cloud à l’utilisation de solutions de cloud public compatibles avec Hadoop et même à l’adoption de solutions comme le stockage d’objets + JuiceFS, qui conviennent aux calculs et au stockage complexes de big data dans le cloud.
Pour les entreprises, il n’y a pas de solution miracle, et l’essentiel réside dans le choix de l’architecture en fonction de leurs besoins spécifiques. Cependant, quelle que soit la décision, la simplicité reste toujours une option sûre.
À propos de l’Auteur
Rui Su, partenaire de Juicedata, a été membre fondateur impliqué dans le développement complet du produit JuiceFS, du marché et de la communauté open source depuis 2017. Avec 16 ans d’expérience dans l’industrie, il a occupé des postes tels que R&D, responsable produit et fondateur dans des secteurs tels que les logiciels, Internet et les organisations non gouvernementales.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora