













Le partitionnement de base de données, ou « sharding », est le processus de division des données en morceaux plus petits appelés « fragments ». Sharding est généralement introduit lorsqu’il y a besoin de mettre à l’échelle les écritures. Au cours de la durée de vie d’une application réussie, le serveur de base de données atteindra le nombre maximum d’écritures qu’il peut effectuer soit au niveau de la gestion des processus, soit en termes de capacité. Couper les données en plusieurs fragments – chacun sur son propre serveur de base de données – réduit la pression sur chaque nœud individuel, augmentant efficacement la capacité d’écriture de la base de données dans son ensemble. C’est ce qu’est le sharding de base de données.
SQL distribué est la nouvelle façon de mettre à l’échelle les bases de données relationnelles avec une stratégie similaire au sharding qui est entièrement automatisée et transparente pour les applications. Les bases de données SQL distribuées sont conçues pour se développer presque de manière linéaire. Dans cet article, vous apprendrez les bases du SQL distribué et comment commencer.
Inconvénients du Sharding de Base de Données
Le sharding introduit un certain nombre de défis:
- Partitionnement des données: Décider comment partitionner les données sur plusieurs fragments peut être un défi, car cela nécessite de trouver un équilibre entre la proximité des données et la distribution équitable des données pour éviter les points chauds.
- Gestion des défaillances: Si un nœud clé tombe en panne et qu’il n’y a pas suffisamment de fragments pour supporter la charge, comment récupérer les données sur un nouveau nœud sans temps d’arrêt?
- Complexité de la requête : Le code de l’application est lié à la logique de fragmentation des données et les requêtes qui nécessitent des données provenant de plusieurs nœuds doivent être rejointes.
- Consistance des données : Assurer la consistance des données à travers plusieurs fragments peut être un défi, car cela nécessite de coordonner les mises à jour des données à travers les fragments. Cela peut être particulièrement difficile lorsque des mises à jour sont effectuées simultanément, car il peut être nécessaire de résoudre les conflits entre différentes écritures.
- Évolutivité élastique : En cas d’augmentation du volume de données ou du nombre de requêtes, il peut être nécessaire d’ajouter des fragments supplémentaires à la base de données. Ce processus peut être complexe avec un temps d’arrêt inévitable, nécessitant des processus manuels pour répartir équitablement les données sur tous les fragments.
Certains de ces inconvénients peuvent être atténués en adoptant une persistance polyglotte (utiliser différentes bases de données pour différentes charges de travail), des moteurs de stockage de base de données avec des capacités de fragmentation natives, ou des proxies de base de données. Cependant, bien que cela aide à surmonter certains des défis de la fragmentation de la base de données, ces outils ont des limitations et introduisent une complexité qui nécessite une gestion constante.
Qu’est-ce que SQL distribué ?
Distributed SQL fait référence à une nouvelle génération de bases de données relationnelles. En termes simples, une base de données SQL distribuée est une base de données relationnelle dotée de sharding transparent qui apparaît comme une seule base de données logique aux applications. Les bases de données SQL distribuées sont mises en œuvre dans un architecture shared-nothing et un moteur de stockage qui évolue à la fois les lectures et les écritures tout en maintenant une véritable conformité ACID et une haute disponibilité. Les bases de données SQL distribuées possèdent les fonctionnalités de scalabilité des bases de données NoSQL—qui ont gagné en popularité dans les années 2000—sans sacrifier la cohérence. Elles conservent les avantages des bases de données relationnelles et ajoutent une compatibilité avec le cloud et une résilience multi-région.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
Comment fonctionne le Distributed SQL?
Pour comprendre comment fonctionne le SQL distribué, prenons le cas de MariaDB Xpand—une base de données SQL distribuée compatible avec la base de données open-source MariaDB. Xpand opère en fractionnant les données et les index parmi les nœuds et en effectuant automatiquement des tâches telles que le rééquilibrage des données et l’exécution de requêtes distribuées. Les requêtes sont exécutées en parallèle pour minimiser le retard. Les données sont automatiquement répliquées pour s’assurer qu’il n’y a pas de point de défaillance unique. Lorsqu’un nœud tombe en panne, Xpand rééquilibre les données parmi les nœuds survivants. La même chose se produit lorsqu’un nouveau nœud est ajouté. Un composant appelé rééquilibreur assure qu’il n’y a pas de points chauds—un défi avec le fractionnement de base de données manuel—qui se produit lorsqu’un nœud doit traiter de manière inégale trop de transactions par rapport à d’autres nœuds qui peuvent rester inactifs parfois.
Étudions un exemple. Supposons que nous ayons une instance de base de données avec some_table et un certain nombre de lignes:
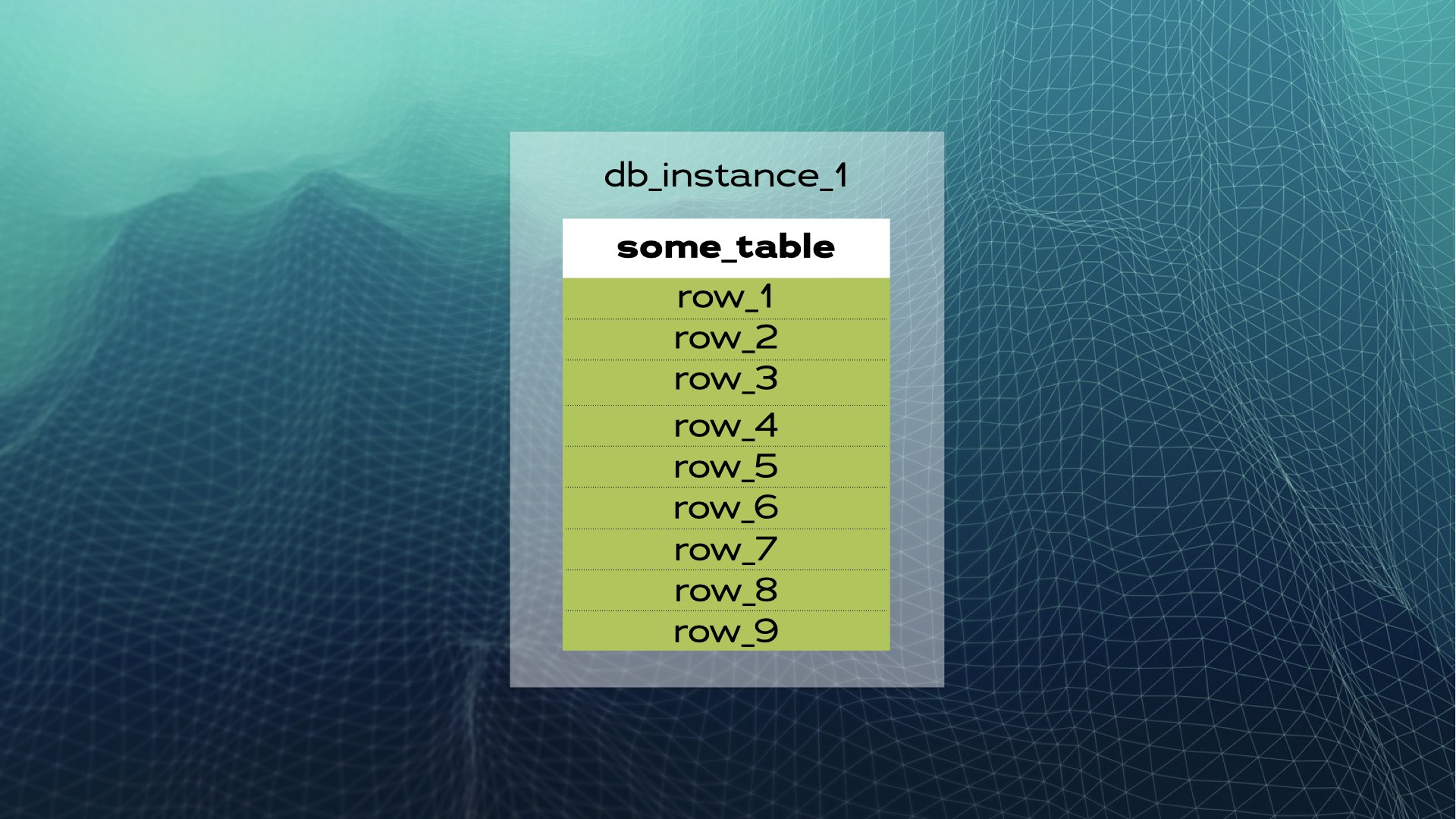
Nous pouvons diviser les données en trois morceaux (fragments):

Et ensuite déplacer chaque morceau de données vers une instance de base de données distincte:
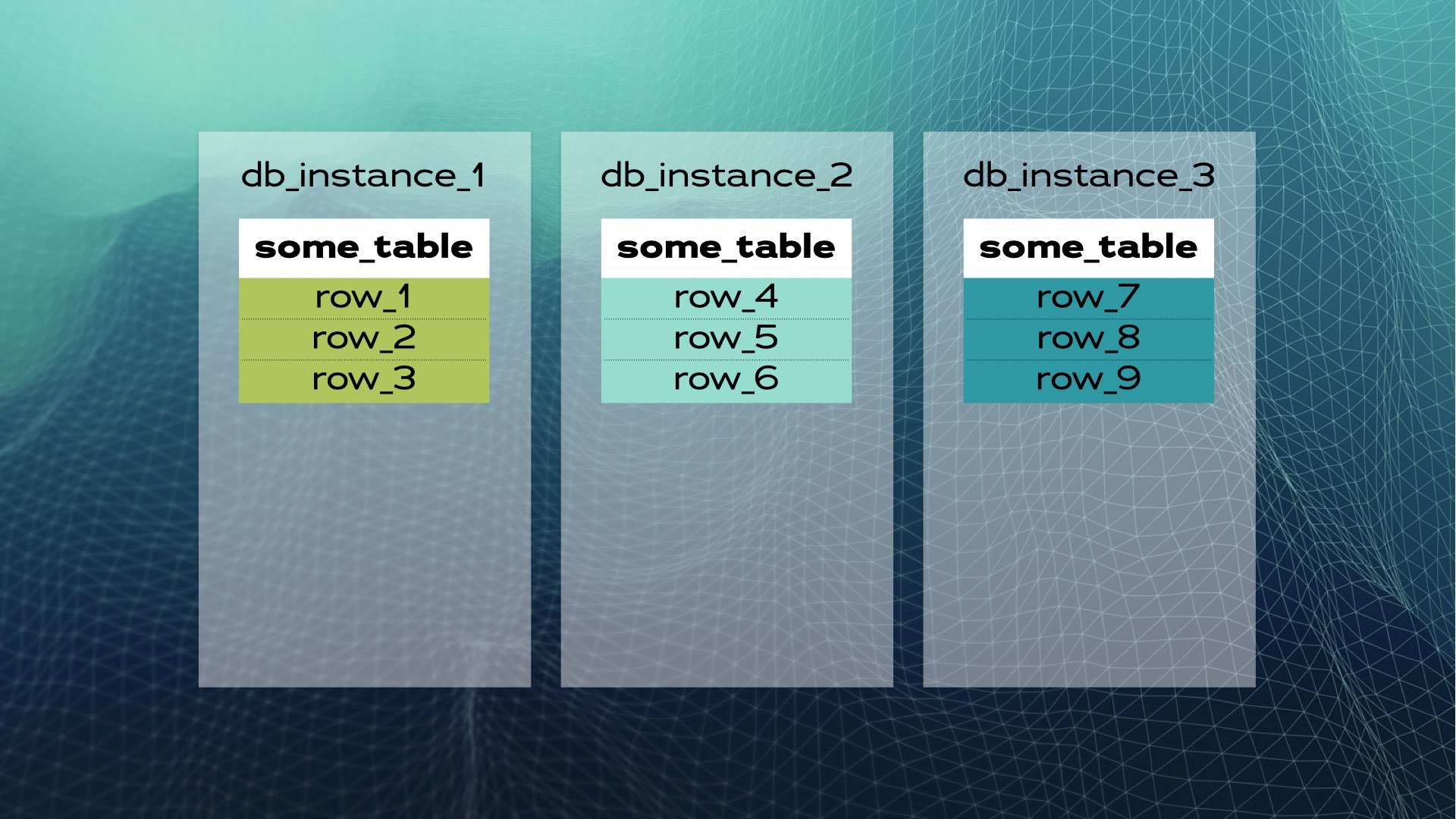
Voici à quoi ressemble le partage de base de données manuel. SQL distribué le fait automatiquement pour vous. Dans le cas de Xpand, chaque fragment est appelé un tranche. Les lignes sont tranchées en utilisant un hachage d’un sous-ensemble des colonnes de la table. Non seulement les données sont tranchées, mais les index sont également tranchés et répartis entre les nœuds (instances de base de données). De plus, pour maintenir une haute disponibilité, les tranches sont répliquées sur d’autres nœuds (le nombre de réplicas par nœud est configurable). Cela se fait également automatiquement :
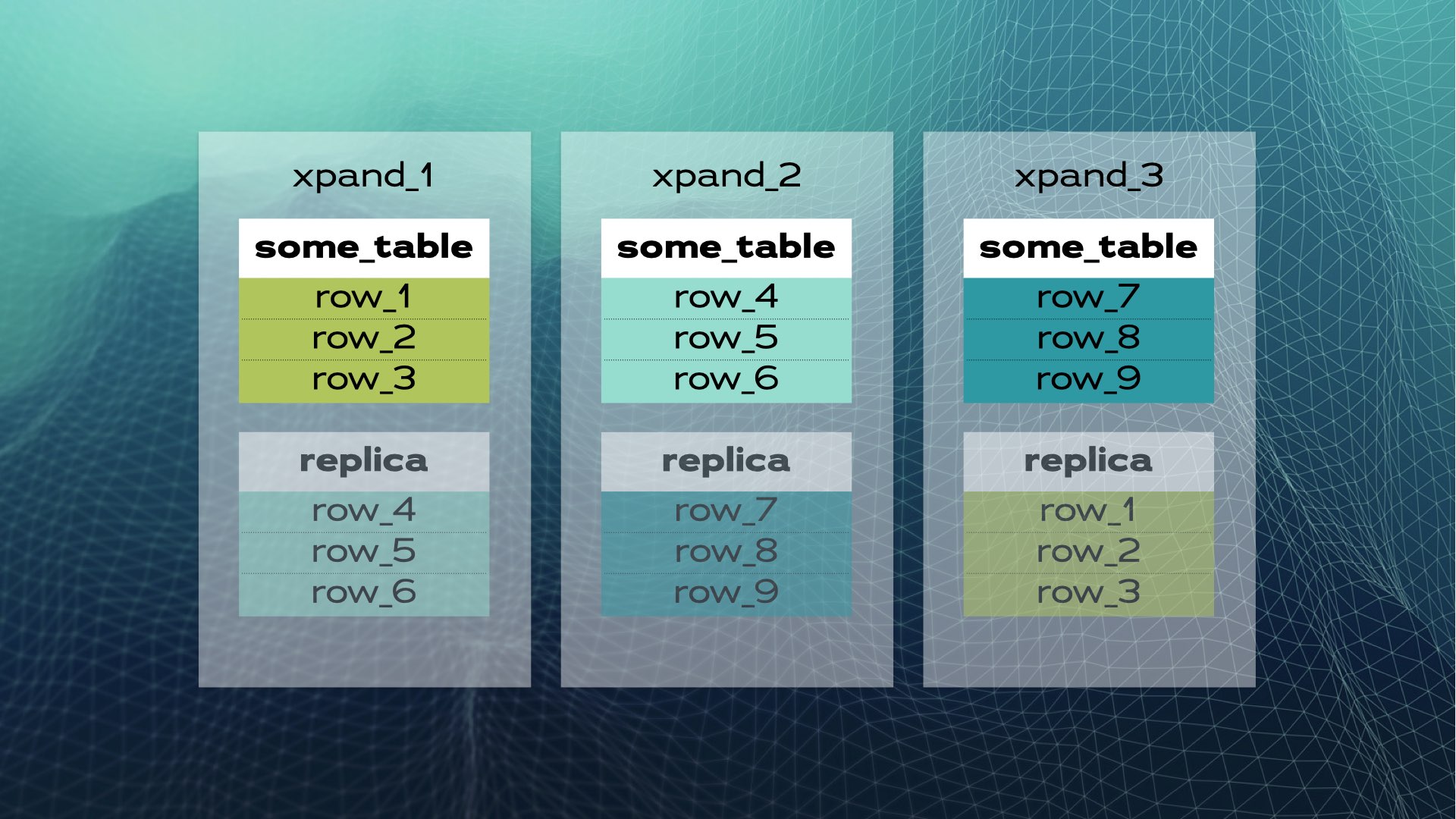
Lorsqu’un nouveau nœud est ajouté au cluster ou lorsqu’un nœud tombe en panne, Xpand rééquilibre automatiquement les données sans besoin d’intervention manuelle. Voici ce qui se passe lorsqu’un nœud est ajouté au précédent cluster :

Certaines lignes sont déplacées vers le nouveau nœud pour augmenter la capacité globale du système. Gardez à l’esprit que, bien que cela ne soit pas montré dans le schéma, les index ainsi que les réplicas sont également déplacés et mis à jour en conséquence. Une vue légèrement plus complète (avec un déplacement légèrement différent des données) du précédent cluster est présentée dans ce schéma :
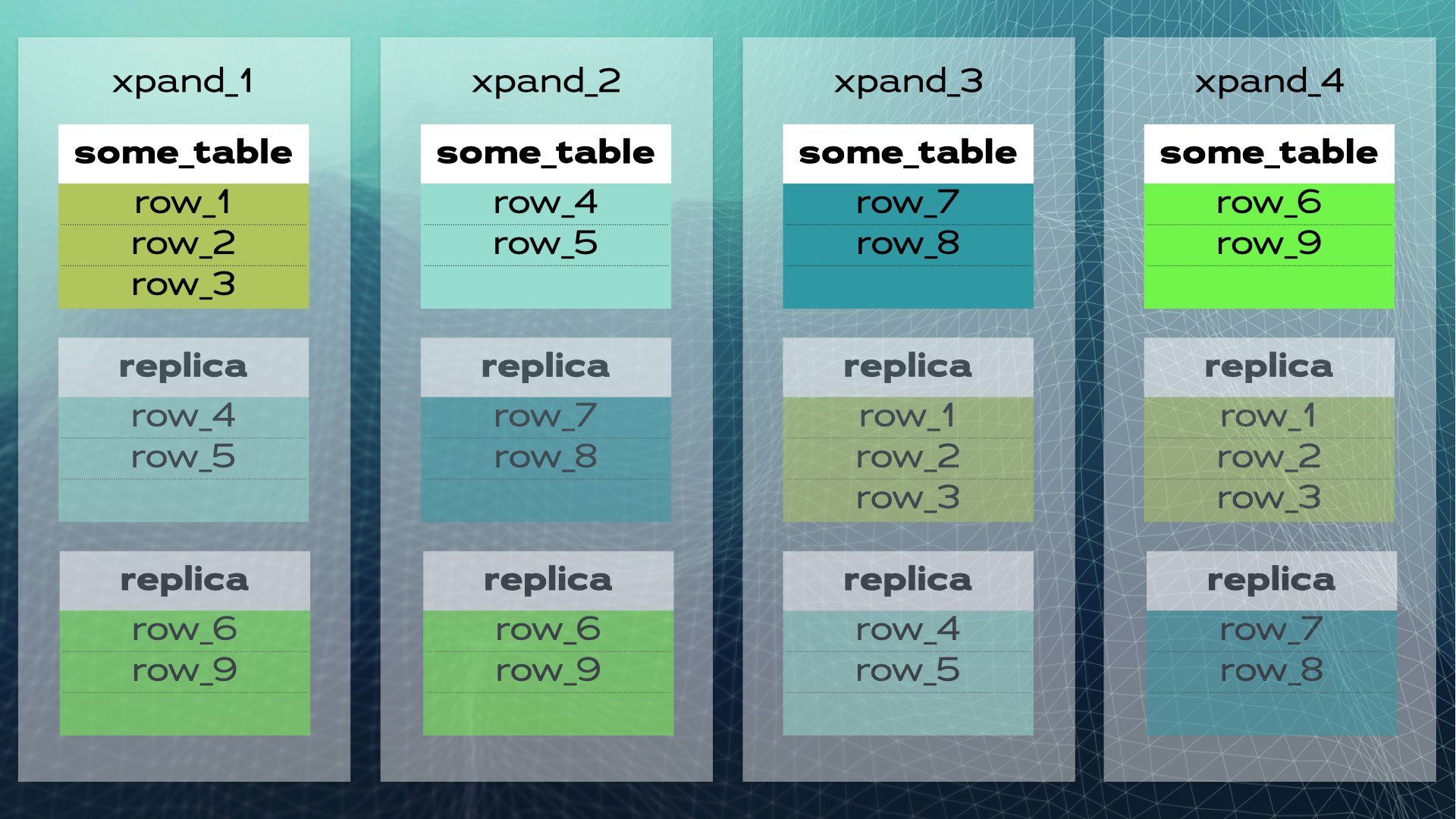
Cette architecture permet une scalabilité presque linéaire. Il n’est pas nécessaire d’intervenir manuellement au niveau de l’application. Pour l’application, le cluster ressemble à une seule base de données logique. L’application se connecte simplement à la base de données via un équilibreur de charge (MariaDB MaxScale) :
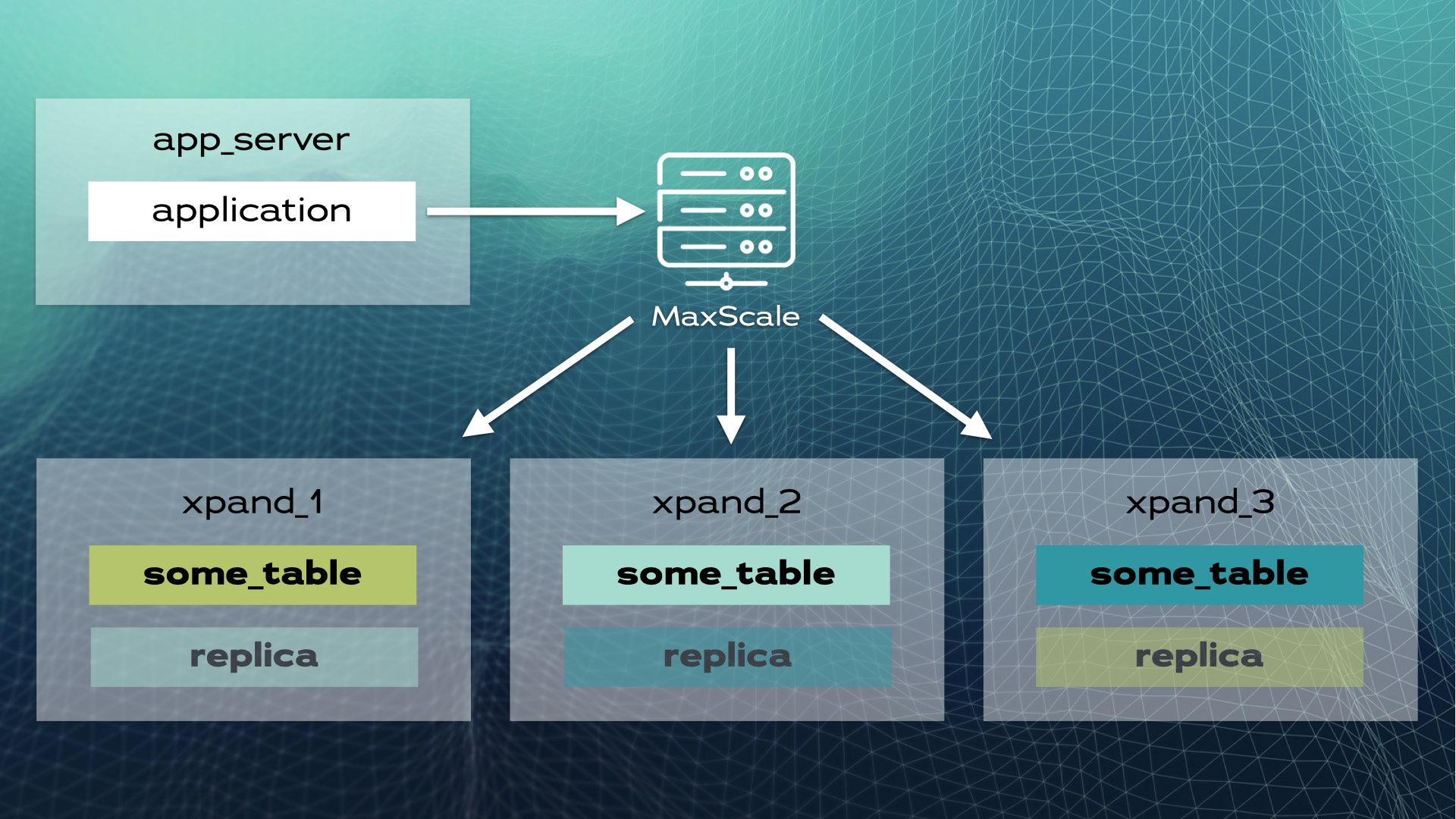
Lorsque l’application envoie une opération d’écriture (par exemple, INSERT ou UPDATE), le hachage est calculé et envoyé pour corriger la tranche. Plusieurs écritures sont envoyées en parallèle à plusieurs nœuds.
Lorsque ne pas utiliser SQL distribué
Le partitionnement d’une base de données améliore les performances mais introduit également une surcharge supplémentaire au niveau de la communication entre les nœuds. Cela peut entraîner des performances plus lentes si la base de données n’est pas configurée correctement ou si le routeur de requêtes n’est pas optimisé. SQL distribué pourrait ne pas être la meilleure alternative pour les applications avec moins de 10 000 requêtes par seconde ou 5 000 transactions par seconde. De plus, si votre base de données est principalement composée de nombreuses petites tables, une base de données monolithique pourrait offrir de meilleures performances.
Démarrage avec SQL distribué
Puisqu’une base de données SQL distribuée apparaît à une application comme une seule base de données logique, le démarrage est simple. Vous avez juste besoin des éléments suivants:
- Un client SQL tel que DBeaver, DbGate, DataGrip, ou toute extension de client SQL pour votre IDE
- A distributed SQL database
Docker facilite la deuxième partie. Par exemple, MariaDB publie l’image Docker mariadb/xpand-single qui vous permet de lancer une base de données Xpand à nœud unique pour évaluation, test et développement.
Pour démarrer un conteneur Xpand, exécutez la commande suivante:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Voir l’image Docker documentation pour plus de détails.
Remarque : Au moment de la rédaction de cet article, l’image Docker mariadb/xpand-single n’est pas disponible sur les architectures ARM. Sur ces architectures (par exemple, les machines Apple avec des processeurs M1), utilisez UTM pour créer une machine virtuelle (VM) et installer, par exemple, Debian. Attribuez un nom d’hôte et utilisez SSH pour vous connecter à la VM afin d’installer Docker et créer le conteneur MariaDB Xpand.
Connexion à la base de données
Se connecter à une base de données Xpand est identique à se connecter à un serveur MariaDB Community ou Enterprise. Si vous avez l’outil CLI mariadb installé, exécutez simplement ce qui suit :
mariadb -h 127.0.0.1 -u user -pVous pouvez vous connecter à la base de données à l’aide d’une interface graphique pour les bases de données SQL comme DBeaver, DataGrip, ou une extension SQL pour votre IDE (comme celle-ci pour VS Code). Nous allons utiliser un client SQL gratuit et open-source appelé DbGate. Vous pouvez télécharger DbGate et l’exécuter comme application de bureau ou, puisque vous utilisez Docker, vous pouvez le déployer comme application web que vous pouvez accéder de n’importe où via un navigateur web (semblable au populaire phpMyAdmin). Exécutez simplement la commande suivante :
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateUne fois que le conteneur démarre, dirigez votre navigateur vers http://localhost:3000/. Remplissez les détails de connexion :
Cliquez sur Tester et confirmez que la connexion est réussie :

Cliquez sur Enregistrer et créez une nouvelle base de données en faisant un clic droit sur la connexion dans le panneau de gauche et en sélectionnant Créer une base de données. Essayez de créer des tables ou d’importer un script SQL. Si vous voulez simplement tester quelque chose, les Nation ou Sakila sont de bonnes bases de données d’exemple.
Se connecter à partir de Java, JavaScript, Python et C++
Pour se connecter à Xpand à partir d’applications, vous pouvez utiliser les Connecteurs MariaDB. Il existe de nombreuses combinaisons possibles de langages de programmation et de frameworks de persistance. L’étude de ces combinaisons dépasse le cadre de cet article, mais si vous souhaitez simplement démarrer et voir quelque chose en action, jetez un Ÿil à cette page de démarrage rapide avec des exemples de code pour Java, JavaScript, Python et C++.
La vraie puissance du SQL distribué
Dans cet article, nous avons appris à lancer un Xpand à nœud unique pour des besoins de développement et de test, contrairement aux charges de travail de production. Cependant, la vraie puissance d’une base de données SQL distribuée réside dans sa capacité à évoluer non seulement les lectures (comme dans le fractionnement classique des bases de données) mais aussi les écritures en ajoutant simplement plus de nœuds et en laissant le rééquilibreur déplacer de manière optimale les données. Bien qu’il soit possible de déployer Xpand dans une topologie à plusieurs nœuds, la manière la plus simple d’utiliser Xpand en production est via SkySQL.
Si vous souhaitez en savoir plus sur le SQL distribué et MariaDB Xpand, voici une liste de ressources utiles:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding