













Dans la Partie 1 de cette série, nous avons examiné MongoDB, l’une des bases de données NoSQL orientées documents les plus fiables et robustes. Ici, dans la Partie 2, nous allons examiner une autre base de données NoSQL quasi incontournable : Elasticsearch.
Plus qu’une simple base de données distribuée NoSQL open-source populaire et puissante, Elasticsearch est avant tout un moteur de recherche et d’analyse. Il est construit sur le dessus de Apache Lucene, la bibliothèque de moteur de recherche Java la plus célèbre, et est capable d’effectuer des opérations de recherche et d’analyse en temps réel sur des données structurées et non structurées. Il est conçu pour gérer efficacement de grandes quantités de données.
Encore une fois, nous devons préciser que cet article court n’est en aucun cas un tutoriel Elasticsearch. En conséquence, le lecteur est vivement conseillé à utiliser largement la documentation officielle, ainsi que le livre excellent, « Elasticsearch in Action » par Madhusudhan Konda (Manning, 2023) pour en apprendre davantage sur l’architecture et les opérations du produit. Ici, nous réimplémentons simplement le même cas d’utilisation que précédemment, mais cette fois, en utilisant Elasticsearch au lieu de MongoDB.
Alors, c’est parti !
Le Modèle de Domaine
Le diagramme ci-dessous montre notre modèle de domaine *customer-order-product* :
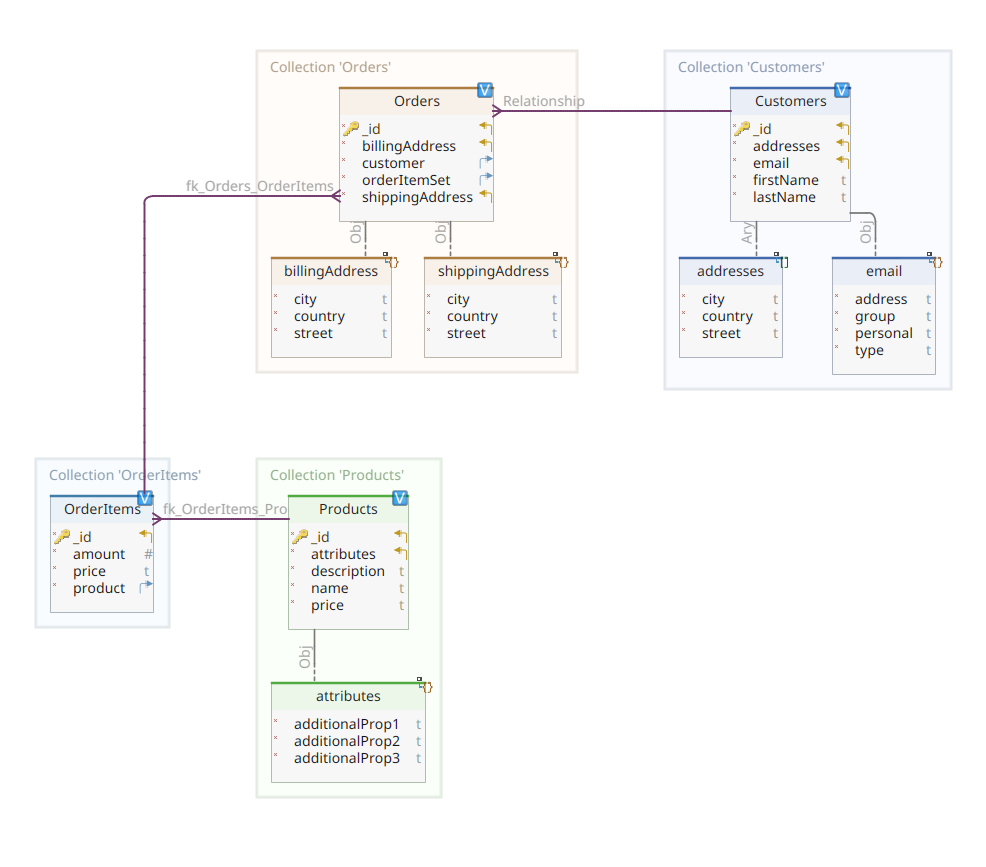
Ce diagramme est le même que celui présenté dans la Partie 1. Comme MongoDB, Elasticsearch est également un entrepôt de données documentaires et, de ce fait, il attend que les documents soient présentés en notation JSON. La seule différence est que pour gérer ses données, Elasticsearch a besoin de les faire indexer.
Il y a plusieurs manières dont les données peuvent être indexées dans un entrepôt de données Elasticsearch ; par exemple, les acheminer depuis une base de données relationnelle, les extraire d’un système de fichiers, les streamer depuis une source en temps réel, etc. Mais peu importe la méthode d’ingestion, elle consiste finalement à invoquer l’API RESTful d’Elasticsearch via un client dédié. Il y a deux catégories de tels clients dédiés :
- clients basés sur REST comme
curl,Postman, les modules HTTP pour Java, JavaScript, Node.js, etc. - SDKs de langages de programmation (Software Development Kit) : Elasticsearch fournit des SDKs pour tous les langages de programmation les plus utilisés, y compris mais sans s’y limiter Java, Python, etc.
Indexer un nouveau document avec Elasticsearch signifie le créer en utilisant une requête POST contre un point de terminaison RESTful spécial nommé _doc. Par exemple, la requête suivante créera un nouvel index Elasticsearch et stockera une nouvelle instance de client dedans.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Exécuter la requête ci-dessus avec curl ou la console Kibana (comme nous le verrons plus tard) produira le résultat suivant :
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Voici la réponse standard d’Elasticsearch à une requête POST. Elle confirme avoir créé l’index nommé customers, avec un nouveau document customer, identifié par un ID généré automatiquement (dans ce cas, ZEQsJI4BbwDzNcFB0ubC).
D’autres paramètres intéressants apparaissent ici, comme _version et surtout _shards. Sans entrer dans trop de détails, Elasticsearch crée des indexes en tant que collections logiques de documents. Comme garder des documents papier dans un classeur, Elasticsearch conserve les documents dans un index. Chaque index est composé de shards, qui sont des instances physiques d’Apache Lucene, le moteur derrière le rideau responsable de la récupération des données ou de leur stockage. Ils peuvent être soit primaires, stockant des documents, soit répliques, stockant, comme leur nom l’indique, des copies des shards primaires. Plus de détails à ce sujet dans la documentation Elasticsearch – pour l’instant, il nous faut noter que notre index nommé customers est composé de deux shards : l’un est bien sûr primaire.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Pour revenir à notre diagramme de modèle de domaine, comme vous pouvez le voir, son document central est Order, stocké dans une collection dédiée nommée Orders. Une Order est un agrégat de documents OrderItem, chacun pointant vers son Product associé. Un document Order fait également référence au Customer qui l’a passée. En Java, ceci est implémenté comme suit :
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
Le code ci-dessus montre un fragment de la classe Customer. Il s’agit d’un simple POJO (Plain Old Java Object) possédant des propriétés telles que l’ID du client, le prénom et le nom de famille, l’adresse e-mail, et un ensemble d’adresses postales.
Revenons maintenant sur le document Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Ici, vous pouvez noter quelques différences par rapport à la version MongoDB. En fait, avec MongoDB, nous utilisions une référence à l’instance du client associée à cette commande. Cette notion de référence n’existe pas avec Elasticsearch, et c’est pourquoi nous utilisons cet ID de document pour créer une association entre la commande et le client qui l’a passée. La même chose s’applique à la propriété orderItemSet qui crée une association entre la commande et ses articles.
Le reste de notre modèle de domaine est plutôt similaire et se base sur les mêmes idées de normalisation. Par exemple, le document OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Ici, nous devons associer le produit qui constitue l’objet de l’article de commande actuel. Enfin, nous avons le document Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}Les dépôts de données
Quarkus Panache simplifie grandement le processus de persistance des données en prenant en charge à la fois les patrons de conception active record et repository. Dans la Partie 1, nous avons utilisé l’extension Quarkus Panache pour MongoDB pour implémenter nos dépôts de données, mais il n’existe pas encore d’extension équivalente Quarkus Panache pour Elasticsearch. En attendant une possible future extension Quarkus pour Elasticsearch, nous devons ici implémenter manuellement nos dépôts de données en utilisant le client dédié à Elasticsearch.
Elasticsearch est écrit en Java et, par conséquent, il n’est pas surprenant qu’il offre un support natif pour l’appel de l’API Elasticsearch en utilisant la bibliothèque client Java. Cette bibliothèque est basée sur le patron de conception de constructeur d’API fluent et fournit à la fois des modèles de traitement synchrone et asynchrone. Elle nécessite au minimum Java 8.
Alors, à quoi ressemblent nos dépôts de données basés sur le constructeur d’API fluent ? Voici un extrait de la classe CustomerServiceImpl qui agit comme dépôt de données pour le document Customer.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
Comme nous pouvons le voir, notre implémentation de dépôt de données doit être un bean CDI avec un scope d’application. Le client Java Elasticsearch est simplement injecté, grâce à l’extension quarkus-elasticsearch-java-client de Quarkus. Cela évitera beaucoup d’éléments superflus que nous aurions dû utiliser autrement. La seule chose dont nous avons besoin pour pouvoir injecter le client est de déclarer la propriété suivante :
quarkus.elasticsearch.hosts = elasticsearch:9200Voici, elasticsearch est le nom DNS (Domain Name Server) que nous associons au serveur de base de données Elastic search dans le fichier docker-compose.yaml. 9200 est le numéro de port TCP utilisé par le serveur pour écouter les connexions.
La méthode doIndex() ci-dessus crée un nouvel index nommé customers s’il n’existe pas et indexe (stocke) dedans un nouveau document représentant une instance de la classe Customer. Le processus d’indexation est effectué sur la base d’une IndexRequest acceptant comme arguments d’entrée le nom de l’index et le corps du document. Quant à l’ID du document, il est généré automatiquement et renvoyé à l’appelant pour une utilisation ultérieure.
La méthode suivante permet de récupérer le client identifié par l’ID donné en argument d’entrée:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
Le principe est le même : en utilisant ce patron de conception API fluide, nous construisons une instance de GetRequest de la même manière que nous l’avons fait avec la IndexRequest, et nous l’exécutons contre le client Java Elasticsearch. Les autres points de terminaison de notre dépôt de données, permettant d’effectuer des opérations de recherche complète ou de mettre à jour et de supprimer des clients, sont conçus de la même manière.
Prenez un peu de temps pour examiner le code pour comprendre comment les choses fonctionnent.
L’API REST
Notre interface API REST pour MongoDB était simple à implémenter, grâce à l’extension quarkus-mongodb-rest-data-panache, dans laquelle le processeur d’annotations a automatiquement généré tous les endpoints nécessaires. Avec Elasticsearch, nous ne bénéficions pas encore du même confort et, par conséquent, nous devons l’implémenter manuellement. Ce n’est pas un problème majeur, car nous pouvons injecter les dépôts de données précédents, comme indiqué ci-dessous :
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Ceci est l’implémentation de l’API REST du client. Les autres associées aux commandes, aux articles de commande et aux produits sont similaires.
Voyons maintenant comment exécuter et tester tout cela.
Exécution et Test de Nos Microservices
Après avoir examiné les détails de notre implémentation, voyons comment l’exécuter et le tester. Nous avons choisi de le faire au nom de l’utilitaire docker-compose. Voici le fichier associé docker-compose.yml :
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Ce fichier instructions l’utilitaire docker-compose pour exécuter trois services :
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
À présent, vous pouvez vérifier que tous les processus nécessaires sont en cours d’exécution :
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Pour confirmer que le serveur Elasticsearch est disponible et capable d’exécuter des requêtes, vous pouvez vous connecter à Kibana à l’adresse http://localhost:601. Après avoir fait défiler la page vers le bas et sélectionné Dev Tools dans le menu des préférences, vous pouvez exécuter des requêtes comme indiqué ci-dessous :
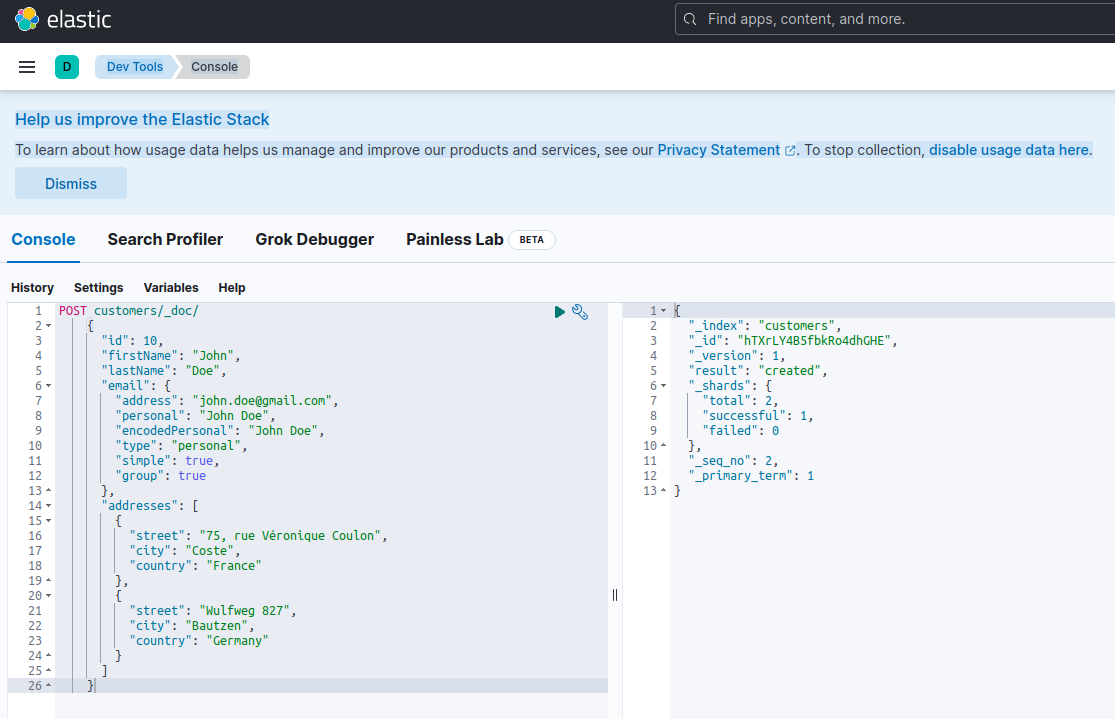
Pour tester les microservices, procédez comme suit :
1. Clone le dépôt GitHub associé :
$ git clone https://github.com/nicolasduminil/docstore.git2. Allez dans le projet :
$ cd docstore3. Sélectionnez la bonne branche :
$ git checkout elastic-search4. Compilez :
$ mvn clean install5. Exécutez les tests d’intégration :
$ mvn -DskipTests=false failsafe:integration-testCette dernière commande exécutera les 17 tests d’intégration fournis, qui devraient tous réussir. Vous pouvez également utiliser l’interface Swagger UI à des fins de test en ouvrant votre navigateur préféré à l’adresse http://localhost:8080/q:swagger-ui. Ensuite, pour tester les points de terminaison, vous pouvez utiliser le chargeur utile dans les fichiers JSON situés dans le répertoire src/resources/data du projet docstore-api.
Profitez-en!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse