













Dans ce laboratoire pratique de l’Université ScyllaDB, vous apprendrez à utiliser le connecteur source CDC ScyllaDB pour envoyer les événements de changements au niveau des lignes dans les tables d’un cluster ScyllaDB vers un serveur Kafka.
Qu’est-ce que le CDC ScyllaDB?
Pour résumer, la Capture des Données de Changements (CDC) est une fonctionnalité qui vous permet non seulement de consulter l’état actuel d’une table de base de données, mais aussi de consulter l’historique de tous les changements effectués sur la table. Le CDC est prêt pour la production (GA) à partir de ScyllaDB Entreprise 2021.1.1 et ScyllaDB Open Source 4.3.
Dans ScyllaDB, le CDC est optionnel et activé au niveau de la table. L’historique des changements apportés à une table activée pour le CDC est stocké dans une table associée distincte.
Vous pouvez activer le CDC lors de la création ou de la modification d’une table en utilisant l’option CDC, par exemple:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};Connecteur Source ScyllaDB CDC
Le ScyllaDB CDC Source Connector est un connecteur source capturant les modifications au niveau des lignes dans les tables d’un cluster ScyllaDB. Il s’agit d’un Debezium connecteur, compatible avec Kafka Connect (avec Kafka 2.6.0+). Le connecteur lit le journal CDC pour les tables spécifiées et produit des messages Kafka pour chaque opération de niveau ligne INSERT, UPDATE, ou DELETE. Le connecteur est tolérant aux pannes, essayant de nouveau la lecture des données à partir de Scylla en cas d’échec. Il enregistre périodiquement la position actuelle dans le journal CDC ScyllaDB en utilisant le suivi des décalages Kafka Connect. Chaque message Kafka généré contient des informations sur la source, telles que l’horodatage et le nom de la table.
Note: au moment de la rédaction, il n’y a pas de support pour les types de collections (LIST, SET, MAP) et les UDTs—les colonnes avec ces types sont omises des messages générés. Restez à jour sur cette demande d’amélioration et autres développements dans le projet GitHub.
Confluent et Kafka Connect
Confluent est une plateforme complète de diffusion de données qui vous permet d’accéder, stocker et gérer des données sous forme de flux continus et en temps réel. Elle étend les avantages d’Apache Kafka avec des fonctionnalités de niveau entreprise. Confluent facilite la construction d’applications modernes basées sur des événements et offre un pipeline universel de données, soutenu par la scalabilité, la performance et la fiabilité.
Kafka Connect est un outil pour diffuser de manière scalable et fiable des données entre Apache Kafka et d’autres systèmes de données. Il simplifie la définition de connecteurs qui déplacent de grands ensembles de données dans et hors de Kafka. Il peut ingérer des bases de données entières ou collecter des métriques à partir des serveurs d’applications pour les intégrer dans des sujets Kafka, rendant les données disponibles pour le traitement en flux avec faible latence.
Kafka Connect comprend deux types de connecteurs:
- Connecteur source : Les connecteurs source ingèrent des bases de données entières et diffusent les mises à jour de table vers des sujets Kafka. Les connecteurs source peuvent également collecter des métriques à partir des serveurs d’applications et stocker les données dans des sujets Kafka, rendant les données disponibles pour le traitement en flux avec faible latence.
- Connecteur sink : Les connecteurs sink distribuent des données à partir de sujets Kafka vers des index secondaires, tels qu’Elasticsearch, ou des systèmes batch, tels que Hadoop, pour une analyse hors ligne.
Installation de service avec Docker
Dans ce laboratoire, vous utiliserez Docker.
Veuillez vous assurer que votre environnement répond aux prérequis suivants:
- Docker pour Linux, Mac ou Windows.
- Note :l’exécution de ScyllaDB dans Docker est seulement recommandée pour évaluer et tester ScyllaDB.
- ScyllaDB open source. Pour obtenir les meilleures performances, il est recommandé d’installer régulièrement.
- 8 Go de RAM ou plus pour les services Kafka et ScyllaDB.
- docker-compose
- Git
ScyllaDB Installation et Initialisation de Table
Tout d’abord, vous allez lancer un cluster ScyllaDB à trois nœuds et créer une table avec CDC activé.
Si vous ne l’avez pas déjà fait, téléchargez l’exemple de git:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabCeci est le fichier docker-compose que vous utiliserez. Il démarre un cluster ScyllaDB à trois nœuds:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Démarrez le cluster ScyllaDB:
docker-compose -f docker-compose-scylladb.yml up -dAttendez une minute environ, puis vérifiez que le cluster ScyllaDB est opérationnel et en état normal:
docker exec scylla-node1 nodetool statusEnsuite, vous utiliserez cqlsh pour interagir avec ScyllaDB. Créez un keyspace, une table avec CDC activé, et insérez une ligne dans la table:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Adresse Charge Jetons Propres ID de l'hôte Rack
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Configuration de Confluent et du Connecteur
Pour lancer un serveur Kafka, vous utiliserez la plateforme Confluent, qui offre une interface web conviviale pour suivre les sujets et les messages. La plateforme Confluent fournit un fichier docker-compose.yml pour configurer les services.
Note: ce n’est pas ainsi que vous utiliseriez Apache Kafka en production. L’exemple est utile uniquement à des fins de formation et de développement. Obtenez le fichier:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlEnsuite, téléchargez le connecteur CDC ScyllaDB:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarAjoutez le connecteur CDC ScyllaDB au répertoire des plugins de service Confluent connect en utilisant un volume Docker en modifiant le fichier docker-compose-confluent.yml pour ajouter les deux lignes comme ci-dessous, en remplaçant le répertoire par le répertoire de votre fichier scylla-cdc-plugin.jar.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryLancez les services Confluent:
docker-compose -f docker-compose-confluent.yml up -dAttendez une minute ou deux, puis accédez à http://localhost:9021 pour la GUI web Confluent.
Ajoutez le ScyllaConnector à l’aide du tableau de bord Confluent:
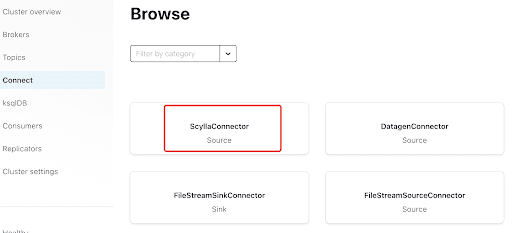
Ajoutez le Scylla Connector en cliquant sur le plugin:
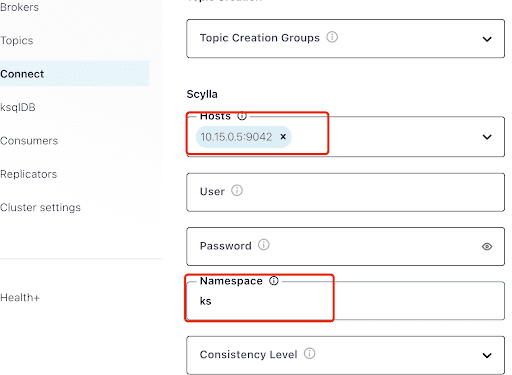
Remplissez le champ “Hosts” avec l’adresse IP d’un des nœuds Scylla (vous pouvez la voir dans la sortie de la commande nodetool status) et le port 9042, qui est écouté par le service ScyllaDB.
Le “Namespace” est l’espace de clés que vous avez créé précédemment dans ScyllaDB.
Notez qu’il peut prendre une minute ou deux pour que ks.my_table apparaisse:
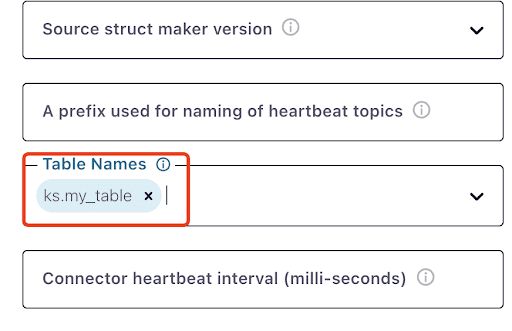
Testez les messages Kafka
Vous pouvez voir que MyScyllaCluster.ks.my_table est le sujet créé par le connecteur CDC ScyllaDB.
Maintenant, recherchez des messages Kafka à partir du panneau des sujets:
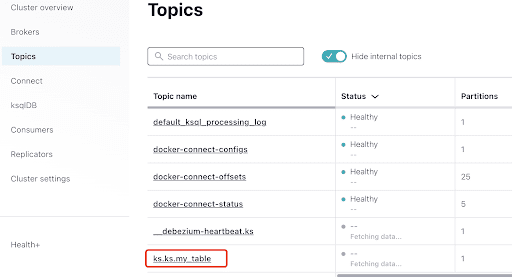
Sélectionnez le sujet, qui est le même que le nom de l’espace de clés et de la table que vous avez créés dans ScyllaDB:
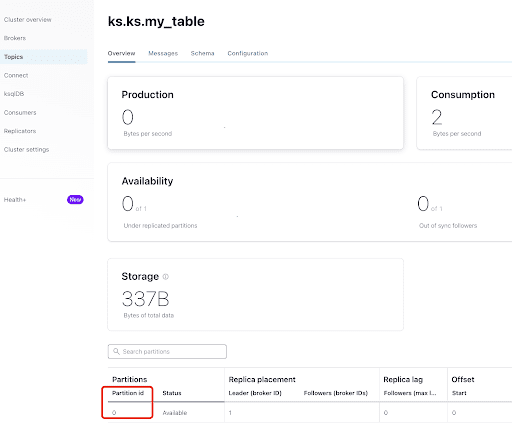
À partir de l’onglet “Aperçu”, vous pouvez voir les informations du sujet. En bas, il indique que ce sujet est sur la partition 0.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
Comme vous le savez déjà, les messages CDC de ScyllaDB sont envoyés au sujet ks.my_table, et l’identifiant de partition du sujet est 0. Ensuite, allez à l’onglet “Messages” et entrez l’identifiant de partition 0 dans le champ “offset” :
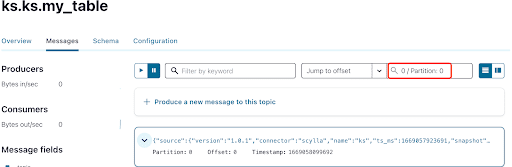
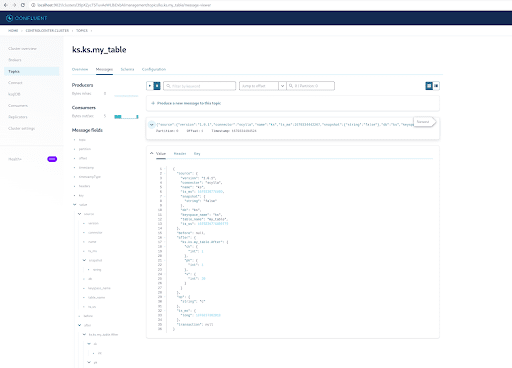
Vous pouvez voir à partir de la sortie des messages du sujet Kafka que l’événement de table ScyllaDB INSERT et les données ont été transférés aux messages Kafka par le connecteur Source CDC Scylla. Cliquez sur le message pour voir toutes les informations du message :
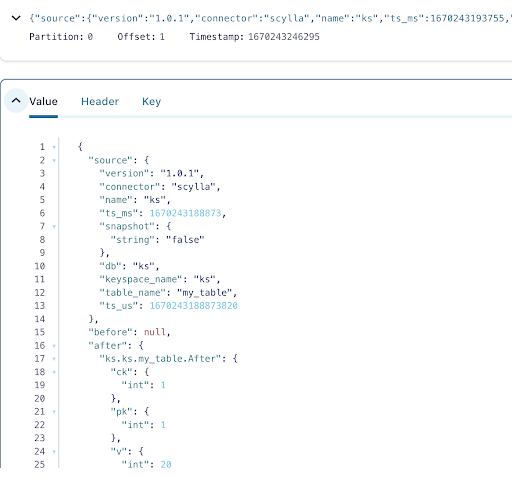
Le message contient le nom de la table ScyllaDB, le nom de l’espace de clés avec l’heure, ainsi que l’état des données avant et après l’action. Puisque c’est une opération d’insertion, les données avant l’insertion sont nulles.
Ensuite, insérez une autre ligne dans la table ScyllaDB :
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Maintenant, dans Kafka, attendez quelques secondes et vous pourrez voir les détails du nouveau Message :
Nettoyage
Une fois que vous avez terminé de travailler sur ce laboratoire, vous pouvez arrêter et supprimer les conteneurs et images Docker.
Pour afficher la liste de tous les IDs de conteneur :
docker container ls -aqEnsuite, vous pouvez arrêter et supprimer les conteneurs que vous n’utilisez plus :
docker stop <ID_or_Name>
docker rm <ID_or_Name>Plus tard, si vous souhaitez relancer le laboratoire, vous pouvez suivre les étapes et utiliser docker-compose comme précédemment.
Résumé
Avec le connecteur source CDC, un plugin Kafka compatible avec Kafka Connect, vous pouvez capturer tous les changements au niveau des lignes de la table ScyllaDB (INSERT, UPDATE, ou DELETE) et convertir ces événements en messages Kafka. Vous pouvez ensuite consommer les données à partir d’autres applications ou effectuer toute autre opération avec Kafka.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb