













Les journaux de bord représentent souvent la majorité des actifs de données d’une entreprise. Parmi les exemples de journaux figurent les journaux d’activité commerciale (tels que les journaux d’activité des utilisateurs) et les journaux d’exploitation et de maintenance des serveurs, bases de données, réseaux ou dispositifs IoT.
Les journaux sont l’ange gardien des affaires. D’une part, ils fournissent des alertes de risque système et aident les ingénieurs à localiser rapidement les causes principales lors de la résolution des problèmes. D’autre part, si vous les zoomez par gamme de temps, vous pourriez identifier certaines tendances et modèles utiles, sans parler des journaux d’activité commerciale qui sont la pierre angulaire des insights sur les utilisateurs.
Cependant, les journaux peuvent être éprouvants car :
- Ils affluent à perdre haleine. Chaque événement système ou clic de l’utilisateur génère un journal. Une entreprise produit souvent des dizaines de milliards de nouveaux journaux par jour.
- Ils sont volumineux. Les journaux sont censés rester. Ils pourraient ne pas être utiles jusqu’à ce qu’ils le soient. Ainsi, une entreprise peut accumuler jusqu’à des PBs de données de journal, dont beaucoup sont rarement consultées mais occupent un espace de stockage énorme.
- Ils doivent être rapides à charger et à trouver. Localiser le journal cible pour la résolution des problèmes est littéralement comme chercher une aiguille dans une botte de foin. Les gens rêvent d’écriture de journaux en temps réel et de réponses en temps réel aux requêtes de journaux.
Vous voyez maintenant un tableau clair de ce à quoi ressemble un système idéal de traitement des journaux. Il devrait supporter ce qui suit :
- Ingestion de données en temps réel à haut débit : Il devrait être capable d’écrire des blogs en masse et de les rendre visibles immédiatement.
- Stockage à faible coût : Il devrait être capable de stocker d’importantes quantités de journaux sans coûter trop de ressources.
- Recherche de texte en temps réel : Elle doit être capable de rechercher rapidement du texte.
Solutions courantes : Elasticsearch et Grafana Loki
Il existe deux solutions courantes de traitement des logs dans l’industrie, illustrées respectivement par Elasticsearch et Grafana Loki.
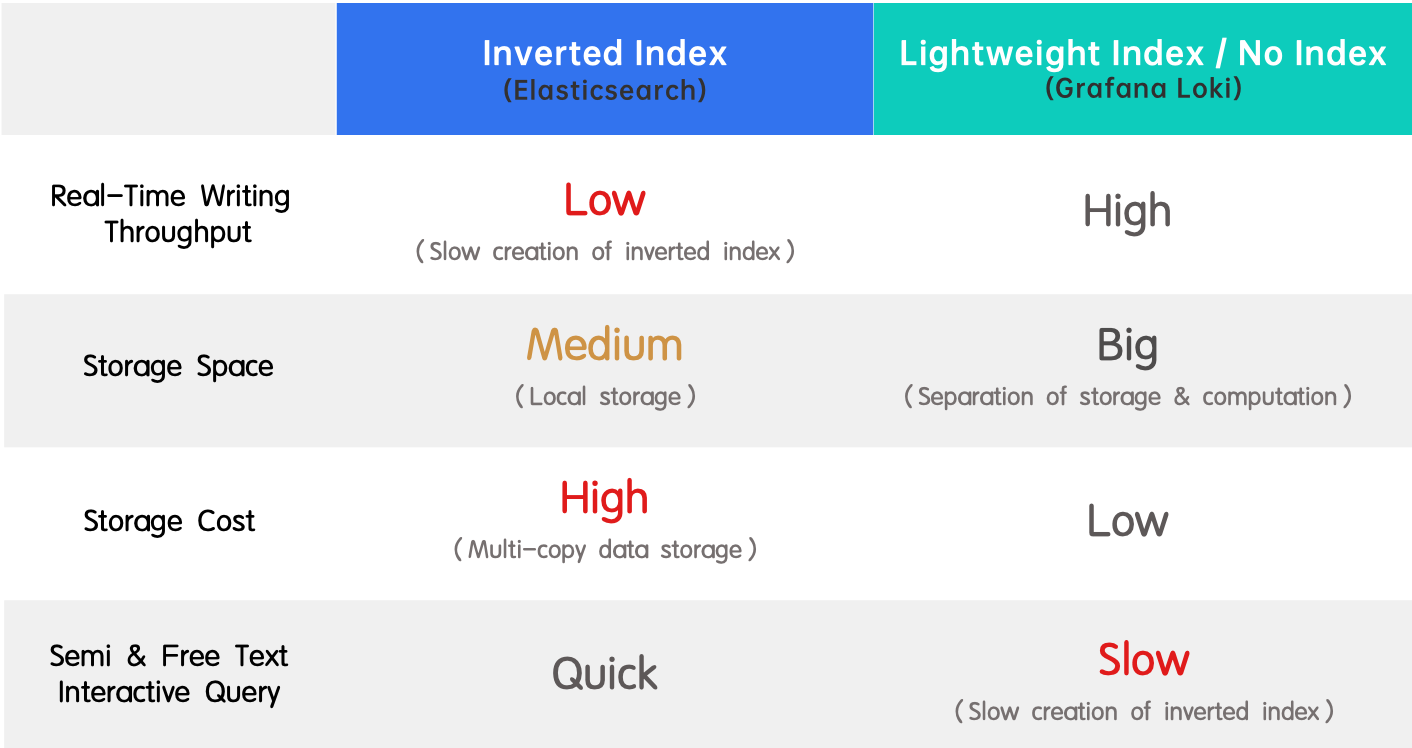
- Index inversé (Elasticsearch) : Il est largement adopté en raison de son soutien à la recherche plein texte et de sa haute performance. Le revers de la médaille est le faible débit en écriture en temps réel et la consommation importante de ressources lors de la création de l’index.
- Index léger / pas d’index (Grafana Loki) : Il est l’opposé d’un index inversé car il offre un fort débit d’écriture en temps réel et un faible coût de stockage mais fournit des requêtes lentes.
Introduction à l’Index Inversé
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
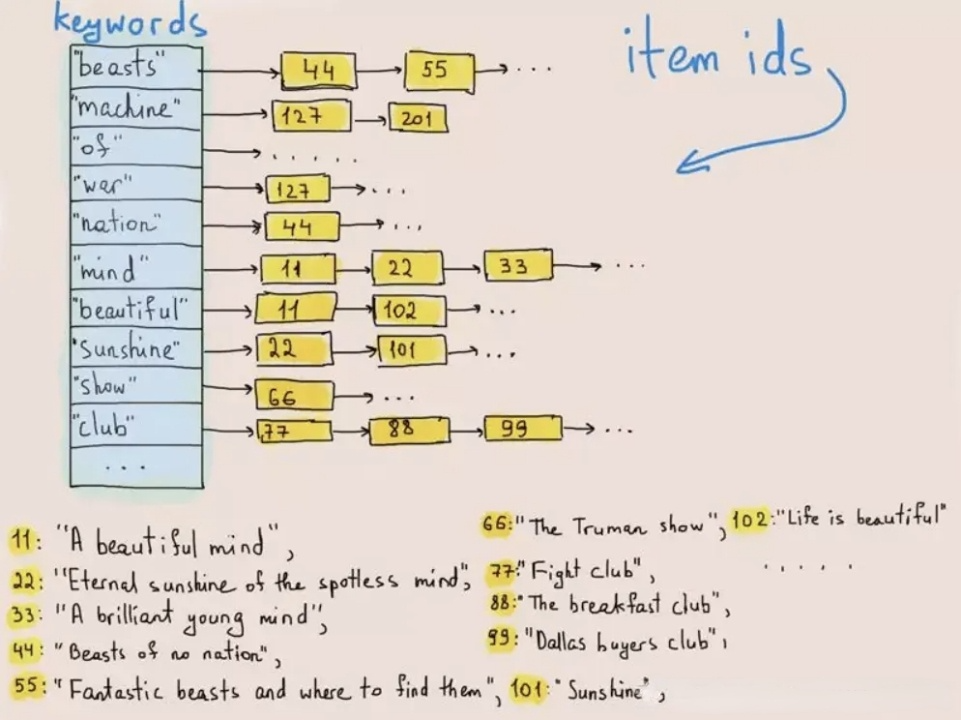
L’indexation inversée a été à l’origine utilisée pour retrouver des mots ou des phrases dans des textes. La figure ci-dessous illustre comment cela fonctionne :
Lors de l’écriture des données, le système tokenise les textes en termes et stocke ces termes dans une liste de diffusion qui mappe les termes à l’ID de la ligne où ils existent. Dans les requêtes de texte, la base de données trouve l’ID de ligne correspondant au mot-clé (terme) dans la liste de diffusion et récupère la ligne cible en fonction de l’ID de ligne. De cette manière, le système n’a pas besoin de parcourir l’ensemble des données et améliore ainsi la vitesse des requêtes de plusieurs ordres de grandeur.
Dans l’indexation inversée d’Elasticsearch, l’accès rapide est obtenu au prix de la vitesse d’écriture, du débit d’écriture et de l’espace de stockage. Pourquoi ? Tout d’abord, le tokenization, le tri du dictionnaire et la création de l’index inversé sont tous des opérations intensives en CPU et en mémoire. Deuxièmement, Elasticssearch doit stocker les données originales, l’index inversé et une copie supplémentaire des données stockées en colonnes pour l’accélération des requêtes. C’est une triple redondance.
Mais sans index inversé, Grafana Loki, par exemple, dégrade l’expérience utilisateur avec ses requêtes lentes, ce qui est le plus grand point de douleur pour les ingénieurs dans l’analyse des logs.
En résumé, Elasticsearch et Grafana Loki représentent différents compromis entre un débit d’écriture élevé, un coût de stockage faible et une performance de requête rapide. Et si je vous disais qu’il existe un moyen d’en avoir tous ? Nous avons introduit des index inversés dans Apache Doris 2.0.0 et l’avons encore optimisé pour réaliser deux fois plus rapide que Elasticsearch en matière de performance de requête de logs avec 1/5 de l’espace de stockage qu’il utilise. Combinés, ces facteurs constituent une solution 10 fois meilleure.
Index inversé dans Apache Doris
Généralement, il existe deux manières d’implémenter des index : système d’indexation externe ou index intégrés.
Système d’indexation externe : Vous connectez un système d’indexation externe à votre base de données. Lors de l’ingestion de données, les données sont importées dans les deux systèmes. Après que le système d’indexation crée des index, il supprime les données originales en son sein. Lorsque les utilisateurs de données saisissent une requête, le système d’indexation fournit les identifiants des données pertinentes, puis la base de données recherche les données cibles en fonction des identifiants.
Construire un système d’indexation externe est plus facile et moins intrusif pour la base de données, mais cela présente quelques inconvénients gênants :
- La nécessité d’écrire des données dans deux systèmes peut entraîner une incohérence des données et une redondance de stockage.
- L’interaction entre la base de données et le système d’indexation entraîne des surcoûts, de sorte que lorsque les données cibles sont importantes, la requête entre les deux systèmes peut être lente.
- Il est épuisant de maintenir deux systèmes.
Dans Apache Doris, nous choisissons l’autre méthode. Les index inversés intégrés sont plus difficiles à mettre en place, mais une fois cela fait, ils sont plus rapides, plus conviviaux et sans souci à maintenir.
Dans Apache Doris, les données sont organisées sous la forme suivante. Les index sont stockés dans la région Index :
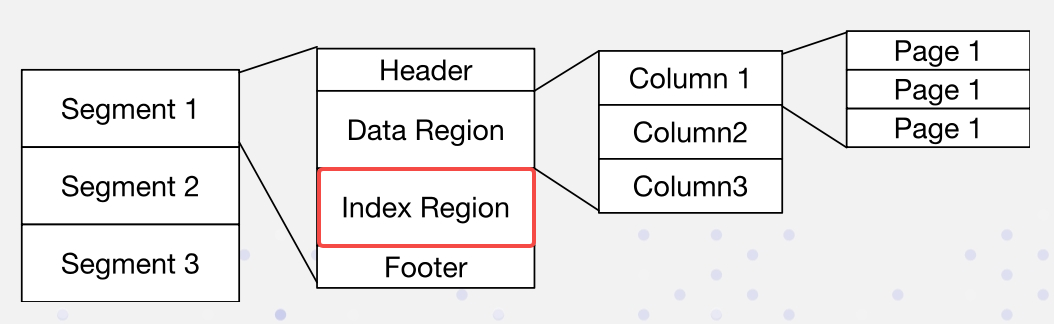
Nous mettons en œuvre des index inversés de manière non intrusive :
- Ingestion et compactage des données : Lorsqu’un fichier de segment est écrit dans Doris, un fichier d’index inversé sera également écrit. Le chemin du fichier d’index est déterminé par l’ID de segment et l’ID d’index. Les lignes dans les segments correspondent aux docs dans les index, tout comme RowID et DocID.
- Requête: Si la clause
whereinclut une colonne avec index inversé, le système va chercher dans le fichier d’index, retourner une liste de DocID, et convertir cette liste de DocID en un Bitmap de RowID. Sous le mécanisme de filtrage des RowID d’Apache Doris, seules les lignes cibles seront lues. Voici comment les requêtes sont accélérées.
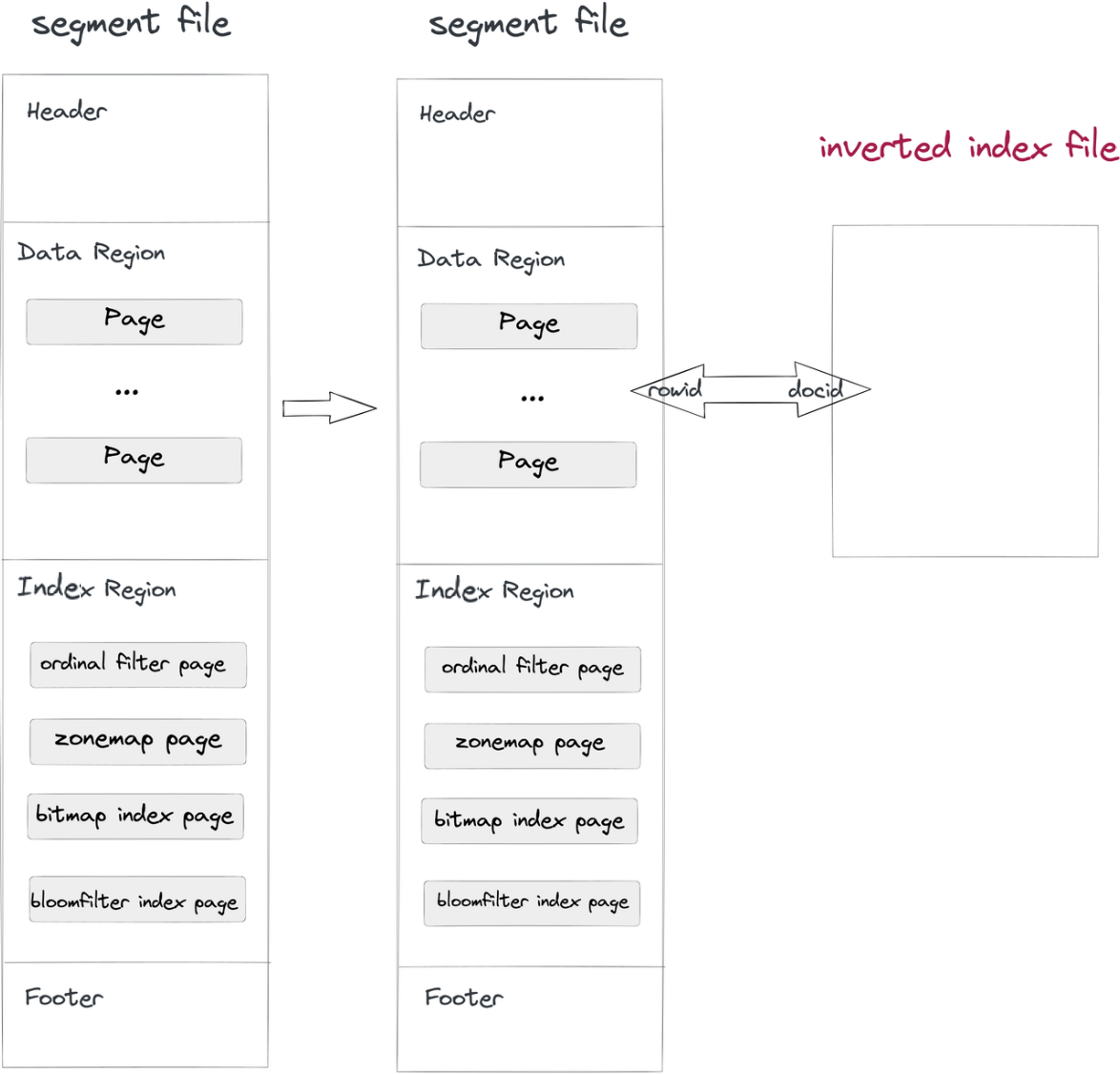
Une telle méthode non intrusive sépare le fichier d’index des fichiers de données, vous permet donc de faire n’importe quelle modification aux index inversés sans vous soucier d’affecter les fichiers de données eux-mêmes ou d’autres index.
Optimisations pour Index Inversé
Optimisations Générales
C++ Implementation and Vectorization
Contrairement à Elasticsearch, qui utilise Java, Apache Doris implémente le C++ dans ses modules de stockage, moteur d’exécution de requêtes et index inversés. Par rapport à Java, C++ offre de meilleures performances, permet une vectorisation plus aisée et ne produit pas de surcoûts de GC de la JVM. Nous avons vectorisé chaque étape de l’indexation inversée dans Apache Doris, comme la tokenisation, la création d’index et les requêtes. Pour vous donner un aperçu, dans l’indexation inversée, Apache Doris écrit des données à une vitesse de 20 Mo/s par coeur, ce qui est quatre fois supérieur à Elasticsearch (5 Mo/s).
Stockage en colonnes et Compression
Apache Lucene pose les bases pour les index inversés dans Elasticsearch. Comme Lucene est construit pour supporter le stockage de fichiers, il stocke les données dans un format orienté ligne.
Dans Apache Doris, les index inversés pour différentes colonnes sont isolés les uns des autres, et les fichiers d’index inversé adoptent le stockage en colonnes pour faciliter la vectorisation et la compression des données.
En utilisant la compression Zstandard, Apache Doris obtient un taux de compression allant de 5:1 à 10:1, des vitesses de compression plus rapides et une utilisation d’espace réduite de 50% par rapport à la compression GZIP.
Arbres BKD pour les colonnes numériques / datetime
Apache Doris met en œuvre des arbres BKD pour les colonnes numériques et datetime. Cela non seulement augmente les performances des requêtes par intervalle, mais est également une méthode plus économe en espace que la conversion de ces colonnes en chaînes de longueur fixe. Les autres avantages incluent :
- Requêtes par intervalle efficaces : Il est capable de localiser rapidement la plage de données cible dans les colonnes numériques et datetime.
- Moins d’espace de stockage : Il agrège et compresse les blocs de données adjacents pour réduire les coûts de stockage.
- Prise en charge des données multidimensionnelles : Les arbres BKD sont évolutifs et adaptatifs aux types de données multidimensionnelles, tels que les points GEO et les plages.
En plus des arbres BKD, nous avons encore optimisé les requêtes sur les colonnes numériques et datetime.
- Optimisation pour les scénarios à faible cardinalité : Nous avons affiné l’algorithme de compression pour les scénarios à faible cardinalité, de sorte que la décompression et la désérialisation de grandes quantités de listes inversées consomment moins de ressources CPU.
- Pré-fetching : Pour les scénarios à taux de réussite élevé, nous adoptons le pré-fetching. Si le taux de réussite dépasse un certain seuil, Doris sautera le processus d’indexation et commencera le filtrage des données.
Optimisations personnalisées pour OLAP
D’habitude, l’analyse des logs est un type de requête simple qui n’a pas besoin de fonctionnalités avancées (par exemple, le score de pertinence dans Apache Lucene). La capacité de base d’un outil de traitement des logs est des requêtes rapides et des coûts de stockage faibles. Par conséquent, dans Apache Doris, nous avons allégé la structure de l’index inversé pour répondre aux besoins d’une base de données OLAP.
- Lors de l’ingestion de données, nous empêchons plusieurs threads d’écrire des données dans le même index et évitons ainsi les surcoûts causés par la contention des verrous.
- Nous abandonnons les fichiers d’index avant et les fichiers Norm pour libérer de l’espace de stockage et réduire les surcoûts d’E/S.
- Nous simplifions la logique de calcul du score de pertinence et de classement pour réduire davantage les surcoûts et augmenter les performances.
Compte tenu du fait que les logs sont partitionnés par plage de temps et que les logs historiques sont consultés moins fréquemment, nous prévoyons d’offrir une gestion d’index plus granulaire et flexible dans les futures versions d’Apache Doris:
- Créer un index inversé pour une partition de données spécifiée: créer un index pour les logs des sept derniers jours, etc.
- Supprimer l’index inversé pour une partition de données spécifiée: supprimer l’index pour les logs d’il y a plus d’un mois, etc. (afin de libérer l’espace d’index).
Benchmarking
Nous avons testé Apache Doris sur des jeux de données disponibles publiquement contre Elasticsearch et ClickHouse.
Pour une comparaison équitable, nous nous assurons de l’uniformité des conditions de test, y compris l’outil de benchmarking, les jeux de données et le matériel.
Apache Doris vs. Elasticsearch
- Outil de benchmarking: ES Rally, l’outil de test officiel pour Elasticsearch
- Jeu de données: Logs du serveur HTTP de la Coupe du Monde de 1998 (jeu de données auto-contenu dans ES Rally)
- Taille des données (avant compression): 32G, 247 millions de lignes, 134 octets par ligne (en moyenne)
- Requête: 11 requêtes, y compris la recherche par mot-clé, la requête de plage, l’agrégation et le classement; Chaque requête est exécutée 100 fois de manière séquentielle.
- Environnement: 3 machines virtuelles en nuage × 16C 64G
Résultats d’Apache Doris:
- Vitesse d’écriture: 550 Mo/s,4,2 fois celle d’Elasticsearch
- Ratio de compression: 10:1
- Utilisation de l’espace de stockage: 20% de celle d’Elasticsearch
- Temps de réponse: 43% de celle d’Elasticsearch

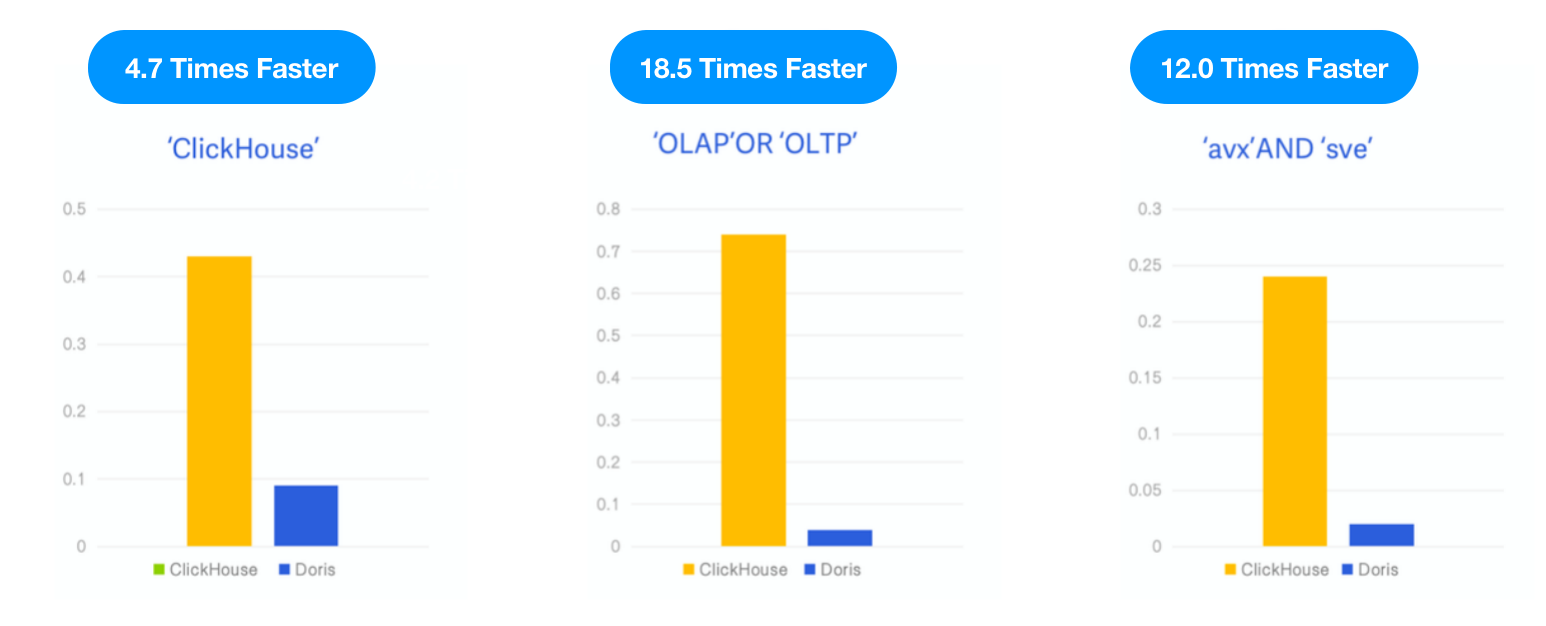
Apache Doris vs. ClickHouse
Comme ClickHouse a lancé un index inversé en tant que fonctionnalité expérimentale dans la version v23.1, nous avons testé Apache Doris avec le même jeu de données et les mêmes SQL décrits dans le blog ClickHouse et comparé les performances des deux sous les mêmes ressources de test, cas et outil.
- Données: 6,7G, 28,73 millions de lignes, le jeu de données Hacker News, format Parquet
- Requête: 3 recherches par mot-clé, comptage du nombre d’occurrences des mots-clés « ClickHouse, » « OLAP, » OR « OLTP, » et « avx » AND « sve ».
- Environnement: 1 machine virtuelle en nuage × 16C 64G
Résultat: Apache Doris était 4,7 fois, 18,5 fois et 12 fois plus rapide que ClickHouse dans les trois requêtes, respectivement.
Utilisation et Exemple
- Jeu de données: un million de records de commentaires de Hacker News
Étape 1: Spécifier l’index inversé à la table de données lors de la création de la table.
Paramètres:
- INDEX idx_comment (
comment): créer un index nommé « idx_comment » pour la colonne « comment » - USING INVERTED: spécifier l’index inversé pour la table
- PROPERTIES(« parser » = « english »): spécifier la langue de tokenisation en anglais
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Note : Vous pouvez ajouter un index à une table existante via ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). Contrairement à celui de l’index intelligent et de l’index secondaire, la création d’un index inversé ne concerne que la lecture de la colonne de commentaires, il peut donc être beaucoup plus rapide.)
Étape 2: Récupérer les mots « OLAP » et « OLTP » dans la colonne de commentaires avec MATCH_ALL. Le temps de réponse ici était 1/10 de celui de la correspondance dure avec like. (L’écart de performance s’élargit à mesure que le volume de données augmente.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
Pour plus d’introduction de fonctionnalités et guide d’utilisation, voir la documentation : Index Inversé
Récapitulatif
En un mot, ce qui contribue à la plus grande rentabilité d’Apache Doris, soit 10 fois supérieure à celle d’Elasticsearch, réside dans ses optimisations spécifiques au traitement analytique en ligne (OLAP) pour l’indexation inversée, soutenues par le moteur de stockage en colonnes, le cadre de traitement parallèle massif, le moteur de requêtes vectorisées et l’optimiseur basé sur les coûts d’Apache Doris.
Bien que nous soyons fiers de notre propre solution d’indexation inversée, nous comprenons que les benchmarks auto-publiés peuvent être controversés, donc nous sommes ouverts àretourde n’importe quel testeur tiers et voyons commentApache Dorisfonctionne dans des cas réels.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co