













Ceci fait partie de la transformation numérique d’un géant de l’immobilier. Au nom de la confidentialité, je ne vais pas révéler de données commerciales, mais vous aurez une vue détaillée de notre entrepôt de données et de nos stratégies d’optimisation.
Commençons.
Architecture
Logiquement, notre architecture de données peut être divisée en quatre parties.
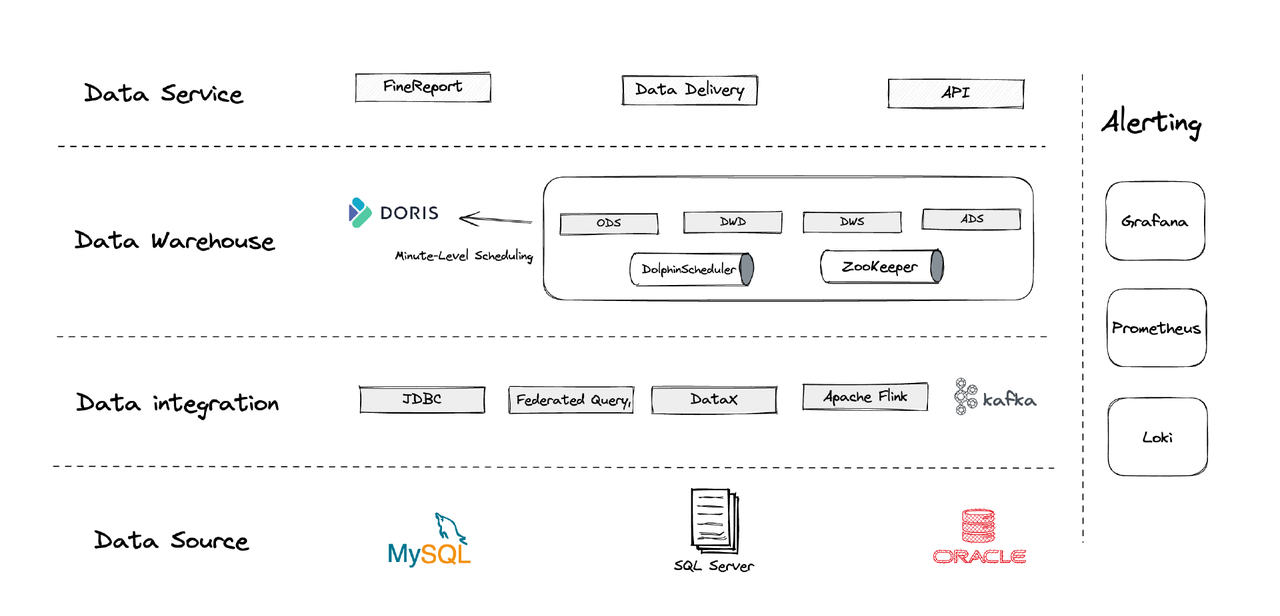
- Intégration des données: Cela est soutenu par Flink CDC, DataX et la fonctionnalité Multi-Catalog d’Apache Doris.
- Gestion des données: Nous utilisons Apache Dolphinscheduler pour la gestion du cycle de vie des scripts, les privilèges dans la gestion multi-locataires et la surveillance de la qualité des données.
- Alerte: Nous utilisons Grafana, Prometheus et Loki pour surveiller les ressources des composants et les journaux.
- Services de données: C’est là que les outils BI interviennent pour l’interaction avec les utilisateurs, comme les requêtes et l’analyse de données.
1. Tables
Nous créons nos tables de dimension et de fait autour de chaque entité opérationnelle dans l’entreprise, y compris les clients, les maisons, etc. Si une série d’activités impliquent la même entité opérationnelle, elles doivent être enregistrées par un seul champ. (C’est une leçon tirée de notre système de gestion des données précédemment chaotique.)
2. Couches
Notre entrepôt de données est divisé en cinq couches conceptuelles. Nous utilisons Apache Doris et Apache DolphinScheduler pour planifier les scripts DAG entre ces couches.

Chaque jour, les couches subissent une mise à jour globale en plus des mises à jour incrémentielles en cas de modifications dans les champs de statut historiques ou de synchronisation de données incomplète des tables ODS.
3. Stratégies de Mise à Jour Incrémentielle
(1) Définir where >= "activity time -1 jour ou -1 heure" au lieu de where >= "activity time
La raison en est de prévenir le dérive des données causée par l’écart de temps des scripts de planification. Disons, avec l’intervalle d’exécution réglé à 10 minutes, supposons que le script soit exécuté à 23:58:00 et qu’un nouvel élément de données arrive à 23:59:00. Si nous définissons where >= "activity time, cet élément de données du jour sera manquant.
(2) Récupérer l’ID du plus grand clé primaire de la table avant chaque exécution du script, stocker l’ID dans la table auxiliaire, et définir where >= "ID dans la table auxiliaire"
Ceci est pour éviter la duplication des données. La duplication des données pourrait se produire si vous utilisez le modèle de Clé Unique d’Apache Doris et désignez un ensemble de clés primaires car s’il y a des changements dans les clés primaires dans la table source, les changements seront enregistrés, et les données pertinentes seront chargées. Cette méthode peut résoudre ce problème, mais elle n’est applicable que lorsque les tables sources ont des clés primaires auto-incrémentales.
(3) Partitionner les tables
En ce qui concerne les données auto-incrémentales basées sur le temps, telles que les tables de journaux, il y a peut-être moins de changements dans les données historiques et les statuts, mais le volume de données est important, ce qui pourrait entraîner une pression computationnelle énorme sur les mises à jour globales et la création de snapshots. Par conséquent, il est préférable de partitionner de telles tables de sorte que pour chaque mise à jour incrémentale, nous n’ayons besoin de remplacer qu’une seule partition. (Il pourrait également être nécessaire de surveiller les écarts de données.)
4. Stratégies de mise à jour globale
(1) Supprimer la table
Vider la table puis ingérer toutes les données à partir de la table source. Cela s’applique aux petites tables et aux scénarios où il n’y a pas d’activité utilisateur en début de nuit.
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Il s’agit d’une opération atomique, et elle est recommandée pour les grandes tables. Avant chaque exécution d’un script, nous créons une table temporaire avec le même schéma, chargeons toutes les données dedans, puis remplaçons la table originale par elle.
Application
- Tâche ETL: toutes les minutes
- Configuration pour le premier déploiement: 8 nœuds, 2 frontends, 8 backends, déploiement hybride
- Configuration des nœuds: 32C * 60GB * 2TB SSD
Ceci est notre configuration pour des TBs de données legacy et des GBs de données incrémentales. Vous pouvez l’utiliser comme référence et échelonner votre cluster à partir de cette base. Le déploiement d’Apache Doris est simple. Vous n’avez pas besoin d’autres composants.
1. Pour intégrer les données hors ligne et les données de journal, nous utilisons DataX, qui prend en charge le format CSV et les lecteurs de nombreux systèmes de gestion de bases de données relationnelles, et Apache Doris fournit un DataX-Doris-Writer.

2. Nous utilisons Flink CDC pour synchroniser les données à partir des tables sources. Ensuite, nous agrégeons les métriques en temps réel en utilisant la Materialized View ou le modèle agrégé d’Apache Doris. Étant donné que nous n’avons besoin de traiter qu’une partie des métriques de manière en temps réel et que nous ne souhaitons pas générer trop de connexions bases de données, nous utilisons un seul job Flink pour maintenir plusieurs tables sources CDC. Ceci est réalisé grâce aux fonctionnalités de fusion de multiples sources et de synchronisation complète de la base de données de Dinky, ou vous pouvez implémenter vous-même une tâche de fusion de multiples sources Flink DataStream. Il est important de noter que Flink CDC et Apache Doris prennent en charge la modification du schéma.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. Nous utilisons des scripts SQL ou des scripts « Shell + SQL » et nous effectuons la gestion du cycle de vie des scripts. À l’étape ODS, nous écrivons un fichier de job DataX général et transmettons des paramètres pour chaque ingestion de table source au lieu d’écrire un job DataX pour chaque table source. De cette manière, nous facilitons grandement la maintenance. Nous gérons les scripts ETL d’Apache Doris sur DolphinScheduler, où nous effectuons également le contrôle de version. En cas d’erreurs dans l’environnement de production, nous pouvons toujours revenir en arrière.
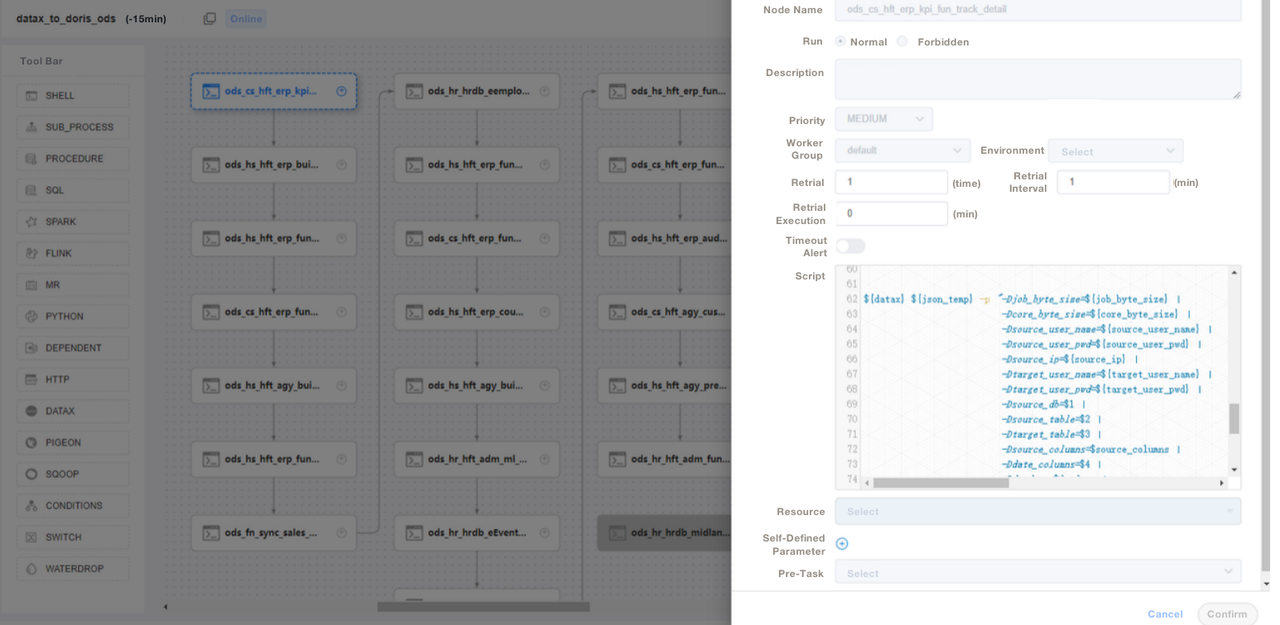
4. Après l’ingestion des données avec des scripts ETL, nous créons une page dans notre outil de reporting. Nous attribuons différents privilèges à différents comptes en utilisant SQL, y compris le privilège de modification des lignes, des champs et des dictionnaires globaux. Apache Doris prend en charge le contrôle des privilèges sur les comptes, ce qui fonctionne de la même manière que dans MySQL.
Nous utilisons également la sauvegarde de données Apache Doris pour la reprise après sinistre, les journaux d’audit Apache Doris pour surveiller l’efficacité de l’exécution des requêtes SQL, Grafana+Loki pour les alertes de métriques de cluster, et Supervisor pour surveiller les processus de démon des composants de nœud.
Optimisation
Ingestion de données
Nous utilisons DataX pour charger en continu les données hors ligne. Cela nous permet de régler la taille de chaque lot. La méthode Stream Load renvoie des résultats de manière synchrone, ce qui répond aux besoins de notre architecture. Si nous exécutons une importation de données asynchrone à l’aide de DolphinScheduler, le système pourrait supposer que le script a été exécuté, ce qui peut causer des problèmes. Si vous utilisez une méthode différente, nous recommandons d’exécuter show load dans le script shell et de vérifier l’état de filtrage regex pour voir si l’ingestion réussit.
Modèle de données
Nous adoptons le modèle Unique Key d’Apache Doris pour la plupart de nos tables. Le modèle Unique Key garantit l’idempotence des scripts de données et évite efficacement la duplication de données en amont.
Lecture de données externes
Nous utilisons la fonctionnalité Multi-Catalog d’Apache Doris pour nous connecter à des sources de données externes. Elle nous permet de créer des mappages de données externes au niveau du Catalog.
Optimisation des requêtes
Nous vous suggérons de placer les champs les plus fréquemment utilisés de types non caractères (tels que int et clauses where) dans les 36 premiers octets, afin de pouvoir filtrer ces champs en quelques millisecondes dans les requêtes ponctuelles.
Dictionnaire de données
Pour nous, il est important de créer un dictionnaire de données car cela réduit considérablement les coûts de communication entre personnel, ce qui peut être une source de problèmes lorsque vous avez une grande équipe. Nous utilisons le information_schema dans Apache Doris pour générer un dictionnaire de données. Avec cela, nous pouvons rapidement saisir l’ensemble des tableaux et des champs et ainsi augmenter l’efficacité du développement.
Performance
Temps d’ingestion des données hors ligne: En quelques minutes
Latence des requêtes: Pour les tableaux contenant plus de 100 millions de lignes, Apache Doris répond aux requêtes ad-hoc en une seconde et aux requêtes complexes en cinq secondes.
Consommation de ressources: Il suffit de peu de serveurs pour construire ce entrepôt de données. Le taux de compression de 70% d’Apache Doris nous permet de faire des économies considérables sur les ressources de stockage.
Expérience et Conclusion
En réalité, avant de passer à notre architecture de données actuelle, nous avons essayé Hive, Spark et Hadoop pour construire un entrepôt de données hors ligne. Il s’est avéré que Hadoop était de trop pour une entreprise traditionnelle comme la nôtre puisque nous n’avions pas trop de données à traiter. Il est important de trouver le composant qui vous convient le mieux.
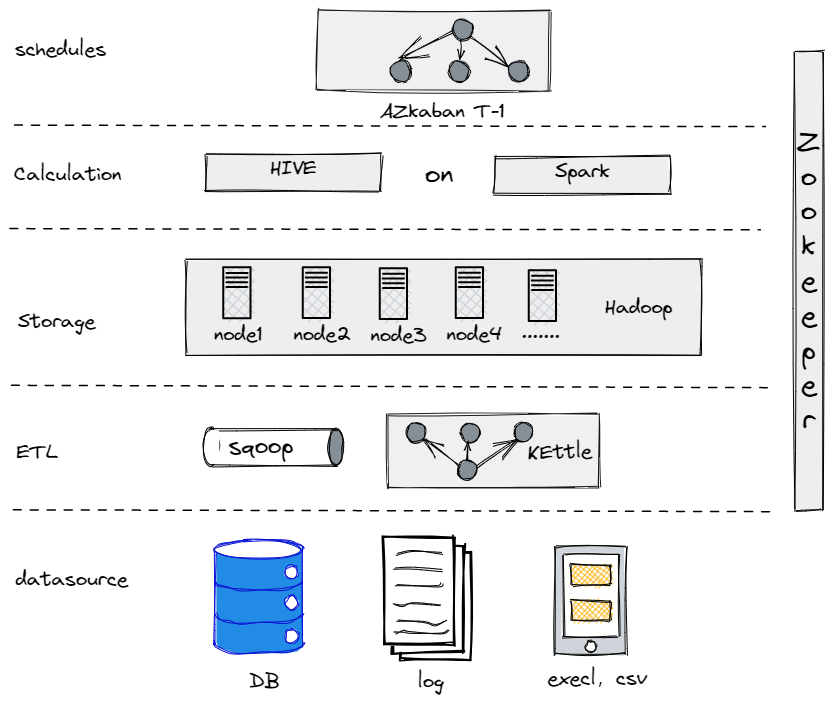
Notre Ancien Entrepôt de Données Hors Ligne
D’un autre côté, pour faciliter notre transition vers le big data, nous devons rendre notre plateforme de données aussi simple que possible en termes d’utilisation et de maintenance. C’est pourquoi nous avons opté pour Apache Doris. Elle est compatible avec le protocole MySQL et offre une vaste gamme de fonctions, ce qui nous évite de devoir développer nos propres UDF. De plus, elle est composée de seulement deux types de processus : les frontends et les backends, ce qui la rend facile à étendre et à suivre.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry