













L’essor de l’IA agentique a suscité un engouement autour des agents qui exécutent de manière autonome des tâches, font des recommandations et exécutent des flux de travail complexes mêlant IA et informatique traditionnelle. Mais créer de tels agents dans des environnements réels, axés sur les produits présente des défis qui vont au-delà de l’IA elle-même.
Sans une architecture soigneuse, les dépendances entre les composants peuvent créer des goulets d’étranglement, limiter la scalabilité et compliquer la maintenance à mesure que les systèmes évoluent. La solution réside dans le découplage des flux de travail, où les agents, l’infrastructure et d’autres composants interagissent de manière fluide sans dépendances rigides.
Ce type d’intégration flexible et évolutive nécessite un « langage » partagé pour l’échange de données — une architecture robuste orientée événements (EDA) alimentée par des flux d’événements. En organisant les applications autour des événements, les agents peuvent fonctionner dans un système réactif et découplé où chaque partie fait son travail de manière indépendante. Les équipes peuvent faire des choix technologiques librement, gérer les besoins de scalabilité séparément et maintenir des frontières claires entre les composants, permettant ainsi une véritable agilité.
Pour mettre ces principes à l’épreuve, j’ai développé PodPrep AI, un assistant de recherche alimenté par IA qui m’aide à me préparer pour des interviews de podcast sur Software Engineering Daily et Software Huddle. Dans cet article, je vais plonger dans la conception et l’architecture de PodPrep AI, montrant comment l’EDA et les flux de données en temps réel alimentent un système agentique efficace.
Remarque : Si vous souhaitez simplement consulter le code, rendez-vous sur mon dépôt GitHub ici.
Pourquoi une architecture orientée événements pour l’IA ?
Dans les applications d’IA du monde réel, une conception monolithique et étroitement couplée n’est pas viable. Bien que les preuves de concept ou les démonstrations utilisent souvent un système unique et unifié pour des raisons de simplicité, cette approche devient rapidement impraticable en production, notamment dans des environnements distribués. Les systèmes étroitement couplés créent des goulets d’étranglement, limitent la scalabilité et ralentissent l’itération — autant de défis critiques à éviter à mesure que les solutions d’IA se développent.
Considérons un agent d’IA typique.
Il peut avoir besoin de récupérer des données de plusieurs sources, de gérer l’ingénierie des invites et les flux de travail RAG, et d’interagir directement avec divers outils pour exécuter des flux de travail déterministes. L’orchestration requise est complexe, avec des dépendances sur plusieurs systèmes. Et si l’agent doit communiquer avec d’autres agents, la complexité n’en est que accrue. Sans une architecture flexible, ces dépendances rendent la mise à l’échelle et la modification presque impossibles.

En production, différentes équipes gèrent généralement différentes parties de la pile : MLOps et ingénierie des données gèrent le pipeline RAG, la science des données sélectionne les modèles, et les développeurs d’applications construisent l’interface et le backend. Une configuration étroitement couplée force ces équipes à des dépendances qui ralentissent la livraison et rendent la mise à l’échelle difficile. Idéalement, les couches d’application ne devraient pas avoir besoin de comprendre les détails internes de l’IA ; elles devraient simplement consommer les résultats lorsque cela est nécessaire.
De plus, les applications d’IA ne peuvent pas fonctionner en isolation. Pour une valeur réelle, les informations de l’IA doivent circuler de manière transparente à travers les plateformes de données clients (CDP), les CRM, les outils d’analyse, et plus encore. Les interactions avec les clients devraient déclencher des mises à jour en temps réel, alimentant directement d’autres outils pour l’action et l’analyse. Sans une approche unifiée, l’intégration des informations à travers les plateformes devient un patchwork difficile à gérer et impossible à mettre à l’échelle.
L’IA alimentée par EDA relève ces défis en créant un « système nerveux central » pour les données. Avec EDA, les applications diffusent des événements au lieu de se fier à des commandes enchaînées. Cela découple les composants, permettant aux données de circuler de manière asynchrone où cela est nécessaire, permettant à chaque équipe de travailler de manière indépendante. L’EDA favorise une intégration transparente des données, une croissance évolutive et une résilience, en en faisant une base puissante pour les systèmes d’IA modernes.
Conception d’un Agent de Recherche Alimenté par l’IA Évolutif
Au cours des deux dernières années, j’ai animé des centaines de podcasts sur Software Engineering Daily, Software Huddle, et Partially Redacted.
Pour me préparer à chaque podcast, je mène un processus de recherche approfondie pour préparer un briefing de podcast contenant mes réflexions, des informations sur l’invité et le sujet, ainsi qu’une série de questions potentielles. Pour construire ce briefing, je recherche généralement l’invité et l’entreprise pour laquelle il travaille, écoute d’autres podcasts auxquels il aurait pu participer, lis des articles de blog qu’il a écrits, et me renseigne sur le sujet principal que nous discuterons.
J’essaie d’intégrer des liens vers d’autres podcasts que j’ai animés ou mon expérience liée au sujet ou à des sujets similaires. Tout ce processus prend beaucoup de temps et d’efforts. Les grandes opérations de podcast ont des chercheurs dédiés et des assistants qui font ce travail pour l’animateur. Je ne gère pas ce genre d’opération ici. Je dois tout faire moi-même.
Pour remédier à cela, j’ai voulu construire un agent qui pourrait faire ce travail pour moi. En gros, l’agent ressemblerait à l’image ci-dessous.

Je fournis des matériaux sources de base comme le nom de l’invité, l’entreprise, les sujets sur lesquels je veux me concentrer, quelques URL de référence comme des articles de blog et des podcasts existants, et ensuite un peu de magie de l’IA opère, et ma recherche est complète.
Cette idée simple m’a amené à créer PodPrep AI, mon assistant de recherche alimenté par l’IA qui ne me coûte que des jetons.
Le reste de cet article discute de la conception de PodPrep AI, en commençant par l’interface utilisateur.
Construction de l’Interface Utilisateur de l’Agent
J’ai conçu l’interface de l’agent comme une application web où je peux facilement saisir les matériaux sources pour le processus de recherche. Cela inclut le nom de l’invité, leur entreprise, le sujet de l’interview, tout contexte supplémentaire, et des liens vers des blogs pertinents, des sites web et des interviews de podcasts précédentes.
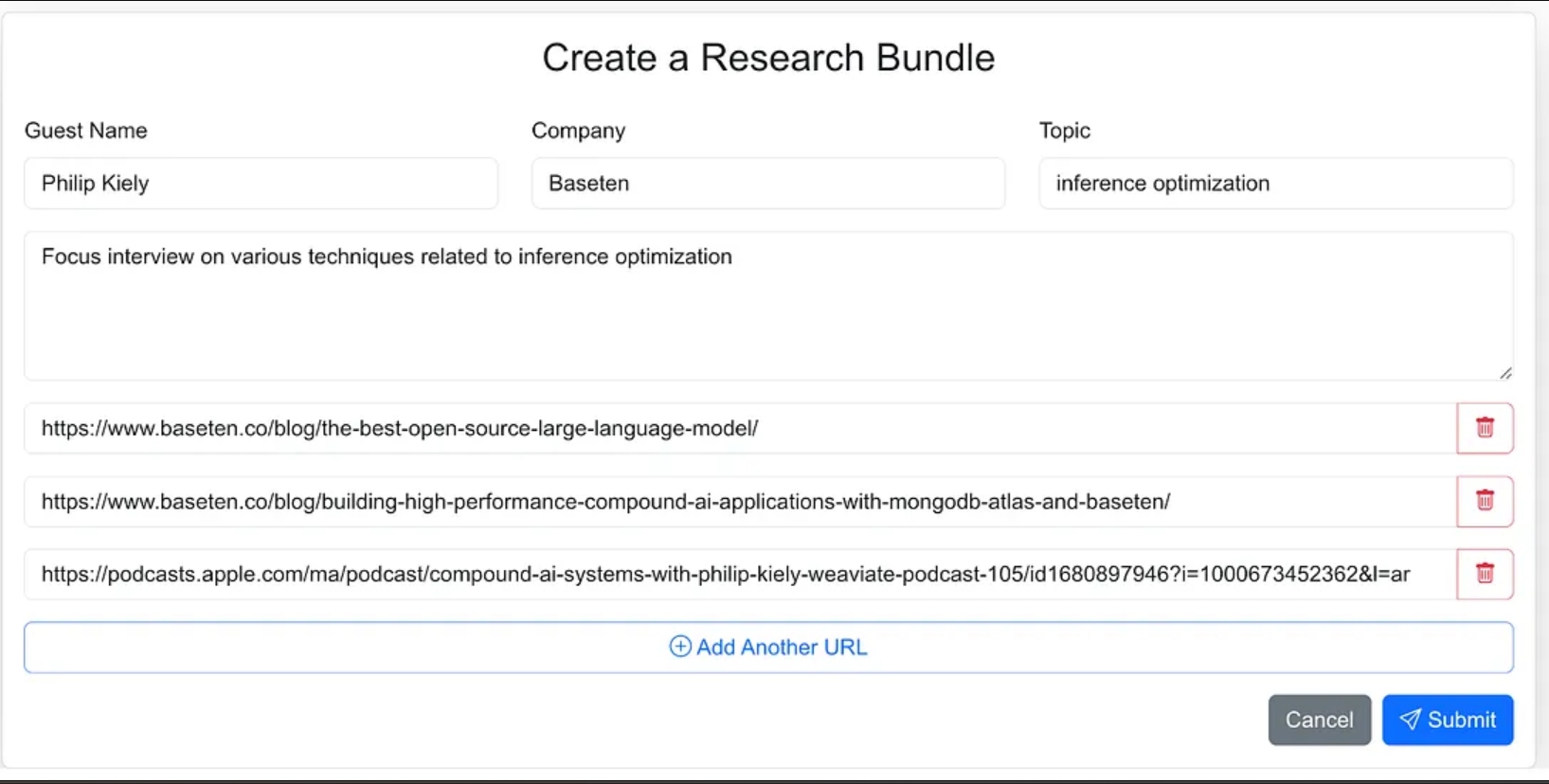
J’aurais pu donner moins d’instructions à l’agent et dans le cadre du flux de travail de l’agent le laisser trouver les matériaux sources, mais pour la version 1.0, j’ai décidé de fournir les URLs sources.
L’application web est une application standard à trois niveaux construite avec Next.js et MongoDB pour la base de données de l’application. Elle ne sait rien sur l’IA. Elle permet simplement à l’utilisateur d’entrer de nouveaux ensembles de recherche et ceux-ci apparaissent dans un état de traitement jusqu’à ce que le processus agentique ait terminé le flux de travail et peuplé un résumé de recherche dans la base de données de l’application.
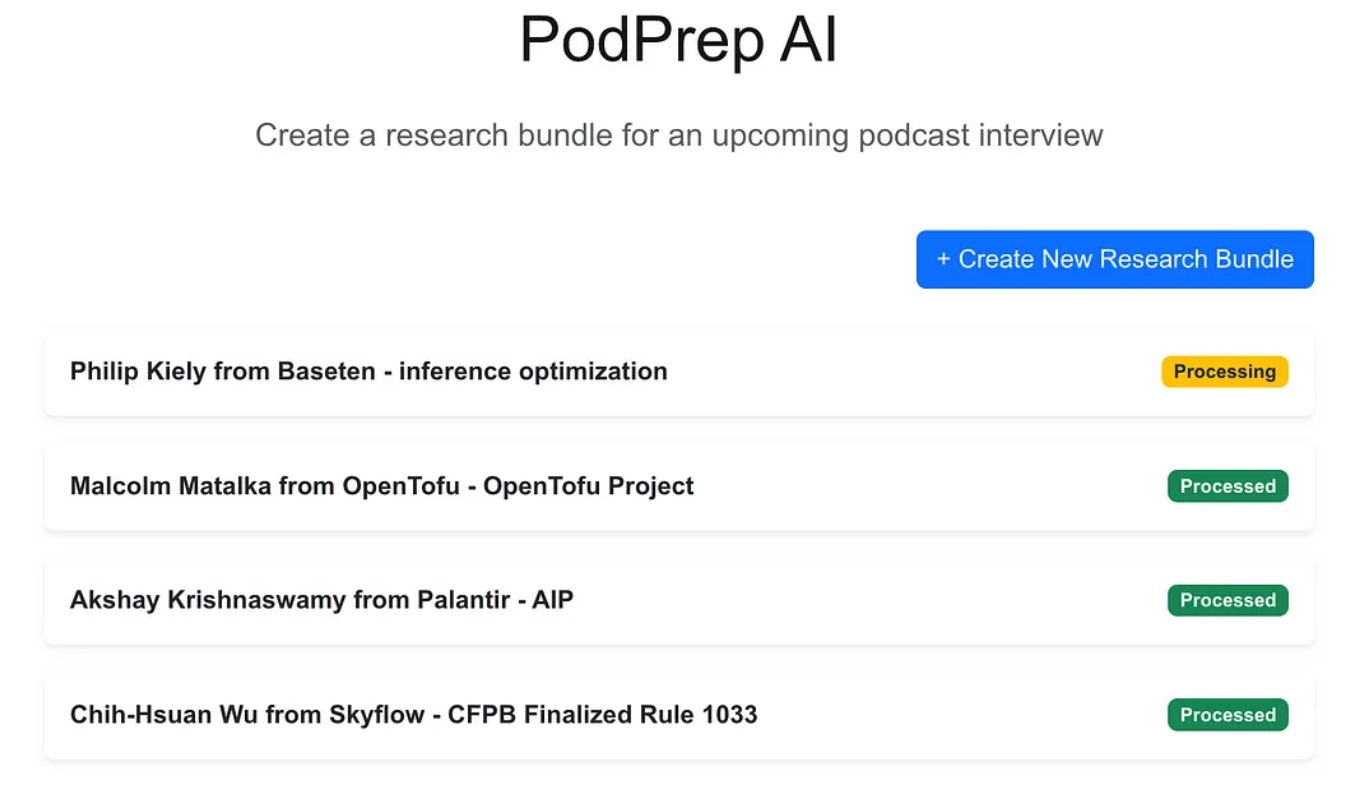
Une fois que la magie de l’IA est terminée, je peux accéder à un document de briefing pour l’entrée comme montré ci-dessous.

Création du Flux de Travail Agentique
Pour la version 1.0, je voulais pouvoir effectuer trois actions principales pour construire le résumé de recherche :
- Pour toute URL de site web, article de blog ou podcast, récupérer le texte ou le résumé, diviser le texte en morceaux de taille raisonnable, générer des embeddings et stocker la représentation vectorielle.
- Pour tout texte extrait des URLs de sources de recherche, extraire les questions les plus intéressantes et les stocker.
- Générer un résumé de recherche de podcast combinant le contexte le plus pertinent basé sur les embeddings, les meilleures questions posées précédemment, et toute autre information qui faisait partie de l’entrée de l’ensemble.
L’image ci-dessous montre l’architecture de l’application web au flux de travail agentique.
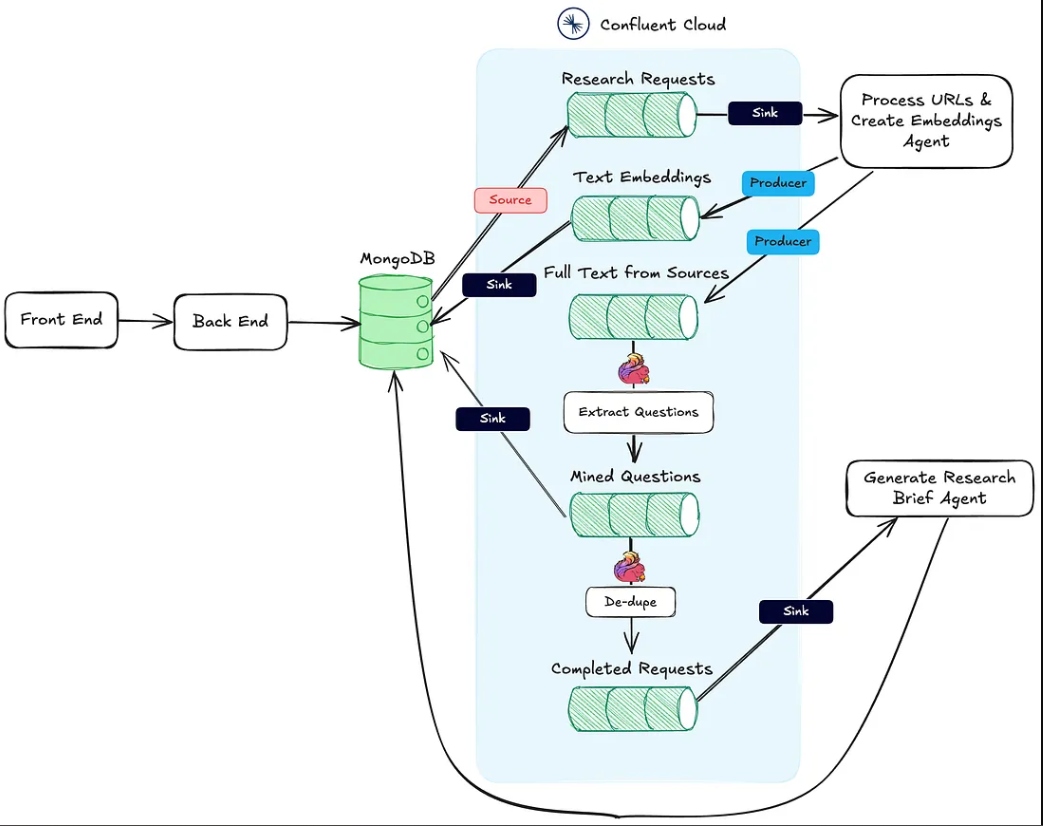
L’action #1 mentionnée ci-dessus est soutenue par le point de terminaison HTTP Process URLs & Create Embeddings Agent.
L’action #2 est réalisée en utilisant Flink et le support de modèle d’IA intégré dans Confluent Cloud.
Enfin, l’Action #3 est exécutée par le Agent de Génération de Note de Recherche, également un point de terminaison HTTP, qui est appelé une fois que les deux premières actions sont terminées.
Dans les sections suivantes, je discute de chacune de ces actions en détail.
L’Agent de Traitement des URLs et de Création d’Incorporations
Cet agent est chargé d’extraire du texte à partir des URLs sources de recherche et du pipeline d’incorporation vectorielle. Voici le flux global de ce qui se passe en coulisses pour traiter les documents de recherche.

Une fois qu’un ensemble de recherche est créé par l’utilisateur et enregistré dans MongoDB, un connecteur source MongoDB produit des messages vers un sujet Kafka appelé demandes-de-recherche. C’est ce qui lance le flux de travail agentique.
Chaque requête post vers le point de terminaison HTTP contient les URLs de la demande de recherche et la clé primaire dans la collection des ensembles de recherche MongoDB.
L’agent boucle à travers chaque URL et s’il ne s’agit pas d’un podcast Apple, il extrait le HTML de la page entière. Comme je ne connais pas la structure de la page, je ne peux pas compter sur les bibliothèques d’analyse HTML pour trouver le texte pertinent. Au lieu de cela, j’envoie le texte de la page au modèle gpt-4o-mini avec une température de zéro en utilisant le prompt ci-dessous pour obtenir ce dont j’ai besoin.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Pour les podcasts, j’ai besoin de faire un peu plus de travail.
Rétro-ingénierie des URLs de Podcast Apple
Pour extraire des données des épisodes de podcast, nous devons d’abord convertir l’audio en texte en utilisant le modèle Whisper. Mais avant de pouvoir le faire, nous devons localiser le fichier MP3 réel de chaque épisode de podcast, le télécharger et le découper en morceaux de 25 Mo ou moins (la taille maximale pour Whisper).
Le défi est qu’Apple ne fournit pas de lien MP3 direct pour ses épisodes de podcast. Cependant, le fichier MP3 est disponible dans le flux RSS original du podcast, et nous pouvons trouver ce flux de manière programmatique en utilisant l’ID de podcast d’Apple.
Par exemple, dans l’URL ci-dessous, la partie numérique après /id est l’ID unique d’Apple du podcast :
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
En utilisant l’API d’Apple, nous pouvons rechercher l’ID du podcast et récupérer une réponse JSON contenant l’URL du flux RSS :
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
Une fois que nous avons le XML du flux RSS, nous le recherchons pour l’épisode spécifique. Comme nous n’avons que l’URL de l’épisode d’Apple (et non le titre réel), nous utilisons le slug du titre de l’URL pour localiser l’épisode dans le flux et récupérer son URL MP3.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Maintenant avec le texte provenant des articles de blog, des sites Web et des MP3 disponibles, l’agent utilise le diviseur de texte récursif de LangChain pour diviser le texte en morceaux et générer les embeddings à partir de ces morceaux. Les morceaux sont publiés dans le sujet text-embeddings et envoyés à MongoDB.
- Note : J’ai choisi d’utiliser MongoDB comme base de données pour mon application et base de données vectorielle. Cependant, en raison de l’approche EDA que j’ai adoptée, ces systèmes peuvent facilement être distincts, et il suffit de changer le connecteur de sink du sujet Text Embeddings.
En plus de créer et de publier les embeddings, l’agent publie également le texte des sources sur un sujet appelé full-text-from-sources. La publication sur ce sujet déclenche l’Action #2.
Extraction des questions avec Flink et OpenAI
Apache Flink est un framework de traitement de flux open-source conçu pour gérer de gros volumes de données en temps réel, idéal pour les applications à haut débit et faible latence. En associant Flink à Confluent, nous pouvons intégrer des LLMs comme le GPT d’OpenAI directement dans les flux de travail en continu. Cette intégration permet des flux de travail RAG en temps réel, garantissant que le processus d’extraction des questions fonctionne avec les données les plus récentes disponibles.
Avoir le texte source d’origine dans le flux nous permet également d’introduire de nouveaux flux de travail ultérieurement qui utilisent les mêmes données, améliorant le processus de génération de résumés de recherche ou l’envoyant à des services en aval comme un entrepôt de données. Cette configuration flexible nous permet de superposer des fonctionnalités supplémentaires d’IA et non-IA au fil du temps sans avoir besoin de refondre le pipeline central.
Dans PodPrep AI, j’utilise Flink pour extraire des questions à partir de textes extraits d’URL sources.
Configurer Flink pour appeler un LLM implique de configurer une connexion via l’interface en ligne de commande de Confluent. Voici un exemple de commande pour configurer une connexion OpenAI, bien que plusieurs options soient disponibles.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Une fois que la connexion est établie, je peux créer un modèle soit dans la Console Cloud soit dans l’interpréteur de commandes Flink SQL. Pour l’extraction des questions, je configure le modèle en conséquence.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
Avec le modèle prêt, j’utilise la fonction ml_predict intégrée de Flink pour générer des questions à partir du matériel source, en écrivant la sortie dans un flux appelé mined-questions, qui se synchronise avec MongoDB pour une utilisation ultérieure.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink aide également à suivre quand tous les matériaux de recherche ont été traités, déclenchant la génération du briefing de recherche. Cela se fait en écrivant dans un flux completed-requests une fois que les URL dans mined-questions correspondent à ceux du flux des sources de texte intégral.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
À mesure que des messages sont écrits dans completed-requests, l’identifiant unique du regroupement de recherche est envoyé à l’agent Générer le Briefing de Recherche.
L’agent Générer le Briefing de Recherche
Cet agent prend tous les matériaux de recherche les plus pertinents disponibles et utilise un LLM pour créer un briefing de recherche. Voici le flux d’événements de haut niveau qui se déroulent pour créer un briefing de recherche.

Schéma de flux pour l’agent Générer le Briefing de Recherche
Explorons quelques-unes de ces étapes. Pour construire l’invite pour le LLM, je combine les questions extraites, le sujet, le nom de l’invité, le nom de l’entreprise, une invite système pour l’orientation, et le contexte stocké dans la base de données vectorielle qui est le plus sémantiquement similaire au sujet du podcast.
Étant donné que le regroupement de recherche a des informations contextuelles limitées, il est difficile d’extraire le contexte le plus pertinent directement du magasin de vecteurs. Pour remédier à cela, j’ai demandé à LLM de générer une requête de recherche pour localiser le contenu le plus pertinent, comme le montre le nœud « Créer une requête de recherche » dans le schéma.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
En utilisant la requête générée par LLM, je crée un plongement et recherche MongoDB à travers un index de vecteurs, en filtrant par l’bundleId pour limiter la recherche aux documents pertinents pour le podcast spécifique.
Avec les meilleures informations contextuelles identifiées, je crée un message et génère le rapport de recherche, en enregistrant le résultat dans MongoDB pour que l’application Web puisse l’afficher.
Points à noter sur la mise en œuvre
J’ai écrit à la fois l’application frontale pour PodPrep AI et les agents en Javascript, mais dans un scénario réel, l’agent serait probablement dans une langue différente comme Python. De plus, pour des raisons de simplicité, à la fois l’agent de traitement des URL et création de plongements et l’agent de génération de rapport de recherche sont dans le même projet fonctionnant sur le même serveur web. Dans un système de production réel, ceux-ci pourraient être des fonctions sans serveur, fonctionnant de manière indépendante.
Pensées finales
La construction de PodPrep AI met en lumière comment une architecture orientée événements permet aux applications d’IA du monde réel de s’adapter et de se développer de manière fluide. Avec Flink et Confluent, j’ai créé un système qui traite les données en temps réel, alimentant un flux de travail piloté par l’IA sans dépendances rigides. Cette approche découplée permet aux composants de fonctionner de manière indépendante, tout en restant connectés via des flux d’événements – essentiels pour des applications complexes et distribuées où différentes équipes gèrent différentes parties de la pile.
Dans l’environnement actuel piloté par l’IA, l’accès à des données fraîches et en temps réel à travers les systèmes est essentiel. L’EDA sert de « système nerveux central » pour les données, permettant une intégration transparente et une flexibilité à mesure que le système se développe.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink