













AWS Lambda est un puissant service de calcul sans serveur qui vous permet d’exécuter du code sans gérer d’infrastructure, afin que vous puissiez vous concentrer uniquement sur l’écriture de code sans vous soucier de la fourniture ou de la maintenance des serveurs.
Dans ce tutoriel, nous explorerons AWS Lambda, de la configuration de votre première fonction à son intégration avec d’autres services AWS. Que vous traitiez des flux de données ou que vous construisiez des API, ce guide vous aidera à commencer avec des déploiements sans serveur en utilisant AWS Lambda.
Qu’est-ce qu’AWS Lambda ?
AWS Lambda est une plateforme de calcul sans serveur fournie par Amazon Web Services (AWS) qui permet aux développeurs d’exécuter du code sans provisionner ou gérer des serveurs.AWS Lambda facilite cela en allouant dynamiquement des ressources pour exécuter vos fonctions uniquement lorsque cela est nécessaire, vous facturant en fonction de l’utilisation plutôt que de la capacité serveur pré-allouée.
Cette approche de développement d’applications supprime le besoin de configuration d’infrastructure traditionnelle, vous permettant de vous concentrer uniquement sur l’écriture et le déploiement de code.
AWS Lambda est basé sur des événements, ce qui signifie qu’il est déclenché par des événements spécifiques provenant d’autres services AWS, le rendant idéal pour la création de solutions réactives, évolutives et rentables.
Les méthodes de déploiement traditionnelles nécessitent la configuration et la gestion de serveurs, ce qui implique la mise à l’échelle, la mise à jour et le patching. Ces tâches peuvent être chronophages, coûteuses et moins efficaces pour des charges de travail sporadiques. En revanche, le déploiement sans serveur supprime ces surcharges, offrant une mise à l’échelle automatique et une haute disponibilité prêtes à l’emploi.
Caractéristiques d’AWS Lambda
- Architecture basée sur les événements: Les fonctions AWS Lambda sont invoquées en réponse à des événements tels que des changements de données, des requêtes HTTP ou des mises à jour des ressources AWS.
- Prise en charge de plusieurs langages d’exécution: Lambda prend en charge divers langages d’exécution, dont Python, Node.js, Java, Go, Ruby et .NET. Les développeurs peuvent également apporter leur propre langage d’exécution en utilisant l’API de runtime AWS Lambda, ce qui en fait une plateforme polyvalente pour divers cas d’utilisation.
- Scalabilité automatique: AWS Lambda ajuste automatiquement l’échelle de votre application en fonction de la demande. Que vous traitiez un seul événement ou que vous gériez des milliers simultanément, Lambda ajuste dynamiquement les ressources de calcul.
- Tarification à l’utilisation : Les coûts sont déterminés par le nombre de requêtes et le temps d’exécution de vos fonctions. Cela élimine le besoin d’investissements initiaux et garantit que vous ne payez que pour ce que vous utilisez.
- Sécurité intégrée : Lambda fonctionne avec AWS Identity and Access Management (IAM), garantissant un contrôle d’accès fin et des interactions sécurisées entre vos fonctions et d’autres services AWS.
Cas d’utilisation courants de Lambda
- Traitement des flux de données: AWS Lambda s’intègre avec Amazon Kinesis pour traiter et analyser des données en continu en temps réel. Par exemple, vous pouvez surveiller des dispositifs IoT ou traiter des fichiers journaux dynamiquement.
- Construction d’API RESTful: Les fonctions Lambda peuvent être associées à AWS API Gateway pour créer des APIs évolutives pour des applications web et mobile. Cette configuration est couramment utilisée pour gérer l’authentification des utilisateurs, interroger des bases de données ou générer du contenu dynamique.
- Automatisation des flux de travail: Automatisez des flux de travail complexes en déclenchant des fonctions Lambda en fonction d’événements provenant de services comme S3, DynamoDB ou CloudWatch. Par exemple, vous pouvez redimensionner des images téléchargées sur S3 ou archiver automatiquement d’anciens enregistrements de base de données.
- Gestion des événements dans les pipelines de données: Vous pouvez utiliser Lambda pour gérer des événements de données en temps réel, tels que le traitement de nouveaux téléchargements dans un compartiment S3, la transformation des données avant le stockage ou l’enrichissement des flux de données avec des appels d’API externes.
- Traitement backend sans serveur : Lambda est couramment utilisé pour déléguer des tâches backend telles que la validation des données (Extraire, Transformer, Charger), ou l’envoi de notifications via Amazon SNS ou SES.
Comment fonctionne AWS Lambda ?
AWS Lambda fonctionne sur un modèle basé sur des événements, ce qui signifie qu’il exécute du code en réponse à des déclencheurs ou événements spécifiques. La clé de la fonctionnalité de Lambda est son intégration avec d’autres services AWS et sa capacité à exécuter des fonctions à la demande. Plongeons dans les mécanismes de fonctionnement d’AWS Lambda étape par étape :
Un exemple de diagramme d’architecture utilisant Lambda et d’autres services AWS essentiels. Source de l’image : AWS.
1. Déclenchement des fonctions AWS Lambda
Les fonctions AWS Lambda sont initiées par des événements provenant de divers services AWS ou systèmes externes. Des exemples courants de sources d’événements incluent :
- API Gateway : Lorsqu’un utilisateur envoie une requête HTTP (par exemple, une requête GET ou POST) à votre point de terminaison API Gateway, Lambda peut exécuter une fonction pour traiter la requête—par exemple, un point de terminaison API RESTful pour créer un utilisateur dans une base de données.
- Événements S3: Les fonctions Lambda peuvent répondre à des actions telles que le téléchargement, la suppression ou la modification d’un objet dans un compartiment S3. Par exemple, elles peuvent redimensionner des images ou convertir des formats de fichier après qu’une image a été téléchargée dans un compartiment S3.
- Flux DynamoDB: Toutes modifications apportées aux tables DynamoDB, telles que les insertions, mises à jour ou suppressions, peuvent déclencher une fonction Lambda. Par exemple, déclencher un pipeline d’analyse lorsque de nouvelles lignes sont ajoutées à une table DynamoDB.
- Applications personnalisées: Vous pouvez invoquer directement des fonctions Lambda en utilisant des SDK, la CLI ou des requêtes HTTP, ce qui vous permet de vous intégrer avec des systèmes externes.
2. Environnement d’exécution
Lorsqu’un événement déclenche une fonction Lambda, AWS crée automatiquement un environnement d’exécution pour exécuter le code. Cet environnement inclut :
- Votre code de fonction : Le code que vous avez écrit pour votre tâche spécifique.
- Les ressources allouées : Le CPU et la mémoire (configurables) sont assignés dynamiquement en fonction des besoins de la fonction.
- Dépendances : Toutes les bibliothèques externes ou packages spécifiés lors du déploiement sont inclus.
3. Concurrence et mise à l’échelle
AWS Lambda prend en charge la mise à l’échelle automatique en exécutant plusieurs instances de votre fonction en parallèle. Il parvient à s’adapter de manière transparente sans aucune configuration. Voici comment fonctionne la concurrence :
- Si votre fonction doit traiter 100 événements simultanément, Lambda créera autant d’environnements d’exécution que nécessaire (jusqu’à la limite de concurrence).
4. Intégration avec d’autres services AWS
AWS Lambda s’intègre étroitement avec les services AWS pour construire des solutions robustes de bout en bout :
- Interactions avec la base de données: Lambda peut lire/écrire des données dans DynamoDB ou RDS pendant l’exécution.
- Services de messagerie: Lambda peut déclencher des notifications via SNS ou envoyer des messages aux files d’attente SQS pour un traitement ultérieur.
- Surveillance et journalisation: CloudWatch capture tous les journaux, les métriques et les détails des erreurs des fonctions Lambda, vous permettant de surveiller et de résoudre les problèmes de performance.
Maintenant, commençons par configurer votre première fonction Lambda !
Configuration de AWS Lambda
Prérequis
- Compte AWS : Assurez-vous d’avoir un compte AWS actif. Inscrivez-vous ici.
- Configuration de l’utilisateur IAM : Créez un utilisateur IAM avec des autorisations pour AWS Lambda. Suivez le guide IAM.
Configuration de l’environnement de développement
- Installer AWS CLI: Téléchargez et installez AWS CLI. Configurez-le en utilisant vos identifiants IAM.
- Configurer Python ou Node.js: Installez Python ou Node.js en fonction de votre environnement d’exécution préféré. AWS Lambda prend en charge plusieurs environnements d’exécution. Nous utiliserons l’environnement d’exécution Python dans ce tutoriel.
Étape 1 : Accédez à la console AWS Lambda
- Connectez-vous à la Console de gestion AWS.
- Accédez au service Lambda.
Tableau de navigation dans la console AWS.
Cliquez sur Lambda dans le menu de navigation pour voir le tableau de bord :
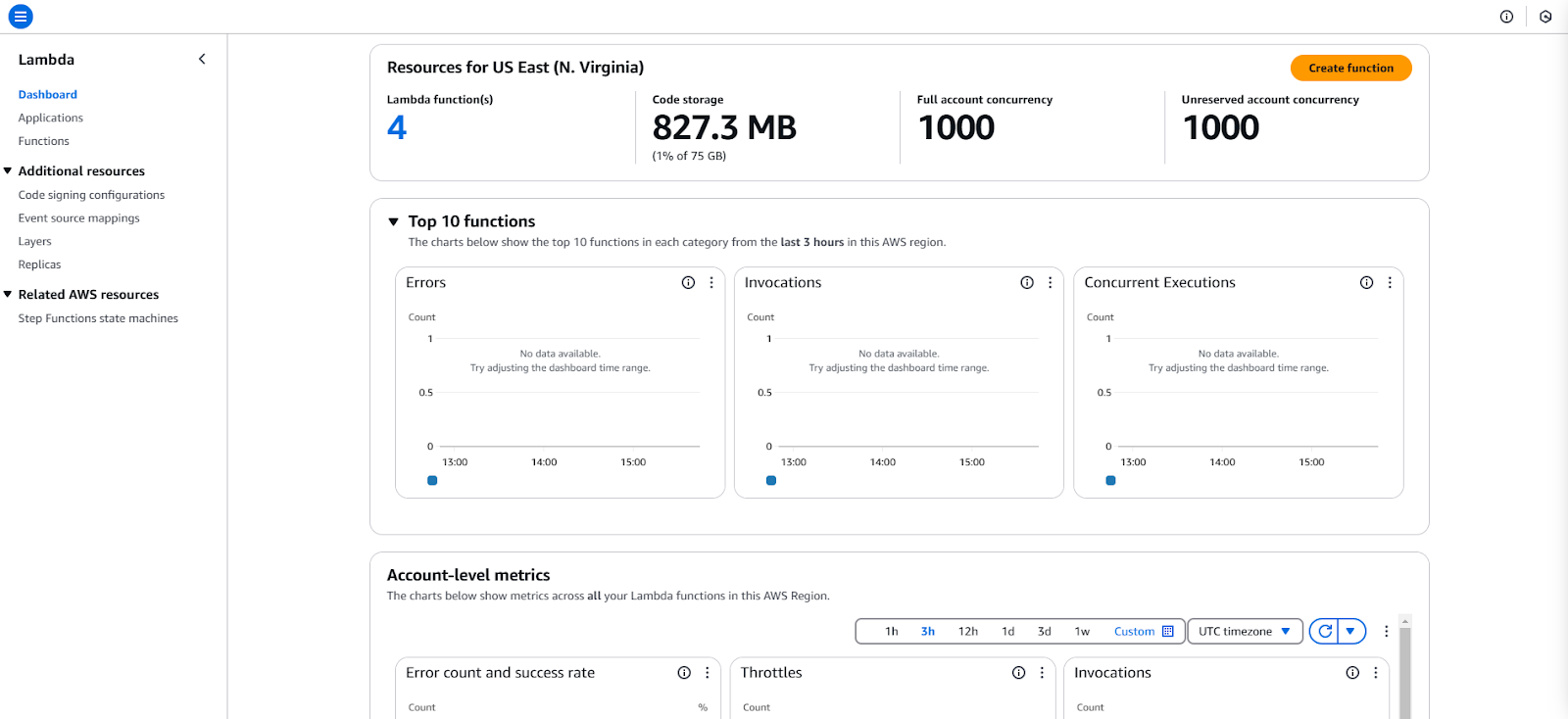
Tableau de bord AWS Lambda dans la console AWS.
Étape 2 : Créer une nouvelle fonction
- CliquezCréer une fonction.
- Choisissez « Auteur à partir de zéro ».
- Donnez un nom à votre fonction.
- Sélectionnez un environnement d’exécution (par exemple, Python 3.11).
- Cliquez sur le bouton Créer la fonction.
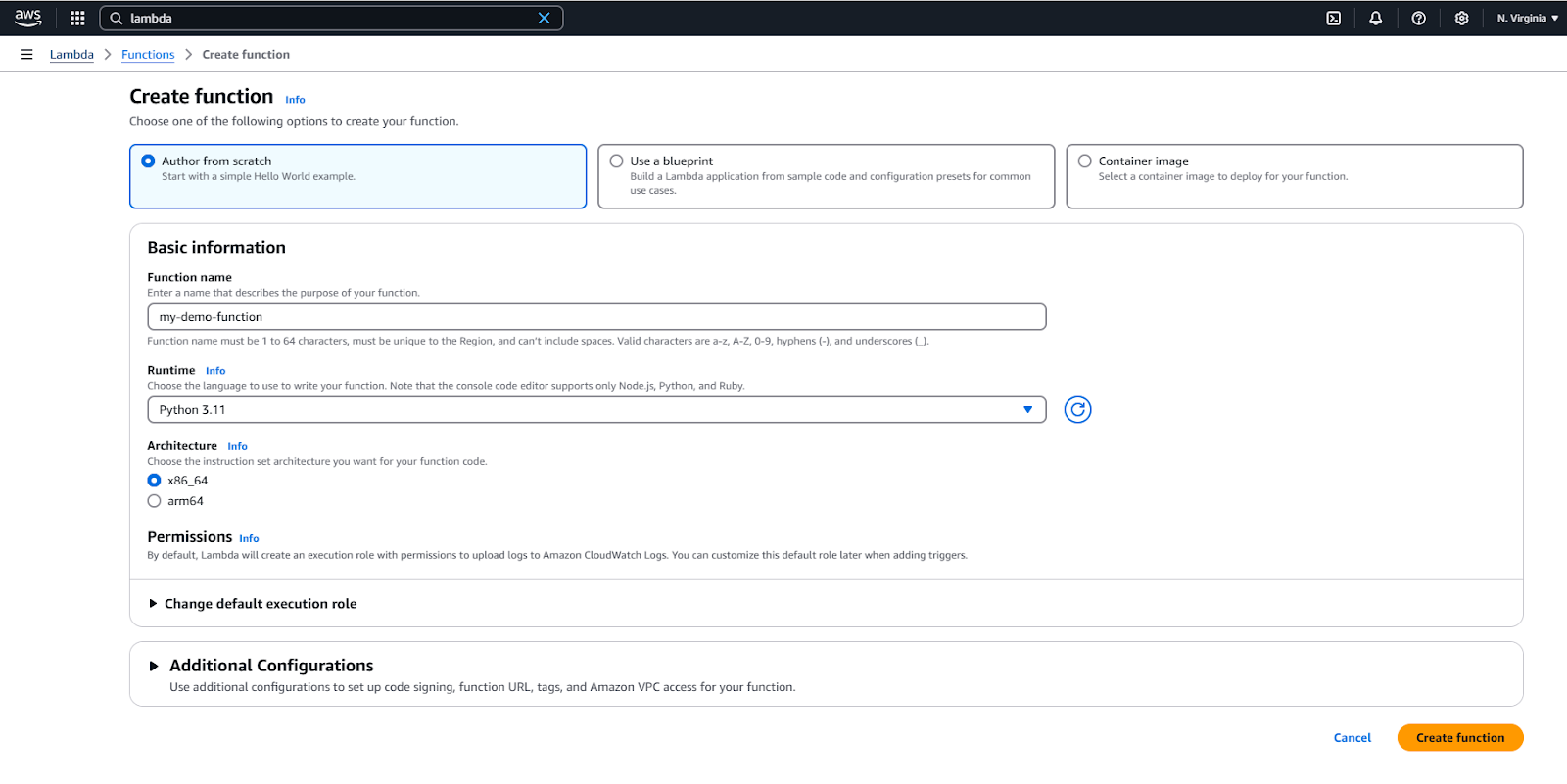
Créez une nouvelle fonction AWS Lambda.
Cela prendra quelques secondes. Une fois la fonction créée, vous verrez un message de succès en haut.
Étape 3 : Écrivez le code de votre fonction
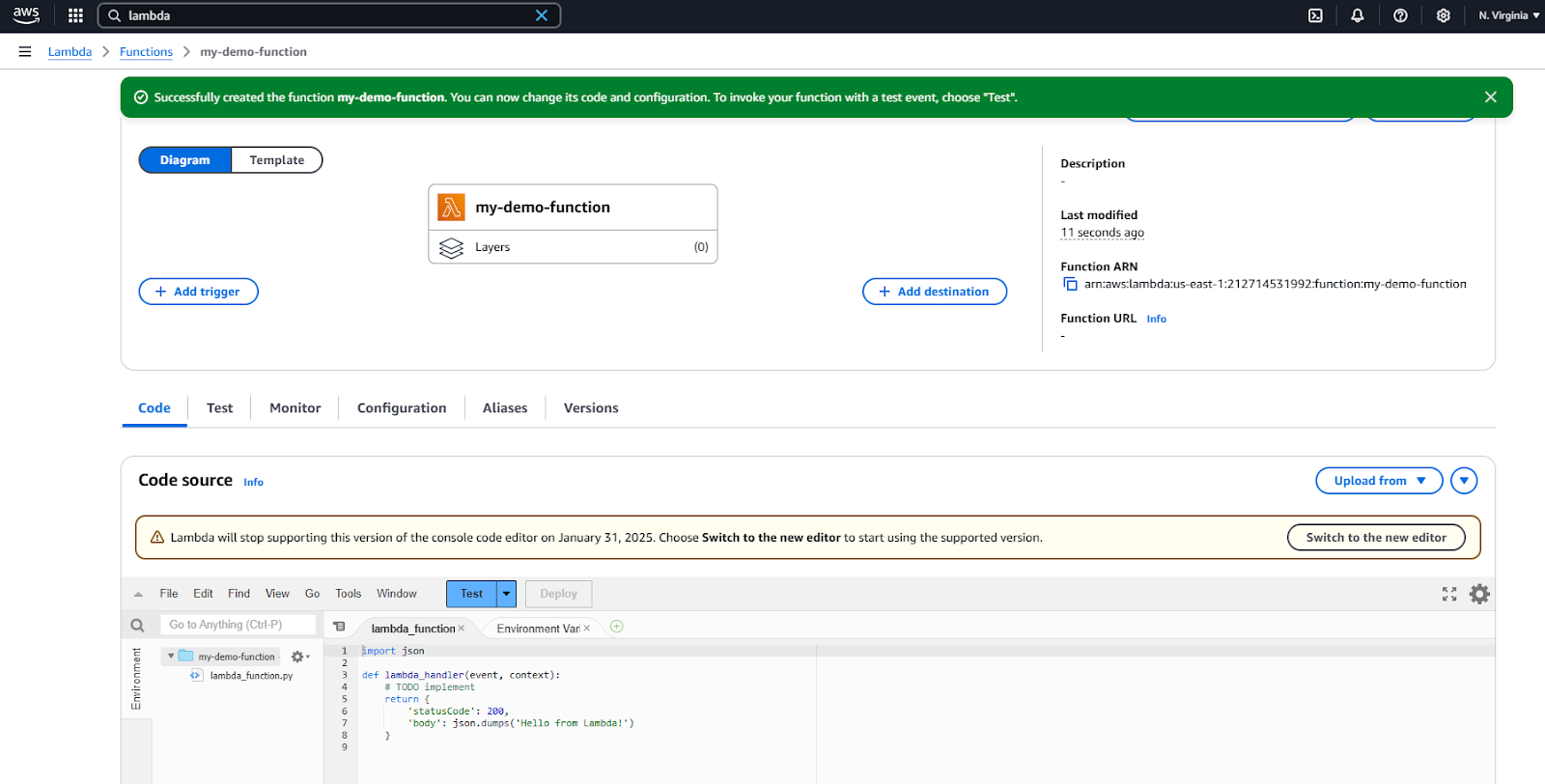
IDE de navigateur AWS Lambda pour une édition de code simple.
Étape 4 : Testez votre fonction Lambda
À ce stade, cette fonction renvoie simplement la chaîne “Bonjour de Lambda !”.
Il n’y a aucune logique, aucune dépendance, rien.
Nous avons un script Python appelé lambda_function.py qui contient la fonction nommée lambda_handler() qui renvoie une chaîne.
Nous pouvons maintenant le tester en cliquant simplement sur le bouton Test.
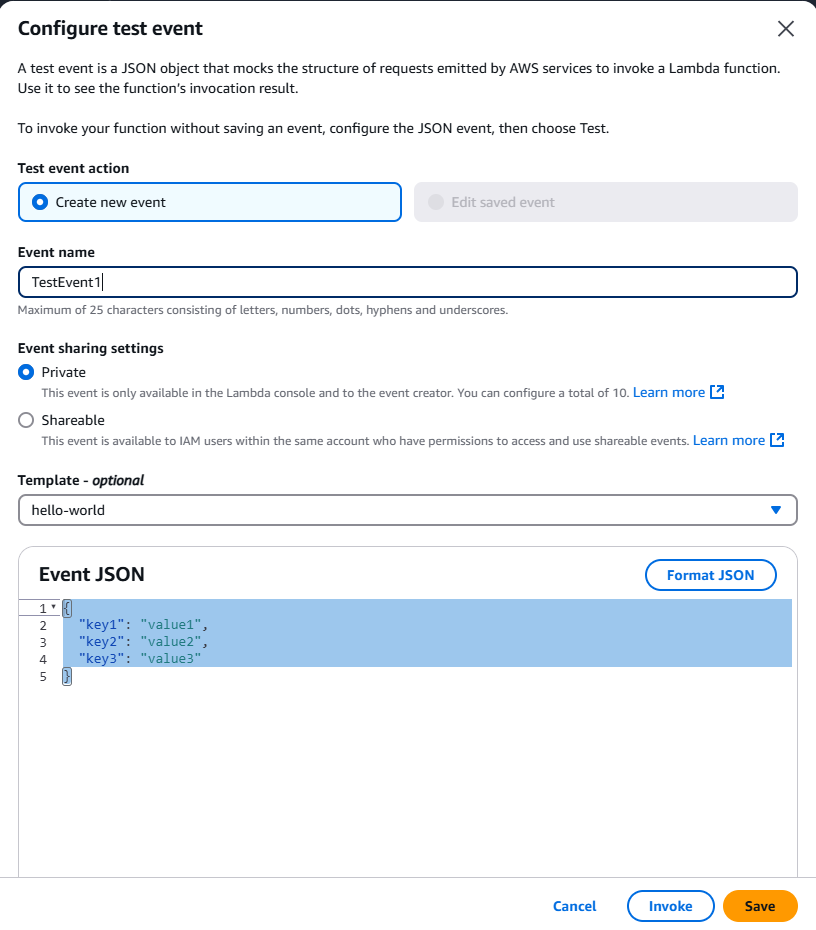
Testez votre fonction AWS Lambda dans le navigateur.
Vous pouvez supprimer le “JSON de l’événement” car notre fonction ne prend aucune entrée. Donnez un nom à l’événement et cliquez sur le bouton Invoke.
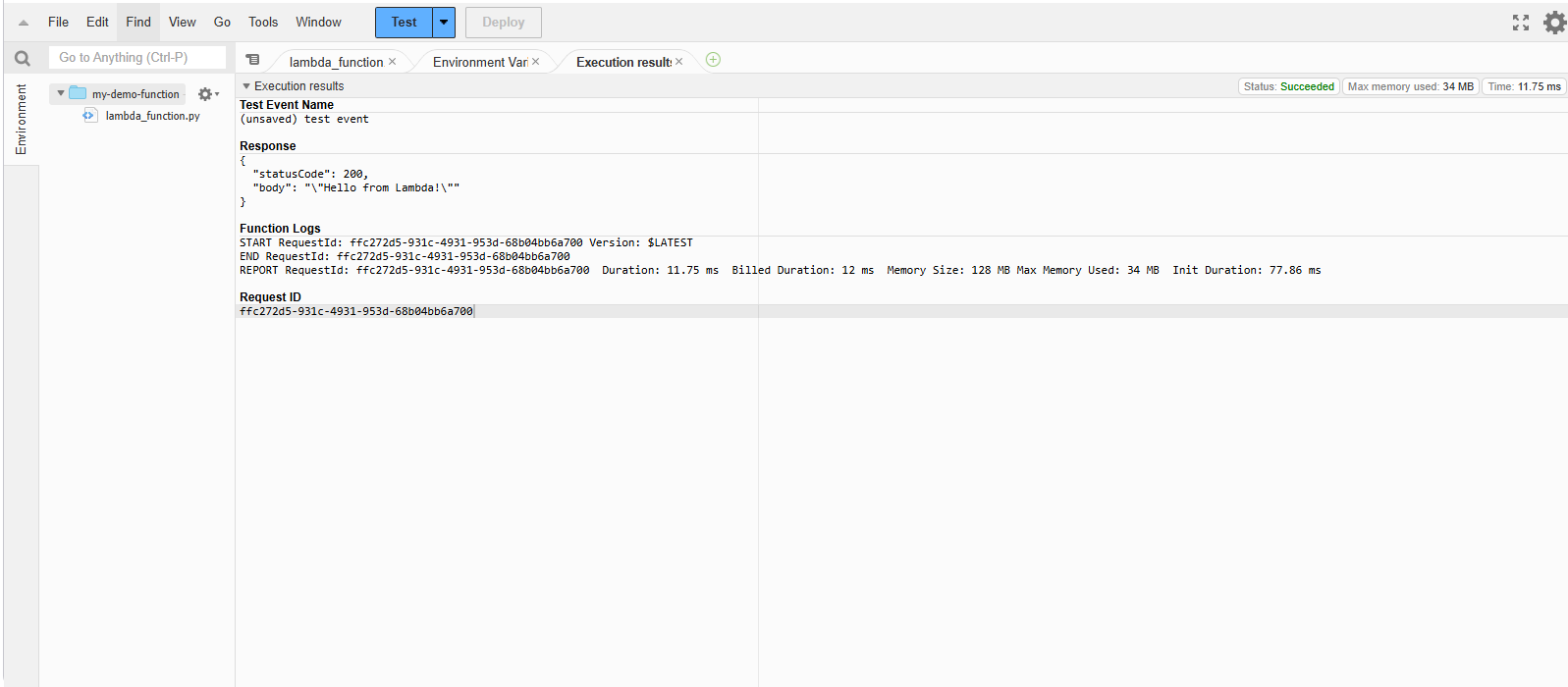
Test réussi de la fonction AWS Lambda.
La fonction a été exécutée avec succès, et le message a été renvoyé.
Hourra! Nous venons de déployer une fonction serverless en utilisant AWS Lambda. Pour l’instant, elle ne fait pas grand-chose, mais elle est opérationnelle. Chaque fois que cette fonction est invoquée, elle renvoie une simple chaîne de caractères.
Déclenchement de Lambda avec des événements
Comme mentionné, l’architecture AWS Lambda vous permet de déclencher des fonctions en réponse à des événements spécifiques provenant de divers services AWS, en faisant un outil polyvalent pour automatiser les flux de travaux et intégrer des systèmes.
Des événements tels que des téléchargements de fichiers vers un compartiment S3, des mises à jour dans une table DynamoDB, ou des appels d’API via API Gateway peuvent déclencher des fonctions Lambda, permettant un traitement en temps réel et une exécution scalable.
1. Configuration d’un déclencheur S3
- Accédez à la console S3.
- Sélectionnez le compartiment S3.
- Sous Propriétés, ajoutez une notification d’événement pour déclencher votre fonction Lambda lors de la création d’un objet.
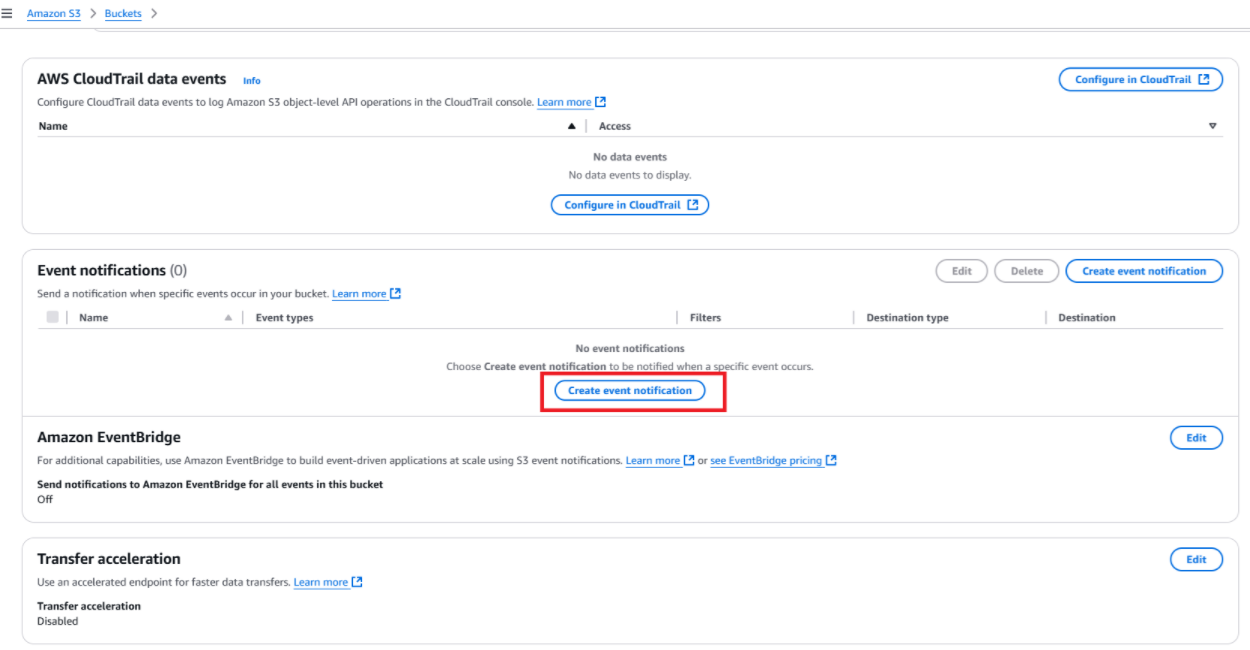 Créez une notification d’événement dans le compartiment AWS S3.
Créez une notification d’événement dans le compartiment AWS S3.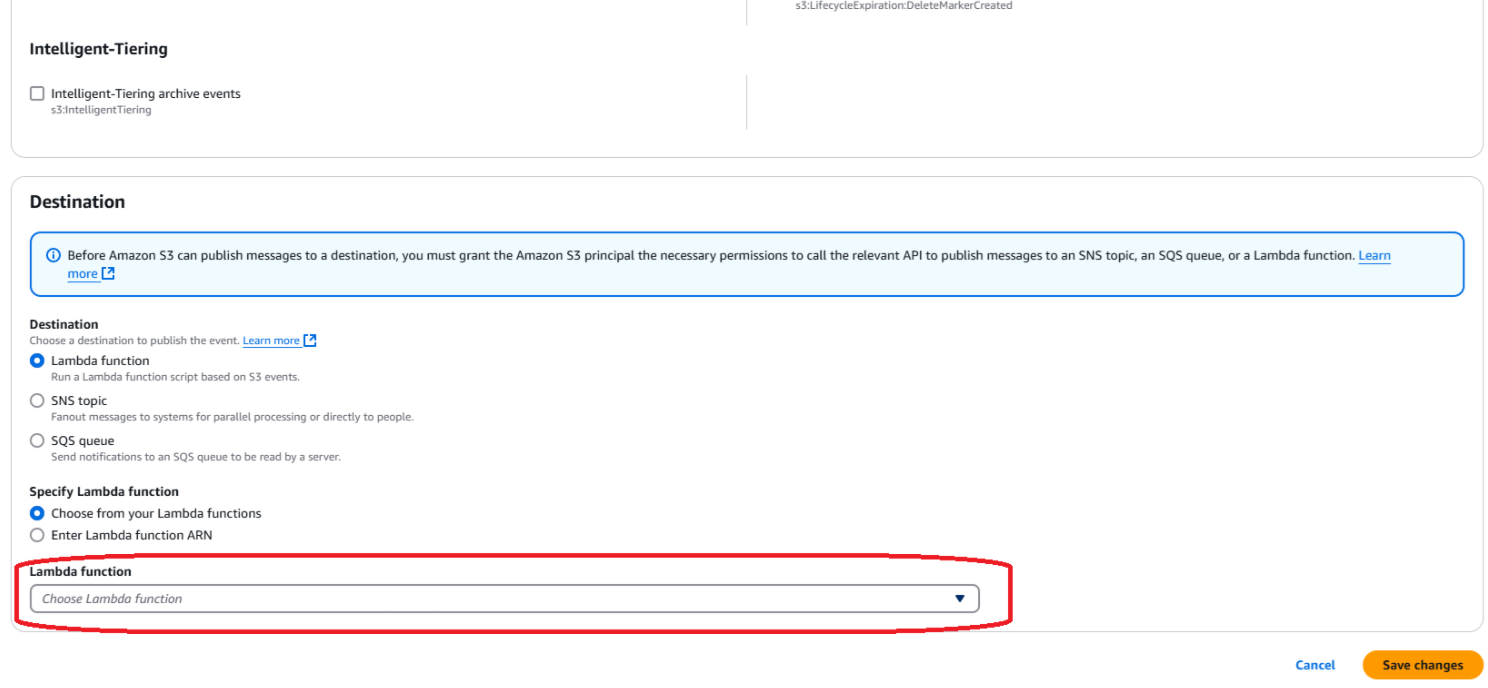 Sélectionnez la fonction Lambda à déclencher dans S3.
Sélectionnez la fonction Lambda à déclencher dans S3.
Exemples d’utilisation :
-
- Redimensionner automatiquement les images téléversées sur S3.
- Convertir des vidéos en plusieurs résolutions ou formats pour le streaming.
- Vérifier les formats de fichiers, tailles ou métadonnées lors du téléversement.
- Utiliser l’IA pour extraire du texte des documents téléversés (par exemple, via Amazon Textract).
2. Intégration de l’API Gateway
- Accéder au service API Gateway.
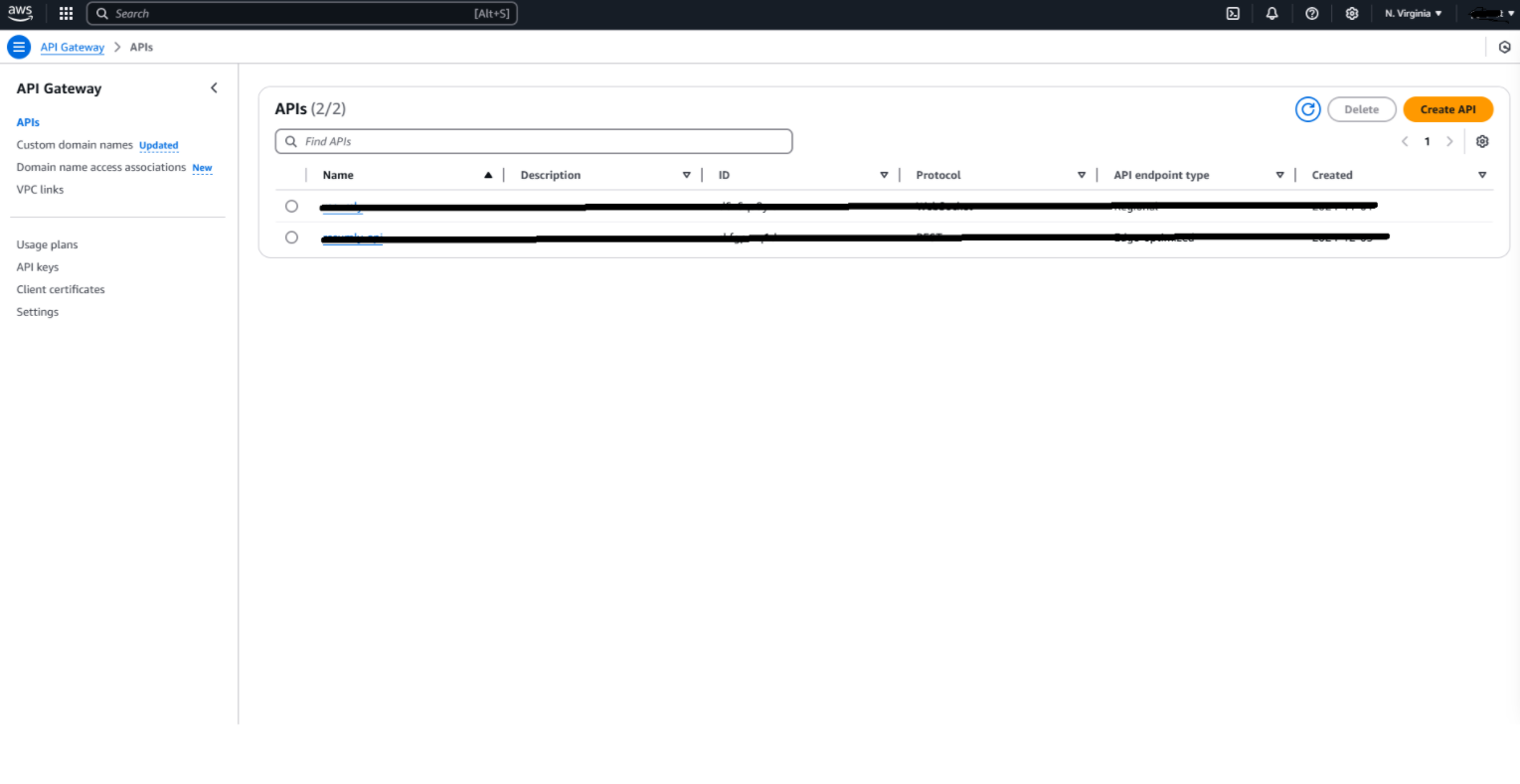
Tableau de bord du service API Gateway dans la console AWS.
- Créer une nouvelle API REST.
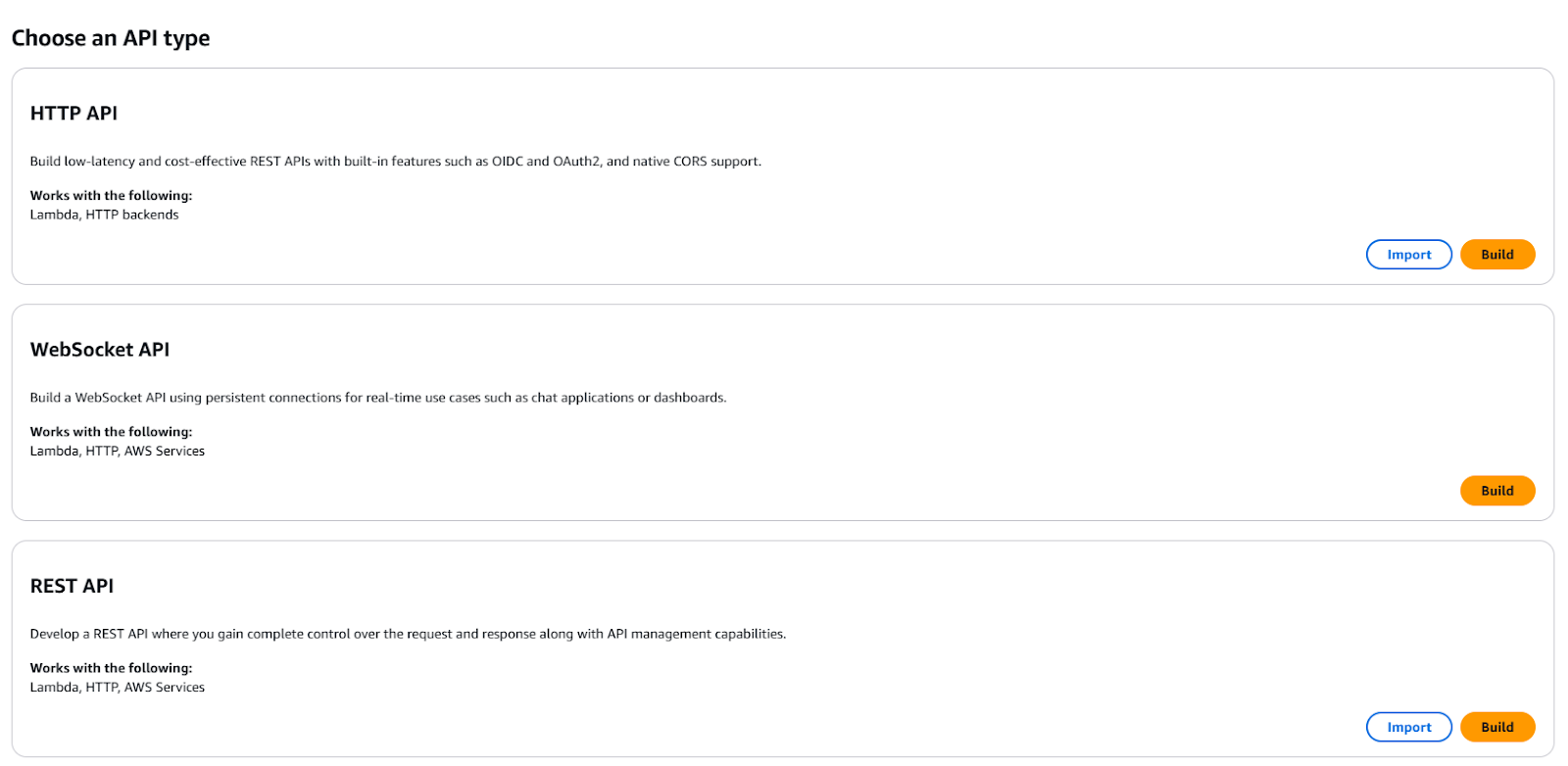
Créer une nouvelle API REST via API Gateway.
- Configurer une méthode (par exemple, POST) pour déclencher votre fonction Lambda.
Exemples d’utilisation:
-
- Créer une API serverless pour des réponses en temps réel.
- Déclencher une fonction Lambda pour créer et stocker les données utilisateur dans une base de données.
- Gérer les demandes POST pour traiter et valider les commandes des clients en temps réel
- Déclencher une fonction Lambda pour interroger et renvoyer des données à partir d’une base de données ou d’une API.
Déploiement et surveillance des AWS Lambdas
Le déploiement des fonctions AWS Lambda est simple et peut être effectué en utilisant différentes méthodes selon vos besoins, comme la console de gestion AWS pour des déploiements manuels ou l’AWS CLI pour des déploiements automatisés.
1. Déploiement manuel en utilisant la console AWS
La console de gestion AWS offre une interface web intuitive pour déployer des fonctions Lambda. Cette méthode est idéale pour des petits projets ou des changements rapides. Voici comment déployer une fonction Lambda en utilisant la console :
- Créer ou modifier une fonction :
- Connectez-vous à la console de gestion AWS.
- Accédez à AWS Lambda.
- Cliquez sur Créer une fonction pour configurer une nouvelle fonction ou sélectionnez une fonction existante à mettre à jour.
- Télécharger votre code :
- Choisissez Télécharger depuis et sélectionnez un fichier .zip ou une image de conteneur.
- Vous pouvez modifier le code de votre fonction directement dans l’éditeur de code intégré pour un développement à petite échelle.
- Configurer la fonction :
- Définissez des variables d’environnement, l’allocation de mémoire et les limites de temps d’exécution en fonction de votre cas d’utilisation.
- Ajoutez les autorisations nécessaires en utilisant les rôles IAM d’AWS pour permettre à la fonction d’interagir avec d’autres services AWS.
- Déployer les modifications :
- Cliquez sur Déployer pour enregistrer et activer vos modifications.
- Utilisez la fonction de test pour invoquer manuellement la fonction et vérifier qu’elle fonctionne comme prévu.
2. Déploiement automatisé en utilisant l’AWS CLI
L’AWS CLI est un moyen efficace de déployer et mettre à jour les fonctions Lambda pour l’automatisation ou les mises à jour fréquentes. Cela garantit la cohérence et réduit les erreurs manuelles, en particulier dans les projets plus importants ou les pipelines CI/CD.
Étape 1 – Préparer le package de déploiement
Emballez votre code et ses dépendances dans un fichier .zip. Par exemple :
zip -r my-deployment-package.zip .
Étape 2 – Déployer la fonction en utilisant l’interface CLI
Utilisez la commande update-function-code pour télécharger le nouveau code sur AWS Lambda :
aws lambda update-function-code \ --function-name MyFunction \ --zip-file fileb://my-deployment-package.zip
–function-name MonFonction \
–zip-file fileb://mon-package-de-deploiement.zip
aws lambda get-function --function-name MyFunction
Étape 3 – Vérifier le déploiement
Après le déploiement, vérifiez le statut de la fonction en utilisant :
Cette commande récupère la configuration de la fonction et confirme le déploiement.
Surveillance de Lambda avec CloudWatch
La surveillance est essentielle pour garantir que vos fonctions Lambda s’exécutent efficacement, gèrent les erreurs avec élégance et répondent aux attentes de performance. AWS Lambda s’intègre à Amazon CloudWatch pour fournir des capacités de surveillance et de journalisation.
- Amazon CloudWatch collecte et affiche automatiquement des indicateurs clés pour vos fonctions Lambda. Ces indicateurs vous aident à analyser les performances de votre fonction et à résoudre les problèmes.
- Indicateurs à surveiller :
- Appels: Suivi du nombre de fois où votre fonction est appelée. Vous aide à comprendre les tendances de trafic et d’utilisation.
- Erreurs: Affiche le nombre d’erreurs pendant l’exécution de la fonction. Utilisez ceci pour identifier les taux d’échec et déboguer les problèmes.
Durée: Mesure le temps nécessaire pour exécuter la fonction. C’est crucial pour optimiser les performances et gérer les coûts.
- Gestionnaires de débit: Indique le nombre d’invocations qui ont été limitées en raison de l’atteinte des limites de concurrence.
- Accès aux métriques:
- Naviguer vers la Console des métriques CloudWatch.
Sélectionnez Lambda dans la liste des espaces de noms.
Choisissez la fonction que vous souhaitez surveiller pour afficher des métriques détaillées.
Meilleures pratiques AWS Lambda
Maintenant que vous avez déployé votre première fonction Lambda, connaître certaines meilleures pratiques pour des projets futurs plus complexes est utile. Dans cette section, je vous propose quelques meilleures pratiques à garder à l’esprit.
1. Optimisez les démarrages à froid des fonctions
- Les démarrages à froid se produisent lorsqu’une fonction Lambda est invoquée après avoir été inactive, entraînant une légère latence alors qu’AWS provisionne l’environnement d’exécution. Bien qu’AWS minimise cette surcharge, il existe des mesures que vous pouvez prendre pour réduire le temps de démarrage à froid :
- Utilisez des packages de déploiement plus petits
- Gardez votre package de déploiement léger en n’incluant que les dépendances nécessaires.
Utilisez des outils comme les AWS Lambda Layers pour partager des bibliothèques communes (par ex. AWS SDK) entre les fonctions sans les inclure dans des packages individuels.
Compressez et minifiez le code lorsque c’est possible, surtout pour les fonctions basées sur JavaScript ou Python.
Évitez les initialisations lourdes dans votre fonction
Déplacez l’initialisation intensive en ressources (par exemple, les connexions de base de données, les clients API ou les bibliothèques tierces) en dehors du gestionnaire de fonctions. Cela garantit que le code est exécuté une seule fois par environnement et réutilisé pour toutes les invocations.
Exploitez la capacité provisionnée
Pour les fonctions critiques sensibles à la latence, utilisez la Capacité Provisionnée pour maintenir l’environnement d’exécution prêt à traiter les demandes. Bien que cela entraîne des coûts supplémentaires, cela garantit une faible latence pour les charges de travail prioritaires.
2. Gardez les fonctions sans état
La sans-état est un principe fondamental de l’architecture serverless, garantissant que votre application s’adapte de manière transparente :
Évitez de dépendre des données en mémoire
Les fonctions Lambda sont éphémères, ce qui signifie que leur environnement d’exécution est temporaire et peut ne pas persister entre les invocations. Au lieu de compter sur des variables en mémoire, stockez les informations d’état dans des systèmes externes comme DynamoDB, S3 ou Redis.
Activez l’idempotence
Concevez vos fonctions pour gérer les événements en double avec élégance. Utilisez des identifiants uniques pour les demandes et vérifiez les journaux ou les bases de données pour vous assurer que le même événement n’est pas traité plusieurs fois.
3. Utilisez des variables d’environnement
- Les variables d’environnement sont un moyen sécurisé et pratique de configurer vos fonctions Lambda :
- Conservez des informations sensibles
Stockez des clés API, des chaînes de connexion à la base de données et d’autres secrets en tant que variables d’environnement. AWS Lambda chiffre ces variables au repos et les déchiffre pendant l’exécution.
Pour une sécurité accrue, utilisez AWS Secrets Manager ou Systems Manager Parameter Store pour gérer les secrets de manière dynamique.
Simplifiez la gestion de la configuration
Utilisez des variables d’environnement pour gérer des configurations telles que les niveaux de journalisation, les paramètres régionaux ou les URL de services tiers. Cela élimine le besoin de valeurs codées en dur, rendant votre fonction plus portable à travers différents environnements (par exemple, dev, staging, prod).
Conclusion