













Dans l’ère de la transformation numérique, les entreprises ont besoin de solutions de base de données qui offrent une scalabilité et une fiabilité. AWS Aurora, une base de données relationnelle qui supporte MySQL et PostgreSQL, est devenue une choix populaire pour les entreprises recherchant de hautes performances, de la durabilité et des économies de coûts. Cet article plonge dans les avantages d’AWS Aurora et présente un exemple réel de son utilisation dans un plateforme de médias sociaux en ligne.
Comparaison d’AWS Aurora : avantages vs défis
| Key Benefits | Description | Challenges | Description |
|---|---|---|---|
| High Performance and Scalability |
La conception d’Aurora sépare les fonctions d’ stockage et de calcul, offrant une bande passante cinq fois supérieure à MySQL et deux fois celle de PostgreSQL. Elle garantit des performances cohérentes même pendant les périodes de trafic fort en utilisant des capacités d’auto-échelle. |
Financial Implications | The complex pricing structure can lead to high costs due to charges for instance, storage, replicas, and support. |
| Durability and Availability | Data in Aurora is distributed across multiple Availability Zones (AZs), with six copies stored across three AZs to ensure data availability and resilience. Failover mechanisms are automated to facilitate durable writes, incorporating retry logic for transactional integrity. | Dependency Risks | A significant dependence on AWS services may lead to vendor lock-in, making it more challenging and costly to migrate to alternative platforms in the future. |
| Security | Aurora offers robust security with encryption for data at rest and in transit, network isolation via Amazon VPC, and precise access control through AWS IAM. | Migration Challenges | Data transfer can be lengthy and may involve downtime. Compatibility issues might require modifications to existing code. |
| Cost Efficiency | Aurora’s flexible pricing structure enables businesses to reduce database costs. The automatic scaling feature guarantees that you are charged based on the actual resources utilized, resulting in a cost-effective solution for varying workloads. | Training Requirements | Teams need to dedicate a significant amount of time and resources to acquiring the necessary knowledge of AWS-specific tools and optimal practices to effectively manage Aurora. |
| Performance Optimization | Auto-scaling and read replicas help optimize performance by dynamically adjusting resources and distributing read traffic. | Performance Impacts | Latency may be introduced due to abstraction layers and networking between Aurora instances and other AWS services, impacting latency-sensitive applications. |
Étapes de mise en œuvre
1. Configurer un cluster Aurora
- Accéder au console de gestion AWS.
- Choisir Amazon Aurora et sélectionner « Créer une base de données ».
- Sélectionner le moteur approprié (MySQL ou PostgreSQL) et configurer les réglages de instances.
2. Activer l’échelle automatique
- Configurer des politiques d’échelle automatique pour le calcul et le stockage.
- Définir des seuils pour l’escalade montante et descendante en fonction des schémas de trafic.
3. Configurer le déploiement Multi-AZ
- Activer le déploiement Multi-AZ pour assurer la haute disponibilité.
- Configurer les sauvegardes automatiques et les instantanés pour la protection des données.
4. Créer des répliques de lecture
- Ajouter des répliques de lecture pour distribuer le trafic de lecture.
- Configurer les points de terminaison des applications pour équilibrer les demandes de lecture sur les répliques.
Exemple fonctionnel : plateforme de médias sociaux en ligne
Une plateforme de médias sociaux en ligne, « SocialBuzz », connecte des millions d’utilisateurs à travers le monde. Pour répondre à ses besoins en termes de traitement de volumes de trafic élevés, de réponses à bas délai et de durabilité des données, SocialBuzz a besoin d’une solution de base de données fiable. AWS Aurora est le choix idéal pour remplir ces besoins :
- Aperçu de l’architecture : SocialBuzz utilise Aurora pour ses besoins de base de données principaux, en exploitant les moteurs MySQL et PostgreSQL pour différents composants. Les profils utilisateurs, les publications, les commentaires et les interactions sont stockés dans Aurora, bénéficiant de ses performances élevées et de sa scalabilité.
- Scalabilité en action : Pendant les périodes de haute utilisation, telles que lorsqu’une publication virale est partagée, SocialBuzz connaît une surcharge de trafic. La fonction d’auto-échelle d’Aurora ajuste les ressources de calcul pour gérer la charge accrue, assurant des expériences utilisateur continues sans dégradation des performances.
- Haute disponibilité : Pour s’assurer un service non interrompu, SocialBuzz configure Aurora dans un dispositif Multi-AZ. Cela assure que même si une AZ subit une issue, la base de données reste disponible, fournissant un mécanisme de redressement robuste. Les sauvegardes automatiques et les instantanés automatisés d’Aurora进一步增强了 la protection des données.
- Optimisation des performances : SocialBuzz utilise des répliques en lecture sur Aurora pour distribuer le trafic de lecture, ce qui réduit la charge sur l’instance principale. Cette configuration permet un accès rapide aux données, ce qui permet de mettre en œuvre des fonctionnalités telles que les notifications en temps réel et les mises à jour instantanées des publications.
- Gestion des coûts : En utilisant le modèle payant à la demande d’Aurora, SocialBuzz gère efficacement ses coûts opérationnels. Aux heures de pointe, les ressources sont redimensionnées, réduisant les dépenses. De plus, l’option sans serveur d’Aurora permet à SocialBuzz de gérer des charges de travail imprévisibles sans surprovisionner les ressources.
Aperçu
Découvrons comment un plateforme sociale en ligne, SocialBuzz, utilise AWS Aurora pour une gestion de base de données scalable et fiable. Nous incluons un exemple de code pour l’implémentation, un jeu de données exemple et un diagramme de flux pour illustrer le processus.
Aperçu de l’architecture
SocialBuzz utilise AWS Aurora pour stocker et gérer les profils utilisateurs, les publications, les commentaires et les interactions. L’architecture système se compose des éléments suivants :
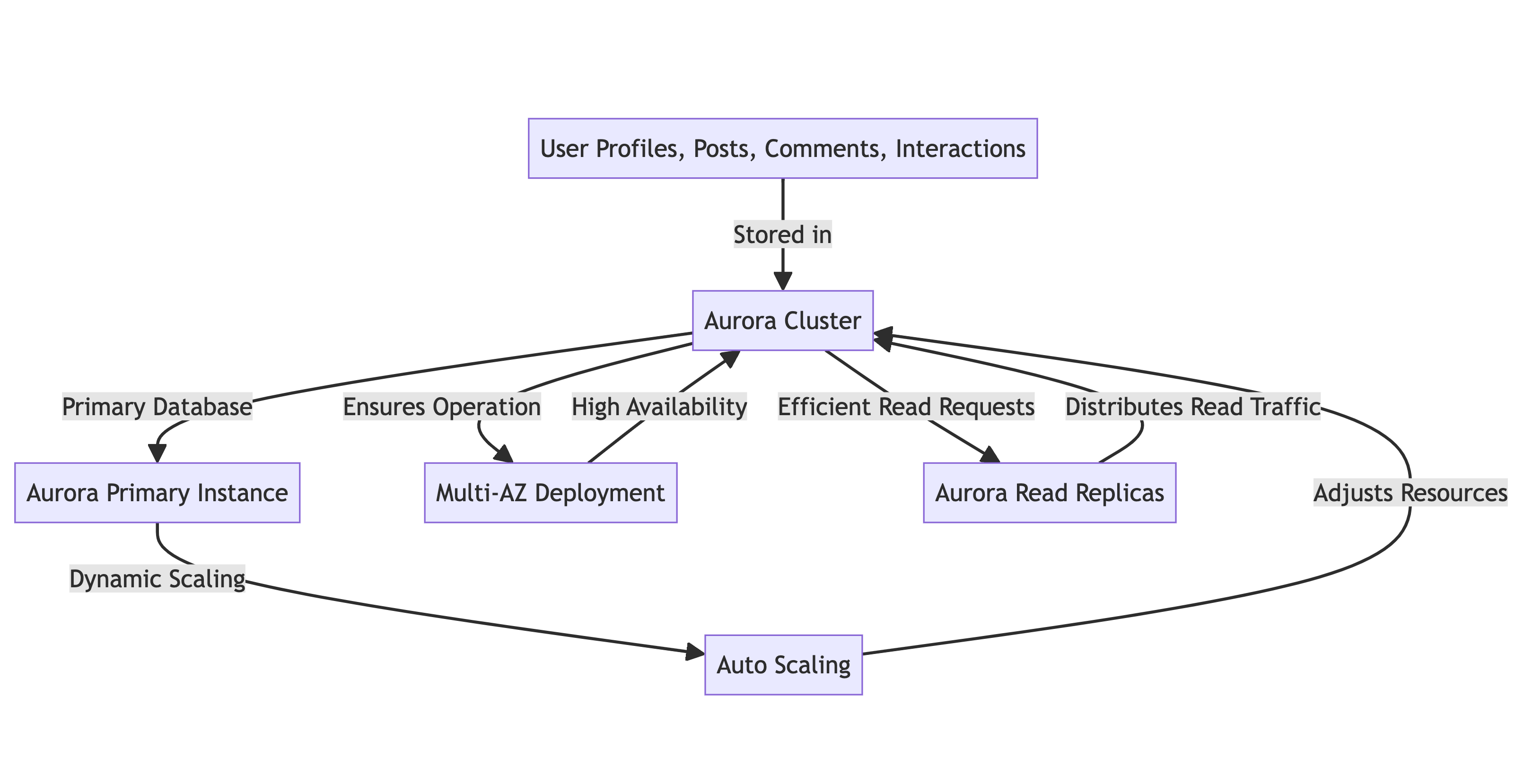
- Base de données principale : Cluster Aurora
- Ajustement des ressources : Fonctionnalité Auto Scaling permettant le redimensionnement automatique des ressources en fonction de la demande
- Haute disponibilité : Déploiement Multi-AZ pour assurer une exploitation continue
- Distribution du trafic de lecture : Répliques de lecture pour une distribution efficiente des demandes de lecture
Diagramme de flux
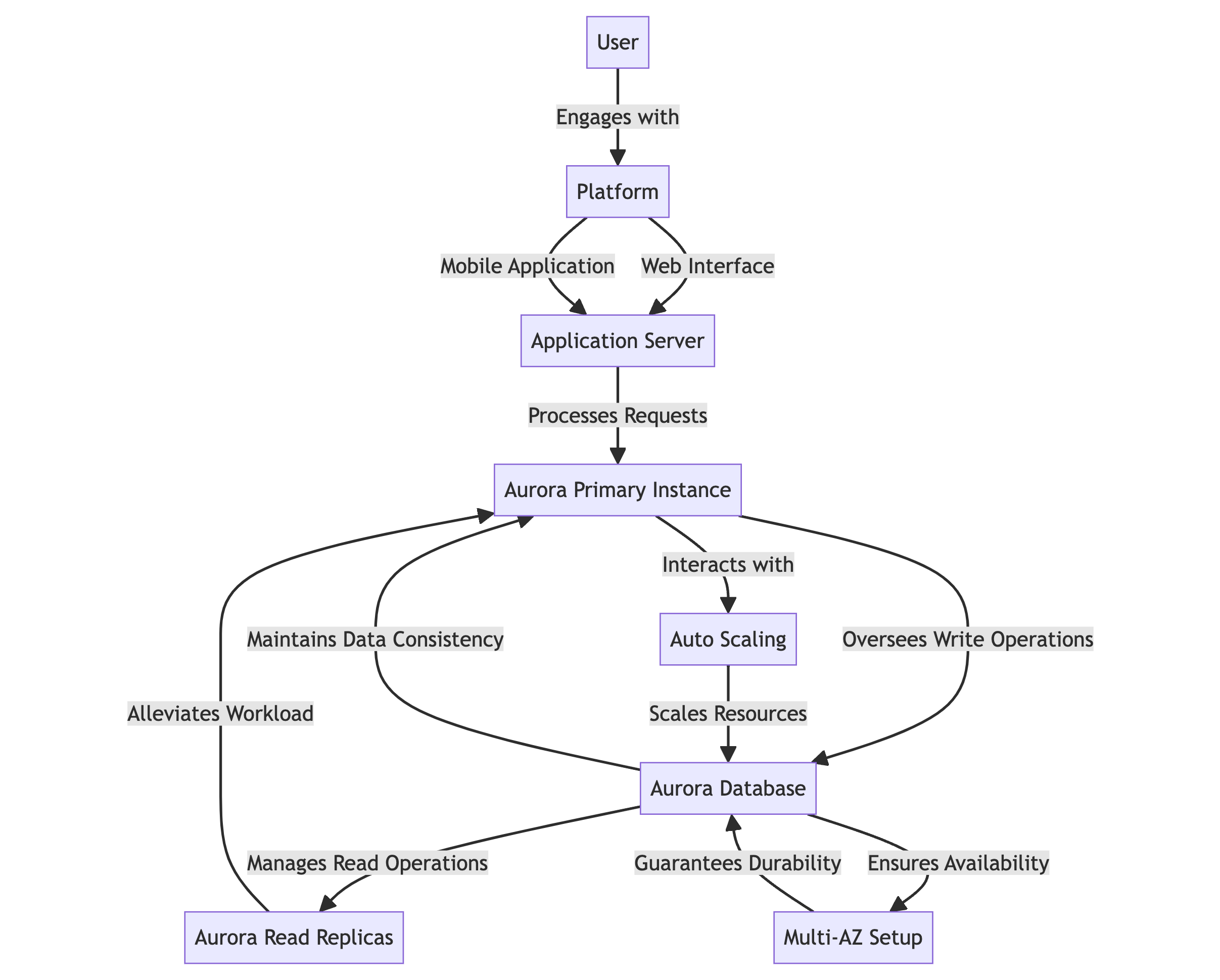
- L’utilisateur interagit avec la plateforme soit via l’interface web que via l’application mobile.
- Le serveur d’applications traite les demandes et interagit avec la base de données Aurora.
- L’instance primaire Aurora supervise les opérations d’écriture et maintient la cohérence des données.
- Les répliques de lecture Aurora gèrent les opérations de lecture pour atténuer la charge sur l’instance primaire.
- L’auto-échelle permet automatiquement de redimensionner les ressources en fonction des niveaux de trafic variables.
- La configuration Multi-AZ garantit la disponibilité et la durabilité des données sur plusieurs zones de disponibilité.
Instance AWS
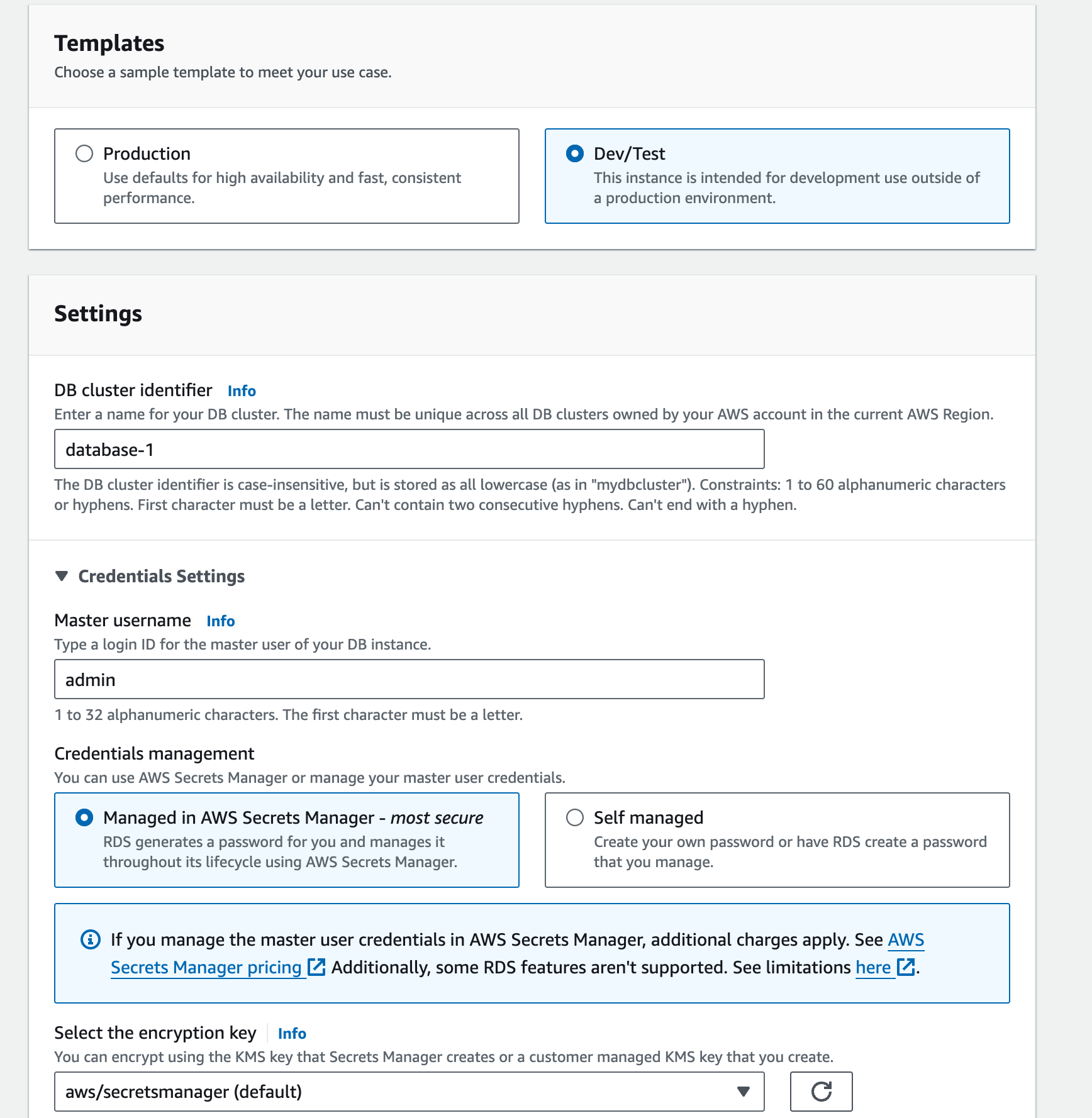
- Choisissez la norme pour créer une instance Aurora (MySQL).

- Choisissez un modèle, des identifiants et des paramètres de nom de base de données.
- La configuration de l’instance, de la disponibilité et de la connectivité sont des facteurs importants à considérer. J’ai décidé de ne pas connecter l’EC2 selon les exigences.
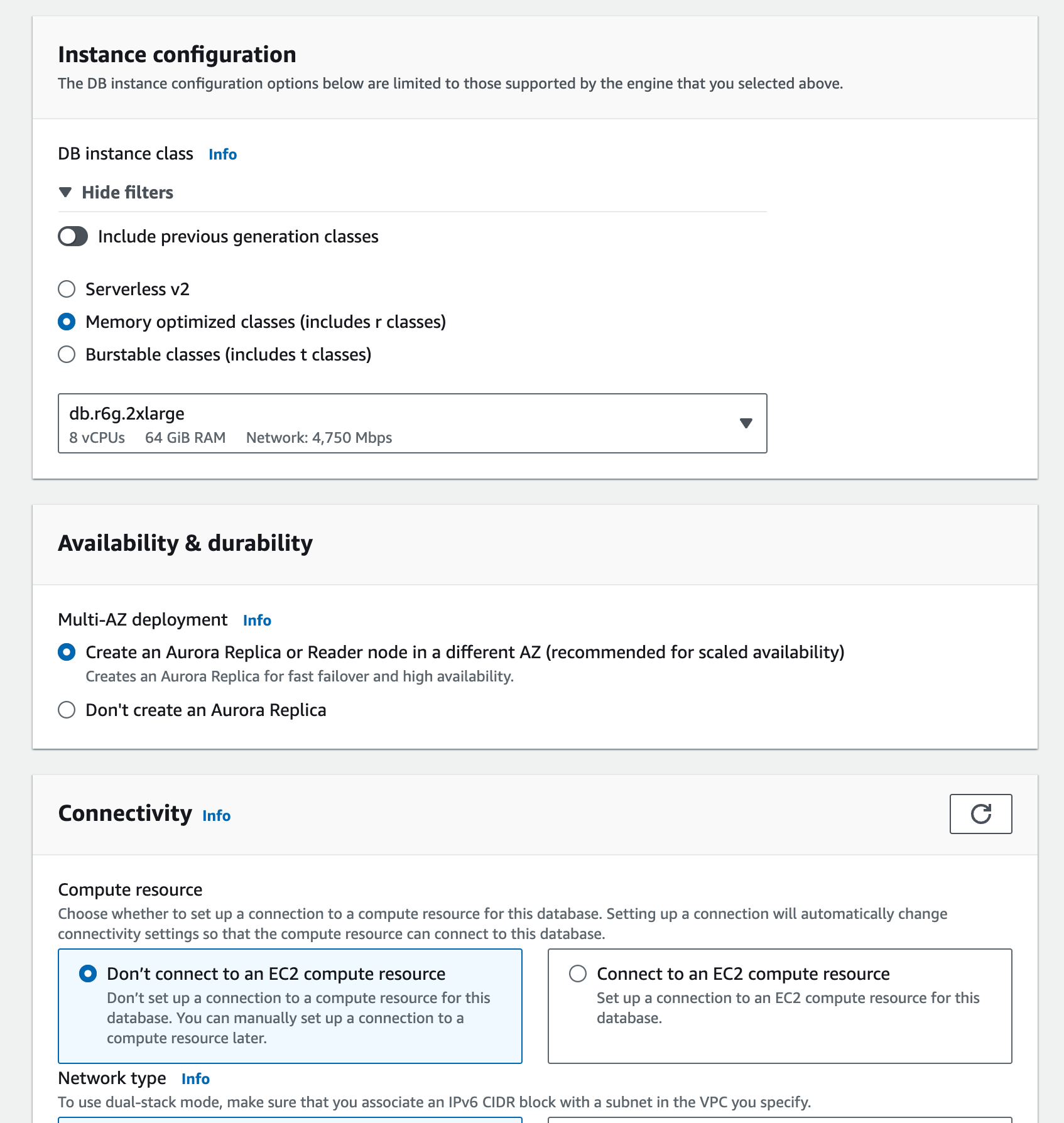
- Paramètres du VPC : Activez la réplique de lecture et les étiquettes pour identifier la base de données.
- Sélectionnez les autorisations de base de données et le contrôle, et finalement, vous recevrez une estimation mensuelle du coût de la base de données.
Exemple de code
Nous allons procéder à la configuration d’un cluster Aurora pour SocialBuzz.
Configuration du cluster Aurora
import boto3
# Initialisation d'une session en utilisant Amazon RDS
client = boto3.client('rds', region_name='us-west-2')Créer un cluster de base de données Aurora
response = client.create_db_cluster(
DBClusterIdentifier='socialbuzz-cluster',
Engine='aurora-mysql',
MasterUsername='admin',
MasterUserPassword='password',
BackupRetentionPeriod=7,
VpcSecurityGroupIds=['sg-0a1b2c3d4e5f6g7h'],
DBSubnetGroupName='default'
)
print(response)
Création d’instance Aurora
response = client.create_db_instance(
DBInstanceIdentifier='socialbuzz-instance',
DBClusterIdentifier='socialbuzz-cluster',
DBInstanceClass='db.r5.large',
Engine='aurora-mysql',
PubliclyAccessible=True
)
print(response)
Jeton de données de exemple
Voici un jeu de données simple pour représenter les utilisateurs, les posts et les commentaires :
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE posts (
post_id INT PRIMARY KEY,
user_id INT,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE comments (
comment_id INT PRIMARY KEY,
post_id INT,
user_id INT,
comment TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- Insérer des données de exemple
INSERT INTO users (user_id, username, email) VALUES
(1, 'john_doe', '[email protected]'),
(2, 'jane_doe', '[email protected]');
INSERT INTO posts (post_id, user_id, content) VALUES
(1, 1, 'Hello World!'),
(2, 2, 'This is my first post.');
INSERT INTO comments (comment_id, post_id, user_id, comment) VALUES
(1, 1, 2, 'Nice post!'),
(2, 2, 1, 'Welcome to the platform!');Logique d’application pour les opérations de lecture/écriture
import pymysql
# Connexion à la base de données
connection = pymysql.connect(
host='socialbuzz-cluster.cluster-xyz.us-west-2.rds.amazonaws.com',
user='admin',
password='password',
database='socialbuzz'
)
# Opération d'écriture
def create_post(user_id, content):
with connection.cursor() as cursor:
sql = "INSERT INTO posts (user_id, content) VALUES (%s, %s)"
cursor.execute(sql, (user_id, content))
connection.commit()
# Opération de lecture
def get_posts():
with connection.cursor() as cursor:
sql = "SELECT * FROM posts"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# Exemple d'utilisation
create_post(1, 'Exploring AWS Aurora!')
get_posts()Conclusion
AWS Aurora offre une solution de gestion de base de données robuste, scalable et fiable. L’étude de cas de SocialBuzz montre comment les entreprises peuvent utiliser les capacités avancées d’Aurora pour gérer un trafic important, garantir l’intégrité des données et améliorer l’efficacité. En suivant les méthodes recommandées et en déployant l’infrastructure appropriée, les entreprises peuvent utiliser pleinement les capacités d’AWS Aurora pour favoriser le développement et la créativité.
Source:
https://dzone.com/articles/aws-aurora-for-scalable-and-reliable-databases