













Les organisations commencent leur adoption du streaming de données avec un seul cluster Apache Kafka pour déployer les premiers cas d’utilisation. Le besoin de gouvernance et de sécurité des données à l’échelle du groupe mais avec des exigences différentes en termes de SLA, de latence et d’infrastructure introduit de nouveaux clusters Kafka. Plusieurs clusters Kafka sont la norme, pas l’exception. Les cas d’utilisation incluent l’intégration hybride, l’agrégation, la migration et la reprise après sinistre. Cet article de blog explore des histoires à succès du monde réel et des stratégies de cluster pour différents déploiements Kafka à travers les industries.

Apache Kafka : La norme de facto pour les architectures orientées événements et le streaming de données
Apache Kafka est une plateforme de streaming d’événements distribuée et open-source conçue pour le traitement de données à haut débit et à faible latence. Il vous permet de publier, de vous abonner, de stocker et de traiter des flux d’enregistrements en temps réel.
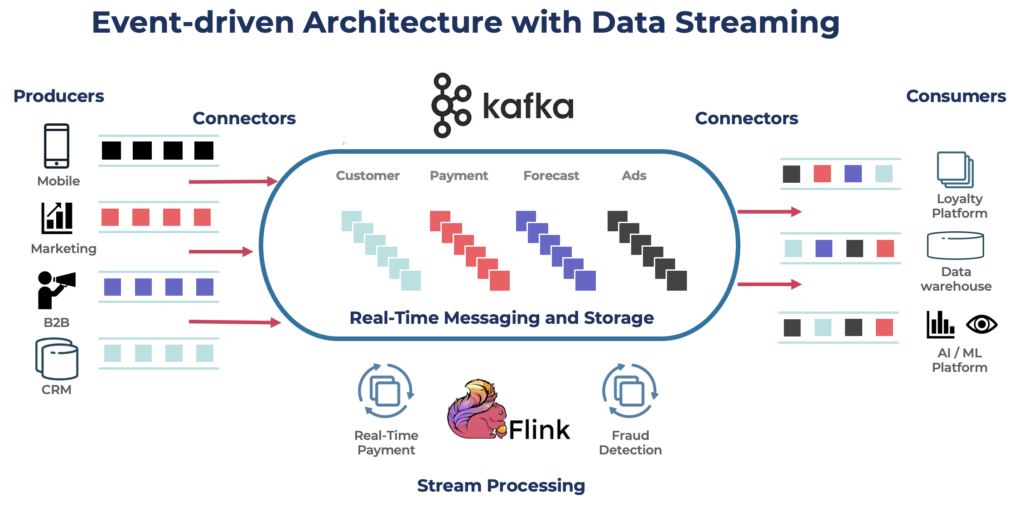
Kafka est un choix populaire pour la construction de pipelines de données en temps réel et d’applications de streaming. Le protocole Kafka est devenu le standard de facto pour le streaming d’événements à travers divers frameworks, solutions et services cloud. Il prend en charge les charges de travail opérationnelles et analytiques avec des fonctionnalités telles que le stockage persistant, l’évolutivité et la tolérance aux pannes. Kafka comprend des composants comme Kafka Connect pour l’intégration et Kafka Streams pour le traitement des flux, ce qui en fait un outil polyvalent pour divers cas d’utilisation axés sur les données.
Bien que Kafka soit célèbre pour les cas d’utilisation en temps réel, de nombreux projets exploitent la plateforme de streaming de données pour assurer la cohérence des données à travers l’ensemble de l’architecture d’entreprise, y compris les bases de données, les lacs de données, les systèmes hérités, les API ouvertes et les applications cloud-native.
Différents types de clusters Apache Kafka
Kafka est un système distribué. Une configuration de production nécessite généralement au moins quatre courtiers. Ainsi, la plupart des gens supposent automatiquement que tout ce dont vous avez besoin est un seul cluster distribué que vous évoluez lorsque vous ajoutez du débit et des cas d’utilisation. Ce n’est pas faux au début. Mais…
Un cluster Kafka n’est pas la bonne réponse pour chaque cas d’utilisation. Diverses caractéristiques influencent l’architecture d’un cluster Kafka :
- Disponibilité : Zero downtime ? SLA de disponibilité de 99,99 % ? Analyses non critiques ?
- Latence: Traitement de bout en bout en moins de 100 ms (y compris le traitement) ? Pipeline d’entrepôt de données de bout en bout de 10 minutes ? Voyage dans le temps pour le retraitement des événements historiques ?
- Coût: Valeur par rapport au coût ? Le coût total de possession (TCO) est important. Par exemple, dans le cloud public, le réseau peut représenter jusqu’à 80 % du coût total de Kafka !
- Sécurité et Confidentialité des données: Confidentialité des données (données PCI, RGPD, etc.) ? Gouvernance des données et conformité ? Chiffrement de bout en bout au niveau de l’attribut ? Apportez votre propre clé ? Accès public et partage de données ? Environnement edge air-gapped ?
- Débit et Taille des données: Transactions critiques (généralement de faible volume) ? Flux de données volumineux (clickstream, capteurs IoT, journaux de sécurité, etc.) ?
Des sujets connexes comme sur site vs. cloud public, régional vs. global, et de nombreux autres besoins affectent également l’architecture de Kafka.
Stratégies et architectures de cluster Apache Kafka
Un seul cluster Kafka est souvent le bon point de départ pour votre parcours de streaming de données. Il peut prendre en charge plusieurs cas d’utilisation de différents domaines métier et traiter des gigaoctets par seconde (si exploité et mis à l’échelle de la bonne manière).
Cependant, en fonction des exigences de votre projet, vous avez besoin d’une architecture d’entreprise avec plusieurs clusters Kafka. Voici quelques exemples courants :
- Architecture Hybride: Intégration des données et synchronisation des données uni- ou bidirectionnelle entre plusieurs centres de données. Souvent, connectivité entre un centre de données sur site et un fournisseur de services de cloud public. Le transfert de données des systèmes hérités vers l’analyse cloud est l’un des scénarios les plus courants. Mais la communication de commande et de contrôle est également possible, c’est-à-dire l’envoi de décisions/recommandations/transactions dans un environnement régional (par exemple, stocker un paiement ou une commande provenant d’une application mobile dans le mainframe).
- Multi-Région/Multi-Cloud: Réplication des données pour des raisons de conformité, de coût ou de confidentialité des données. Le partage de données inclut généralement seulement une fraction des événements, pas tous les sujets Kafka. Le secteur de la santé est l’un des nombreux secteurs qui empruntent cette voie.
- Plan de Reprise d’Activité: Réplication des données critiques en mode actif-actif ou actif-passif entre différents centres de données ou régions cloud. Comprend des stratégies et des outils pour les mécanismes de basculement et de retour en arrière en cas de sinistre afin de garantir la continuité des activités et la conformité.
- Agrégation: Regroupement régional pour le traitement local (par exemple, prétraitement, ETL en continu, applications métier de traitement de flux) et réplication des données sélectionnées vers le centre de données central ou le cloud. Les magasins de détail en sont un excellent exemple.
- Migration: Modernisation des TI avec une migration depuis un environnement sur site vers le cloud ou depuis une source ouverte auto-gérée vers un SaaS entièrement géré. Ces migrations peuvent être effectuées sans temps d’arrêt ni perte de données, tandis que l’activité commerciale se poursuit pendant la transition.
- Edge (Déconnecté/Hors ligne) : La sécurité, le coût ou la latence nécessitent des déploiements en périphérie, par exemple dans une usine ou un magasin de détail. Certaines industries déploient dans des environnements critiques en matière de sécurité avec une passerelle matérielle unidirectionnelle et une diode de données.
- Broker Unique : Non résilient, mais suffisant pour des scénarios tels que l’intégration d’un courtier Kafka dans une machine ou sur un PC industriel (IPC) et la réplication des données agrégées dans un grand cluster d’analyse cloud Kafka. Un bel exemple est l’installation de la diffusion de données (y compris l’intégration et le traitement) sur l’ordinateur d’un soldat sur le champ de bataille.
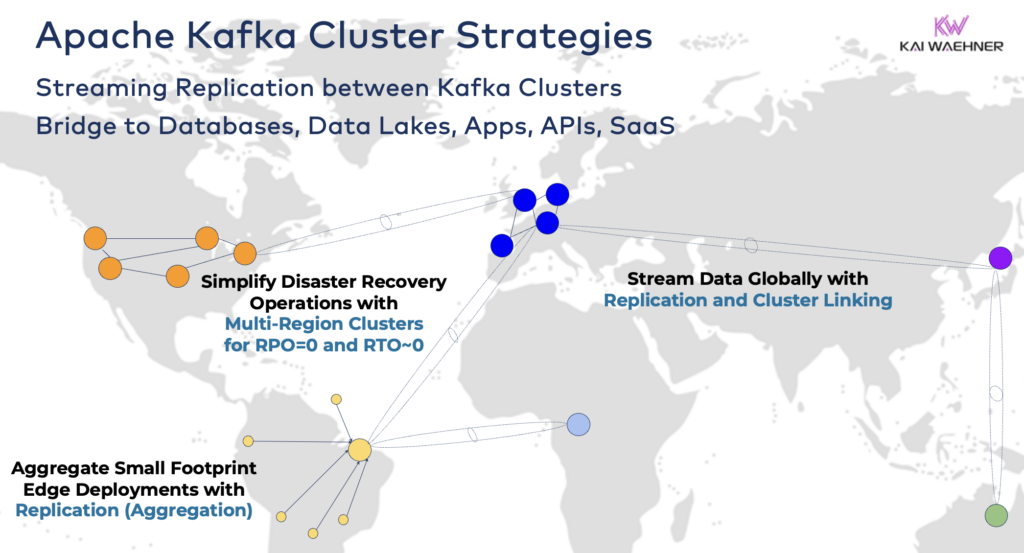
La Liaison des Clusters Hybrides Kafka
Ces options peuvent être combinées. Par exemple, un courtier unique en périphérie réplique généralement certaines données sélectionnées vers un centre de données distant. Les clusters hybrides ont des architectures différentes selon la manière dont ils sont reliés : connexions via Internet public, lien privé, appairage VPC, passerelle de transit, etc.
Ayant observé le développement de Confluent Cloud au fil des années, j’ai sous-estimé le temps d’ingénierie nécessaire pour la sécurité et la connectivité. Cependant, les lacunes dans les ponts de sécurité sont les principaux obstacles à l’adoption d’un service cloud Kafka. Ainsi, il est indispensable de fournir divers ponts de sécurité entre les clusters Kafka au-delà de l’Internet public.
Il y a même des cas d’utilisation où les organisations ont besoin de répliquer des données du centre de données vers le cloud, mais le service cloud n’est pas autorisé à initier la connexion. Confluent a développé une fonctionnalité spécifique, « lien initié par la source », pour répondre à ces exigences de sécurité où la source (c’est-à-dire le cluster Kafka sur site) initie toujours la connexion – même si les clusters Kafka cloud consomment les données :
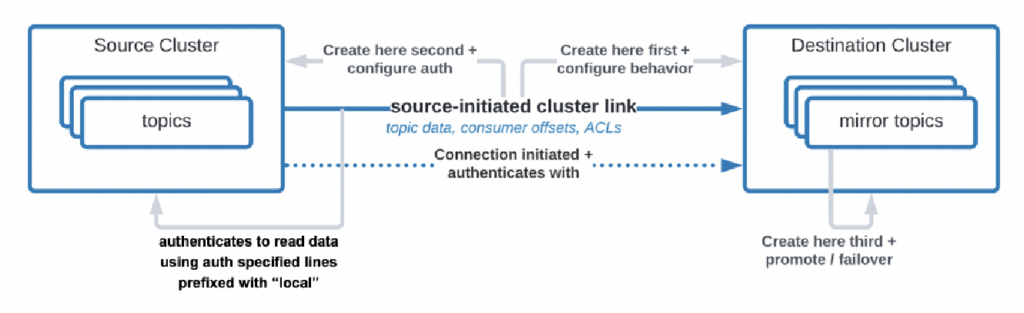 Source : Confluent
Source : Confluent
Comme vous pouvez le constater, cela devient rapidement complexe. Trouvez les bons experts pour vous aider dès le début, pas après avoir déjà déployé les premiers clusters et applications.
Il y a longtemps, j’ai déjà décrit dans une présentation détaillée les modèles d’architecture pour les déploiements Apache Kafka distribués, hybrides, edge et mondiaux. Consultez ce diaporama et l’enregistrement vidéo pour plus de détails sur les options de déploiement et les compromis.
RPO vs RTO = Perte de données vs Temps d’arrêt
RPO et RTO sont deux KPI critiques que vous devez discuter avant de décider d’une stratégie de cluster Kafka :
- RPO (Recovery Point Objective) est la quantité maximale acceptable de perte de données mesurée dans le temps, indiquant à quelle fréquence les sauvegardes doivent être effectuées pour minimiser la perte de données.
- Le RTO (Recovery Time Objective) est la durée maximale acceptable pour restaurer les opérations commerciales après une perturbation. Ensemble, ils aident les organisations à planifier leurs stratégies de sauvegarde de données et de reprise après sinistre pour équilibrer coût et impact opérationnel.
Alors que les gens commencent souvent avec l’objectif RPO = 0 et RTO = 0, ils réalisent rapidement combien il est difficile (mais pas impossible) d’y parvenir. Vous devez décider combien de données vous pouvez perdre en cas de catastrophe. Vous avez besoin d’un plan de reprise après sinistre si la catastrophe survient. Les équipes juridiques et de conformité devront vous dire s’il est acceptable de perdre quelques ensembles de données en cas de catastrophe ou non. Ces défis, parmi d’autres, doivent être discutés lors de l’évaluation de votre stratégie de cluster Kafka.
La réplication entre les clusters Kafka avec des outils tels que MIrrorMaker ou Cluster Linking est asynchrone et RPO > 0. Seul un cluster Kafka étendu offre un RPO = 0.
Cluster Kafka étendu : aucune perte de données avec une réplication synchrone entre les centres de données
La plupart des déploiements avec plusieurs clusters Kafka utilisent une réplication asynchrone entre les centres de données ou les clouds via des outils comme MirrorMaker ou Confluent Cluster Linking. Cela est suffisant pour la plupart des cas d’utilisation. Mais en cas de catastrophe, vous perdez quelques messages. Le RPO est > 0.
Un cluster Kafka étendu déploie des courtiers Kafka d’un seul cluster à travers trois centres de données. La réplication est synchrone (car c’est ainsi que Kafka réplique les données au sein d’un seul cluster) et garantit aucune perte de données (RPO = 0) – même en cas de catastrophe!
Pourquoi ne devriez-vous pas toujours utiliser des clusters étendus?
- Une connexion à faible latence (<~50ms) et stable est nécessaire entre les centres de données.
- Trois (!) centres de données sont nécessaires; deux ne suffisent pas car une majorité (quorum) doit approuver les écritures et les lectures pour garantir la fiabilité du système.
- Ils sont difficiles à mettre en place, à exploiter et à surveiller et beaucoup plus difficiles qu’un cluster fonctionnant dans un seul centre de données.
- Le rapport coût vs. valeur n’en vaut pas la peine dans de nombreux cas d’utilisation; lors d’une véritable catastrophe, la plupart des organisations et cas d’utilisation ont des problèmes plus importants que de perdre quelques messages (même s’il s’agit de données critiques comme un paiement ou une commande).
Pour être clair, dans le cloud public, une région a généralement trois centres de données (= zones de disponibilité). Ainsi, dans le cloud, tout dépend de vos SLA si une région cloud compte comme un cluster étendu ou non. La plupart des offres Kafka SaaS se déploient dans un cluster étendu ici.
Cependant, de nombreux scénarios de conformité ne considèrent pas qu’un cluster Kafka dans une seule région cloud soit suffisant pour garantir les SLA et la continuité des activités en cas de catastrophe.
Confluent a développé un produit dédié pour résoudre (certains) de ces défis : Clusters Multi-Régions (MRC). Il offre des capacités de réplication synchrone et asynchrone au sein d’un cluster Kafka étendu.
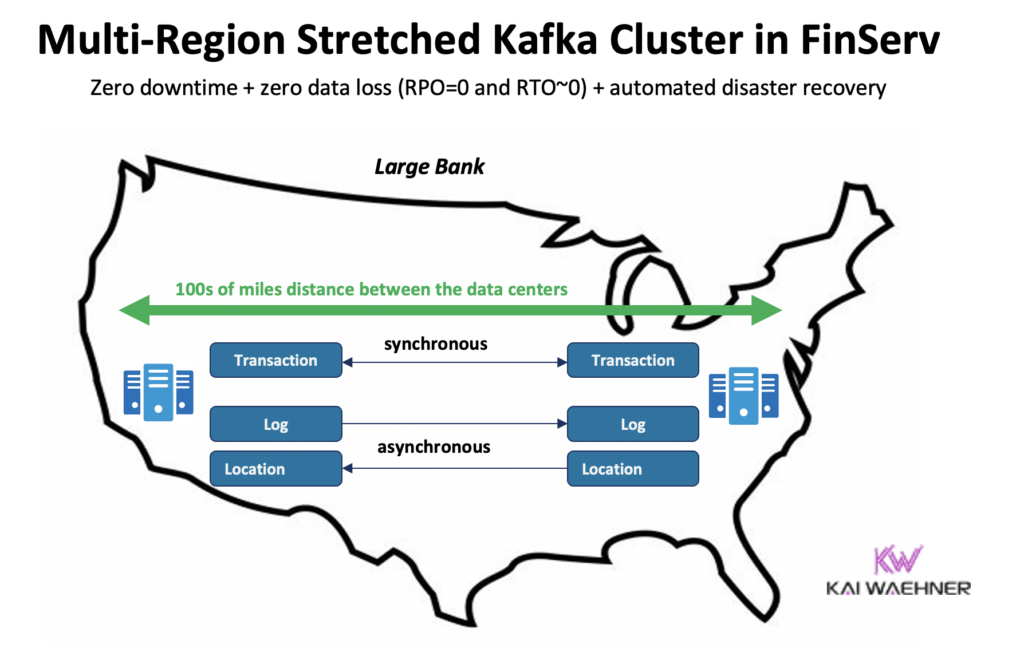
Par exemple, dans un scénario de services financiers, MRC réplique de manière synchrone les transactions critiques de faible volume, mais de manière asynchrone les journaux de grande volume :
- Gère les transactions « Paiement » provenant des États-Unis Est et Ouest avec une réplication entièrement synchrone
- Les informations « Journal » et « Emplacement » dans le même cluster utilisent l’asynchrone – optimisé pour la latence
- Plan de reprise après sinistre automatisé (aucun temps d’arrêt, aucune perte de données)
Plus de détails sur les clusters Kafka étendus par rapport à la réplication actif-actif / actif-passif entre deux clusters Kafka dans ma présentation Kafka globale.
Tarification des offres Cloud Kafka (vs. Auto-géré)
Les sections ci-dessus expliquent pourquoi vous devez tenir compte des différentes architectures Kafka en fonction des besoins de votre projet. Les clusters Kafka auto-gérés peuvent être configurés selon vos besoins. Dans le cloud public, les offres entièrement gérées sont différentes (de la même manière que tout autre SaaS entièrement géré). La tarification est différente car les fournisseurs de SaaS doivent configurer des limites raisonnables. Le fournisseur doit fournir des SLA spécifiques.
Le paysage de la diffusion de données comprend diverses offres cloud Kafka. Voici un exemple des offres cloud actuelles de Confluent, comprenant des environnements multi-locataires et dédiés avec différents SLA, fonctionnalités de sécurité et modèles de coûts.
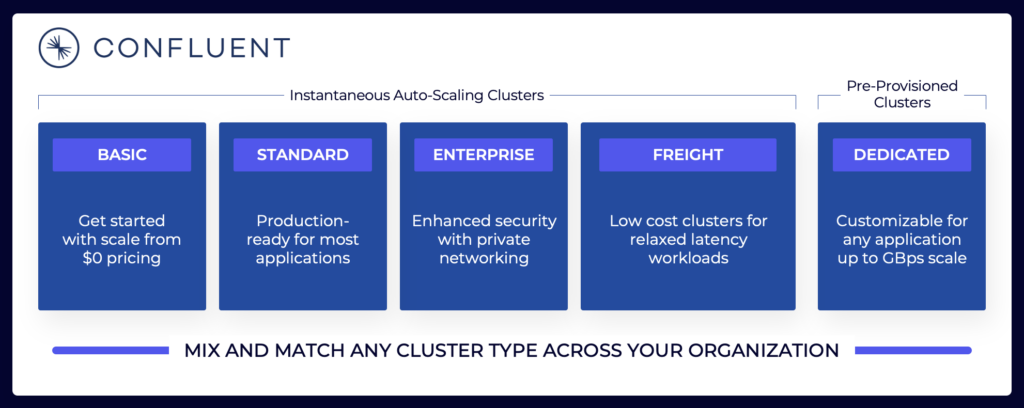 Source : Confluent
Source : Confluent
Assurez-vous d’évaluer et de comprendre les différents types de clusters proposés par les différents fournisseurs disponibles dans le cloud public, y compris le TCO, les SLAs de disponibilité fournis, les coûts de réplication entre les régions ou les fournisseurs de cloud, et ainsi de suite. Les lacunes et limitations sont souvent intentionnellement cachées dans les détails.
Par exemple, si vous utilisez Amazon Managed Streaming for Apache Kafka (MSK), vous devez être conscient que les conditions générales précisent que « L’engagement de service ne s’applique pas à toute indisponibilité, suspension ou résiliation … causée par le logiciel moteur sous-jacent Apache Kafka ou Apache Zookeeper qui entraîne des échecs de demande. »
Cependant, la tarification et les SLAs de support ne sont qu’un aspect critique de la comparaison. Il y a beaucoup de « décisions de achat par rapport à la construction que vous devez prendre dans le cadre de l’évaluation d’une plateforme de diffusion de données.
Stockage Kafka : Stockage à niveaux et format de table Iceberg pour stocker les données une seule fois
Apache Kafka a ajouté le Stockage hiérarchisé pour séparer le calcul et le stockage. Cette fonctionnalité permet des architectures d’entreprise plus évolutives, fiables et rentables. Le Stockage hiérarchisé pour Kafka permet un nouveau type de cluster Kafka : Stocker des pétaoctets de données dans le journal d’engagement Kafka de manière rentable (comme dans votre lac de données) avec des horodatages et une commande garantie pour remonter dans le temps afin de retraiter les données historiques. KOR Financial est un bel exemple de l’utilisation d’Apache Kafka comme base de données pour la persistance à long terme.
Kafka permet une architecture de décalage vers la gauche pour stocker les données une seule fois pour les ensembles de données opérationnels et analytiques :

Avec cela à l’esprit, réfléchissez à nouveau aux cas d’utilisation que j’ai décrits ci-dessus pour plusieurs clusters Kafka. Devriez-vous toujours répliquer les données par lots au repos dans la base de données, le lac de données ou la maison du lac d’un centre de données ou d’une région cloud à une autre? Non. Vous devriez synchroniser les données en temps réel, stocker les données une seule fois (généralement dans un magasin d’objets comme Amazon S3), puis connecter tous les moteurs analytiques comme Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery, et ainsi de suite à ce format de table standard.
Success Stories réelles pour plusieurs clusters Kafka
La plupart des organisations ont plusieurs clusters Kafka. Cette section explore quatre histoires à succès dans différents secteurs :
- Paypal (Services financiers) – États-Unis : Paiements instantanés, prévention de la fraude.
- JioCinema (Telco/Media) – APAC: Intégration de données, analytique de clics, publicité, personnalisation.
- Audi (Automobile/Fabrication)– EMEA: Voitures connectées avec des exigences critiques et analytiques.
- New Relic (Logiciel/Cloud)– US: Observabilité et gestion des performances des applications (APM) à travers le monde.
Paypal: Séparation par zone de sécurité
PayPal est une plateforme de paiement numérique qui permet aux utilisateurs d’envoyer et de recevoir de l’argent en ligne de manière sécurisée et pratique dans le monde entier en temps réel. Cela nécessite une infrastructure Kafka évolutive, sécurisée et conforme.
Pendant le Black Friday 2022, le volume du trafic Kafka a atteint environ 1,3 billion de messages par jour. À l’heure actuelle, PayPal dispose de plus de 85 clusters Kafka, et chaque saison des fêtes, ils renforcent leur infrastructure Kafka pour gérer l’augmentation du trafic. La plateforme Kafka continue de s’adapter de manière transparente pour prendre en charge cette croissance du trafic sans aucun impact sur leur activité.
Aujourd’hui, la flotte Kafka de PayPal se compose de plus de 1 500 courtiers qui hébergent plus de 20 000 sujets. Les événements sont répliqués entre les clusters, offrant une disponibilité de 99,99%.
Les déploiements de clusters Kafka sont séparés dans différentes zones de sécurité au sein d’un centre de données:
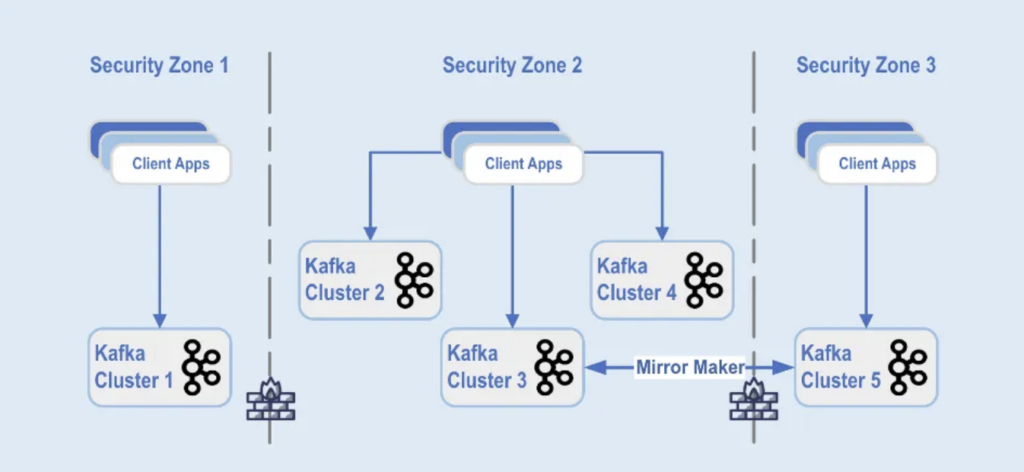 Source: Paypal
Source: Paypal
Les clusters Kafka sont déployés dans ces zones de sécurité, en fonction de la classification des données et des besoins commerciaux. La réplication en temps réel avec des outils tels que MirrorMaker (dans cet exemple, exécuté sur l’infrastructure Kafka Connect) ou Confluent Cluster Linking (utilisant une approche plus simple et moins sujette aux erreurs en utilisant directement le protocole Kafka pour la réplication) est utilisée pour refléter les données à travers les centres de données, ce qui aide à la récupération après sinistre et à la communication entre les zones de sécurité.
JioCinema : Séparation par cas d’utilisation et SLA
JioCinema est une plateforme de streaming vidéo en plein essor en Inde. Le service OTT de télécommunications est connu pour ses offres de contenu étendues, notamment les sports en direct tels que l’Indian Premier League (IPL) pour le cricket, un Anime Hub récemment lancé et des plans complets pour couvrir des événements majeurs tels que les Jeux olympiques de Paris 2024.
L’architecture des données s’appuie sur Apache Kafka, Flink et Spark pour le traitement des données, comme présenté lors du sommet Kafka India 2024 à Bangalore :
 Source: JioCinema
Source: JioCinema
Le streaming de données joue un rôle clé dans divers cas d’utilisation pour transformer les expériences des utilisateurs et la livraison de contenu. Plus de dix millions de messages par seconde améliorent les analyses, les insights utilisateurs et les mécanismes de livraison de contenu.
Les cas d’utilisation de JioCinema incluent :
- Communication inter-service
- Clickstream/Analytique
- Suivi des publicités
- Apprentissage automatique et personnalisation
Kushal Khandelwal, responsable de la plateforme de données, de l’analyse et de la consommation chez JioCinema, a expliqué que toutes les données ne se valent pas et que les priorités et les SLA diffèrent selon les cas d’utilisation :
 Source : JioCinema
Source : JioCinema
Le streaming de données est un voyage. Comme de nombreuses autres organisations dans le monde, JioCinema a commencé avec un grand cluster Kafka utilisant plus de 1000 sujets Kafka et plus de 100 000 partitions Kafka pour divers cas d’utilisation. Au fil du temps, une séparation des préoccupations concernant les cas d’utilisation et les SLA a évolué vers plusieurs clusters Kafka :
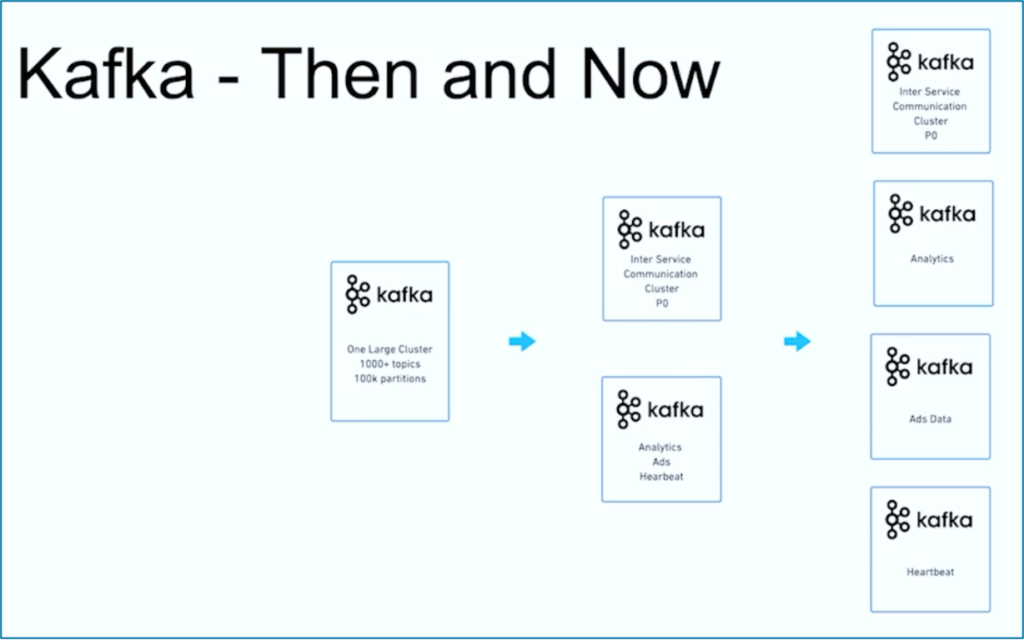 Source : JioCinema
Source : JioCinema
L’histoire de succès de JioCinema montre l’évolution commune d’une organisation de streaming de données. Explorons maintenant un autre exemple où deux clusters Kafka très différents ont été déployés dès le début pour un cas d’utilisation.
Audi : Opérations vs. Analytique pour Voitures Connectées
Le constructeur automobile Audi propose des voitures connectées dotées d’une technologie avancée qui intègre la connectivité Internet et des systèmes intelligents. Les voitures d’Audi permettent une navigation en temps réel, des diagnostics à distance et un divertissement amélioré dans la voiture. Ces véhicules sont équipés des services Audi Connect. Les fonctionnalités incluent les appels d’urgence, les informations sur le trafic en ligne et l’intégration avec des dispositifs de maison intelligente, pour améliorer la commodité et la sécurité des conducteurs.
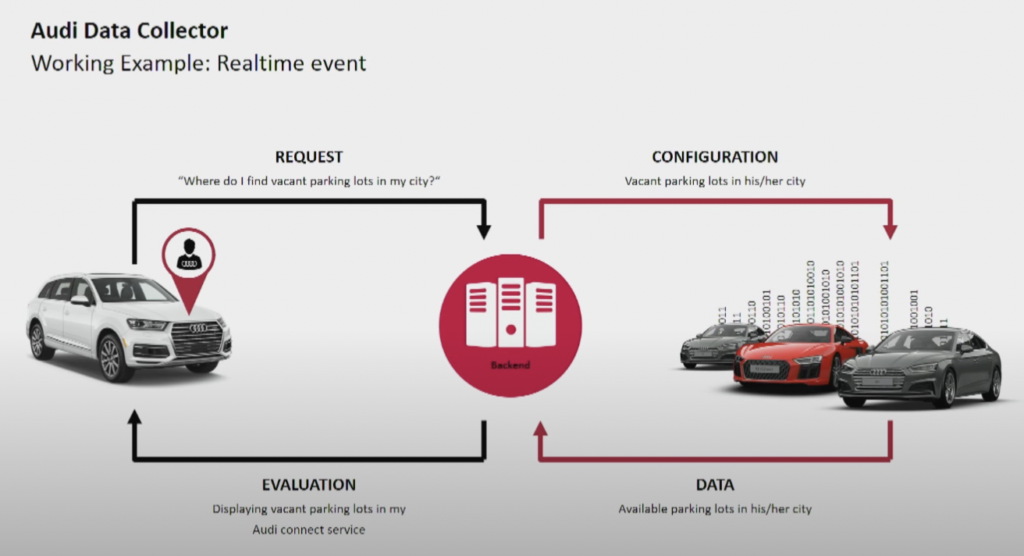 Source : Audi
Source : Audi
Audi a présenté son architecture de voiture connectée lors de la keynote du Kafka Summit 2018. L’architecture d’entreprise d’Audi repose sur deux clusters Kafka avec des SLA et des cas d’utilisation très différents.
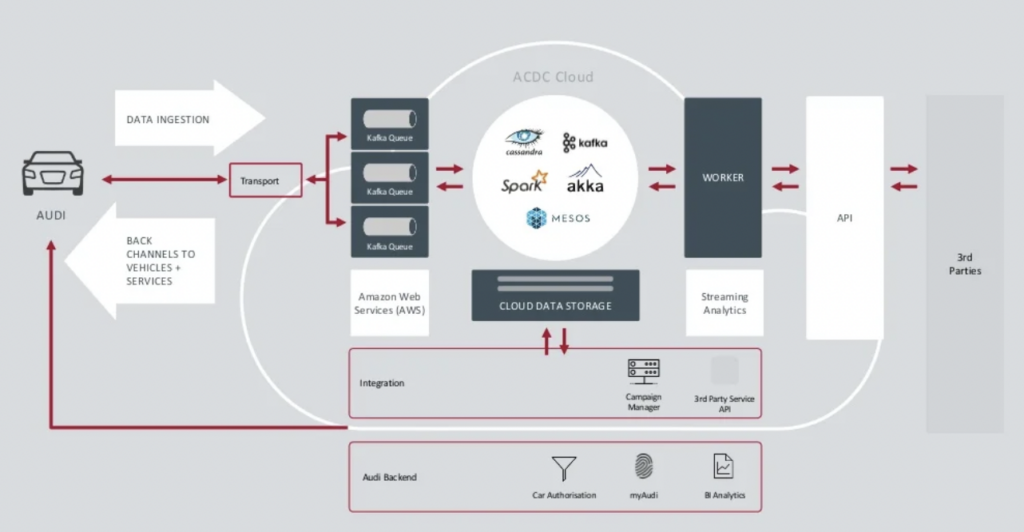 Source : Audi
Source : Audi
Le cluster Kafka d’ingestion de données est très critique.Il doit fonctionner 24h/24 à grande échelle. Il assure la connectivité de dernière mile à des millions de voitures en utilisant Kafka et MQTT. Les canaux de retour depuis le côté informatique vers le véhicule aident à la communication de services et aux mises à jour par voie aérienne (OTA).
Le cluster ACDC Cloud est le cluster Kafka analytique de l’architecture de voiture connectée d’Audi. Le cluster est la base de nombreux travaux analytiques, qui traitent d’énormes volumes de données IoT et de logs à grande échelle avec des frameworks de traitement par lots comme Apache Spark.
Cette architecture a été présentée en 2018. La devise d’Audi, « Le progrès par la technologie », montre comment l’entreprise a appliqué de nouvelles technologies pour l’innovation bien avant que la plupart des constructeurs automobiles déploient des scénarios similaires. Toutes les données des capteurs des voitures connectées sont traitées en temps réel et stockées pour une analyse et des rapports historiques.
New Relic : Observabilité Multi-Cloud Mondiale
New Relic est une plateforme d’observabilité basée sur le cloud qui fournit une surveillance des performances en temps réel et des analyses pour les applications et l’infrastructure à des clients du monde entier.
Andrew Hartnett, VP de l’Ingénierie Logicielle chez New Relic, explique comment le streaming de données est crucial pour l’ensemble du modèle commercial de New Relic:
« Kafka est notre système nerveux central. C’est une partie intégrante de tout ce que nous faisons. La plupart des services des 110 équipes d’ingénierie différentes avec des centaines de services touchent Kafka de quelque manière que ce soit dans notre entreprise, c’est donc vraiment critique. Ce que nous recherchions, c’est la capacité de croître, et Confluent Cloud nous l’a fournie. »
New Relic ingère jusqu’à 7 milliards de points de données par minute et est en passe d’ingérer 2,5 exaoctets de données en 2023. Alors que New Relic développe ses stratégies multi-cloud, les équipes utiliseront Confluent Cloud pour une vue globale sur tous les environnements.
« New Relic est multi-cloud. Nous voulons être là où se trouvent nos clients. Nous voulons être dans ces mêmes environnements, dans ces mêmes régions, et nous voulions avoir notre Kafka avec nous. » déclare Artnett dans une étude de cas de Confluent.
De multiples clusters Kafka sont la norme, pas une exception
Les architectures orientées événements et le traitement en continu existent depuis des décennies. L’adoption croît avec des frameworks open source comme Apache Kafka et Flink combinés à des services cloud entièrement gérés. De plus en plus d’organisations ont du mal avec l’échelle de leur Kafka. La gouvernance des données à l’échelle de l’entreprise, le centre d’excellence, l’automatisation du déploiement et des opérations, et les meilleures pratiques de l’architecture d’entreprise aident à fournir avec succès le streaming de données avec de multiples clusters Kafka pour des domaines métier indépendants ou collaboratifs.
Plusieurs clusters Kafka sont la norme, pas l’exception. Des cas d’utilisation tels que l’intégration hybride, la reprise après sinistre, la migration ou l’agrégation permettent la diffusion de données en temps réel partout avec les SLA nécessaires.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies