













En una era caracterizada por un aumento exponencial en la generación de datos, las organizaciones deben aprovechar eficazmente esta abundancia de información para mantener su ventaja competitiva. La búsqueda y análisis eficientes de datos de clientes — como identificar las preferencias de los usuarios para recomendaciones de películas o análisis de sentimientos — juegan un papel crucial en la toma de decisiones informadas y en la mejora de las experiencias de los usuarios. Por ejemplo, un servicio de streaming puede emplear búsqueda vectorial para recomendar películas adaptadas a los historiales de visualización y calificaciones individuales, mientras que una marca minorista puede analizar los sentimientos de los clientes para afinar las estrategias de marketing.
Como ingenieros de datos, tenemos la tarea de implementar estas soluciones sofisticadas, asegurando que las organizaciones puedan obtener información procesable de vastos conjuntos de datos. Este artículo explora las complejidades de la búsqueda vectorial utilizando Elasticsearch, centrándose en técnicas efectivas y mejores prácticas para optimizar el rendimiento. Al examinar estudios de caso sobre recuperación de imágenes para marketing personalizado y análisis de texto para la agrupación de sentimientos de los clientes, demostramos cómo la optimización de la búsqueda vectorial puede conducir a interacciones mejoradas con los clientes y un crecimiento empresarial significativo.
¿Qué es la búsqueda vectorial?
La búsqueda vectorial es un método poderoso para identificar similitudes entre puntos de datos al representarlos como vectores en un espacio de alta dimensionalidad. Este enfoque es particularmente útil para aplicaciones que requieren la recuperación rápida de elementos similares basados en sus atributos.
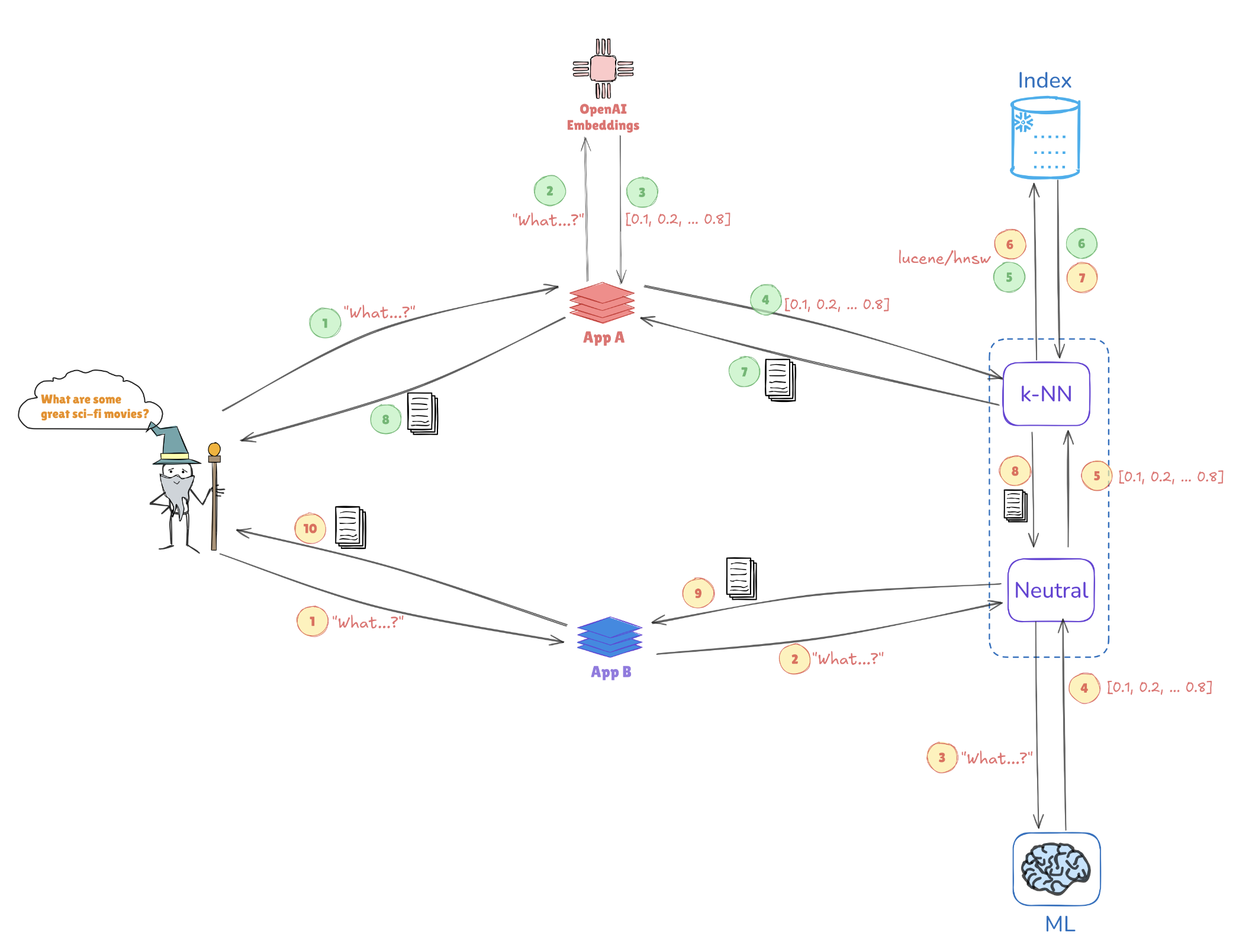
Ilustración de la Búsqueda Vectorial
Considere la ilustración a continuación, que muestra cómo las representaciones vectoriales permiten búsquedas de similitud:
- Incrustaciones de consulta: La consulta “¿Cuáles son algunas películas de ciencia ficción geniales?” se convierte en una representación vectorial, como [0.1, 0.2, …, 0.4].
- Indexación: Este vector se compara con vectores preindexados almacenados en Elasticsearch (por ejemplo, de aplicaciones como AppA y AppB) para encontrar consultas o puntos de datos similares.
- Búsqueda de k-NN: Utilizando algoritmos como Vecinos más Cercanos (k-NN), Elasticsearch recupera de manera eficiente las mejores coincidencias de los vectores indexados, lo que ayuda a identificar rápidamente la información más relevante.
Este mecanismo permite a Elasticsearch destacarse en casos de uso como sistemas de recomendación, búsquedas de imágenes y procesamiento de lenguaje natural, donde entender el contexto y la similitud es clave.
Beneficios Clave de la Búsqueda Vectorial con Elasticsearch
Soporte de Alta Dimensionalidad
Elasticsearch se destaca en la gestión de estructuras de datos complejas, esenciales para aplicaciones de IA y aprendizaje automático. Esta capacidad es crucial al tratar con tipos de datos multifacéticos, como imágenes o datos textuales.
Escalabilidad
Su arquitectura admite escalado horizontal, lo que permite a las organizaciones manejar conjuntos de datos en constante expansión sin sacrificar el rendimiento. Esto es vital a medida que los volúmenes de datos continúan creciendo.
Integración
Elasticsearch funciona sin problemas con la pila Elastic, proporcionando una solución integral para la ingesta, análisis y visualización de datos. Esta integración garantiza que los ingenieros de datos puedan aprovechar una plataforma unificada para diversas tareas de procesamiento de datos.
Mejores Prácticas para Optimizar el Rendimiento de Búsqueda de Vectores
1. Reducir Dimensiones de Vectores
Reducir la dimensionalidad de tus vectores puede mejorar significativamente el rendimiento de búsqueda. Técnicas como PCA (Análisis de Componentes Principales) o UMAP (Aproximación y Proyección de Variedades Uniformes) ayudan a mantener características esenciales mientras simplifican la estructura de datos.
Ejemplo: Reducción de Dimensionalidad con PCA
A continuación se muestra cómo implementar PCA en Python usando Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Indexar de Manera Eficiente
Aprovechar algoritmos de Vecino Más Cercano Aproximado (ANN) puede acelerar significativamente los tiempos de búsqueda. Considera usar:
- HNSW (Mundo Pequeño Navegable Jerárquico): Conocido por su equilibrio entre rendimiento y precisión.
- FAISS (Búsqueda de Similitud de Facebook AI): Optimizado para grandes conjuntos de datos y capaz de utilizar aceleración por GPU.
Ejemplo: Implementación de HNSW en Elasticsearch
Puedes definir la configuración de tu índice en Elasticsearch para utilizar HNSW de la siguiente manera:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Consultas por Lotes
Para mejorar la eficiencia, el procesamiento por lotes de múltiples consultas en una sola solicitud minimiza la sobrecarga. Esto es particularmente útil para aplicaciones con alto tráfico de usuarios.
Ejemplo: Procesamiento por Lotes en Elasticsearch
Puedes usar el punto de enlace _msearch para consultas por lotes:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Usar Caché
Implementa estrategias de caché para consultas de acceso frecuente para disminuir la carga computacional y mejorar los tiempos de respuesta.
5. Monitorear el Rendimiento
Analizar regularmente las métricas de rendimiento es crucial para identificar cuellos de botella. Herramientas como Kibana pueden ayudar a visualizar estos datos, permitiendo ajustes informados en tu configuración de Elasticsearch.
Ajuste de Parámetros en HNSW para un Rendimiento Mejorado
Optimizar HNSW implica ajustar ciertos parámetros para lograr un mejor rendimiento en grandes conjuntos de datos:
M(número máximo de conexiones): Aumentar este valor mejora el recall pero puede requerir más memoria.EfConstruction(tamaño de la lista dinámica durante la construcción): Un valor más alto conduce a un grafo más preciso pero puede aumentar el tiempo de indexación.EfSearch(tamaño de lista dinámico durante la búsqueda): Ajustar esto afecta la compensación entre velocidad y precisión; un valor mayor produce mejor recuperación pero tarda más en calcular.
Ejemplo: Ajustando Parámetros HNSW
Puede ajustar los parámetros HNSW en la creación de su índice de la siguiente manera:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Estudio de Caso: Impacto de la Reducción de Dimensionalidad en el Rendimiento de HNSW en Aplicaciones de Datos de Clientes
Recuperación de Imágenes para Marketing Personalizado
Las técnicas de reducción de dimensionalidad juegan un papel fundamental en la optimización de sistemas de recuperación de imágenes dentro de aplicaciones de datos de clientes. En un estudio, los investigadores aplicaron Análisis de Componentes Principales (PCA) para reducir la dimensionalidad antes de indexar imágenes con redes HNSW (Hierarchical Navigable Small World). PCA proporcionó un notable aumento en la velocidad de recuperación —vital para aplicaciones que manejan altos volúmenes de datos de clientes— aunque esto tuvo un costo de pérdida de precisión menor debido a la reducción de información. Para abordar esto, los investigadores también examinaron la Aproximación y Proyección de Variedades Uniformes (UMAP) como alternativa. UMAP preservó estructuras de datos locales de manera más efectiva, manteniendo los detalles intrincados necesarios para las recomendaciones de marketing personalizado. Aunque UMAP requería mayor potencia computacional que PCA, equilibró la velocidad de búsqueda con alta precisión, lo que lo convierte en una opción viable para tareas críticas de precisión.
Análisis de Texto para Agrupamiento de Sentimientos de Clientes
En el ámbito del análisis de sentimientos de los clientes, un estudio diferente encontró que UMAP superó a PCA en la agrupación de datos de texto similares. UMAP permitió que el modelo HNSW agrupara los sentimientos de los clientes con mayor precisión, lo que supone una ventaja en la comprensión de los comentarios de los clientes y la entrega de respuestas más personalizadas. El uso de UMAP facilitó valores más pequeños de EfSearch en HNSW, mejorando la velocidad y precisión de búsqueda. Esta mayor eficiencia en la agrupación permitió una identificación más rápida de los sentimientos relevantes de los clientes, mejorando los esfuerzos de marketing dirigido y la segmentación de clientes basada en sentimientos.
Integración de Técnicas de Optimización Automatizadas
Optimizar la reducción de dimensionalidad y los parámetros de HNSW es esencial para maximizar el rendimiento de los sistemas de datos de clientes. Las técnicas de optimización automatizadas simplifican este proceso de ajuste, asegurando que las configuraciones seleccionadas sean efectivas en diversas aplicaciones:
- Búsqueda en cuadrícula y aleatoria: Estos métodos ofrecen una exploración amplia y sistemática de parámetros, identificando configuraciones adecuadas eficientemente.
- Optimización bayesiana: Esta técnica se centra en los parámetros óptimos con menos evaluaciones, conservando recursos computacionales.
- Validación cruzada: La validación cruzada ayuda a validar parámetros en diversos conjuntos de datos, asegurando su generalización a diferentes contextos de datos de clientes.
Abordando Desafíos en la Automatización
Integrar la automatización dentro de la reducción de dimensionalidad y los flujos de trabajo HNSW puede presentar desafíos, especialmente en la gestión de las demandas computacionales y la evitación del sobreajuste. Las estrategias para superar estos desafíos incluyen:
- Reducir la sobrecarga computacional: Utilizar procesamiento paralelo para distribuir la carga de trabajo reduce el tiempo de optimización, mejorando la eficiencia del flujo de trabajo.
- Integración modular: Un enfoque modular facilita la integración sin problemas de sistemas automatizados en flujos de trabajo existentes, reduciendo la complejidad.
- Prevenir el sobreajuste: La validación robusta a través de validación cruzada asegura que los parámetros optimizados funcionen consistentemente en diferentes conjuntos de datos, minimizando el sobreajuste y mejorando la escalabilidad en aplicaciones de datos de clientes.
Conclusión
Para aprovechar al máximo el rendimiento de búsqueda vectorial en Elasticsearch, es esencial adoptar una estrategia que combine la reducción de dimensionalidad, la indexación eficiente y la sintonización cuidadosa de parámetros. Al integrar estas técnicas, los ingenieros de datos pueden crear un sistema de recuperación de datos altamente receptivo y preciso. Los métodos de optimización automatizada elevan aún más este proceso, permitiendo un refinamiento continuo de los parámetros de búsqueda y las estrategias de indexación. A medida que las organizaciones dependen cada vez más de información en tiempo real a partir de vastos conjuntos de datos, estas optimizaciones pueden mejorar significativamente las capacidades de toma de decisiones, ofreciendo resultados de búsqueda más rápidos y relevantes. Adoptar este enfoque sienta las bases para una escalabilidad futura y una mejor capacidad de respuesta, alineando las capacidades de búsqueda con las demandas comerciales en evolución y el crecimiento de los datos.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch